
CS276 Lecture 14 Crawling and web indexes. Today’s lecture Crawling Connectivity servers.

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
a tutorial on crawling tools
jianguo lu
September 25, 2014
jianguo lu September 25, 2014 1 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Outline
1 overview
2 wget
3 crawler4j
4 nutch
jianguo lu September 25, 2014 2 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
overview
type of crawlers
classify crawling according to the type of the web:
surface web crawler: obtain web pages by following hyperlinksdeep web crawlerprogrammable web apis
classify crawling according to the content:
general purpose, e.g., google. archive.focused crawlers, e.g.,
academic crawlers (google scholar)social networks (twitter, weibo)
surface web and deep web are intertwined
most large web sites provide both surface web and deep web (e.g.,google scholar, twitter)
jianguo lu September 25, 2014 3 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
overview
tools for surface web crawling
command line
wget (www get), preinstalled in ubuntu(our cs machines)curl (crawl url), OSX preinstalled
Simple crawling apis
Java: crawler4j in java: http://code.google.com/p/crawler4j/Python: scrapy: http://scrapy.org/
large scale scrawling
Heritrix, crawler for archive.org.nutch
jianguo lu September 25, 2014 4 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
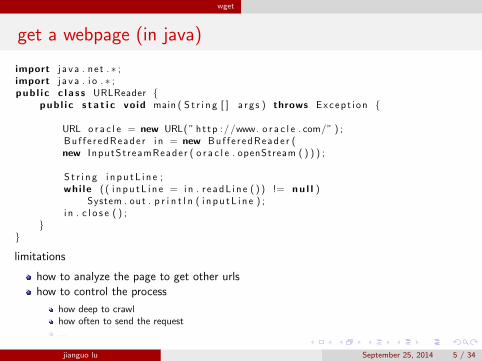
get a webpage (in java)
import j a v a . net . ∗ ;import j a v a . i o . ∗ ;pub l i c c l a s s URLReader {
pub l i c s t a t i c void main ( S t r i n g [ ] a r g s ) throws Excep t i on {
URL o r a c l e = new URL( ” ht tp ://www. o r a c l e . com/” ) ;Bu f f e r edReade r i n = new Buf f e r edReade r (new InputSt reamReader ( o r a c l e . openStream ( ) ) ) ;
S t r i n g i n p u t L i n e ;whi le ( ( i n p u t L i n e = i n . r e adL i n e ( ) ) != nu l l )
System . out . p r i n t l n ( i n p u t L i n e ) ;i n . c l o s e ( ) ;
}}
limitations
how to analyze the page to get other urlshow to control the process
how deep to crawlhow often to send the request...
jianguo lu September 25, 2014 5 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
get a webpage (in java)
import j a v a . net . ∗ ;import j a v a . i o . ∗ ;pub l i c c l a s s URLReader {
pub l i c s t a t i c void main ( S t r i n g [ ] a r g s ) throws Excep t i on {
URL o r a c l e = new URL( ” ht tp ://www. o r a c l e . com/” ) ;Bu f f e r edReade r i n = new Buf f e r edReade r (new InputSt reamReader ( o r a c l e . openStream ( ) ) ) ;
S t r i n g i n p u t L i n e ;whi le ( ( i n p u t L i n e = i n . r e adL i n e ( ) ) != nu l l )
System . out . p r i n t l n ( i n p u t L i n e ) ;i n . c l o s e ( ) ;
}}
limitations
how to analyze the page to get other urlshow to control the process
how deep to crawlhow often to send the request...
jianguo lu September 25, 2014 5 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
get a webpage (in java)
import j a v a . net . ∗ ;import j a v a . i o . ∗ ;pub l i c c l a s s URLReader {
pub l i c s t a t i c void main ( S t r i n g [ ] a r g s ) throws Excep t i on {
URL o r a c l e = new URL( ” ht tp ://www. o r a c l e . com/” ) ;Bu f f e r edReade r i n = new Buf f e r edReade r (new InputSt reamReader ( o r a c l e . openStream ( ) ) ) ;
S t r i n g i n p u t L i n e ;whi le ( ( i n p u t L i n e = i n . r e adL i n e ( ) ) != nu l l )
System . out . p r i n t l n ( i n p u t L i n e ) ;i n . c l o s e ( ) ;
}}
limitations
how to analyze the page to get other urlshow to control the process
how deep to crawlhow often to send the request...
