
Adam Silberstein, Hao He, Ke Yi, Jun Yang Duke University Durham, North Carolina, USA BOXes:...
25
Adam Silberstein, Hao He, Ke Yi, Jun Yang Duke University Durham, North Carolina, USA BOXes: Efficient Maintenance of Order-Based Labeling for Dynamic XML Data
-
date post
19-Dec-2015 -
Category
Documents
-
view
220 -
download
0
Transcript of Adam Silberstein, Hao He, Ke Yi, Jun Yang Duke University Durham, North Carolina, USA BOXes:...

Adam Silberstein, Hao He, Ke Yi, Jun YangDuke University
Durham, North Carolina, USA
BOXes: Efficient Maintenance of Order-Based Labeling for
Dynamic XML Data

XML labeling
• Assign labels to XML elements to capture the document hierarchy– Facilitates query processing by providing
efficient checking of relationships between elements
• Having a labeling scheme for dynamic documents is important– As more and larger data is maintained as
XML, need to be able to make updates– Problem has been addressed by many
academic and industry groups (Niagara, Timber, Microsoft ORDPATH, etc.)

Order-based labeling• Popular method is to assign each element an
interval (start_label, end_label) based on document order of its start and end tags– If tag t1 precedes tag t2 in the document,
then t1’s label is less than t2’s
• Widely used by many systems (e.g., Niagara, Timber) in processing XPath location steps– E1 is an ancestor of E2 iff
E1’s interval contains that of E2
Labeling a static document is easy, but
what if document is updated?
bib
book book
titleauthorauthor
section
section
section
bookref
(1, 1000)
(2, 100)(101, 142)
(3, 4)(5, 6)(7, 8)
(9, 20)
(10, 15)
(21, 32)
(23, 28)

Immutable labeling scheme
[Cohen et al., PODS 2002]• Any immutable labeling scheme (i.e.,
label values don’t change once assigned) will necessarily require (N) bits per label, where N is the size of the document– Can do better if we know something about
the document structure in advance, but still hopeless in adversarial cases

Dynamic labeling scheme
Allow labels to be mutable• When we run out of labels to assign, change
some existing labels to make space– Updating various copies (e.g., in inverted keyword
indexes) is problematic “One more level of indirection solves everything”: Map immutable label IDs to mutable label values
using, say, a heap file
• Challenges addressed by our BOXes– How to reduce relabeling cost?– How to do it in an I/O-efficient manner?– How to avoid the extra indirection when accessing
labels?
Immutable label IDHeap file rec. no.
Mutable
label value

