
Adaptive Clustering Of Incomplete Data Using Neuro-fuzzy Kohonen Network.
19
Adaptive Clustering Of Incomplete Data Adaptive Clustering Of Incomplete Data Using Neuro-fuzzy Kohonen Network Using Neuro-fuzzy Kohonen Network
-
Upload
junior-danson -
Category
Documents
-
view
228 -
download
1
Transcript of Adaptive Clustering Of Incomplete Data Using Neuro-fuzzy Kohonen Network.

Adaptive Clustering Of Incomplete Data Adaptive Clustering Of Incomplete Data Using Neuro-fuzzy Kohonen NetworkUsing Neuro-fuzzy Kohonen Network

OutlineOutlineData with gaps clustering on the basis of
neuro-fuzzy Kohonen networkAdaptive algorithm for probabilistic fuzzy
clusteringAdaptive probabilistic fuzzy clustering
algorithm for data with missing valuesAdaptive algorithm for possibilistic fuzzy
clusteringAdaptive algorithm for possibilistic fuzzy
clustering of data with missing values
2/22

IntroductionIntroduction The clustering problem for multivariate observations often
encountered in many applications connected with Data Mining and Exploratory Data Analysis. Conventional approach to solving these problems requires that each observation may belong to only one cluster. There are many situations when a feature vector with different levels of probabilities or possibilities can belong to several classes. This situation is the subject of fuzzy cluster analysis, intensively developing today.
In many practical tasks of Data Mining, including clustering, data sets may contain gaps, information in which, for whatever reasons, is missing. More effective in this situation are approaches based on the mathematical apparatus of Computational Intelligence and first of all artificial neural networks and different modifications of classical fuzzy c-means (FCM) method.
3/22
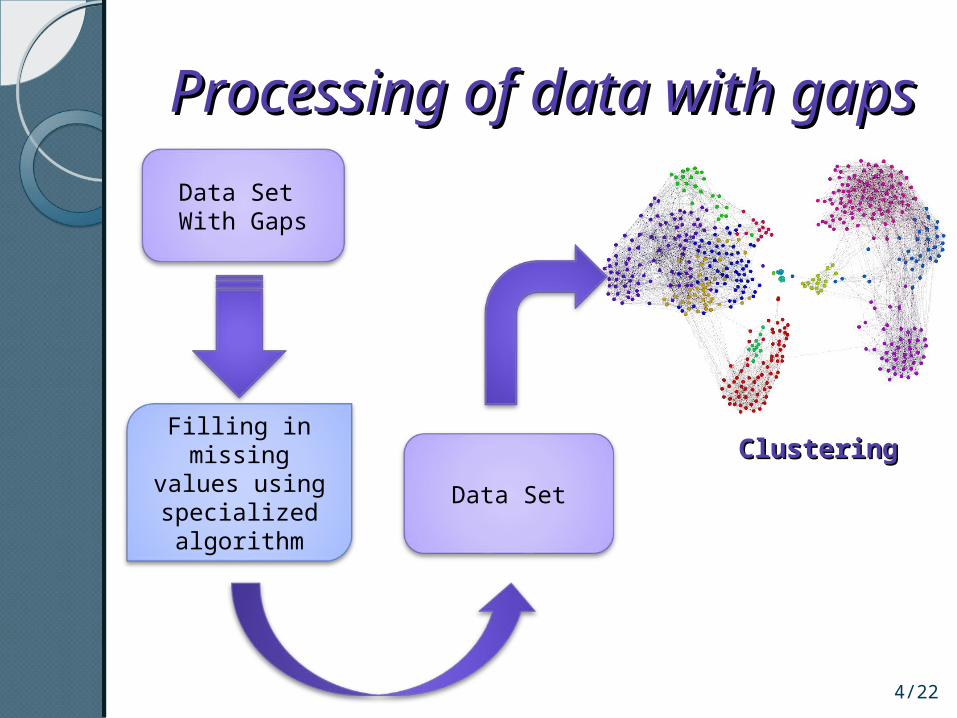
Processing of data with Processing of data with gapsgaps
Data Set With Gaps
Filling in missing values using specialized algorithm
Data Set
ClusteringClustering
4/22

