
ACOUSTIC FINGERPRINTING SYSTEMS
14
LINKÖPINGS UNIVERSITET - IDA ACOUSTIC FINGERPRINTING SYSTEMS Louise Walletun Artificiell Intelligens II 729G11 HT2012
Transcript of ACOUSTIC FINGERPRINTING SYSTEMS

LINKÖPINGS UNIVERSITET - IDA
ACOUSTIC FINGERPRINTING SYSTEMS
Louise Walletun
Artificiell Intelligens II 729G11
HT2012

2
Innehållsförteckning
Inledning ............................................................................................................................................... 3
Attribut hos akustiska fingeravtryck ....................................................................................................... 4
Evalueringssystemet ....................................................................................................................................... 4
Generell uppbyggnad av ett system ........................................................................................................ 6
Front-end ........................................................................................................................................................ 6
Fingerprint Modeling Block ........................................................................................................................ 8
Exempel på implementering (Shazam) .................................................................................................... 9
Framing och transformation ........................................................................................................................... 9
Databas och matchning ............................................................................................................................ 10
Referenser ........................................................................................................................................... 14

3
Inledning
I vår ständigt teknologiskt föränderliga värld tillkommer det dagligen intressanta tjänster inom
musikbranschen. Detta är ett område där nya kreativa lösningar har efterfrågats enormt allt
eftersom skivhandlandet minskat drastiskt samtidigt som fler musiker vill kunna försörja sig på sitt
skapande. Med detta som grund har utvecklingen inom intelligent teknik för att få konsumenter
att köpa mer musik ökat under senare år. Många företag, däribland Shazam Entertainment Ltd.,
har valt att utveckla musikigenkännande applikationer som är tänkta att underlätta då lyssnaren
hör ett icke-familjärt stycke som den gillar och skulle vilja undersöka vid senare tillfälle men inte
vet vad artisten eller stycket heter. Ett intressant lösning som hjälper konsumenterna att själva
hitta musiken likväl som den hjälper musiken att hitta konsumenterna.
Denna tjänst är baserad på en teknik som kallas för akustiska fingeravtryck (acoustic
fingerprinting) vilket kan sammanfattas som digitala representationer av ljudsignaler. Lyssnaren
samplar en tio sekunders sekvens av musik, som avkodas till ett fingeravtryck och sedan matchas
mot en databas av liknande akustiska fingeravtryck. Flertalet andra användningsområden finns
även för denna teknik, som exempelvis igenkänning av copyright och stulet musikmaterial.
I detta fördjupningsarbete beskrivs först ett generellt evalueringssystem för akustiska
fingeravtryckssystem och vilka faktorer som bör tas hänsyn till i konstruktionen. Vidare
sammanfattas ett förslag på hur den allmänna uppbyggnaden av ett sådant system ser ut.
Slutligen konkretiseras bilden av ett akustiskt fingeravtryckssystem genom en beskrivning av hur
detta används i musiktjänsten Shazam.

4
Attribut hos akustiska fingeravtryck
Akustiska fingeravtryck (acoustic fingerprinting) går att beskriva som digitala sammanfattningar av
ljudsignaler. Användandet av dessa fingeravtryck känns främst igen hos dess förmåga att utföra
musikigenkänning av okänd musik oberoende av format på musikfilen ifråga. System baserade på
akustiska fingeravtryck tar ett stycke musik, gör ett perceptuellt sammandrag av de akustiskt
utstickande elementen för att sedan lagra i en fingeravtrycksdatabas. När systemet sedan
presenteras med icke-familjärt ljud letar den i databasen och med hjälp av sök- och
matchningsalgoritmer kan den utföra den automatiska musikigenkänningen.
Ett system som använder sig av akustiska fingeravtryck har många faktorer att ta hänsyn till för att
vara funktionellt användbart. Det måste även kunna sammanfatta och representera ljudsignalen
på ett bra och relevant vis som överensstämmer med hur människan perceptuellt uppfattar ljudet,
även om dess binära representation skiljer sig åt.