Naïve relabeling• To insert a new label between two existing labels
(e.g., 20 and 30)– Assign the average to the new label (e.g., avg(20,
30)=25)– If there is no space between existing labels (e.g., 2 and
3), relabel everything to leave equally sized gaps between adjacent labels
• Easily broken by an adversary that repeatedly inserts into the smallest gap– For a gap of k bits, it takes only k+1 insertions to
trigger relabeling Using floating-point numbers instead of integers won’t
help, because the number of bit patterns still pose the same limit
Must cut down the cost of relabeling!
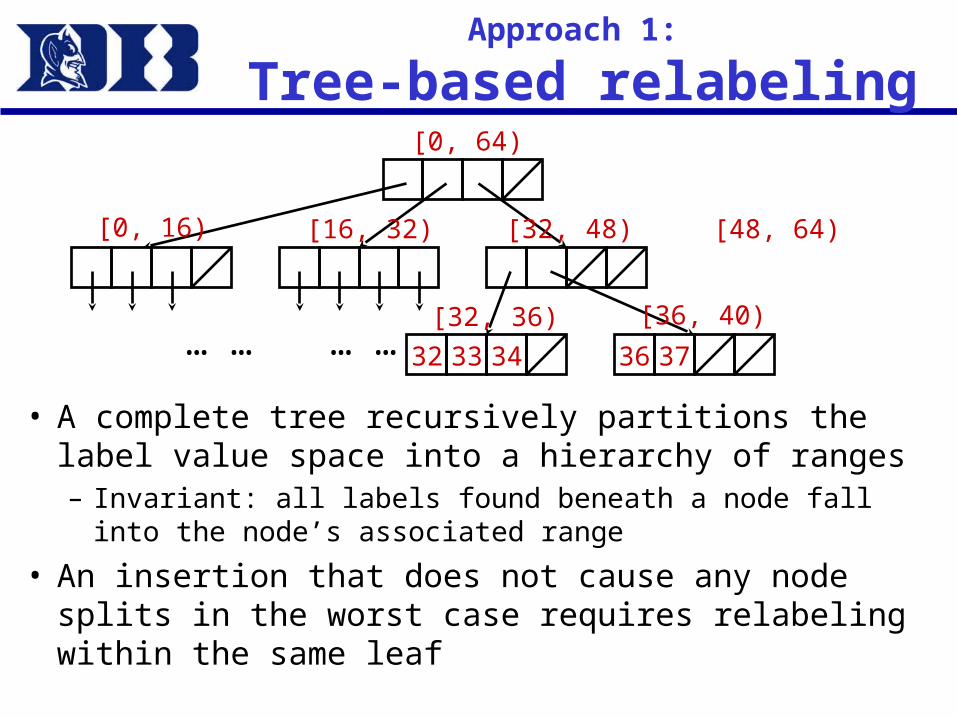
Approach 1:
Tree-based relabeling
• A complete tree recursively partitions the label value space into a hierarchy of ranges– Invariant: all labels found beneath a node fall into
the node’s associated range
• An insertion that does not cause any node splits in the worst case requires relabeling within the same leaf
36 3732 33 34… …… …
[0, 64)
[0, 16) [16, 32) [32, 48) [48, 64)
[32, 36) [36, 40)
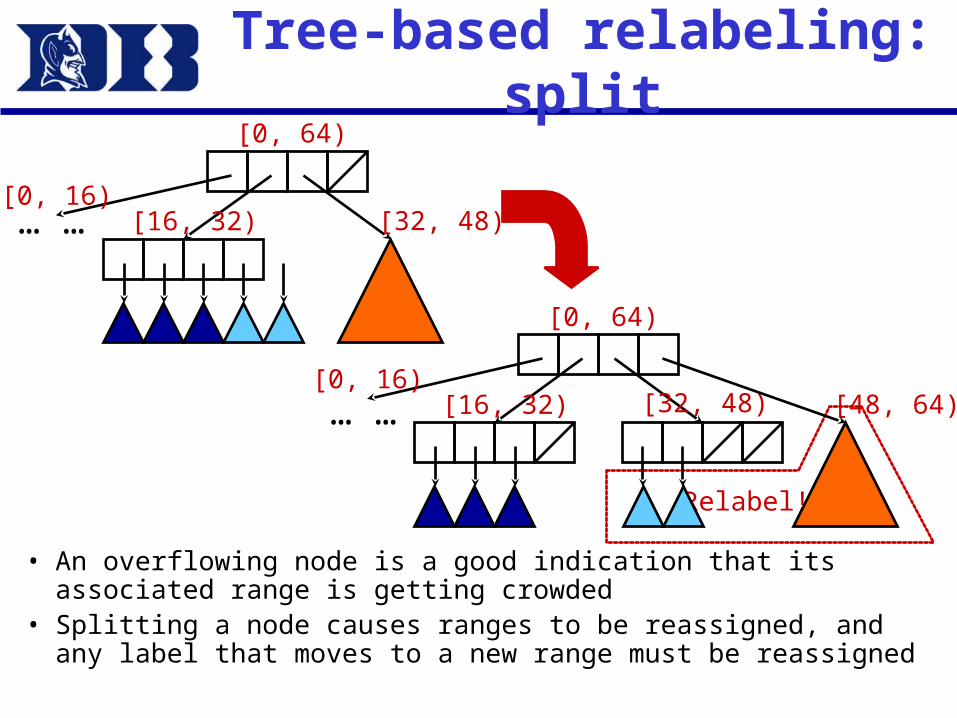
Tree-based relabeling: split
• An overflowing node is a good indication that its associated range is getting crowded
• Splitting a node causes ranges to be reassigned, and any label that moves to a new range must be reassigned
… …
[0, 64)
[0, 16)[16, 32) [32, 48)
Relabel!
… …
[0, 64)
[0, 16)[16, 32) [48, 64)[32, 48)

B-tree is not good enough
• Regular B-tree reorganizes too frequently– A node at level i (assuming leaves are at
level 0) can split every (B/2)i+1 insertions, where B is the block size or the maximum fanout
– But this split involves relabeling up to Bi+2 labels
– A factor of 2i+1B difference!
Alternative: weight-balanced B-tree [Arge & Vitter, FOCS 1996]

