
A Robust Framework for Real- Time Distributed Processing of Satellite Data Yongsheng Zhao, Shahram...
31
A Robust Framework for Real-Time Distributed Processing of Satellite Data Yongsheng Zhao, Shahram Tehranian, Viktor Zubko, Anand Swaroop AC Technologies, Inc. Advanced Computation and Information Services 4640 Forbes Blvd. Suite 320 Lanham, MD 20706 Keith Mckenzie National Environmental Satellite Data Information Service (NESDIS) National Oceanic and Atmospheric Administration (NOAA) U.S. Department of Commerce Suitland, MD 20746
-
Upload
joseph-hoover -
Category
Documents
-
view
217 -
download
0
Transcript of A Robust Framework for Real- Time Distributed Processing of Satellite Data Yongsheng Zhao, Shahram...

A Robust Framework for Real-Time Distributed Processing of Satellite Data Yongsheng Zhao, Shahram Tehranian, Viktor Zubko, Anand Swaroop
AC Technologies, Inc.Advanced Computation and Information Services4640 Forbes Blvd. Suite 320Lanham, MD 20706
Keith Mckenzie National Environmental Satellite Data Information Service (NESDIS)National Oceanic and Atmospheric Administration (NOAA)U.S. Department of CommerceSuitland, MD 20746

Agenda
Introduction Linux Clusters GIFTS Data Processing Framework Architectural Design Implementations GIFTS Science Algorithm Pipeline Results Conclusion and Future Work

Introduction
Geosynchronous Imaging Fourier Transform Spectrometer (GIFTS) Large area Focal Plane Array (LFPA)
Each frame covers 512km X 512km at ground level Fourier Transform Spectrometer (FTS)
Provides high spectral resolution of 0.6 cm-1, yielding vertical resolutions of approx. 1 km at nadir to 3 km near the edge of LFPA
Retrieves 16,384 sounding observations per frame scanned in 11 seconds
Two detector arrays to cover LW (68 – 1130 cm-1) and SMW (1650-2250 cm-1)
Anticipated GIFTS Level-0 data rate is 1.5 Terabytes per day

Introduction (2)
Satellite ground data processing will require considerable computing power to process data in real time
Cluster technologies employing a multi-processor system present the current economically viable option
A fault-tolerant real time data processing framework is proposed to provide a platform for encapsulating science algorithms for satellite data processing on Linux Clusters

Linux Clusters
Cost effective, performance to price ratio is much better than traditional parallel computers.
Consists of Commercial of the Shelf (COTS) products. Components may easily be replaced.
Runs a free software operating system such as Linux.
Can be customized to customer’s specific applications.

Linux Clusters (2)
Linux cluster from Linux Networx 18 dual AMD Opteron
desktop 240 1 GB DDR SDRAM per
CPU 120/40.8 GB hard drives SUSE Linux Enterprise
Server for AMD64 Myrinet and Gigabit
Ethernet connections

