
A Neural Network for Factoid Question Answering over ...cs.umd.edu/~miyyer/pubs/2014_qb_rnn.pdf ·...
12
A Neural Network for Factoid Question Answering over Paragraphs Mohit Iyyer 1 , Jordan Boyd-Graber 2 , Leonardo Claudino 1 , Richard Socher 3 , Hal Daum´ e III 1 1 University of Maryland, Department of Computer Science and umiacs 2 University of Colorado, Department of Computer Science 3 Stanford University, Department of Computer Science {miyyer,claudino,hal}@umiacs.umd.edu, [email protected], [email protected] Abstract Text classification methods for tasks like factoid question answering typi- cally use manually defined string match- ing rules or bag of words representa- tions. These methods are ineffective when question text contains very few individual words (e.g., named entities) that are indicative of the answer. We introduce a recursive neural network (rnn) model that can reason over such input by modeling textual composition- ality. We apply our model, qanta, to a dataset of questions from a trivia competition called quiz bowl. Unlike previous rnn models, qanta learns word and phrase-level representations that combine across sentences to reason about entities. The model outperforms multiple baselines and, when combined with information retrieval methods, ri- vals the best human players. 1 Introduction Deep neural networks have seen widespread use in natural language processing tasks such as parsing, language modeling, and sentiment analysis (Bengio et al., 2003; Socher et al., 2013a; Socher et al., 2013c). The vector spaces learned by these models cluster words and phrases together based on similarity. For exam- ple, a neural network trained for a sentiment analysis task such as restaurant review classifi- cation might learn that “tasty” and “delicious” should have similar representations since they are synonymous adjectives. These models have so far only seen success in a limited range of text-based prediction tasks, Later in its existence, this polity’s leader was chosen by a group that included three bishops and six laymen, up from the seven who traditionally made the decision. Free imperial cities in this polity included Basel and Speyer. Dissolved in 1806, its key events included the Investiture Controversy and the Golden Bull of 1356. Led by Charles V, Frederick Barbarossa, and Otto I, for 10 points, name this polity, which ruled most of what is now Germany through the Middle Ages and rarely ruled its titular city. Figure 1: An example quiz bowl question about the Holy Roman Empire. The first sentence contains no words or named entities that by themselves are indicative of the answer, while subsequent sentences contain more and more obvious clues. where inputs are typically a single sentence and outputs are either continuous or a limited dis- crete set. Neural networks have not yet shown to be useful for tasks that require mapping paragraph-length inputs to rich output spaces. Consider factoid question answering: given a description of an entity, identify the per- son, place, or thing discussed. We describe a task with high-quality mappings from natural language text to entities in Section 2. This task—quiz bowl—is a challenging natural lan- guage problem with large amounts of diverse and compositional data. To answer quiz bowl questions, we develop a dependency tree recursive neural network in Section 3 and extend it to combine predic- tions across sentences to produce a question answering neural network with trans-sentential averaging (qanta). We evaluate our model against strong computer and human baselines in Section 4 and conclude by examining the latent space and model mistakes.
Transcript of A Neural Network for Factoid Question Answering over ...cs.umd.edu/~miyyer/pubs/2014_qb_rnn.pdf ·...

A Neural Network for Factoid Question Answering overParagraphs
Mohit Iyyer1, Jordan Boyd-Graber2, Leonardo Claudino1,Richard Socher3, Hal Daume III1
1University of Maryland, Department of Computer Science and umiacs2University of Colorado, Department of Computer Science
3Stanford University, Department of Computer Science{miyyer,claudino,hal}@umiacs.umd.edu,
[email protected], [email protected]
Abstract
Text classification methods for taskslike factoid question answering typi-cally use manually defined string match-ing rules or bag of words representa-tions. These methods are ineffectivewhen question text contains very fewindividual words (e.g., named entities)that are indicative of the answer. Weintroduce a recursive neural network(rnn) model that can reason over suchinput by modeling textual composition-ality. We apply our model, qanta, toa dataset of questions from a triviacompetition called quiz bowl. Unlikeprevious rnn models, qanta learnsword and phrase-level representationsthat combine across sentences to reasonabout entities. The model outperformsmultiple baselines and, when combinedwith information retrieval methods, ri-vals the best human players.
1 Introduction
Deep neural networks have seen widespreaduse in natural language processing tasks suchas parsing, language modeling, and sentimentanalysis (Bengio et al., 2003; Socher et al.,2013a; Socher et al., 2013c). The vector spaceslearned by these models cluster words andphrases together based on similarity. For exam-ple, a neural network trained for a sentimentanalysis task such as restaurant review classifi-cation might learn that “tasty” and “delicious”should have similar representations since theyare synonymous adjectives.
