
Ajustando Distribuciones a los Datos.mcuriel/Cursos/WC/Clases/caracterizacion2.pdf · Tests para...
22
1 M. Curiel Ajustando Distribuciones a los Datos. Prof. Mariela J. Curiel H. Enero, 2009 (por incluir la bibliografía) M. Curiel Técnicas para ajustar una distribución teórica Establecer una Hipótesis acerca de la Distribución. Análisis Exploratorio de los Datos Calcular el(los) parámetros: Maximun- likelihood estimators (MLE) Determinar cuán representativa es la distribución escogida: Métodos Gráficos: qqplots, p-pplots, Otro tests: chi-cuadrado, kolmogorov-Smirnov, Anderson-Darling.
Transcript of Ajustando Distribuciones a los Datos.mcuriel/Cursos/WC/Clases/caracterizacion2.pdf · Tests para...

1
M. Curiel
Ajustando Distribucionesa los Datos.
Prof. Mariela J. Curiel H.Enero, 2009
(por incluir la bibliografía)
M. Curiel
Técnicas para ajustar una distribuciónteórica
Establecer una Hipótesis acerca de la Distribución. Análisis Exploratorio de los DatosCalcular el(los) parámetros: Maximun-likelihood estimators (MLE)Determinar cuán representativa es la distribución escogida:
Métodos Gráficos: qqplots, p-pplots, Otro tests: chi-cuadrado, kolmogorov-Smirnov, Anderson-Darling.

2
M. Curiel
Distribuciones Empíricas
readreadreadwritewritewritewritewritewriteseek
P(read)= 0.3P(write)= 0.6P(seek)=0.1F(read)=0.3F(write) = 0.9F(seek) = 1
D = R(0,1)If D <= 0.3 then readIf D <= 0.9 then writeElse seek
Simulación
X(1) X(2) X(3) X(4) X(5)
1/4
1
3/4
2/4
F(x)
M. Curiel
Técnicas para ajustar unadistribución teórica: Hipótesis
Ver qué fenómenos modela usualmente una distribución: Ejm. Tiempos entre llegadas, tiempo para que falle la pieza de un equipo, tiempos de servicio en el CPU (exponencial). Errores de varios tipos (Normal), etc.Valores posibles de lo que se modela, ejm. Tiempos de servicio no son negativos, por lo tanto no se puede usar una distribución normal.Histogramas

