
"A Study of I/O and Virtualization Performance with a Search Engine based on an XML database and...
45
A Study of I/O and Virtualization Performance with a Search Engine based on an XML database and Lucene Ed Bueché, EMC [email protected], May 25, 2011
-
Upload
lucidworks-archived -
Category
Technology
-
view
1.112 -
download
5
description
Documentum xPlore provides an integrated Search facility for the Documentum Content Server. The standalone search engine is based on EMC's xDB (Native XML database) and Lucene. In this talk we will introduce xPlore and some of its key components and capabilities. These include aspects of a tight integration of Lucene with the XML database: xQuery translation and optimization into Lucene query/API's as well as transactional update Lucene). In addition, xPlore is being deployed aggressively into virtualized environments (both disk I/O and VM). We cover some performance results and tuning tips in these areas.
Transcript of "A Study of I/O and Virtualization Performance with a Search Engine based on an XML database and...

A Study of I/O and Virtualization Performance with a Search Engine
based on an XML database and Lucene
Ed Bueché, EMC [email protected], May 25, 2011

Agenda
§ My Background § Documentum xPlore Context and History § Overview of Documentum xPlore § Tips and Observations on IO and Host
Virtualization
3

My Background § Ed Bueché § Information Intelligence Group within EMC § EMC Distinguished Engineer & xPlore Architect § Areas of expertise
• Content Management (especially performance & scalability)
• Database (SQL and XML) and Full text search • Previous experience: Sybase and Bell Labs
§ Part of the EMC Documentum xPlore development team • Pleasanton (CA), Grenoble (France), Shanghai,
and Rotterdam (Netherlands) 4

Documentum search 101 • Documentum Content Server provides an “object/
relational” data model and query language — Object metadata called “attributes” (sample: title, subject,
author) — Sub-types can be created with customer defined attributes — Documentum Query Language (DQL) — Example:
SELECT object_name FROM foo WHERE subject = ‘bar’ AND customer_id = ‘ID1234’
• DQL also support full text extensions — Example:
SELECT object_name FROM foo SEARCH DOCUMENT CONTAINS ‘hello world’ WHERE subject = ‘bar’ AND customer_id = ‘ID1234’

Introducing Documentum xPlore
§ Provides ‘Integrated Search’ for Documentum • but is built as a
standalone search engine to replace FAST Instream
§ Built over EMC xDB, Lucene, and leading content extraction and linguistic analysis software
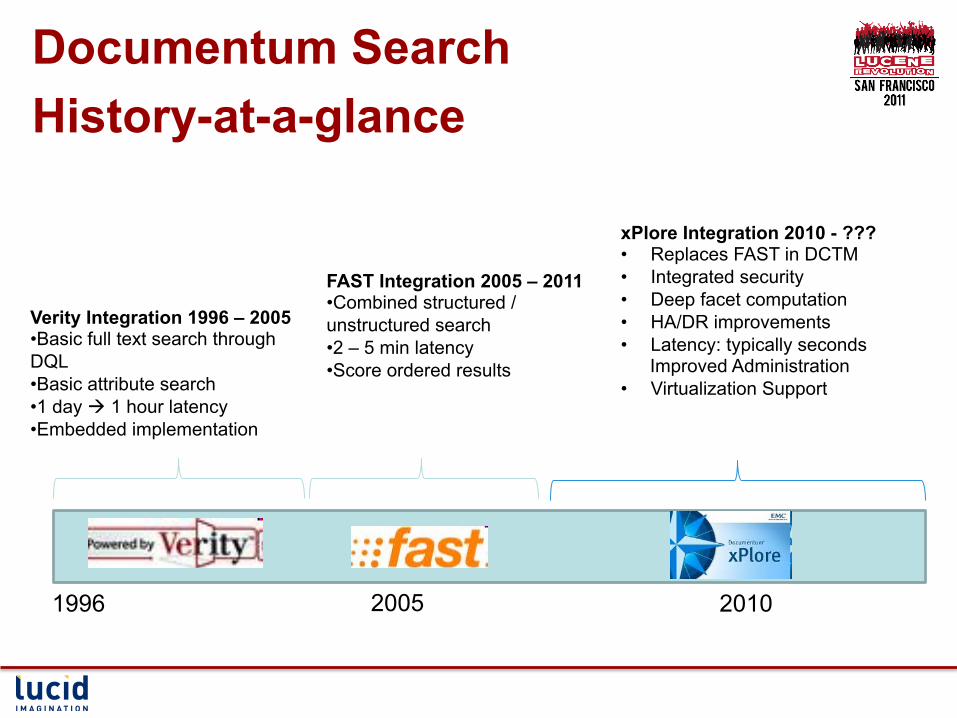
Documentum Search History-at-a-glance § almost 15 years of Structured/Unstructured integrated search
Verity Integration 1996 – 2005 • Basic full text search through DQL • Basic attribute search • 1 day à 1 hour latency • Embedded implementation
FAST Integration 2005 – 2011 • Combined structured / unstructured search • 2 – 5 min latency • Score ordered results
xPlore Integration 2010 - ??? • Replaces FAST in DCTM • Integrated security • Deep facet computation • HA/DR improvements • Latency: typically seconds
Improved Administration • Virtualization Support
1996 2010 2005
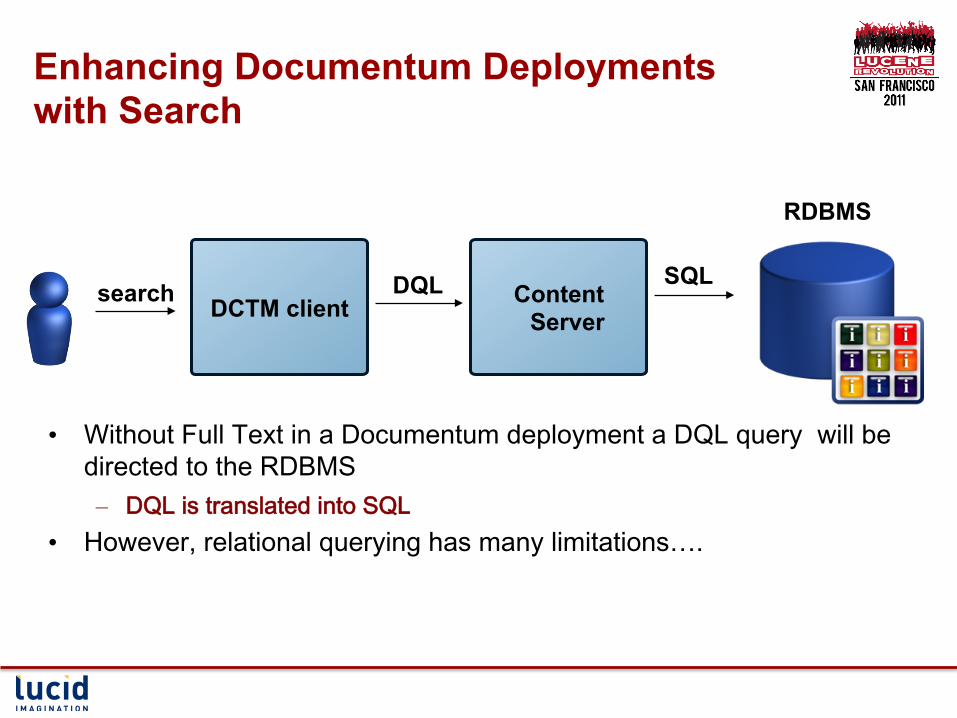
Enhancing Documentum Deployments with Search
• Without Full Text in a Documentum deployment a DQL query will be directed to the RDBMS – DQL is translated into SQL
• However, relational querying has many limitations….
Content Server DCTM client
DQL SQL
RDBMS
search
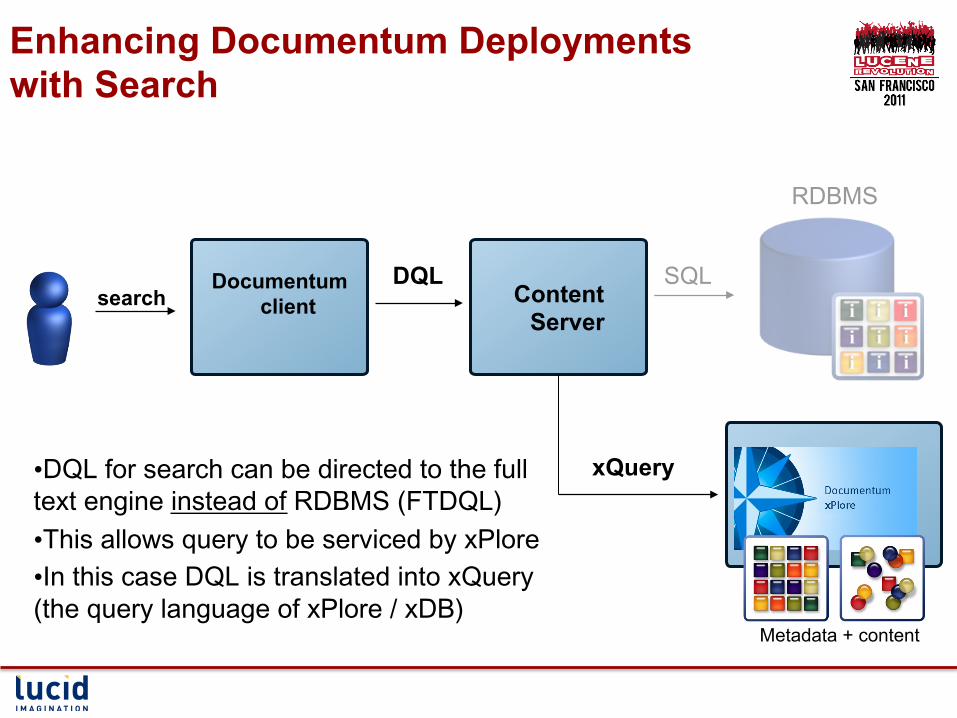
Enhancing Documentum Deployments with Search
• DQL for search can be directed to the full text engine instead of RDBMS (FTDQL) • This allows query to be serviced by xPlore • In this case DQL is translated into xQuery (the query language of xPlore / xDB)
Content Server
Documentum client
DQL SQL
xQuery
RDBMS
Metadata + content
search

