
Addressing Optimization for Loop Execution Targeting DSP with Auto-Increment/Decrement Architecture...
19
Optimization for Loop Execution Targeting DSP with Auto- Increment/Decrement Architecture Wei-Kai Cheng Youn-Long Lin* Computer & Communications Research Laboratories *CS Department, NTHU Taiw an
-
date post
20-Dec-2015 -
Category
Documents
-
view
232 -
download
2
Transcript of Addressing Optimization for Loop Execution Targeting DSP with Auto-Increment/Decrement Architecture...

Addressing Optimization for Loop Execution Targeting DSP
with Auto-Increment/Decrement Architecture
Wei-Kai Cheng
Youn-Long Lin*
Computer & Communications Research Laboratories
*CS Department, NTHU Taiwan

2
Overview
Features: – Auto-Increment/Decrement for Address
Generation– Constraints for Loop Execution
Optimization Methods:– Multi-Phase Data Ordering– Graph-Based Address Register Allocation
» Block Access Graph
3
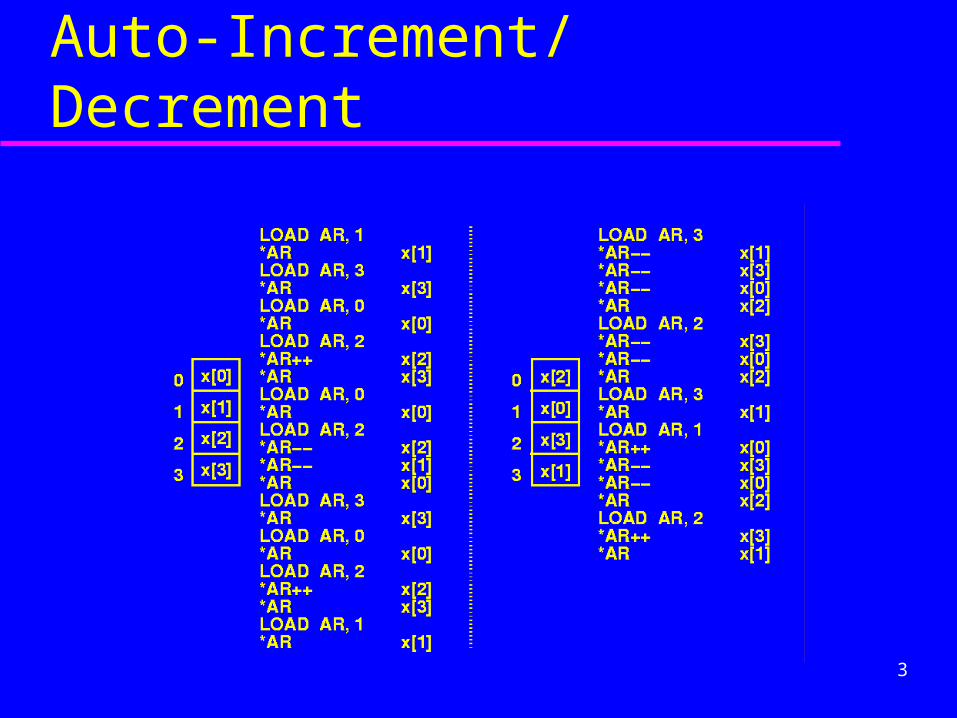
Auto-Increment/Decrement