3
M. Curiel
Distribuciones Teóricas: Hipótesis
(X1 + Xn)/2X1 Xn1Extremes
(Xk + X(n-k+1))/2Xk X(n-k+1)k= (|j| + 1)/2
Octiles
(Xj + X(n-j+1))/2Xj X(n-j+1)j = (|i| + 1)/2Quartiles
XiXii = (n+1)/2Median
MidpointSample value(s)Depthquantile
-Si la distribución es simétrica los 4 puntos medios deberían ser aproximadamente iguales.-Si la distribución es sesgada a la derecha (izquierda) los 4 puntos medios (de arriba hacia abajo) deberían ir creciendo (decreciendo)
M. Curiel
Otros Estadísticos de Interés
CV: cv = 1 (o cercano a 1) sugiere una distribución exponencial. Para las distribuciones Gamma o Weibull, cv es mayor, igual o menor que uno, si el parámetro shape es menor, igual o mayor que 1, respectivamente. Skewness (v): es una medida de la simetría de la distribución. Para distribuciones simétricas como la normal, v=0, si v>0, la distribución es sesgada a la derecha (v=2 para la distribución exponencial). Si v < 0 la distribución es sesgada a la izquierda.
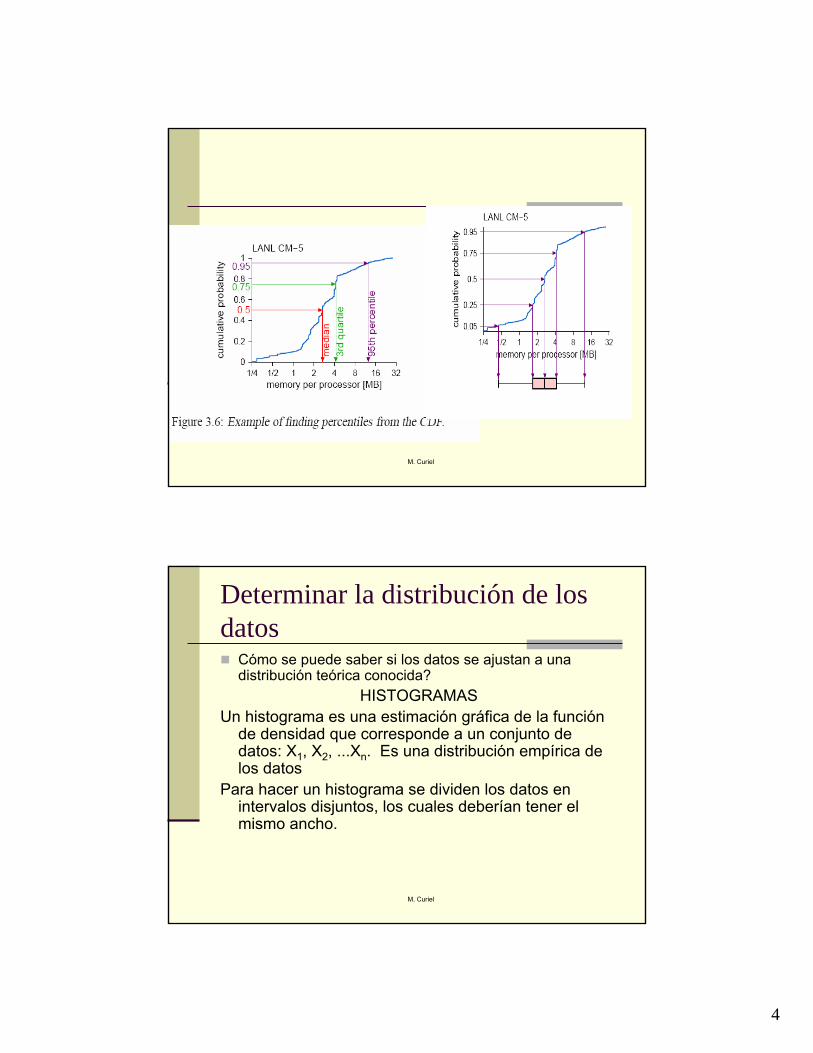
4
M. Curiel
M. Curiel
Determinar la distribución de losdatos
Cómo se puede saber si los datos se ajustan a unadistribución teórica conocida?
HISTOGRAMAS Un histograma es una estimación gráfica de la función
de densidad que corresponde a un conjunto de datos: X1, X2, ...Xn. Es una distribución empírica de los datos
Para hacer un histograma se dividen los datos en intervalos disjuntos, los cuales deberían tener el mismo ancho.

5
M. Curiel
Determinar la distribución de losdatos
Después se compara el histograma con funciones de densidad conocidas a fin de determinar quéfunciones se asemejan al histograma construido.
1.1 2.2 3.0 4.1 5.5 6.7 7.0 8.0 9.1 10.9 12
2.3 3.9 4.2 5.5 6.8 8.23.9 4.3 5.6
4.8
[1,2) [2,3) .... [12,13)
La altura cuenta las unidades en cada clase.
M. Curiel
Número de Clases
Regla empírica: entre 5 y 15Regla de Sturges
nk 2log1+=

6
M. Curiel
Determinar la distribución de losdatos
Si el tamaño del intervalo es 1, el histogramasugiere una función que crece y decrece(normal, beta, etc).Si el tamaño del intervalo es 5 [1,5), [5, 10), [10, 15). El histograma sugiere una funcióndecreciente (exponencial)
M. Curiel
Determinar la distribución de losdatos
Variando el tamaño del intervalo
4.84.34.24.13.93.93.02.32.21.1
8.28.07.06.86.75.65.55.5
[1,5) [5,9) [9,13)
1210.99.1