Some Basic Design Concepts behind Documentum xPlore
§ Inverted Indexes are not optimized for all use-cases • B+-tree indexes can be far more efficient for
simple, low-latency/highly dynamic scenarios § De-normalization can’t efficiently solve all
problems • Update propagation problem can be deadly • Joins are a necessary part of most applications
§ Applications need fine control over not only search criteria, but also result sets
10

Design concepts (con’t) § Applications need fluid, changing metadata
schemas that can be efficiently queried • Adding metadata through joins with side-tables
can be inefficient to query § Users want the power of Information Retrieval
on their structured queries § Data Management, HA, DR shouldn’t be an
after-thought § When possible, operate within standards § Lucene is not a database. Most Lucene
applications deploy with databases.
11
Lessons Learned…
Structured Query use-cases
Unstructured Query use-cases
Fit to use-case
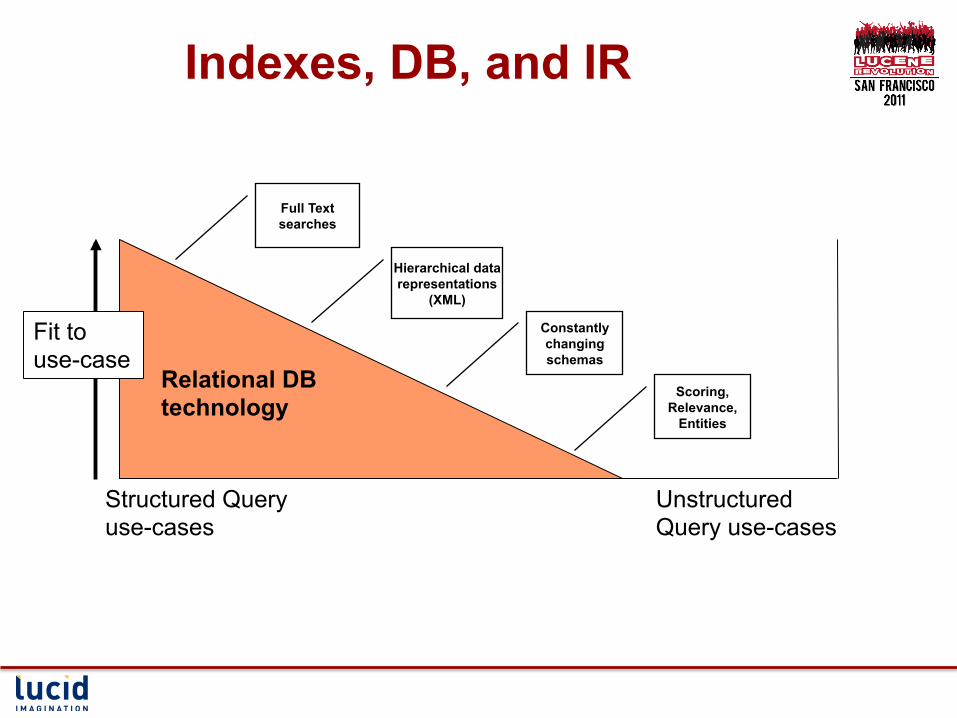
Indexes, DB, and IR
Structured Query use-cases
Unstructured Query use-cases
Relational DB technology
Fit to use-case
Scoring, Relevance,
Entities
Hierarchical data representations
(XML)
Full Text searches
Constantly changing schemas
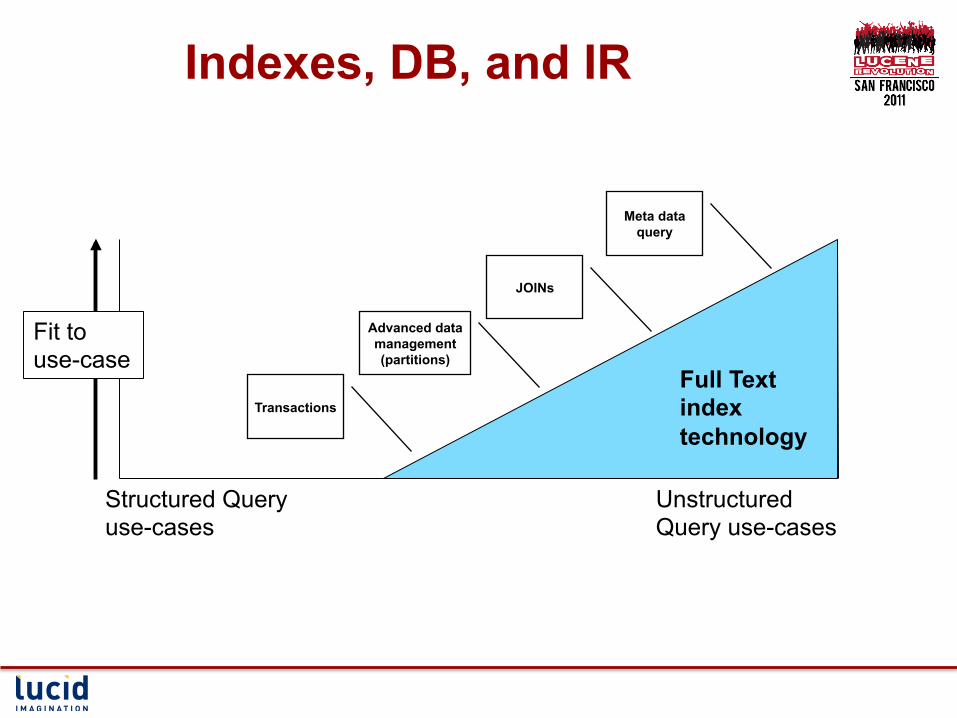
Indexes, DB, and IR
Structured Query use-cases
Unstructured Query use-cases
Fit to use-case
Full Text index technology
Meta data query
Transactions
Advanced data management (partitions)
JOINs
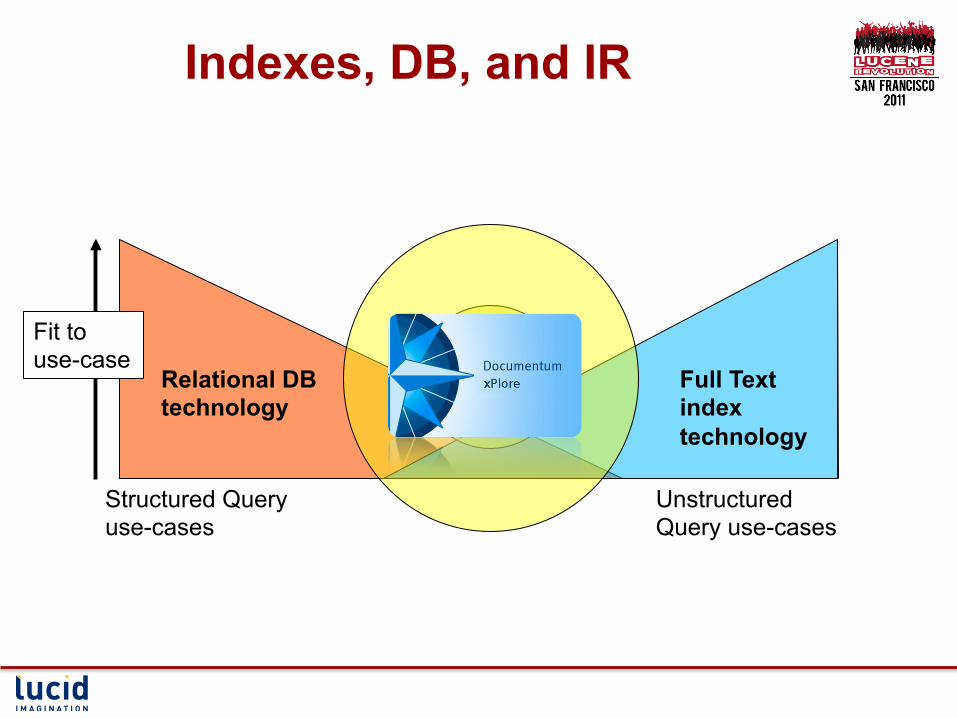
Indexes, DB, and IR
Structured Query use-cases
Unstructured Query use-cases
Relational DB technology
Fit to use-case
Full Text index technology
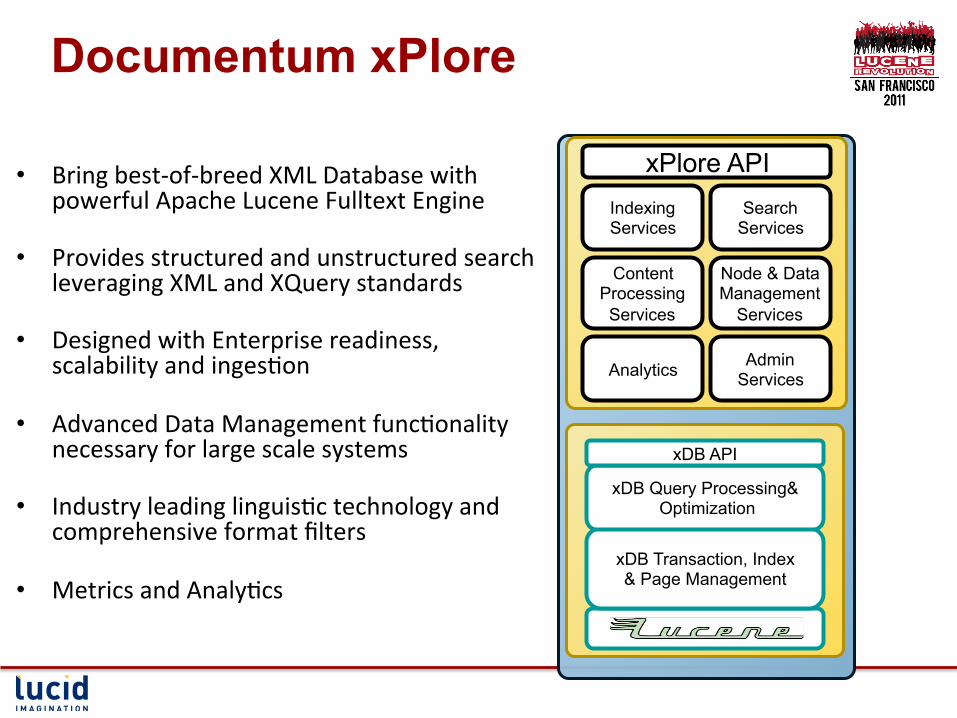
Documentum xPlore
• Bring best-‐of-‐breed XML Database with powerful Apache Lucene Fulltext Engine
• Provides structured and unstructured search leveraging XML and XQuery standards
• Designed with Enterprise readiness, scalability and ingesCon
• Advanced Data Management funcConality necessary for large scale systems
• Industry leading linguisCc technology and comprehensive format filters
• Metrics and AnalyCcs
xDB Transaction, Index & Page Management
xDB Query Processing& Optimization
xDB API
xPlore API Search
Services
Node & Data Management
Services
Indexing Services
Admin Services
Content Processing Services
Analytics

