Accurate Math Functions on the Intel IA-32 ... - RNC 7
20
INTEL CONFIDENTIAL Accurate Math Functions on the Intel IA-32 Architecture: A Performance-Driven Design Cristina Anderson, Nikita Astafiev and Shane Story Intel Corporation July 2006
Transcript of Accurate Math Functions on the Intel IA-32 ... - RNC 7

INTEL CONFIDENTIAL
Accurate Math Functions on the Intel IA-32 Architecture: A Performance-Driven Design
Cristina Anderson, Nikita Astafiev and Shane StoryIntel Corporation
July 2006

Agenda
• Intel LIBM design– Goals– Techniques– Verification
• Implementation tricks for gaining– Performance– Accuracy
• Current results– Performance and Accuracy tables
• Future development– Challenges of coding in C– Correctly rounded

Intel LIBM design
• Goals– Performance: Latency optimized routines
• Given the maximum resources function should finish execution as soon as possible
• Opposed to Through-put optimization: maximum number of independent functions run in parallel – each is constrained in resources
sin(x)
sin(x) sin(x) sin(x)

Intel LIBM design
• Goals– Performance: Latency optimized routines– Accuracy: 0.55 ulps (units in the last place) or better in round-to-nearest
Rounding error = |bexp·d0.d1d2 … dp-1 – bexp·d0.d1d2 … dp-1dddddddd… |·bp-1-exp
p-digits format Exact base b representation
d0.d1d2 … dp-20
d0.d1d2 … dp-201
d0.d1d2 … dp-21

Intel LIBM design
• Goals– Performance: Latency optimized routines– Accuracy: 0.55 ulps or better in round-to-nearest– Correctly rounded in IEEE-754 mandated cases– Exception flags– C99, F90 conformance– Structured Exception Handling

Intel LIBM design
• Algorithms– Argument reduction– Table-lookup– Polynomial approximation– Reconstruction
log(2n · M) = n·log2 + logM = n·log2 – log(B) + log(B·M)
= n·log2 – log(B) + log(1 + (B·M – 1)) B 1/M≈
≈ n·Tlog2 – Tlog(1/M) + Poly(r)
= n·(Tlog2_hi + Tlog2_lo) – T(indexlog(1/M)) + r·(P1 + r·(P2… )… )

Intel LIBM design
• Architecture– IA-32 instructions set
• General Purpose– 32-bit GP registers
• x87 FPU– 80-bit FP registers
MOVLoads
CMP, TESTTests
SHL, SHR, SARShifts
OR, AND, XORLogical
ADD, SUBArithmetic
General Purpose
FADD, FMULArithmetic
FPREM1Remainder
FLDLoad
x87 FPU

Intel LIBM design
• Architecture– IA-32 instructions set
• General Purpose• x87 FPU• SSE/SSE2/SSE3…
– 128-bit registers– 2 double FP– 4 single FP
PSHUFDPack / unpack
MOVD, PEXTRW, PINSRWTransfers to /from GPR
CVTSS2SD, CVTSD2SSFormat conversions
PSRLQ, PSLLQ,PSRLD, PSLLD
Logical shifts
MOVSSMOVAPS
ORPS,ANDPS,XORPS
ORPD,ANDPD,XORPD
Logical
MOVSDMOVAPD
Load one elementLoad 128 bit
MOVDDUPPack
MULPS/SSDIVPS/SS
MULPD/SDDIVPD/SD
FP SIMD/scalarmultiply, divide
ADDPS/SSSUBPS/SS
ADDPD/SDSUBPD/SD
FP SIMD/scalaradd, subtract
SinglePrecision
DoublePrecision
SSE/SSE2/SSE3

Intel LIBM design
• Architecture– IA-32 instructions set
• General Purpose• x87 FPU• SSE/SSE2/SSE3…
– Instruction-level parallelism

