

Algorithmic Adaptations to Extreme Scale · 2014-05-20 · e.g., P2P and P2M/M2M/M2M/L2P n...
54
Algorithmic Adaptations to Extreme Scale David Keyes Division of Computer, Electrical and Mathematical Sciences and Engineering King Abdullah University of Science and Technology
Transcript of Algorithmic Adaptations to Extreme Scale · 2014-05-20 · e.g., P2P and P2M/M2M/M2M/L2P n...

CoDesign 2013
Algorithmic Adaptations to Extreme Scale
David Keyes Division of Computer, Electrical and Mathematical Sciences and Engineering King Abdullah University of Science and Technology

CoDesign 2013
Happy birthday, John Pople
1. Identify your target accuracy. 2. Precisely formulate a general
mathematical procedure. 3. Implement it as an efficient
computational algorithm. 4. Thoroughly and systematically
test the model. 5. Apply the model.
Five-sentence paraphrase of Pople’s Nobel address, J. Chem. Phys., May 2004
First Nobel Prize (1998) for a computational method (Gaussian, 1970)
Born 31 October 1925 Died 15 March 2004

CoDesign 2013
BSP generation
Energy-aware generation
To paraphrase Benjamin Franklin:
“An [infrastructure], if you can keep it.”

CoDesign 2013
Conclusions up front n There is hope for some of today’s best algorithms
to make the leap to greater arithmetic intensity reduced synchrony greater SIMD-style shared-memory concurrency built-in resilience (“algorithm-based fault tolerance” or
ABFT) to arithmetic faults or lost/delayed messages
n Programming models and runtimes will have to be stretched to accommodate
n Everything should be on the table for trades, over the thresholds of disciplines è co-design

CoDesign 2013
Caveats n This talk is not a full algorithmic big picture, but
some pixels out of that big picture … a point of light here, a point of light there… we are confident that a full picture will emerge
n By Day #3 in the workshop, we skip the recitation of the architectural constraints

CoDesign 2013
Philosophy n Algorithms must adapt to span the gulf between
greedy applications and hostile architectures J
full employment!

CoDesign 2013
Motivation for algorithmic attention n High performance with high productivity on
“the multis”: Multi-scale, multi-physics problems in multi-dimensions Using multi-models and/or multi-levels of refinement Exploiting polyalgorithms in adaptively multiple precisions
in multi-protocol hybrid programming styles On multi-core, massively multi-processor systems Requiring a multi-disciplinary approach

CoDesign 2013
Motivation for algorithmic attention n High performance with high(-est possible)
productivity on “the multis”: Multi-scale, multi-physics problems in multi-dimensions Using multi-models and/or multi-levels of refinement Exploiting polyalgorithms in adaptively multiple precisions
in multi-protocol hybrid programming styles On multi-core, massively multi-processor systems Requiring a multi-disciplinary approach
Can’t cover all this in 30 minutes J, but … Given the architectural stresses, how can new algorithms help?

CoDesign 2013
Algorithmic agenda n New formulations with
greater arithmetic intensity (flops per byte moved into and out of registers and upper cache) including assured accuracy with (adaptively) less floating-point
precision reduced synchronization
less frequent and/or less global
greater SIMD-style thread concurrency for accelerators algorithmic resilience to various types of faults
n Quantification of trades between limiting resources n Plus all of the exciting analytical agendas that
exascale is meant to exploit