EMC xDB: Native XML database § Formerly XHive database
• 100% java • XML stored in “persistent DOM” format
§ Each XML node can be located through a 64 bit identifier § Structure mapped to pages § Easy to operate on GB XML files
• Full Transactional Database • Query Language: XQuery with full text extensions
§ Indexing & Optimization • Palette of index options optimizer can pick from • At it simplest: indexLookup(key) à node id
17
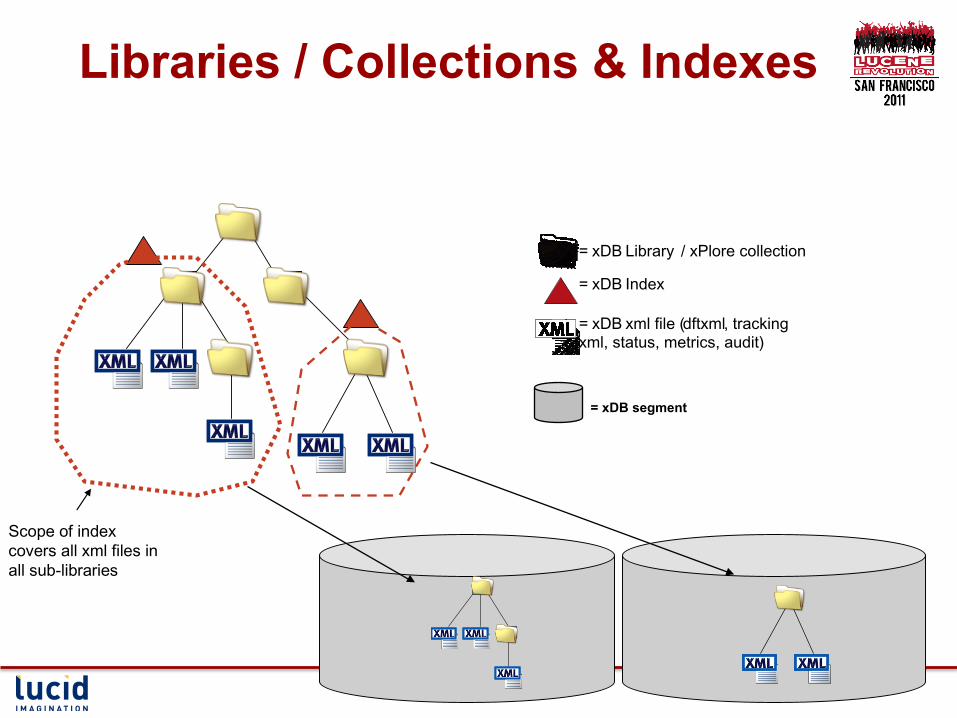
Scope of index covers all xml files in all sub-libraries
A
B C
Libraries / Collections & Indexes
A
B
C
= xDB segment
= xDB Library / xPlore collection = xDB Index = xDB xml file ( dftxml , tracking xml, status, metrics, audit)

Lucene Integration § Transactional
• Non-committed index updates in separate (typically in memory) lucene indexes
• Recently committed (but dirty) indexes backed by xDB log
• Query to “index” leverages Lucene multi-searcher with filter to apply update/delete blacklisting
§ Lucene indexes managed to fit into xDB’s ARIES-based recovery mechanism
§ No changes to Lucene • Goal: no obstacles to be as current as possible
19