• Weight of a node = number of leaf entries below it• Basic idea: balance tree by weight rather than
fanout
• A weight-balanced B-tree has two parameters:– Branching parameter a (2 less than ½ of max fanout)– Leaf parameter k (roughly ½ of max leaf capacity)
• And following constraints (tuned specifically for W-BOX):– All leaves are at the same depth, and root has more than one child– A node at level i (assuming leaves are at level 0) has weight < 2aik– A node at level i (except root) has weight > aik – 2ai–1k
Implies that internal fanout is in [max/4 – 1, max], so Emptier than a regular B-tree Still O(logB N) height and O(N/B) space, where B is the block size
Implies that weight(parent(u)) = O(B weight(u))
W-BOX:Weight-balanced B-tree for Ordering XML

Complexity of W-BOX• Space is O(N/B)• Bits per label is at most
log N +1+d1.3 loga(N/k)+log be
• Amortized update cost is O(logB N) I/Os, because– W-BOX splits much less frequently than regular B-tree:
a node u will not be split again until (weight(u)) leaf entries are inserted below u
– Splitting u in the worst case involves relabeling all entries below u’s parent, with O(weight(parent(u))/B) = O(weight(u)) I/Os
• Worst-case lookup cost is one I/O, given the heap file record associated with the label (which points to the W-BOX leaf containing the label value)

Approach 2:
Virtual labels• Since updating labels is so messy, why physically store
them? Why not just provide a way to reconstruct them efficiently?
• Given the path from root to the leaf entry, we can construct a multi-component label consisting of the ordinal positions of the child links traversed
But without storing any labels—which are the B-tree search key values—how do we obtain this path in the first place?
… …… …
2
0
1
Label of the red leaf entry:
(2, 1, 0)
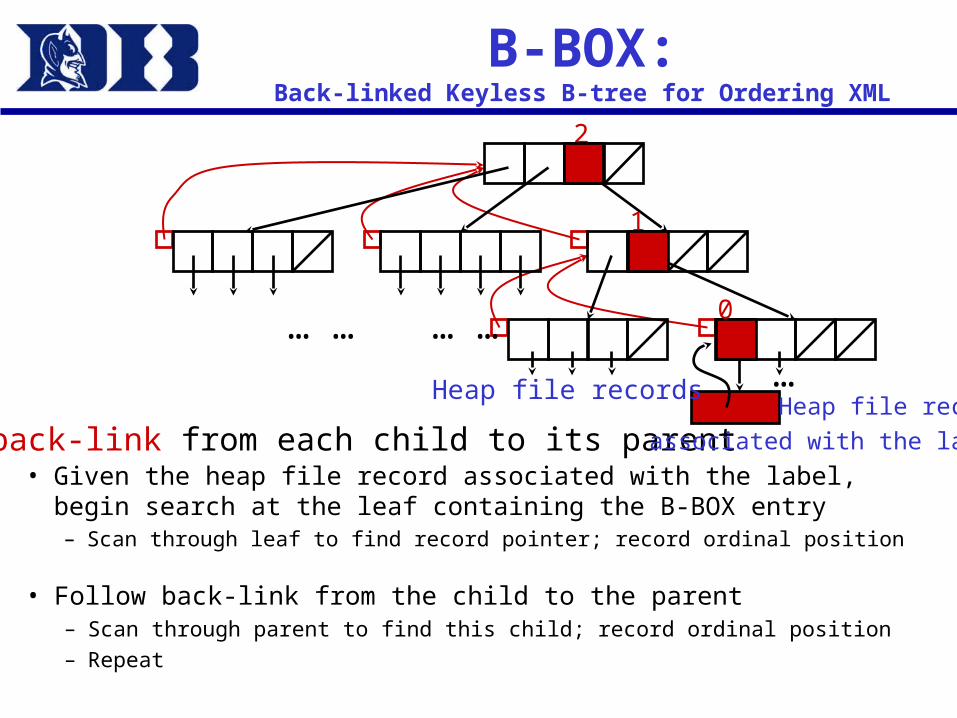
B-BOX:Back-linked Keyless B-tree for Ordering XML
• Given the heap file record associated with the label, begin search at the leaf containing the B-BOX entry– Scan through leaf to find record pointer; record ordinal position
Add back-link from each child to its parent
… …… …
Heap file recordassociated with the label
…Heap file records
0
1
2
• Follow back-link from the child to the parent– Scan through parent to find this child; record ordinal position– Repeat

Complexity of B-BOX
• Space is O(N/B)• Bits per label is at most
log N +1+d (logN–1)/(logB–1) e
• Worst-case lookup cost is O(logB N) I/Os
• Amortized update cost is O(1), because– Worst-case update cost is O(B logB N) I/Os
• Every node split relocates B/2 children to a different parent, requiring B/2 I/Os to update their back-links
• Splits can happen at every level• But no need to reorganize siblings of splitting node
– Splits are not too often: leaf splits only every B/2 insertions; level-1 node splits only every (B/2)2 insertions; level-2 node splits only every (B/2)3 insertions; and so on