7
M. Curiel
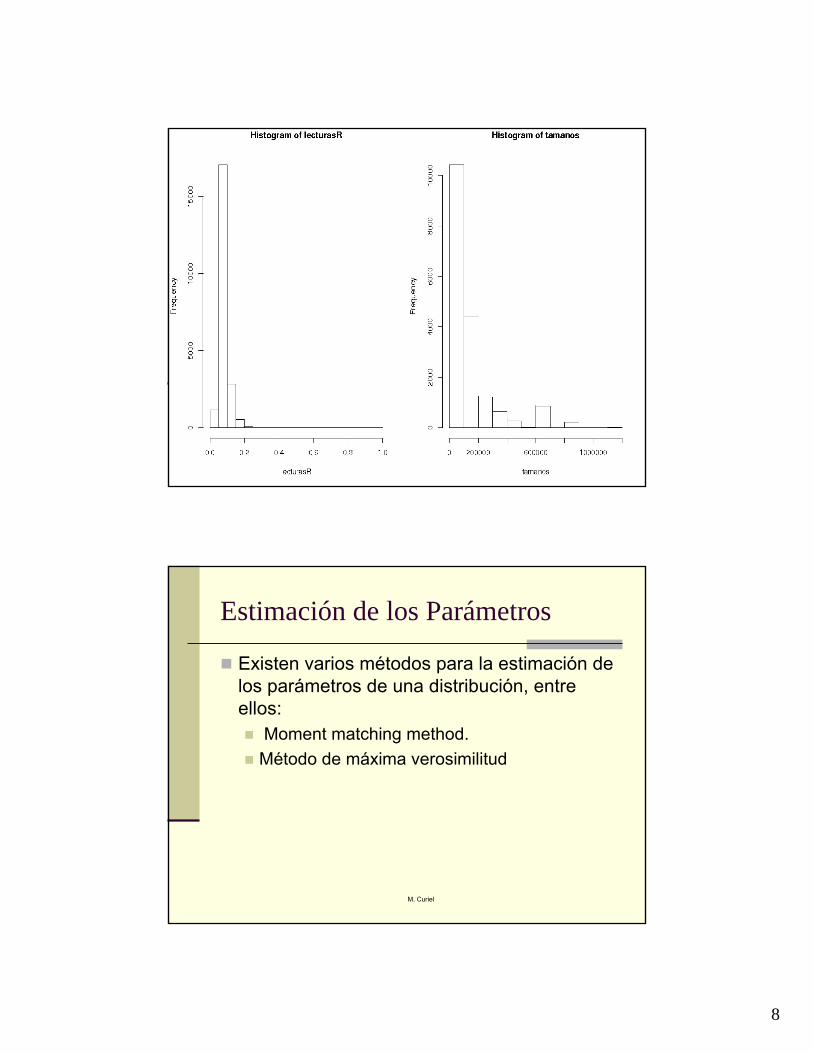
Histogramas en R
totall <- scan("tlecturas19.txt") hist(totall)hist(totall, main=“Histograma de los datos”)
Lee un archivo de datos con una sola Columna.
Hace el histograma
M. Curiel
8
M. Curiel
M. Curiel
Estimación de los Parámetros
Existen varios métodos para la estimación de los parámetros de una distribución, entre ellos:
Moment matching method. Método de máxima verosimilitud

9
M. Curiel
Estimador de Máxima Verosimilitud
La idea detrás de este método, es encontrar aquellos parámetros de la distribución subyacente (la que se plantea en la hipótesis) que dan a los valores de la muestra la probabilidad más alta. A continuación se da la explicación del método para un solo parámetro.
M. Curiel
Estimador de Máxima Verosimilitud
Sea X una variable aleatoria continua o discreta, cuya función de densidad f(x) depende de un único parámetro θ.Supongamos que se observa la variable n veces (se efectúa el experimento n veces) y se obtienen una muestra de n números x1, …..xn.La función de verosimilitud es la probabilidad de observar ciertos valores en la muestra X1, X2, ….Xn, dado que estas variables vienen de una misma distribución. Queremos la probabilidad conjunta de que X1= x1, X2=x2,……Xn=xn. A esta función la llamaremos L. L tiene un parámetro desconocido θ.n