Algorithms for filling Algorithms for filling the missing valuesthe missing values
5/22

Data with gaps clustering on Data with gaps clustering on the basis of neuro-fuzzy the basis of neuro-fuzzy
Kohonen networkKohonen networkThe clustering of multivariate observations problem often occurs in many applications associated with Data Mining.
The traditional approach to solving these tasks requires that each observation may relate to only one cluster, although the situation more real is when the processed feature vector with different levels of probabilities or possibilities may belong more than one class. [Bezdek, 1981; Hoeppner 1999; Xu, 2009].
Notable approaches and solutions are efficient only in cases when the original array data set has batch form and does not change during the analysis. However there is enough wide class of problems when the data are fed to the processing sequentially in on-line mode as this occurs when training Kohonen self-organizing maps [Kohonen, 1995]. In this case it is not known beforehand which of the processed vector-images contains missing values.
This work is devoted to solving the problem on-line clustering of data based on the Kohonen neural network, adapted for operation in presence of overlapping classes.
6/22

1 … p … j … n1 x11 … x1p … x1j … x1n
… … … … … … … …i xi1 … xip … xij … xin
… … … … … … … …k xk1 … xkp … xkj … xkn
… … … … … … … …N xN1 … xNp … xNj … xNn
”object-property“ table
1 2{ , ,..., } , , 1,2,...,nN kX x x x R x X k N
(1 )m N
( )qU k
Adaptive algorithm for Adaptive algorithm for probabilistic fuzzy clusteringprobabilistic fuzzy clustering
7/22
(1)

2
1 1( ( ), ) ( ) ( , )
N m
q q q k qk q
E U k w U k D x w
1 1( ) 1, 0 ( )
m N
q qq k
U k U k N
12 ( ) 1
( 1)1
2 ( ) 1
1
( 1)
( 1) 1
( 1)
1
( ( , ))( ) ,
( ( , ))
( ),
( ( ))
k qq
m
k ll
N
q kk
q N
qk
D x wU k
D x w
U xw
U k
The steps algorithmThe steps algorithmIntroducing the objective function of clustering
wq
(4)
12 ( ) 1
11
2 11
1
1
( ( , ))( 1) ,
( ( , ( )))
( 1) ( ) ( 1) ( 1)( ( )),
kk q
qm
k ll
q q q k q
D x wU k
D x w k
w k w k k U k x w k
(5)
(3)
8/22

Adaptive probabilistic fuzzy Adaptive probabilistic fuzzy clustering algorithm for data clustering algorithm for data
with gapswith gapsIn the situation if the data in the array contain gaps, the approach discussed above should be modified accordingly. For example, in [Hathaway, 2001] it was proposed the modification of the FCM-procedure based on partial distance strategy (PDS FCM).
X
FX
PX
GX
9/22

Processing of data with Processing of data with gapsgaps
Data Set With Gaps
Filling in missing values using specialized algorithm
Data SetClusteringClustering
10/22

Data set1{ ,..., ,..., } n
k NX x x x R
{ | - }F k kX x X x vector containing all gaps
{ ,1 ,1 | , }P ki kX x i n k N values x available in X
{ ?,1 ,1 | , }G ki kX x i n k N values x absent in X
11/22