CoDesign 2013
Arithmetic intensity of numerical kernels
c/o R. Yokota, KAUST, et al.
1/16 1/8 1/4 1/2 1 2 4 8 16 32 64 128 2568
16
32
64
128
256
512
1024
2048
Operational intensity (flop/byte)
Double
pre
cis
ion p
erf
orm
ance (
Gflop/s
)
FM
M P
2P
DG
EM
M
FM
M M
2L (
Cart
esia
n)
FM
M M
2L (
Spherical)
3D
FF
T
Ste
ncil
SpM
V
Intel Sandy Bridge
AMD Abu Dhabi
IBM BG/Q
Fujitsu FX10
NVIDIA Kepler
Intel Xeon Phi
two orders of magnitude varia1on
CoDesign 2013
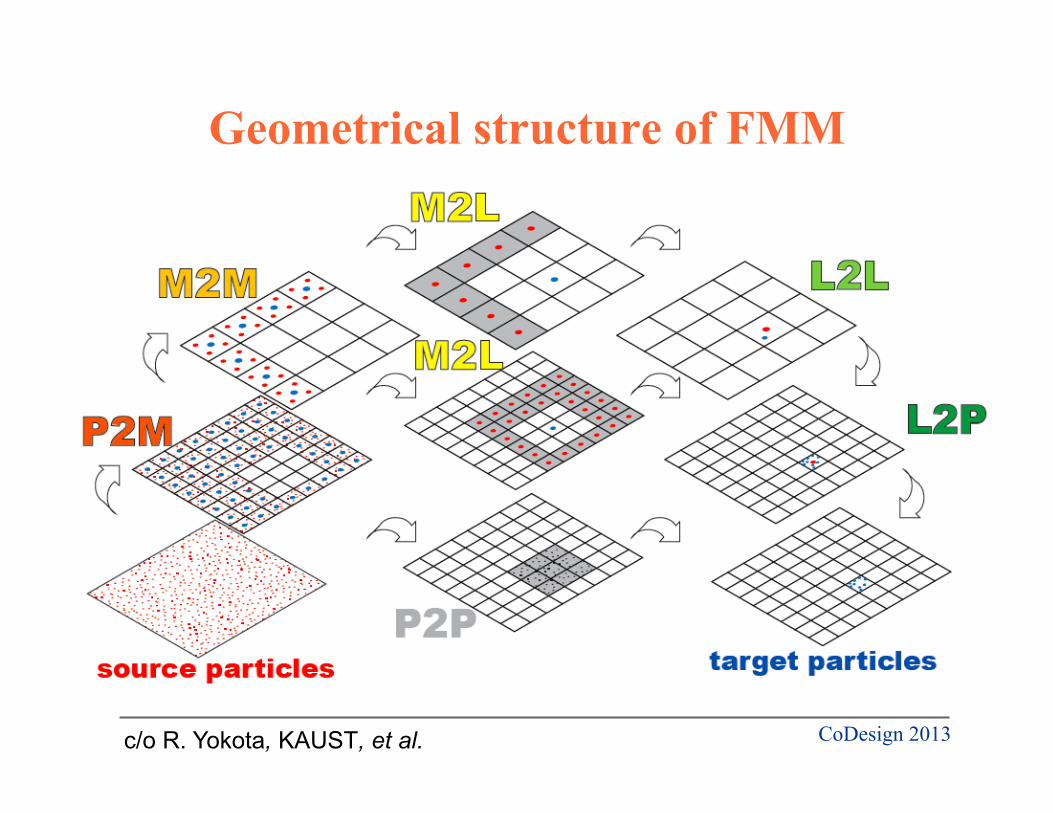
Geometrical structure of FMM
c/o R. Yokota, KAUST, et al.

CoDesign 2013
Hierarchical interactions of FMM
c/o R. Yokota, KAUST, et al.

CoDesign 2013
FMM vs. FFT in weak scaling
! " #$ %!& $'(#'
')&
')$
')#
')"
!
!)&
*+,-./01203/14.55.5
67/788.80.22949.:4;
<==53.4>/780,.>?1@
Weak scaling of a vortex-‐formula1on 3D Navier-‐Stokes code simula1ng decaying isotropic turbulence, referenced to the pseudo-‐spectral method, which uses FFT.
FFT: 14% parallel efficiency at 4096 processes, no GPU use. FMM: 74% going from one to 4096 processes at one GPU per MPI process, 3 GPUs per node. Largest problem corresponds to a 4096^3 mesh, i.e., almost 69 billion points (about 17 million points per process).
Run on the TSUBAME 2.0 system of the Tokyo Ins1tute of Technology.
c/o R. Yokota, KAUST, et al.