10
M. Curiel
Estimador de Máxima Verosimilitud
Se puede escribir de la siguiente forma:
∏=
=n
iin XfXXXL
1,21 );();,,( θθK
Suponiendo que las variables son independientes.
Deseamos encontrar la máxima probabilidad, es decir, el máximo valor de la Función. Queremos encontrar el valor de theta, para el que el valor de L sea lo mas grande posible. La verosimilitud de un conjunto de datos, es la probabilidad de obtener esos datos, dado que se ha elegido un determinado modelo de probabilidades teórico.
Si L es una función derivable en theta, entonces la condición necesaria para que tenga un máximo, es que la primera derivada con respecto a theta sea 0.
M. Curiel
Estimador de Máxima Verosimilitud
Se puede escribir de la siguiente forma:
∏=
=n
iin XfXXXL
1,21 );();,,( θθK
Suponiendo que las variables son independientes.
Si f(x) es no-negativa un máximo de L será positivo. Como el logaritmo natural esuna función monotonicamente creciente, tendrá máximos en los puntos en losque L tenga máximo. Es más fácil usar logaritmos porque las sumas se convierten en productos.

11
M. Curiel
Estimador de Máxima Verosimilitud
Pasos a seguir:Dada una función de distribución f, calcule la función de máxima verosimilitud L. Tome logaritmos de esta expresión. Derive con respecto a theta. Iguale el resultado a cero. Despeje thetaVerifique que es un máximo, obteniendo la segunda derivada y chequeando que el valor es negativo.
M. Curiel
Estimador de Máxima Verosimilitud
Ejemplo para la distribución Exponencial:
∑ ∑
∏
∏
= =
−
=
=
−
−=⎟⎠⎞
⎜⎝⎛ −
==
=
n
i
n
ii
i
Xn
in
n
i
X
n
XnX
eXXXL
eXXXL
i
i
1 1
12,1
12,1
1)1ln()1ln(
)1ln()]);,(ln(
1);,(
θθθθ
θθ
θθ
θ
θ
L
L
Diferenciamos con respecto a theta e igualamos a 0
∑=
+−=∂∂ n
iiXnL
12
11)ln(θθθ ∑
=
=n
iiXn
1θ

12
M. Curiel
nXi∑=θ
Un estimador del parámetro de la distribución es el promedio.
M. Curiel
Estimador de Máxima Verosimilitud
Obtenemos que theta es el promedio de las muestras. Nota: la metodología no siempre puede aplicarse. No tiene una forma cerrada o la derivada no se puede obtener usando álgebra sino métodos numéricos. Las distribuciones Gamma, Weibull y Beta son ejemplos de estos casos.