Linux Clusters (3)
Linux cluster capabilities: Performance Scalability High availability, Server failover support Comprehensive system monitoring
Track system health, predict computing trends, avoid computing bottlenecks.
Workload management Manage multiple users and applications - allowing for the efficient use of
system resources. Version controlled system image management
Send a system image from the host node to the rest of the cluster system. Allow system administrators to track upgrades and changes to the system
image. Fall back on older, known working version when necessary. Add or update system images within minutes regardless of number of
nodes.
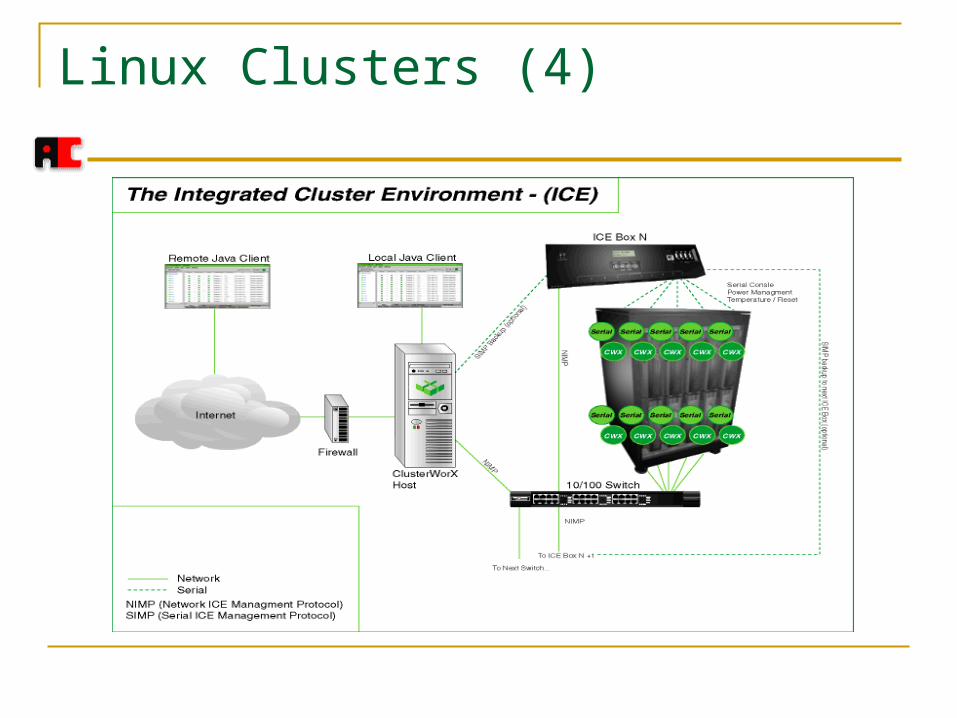
Linux Clusters (4)

GIFTS Data Processing Framework Provide an operational platform within which
algorithm software pipelines can be deployed for Level-0 (un-calibrated interferograms) to Level-1 (calibrated radiances) data processing.
Hide the complexities involved with an operational cluster environment.
Separate the science algorithm layer from the cluster management layer.
Provide FAULT TOLERANCE.

Architectural Design
Provide task scheduling through a master process. Divide a job into parallel tasks. Assign tasks to worker processes. Retrieve algorithm specific parameters from a
database server. Retrieve data sets corresponding to tasks from a
data input server. Retrieve solutions corresponding to tasks on a
data output server. Provide fault tolerance for all crucial components
within the system.
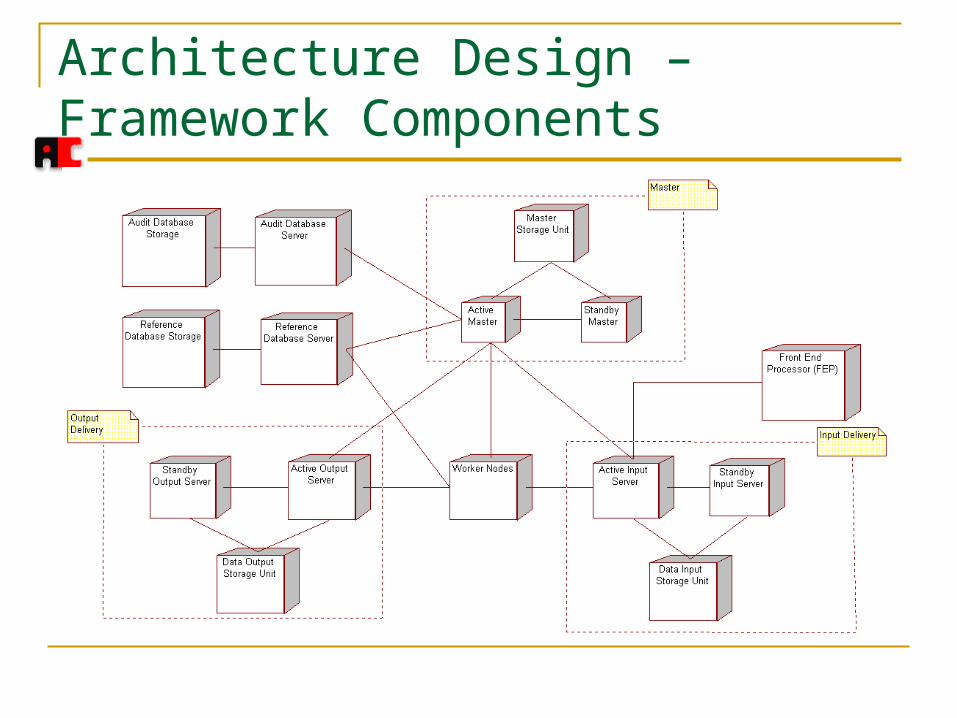
Architecture Design – Framework Components