Lucene Integration (con’t) § Both value and full text queries supported
• XML elements mapped to lucene fields • Tokenized and value-based fields available
§ Composite key queries supported • Lucene much more flexible than traditional B-
tree composite indexes § ACL and Facet information stored in Lucene
field array • Documentum’s security ACL security model
highly complex and potentially dynamic • Enables “secure facet” computation
20

xPlore has lucene search engine capabilities plus….
ü XQuery provides powerful query & data manipulation language • A typical search engine can’t even express a join • Creation of arbitrary structure for result set • Ability to call to language-based functions or java-
based methods ü Ability to use B-tree based indexes when needed
• xDB optimizer decides this ü Transactional update and recovery of data/index ü Hierarchical data modeling capability

Tips and Observations on IO and Host Virtualization
§ Virtualization offers huge savings for companies through consolidation and automation
§ Both Disk and Host virtualization available § However, there are pitfalls to avoid
• One-size-fits-all • Consolidation contention • Availability of resources
22

Tip #1: Don’t assume that one-size-fits all
§ Most IT shops will create “VM or SAN templates” that have a fixed resource consumption • Reduces admin costs • Example: Two CPU VM with 2 GB of memory • Deviations from this must be made in a special
request § Recommendations:
• Size correctly, don’t accept insufficient resources • Test pre-production environments
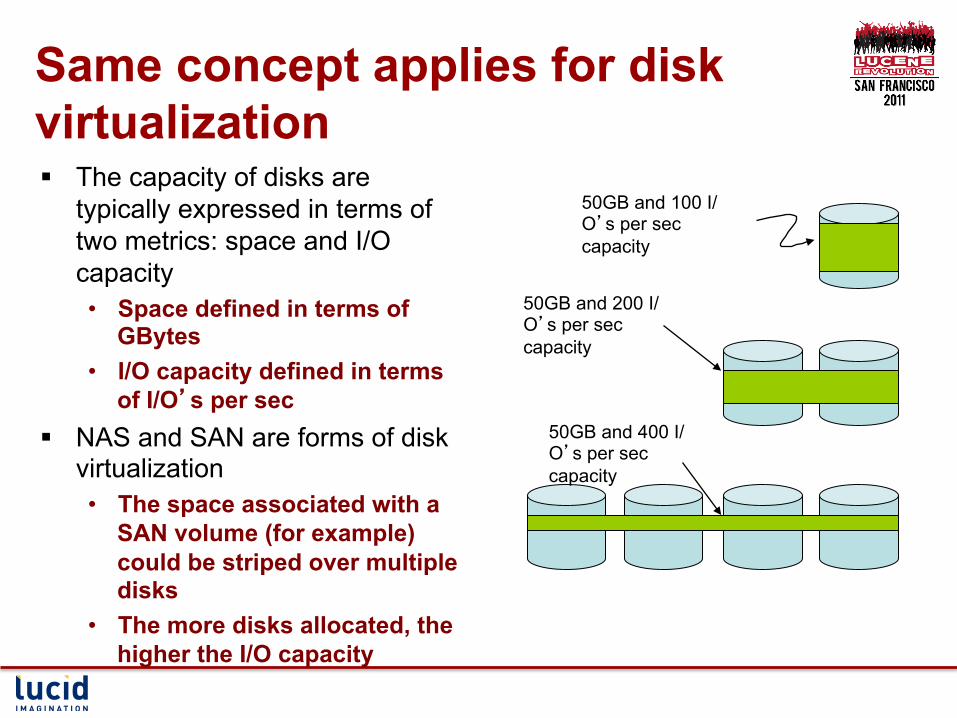
Same concept applies for disk virtualization § The capacity of disks are
typically expressed in terms of two metrics: space and I/O capacity • Space defined in terms of
GBytes • I/O capacity defined in terms
of I/O’s per sec § NAS and SAN are forms of disk
virtualization • The space associated with a
SAN volume (for example) could be striped over multiple disks
• The more disks allocated, the higher the I/O capacity
50GB and 100 I/O’s per sec capacity
50GB and 200 I/O’s per sec capacity
50GB and 400 I/O’s per sec capacity
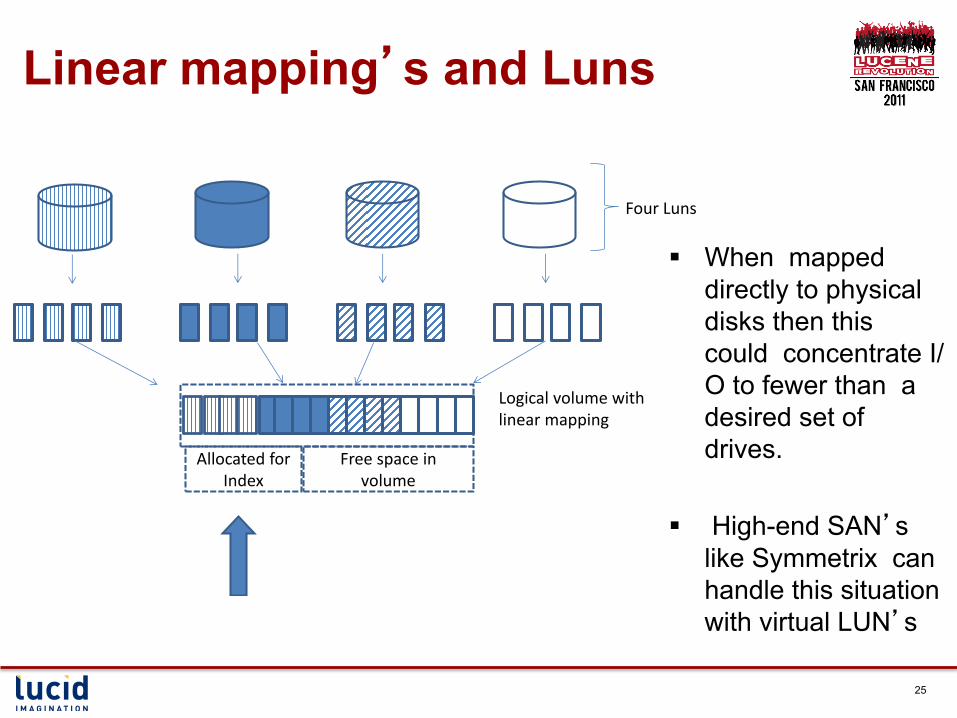
Linear mapping’s and Luns
§ When mapped directly to physical disks then this could concentrate I/O to fewer than a desired set of drives.
§ High-end SAN’s
like Symmetrix can handle this situation with virtual LUN’s
25
Allocated for Index
Logical volume with linear mapping
Four Luns
Free space in volume
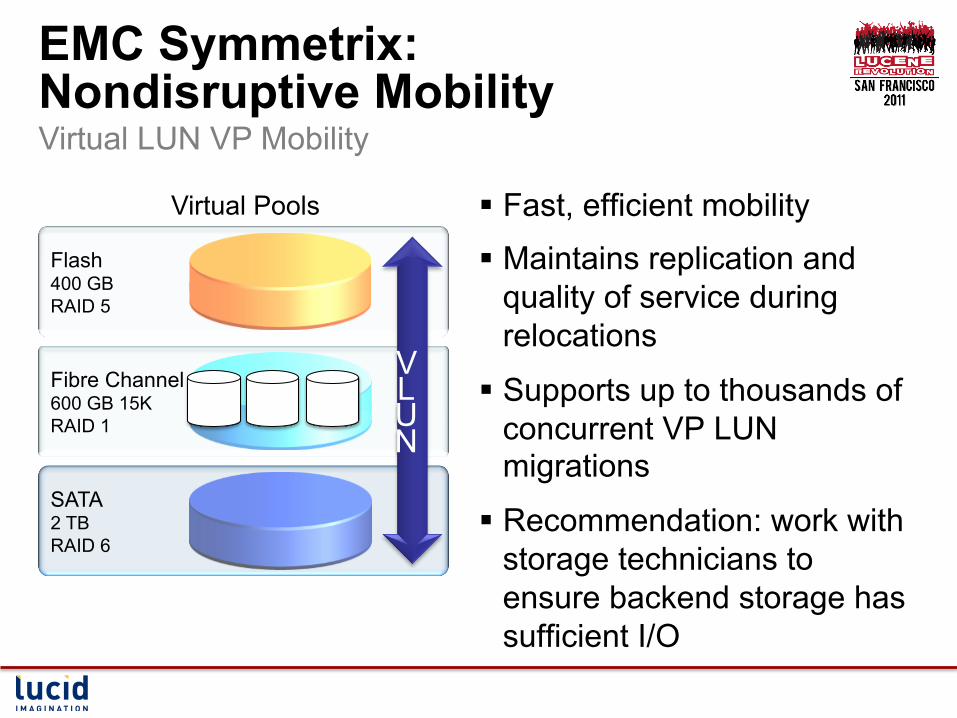
EMC Symmetrix: Nondisruptive Mobility Virtual LUN VP Mobility
§ Fast, efficient mobility
§ Maintains replication and quality of service during relocations
§ Supports up to thousands of concurrent VP LUN migrations
§ Recommendation: work with storage technicians to ensure backend storage has sufficient I/O
Virtual Pools
Flash 400 GB RAID 5
Tier 2
Fibre Channel 600 GB 15K RAID 1
SATA 2 TB RAID 6
VLUN