13
M. Curiel
Estimador de Máxima Verosimilitud
Cómo lo hacemos en R?
Tenemos dos formas:1) mle(), incluido en el paquete stats42) fitdistr() incluido en el paquete MASS
> library(MASS) fitdistr(lecturas, "log-normal")
meanlog sdlog-2.503219229 0.316825460
( 0.001551761) ( 0.001097261)
fitdistr(comentarioss[[2]], "gamma")shape rate
1.00267060 0.24399318 (0.04280851) (0.01335210)
> fitdistr(comentarioss[[2]], "weibull") shape scale
1.00054891 4.11036738 (0.02673682) (0.14831511)
Warning messages: 1: NaNs produced in: dweibull(x, shape, scale, log) 2: NaNs produced in: dweibull(x, shape, scale, log)
M. Curiel
Distribución Teórica: Cuán bueno es el ajuste?1- Procedimientos Gráficos: QQplots- PPplots,
etc. 2.- Tests para revisar la bondad del ajuste: Ji-
cuadrado, Kolmogorov Smirnov, Anderson-Darling, etc.
14
M. Curiel
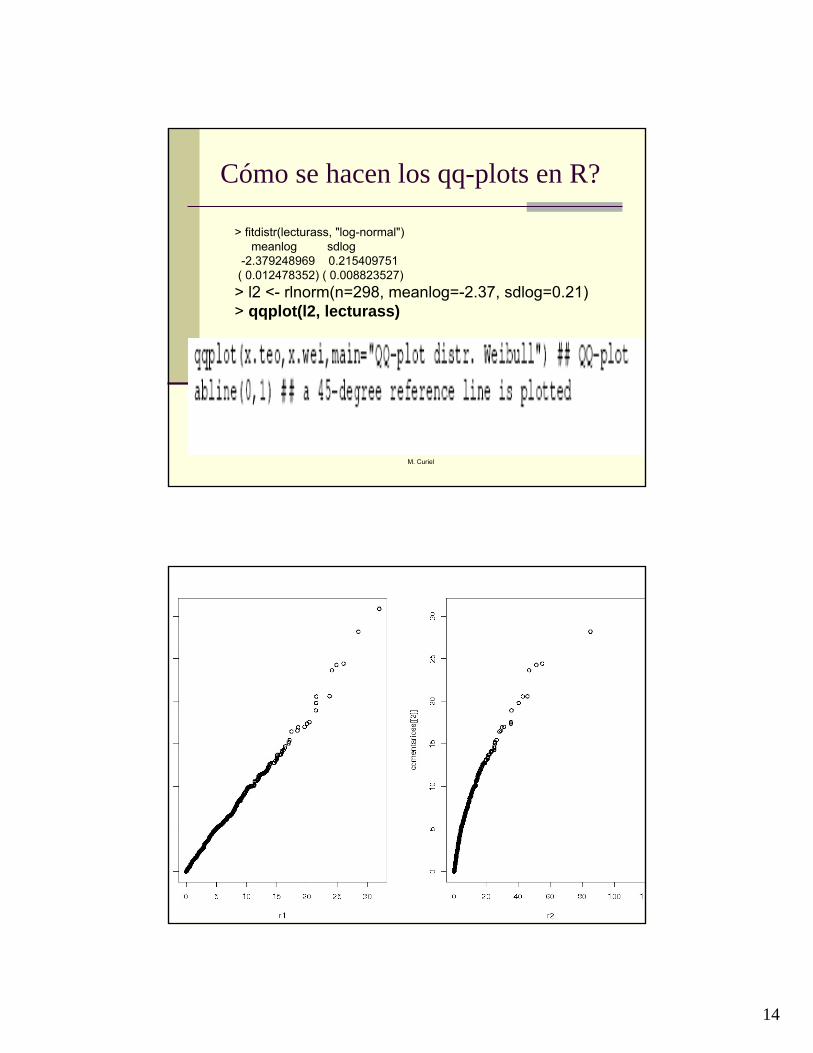
Cómo se hacen los qq-plots en R?
> fitdistr(lecturass, "log-normal") meanlog sdlog
-2.379248969 0.215409751 ( 0.012478352) ( 0.008823527) > l2 <- rlnorm(n=298, meanlog=-2.37, sdlog=0.21) > qqplot(l2, lecturass)
M. Curiel

15
M. Curiel
M. Curiel
Distribución Teórica: Cuán bueno es el ajuste?
Q-QplotConsiste en graficar (to plot) los cuantilesteóricos (yi) versus los cuantiles observados (xi). Si las observaciones siguen la distribución teórica, el qqplot debería ser lineal.

16
M. Curiel
QQPlot
Suponga que yi es el i-ésimo cuantil observado.Si se quiere el iésimo cuantil teórico xi se necesita invertir la función de distribución acumulada. Por ejemplo, si F(x) es la CDF para la distribución supuesta:
qi = F(xi) y xi = F-1(qi)Finalmente, se coloca un punto en la posición (xi, yi) del plot.Ejemplo
Para las distribuciones que tienen una función inversa, es fácil determinar los cuantiles teóricos. Para otras distribuciones uno puede usar tablas e interpolar valores si es necesario.
M. Curiel

17
M. Curiel
Otros gráficosP-P plots: en lugar de graficar los X´s uno grafica las probabilidades o cuantiles. El Q-Qplot amplifica las diferencias en las colas y el P-Pplot (válido para variables continuas y discretas) las diferencias en el cuerpo de la distribución.Plot de diferencias de las funciones de distribución:
qi = F(xi)
)()(^
xFx nF −
M. Curiel
El test de Kolmogorov-Smirnov es un test de ajuste que compara una función de distribución empírica con la función de distribución que suponemos tienen los datos F0..La Hipótesis Nula H0 es:
Los datos siguen F0Hipótesis Alternativa: Los datos no siguen la distribución especificada.
Test de Kolmogorov-Smirnov

