
Aleksei Udatšnõi – Crunching thousands of events per second in nearly real time - NoSQL matters...
29
Crunching thousands of events per second in nearly real time Aleksei Udatšnõi Lead Software Engineer @ Softonic NoSQL matters Barcelona 22 November 2014 Photo by Chris Loxton/ CC BY
-
Upload
nosqlmatters -
Category
Data & Analytics
-
view
256 -
download
0
Transcript of Aleksei Udatšnõi – Crunching thousands of events per second in nearly real time - NoSQL matters...

Crunching thousands of events per second in nearly real time
Aleksei Udatšnõi
Lead Software Engineer @ Softonic
NoSQL matters Barcelona
22 November 2014
Photo by Chris Loxton/ CC BY

Softonic use case

Softonic use case
• Software guide, reviews, news, downloads
• Originally built on LAMP stack
• 100M+ visitors monthly
• 1000+ tracking events/sec generated

Big Data challenges
• Track large volume of events
• Process the stream of events in near real time
• Present insights to stakeholders

Softonic Developer Center
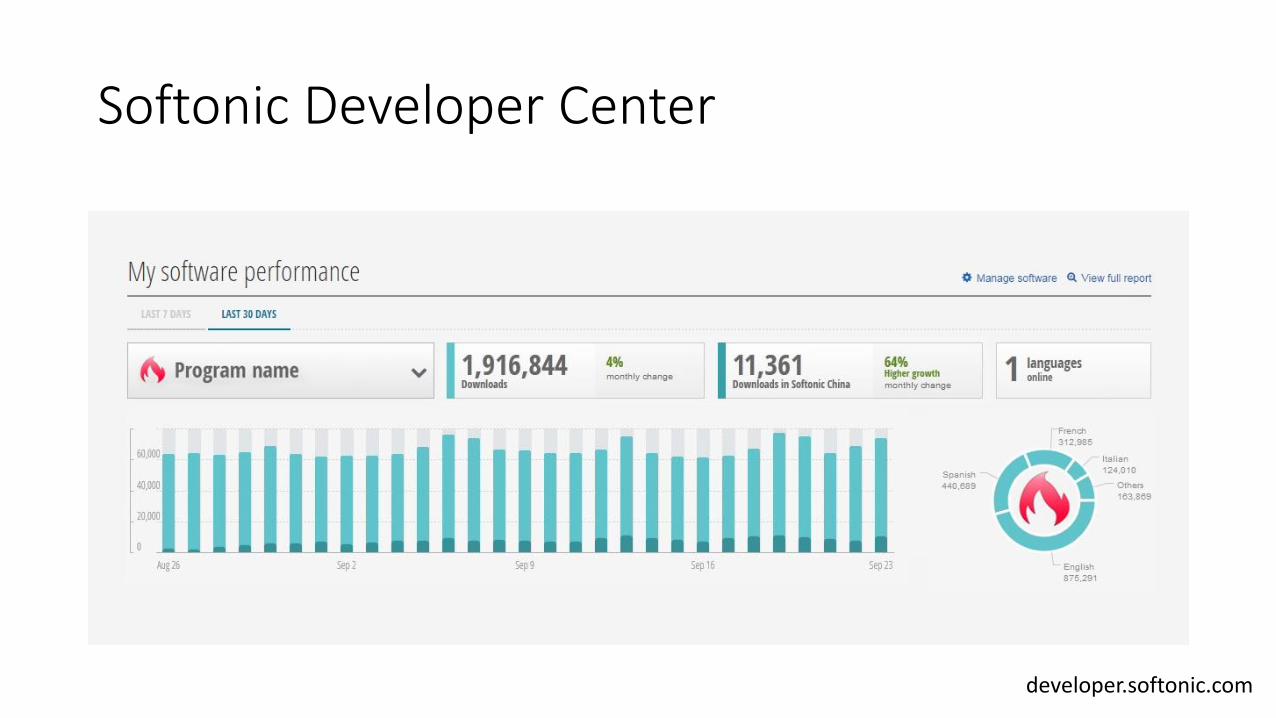
Softonic Developer Center
developer.softonic.com

Legacy RDMBS based solution
INSERT INTO tracking VALUES ..