Tip #2: Consolidation Contention § Virtualization provides benefit from consolidation § Consolidation provides resources to the ‘active’
• Your resources can be consumed by other VM’s, other apps
• Physical resources can be over-stretched § Recommendations:
• Track actual capacity vs. planned § Vmware: track number of times your VM is denied CPU § SANs: track % I/O utilization vs. number of I/O’s
• For Vmware leverage guaranteed minimum resource allocations and/or allocate to non-overloaded HW

Some Vmware statistics § Ready metric
• Generated by Vcenter and represents the number of cycles (across all CPUs) in which VM was denied CPU
• Generated in milliseconds and “real-time” sample happens at best every 20 secs
• For interactive apps: As a percentage of offered capacity > 10% is considered worrisome
§ Pages-in, Pages-out • Can indicate over subscription of memory
28
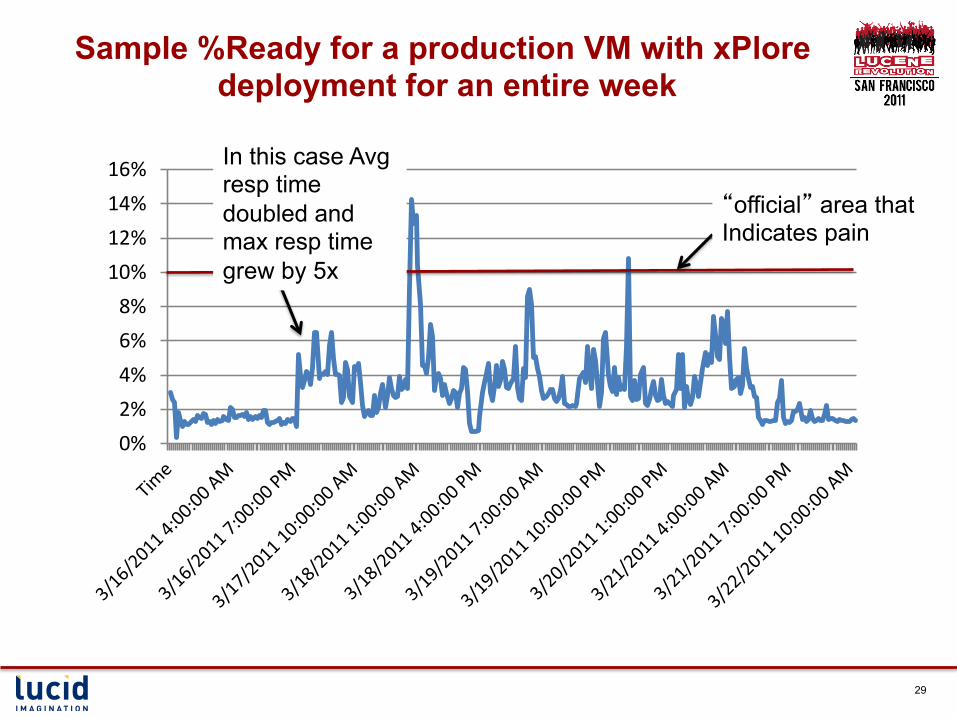
Sample %Ready for a production VM with xPlore deployment for an entire week
29
0%2%4%6%8%
10%12%14%16%
“official” area that Indicates pain
In this case Avg resp time doubled and max resp time grew by 5x
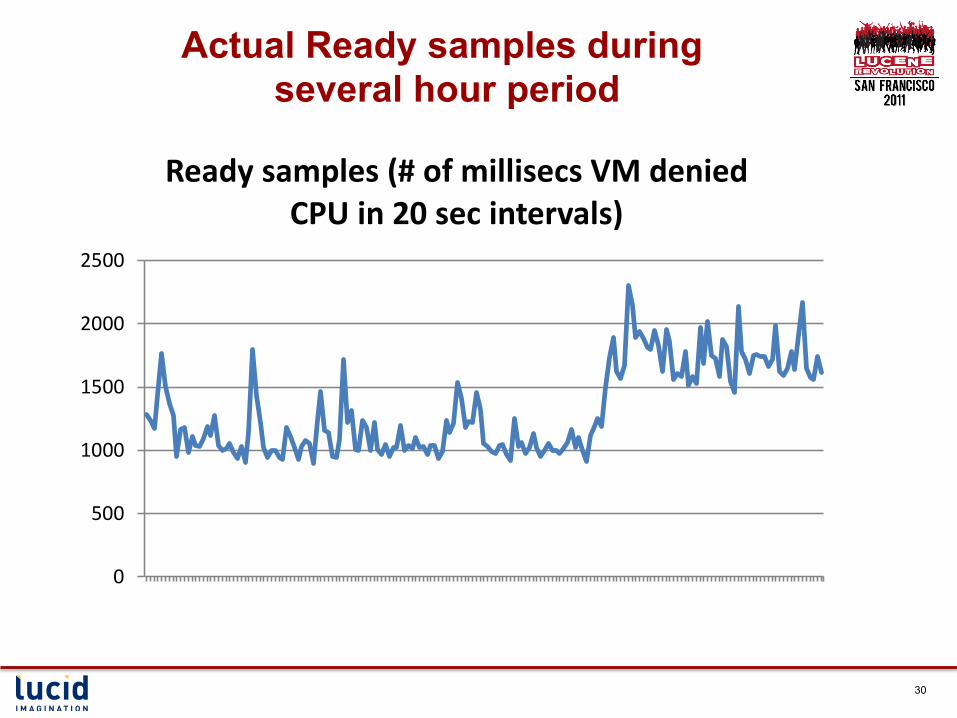
Actual Ready samples during several hour period
30
0
500
1000
1500
2000
2500
Ready samples (# of millisecs VM denied CPU in 20 sec intervals)