CoDesign 2013
FMM as preconditioner n FMM is a solver for free-space problems for which
one has a Green’s function n For finite boundaries, combines with BEM n FMM and BEM have controllable truncation
accuracies; can precondition other discretizations of the same PDE
n Can be regarded as a preconditioner for “nearby” problems, e.g., for !2 !" (1+!(!x))!

CoDesign 2013
FMM’s role in solving PDEs
The preconditioner is reduced to a matvec, like the forward operator itself, the same philosophy of the sparse approximate inverse (SPAI), or Tufo-Fischer, but cheaper.
More concurrency, more intensity, less synchrony than ILU, MG, DD, etc.
BEM FMM

CoDesign 2013
FMM/BEM preconditioning of FEM-discretized Poisson
c/o R. Yokota, KAUST, et al.

CoDesign 2013 c/o R. Yokota, KAUST, et al.
FMM/BEM preconditioning of FEM-discretized Poisson

CoDesign 2013
FMM vs AMG preconditioning: strong scaling on Stampede*
* FEM Poisson problem, Dirichlet BCs handled via BEM for FMM (cost included) c/o R. Yokota, KAUST, et al.

CoDesign 2013
Synchronization reduction – FMM n Within an FMM application, data pipelines of different types
can be executed asynchronously e.g., P2P and P2M/M2M/M2M/L2P
n Geographically distinct targets can be updated completely asynchronously
n Obviously, different simultaneously available right-hand sides can be solved asynchronously
n Proceeding without “best available” data in successive applications, errors made by “lagging” force
computations for distant sources could be bounded under other known tolerances

CoDesign 2013
FMM as preconditioner n Of course, when “trapped” inside a conventional
preconditioned Krylov, gives up some of its potential benefits of relaxed synchrony because of the synchrony of the Krylov method
n Krylov methods need rework, generally

CoDesign 2013
Less synchronous pipelined GMRES
c/o P. Ghysels, Antwerp, et al.
A reorganization using non-blocking global reductions requires additional flops, but “flops are free”

CoDesign 2013
Pipelined p(l) Krylov implementations
c/o P. Ghysels, Antwerp, et al.
Simulated data
Strong scaling of iterations/sec for 8 billion unknowns in GMRES l is the number of SpMVs needed to hide a reduction
~3X

CoDesign 2013
n Classical: amortize communication over many power/reduction steps s-step Krylov methods: power kernels with wide halos and extra
orthogonalization Block Krylov methods: solve b several independent systems at
once with improved convergence (based on λmax/λb rather than λmax/λmin)
“tall skinny QR” (n×m): recursively double the row-scope of independent QRs – log p messages for p processors (vs. n log p)
n Invade classical steps: operations dynamically scheduled with DAGs NUMA-aware (local) work-stealing
Reduction of frequency of communication and synchronization for sparse Ax=b

CoDesign 2013
Reduction of domain of synchronization in nonlinearly preconditioned Newton
• Nonlinear Schwarz replaces a Newton method for a global nonlinear system, F(u)=0, – which computes a global distributed Jacobian matrix and
synchronizes globally in both the Newton step and in solving the global linear system for the Newton
• … with a set of local problems on subsets of the global nonlinear system – each local problem has only local synchronization – all of the linear systems for local Newton updates have only local
synchronization – there is still global synchronization in a number of steps hopefully
much fewer than required in the original Newton method

CoDesign 2013
Reducing over-ordering and synchronization through dataflow: e.g., generalized eigensolver
c/o H. Ltaief (KAUST)