2 ( , )P k qD x w
2
1 1 1
( ( ), ) ( ) ( )N m n
q q q ki qi kikk q i
nE U k w U k x w
Objective function of clustering
here
,~|1
,~|0
Fki
Gkiki Xx
Xx
n
ikik
1
2 2
1
( , ) ( )n
P k q ki qi kik i
nD x w x w
(6)
(7)
12/22
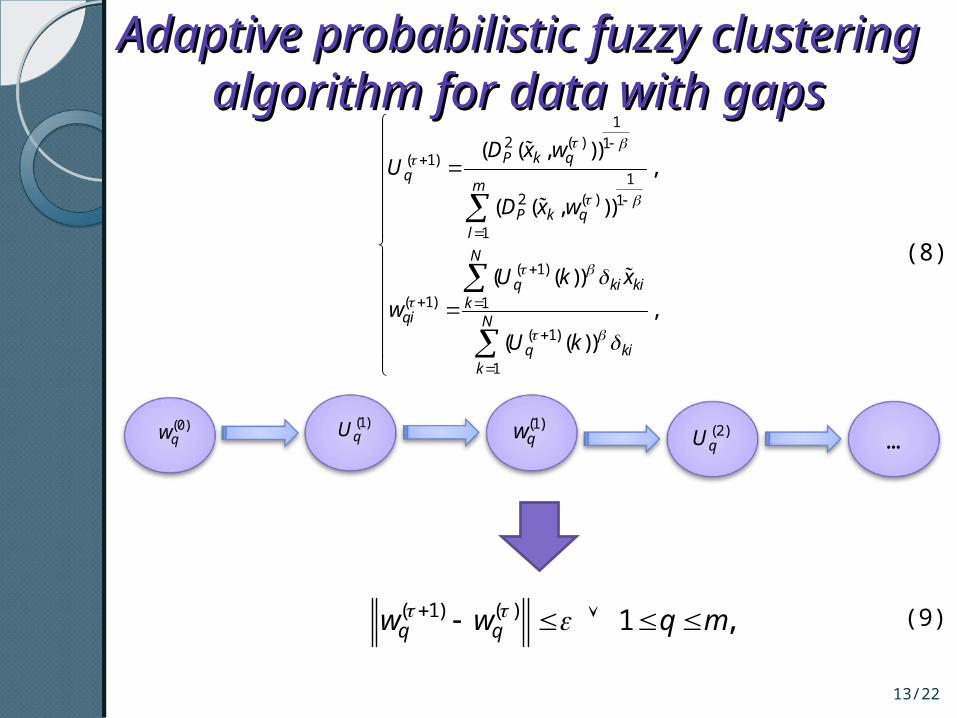
…
Adaptive probabilistic fuzzy Adaptive probabilistic fuzzy clustering algorithm for data with clustering algorithm for data with
gapsgaps
(0)qw (1)
qU (1)qw (2)
qU(0)qw
12 ( ) 1
( 1)1
2 ( ) 1
1
( 1)
( 1) 1
( 1)
1
( ( , )),
( ( , ))
( ( ))
,
( ( ))
P k qq
m
P k ql
N
q ki kik
qi N
q kik
D x wU
D x w
U k x
w
U k
( 1) ( ) 1 ,q qw w q m
(8)
(9)
13/22

12 1
1
12 1
11
1,
( ( , ( )))( 1) ,
( ( , ( )))
( 1) ( ) ( 1) ( 1)( ( )) ,
P k qq
m
P k ql
qi qi q k i qi ki
D x w kU k
D x w k
w k w k k U k x w k
1( 1) ( ) ( 1) ( 1)( ( ))q q q k q kw k w k k k x w k
Kohonen’s “Winner – takes – more” rule
Adaptive probabilistic fuzzy Adaptive probabilistic fuzzy clustering algorithm for data clustering algorithm for data
with gapswith gaps
(10)
(11)
14/22