These models have so far only seen success ina limited range of text-based prediction tasks,
Later in its existence, this polity’s leader was chosenby a group that included three bishops and six laymen,up from the seven who traditionally made the decision.Free imperial cities in this polity included Basel andSpeyer. Dissolved in 1806, its key events included theInvestiture Controversy and the Golden Bull of 1356.Led by Charles V, Frederick Barbarossa, and Otto I,for 10 points, name this polity, which ruled most ofwhat is now Germany through the Middle Ages andrarely ruled its titular city.
Figure 1: An example quiz bowl question aboutthe Holy Roman Empire. The first sentencecontains no words or named entities that bythemselves are indicative of the answer, whilesubsequent sentences contain more and moreobvious clues.
where inputs are typically a single sentence andoutputs are either continuous or a limited dis-crete set. Neural networks have not yet shownto be useful for tasks that require mappingparagraph-length inputs to rich output spaces.
Consider factoid question answering: givena description of an entity, identify the per-son, place, or thing discussed. We describe atask with high-quality mappings from naturallanguage text to entities in Section 2. Thistask—quiz bowl—is a challenging natural lan-guage problem with large amounts of diverseand compositional data.
To answer quiz bowl questions, we developa dependency tree recursive neural networkin Section 3 and extend it to combine predic-tions across sentences to produce a questionanswering neural network with trans-sententialaveraging (qanta). We evaluate our modelagainst strong computer and human baselinesin Section 4 and conclude by examining thelatent space and model mistakes.

2 Matching Text to Entities: QuizBowl
Every weekend, hundreds of high school andcollege students play a game where they mapraw text to well-known entities. This is a triviacompetition called quiz bowl. Quiz bowl ques-tions consist of four to six sentences and areassociated with factoid answers (e.g., historyquestions ask players to identify specific battles,presidents, or events). Every sentence in a quizbowl question is guaranteed to contain cluesthat uniquely identify its answer, even withoutthe context of previous sentences. Players an-swer at any time—ideally more quickly thanthe opponent—and are rewarded for correctanswers.
Automatic approaches to quiz bowl based onexisting nlp techniques are doomed to failure.Quiz bowl questions have a property calledpyramidality, which means that sentences earlyin a question contain harder, more obscureclues, while later sentences are “giveaways”.This design rewards players with deep knowl-edge of a particular subject and thwarts bagof words methods. Sometimes the first sen-tence contains no named entities—answeringthe question correctly requires an actual un-derstanding of the sentence (Figure 1). Latersentences, however, progressively reveal morewell-known and uniquely identifying terms.
Previous work answers quiz bowl ques-tions using a bag of words (naıve Bayes) ap-proach (Boyd-Graber et al., 2012). These mod-els fail on sentences like the first one in Figure 1,a typical hard, initial clue. Recursive neuralnetworks (rnns), in contrast to simpler models,can capture the compositional aspect of suchsentences (Hermann et al., 2013).
rnns require many redundant training exam-ples to learn meaningful representations, whichin the quiz bowl setting means we need multiplequestions about the same answer. Fortunately,hundreds of questions are produced during theschool year for quiz bowl competitions, yield-ing many different examples of questions ask-ing about any entity of note (see Section 4.1for more details). Thus, we have built-in re-dundancy (the number of “askable” entities islimited), but also built-in diversity, as difficultclues cannot appear in every question withoutbecoming well-known.
3 Dependency-Tree RecursiveNeural Networks
To compute distributed representations for theindividual sentences within quiz bowl ques-tions, we use a dependency-tree rnn (dt-rnn).These representations are then aggregated andfed into a multinomial logistic regression clas-sifier, where class labels are the answers asso-ciated with each question instance.
In previous work, Socher et al. (2014) usedt-rnns to map text descriptions to images.dt-rnns are robust to similar sentences withslightly different syntax, which is ideal for ourproblem since answers are often described bymany sentences that are similar in meaningbut different in structure. Our model improvesupon the existing dt-rnn model by jointlylearning answer and question representationsin the same vector space rather than learningthem separately.
3.1 Model Description
As in other rnn models, we begin by associ-ating each word w in our vocabulary with avector representation xw ∈ Rd. These vectorsare stored as the columns of a d × V dimen-sional word embedding matrix We, where V isthe size of the vocabulary. Our model takesdependency parse trees of question sentences(De Marneffe et al., 2006) and their correspond-ing answers as input.