jianguo lu September 25, 2014 5 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
get a webpage (in java)
import j a v a . net . ∗ ;import j a v a . i o . ∗ ;pub l i c c l a s s URLReader {
pub l i c s t a t i c void main ( S t r i n g [ ] a r g s ) throws Excep t i on {
URL o r a c l e = new URL( ” ht tp ://www. o r a c l e . com/” ) ;Bu f f e r edReade r i n = new Buf f e r edReade r (new InputSt reamReader ( o r a c l e . openStream ( ) ) ) ;
S t r i n g i n p u t L i n e ;whi le ( ( i n p u t L i n e = i n . r e adL i n e ( ) ) != nu l l )
System . out . p r i n t l n ( i n p u t L i n e ) ;i n . c l o s e ( ) ;
}}
limitations
how to analyze the page to get other urlshow to control the process
how deep to crawlhow often to send the request...
jianguo lu September 25, 2014 5 / 34
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
get a webpage (in java)
import j a v a . net . ∗ ;import j a v a . i o . ∗ ;pub l i c c l a s s URLReader {
pub l i c s t a t i c void main ( S t r i n g [ ] a r g s ) throws Excep t i on {
URL o r a c l e = new URL( ” ht tp ://www. o r a c l e . com/” ) ;Bu f f e r edReade r i n = new Buf f e r edReade r (new InputSt reamReader ( o r a c l e . openStream ( ) ) ) ;
S t r i n g i n p u t L i n e ;whi le ( ( i n p u t L i n e = i n . r e adL i n e ( ) ) != nu l l )
System . out . p r i n t l n ( i n p u t L i n e ) ;i n . c l o s e ( ) ;
}}
limitations
how to analyze the page to get other urlshow to control the process
how deep to crawlhow often to send the request...
jianguo lu September 25, 2014 5 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
get a webpage (in java)
import j a v a . net . ∗ ;import j a v a . i o . ∗ ;pub l i c c l a s s URLReader {
pub l i c s t a t i c void main ( S t r i n g [ ] a r g s ) throws Excep t i on {
URL o r a c l e = new URL( ” ht tp ://www. o r a c l e . com/” ) ;Bu f f e r edReade r i n = new Buf f e r edReade r (new InputSt reamReader ( o r a c l e . openStream ( ) ) ) ;
S t r i n g i n p u t L i n e ;whi le ( ( i n p u t L i n e = i n . r e adL i n e ( ) ) != nu l l )
System . out . p r i n t l n ( i n p u t L i n e ) ;i n . c l o s e ( ) ;
}}
limitations
how to analyze the page to get other urlshow to control the process
how deep to crawlhow often to send the request...
jianguo lu September 25, 2014 5 / 34
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
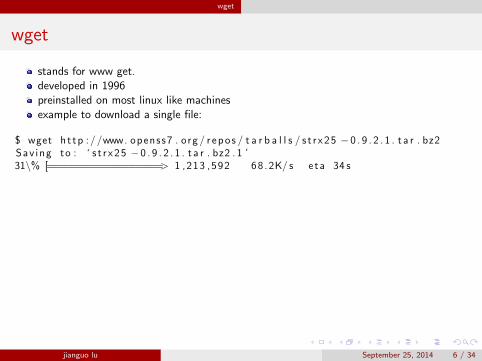
wget
stands for www get.developed in 1996preinstalled on most linux like machinesexample to download a single file:
$ wget h t tp : //www. openss7 . org / r epo s / t a r b a l l s / s t r x25 − 0 . 9 . 2 . 1 . t a r . bz2Sav ing to : ‘ s t r x25 − 0 . 9 . 2 . 1 . t a r . bz2 . 1 ’31\% [=================> 1 ,213 ,592 68 .2K/ s e ta 34 s
jianguo lu September 25, 2014 6 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
get more pages
get a single page
wget http://www.example.com/index.html
support http, ftp etc., e.g.
wget ftp://ftp.gnu.org/pub/gnu/wget/wget-latest.tar.gz
More complex usage includes automatic download of multiple URLsinto a directory hierarchy.
wget -e robots=off -r -l1 --no-parent -A.gif
ftp://www.example.com/dir/
jianguo lu September 25, 2014 7 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
Recursive retrieval using -r
program begins following links from the website and downloadingthem too.
http://activehistory.ca/papers/ has a link tohttp://activehistory.ca/papers/historypaper-9/, so it willdownload that too if we use recursive retrieval.
will also follow any other links: if there was a link to http://uwo.casomewhere on that page, it would follow that and download it as well.
By default, -r sends wget to a depth of five sites after the first one.This is following links, to a limit of five clicks after the first website.
jianguo lu September 25, 2014 8 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
not beyond last parent directory using –no-parent
The double-dash indicates the full-text of a command. All commandsalso have a short version, this could be initiated using -np.
wget should follow links, but not beyond the last parent directory.
wont go anywhere that is not part of thehttp://activehistory.ca/papers/hierarchy
jianguo lu September 25, 2014 9 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
how far you want to go
The default: follow each link and carry on to a limit of five pagesaway from the first page.
wget -l 2, which takes us to a depth of two web-pages.