18
M. Curiel
La idea es la siguiente: si la hipótesis es correcta, entonces la función de distribución empírica de la muestra debe parecersea la función . La función de distribución empírica es la función que va de en , y que toma los valores:
.
es la proporción de elementos de la muestra que son menores o iguales a x .
Test de Kolmogorov-Smirnov
M. Curiel
X(1) X(3)X(2) X(4)
1/4
1
3/4
1/2Dn+
Dn-
F0 (x4)(X(3))

19
M. Curiel
Para calcularla basta evaluar la diferencia entre y en lospuntos .
⎭⎬⎫
⎩⎨⎧ −
−−=≤≤ n
iXFXFniD iinin
1)(,)(max 001
Caso 1: todos los parámetros son conocidosCaso 2: Distribución NormalCaso 3: Distribucion ExponencialCaso 4: Weibull
Test de Kolmogorov-Smirnov
Dn-Dn+
M. Curiel
Test de Kolmogorov-Smirnov
Caso 3: se rechaza Ho si:
"1
5.026.02.0α−>⎟
⎠
⎞⎜⎝
⎛ ++⎟⎠⎞
⎜⎝⎛ − c
nn
nDn
> ks.test(comentarioss[[2]], "pgamma", shape=1.00, rate=0.24)One-sample Kolmogorov-Smirnov test
data: comentarioss[[2]] D = 0.0269, p-value = 0.5702 alternative hypothesis: two-sided

20
M. Curiel
> ks.test(comentarioss[[2]], "plnorm", meanlog=0.83, sdlog=1.27) One-sample Kolmogorov-Smirnov test
data: comentarioss[[2]] D = 0.0711, p-value = 0.0003684 alternative hypothesis: two-sided
Otras funciones a revisar: goodfit (library vcd), ad.test (test de Anderson DarlingLibrería nortest)
Ho se acepta si el p-valor es mayor que un nivel de significanciade al menos el 5% (0.05)
Test de Kolmogorov-Smirnov
M. Curiel
Algunas desventajas:La forma original del test sólo podía aplicarse si se conocían los parámetros de la distribución, i.e. los parámetros no podían ser estimados de los datos. Más recientemente, sí se permite la estimación de los parámetros para algunas distribuciones como la log-normal, lormal, exponencial, Weibull y log-logistic.Da el mismo peso a todas las diferencias sin importar si es el cuerpo o en la cola de la distribución y en algunos casos las principales diferencias están en las colas.
Test de Kolmogorov-Smirnov

21
M. Curiel
Algunas desventajas:Dado que la distribución tienen que estar completamente especificada y por darle igual peso a todas las diferencias, muchas veces se prefiere el TestAnderson-Darling. Sólo se puede aplicar a determinadas distribuciones: normal, log-normal, exponencial, weibull.
Test de Kolmogorov-Smirnov
M. Curiel
Datos Reales ExpertFit: shape= 1.21, scale= 6.35 (es el tercer mejor modelo, el primero es Beta)
Datos Sintéticos ExpertFit: shape=0.96, scale=5.19 (es el segundo mejor modelo)
R S

22
M. Curiel
Otras Formas de Ajustar Distribuciones a los Datos
ExpertFitEasyFit
No se trata de software libre, no resuelve distribuciones mixtas, puede estar limitado respecto al número de datos que maneja.
M. Curiel
Bibliografía
Daniel Menascé. Virgilio Almeida. Larry W. Dowdy. Capacity Planning and Performance Modeling. Prentice Hall, 1994.Raj Jain. The Art of Computer Systems Performance Analysis, Wiley, 1991.Averill M. Law y David Kelton. Simulation Modelling and Analysis. Mc. Graw Hill.2000 Apuntes del curso análisis de datos II de la Prof. Ma. EgleePérez.Material on-line del libro: Evaluación y Modelado del Rendimiento de Sistemas Informáticos. Juiz, Molero, Rodeño


