Each node n in the parse tree for a partic-ular sentence is associated with a word w, aword vector xw, and a hidden vector hn ∈ Rd
of the same dimension as the word vectors. Forinternal nodes, this vector is a phrase-level rep-resentation, while at leaf nodes it is the wordvector xw mapped into the hidden space. Un-like in constituency trees where all words resideat the leaf level, internal nodes of dependencytrees are associated with words. Thus, the dt-rnn has to combine the current node’s wordvector with its children’s hidden vectors to formhn. This process continues recursively up tothe root, which represents the entire sentence.
We associate a separate d×d matrix Wr witheach dependency relation r in our dataset andlearn these matrices during training.1 Syntac-tically untying these matrices improves com-
1We had 46 unique dependency relations in our quizbowl dataset.

This city ’s economy depended on subjugated peasants called helots
ROOT
DET POSSESSIVE
POSSNSUBJ
PREP
POBJ
AMODVMOD DOBJ
Figure 2: Dependency parse of a sentence from a question about Sparta.
positionality over the standard rnn model bytaking into account relation identity along withtree structure. We include an additional d× dmatrix, Wv, to incorporate the word vector xwat a node into the node vector hn.
Given a parse tree (Figure 2), we first com-pute leaf representations. For example, thehidden representation hhelots is
hhelots = f(Wv · xhelots + b), (1)
where f is a non-linear activation function suchas tanh and b is a bias term. Once all leavesare finished, we move to interior nodes withalready processed children. Continuing from“helots” to its parent, “called”, we compute
hcalled =f(WDOBJ · hhelots +Wv · xcalled+ b). (2)
We repeat this process up to the root, which is
hdepended =f(WNSUBJ · heconomy +WPREP · hon+Wv · xdepended + b). (3)
The composition equation for any node n withchildren K(n) and word vector xw is hn =
f(Wv · xw + b+∑
k∈K(n)
WR(n,k) · hk), (4)
where R(n, k) is the dependency relation be-tween node n and child node k.
3.2 Training
Our goal is to map questions to their corre-sponding answer entities. Because there area limited number of possible answers, we canview this as a multi-class classification task.While a softmax layer over every node in thetree could predict answers (Socher et al., 2011;Iyyer et al., 2014), this method overlooks thatmost answers are themselves words (features)in other questions (e.g., a question on World
War II might mention the Battle of the Bulgeand vice versa). Thus, word vectors associatedwith such answers can be trained in the samevector space as question text,2 enabling us tomodel relationships between answers insteadof assuming incorrectly that all answers areindependent.
To take advantage of this observation, wedepart from Socher et al. (2014) by trainingboth the answers and questions jointly in asingle model, rather than training each sep-arately and holding embeddings fixed duringdt-rnn training. This method cannot be ap-plied to the multimodal text-to-image mappingproblem because text captions by definition aremade up of words and thus cannot include im-ages; in our case, however, question text canand frequently does include answer text.
Intuitively, we want to encourage the vectorsof question sentences to be near their correctanswers and far away from incorrect answers.We accomplish this goal by using a contrastivemax-margin objective function described be-low. While we are not interested in obtaining aranked list of answers,3 we observe better per-formance by adding the weighted approximate-rank pairwise (warp) loss proposed in Westonet al. (2011) to our objective function.
Given a sentence paired with its correct an-swer c, we randomly select j incorrect answersfrom the set of all incorrect answers and denotethis subset as Z. Since c is part of the vocab-ulary, it has a vector xc ∈ We. An incorrectanswer z ∈ Z is also associated with a vectorxz ∈We. We define S to be the set of all nodesin the sentence’s dependency tree, where anindividual node s ∈ S is associated with the
2Of course, questions never contain their own answeras part of the text.
3In quiz bowl, all wrong guesses are equally detri-mental to a team’s score, no matter how “close” a guessis to the correct answer.

hidden vector hs. The error for the sentence is
C(S, θ) =∑s∈S
∑z∈Z
L(rank(c, s, Z))max(0,
1− xc · hs + xz · hs), (5)
where the function rank(c, s, Z) provides therank of correct answer c with respect to theincorrect answers Z. We transform this rankinto a loss function4 shown by Usunier et al.(2009) to optimize the top of the ranked list,
L(r) =r∑
i=11/i.
Since rank(c, s, Z) is expensive to compute,we approximate it by randomly sampling Kincorrect answers until a violation is observed(xc · hs < 1 + xz · hs) and set rank(c, s, Z) =(|Z|−1)/K, as in previous work (Weston et al.,2011; Hermann et al., 2014). The model mini-mizes the sum of the error over all sentences Tnormalized by the number of nodes N in thetraining set,
J(θ) =1
N
∑t∈T
C(t, θ). (6)
The parameters θ = (Wr∈R,Wv,We, b), whereR represents all dependency relations in thedata, are optimized using AdaGrad(Duchi etal., 2011).5 In Section 4 we compare perfor-mance to an identical model (fixed-qanta)that excludes answer vectors from We and showthat training them as part of θ produces signif-icantly better results.
