
A Tutorial on Learning with Bayesian Networks David Heckerman.
32
A Tutorial on Learning with Bayesian Networks David Heckerman
-
Upload
gregory-turpin -
Category
Documents
-
view
217 -
download
0
Transcript of A Tutorial on Learning with Bayesian Networks David Heckerman.

A Tutorial on Learning with Bayesian Networks
David Heckerman

What is a Bayesian Network?
“a graphical model for probabilistic relationships among a set of variables.”

Why use Bayesian Networks?
• Don’t need complete data set• Can learn causal relationships• Combines domain knowledge and data• Avoids overfitting – don’t need test data

Probability
• 2 types1. Bayesian2. Classical

Bayesian Probability
• ‘Personal’ probability• Degree of belief• Property of person who assigns it• Observations are fixed, imagine all possible
values of parameters from which they could have come
“I think the coin will land on heads 50% of the time”

Classical Probability
• Property of environment• ‘Physical’ probability• Imagine all data sets of size N that could be
generated by sampling from the distribution determined by parameters. Each data set occurs with some probability and produces an estimate
“The probability of getting heads on this particular coin is 50%”

Notation
• Variable: X • State of X = x• Set of variables: Y• Assignment of variables (configuration): y• Probability that X = x of a person with state of information
ξ:• Uncertain variable: Θ• Parameter: θ• Outcome of lth try: Xl
• D = {X1 = x1, ... XN = xN} observations
)|( xXp

Example
• Thumbtack problem: will it land on the point (heads) or the flat bit (tails)?
• Flip it N times• What will it do on the N+1th time?
How to compute p(xN+1|D, ξ) from p(θ|ξ)?

Step 1
• Use Bayes’ rule to get probability distribution for Θ given D and ξ
where)|(
),|()|(),|(
Dp
DppDp
dpDpDp )|(),|()|(

Step 2
• Expand p(D|θ,ξ) – likelihood function for binomial sampling
• Observations in D are mutually independent – probability of heads is θ and tails is 1- θ
• Substitute into the previous equation...
)|(
)1()|(),|(
Dp
pDp
th

Step 3
• Average over possible values of Θ to determine probability
• Ep (θ|D,ξ)(θ) is the expectation of θ w.r.t. the distribution p(θ|D,ξ)

Prior Distribution
• The prior is taken from a beta distribution:P(θ|ξ) = Beta (θ|αh, αt)
• αh, αt are hyperparameters to distinguish from the θ parameter – sufficient statistics
• Beta prior means posterior is beta too

Assessing the prior
• Imagined future data:– Assess probability in first toss of thumbtack– Imagine you’ve seen outcomes of k flips– Reassess probability
• Equivalent samples– Start with Beta(0,0) prior, observe αh, αt heads and tails –
posterior will be Beta(αh, αt)– Beta (0,0) is state of minimum information– Assess αh, αt by determining number of observations of
heads and tails equivalent to our current knowledge

Can’t always use Beta prior
• What if you bought the thumbtack in a magic shop? It could be biased.
• Need a mixture of Betas – introduces hidden variable H

Distributions
• We’ve only been talking about binomials so far• Observations could come from any physical
probability distribution• We can still use Bayesian methods. Same as
before:– Define variables for unknown parameters– Assign priors to variables– Use Bayes’ rule to update beliefs– Average over possible values of Θ to predict things

Exponential Family
• For distributions in the exponential family – – Calculation can be done efficiently and in closed
form– E.g. Binomial, multinomial, normal, Gamma,
Poisson...

• Bernardo and Smith (1994) compiled important quantities and Bayesian computations for commonly used members of the family
• Paper focuses on multinomial sampling
Exponential Family

Multinomial sampling
• X is discrete – r possible states x1 ... xr
• Likelihood function:
• Same number of parameters as states• Parameters = physical probabilities• Sufficient statistics for D = {X1 = x1, ... XN = xN}:– {N1, ... Nr} where Ni is the number of times X = xi in
D

Multinomial Sampling
• Prior used is Dirichlet: – P(θ|ξ) = Dir(θ|α1, ..., αr)
• Posterior is Dirichlet too– P(θ|ξ) = Dir(θ|α1+N1, ..., αr+Nr)
• Can assess this same way you can Beta distribution