CoDesign 2013
Loop nests and subroutine calls, with their over-orderings, can be replaced with DAGs
Diagram shows a dataflow ordering of the steps of a 4×4 symmetric generalized eigensolver
Nodes are tasks, color-coded by type, and edges are data dependencies
Time is vertically downward
Wide is good; short is good
c/o H. Ltaief (KAUST)
CoDesign 2013
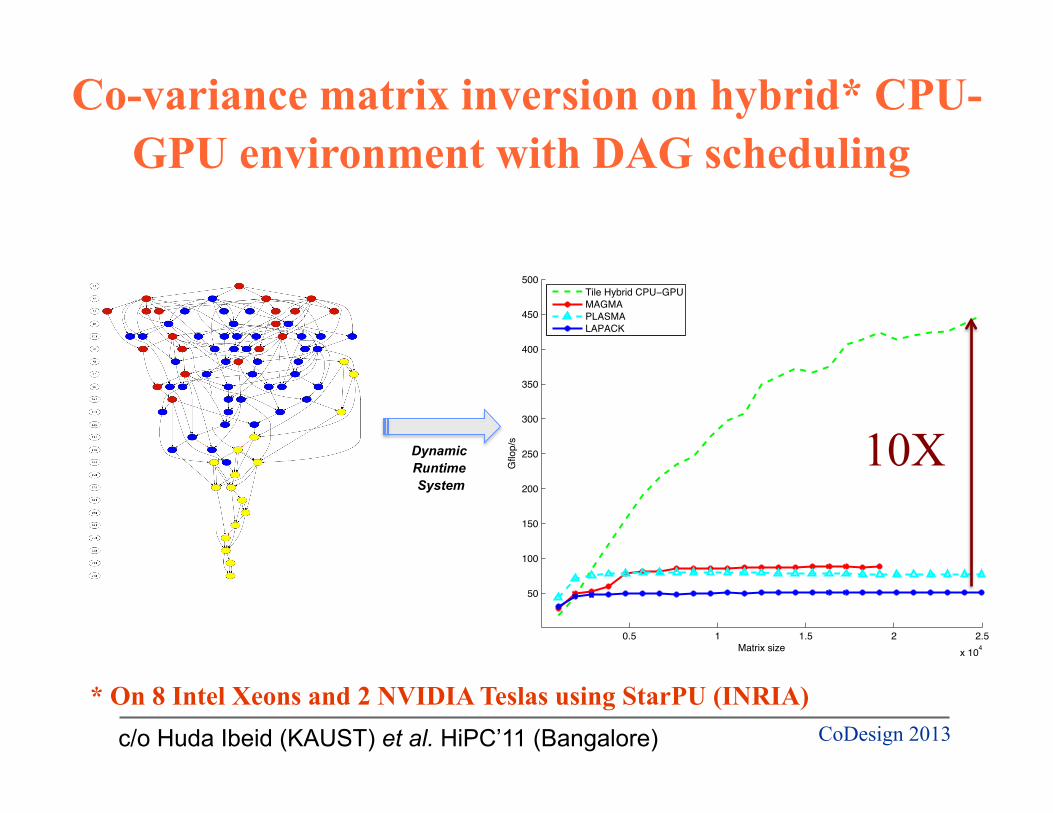
Co-variance matrix inversion on hybrid* CPU-GPU environment with DAG scheduling
0.5 1 1.5 2 2.5x 104
50
100
150
200
250
300
350
400
450
500
Matrix size
Gflo
p/s
Tile Hybrid CPU−GPUMAGMAPLASMALAPACK
Dynamic Runtime System
10X
c/o Huda Ibeid (KAUST) et al. HiPC’11 (Bangalore)
* On 8 Intel Xeons and 2 NVIDIA Teslas using StarPU (INRIA)