Evalueringssystemet
Ett mer generellt evalueringssystem för att kunna jämföra liknande identifieringstekniker av denna
sort har utarbetats som tar upp de kritiskt viktiga punkterna att uppfylla vid utvecklandet (Cano P,
Batlle E, Kalker T, Haitsma J, 2002). Några av dessa termer kommer att användas i senare
beskrivningar vilket gör definitionen av begreppen relevanta att sammanfatta. Följande punkter
utgås ifrån vid värderingar av denna typ av system:
Träffsäkerhet: Systemet värderas beroende på hur många rätta identifikationer, misslyckade
identifikationer samt felaktiga identifikationer (så kallade false positives) den lyckas utföra. Denna
punkt kan sammanfattas som applikationens hit-miss-ratio. Störst fokus är det på de felaktiga
identifikationerna som bör vara obefintliga om systemet ska vara optimalt.
Reliabilitet: Systemet måste vara rättsligt effektivt och veta om huruvida den har tillåtelse rent
copyright-mässigt att identifiera musiken eller ej. Andra situationer kan vara skivor som
exempelvis inte släppts ännu som även de inte får identifieras. De flesta applikationer använder sig
av uppköpta databaser som erbjuds av diverse företag vilket underlättar den rättsliga processen
betydligt.

5
Stabilitet: Denna evalueringsfunktion bedömer hur effektivt systemet klarar av att identifiera när
musikfilen är av dålig kvalitet, har påtagliga brusnivåer eller dylika störningar i bakgrunden. Detta
har att göra med hur väl själva fingeravtrycksalgoritmen fungerar.
Granluering: Detta syftar på hur väl enstaka segment av en hel sång kan igenkännas. Detta
förutsätter att synkroniseringen mellan fingeravtrycket i databasen samt det inspelade segmentet
fungerar väl och att sökningsalgoritmen inte tar för lång tid på sig att identifiera.
Säkerhet: Behandlar hur säkert systemet är mot manipulationer och hur stabilt det är mot intrång
utifrån.
Ombytlighet: Hur flexibel är systemet när det kommer till att identifiera ljud oavsett format på
ljudfilen, eller hur applicerbar är databasen på olika tjänster/applikationer?
Skalbarhet: Bedömer hur lätt systemet kan expanderas till större skalor med stora databaser eller
multipla simultana identifikationsprocesser. Detta är av stor vikt då det påverkar systemets
komplexitet och kan även ha effekt på hur precist det är.
Komplexitet: Syftar till hur beräkningskostsamt och hur tungrott fingeravtrycksextraherandet är
hos systemet. Tar även hänsyn till hur stora fingeravtrycken blir, hur lång tid sökalgoritmen tar på
sig, hur flexibelt det är att ändra i databasen och så vidare.
Ömtålighet: I fall då musikigenkänning inte är fallet utan när liknande system som behandlar
integritetsverifikation och copyrightproblem är i bruk måste ömtålighet tas hänsyn till. Mer
konkret menas motsatsen till stabilitetskravet, det vill säga att systemet måste kunna känna av
små förändringar i stycket som kan vara inverkande på upphovsrätten.
Översiktligt gäller med andra ord att ett robust fingeravtryck måste vara smidigt extraherat med
endast den ytterst relevanta informationen som krävs, vilket är en kamp mellan till exempel
komplexitet- och stabilitetskraven. Systemet får ej vara för beräkningstungt eller
tidskonsumerande i sitt utförande men måste vara stabilt och inte lättpåverkat mot störningar och
brus i bakgrunden som inte tillhör ljudsinalens essentiella element. Slutligen måste det även vara
hållfast mot kollisioner, det vill säga att det måste vara stabilt nog att kunna generera olika
fingeravtryck trots två relativt lika ljudsignaler.

