
A seminar course for the Natural Sciences
33
Information Storage and Processing in Biological Systems: A seminar course for the Natural Sciences Sept. 11 Biological Information, Sept 16 DNA, Gene regulation Sept 18 Translation and Proteins Sept 23 Enzymes and Signal transduction Sept 25 Biochemical Networks Sept 30 Simple Genetic Networks (Dr. Jacob) Oct 2
Transcript of A seminar course for the Natural Sciences

Information Storage and Processing in Biological Systems:
A seminar course for the Natural Sciences
Sept. 11 Biological Information, Sept 16 DNA, Gene regulation
Sept 18 Translation and Proteins
Sept 23 Enzymes and Signal transduction
Sept 25 Biochemical Networks
Sept 30 Simple Genetic Networks (Dr. Jacob)
Oct 2

Background
ÿ The Thread of Life. Susan Aldridge. Chapter 2
ÿ Molecular Biology of the Cell. Alberts et al. Garland Press
Suggested further reading
• Protein molecules as computational elements in living cells. D. Bray.Nature. 1995 Jul 27;376(6538):307-12.
• Signaling complexes: biophysical constraints on intracellularcommunication. D. Bray. Annu Rev Biophys Biomol Struct. 1998;27:59-75.
• Metabolic modeling of microbial strains in silico. Ms W. Covert, et al.Trends in Biochemical Sciences Vol.26 ( 2001). 179-186.
• Modelling cellular behaviour. D. Endy & R. Brent. Nature(2001) 409: 391-395.

A - Introduction to Proteins / Translation
• The primary structure is defined as the sequence of amino acids in theprotein. This is determined by and is co-linear to the sequence of bases(triplet codons) in the gene*.
5’---CTCAGCGTTACCAT---3’3’---GAGTCGCAATGGTA---5’
5’---CUCAGCGUUACCAU---3’
N---Leu-Ser-Val-Thr---C
DNA
RNA
PROTEIN
transcription
translation
* - this is not strictly true in most eukaryotic genomes

Structure of Genes In Eukaryotic Organisms
hnRNAheterogeneous nuclear RNA
RNA splicing
Transcription
mRNA

hnRNAheterogeneous nuclear RNA
RNA splicing
Transcription
mRNA
Introns
Structure of Genes In Eukaryotic Organisms
Exons

Structure of Genes In Eukaryotic Organisms
hnRNAheterogeneous nuclear RNA
RNA splicing
Transcription
mRNA
mRNA
AlternativeRNA splicing

Structure of Genes In Eukaryotic Organisms
hnRNAheterogeneous nuclear RNA
RNA splicing
Transcription
mRNA
Control Elements