Ordinal support• BOXes can be extended to support exact ordinal labels
– Augment with size fields, noting number of records below an entry
• W-BOX– After retrieving the label as normal, traverse top-
down searching for it and sum all size fields to left of traversed pointers in all nodes
– Lookup becomes O(logB N)
• B-BOX– Initialize counter to number of entries on starting leaf
to left of query record– During bottom-up traversal, at each node, add to
counter all size fields to left of record
– Update becomes O(logB N)

Ordinal support
• W-BOX top-down ordinal for “*” is (9+12)+3+2=26
• B-BOX bottom-up ordinal for “*” is 2+3+(9+12)=26
… …… …
size fields
3
9 12
*

Bulk operations• Bulk construction
– Bulk loading done by filling leaves with no splitting
• Inserting an XML subtree (see paper for deletion)– Find the insertion point in leaf– W-BOX: traverse upward to find lowest node that
can accommodate subtree’s number of nodes– B-BOX
• Bulk construct a new B-BOX, T’, with h’ levels• Traverse existing B-BOX upward, “ripping” nodes at
the insertion point, h’ levels up• Place T’ into resulting gapResult: all root-to-leaf paths have same length

Experiment:
Concentrated insertions• Designed to stress-test the data structures
– 2-level XML document with 2 million elements– Insert 0.5 million elements one by one, always
right in the middle of the document• Naïve performs poorly even with 256 more
bits• BOXes handle this near-worst case
gracefully– B-BOX is most efficient– Bear in mind that
W-BOX lookup has constant cost but B-BOX is logarithmic
Avg. I/Os Per Insert
naïve-256naïve-64naïve-16naïve-4
B-BOX
W-BOX
Avg. I/Os Per Insert

Experiment: XMark
• Designed to test “normal operations”– XMark document with 336K elements– Insert elements one by one in document order– Start accounting after 200K elements
• Naïve still struggles, unless it has 32 more bits– But the overhead of
manipulating long labels would be high for query processing, which is not measured in this figure
• BOXes still very efficient– Labels fit in machine word
Avg. I/Os Per Insert
naïve-32naïve-16naïve-8
naïve-4naïve-2B-BOXW-BOX

Removing indirection
• Basic caching– Each reference to a label is augmented with
a cached value and a last-cached timestamp– Each document maintains a last-updated
timestamp– If (last-cached > last-updated), cached value
is valid; otherwise, pay the full cost of lookup
• Good enough for rarely updated documents, less effective when there is a steady update workload

Caching + logging Observation: effect of an update on existing
labels can often be described succinctly for W-BOX and B-BOX– Example: insert a new label before 109 on a leaf
whose largest label is 123; assuming no split, the effect can be described as [109, 123]: +1
• Keep a log of last k updates in memory• Consult the log to see if a cached label value
can be brought up to date by applying the effects of subsequent updates in order– If (last-cached < earliest logged update), pay full
cost of lookup

Conclusion
• XML labeling difficult for dynamic documents• BOXes facilitate mutable labels of size O(log
N)• BOXes trade off update/lookup cost
– W-BOX: logarithmic update (amortized), constant lookup
– B-BOX: constant update (amortized), logarithmic lookup
• Both handle arbitrary insertion/deletion patterns and XML tree shapes
• Indirection/lookup overhead mitigated by caching and logging

Questions?

Related Work• Dewey encoding [Tatarinov, et al., SIGMOD 2002]
– Combine local ordering of each element on incoming path
• Microsoft ORDPATH [O’Neil, et al., SIGMOD 2004]– Extends Dewey to support inserts using “carating-in” (N) bits/label for some insertion sequences or tree shapes
• Relabeling for equally-sized gaps [Jagadish, et al., VLDBJ 2002; Halverson, et al., VLDB 2003; etc.], and use of floating-point labels [Amagasa, et al., ICDE 2003] High relabeling cost for some insertion sequences
• Maintaining order in a linked list [Dietz 1982, 1987; Bender et al., ESA 2002] and application to XML labeling [Fisher, et al., CIKM 2003; Chen et al., EDBT Workshop 2004] Internal-memory data structures

Other features
• BOXes support efficient bulk operations– Bulk loading of data– Insert/delete of whole XML subtrees
• Removing the extra indirection from immutable label IDs to actual label values– Cache label values– Log effects of inserts/deletes and “replay”
them

