6
Generell uppbyggnad av ett system
Akustiska fingeravtryckssystem är oftast mycket varierande beroende på vilka uppgifter de
förväntas utföra, och kompromissar oftast mellan de olika evalueringsfaktorerna i föregående
stycke. Av denna anledning är det relativt svårt att beskriva en generell uppbyggnad för denna typ
av system, men nedan beskrivs ett förslag på ett ramverk som gäller för de allra fall (Cano P, Batlle
E, Kalker T, Haitsma J, 2002). I detta förslag är det fullständiga systemet bestående av två
processer; extraherandet och skapandet av själva fingeravtrycket samt algoritmen som matchar
sökningen mellan databasen och det icke-familjära inspelade ljudet. Processen då fingeravtrycket
skapas kan i sin tur delas upp i en så kallad ”Front-End” samt ett ”Fingerprint modeling block”. I
den förstnämnda delen görs ljudsignalen om till ett prefererat format som sedan matas vidare till
den sistnämnda delen. Detta sker i en mängd steg, men värt att tillägga är att dessa steg kan
beroende på system variera, repeteras eller se ut på annorlunda sätt.
Front-End
Fig 1. Förenklad illustration över konstruktionen av Front-end.
A: Förprocessen:
Här tas analogt ljud och görs om till digitalt för att sedan konverteras till ett standardformat. Vilket
format den konverterar till varierar helt beroende på system, men vanligt förekommande är att
ljudet blir till så kallat raw-format som motsvarar CD-ljud med en sampling rate på 44.1 kHz
(44 100 samples per sekund) och 16-bits upplösning.
B: Framing och överlappning:
Ljudsignalen delas nu upp i mindre stycken som benämns som frames. Dessa delas upp till en
storlek som vanligvis motsvarar ca 10-500 ms av signalen. Antalet frames per sekund kallas för

7
frame rate, vilket är hastigheten som frames extraheras ur signalen i. Överlappning är också
nödvändigt att lägga på för en smidig frameskonstruktion och för att kunna reservera sig för de fall
då ljudsignalen inte överensstämmer ordentligt.
C: Linjär transformation – Spektral uppskattning:
När den linjära transformationen utförs är tanken att de uppmätta variationerna i signalen nu ska
mätas om till en annan representationsform som benämns som features. Fördelen med en lyckad
transformation är att de mest utstickande akustiska variationerna kan urskiljas och överflödig
information kan reduceras vilket i sin tur minskar systemets komplexitet. Den enklaste och minst
krävande typen av transformationer är att använda sig av fixerade basisvektorer som beräknar
sambandet mellan tid och frekvens. En av de vanligaste transformationsmetoderna av denna typ
är Discrete Fourier Transformation som är en algoritm som utförs på varje uppdelad frame vilket
sedan genererar i ett spektrogram, den spektrala uppskattningen av relationen mellan tid och
frekvens.
D: Extraherande av features:
Då tids-frekvensrepresentationen har bildats görs ytterligare transformationer vanligtvis för att få
fram tydligare akustiska vektorer. Här plockas de mest utstickande av features ut åter igen för att
minska komplexiteten. Något som är vanligt förekommande är även att i detta stadie försöka
implementera kunskap om människohörselns olika stadier (The human auditory system HAS) för
att veta tydligare vad som räknas som perceptuellt utstickande element och inte.
Det finns en rad olika algoritmer för att extrahera dessa features beroende på vilken typ av output
som är intressant och beroende på om systemets features hämtas från ett enkelt frekvensband
eller flera subfrekvensband. Shazam som exemplifieras i ett senare stycke är ett exempel på ett
system som är baserat på ett enkelt band. Exempel på output kan vara att matematiskt beräkna ut
features som så kallade Mel-Frequency Cepstrum Coefficients, vars metod jag väljer att inte gå in
på här, men som kort kan sammanfattas som en representation av spektrogrammets amplituder.