CoDesign 2013
Less synchronization vulnerability from over-decomposition with work-stealing
n Even within the strictures of periodic synchronization, vulnerability can be reduced by boosting task concurrency above the number of threads and exploiting NUMA-aware work-stealing
CoDesign 2013
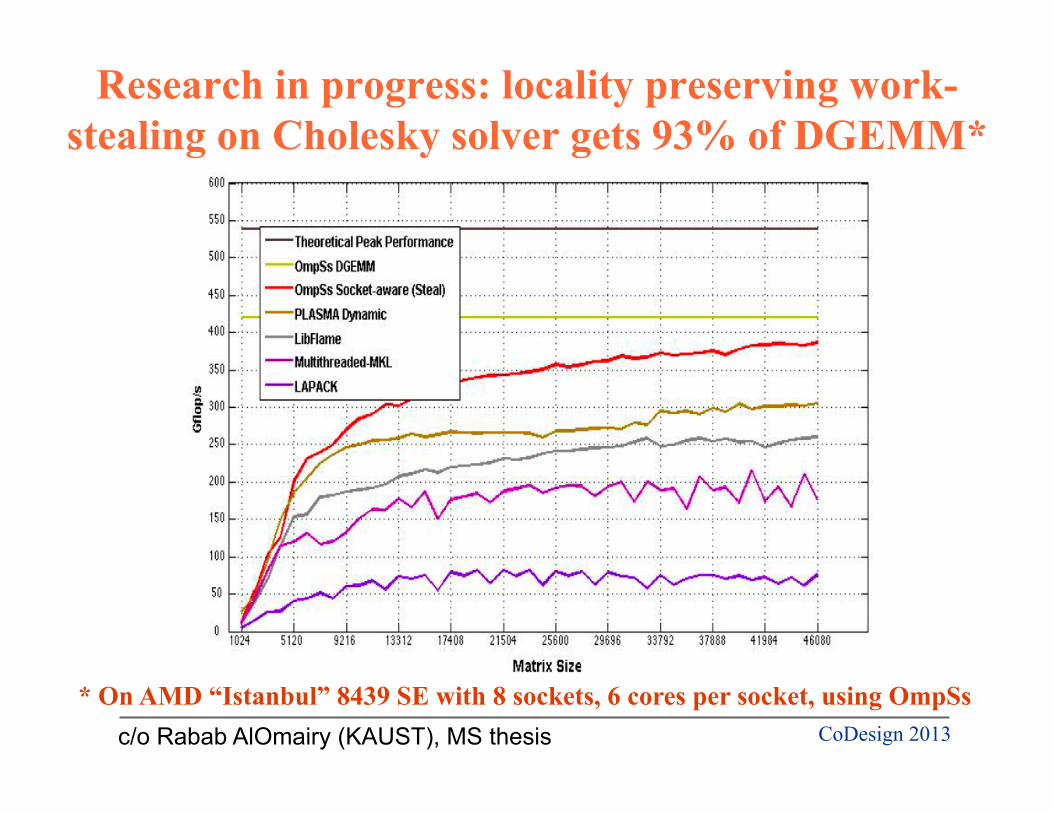
Research in progress: locality preserving work-stealing on Cholesky solver gets 93% of DGEMM*
c/o Rabab AlOmairy (KAUST), MS thesis
* On AMD “Istanbul” 8439 SE with 8 sockets, 6 cores per socket, using OmpSs