Architecture Design – Framework Components (2) Master
Responsible for task scheduling and migration Frond End Processor (FEP)
Receives raw data from downlink and provides input bit stream data to input delivery service
Input delivery service Provides data packages to workers as requested
Output delivery service Takes processed data and packages them for an archival
and distribution system

Architecture Design – Framework Components (3) Reference database
Provides and maintains version control of data structures needed by the algorithm software
Audit database Records which algorithms were used, for purpose
of verification and reconstruction Workers
Individual processes residing on separate CPUs, performing actual software algorithm computation

Architecture Design – Task Scheduling A task is referred to as a unit of work which
contains its own set of data, initialization parameters, reference id, time stamp and so forth.
Master defines task scheduling polices: May use FIFO (First In, First Out) scheduling
Master assigns tasks to workers without any knowledge of their execution of previous tasks
May use selective (Knowledge-based) scheduling Master assigns tasks to workers based on workers’
execution of previous tasks.

Architecture Design – Task Scheduling (2)
/ worker : Worker
/ activeOutput : ActiveOutput
/ fep : FEP
/ activeInput : ActiveInput
/ activeMaster : ActiveMaster
1: New Data1: New Data
2: New Task Identifier2: New Task Identifier
1: Request Task Identifier1: Request Task Identifier
2: Recieve Task Identifier2: Recieve Task Identifier
3: Request Task Data3: Request Task Data
4: Receive Task Data4: Receive Task Data
5: Compute Task5: Compute Task
6: Send Task Output6: Send Task Output
7: Task Completed7: Task Completed
8: Confirm Task Completion8: Confirm Task Completion

Architecture Design – System Reliability Active/standby redundancy for all servers
1:1 redundancy, a hot-standby unit is monitoring the active unit
Active unit saves its state in a checkpoint file In case of failure of active unit, standby unit takes over,
reading the last checkpoint file, and recreating server state Load sharing redundancy for workers
All worker units are active, carry work load in equal distributions
No standby unit In case a worker unit fails, the remaining units take over its
work load

GIFTS Data Processing Framework Implementation Implemented in ACE (Adaptive Communication Environment)
and C++ programming language. Current version contains source code for Master, Input, Output,
Worker and Reference Database servers, respectively. Provides algorithm independence through a set of base classes. Workers may be added and removed during run time. Works with Gigabit Ethernet and Myrinet. Provides easy server configuration.
hosts.conf misc.conf
Provides a complete set of APIs doc\html\index.html

GIFTS Data Processing Framework Implementation (2)– Server Failover High availability and server failover
Active/Standby servers Mirror file systems in real-time from active to standby system. Requires identical hardware
Performs checkpointing using BOOST Serialization Library in C++
Provides both XML and binary format Server starts from last checkpoint file