Spectral Flatness Measure (SFM) används även ibland som mäter i decibel som kan visa en
uppskattning av ”rena toner” respektive ”oljud” i ljudsignalen. Det finns även system som
använder sig av optimerade subband- och eller frameskombinationer. Däribland finns system som
tillämpar så kallade Hidden Markov Models som annars är en vanligt tillämpad modell inom

8
taligenkänningssystem. Fördelen med dessa modeller är att de klarar av att representera ett inre
tillstånd samt beräkna sannolikheter för nästkommande handlingar. Dess metod kommer inte
heller att uppmärksammas här, men i korthet tillämpas den genom att ett färdiga ”alfabet” med
ljud (istället för fonemer som används inom taligenkänningssystem) tillverkas som är modellerade
med HMM:s. Det samplade ljudet bryts sedan ner i dessa alfabetkomponenter till ljud vilket
representerar en sekvens av features i slutändan.
E: Efterprocessen:
I slutet av front-end förbereder fingerprintingsystemet den extraherande sekvensen av features
innan den skickas vidare till Fingerprint Modeling Block där själva fingeravtrycket konkretiseras.
Syftet med efterprocessen är att karaktärisera variationer i signalen ytterligare, vilket kan göras
genom att beräkna derivatan av sina features, vilket tenderar att ge en expanderad ljudstyrka hos
signalen samtidigt om störningar i signalen filtreras bort någorlunda. Vanligt är även att man
lägger till en kvantiseringsprocess (en typ av avskalning) till sina features som gör bland annat
signalen mer robust mot ljudstörningar och reducerar komplexiteten ytterligare.
Fingerprint modeling block
När sekvensen av features skickats vidare till detta block ska själva fingeravtrycket genereras.
Detta genomförs genom en att applicera en modell som reducerar fingeravtrycket till behändig
storlek. Valet av modell påverkar givetvis databasens utformning och även hur väl matchningen
kommer kunna utföras vilket gör det till en mycket viktigt steg. Ett exempel på en enkel och smidig
modell är att summera ihop sina features till en till en och samma vektor innehållandes all
nödvändig information. Där kan exempelvis själva spektrogrammet sammanfattas i kombination
med övriga nödvändiga element (till exempel den genomsnittliga hastigheten, BPM (beats per
minutes) för att representera ljudsignalen. Det essentiella med valet av modell är att
fingeravtrycken får en representation som är kompakt och inte allt för beräkningstung. Konkret
exempel på en fingeravtrycksrepresentation kan ses i Shazam-exemplet i kommande stycke.

9
Exempel på implementering (Shazam)
Ett modernt exempel på en tjänst där akustiska fingeravtryck tillämpas är applikationen Shazam
utvecklat av Shazam Entertainment Ltd. som utför musikigenkänning direkt i mobiltelefonen, även
med hänsyn till eventuellt brus eller oljud i bakgrunden. För att beskriva tjänstens funktion i
korthet grundar den till att börja med i en omfattande databas av musik där varje stycke är lagrat i
form av ett unikt akustiskt fingeravtryck. Användaren spelar in ett tio sekunder långt musiksample
via mobiltelefonens mikrofon som även det omvandlas till ett fingeravtryck. Applikationen är
beroende av nätverksanslutning och kopplar sedan upp sig mot Shazams databas för att
genomföra en sökning som i sin tur genererar en matching.
Framing och transformation
Denna typ av fingeravtryckssystem använder sig av beståndsdelar baserade på ett enda band som
i detta fall är så kallade spektrogram. Dessa kan beskrivas som grafer som uppmäter tid (x),
frekvens (y) och i sin tur intensitet (Fig 2). Som jämförelse skulle en horisontell linje i ett sådant
spektrogram motsvarat en så kallad sinuston, det vill säga en ren ton med endast en frekvens som
hade varit sinusformad i en frekvensmätning (Fig 3). En vertikal linje i spektrogrammet hade
istället inneburit ett så kallat konstant vitt brus som innehåller alla frekvenser och med en jämn
och genomsnittlig energi (Fig 4).