4
New Constraints
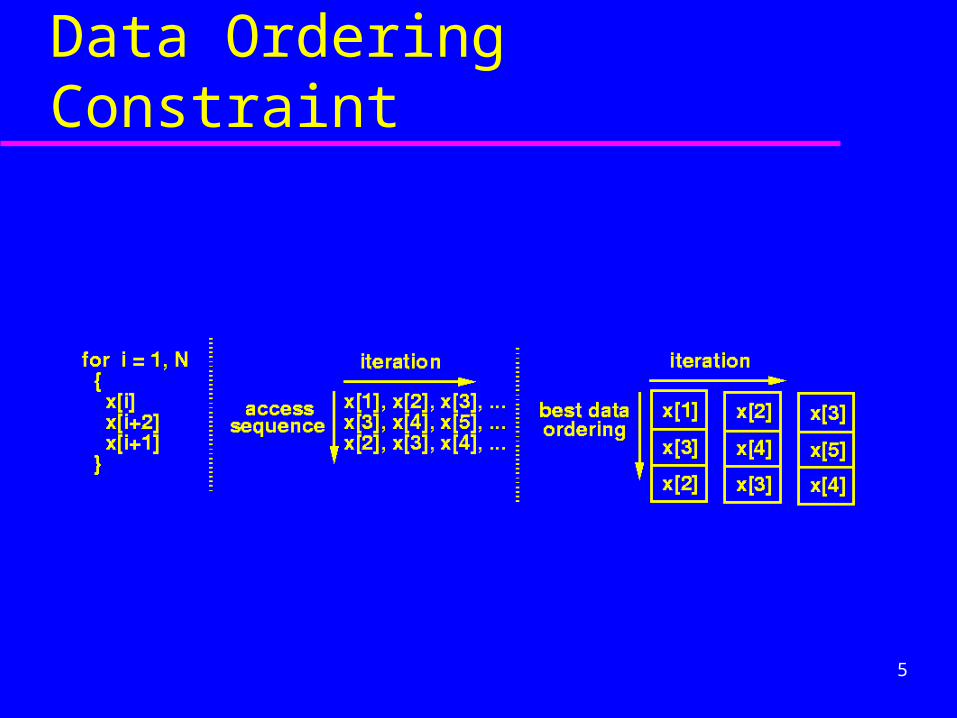
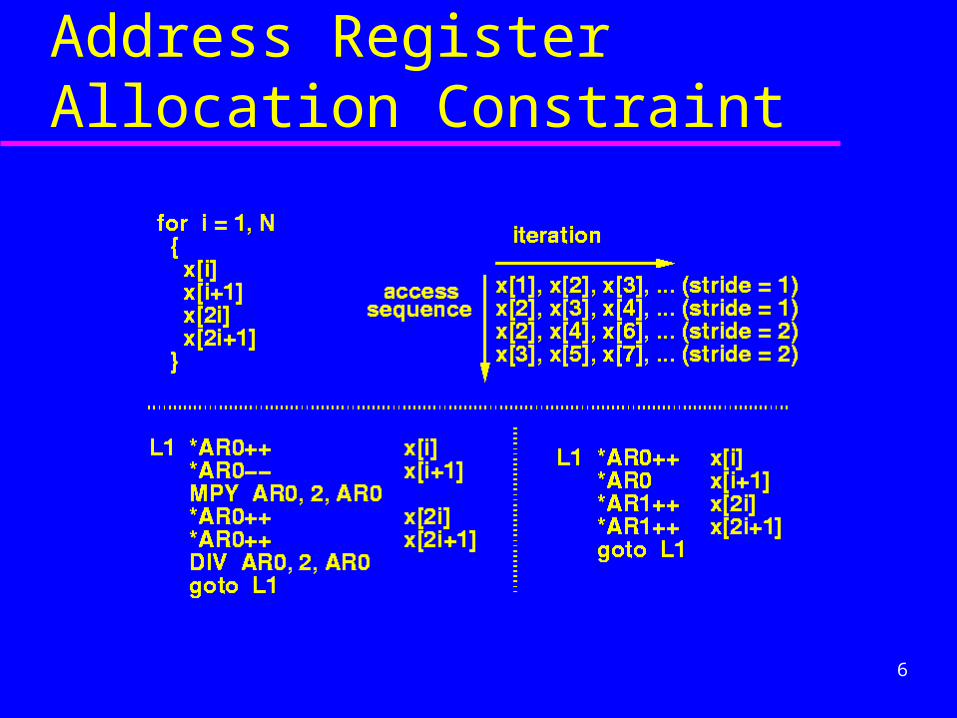
Loop Execution– Data Ordering Constraint– Address Register Allocation Constraint
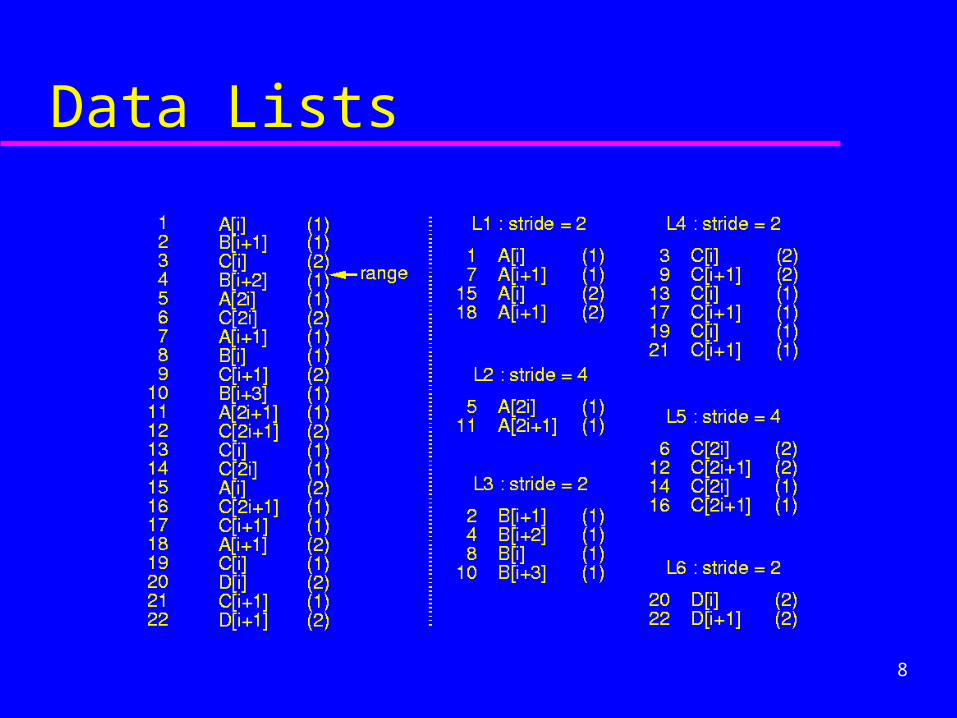
Architectural Constraint– Different arrays are stored in disjoint memory
space– Multiple auto-increment/decrement ranges in
the instruction set architecture
5
Data Ordering Constraint
6
Address Register Allocation Constraint