Intel LIBM design
• Architecture– IA-32 instructions set
• General Purpose• x87 FPU• SSE/SSE2/SSE3…
– Instruction-level parallelism– SIMD parallelism
P(x) = (… ((P9·x + P8)·x + P7)·x +… +P0
Podd = (((P9·x2 + P7)·x2 + P5)·x2 + P3)·x2 + P1
Peven = (((P8·x2 + P6)·x2 + P4)·x2 + P2)·x2 + P0
P(x) = Podd·x + Peven

Intel LIBM design
• Verification– Paper proofs are limited
• IEEE required cases (sqrt, division, remainder)– IMLTS (Intel Math Library Test Suite)
• Black and White box testing– Accuracy / Monotonicity / Symmetry / Special Values / Flags– Hard to round cases
• Errors have been found in the 3 available CR libraries

Implementation tricksBranch collapsing
y = y + a1
a1 = ma & ay = y + a
ma = (b – x) >> 31if (x > b)
Branch collapsing via bit-mask

Implementation tricksBranch collapsing
if ((unsigned) (x-b) > a-b )goto special
…<main path>…
if (x > a)goto overflow
if (x < b)goto underflow
…<main path>…
Let a > b
Branch collapsing via condition shrinking

Implementation tricksFast conversions
cvtsd2si y, xcvtsi2sd r, y
Result is represented in double FP format
Let double |x| < 251
Fast conversion to integer via Right Shifter
252 + 251
1 1 1 * *
rounding
20
.fraction
movd index, x
addsd x, 252 + 251
subsd x, 252 + 251

Implementation tricks
y = 2(E - 1023)·significand
psllq x, 52 – 23paddd x, 0x3800000000000000
cvtss2sd y, x
x = 2(E - 127)·significand
Let single x > 0
Fast Single to Double conversion
y = |x|y = (x + S) xor S
N = 32 or 64
000…0 , if x >= 0111…1 , if x < 0
S = x >> (N − 1)
Fast integer ABS
S =

Implementation tricksAccuracy and performance
• arcsinh(x) = ln(x + sqrt(x2+1)) = ln(1 + (x + sqrt(x2+1) – 1))= ln(1 + V), V >= 0
• Relative error
dy d(ln(1+V)) dV dV y ln(1+V) (1+V)·ln(1+V) V
• Multiprecision computations– Newton iterations for sqrt and argument reduction– Polynomial reconstruction of log (lower terms)
A + B != round to double (A + B)Let |A| > |B|Shi = round to double (A + B)
Slo = (A – Shi) + B
A + B = Shi + Slo
Sometimes it is possible to make the lower terms of the polynomial simple – to have less high-low parts computations
__ _______ _________ __= = < V > 0