Fig 2. Exempel på ett spektrograms utformning där intensitetstopparna markerats med röd färg. (Wang, Avery Li-Chun. An Industrial-Strength Audio Search Algorithm. Shazam Entertainment, 2003)

10
Fig 3. (vänster) Exemplifierande sinusformad kurva (http://www.holger-schnarre.de/Forum/Sinusverz.gif)
Fig 4. (höger) Illustrerande bild av ett vitt brus. (http://www.school-for-champions.com/science/images/noise_reduction-white.gif)
Genom dessa två faktorer genereras alltså den tredje grafen som motsvarar intensiteten. Att lagra
hela spektrogrammet i en databas i Shazams storlek hade gjort programmet allt för
beräkningstungt, vilket bidrog till att deras algoritm istället fokuserar på att endast identifiera de
mest utmärkande intensitetstopparna i spektrogrammet. Detta medför även fördelar när det
kommer till hanteringen brus och andra störningar i bakgrunden som påverkar stabilitetskravet
hos systemet. Enligt Avery Wang, grundaren av Shazam, hittar systemet ungefär tre av dessa
intensitetstoppar per sekund.
Spektrogrammet kalkyleras i fingeravtryckssystemets transformationsprocess utifrån en
uppdelning i en mängd frames som vanligtvis överlappar varandra. Den vanligaste
transformationsmetoden som används är Short-time Fourier Transform som är lämplig att
använda när frekvenserna inte är konstanta i ljudsignalen. Genom att ta magnituden av denna kan
spektrogrammets tid- och frekvensfördelning representeras vilket visas i nedanstående algoritm.