CoDesign 2013
Exploiting accelerators in stencil computations
c/o Ahmad Abdelfatteh (KAUST)
CoDesign 2013
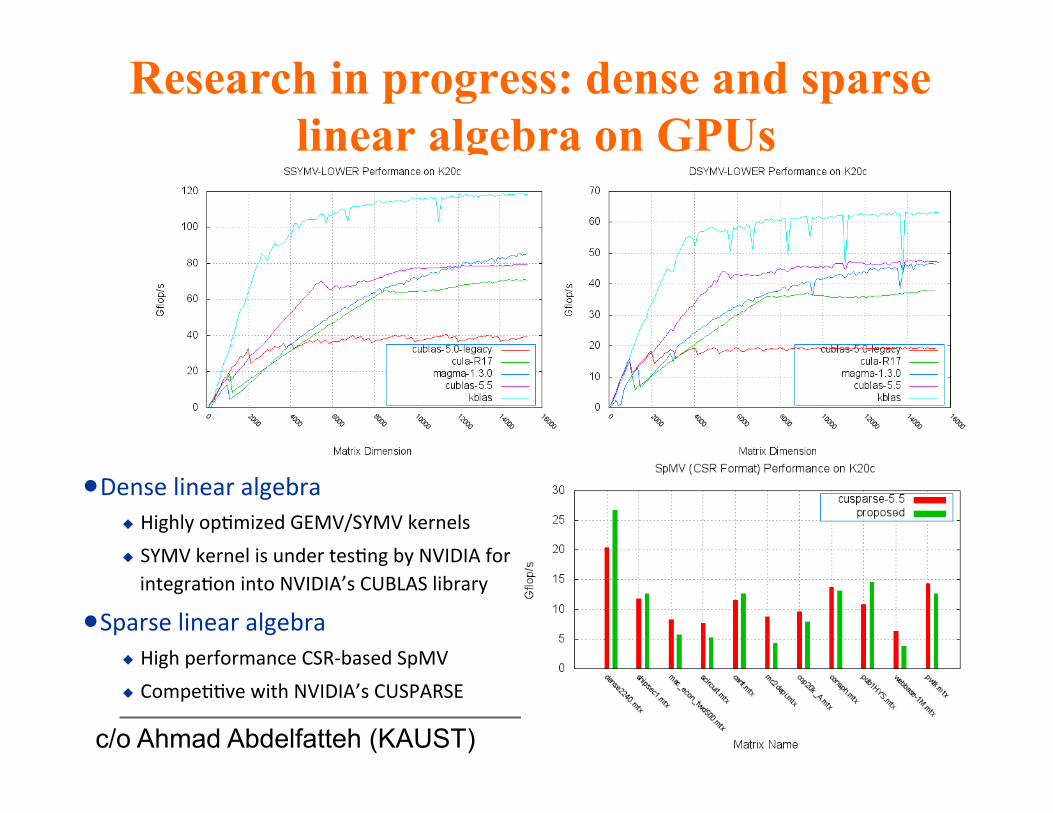
Research in progress: dense and sparse
linear algebra on GPUs
n Dense linear algebra Highly op1mized GEMV/SYMV kernels SYMV kernel is under tes1ng by NVIDIA for integra1on into NVIDIA’s CUBLAS library
n Sparse linear algebra High performance CSR-‐based SpMV Compe11ve with NVIDIA’s CUSPARSE
c/o Ahmad Abdelfatteh (KAUST)

CoDesign 2013
Optimal hierarchical algorithms
n Six classes of optimal hierarchical solvers Fast Multipole Tree codes H-matrices Sparse grids Multigrid Fast Fourier Transforms
n What is the potential for reducing over-ordering and exposing concurrency with these flop-optimal methods? If the algorithm is not first optimal, we may not care

CoDesign 2013
Tree codes
n “The medium is the message” n The tree structure already exposes independent
operations at each leaf, with data flow ordering as one progresses up the tree

R
R R
R R
R
R
R
R R
F RR F
F RR F
F RR F
R
H
H R H H
R H R R H R R R R H R R
F R R F F R R F F R R F
H
H R
H H
R R
R R
H
H
R R
R R
R R
H
H-matrix compression to low rank

CoDesign 2013
H-matrices
n Task of transformation of original full-rank system to H form creates independent concurrent problems in each block, which synchronize only upon application of the hierarchical form
n Depending upon the type of operations executed with the H-matrix, one may need to repeat this reduction, e.g., to add two H-matrices

CoDesign 2013
Sparse grids for spatial data n Saving most simulation results to persistent storage will be
impractical; instead hybrid in situ / in transit analysis n Challenges:
n On-the-fly compression
n Algorithmic idea: sparse grids
O(nd )!O(n " (logn)d#1)
O(n! p )"O(n! p # (logn)k )
Storage complexity (spatial dimension d)
Representation accuracy (order p; k depends on p, d)
c/o H. Bungartz et al. (TU Munich)