Big Data architecture

Data ingestion with Flume
Photo by Bilfinger SE / CC BY
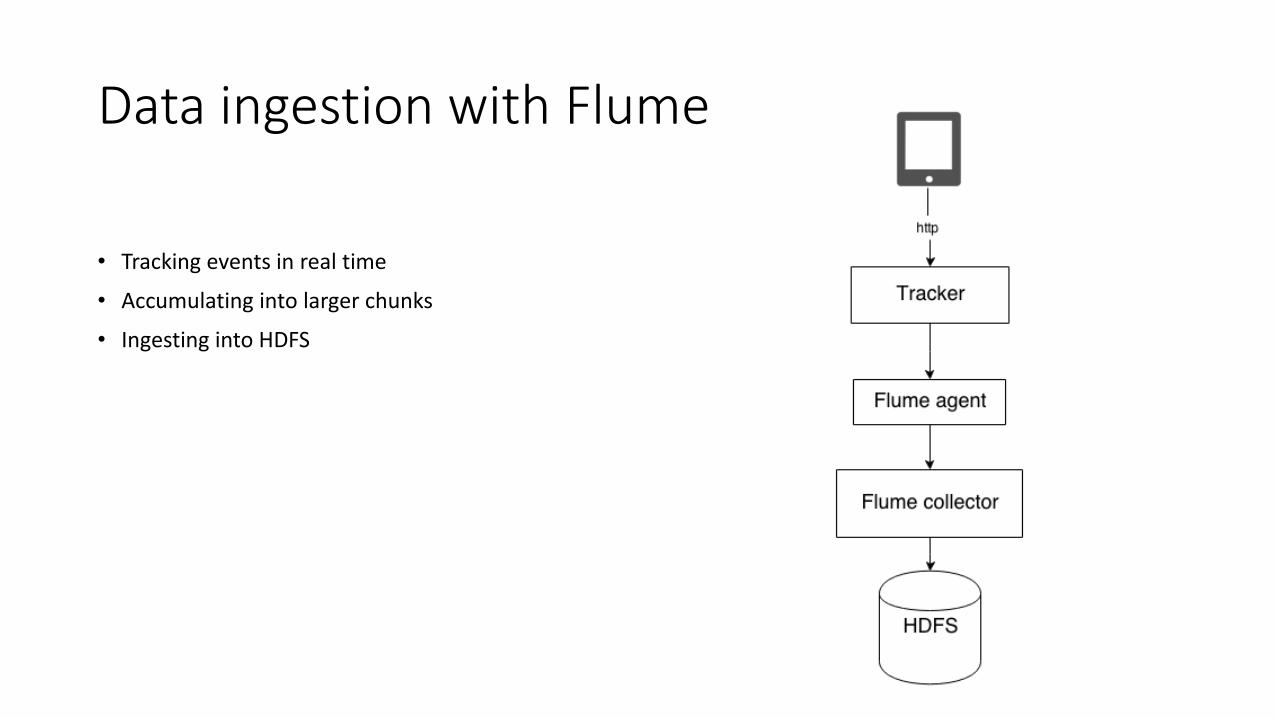
Data ingestion with Flume
• Tracking events in real time
• Accumulating into larger chunks
• Ingesting into HDFS
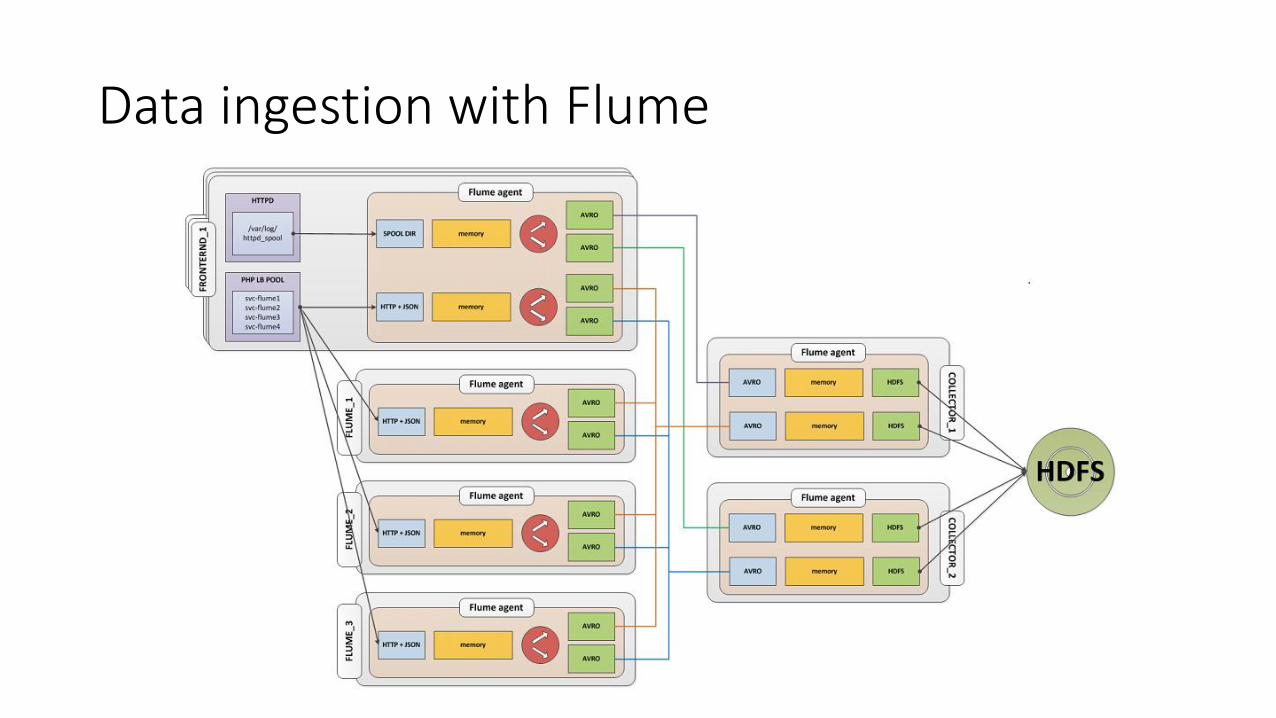
Data ingestion with Flume