Structure of Genes In Eukaryotic Organisms
• Coding sequence can be discontinuous and the gene can be composed ofmany introns and exons.
• The control regions (= operators) can be spread over a large region ofDNA and exert action-at-a-distance.
• There can be many different regulators acting on a single gene – i.e. moresignal integration than in bacteria.
• Alternate splicing can give rise to more than one protein product from asingle ‘gene’.
• Predicting genes (introns, exons and proper splicing) is very challenging.
• Because the control elements can be spread over a large segment of DNA,predicting the important sites and their effects on gene expression are notvery feasible at this time.
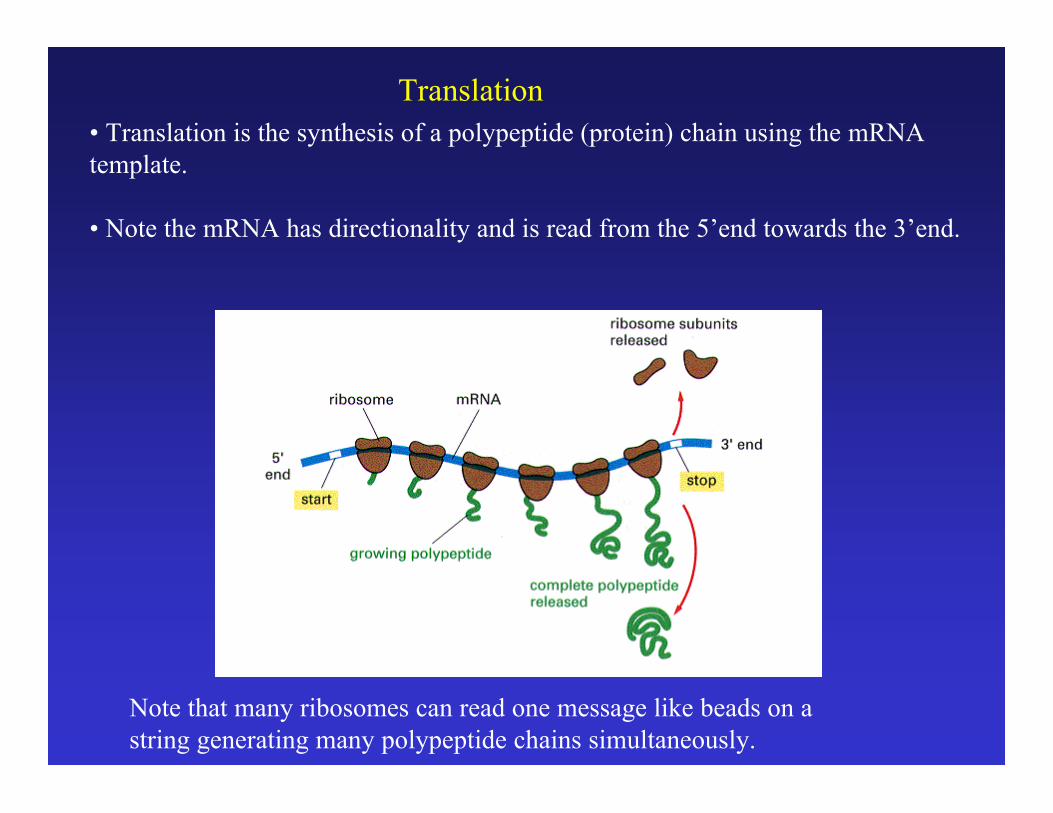
Translation
Note that many ribosomes can read one message like beads on astring generating many polypeptide chains simultaneously.
• Translation is the synthesis of a polypeptide (protein) chain using the mRNAtemplate.
• Note the mRNA has directionality and is read from the 5’end towards the 3’end.
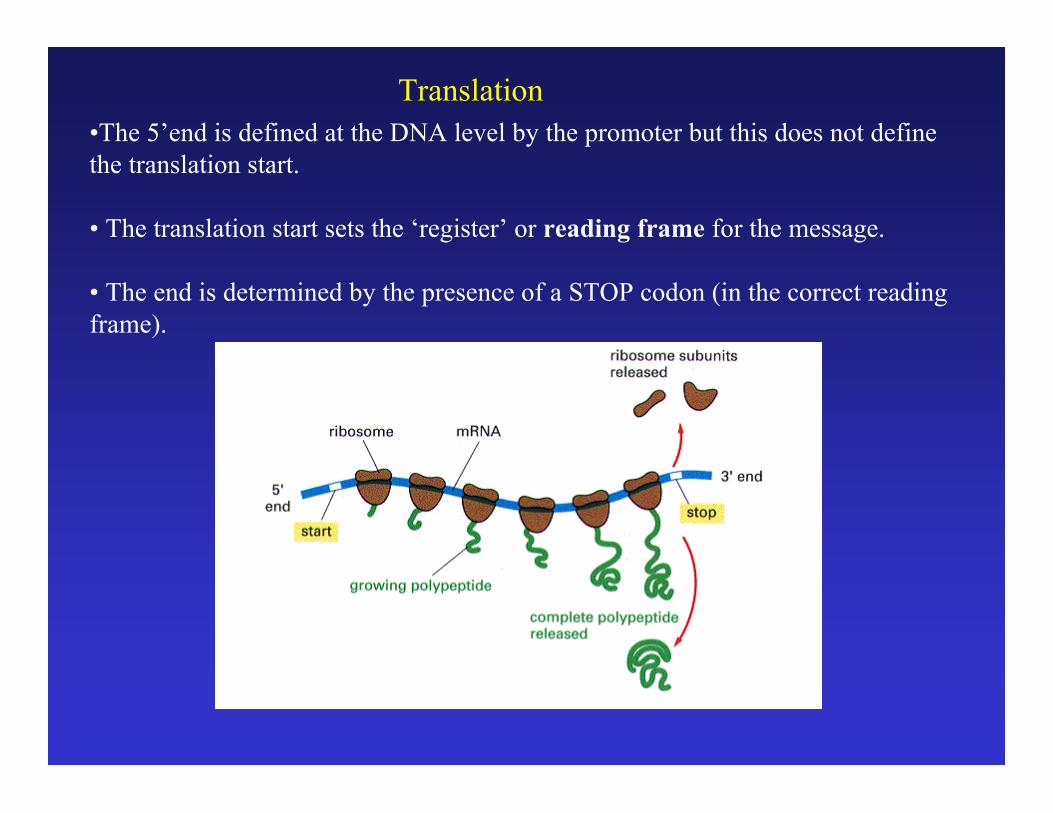
Translation•The 5’end is defined at the DNA level by the promoter but this does not definethe translation start.
• The translation start sets the ‘register’ or reading frame for the message.
• The end is determined by the presence of a STOP codon (in the correct readingframe).