Adaptive algorithm for Adaptive algorithm for possibilistic fuzzy clusteringpossibilistic fuzzy clustering
The main disadvantage of probabilistic algorithms is connected with the constraints on membership levels which sum has to be equal unity. This reason has led to the creation of possibilistic fuzzy clustering algorithms [Krishnapuram, 1993].
In possibilistic clustering algorithms the objective function has the form
where the scalar parameter
determines the distance at which
level of membership equals to 0.5
N
k
m
q
m
q
N
kqqqkqqqq kUwxDkUwkUE
1 1 1 1
2 ))(1(),~()(),),((
0
.)(
)1(~)(
)1(
)),(~)(1()1()()1(
,
)(
)(~1
1)1(
1
2
1
1
22
12
2
pU
kwxpU
k
kwxkUkkwkw
k
kwxkU
k
pq
k
pqpq
q
qkqqq
q
qk
q
(12)
(13)
15/22

Adaptive algorithm for Adaptive algorithm for possibilistic fuzzy clustering possibilistic fuzzy clustering
of data with gapsof data with gapsAdopting instead of Euclidean metric partial distance (PD), we can write the objective function as
and then solving the equations system
Thus, the process of fuzzy possibilistic clustering data with gaps can also be realized by using neuro-fuzzy Kohonen network.
N
k
m
q
n
i
N
kq
m
qqkiqiki
kqqqq kUwx
nkUwkUE
1 1 1 11
2 ))(1()~()(),),((
,0),),((
,0),),((
,0)(
),),((
qqqw
q
qqq
q
qqq
wkUE
wkUE
kU
wkUE
q
,)(
))1(,~()(
)1(
,))(~)(1()1()()1(
,
))(
))(,~((1
1)(
1
1
1
1
2
,1
1
11
2
k
pq
k
pqpPq
q
kiqiikqqiqi
q
qkP
q
pU
kwxDpU
k
kwxkUkkwkw
k
kwxDkU
(14)
(15) (16)
16/22

ResultsResultsIris data set: This is a benchmark data set in pattern recognition analysis, freely available at the UCI Machine Learning Repository.
It contains three clusters (types of Iris plants: Iris Setosa, Iris Versicolor and Iris Virginica) of 50 data points each, of 4 dimensions (features): sepal length, sepal width, petal length and petal width. The class Iris Setosa is linearly separable from the other two, which are not linearly separable in their original clusters.
Validation Cluster validity refers to the problem whether a given fuzzy partition fits to the data all. The clustering algorithm always tries to find the best fit for a fixed number of clusters and the parameterized cluster shapes. However this does not mean that even
the best fit is meaningful at all. Either the number of clusters might be wrong or the cluster shapes might not correspond to the groups in the data, if the data can be grouped in a meaningful way at all. Two main approaches to determining the appropriate number of clusters in data can be distinguished:
17/20

ResultsResultsValidity measures:
Partition Coefficient (PC) - measures the amount of "overlapping" between cluster. The optimal number of cluster is at the maximum value. Classification Entropy (CE) - it measures the fuzzyness of the cluster partition only, which is similar to the Partition Coeffcient. Partition Index (SC) - is the ratio of the sum of compactness and separation of the clusters. It is a sum of individual cluster validity measures normalized through division by the fuzzy cardinality of each cluster. A lower value
of SC indicates a better partition. Separation Index (S) - on the contrary of partition index (SC), the separation index uses a minimum-distance separation for partition validity Xie and Beni’s Undex (XB) - it aims to quantify the ratio of the total variation within clusters and the separation of clusters. The optimal number of clusters should minimize the value of the index.
18/20

ResultsResultsClustering algorithm
PC SC XB
Adaptive algorithm for probabilistic fuzzy clustering
0.2547 2.7039e-004 0.0169
Adaptive probabilistic fuzzy clustering algorithm for data with gaps
0.3755 6.4e-003 0.1842
Adaptive algorithm for possibilistic fuzzy clustering
0.2691 4.4064e-005 0.0122
Adaptive algorithm for possibilistic fuzzy clustering of data with gaps
0.2854 5.103e-003 0.4571
Fuzzy c-means 0.5036 1.6255 0.191
Gustafson-Kessel 0.2755 4.7481e-002 0.5717
Gath-Geva 0.2542 4.941e-005 3.3548
19/20


