Some Subtleties with Interactive CPU denial
§ The Ready metric represents denial upon demand • Interactive workloads can be bursty • If no demand, then Ready counter will be low
§ Poor user response encourages less usage • Like walking on a broken leg • Causing less Ready samples
31
20 sec interval
Denial spike
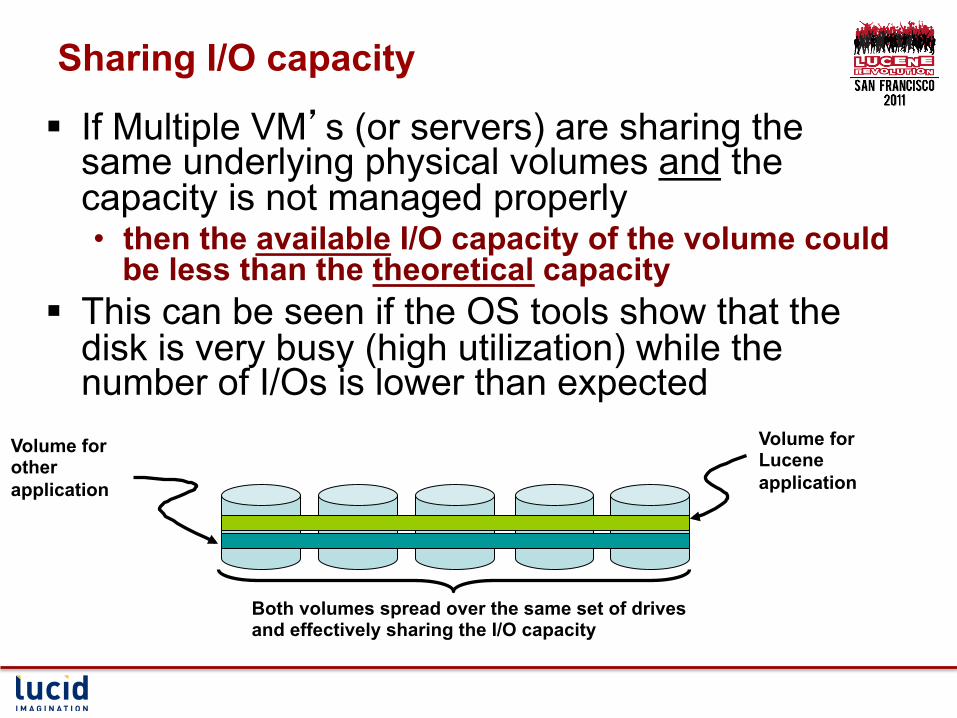
Sharing I/O capacity
§ If Multiple VM’s (or servers) are sharing the same underlying physical volumes and the capacity is not managed properly • then the available I/O capacity of the volume could
be less than the theoretical capacity § This can be seen if the OS tools show that the
disk is very busy (high utilization) while the number of I/Os is lower than expected
Volume for Lucene application
Volume for other application
Both volumes spread over the same set of drives and effectively sharing the I/O capacity

Recommendations on diagnosing disk I/O related issues § On Linux/UNIX
• Have IT group install SAR and IOSTAT § Also install a disk I/O testing tool (like ‘Bonnie’)
• Compare ‘Bonnie’ output with SAR & IOSTAT data § High disk Utilization at much lower achieved rates could
indicate contention from other applications • Also, High SAR I/O wait time might be an
indication of slow disks § On Windows
• Leverage the Windows Performance Monitor • Objects: Processor, Physical Disk, Memory

Sample output from the Bonnie tool
¹ Bonnie is an open source disk I/O driver tool for Linux that can be useful for pretesting Linux disk environments prior to an xPlore/Lucene install.
bonnie -s 1024 -y -u -o_direct -v 10 -p 10 This will increase the size of the file to 2 Gb. Examine the output. Focus on the random I/O area: ---Sequential Output (sync)----- ---Sequential Input-- --Rnd Seek- -CharUnlk- -DIOBlock- -DRewrite- -CharUnlk- -DIOBlock- --04k (10)- Machine MB K/sec %CPU K/sec %CPU K/sec %CPU K/sec %CPU K/sec %CPU /sec %CPU Mach2 10*2024 73928 97 104142 5.3 26246 2.9 8872 22.5 43794 1.9 735.7 15.2
-s 1024 means that 2 GB files will be created
-o_direct means that direct I/O (by-passing buffer cache) will be done
-v 10 means that 10 different 2GB files will be created.
-p 10 means that 10 different threads will query those files
This output means that the random read test saw 735 random I/O’s per sec at 15% CPU busy
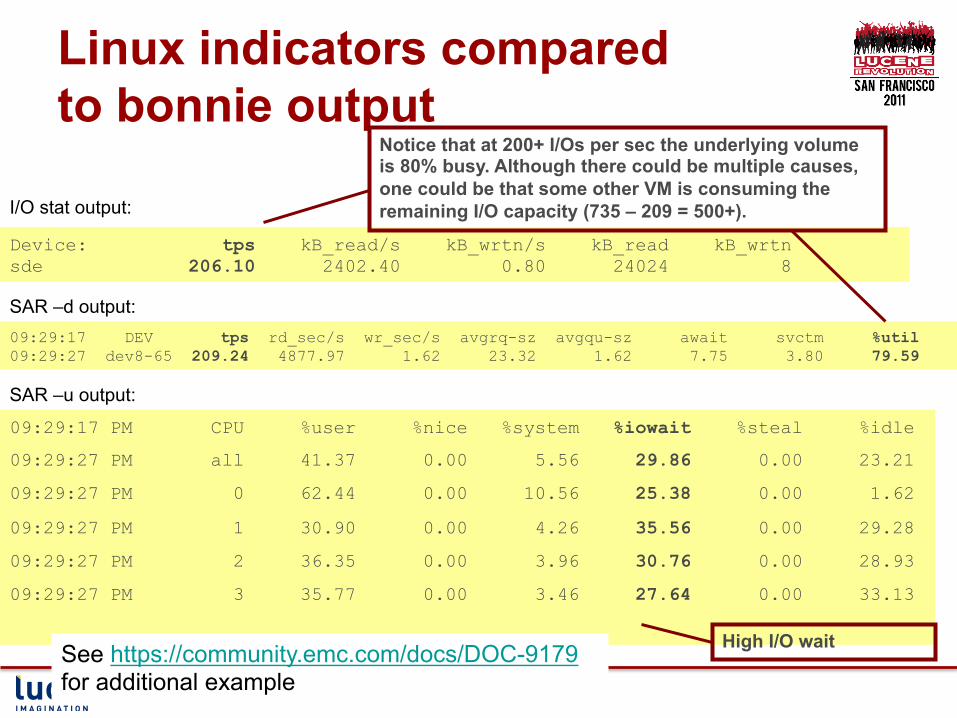
Linux indicators compared to bonnie output
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn sde 206.10 2402.40 0.80 24024 8
09:29:17 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 09:29:27 dev8-65 209.24 4877.97 1.62 23.32 1.62 7.75 3.80 79.59
09:29:17 PM CPU %user %nice %system %iowait %steal %idle
09:29:27 PM all 41.37 0.00 5.56 29.86 0.00 23.21
09:29:27 PM 0 62.44 0.00 10.56 25.38 0.00 1.62
09:29:27 PM 1 30.90 0.00 4.26 35.56 0.00 29.28
09:29:27 PM 2 36.35 0.00 3.96 30.76 0.00 28.93
09:29:27 PM 3 35.77 0.00 3.46 27.64 0.00 33.13
I/O stat output:
SAR –d output:
SAR –u output:
Notice that at 200+ I/Os per sec the underlying volume is 80% busy. Although there could be multiple causes, one could be that some other VM is consuming the remaining I/O capacity (735 – 209 = 500+).
High I/O wait See https://community.emc.com/docs/DOC-9179 for additional example

Tip #3: Try to ensure availability of resources § Similar to the previous issue,
but • resource displacement not
caused by overload, • Inactivity can cause Lucene
resources to be displaced • Not different from running on
large shared native OS host § Recommendation:
• Periodic warmup § non-intrusive
• See next example