Flume considerations
• Flume vs. alternatives (Kafka, Storm)

Flume considerations
• Flume vs. alternatives (Kafka, Storm)
• Prepare failover plan

Flume considerations
• Flume vs. alternatives (Kafka, Storm)
• Prepare failover plan
• Configuring rolling interval

Data processing
Photo by bonzoWiltsUK/ CC BY
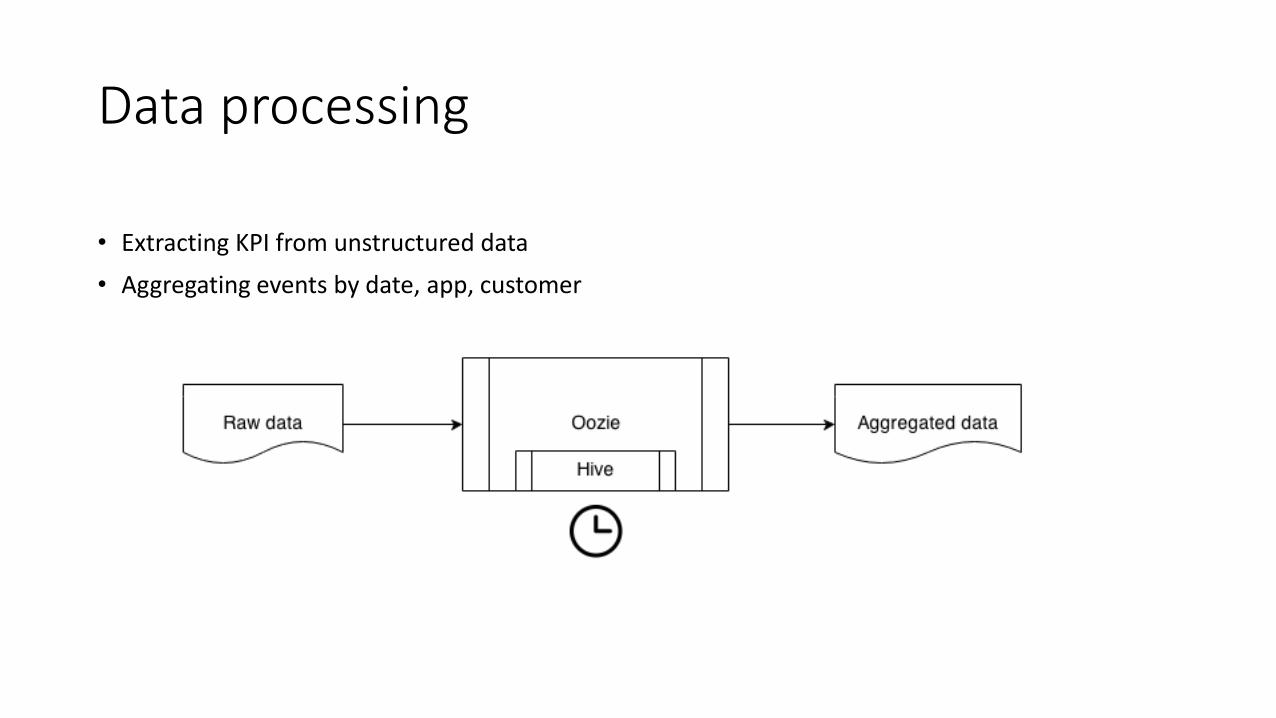
Data processing
• Extracting KPI from unstructured data
• Aggregating events by date, app, customer