GIFTS Data Processing Framework Implementation (3) – Worker Failover and
Task Migration Master detects failed tasks, re-schedules them to
other workers Two queues are maintained for ‘new tasks’ and ‘assigned
tasks’ Task execution time is dynamically estimated based on
previous actual task execution times and an over-estimation factor
Tasks which are not completed within the estimated execution time are considered lost and will be re-scheduled
Master moves a lost task from the ‘assigned task’ queue to the head of ‘new task’ queue, so that it can be re-assigned to another worker
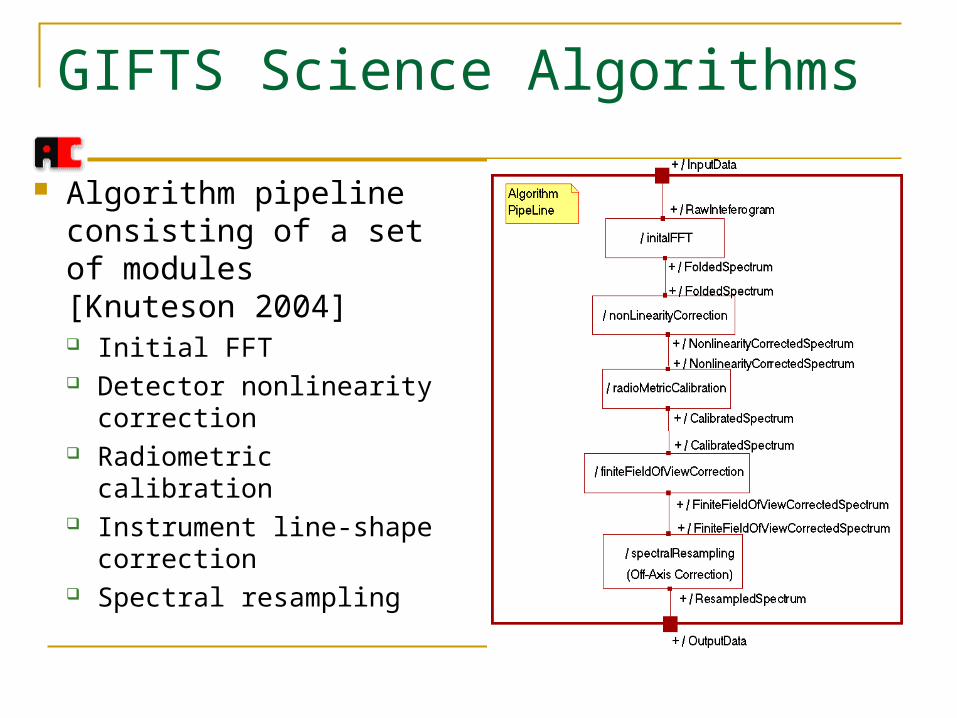
GIFTS Science Algorithms
Algorithm pipeline consisting of a set of modules [Knuteson 2004] Initial FFT Detector nonlinearity
correction Radiometric calibration Instrument line-shape
correction Spectral resampling

Results
Investigate the capability of the framework in terms of performance and reliability Performance
Benchmarking of Spectral resampling algorithms – the most time consuming algorithm module in the algorithm pipeline
Benchmarking of initial algorithm pipeline Reliability
Test of worker fail-over Test of master server fail-over