IO / caching test use-case § Unselective Term search
• 100 sample queries • Avg( hits per term) = 4,300+, max ~ 60,000 • Searching over 100’s of DCTM object attributes + content
§ Medium result window • Avg( results returned per query) = 350 (max: 800)
§ Stored Fields Utilized • Some security & facet info
§ Goal: • Pre-cache portions of the index to improve response time in
scenarios • Reboot, buffer cache contention, & vm memory contention
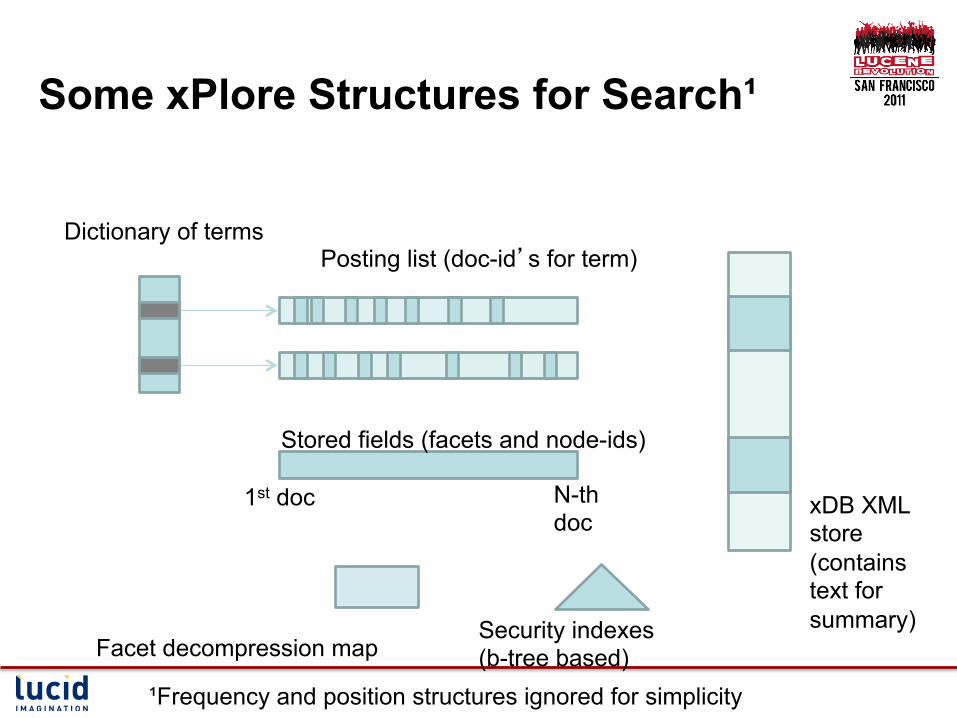
Some xPlore Structures for Search¹
Dictionary of terms Posting list (doc-id’s for term)
Stored fields (facets and node-ids)
Security indexes (b-tree based)
xDB XML store (contains text for summary)
1st doc N-th doc
Facet decompression map
¹Frequency and position structures ignored for simplicity
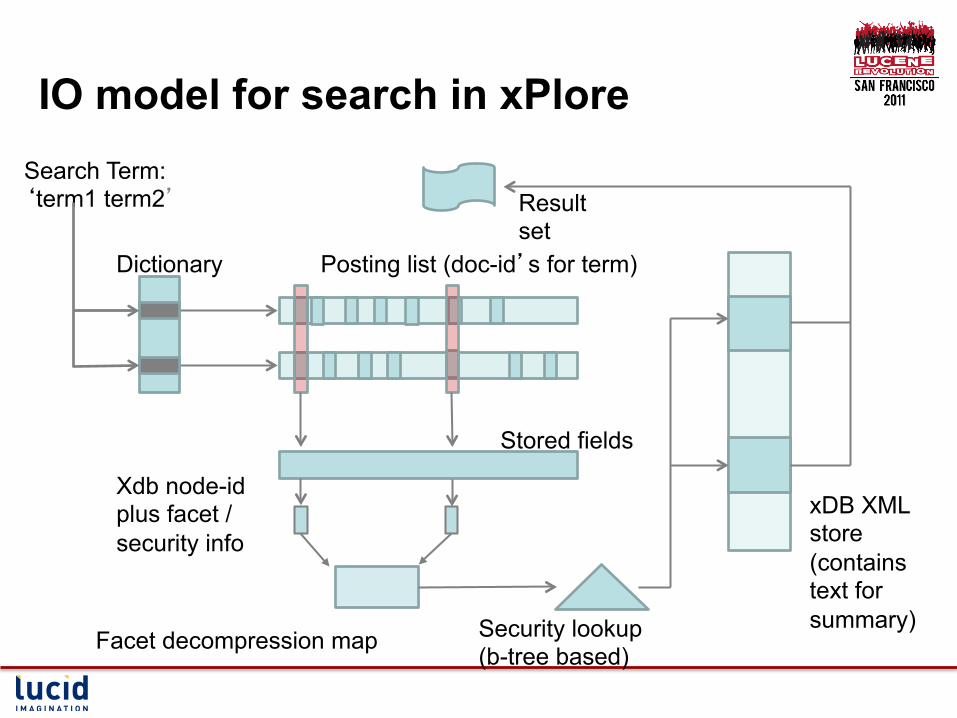
IO model for search in xPlore Search Term: ‘term1 term2’
Dictionary Posting list (doc-id’s for term)
Stored fields
Xdb node-id plus facet / security info
Security lookup (b-tree based)
xDB XML store (contains text for summary)
Result set
Facet decompression map
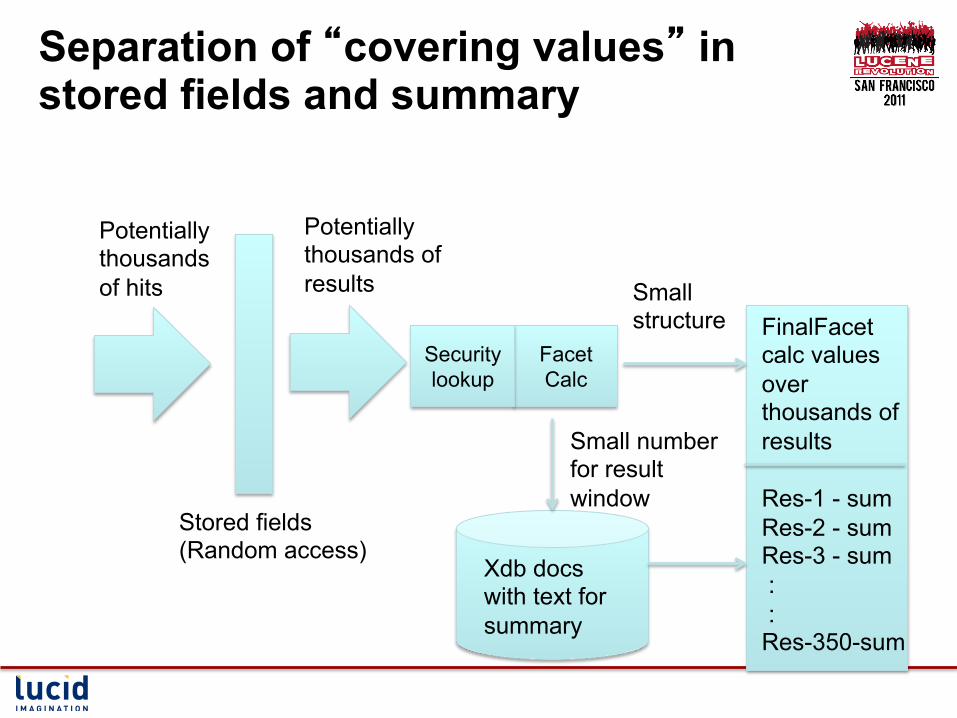
Separation of “covering values” in stored fields and summary
Facet Calc
FinalFacet calc values over thousands of results Res-1 - sum Res-2 - sum Res-3 - sum : : Res-350-sum
Xdb docs with text for summary
Small number for result window
Small structure
Potentially thousands of results
Stored fields (Random access)
Potentially thousands of hits
Security lookup
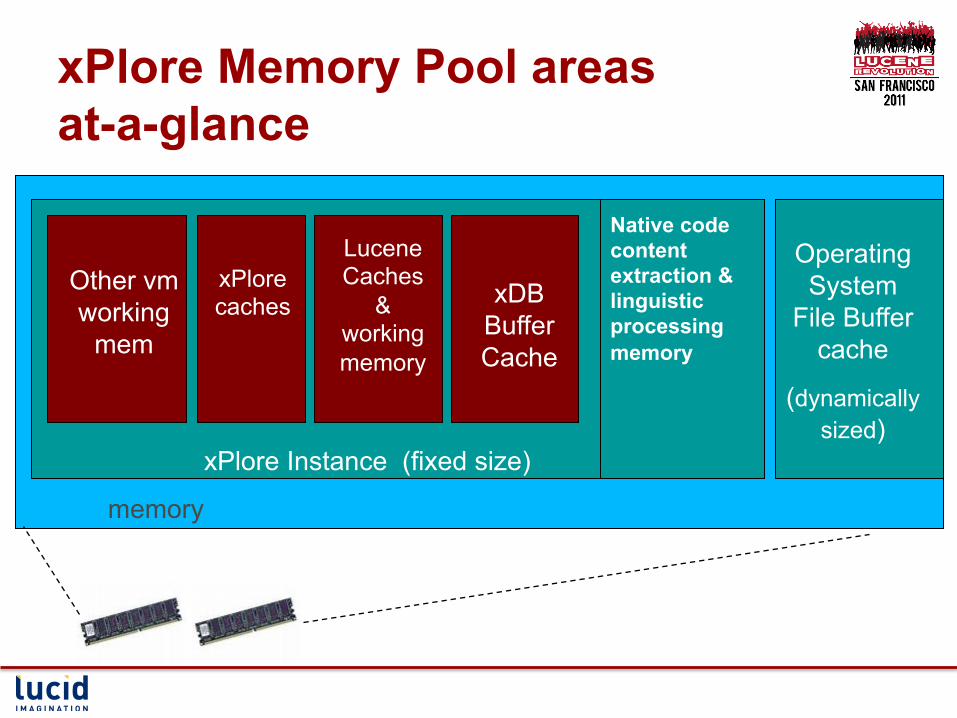
xPlore Memory Pool areas at-a-glance
xPlore Instance (fixed size)
memory
xDB Buffer Cache
Lucene Caches
& working memory
xPlore caches
Other vm working
mem
Operating System
File Buffer cache
(dynamically sized)
Native code content extraction & linguistic processing memory
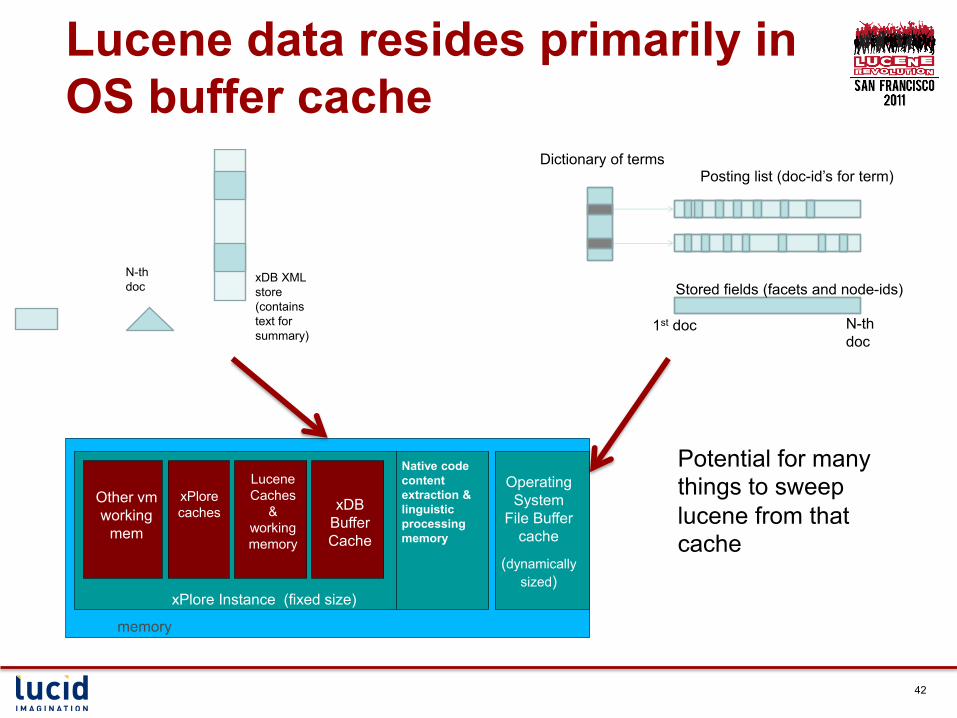
Lucene data resides primarily in OS buffer cache
42
xPlore Instance (fixed size)
memory
xDB Buffer Cache
LuceneCaches
& working memory
xPlorecaches
Other vmworking
mem
Operating System
File Buffer cache
(dynamically sized)
Native code content extraction & linguistic processing memory
Dictionary of termsPosting list (doc-id’s for term)
Stored fields (facets and node-ids)
1st doc N-th doc
xDB XML store (contains text for summary)
N-th doc
Potential for many things to sweep lucene from that cache