Note this is a lower-case L, not a number 1.
jianguo lu September 25, 2014 10 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
politeness
-w 10
adds a ten second wait in between server requests.you can shorten this, as ten seconds is quite long.you can also use the parameter: –random-wait to let wget chose arandom number of seconds to wait.wget --random-wait -r -p -e robots=off -U mozilla
http://www.example.com
--limit-rate=20k
limit the maximum download speed to 20kb/s.Opinion varies on what a good limit rate is, but you are probably goodup to about 200kb/s
jianguo lu September 25, 2014 11 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
some sites are protective
if the robots.txt does not allow you to crawl anything
use robots=offwget -r -p -e robots=off http://www.example.com
jianguo lu September 25, 2014 12 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
mask user agent
if a web site checks a browser identity
$ wget −r −p −e −U mo z i l l a h t tp : //www. example . com
$ wget −−use r−agent=”Moz i l l a /5 .0 (X11 ; U; L inux i 686 ; en−US ; r v : 1 . 9 . 0 . 3 ) Gecko /2008092416 F i r e f o x /3 . 0 . 3 ”URL−TO−DOWNLOAD
jianguo lu September 25, 2014 13 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
Increase Total Number of Retry Attempts
By default wget retries 20 times to make the download successful.
If the internet connection has problem, you may want to increase thenumber of tries
wget –tries=75 DOWNLOAD-URL
jianguo lu September 25, 2014 14 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
Download Multiple Files / URLs Using Wget -i
First, store all the download files or URLs in a text file as:
Next, give the download-file-list.txt as argument to wget using -ioption as shown below.
$ ca t > download− f i l e − l i s t . t x tURL1URL2URL3URL4
$ wget − i download− f i l e − l i s t . t x t
jianguo lu September 25, 2014 15 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
Download Only Certain File Types Using wget -r -A
You can use this under following situations:
Download all images from a websiteDownload all videos from a websiteDownload all PDF files from a website
$ wget −r −A. pdf h t tp : // u r l−to−webpage−with−pd f s /
jianguo lu September 25, 2014 16 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
download a directory
task: download all the files under the papers directory ofActiveHistory.ca.
wget -r --no-parent -w 2 --limit-rate=20k
http://activehistory.ca/papers/
Note that the trailing slash on the URL is critical
if you omit it, wget will think that papers is a file rather than adirectory.
When it is done, you should have a directory labeled ActiveHistory.cathat contains the /papers/ sub-directory perfectly mirrored on yoursystem.
This directory will appear in the location that you ran the commandfrom in your command line
Links will be replaced with internal links to the other pages you’vedownloaded, so you can actually have a fully working ActiveHistory.casite on your computer.
jianguo lu September 25, 2014 17 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
mirror a website using -m
If you want to mirror an entire website, there is a built-in commandto wget.
This command means mirror, and is especially useful for backing upan entire website.
it looks at the time stamps, and does not repeat the download if thefile in the local system is recent.
it supports infinite recursion (it will go as many layers into the site asnecessary).
The command for mirroring ActiveHistory.ca would be:
wget -m -w 2 --limit-rate=20k http://activehistory.ca
jianguo lu September 25, 2014 18 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
wget
download in the background
$ wget −b ht tp ://www. openss7 . org / r epo s / t a r b a l l s / s t r x25 − 0 . 9 . 2 . 1 . t a r . bz2Cont i nu i ng i n background , p i d 1984 .Output w i l l be w r i t t e n to ‘ wget−l og ’ .
jianguo lu September 25, 2014 19 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
crawler4j
crawler4j
pub l i c c l a s s Ba s i c C r aw lC o n t r o l l e r {
pub l i c s t a t i c vo id main ( S t r i n g [ ] a r g s ) throws Excep t i on {S t r i n g c r aw l S t o r a g eFo l d e r = a rg s [ 0 ] ;i n t numberOfCrawlers = I n t e g e r . p a r s e I n t ( a r g s [ 1 ] ) ;C raw lCon f i g c o n f i g = new Craw lCon f i g ( ) ;c o n f i g . s e tC r aw l S t o r a g eFo l d e r ( c r aw l S t o r a g eFo l d e r ) ;c o n f i g . s e t P o l i t e n e s sD e l a y ( 1000 ) ;c o n f i g . setMaxDepthOfCrawl ing ( 2 ) ;c o n f i g . setMaxPagesToFetch ( 1000 ) ;c o n f i g . s e tResumab l eCraw l i ng ( f a l s e ) ;PageFetcher pageFe tche r = new PageFetcher ( c o n f i g ) ;Robo t s t x tCon f i g r o b o t s t x t C o n f i g = new Robo t s t x tCon f i g ( ) ;Robo t s t x t S e r v e r r o b o t s t x t S e r v e r = new Robo t s t x t S e r v e r ( r o b o t s t x tCon f i g , pageFe tche r ) ;C r aw l C o n t r o l l e r c o n t r o l l e r = new C r aw lC o n t r o l l e r ( c on f i g , pageFetcher , r o b o t s t x t S e r v e r ) ;
c o n t r o l l e r . addSeed ( ” h t tp : //www. i c s . u c i . edu/” ) ;c o n t r o l l e r . s t a r t ( Ba s i cC r aw l e r . c l a s s , numberOfCrawlers ) ;
}}
jianguo lu September 25, 2014 20 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
nutch
nutch overview
Apache Nutch is an open source Web crawler written in Java.