Results – Performance
Benchmarking of resampling algorithms DFFT (Double Fast Fourier Transform) resampling
algorithm Resampling algorithm with matrix convolution
With matrix cache: Several tasks use the same matrix Assign worker/workers to one or more resampling matrices.
Workers calculate each matrix locally and store it in a hash map for reuse
Master assigns tasks with the same matrix to corresponding worker/workers (Selective scheduling)
Without matrix cache (FIFO scheduling)
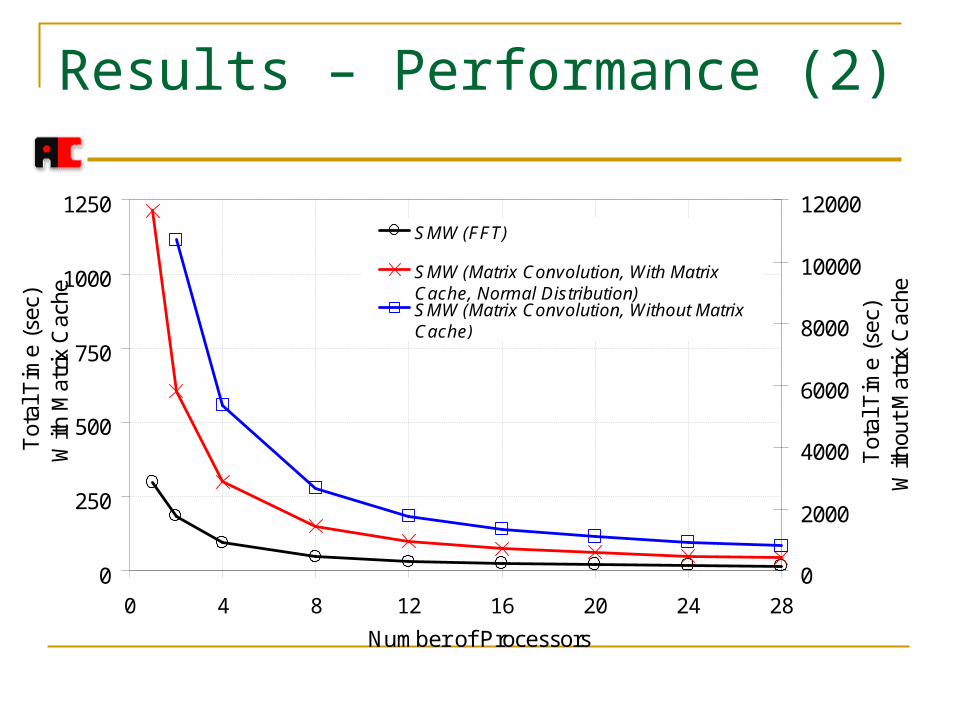
Results – Performance (2)
0
250
500
750
1000
1250
0 4 8 12 16 20 24 28
Number of Processors
Tot
al T
ime
(sec
)
With
Mat
rix C
ache
0
2000
4000
6000
8000
10000
12000
Tot
al T
ime
(sec
)W
ithou
t M
atrix
Cac
he
SMW (FFT)
SMW (Matrix Convolution, With MatrixCache, Normal Distribution)SMW (Matrix Convolution, Without MatrixCache)

Results – Performance (3)
0
4
8
12
16
20
24
28
0 4 8 12 16 20 24 28
Number of Processors
Spe
edup
SMW (FFT)
SMW (Matrix Convolution, With MatrixCache, Normal Distribution)
SMW (Matrix Convolution, Without MatrixCache)
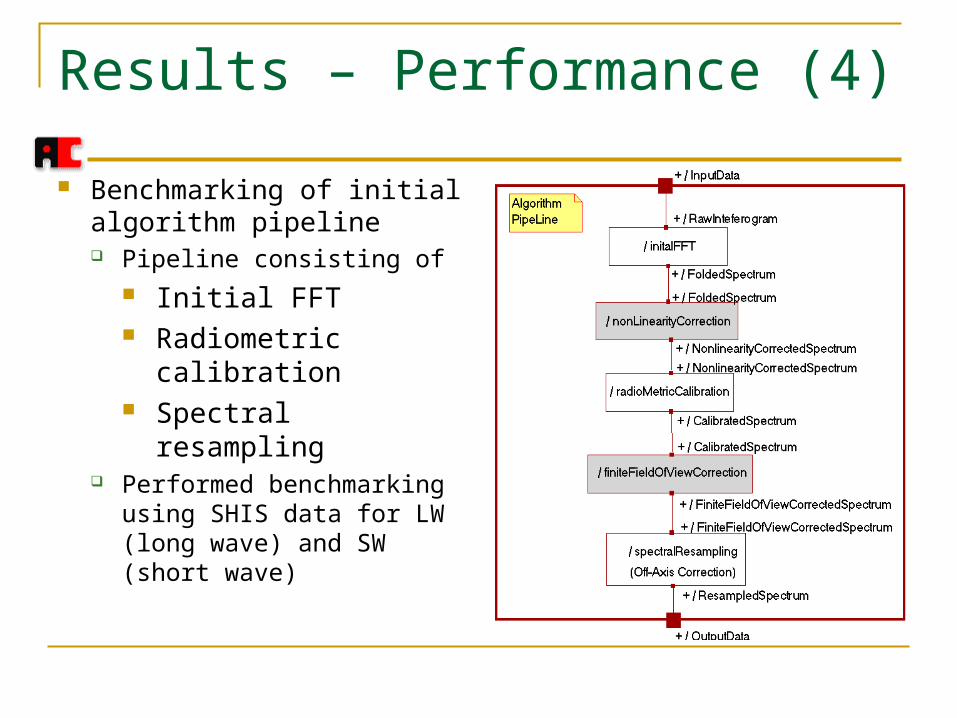
Results – Performance (4)
Benchmarking of initial algorithm pipeline Pipeline consisting of
Initial FFT Radiometric
calibration Spectral resampling
Performed benchmarking using SHIS data for LW (long wave) and SW (short wave)