Databas och matchning
Utformingen av Shazams databas med fingeravtryck är formulerade i en så kallad hash table som i
dagsläget innehåller fingeravtryck som motsvarar över två miljoner låtar. En sådan tabell fungerar
likt en dictionary med en utvald nyckel (key) som i detta fall är fingeravtryckets frekvens. Till denna
nyckel hör ett associerat värde (value) som motsvaras av tiden då frekvensen utspelas. För att
11
lagra en hash har Shazams grundare valt att registrera de tidigare nämnda intensitetstopparna
som konstellationskartor. Fördelarna som kan ses med detta är bland annat att det förenklar
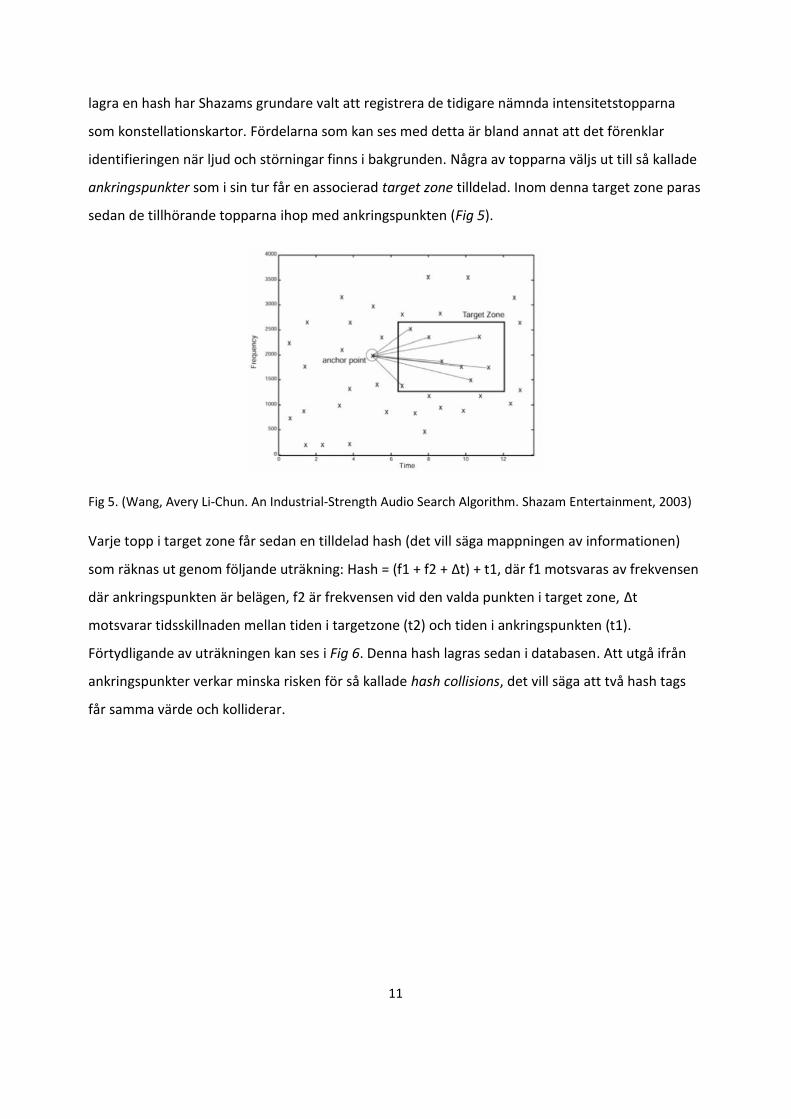
identifieringen när ljud och störningar finns i bakgrunden. Några av topparna väljs ut till så kallade
ankringspunkter som i sin tur får en associerad target zone tilldelad. Inom denna target zone paras
sedan de tillhörande topparna ihop med ankringspunkten (Fig 5).
Fig 5. (Wang, Avery Li-Chun. An Industrial-Strength Audio Search Algorithm. Shazam Entertainment, 2003)
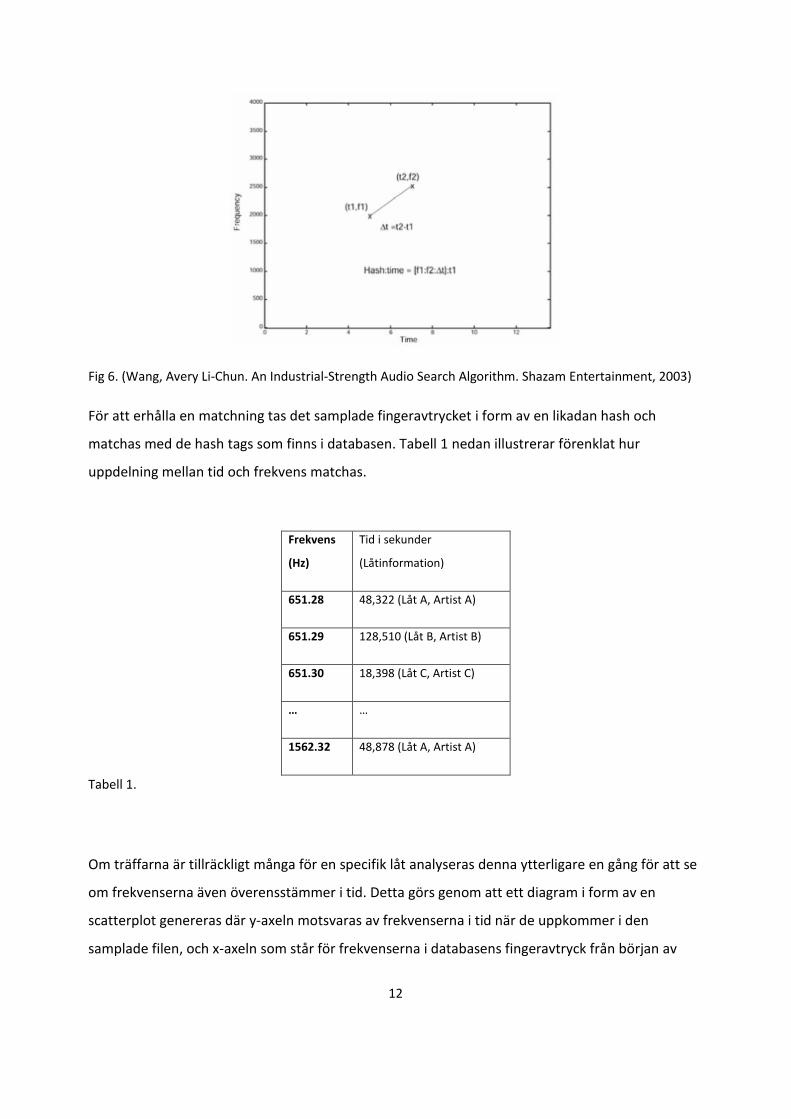
Varje topp i target zone får sedan en tilldelad hash (det vill säga mappningen av informationen)
som räknas ut genom följande uträkning: Hash = (f1 + f2 + Δt) + t1, där f1 motsvaras av frekvensen
där ankringspunkten är belägen, f2 är frekvensen vid den valda punkten i target zone, Δt
motsvarar tidsskillnaden mellan tiden i targetzone (t2) och tiden i ankringspunkten (t1).