CoDesign 2013
How do sparse representations work?
c/o J. Garcke et al. (U Bonn)

CoDesign 2013
Sparse grids n The “combination technique” is the preferred form of sparse
grids in practical implementations, because it allows more regular memory accesses
n The combination method seems to have promise for massive concurrency at a distribution of granularities for operator application however, there is still synchronization at the end of every time
interval where the globally distributed action of the operator is required
n Whereas H-matrices exploit low rank in operators, sparse grids (hierarchical finite elements) simply exploit continuity in functions in the old days, we simply stored dense lots of doubles now we adapt to architectural realities and so teach our children

CoDesign 2013
Multigrid
n With respect to smoothing, for every multiplicative method there is a corresponding additive method that is generally less convergent (per iteration) and considerably more concurrent and asynchronous Additive methods open up a variety of methods for breaking
synchronization between levels (e.g., AFAC, BPX)
n Interpolation/coarsening generally possesses greater concurrency and independence than smoothing (exceptions include LU-based interpolations)
n Problem-size imbalance between levels in a multiplicative method is an increasingly serious problem as MG approaches the exascale

CoDesign 2013
Fast Fourier Transforms n An optimal complexity parallel algorithm exists, e.g.,
O((Carith log N + Ccomm log P)(Nd/P)), with log P latency, which is tree-based, but Carith is very large, and not yet competitive at petascale (butterfly, approximate, uses asymptotics in discarding some target-box/source-box interactions) [Candes-Demanet-Ying, Michielssen-Boag, Rokhlin-O’Neill]
n Synchrony is reduced by replacing some strict interactions with low-rank approximation
n But if the goal is Poisson solvers, use FMM J

CoDesign 2013
Other hopeful algorithmic directions
n 74 two-page whitepapers contributed by the international community to the Exascale Mathematics Working Group (EMWG) at
https://collab.mcs.anl.gov/display/examath/Submitted+Papers
n 20-21 August 2013 in DC n Randomized algorithms n On-the-fly data compression n Algorithmic-based fault tolerance n Adaptive precision algorithms n Concurrency from dimensions beyond space (time, phase
space, stochastic parameters) n etc.

CoDesign 2013
Randomized algorithms in subspace correction methods
n Solve Ax=b by pointwise relaxation
n Gauss-Seidel (1823) n deterministic and pre-
ordered n Southwell (1935)
n deterministic and dynamically ordered
n Griebel-Oswald (2011) n random (and
dynamically ordered) n Excellent convergence w/
fault tolerance and synchronization reduction
c/o M. Griebel et al. (U Bonn)

CoDesign 2013
Algorithm-based fault tolerance Fully reliable executions may simply come to be regarded
as too costly/synchronization-vulnerable Algorithm-based fault tolerance (ABFT) will be much
cheaper than hardware and OS-mediated reliability Developers will partition their data and their program units into
two sets A small set that must be done reliably (with today’s standards
for memory checking and IEEE ECC) A large set that can be done fast and unreliably, knowing the
errors can be either detected, or their effects rigorously bounded
Examples in direct and iterative linear algebra anticipated by Von Neumann, 1956 (“Synthesis of reliable
organisms from unreliable components”)

CoDesign 2013
How will PDE computations adapt? n Programming model will still be message-passing (due to
large legacy code base), adapted to multicore or hybrid processors beneath a relaxed synchronization MPI-like interface
n Load-balanced blocks, scheduled today with nested loop structures will be separated into critical and non-critical parts
n Critical parts will be scheduled with directed acyclic graphs (DAGs)
n Noncritical parts will be made available for NUMA-aware work-stealing in economically sized chunks

CoDesign 2013
Adaptation to asynchronous programming styles
n To take full advantage of such asynchronous algorithms, we need to develop greater expressiveness in scientific programming create separate threads for logically separate tasks,
whose priority is a function of algorithmic state, not unlike the way a time-sharing OS works
join priority threads in a directed acyclic graph (DAG), a task graph showing the flow of input dependencies; fill idleness with noncritical work or steal work