Results – Performance (5)
Total Time of Initial Algorithm Pipeline
0
50
100
150
200
250
300
350
0 4 8 12 16 20 24 28
Number of Processors
Tot
al T
ime
(sec
ond)
SW
LW
Speedup of Initial Algorithm Pipeline
0
5
10
15
20
25
0 4 8 12 16 20 24 28
Number of Processors
Spe
edup
LW
SW

Results – System Reliability
Test of worker fail-over A task may not complete for various reasons such
as network or worker node failure Worker failure is introduced by the application to
simulate real time network or worker node failure Make half of the worker processes fail in a
random sequence with exponential distribution Task completion is monitored and performance
benchmarking is performed Test is repeated 100 times
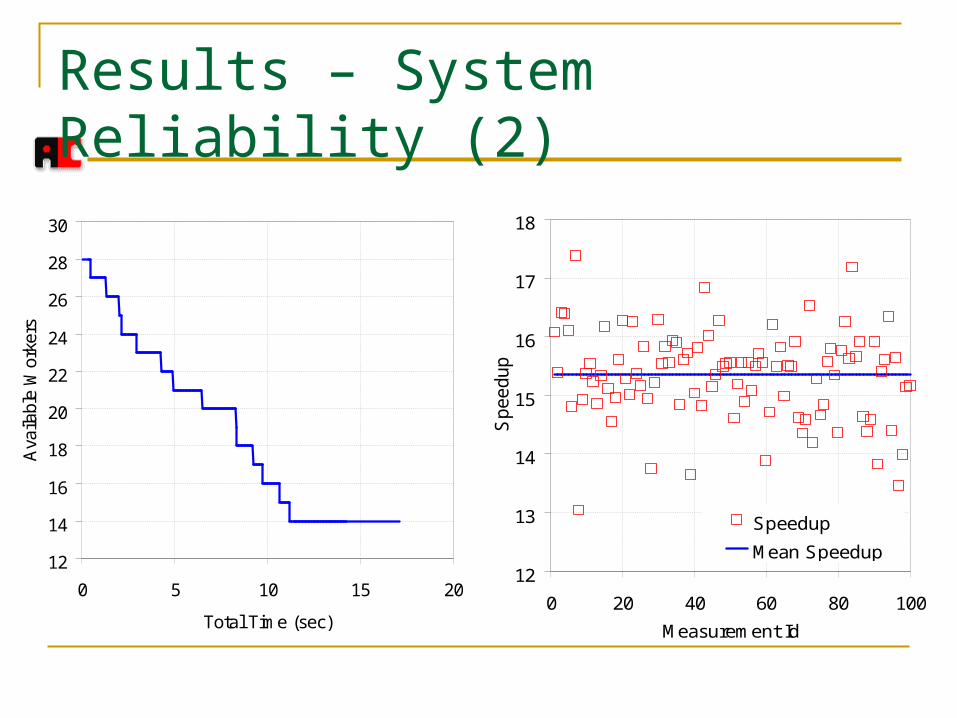
Results – System Reliability (2)
12
13
14
15
16
17
18
0 20 40 60 80 100
Measurement Id
Speedup
Speedup
Mean Speedup12
14
16
18
20
22
24
26
28
30
0 5 10 15 20
Total Time (sec)
Ava
ilabl
e W
orke
rs