7
Architectural Constraint
8
Data Lists

9
Approach
Split the access sequence into data lists– Array– Iteration Stride
Data Ordering Address Register Allocation
– Data Lists Merging or Splitting
10
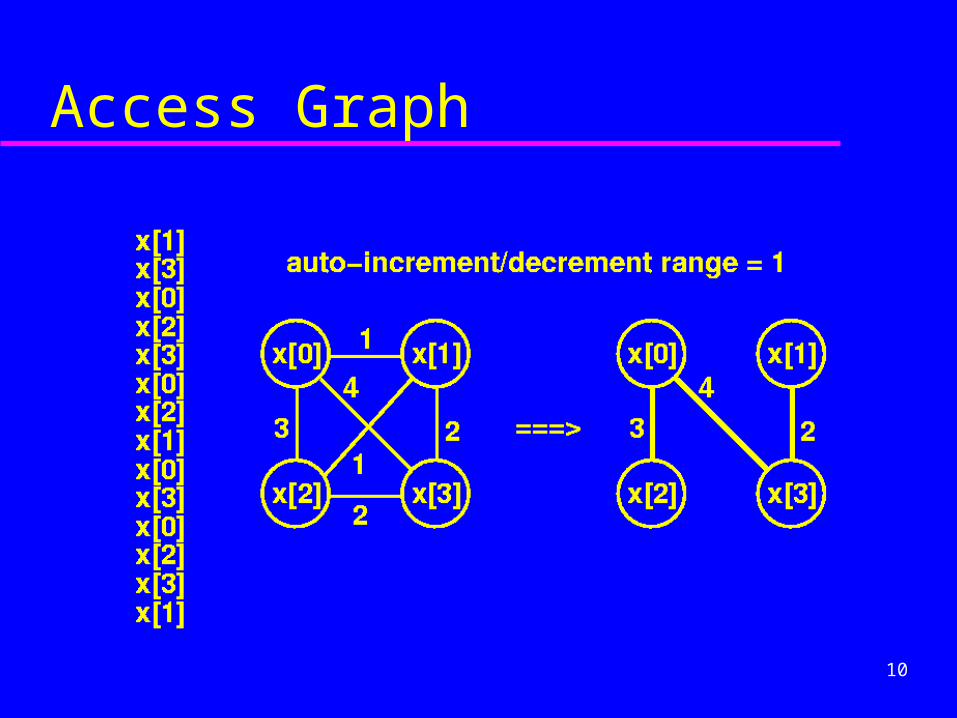
Access Graph
11
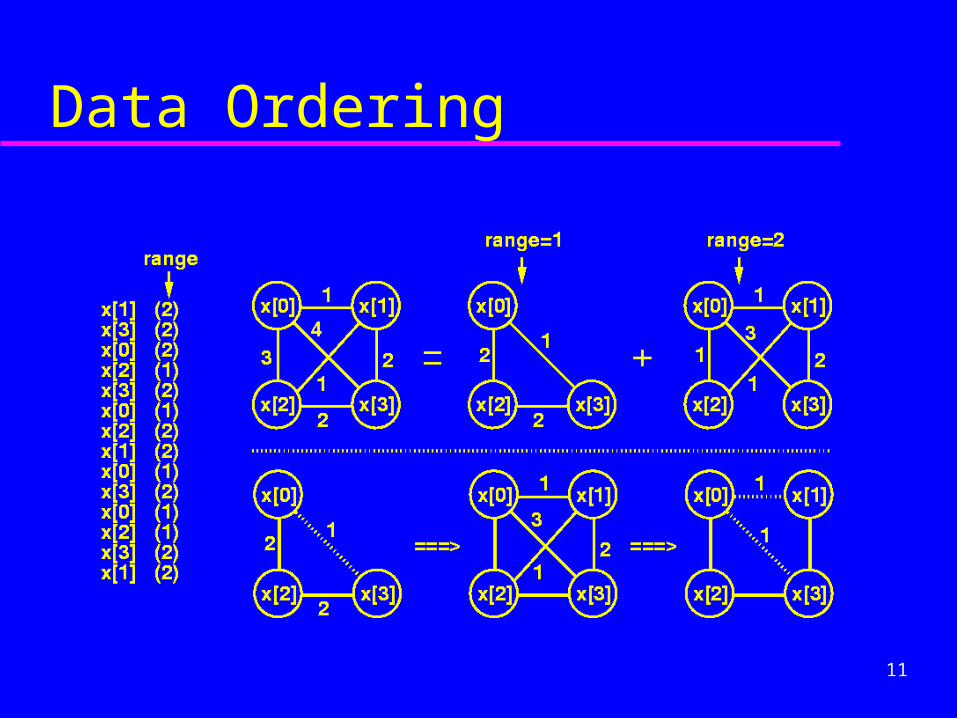
Data Ordering

12
Address Register Allocation
# data lists > # address registers:– data list merging
# data lists < # address registers:– data list splitting