Schematic Illustration of Translation
Protein Synthesis involves specialized RNA molecules called transfer RNAor tRNA.

The translation start is dependent on:1) a sequence motif called a ribosome binding site (rbs)2) an AUG start codon 5-10 bp downstream from the rbs
Translation Start Position
3’end of 16S rRNA
3’AU //-5’ UCCUCA |||||| 5’-NNNNNNNAGGAGU-N5-10-AUG-//-3’
mRNA rbs start

In bacteria a single mRNA molecule can code for several proteins. Suchmessages are said to be polycistronic. Since the message for all genes insuch a transcript are present at the same concentration (they are on the samemolecule), one might predict that translation levels will be the same for all thegenes. This is not the case: translation efficiency can vary for the differentmessages within a transcript.
Gene 1 Gene 2 Gene 3 Gene 4
Promoter(Start)
Terminator(Stop)
mRNA
DNA
4 genes , 1 message

Polycistronic mRNA
Tar Tap R B Y Z 5000 1000 <100 1000 18000 10000
(Protein monomer per cell)
Translation Efficiency is an important part of gene expression
A single mRNA may encode several proteins. The final level of eachprotein may vary significantly and is a function of:1) translation efficiency2) protein stability
Translation

B – Introduction to Proteins / Characteristics
• The primary structure is defined as the sequence of amino acids in theprotein. This is determined by and is co-linear to the sequence of bases(triplet codons) in the gene*.
5’---CTCAGCGTTACCAT---3’3’---GAGTCGCAATGGTA---5’
5’---CUCAGCGUUACCAU---3’
N---Leu-Ser-Val-Thr---C
DNA
RNA
PROTEIN
transcription
translation
* - this is not strictly true in most eukaryotic genomes

H2NCHCCH3OHO
amino group carboxylic acid
amino acid(alanine)
There are 20 naturally occurring amino acids in proteins, each withdistinctive ‘side chains’ that give them characteristic chemical properties.

H2NCHCCH3OHO
amino group carboxylic acid
amino acid(alanine)
There are 20 naturally occurring amino acids in proteins, each withdistinctive ‘side chains’ that give them characteristic chemical properties.
a-carbon
Amino acids differ in the side chains on the a-carbon.

H2NCHCCH3OHO
amino group carboxylic acid
amino acid(alanine)
There are 20 naturally occurring amino acids in proteins, each withdistinctive ‘side chains’ that give them characteristic chemical properties.
a-carbon
Amino acids differ in the side chains on the a-carbon.
-CH3 (methyl)

H2NCHCCH2OHOHN
H2NCHCCH3OHO
CHCCH2OHOHNH2NCHCCH3HNO
H2O
+
peptide bond
Alanine + Tyrptophan(ala) + (trp)(A) + (W)
Dipeptide(Ala-Trp)
By convention polypeptides arewritten from the N-terminus (amino)to the C-terminus (carboxy)