Förtydligande av uträkningen kan ses i Fig 6. Denna hash lagras sedan i databasen. Att utgå ifrån
ankringspunkter verkar minska risken för så kallade hash collisions, det vill säga att två hash tags
får samma värde och kolliderar.
12
Fig 6. (Wang, Avery Li-Chun. An Industrial-Strength Audio Search Algorithm. Shazam Entertainment, 2003)
För att erhålla en matchning tas det samplade fingeravtrycket i form av en likadan hash och
matchas med de hash tags som finns i databasen. Tabell 1 nedan illustrerar förenklat hur
uppdelning mellan tid och frekvens matchas.
Frekvens
(Hz) Tid i sekunder
(Låtinformation)
651.28 48,322 (Låt A, Artist A)
651.29 128,510 (Låt B, Artist B)
651.30 18,398 (Låt C, Artist C)
… …
1562.32 48,878 (Låt A, Artist A)
Tabell 1.
Om träffarna är tillräckligt många för en specifik låt analyseras denna ytterligare en gång för att se
om frekvenserna även överensstämmer i tid. Detta görs genom att ett diagram i form av en
scatterplot genereras där y-axeln motsvaras av frekvenserna i tid när de uppkommer i den
samplade filen, och x-axeln som står för frekvenserna i databasens fingeravtryck från början av

13
låten. Därefter utförs en kalkylering som sedan resulterar i en klusterutformning i form av en
diagonal linje (se övre scatterplot-diagrammet i Fig 7.) om låten klassificeras som en match. Det
undre diagrammet i Fig 7 motsvarar en situation då ingen match lyckats genereras.
Fig 7. (Wang, Avery Li-Chun. An Industrial-Strength Audio Search Algorithm. Shazam Entertainment, 2003)

14
Referenser
Cano P, Batlle E, Kalker T, Haitsma J (2002) A review of algorithms for audio fingerprinting. Proc. of the IEEE MMSP, St. Thomas, V.I.
Doets, P.J.O, Gisbert, M. Menor and Lagendijk, R.L., "On the comparison of audio fingerprints for extracting quality parameters of compressed audio." [ed.] Edward J. Delp III and Ping Wah Wong. Delft : Security, Steganography, and Watermarking of Multimedia Contents VIII, 2006, Vol. 6072.
Shazam, September 2012, http://www.shazam.com/
Van Nieuwenhuizen H.A, Venter W.C, Grobler M.J., ”The Study and Implementation of Shazam’s Audio Fingerprinting Algorithm for Advertisement Identification”, September 2012, http://www.satnac.org.za/proceedings/2011/papers/Software/181.pdf
Wang, Avery Li-Chun., "An Industrial-Strength Audio Search Algorithm." ISMIR, London : Shazam Entertainment, Ltd., 2003.
Wikipedia, “Acoustic Fingerprint”, September 2012, http://en.wikipedia.org/wiki/Acoustic_fingerprint


