Bayesian Network
Network structure of BN:– Directed acyclic graph (DAG)– Each node of the graph represents a variable– Each arc asserts the dependence relationship
between the pair of variables– A probability table associating each node to its
immediate parent nodes
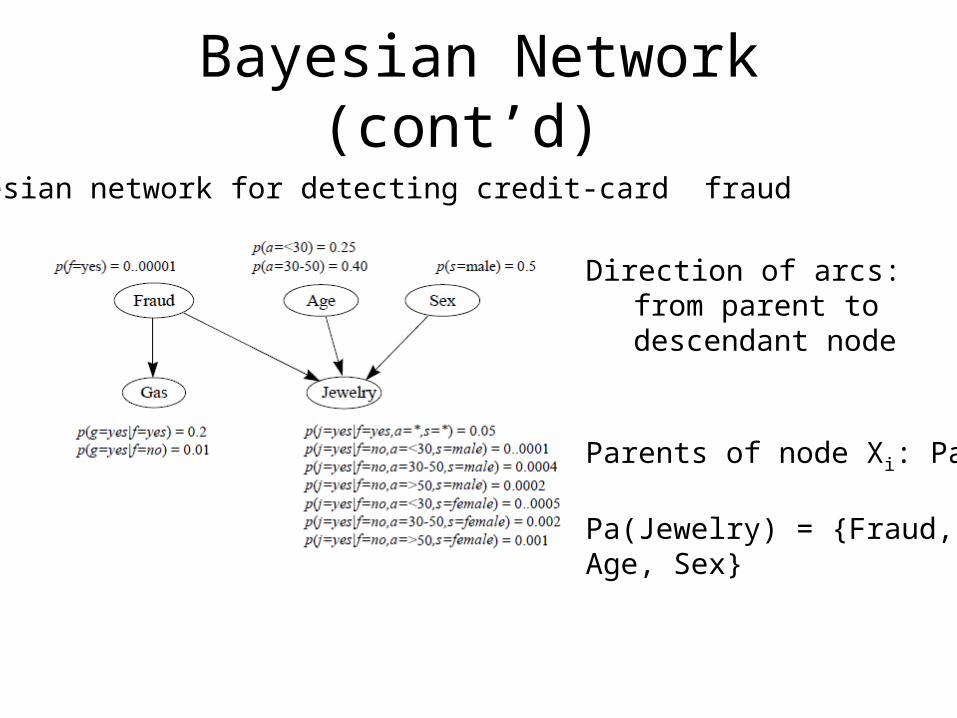
Bayesian Network (cont’d) A Bayesian network for detecting credit-card fraud
Direction of arcs:from parent to descendant node
Parents of node Xi: Pai
Pa(Jewelry) = {Fraud, Age, Sex}

Bayesian Network (cont’d)
• Network structure: S• Set of variables: • Parents of Xi : Pai
Joint distribution of X:
},...,{ 21 NXXXX
N
iiixpp
1
)|()( pax
Markov condition:ND(Xi) = nondescendent nodes of Xi
)|()),(|( iiiii xpxxp papand

Constructing BN
Given set },...,{ 21 NXXXX
N
iii xxxxpp
1121 ),...,|()(x (chain rule of prob)
Now, for every Xi: },...,{ 121 ii XXX
such that Xi and X\ i are cond. independent given i
N
iiixpp
1
)|()( x i Pai

Constructing BN (cont’d)
Using the ordering (F,A,S,G,J)
But by using the ordering (J,G,S,A,F) we obtain a fully connected structure Use some prior assumptions of the causal relationships among variables

Inference in BN The goal is to compute any probability of interest
(probabilistic inference)
Inference (even approximate) in an arbitrary BN for discrete variables is NP-hard (Cooper, 1990 / Dagum and Luby, 1993)
Most commonly used algorithms: Lauritzen & Spiegelhalter (1988), Jensen et al. (1990) and Dawid (1992)
• basic idea: transform BN to a tree – exploit mathematical Properties of that tree

Inference in BN (cont’d)

Learning in BN
• Learning the parameters from data• Learning the structure from data
Learning the parameters: known structure, data is fully observable

Learning parameters in BN
• Recall thumbtack problem:
)|(
),|()|(),|(
Dp
DppDp Step 1:
Step 2: expand p(D|θ,ξ)
Step 3: Average over possible values of Θ to determine probability

• Joint probability distribution:
Learning parameters in BN (cont’d)
N
i
hiii
hs SxpSp
1
),,|(),|( pax
hS : Hypothesis of structure Sθi : vectors of parameters for the local distributionθs : vector of {θ1 , θ2 , ..., θN }D = {X1, X2,... XN} random sample
Goal is to calculate the posterior distribution: ),|( hs SDp

Illustration with multinomial distr. :• Each X1 is discrete: values from• Local distr. is a collection of multinomial
distros, one for each config of Pai
Learning parameters in BN (cont’d)
},...,{ 21 iriii xxx
iqiii papapa ,..., 21 configurations of Pai
mutually independent

Parameter independence:
Learning parameters in BN (cont’d)
Therefore:
We can update each vector of θij independently
Assume that prior distr. of θij is
Thus, posterior distr. of θij is:
where Nijk is the number of cases in D in which kii xX and j
ii papa

To compute , we have to average over possible conf of θs :
Learning parameters in BN (cont’d)
),|( 1h
N SDXp
Using parameter independence:
we obtain:
where



![Learning Bayesian Networks: The Combination of … HECKERMAN, GEIGER AND CHICKERING where c' is another normalization constant 1/[2Bh€Hp(D,B s \ E)]. In short, the Bayesian approach](https://static.fdocuments.in/doc/165x107/5aa91c6c7f8b9a9a188c6715/learning-bayesian-networks-the-combination-of-heckerman-geiger-and-chickering.jpg)