can find Web page hyperlinks in an automated manner, reduce lots ofmaintenance work,
for example checking broken links,
and create a copy of all the visited pages for searching over.
jianguo lu September 25, 2014 21 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
nutch
Install Nutch
Option 1: Setup Nutch from a binary distribution
Download a binary package (apache-nutch-1.X-bin.zip).Unzip your binary Nutch package. There should be a folderapache-nutch-1.X.cd apache-nutch-1.X/
$NUTCH RUNTIME HOME refers to the current directory(apache-nutch-1.X/).
jianguo lu September 25, 2014 22 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
nutch
Set up Nutch from a source distribution
Advanced users may also use the source distribution:
Download a source package (apache-nutch-1.X-src.zip)
Unzip
cd apache-nutch-1.X/
Run ant in this folder (cf. RunNutchInEclipse)
Now there is a directory runtime/local which contains a ready to useNutch installation. When the source distribution is used${NUTCH RUNTIME HOME}refers to apache-nutch-1.X/runtime/local/. Note thatconfig files should be modified inapache-nutch-1.X/runtime/local/conf/
ant clean will remove this directory (keep copies of modified config files)
jianguo lu September 25, 2014 23 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
nutch
Verify your Nutch installation
run ”bin/nutch” - You can confirm a correct installation if you seeingsimilar to the following:
Usage: nutch COMMAND where command is one of:
crawl: one-step crawler for intranets (DEPRECATED)readdb read / dump crawl dbmergedb merge crawldb-s, with optional filteringreadlinkdb read / dump link dbinject inject new urls into the databasegenerate generate new segments to fetch from crawl dbfreegen generate new segments to fetch from text filesfetch fetch a segment’s pages
jianguo lu September 25, 2014 24 / 34
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
nutch
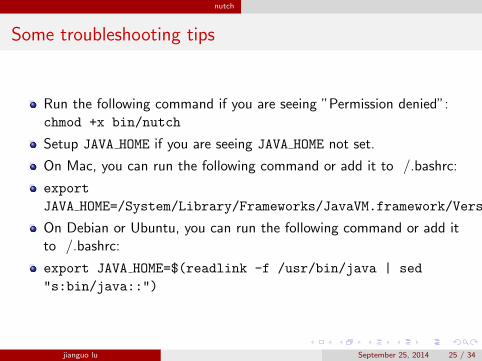
Some troubleshooting tips
Run the following command if you are seeing ”Permission denied”:chmod +x bin/nutch
Setup JAVA HOME if you are seeing JAVA HOME not set.
On Mac, you can run the following command or add it to /.bashrc:
export
JAVA HOME=/System/Library/Frameworks/JavaVM.framework/Versions/1.6/Home
On Debian or Ubuntu, you can run the following command or add itto /.bashrc:
export JAVA HOME=$(readlink -f /usr/bin/java | sed
"s:bin/java::")
jianguo lu September 25, 2014 25 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
nutch
Crawl your first website
Nutch requires two configuration changes before a website can be crawled:
Customize your crawl properties
provide a name for your crawler for external servers to recognize
Set a seed list of URLs to crawl
jianguo lu September 25, 2014 26 / 34

.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
nutch
resources
tutorial for wget. http://programminghistorian.org/lessons/automated-downloading-with-wget
Sun Yang, A COMPREHENSIVE STUDY OF THE REGULATIONAND BEHAVIOR OF WEB CRAWLERS, phd thesis, 2008.
Data Mining the Web Via Crawling, By Kate Matsudaira July 26,2012 http://cacm.acm.org/blogs/blog-cacm/
153780-data-mining-the-web-via-crawling/fulltext
How to crawl a quarter billion webpages in 40 hours by MichaelNielsen on August 10, 2012
crawl using amazon ec2 http://www.michaelnielsen.org/ddi/how-to-crawl-a-quarter-billion-webpages-in-40-hours/
Beautiful Soap, a screen scraping tool,http://www.crummy.com/software/BeautifulSoup/
jianguo lu September 25, 2014 27 / 34


