CoDesign 2013
n Can write code in styles that do not require artifactual synchronization
n Critical path of a nonlinear implicit PDE solve is essentially … lin_solve, bound_step, update; lin_solve, bound_step, update …
n However, we often insert into this path things that could be done less synchronously, because we have limited language expressiveness Jacobian and preconditioner refresh convergence testing algorithmic parameter adaptation I/O, compression visualization, data mining
Evolution of Newton-Krylov-Schwarz: breaking the synchrony stronghold

CoDesign 2013
Sources of nonuniformity n System
Already important: manufacturing, OS jitter, TLB/cache performance variations, network contention,
Newly important: dynamic power management, more soft errors, more hard component failures, software-mediated resiliency, etc.
n Algorithmic physics at gridcell/particle scale (e.g., table lookup, equation of
state, external forcing), discretization adaptivity, solver adaptivity, precision adaptivity, etc.
n Effects of both types are similar when it comes to waiting at synchronization points
n Possible solutions for system nonuniformity will improve programmability, too

CoDesign 2013
Trends (Beckman)

CoDesign 2013
More trends (following Beckman)
User-controlled data replication � System-controlled data replication �
User-controlled error handling � System-controlled error handling �
Adaptive variable precision � Default high precision �
Computing with “deltas”� Computing directly with QoI�
High order discretizations� Low order discretizations�
Exploitation of low rank� Default full rank�

CoDesign 2013
Required software enabling technologies Model-related
Geometric modelers Meshers Discretizers Partitioners Solvers / integrators Adaptivity systems Random no. generators Subgridscale physics Uncertainty
quantification Dynamic load balancing Graphs and
combinatorial algs. Compression
Development-related u Configuration systems u Source-to-source
translators u Compilers u Simulators u Messaging systems u Debuggers u Profilers
Production-related u Dynamic resource
management u Dynamic performance
optimization u Authenticators u I/O systems u Visualization systems u Workflow controllers u Frameworks u Data miners u Fault monitoring,
reporting, and recovery
High-end computers come with little of this stuff.
Most has to be contributed by the user community

Extreme Compu1ng
Simula1on Data Architecture
Par1al Diff Eqs
Par1cle Methods
Eigen systems
Assimila1on & Inversion Analy1cs Sobware Hardware
Aramco TOTAL KACARE
KACST KAPSARC KAIMRC
SABIC
Combus1on Climate Seismic
Reservoirs
Molecular Dynamics
Quantum Chemistry
Red Sea Modeling
Bioinforma1cs Sta1s1cs
Exascale Programming
Models
Green devices Biomime1cs
Scope of Extreme CompuRng at KAUST, with stakeholder Re-‐ins
IBM Intel
NVIDIA
KACST KAPSARC KAIMRC

CoDesign 2013
CS
Math
Applica1ons
Enabling technologies respond to all
Many applica1ons
drive
U. Schwingenschloegl
A. Fratalocchi G. Schuster F. Bisetti R. Samtaney
G. Stenchikov
I. Hoteit V. Bajic M. Mai

Strategic Initiative for Extreme Computing: Students
Ahmad Wajih Gustavo Huda Lulu Tareq Chengbin Enas Abdelfageh Boukaram Chavez Ibeid Liu Malas Peng Yunis
Kai Hatem Rio Saber Rooh Jen Xiangliang Aron Bao Ltaief Yokota Feki Khurram Pestana Zhang Ahmadia
Scientists Affiliates Alumni Abduljabbar Al Farhan Al Harthi Al Omairy Alonazi Amir Siddiqui Sukkari
Mustafa Mohamed Noha Rabab Amani Sahar Shahzeb Dalal
✔ ✔ ✔ ✔
✔
✔ ✔ ✔




![UM Basic Config L2P Rel42 en[1]](https://static.fdocuments.in/doc/165x107/547eed73b4af9faa158b5799/um-basic-config-l2p-rel42-en1.jpg)