13
Two-Way Data List Splitting
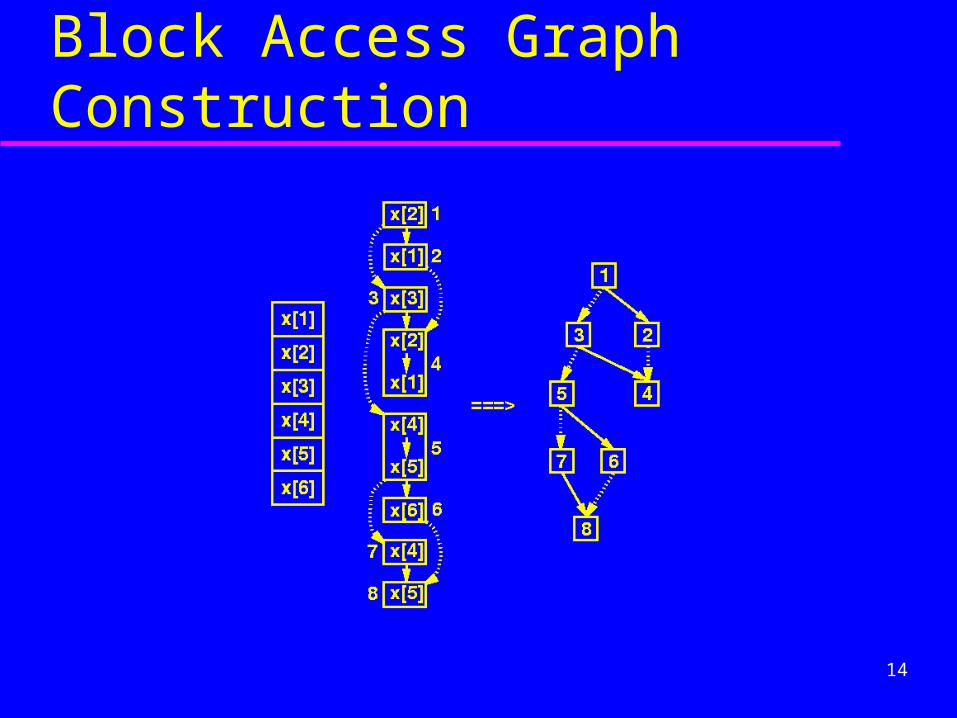
14
Block Access Graph Construction

15
Block Access Graph Partition
16
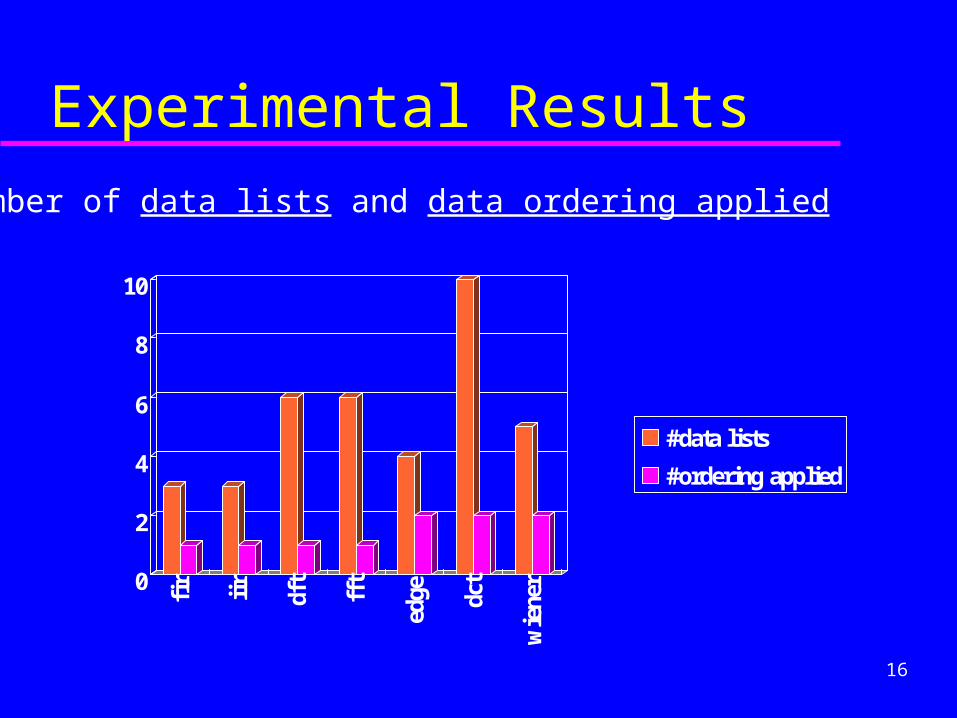
Experimental Results
0
2
4
6
8
10
fir
iir
dft
fft
edge dct
wie
ner
#data lists
#ordering applied
* number of data lists and data ordering applied

17
Experimental Results (Cont.)
0
0.2
0.4
0.6
0.8
1
fir iir dft fft edge dct wiener
T.o+T.a
O.o+T.a
T.o+O.a
O.o+O.a
* ratio over TI’s compiler in term of inserted instructions
T: TI’s compilerO: Our algorithm
o: data orderinga: address register allocation

18
Experimental Results (Cont.)
0
0.2
0.4
0.6
0.8
1
fir iir dft fft edge dct wiener
T.o+T.a
O.o+T.a
T.o+O.a
O.o+O.a
* ratio over TI’s compiler in term of execution cycles
T: TI’s compilerO: Our algorithm
o: data orderinga: address register allocation

19
Conclusions
Data ordering is not so effective in loop execution
Data list splitting is more important than data list merging


