Alanine ala AArginine arg RAsparagine asn NAspartic acid asp DCysteine cys CGlutamine gln QGlutamic acid glu EGlycine gly GHistidine his HIsoleucine ile ILeucine leu LLysine lys KMethionine met MPhenylalanine phe FProline pro PSerine ser SThreonine thr TTryptophan trp WTyrosine tyr YValine val V
H2NCHCHOHO
HNCOHO
H2NCHCCH2OHOSH
Glycine
Proline
Cysteine

The Newly Synthesized Polypeptide
• The information from DNA‡RNA‡Protein is linear and the finalpolypeptide synthesized will have a sequence of amino acids defined bythe sequence of codons in the message.
• The sequence of amino acids is called the primary structure.
• Secondary structure refers to local regular/repeating structural elements.
• The folded three dimensional structure is referred to as tertiary structure.
Protein function depends on an ordered / defined threedimensional folding. The final three dimensional folded state of the proteinis an intrinsic property of the primary sequence. How the primarysequence defines the final folded conformation is generally referred to asthe Protein Folding Problem.

Primary structure of green fluorescent protein
(single letter AA codes)
SEQUENCE 238AA
26886MW
MSKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTLKFICTTGKLPVPWPTLVTTFSYGVQCFSRYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYIMADKQKNGIKVNFKIRHNIEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITHGMDELYK
The primary sequence can be derived directly from the gene sequence butgoing from sequence to structure or sequence to function is not possibleunless there is a related protein for which structure or function is known.Likewise, the structure alone rarely provides information about function(only if the function of a related protein is known).

Projections of the Tertiary Structure of Green Fluorescent Protein
Backbone tracing

Projections of the Tertiary Structure of Green Fluorescent Protein
Backbone tracing
Ile188-Gly189-Asp190-Gly191-Pro192-Val193

Projections of the Tertiary Structure of Green Fluorescent Protein
“Ribbon diagram” showingsecondary structures

Projections of the Tertiary Structure of Green Fluorescent Protein
“Ribbon diagram” showingsecondary structures
Secondary structures
a-helix

Projections of the Tertiary Structure of Green Fluorescent Protein
“Ribbon diagram” showingsecondary structures
Secondary structures
a-helix b-strand

Projections of the Tertiary Structure of Green Fluorescent Protein
“Wireframe” model showingall atoms and chemical bonds.
Ile188-Gly189-Asp190-Gly191-Pro192-Val193

Projections of the Tertiary Structure of Green Fluorescent Protein
“Stick” model showing allatoms and chemical bonds.
“Space filling” model where each atomis represented as a sphere of its Vander Waals radius.

MSKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTLKFICTTGKLPVPWPTLVTTFSYGVQCFSRYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYIMADKQKNGIKVNFKIRHNIEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITHGMDELY
Random Coil“Denatured”“Unfolded”
“Native”“Folded”
“folding”
“denaturation”
The final folded three dimensional (tertiary) structure is anintrinsic property of the primary structure.
Primary structure Tertiary Structure
In general, proteins are unstable outside of the celland very sensitive for solvent conditions.

Active site - the region of a protein (enzyme) to which a substrate moleculebinds.• The active site is formed by the three dimensional folding of the peptidebackbone and amino acid side chains. (lock and key / induced fit)• The active site is highly specific in binding interactions (stereochemicalspecificity).
The three dimensional structure of CAP and the cAMP ligand-binding site(Figures 3-45 and 3-55 from Alberts)

Proteins can undergo changes in their three dimensional structure inresponse to changing conditions or interactions with other molecules.This usually alters the ‘activity’ of the protein.
Conformational Change in Protein Structure

Proteins can undergo changes in their three dimensional structure inresponse to changing conditions or interactions with other molecules.This usually alters the ‘activity’ of the protein.
Conformational Change in Protein Structure
Binding of the substrate (glucose) cause the protein (hexokinase)to shift from an open to closed conformation. (Fig. 5-2, Alberts)
















![2009 Natural and Agricultural Sciences] Part 1] Natural Sciences] … · 2016. 10. 21. · Faculty of Natural and Agricultural Sciences Year Book 2009 Part 1: Natural Sciences: Undergraduate](https://static.fdocuments.in/doc/165x107/60d6e037894e3569c43ddd1e/2009-natural-and-agricultural-sciences-part-1-natural-sciences-2016-10-21.jpg)