Results – System Reliability (3) Test of master server fail-over
Active master server is failed automatically by the application at run-time to simulate a server fail-over
Tested if the standby server can take over and restart from the checkpoint file
Monitored the completion of all tasks and performed benchmarking
Test is repeated 100 times
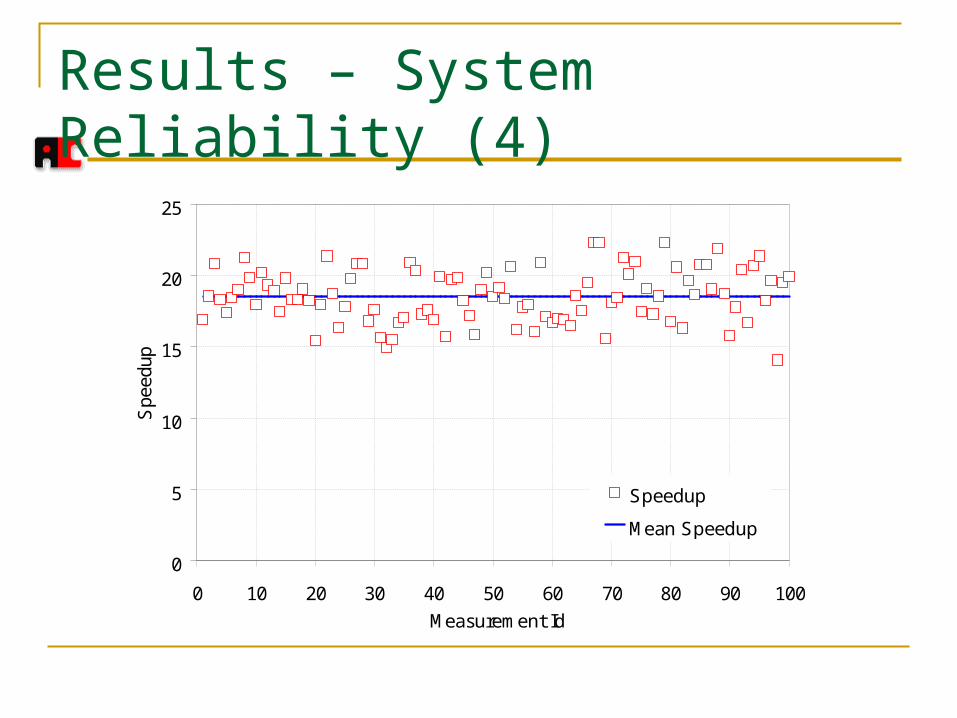
Results – System Reliability (4)
0
5
10
15
20
25
0 10 20 30 40 50 60 70 80 90 100
Measurement Id
Spe
edup
Speedup
Mean Speedup

Conclusion and Future Works Proposed a highly robust and reliable framework
prototype for the distributed real-time processing of satellite data for NOAA’s future ground systems on a Linux Cluster
Showed that considerable performance can be gained for the candidate science algorithms
Demonstrated reliability and high availability for a prototype real-time system
Future work involves the processing of GIFTS science algorithm pipeline in its entirety.


