Current results: Accuracy
0.50.501025POWF0.50.502916LOGF0.50.506582EXPF0.50.520918ATANF0.50.500003ACOSF0.50.500003ASINF7.04E+130.504488TANF3.52E+130.509615COSF1.13E+150.513276SINF8.48E+080.506688POW
0.50.5005830.5003760.501397LOG0.50.5000470.7872140.540348EXP0.50.50.5003070.542333ATAN
2.15E+050.531348ACOS0.50.501573.4408710.535745ASIN0.50.5000012.60E+330.541852TAN0.50.5000012.60E+330.51851COS0.50.52.60E+330.515082SIN
CRlibmCRlibm (first step)GNU libmIntel libmFunction
Intel 9.1 compiler LIBM: Intel(R) C++ Compiler for 32-bit applications, Version 9.1 Build 20060505Zglibc 2.3.6 built on SUSE* SLES9 with gcc 3.3.3Modified CRLIBM* 0.11beta1, built on SUSE* SLES9 with gcc 3.3.3 Performance tests and ratings are measured using specific computer systems and/or components. Any difference in system design or configuration may affect actual performance.Intel, the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries.* Other brands and names may be claimed as the property of others.
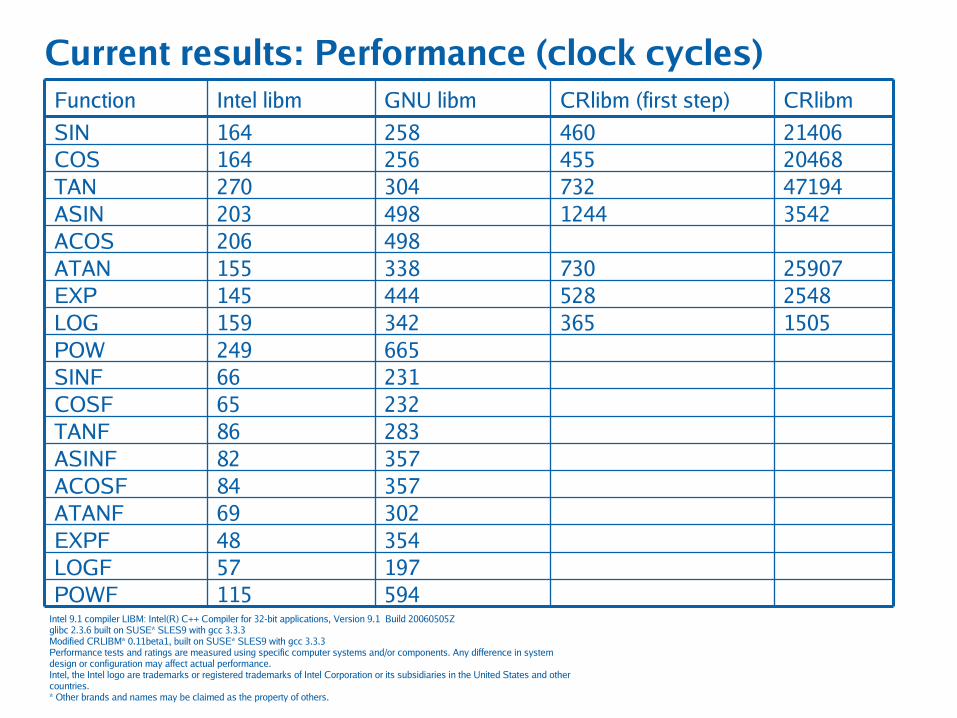
Current results: Performance (clock cycles)
594115POWF19757LOGF35448EXPF30269ATANF35784ACOSF35782ASINF28386TANF23265COSF23166SINF665249POW
1505365342159LOG2548528444145EXP25907730338155ATAN
498206ACOS35421244498203ASIN47194732304270TAN20468455256164COS21406460258164SIN
CRlibmCRlibm (first step)GNU libmIntel libmFunction
Intel 9.1 compiler LIBM: Intel(R) C++ Compiler for 32-bit applications, Version 9.1 Build 20060505Zglibc 2.3.6 built on SUSE* SLES9 with gcc 3.3.3Modified CRLIBM* 0.11beta1, built on SUSE* SLES9 with gcc 3.3.3 Performance tests and ratings are measured using specific computer systems and/or components. Any difference in system design or configuration may affect actual performance.Intel, the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries.* Other brands and names may be claimed as the property of others.

Future Development
• Code in C– Ease of use and support
• In-lining• Portability
– Some architectural features are inaccessible from the high-level programming language (e.g. logical operations on FP numbers)
• Compiler built-ins (extensions to language) can help– Dependency on the compiler
• Correctly rounded– Currently out of scope– Challenge: accuracy (consistency) vs performance– Proof is the main problem: e.g. 3 publicly available CR libraries have had accuracy
issues• IBM Ultimate LIBM*. 1999, 2002.• Sun LIBMCR*. Ver. 0.9; December 2004.• ENS-Lyon CRLIBM*. Ver. 0.8beta; January 2005
* Other brands and names may be claimed as the property of others.

Thank You!