Data processing
From raw data
{“id”:1234, “country”: “AR”, “date:” : “20141113”} .. {}
{“id”:1234, “country”: “AR”, “date:” : “20141113”} .. {}
{“id”:1234, “country”: “ES”, “date:” : “20141113”} .. {}
To aggregated
1234 AR 112
1234 ES 56
1234 MX 40

Real-time querying
Pre-requisites
• Data is read from HDFS
• Advanced filtering
• Minimal latency
• Integrated into existing ecosystem

Real-time querying
Options considered
• Exporting aggregated data to MongoDB
• Apache Spark
• Presto
• Cloudera Impala

Impala
Photo by Colin J. McMechan / CC BY

Impala
• Engine which enables real-time queries in Apache Hadoop
• Based on Dremel paper of Google
• Open source
• Integrated into CDH
• Outperforms alternatives solutions (Shark, Presto)

Impala considerations
• Sharing resources with MapReduce jobs

Impala considerations
• Sharing resources with MapReduce jobs
• Consistent data format is required

Impala considerations
• Sharing resources with MapReduce jobs
• Consistent data format is required
• Invalidating metadata
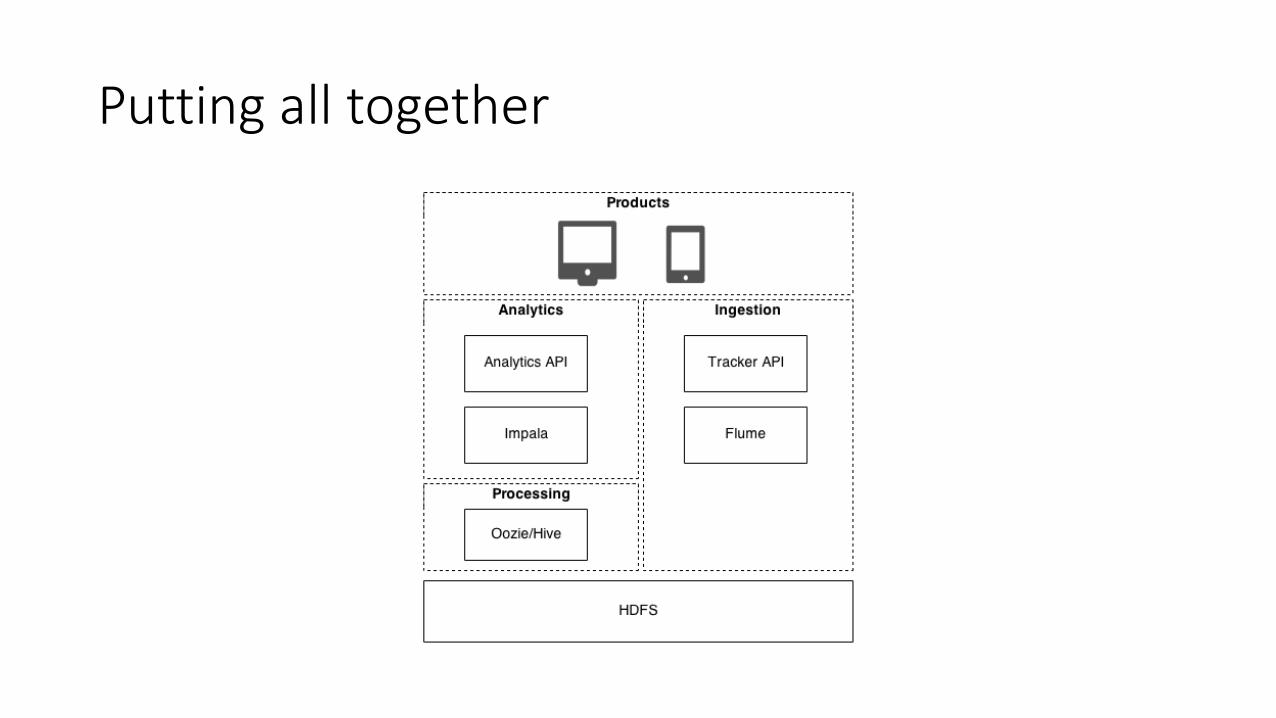
Putting all together
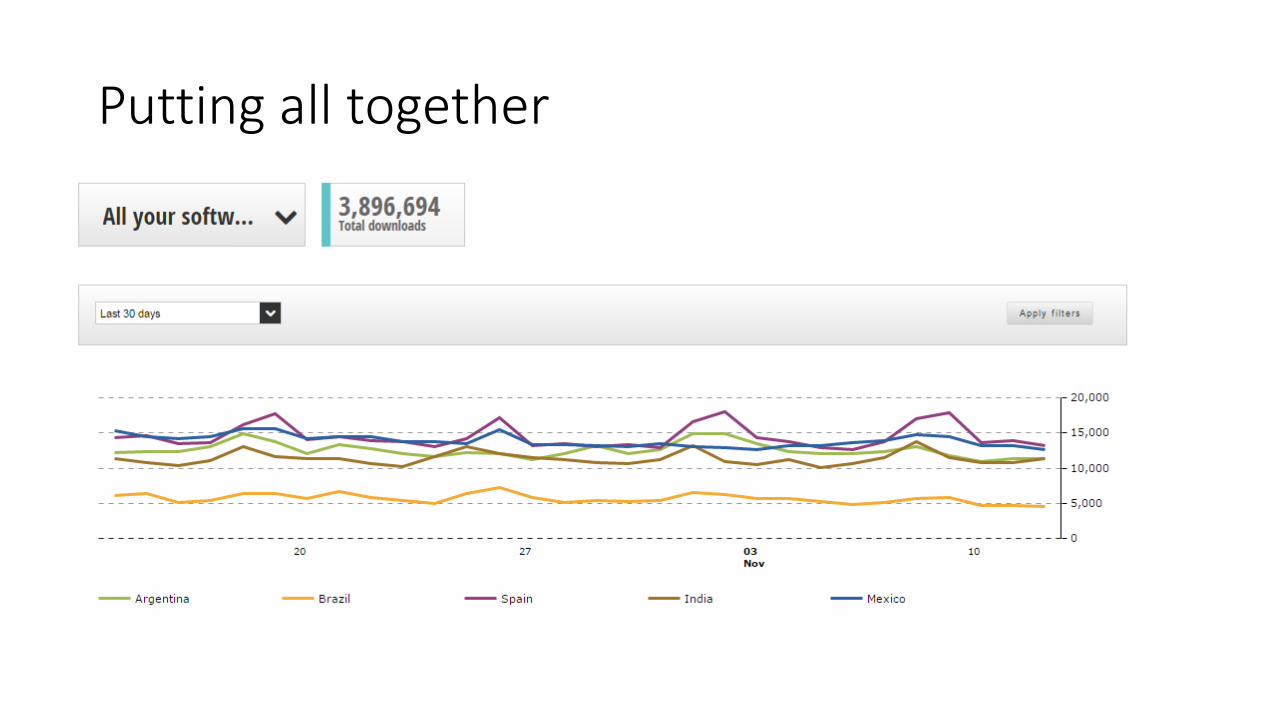
Putting all together

Conclusions
• Data ingested by applications in real-time
• Ingesting 1000+ events/sec
• Data delivered to HDFS every 30 minutes
• Average query response time < 1 sec

References
https://developer.softonic.com/
http://flume.apache.org/
http://www.cloudera.com/content/cloudera/en/documentation/cdh5/v5-1-x/Impala/impala.html
http://research.google.com/pubs/pub36632.html
http://blog.cloudera.com/blog/2014/05/new-sql-choices-in-the-apache-hadoop-ecosystem-why-impala-continues-to-lead/

Thank you! @udachny


