Test Env § 32 GB memory § Direct attached storage (no SAN) § 1.4 million documents § Lucene index size = 10 GB § Size of internal parts of Lucene CFS file
• Stored fields (fdt, fdx): 230 MB (2% of index) • Term Dictionary (tis,tii): 537 MB (5% of index) • Positions (prx): 8.78 GB (80% of index) • Frequencies (frq) : 1.4 GB (13 % of index)
§ Text in xDB stored compressed separately
43
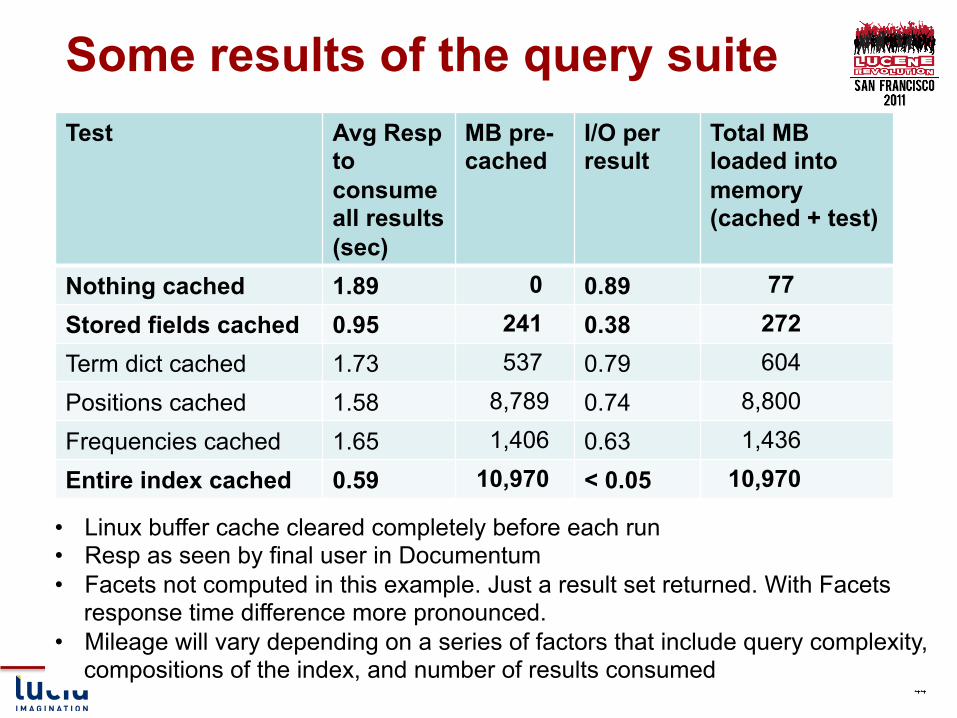
Some results of the query suite Test Avg Resp
to consume all results (sec)
MB pre-cached
I/O per result
Total MB loaded into memory (cached + test)
Nothing cached 1.89 0 0.89 77 Stored fields cached 0.95 241 0.38 272 Term dict cached 1.73 537 0.79 604
Positions cached 1.58 8,789 0.74 8,800
Frequencies cached 1.65 1,406 0.63 1,436
Entire index cached 0.59 10,970 < 0.05 10,970
44
• Linux buffer cache cleared completely before each run • Resp as seen by final user in Documentum • Facets not computed in this example. Just a result set returned. With Facets
response time difference more pronounced. • Mileage will vary depending on a series of factors that include query complexity,
compositions of the index, and number of results consumed

Other Notes § Caching 2% of index yields a response time
that is only 60% greater than if the entire index was cached. • Caching cost only 9 secs on a mirrored drive pair • Caching cost 6800 large sequential I/O’s vs.
potentially 58,000 random I/O’s § Mileage will vary, factors include
• Phrase search • Wildcard search • Multi-term search
§ SAN’s can grow I/O capacity as search complexity increases
45

Contact § Ed Bueché
• [email protected] • http://community.emc.com/people/Ed_Bueche/blog • http://community.emc.com/docs/DOC-8945
46


