The gradient of the objective function,
∂C
∂θ=
1
N
∑t∈T
∂J(t)
∂θ, (7)
is computed using backpropagation throughstructure (Goller and Kuchler, 1996).
3.3 From Sentences to Questions
The model we have just described considerseach sentence in a quiz bowl question indepen-dently. However, previously-heard sentenceswithin the same question contain useful infor-mation that we do not want our model to ignore.
4Our experiments show that adding this loss term tothe objective function not only increases performancebut also speeds up convergence
5We set the initial learning rate η = 0.05 and resetthe squared gradient sum to zero every five epochs.
While past work on rnn models have been re-stricted to the sentential and sub-sententiallevels, we show that sentence-level representa-tions can be easily combined to generate usefulrepresentations at the larger paragraph level.
The simplest and best6 aggregation methodis just to average the representations of eachsentence seen so far in a particular question.As we show in Section 4, this method is verypowerful and performs better than most of ourbaselines. We call this averaged dt-rnn modelqanta: a question answering neural networkwith trans-sentential averaging.
4 Experiments
We compare the performance of qanta againstmultiple strong baselines on two datasets.qanta outperforms all baselines trained onlyon question text and improves an informationretrieval model trained on all of Wikipedia.qanta requires that an input sentence de-scribes an entity without mentioning thatentity, a constraint that is not followed byWikipedia sentences.7 While ir methods canoperate over Wikipedia text with no issues,we show that the representations learned byqanta over just a dataset of question-answerpairs can significantly improve the performanceof ir systems.
4.1 Datasets
We evaluate our algorithms on a corpus of over100,000 question/answer pairs from two differ-ent sources. First, we expand the dataset usedin Boyd-Graber et al. (2012) with publically-available questions from quiz bowl tournamentsheld after that work was published. This givesus 46,842 questions in fourteen different cate-gories. To this dataset we add 65,212 questionsfrom naqt, an organization that runs quizbowl tournaments and generously shared withus all of their questions from 1998–2013.
6We experimented with weighting earlier sentencesless than later ones in the average as well as learning anadditional RNN on top of the sentence-level representa-tions. In the former case, we observed no improvementsover a uniform average, while in the latter case themodel overfit even with strong regularization.
7We tried transforming Wikipedia sentences intoquiz bowl sentences by replacing answer mentions withappropriate descriptors (e.g., “Joseph Heller” with “thisauthor”), but the resulting sentences suffered from avariety of grammatical issues and did not help the finalresult.

Because some categories contain substan-tially fewer questions than others (e.g., astron-omy has only 331 questions), we consider onlyliterature and history questions, as these twocategories account for more than 40% of thecorpus. This leaves us with 21,041 history ques-tions and 22,956 literature questions.
4.1.1 Data Preparation
To make this problem feasible, we only considera limited set of the most popular quiz bowl an-swers. Before we filter out uncommon answers,we first need to map all raw answer strings toa canonical set to get around formatting andredundancy issues. Most quiz bowl answers arewritten to provide as much information aboutthe entity as possible. For example, the follow-ing is the raw answer text of a question on theChinese leader Sun Yat-sen: Sun Yat-sen; orSun Yixian; or Sun Wen; or Sun Deming; orNakayama Sho; or Nagao Takano. Quiz bowlwriters vary in how many alternate acceptableanswers they provide, which makes it tricky tostrip superfluous information from the answersusing rule-based approaches.
Instead, we use Whoosh,8 an information re-trieval library, to generate features in an activelearning classifier that matches existing answerstrings to Wikipedia titles. If we are unableto find a match with a high enough confidencescore, we throw the question out of our dataset.After this standardization process and manualvetting of the resulting output, we can use theWikipedia page titles as training labels for thedt-rnn and baseline models.9
65.6% of answers only occur once or twicein the corpus. We filter out all answers thatdo not occur at least six times, which leavesus with 451 history answers and 595 literatureanswers that occur on average twelve timesin the corpus. These pruning steps result in4,460 usable history questions and 5,685 liter-ature questions. While ideally we would haveused all answers, our model benefits from manytraining examples per answer to learn mean-ingful representations; this issue can possiblybe addressed with techniques from zero shotlearning (Palatucci et al., 2009; Pasupat andLiang, 2014), which we leave to future work.
8https://pypi.python.org/pypi/Whoosh/9Code and non-naqt data available at http://cs.
umd.edu/~miyyer/qblearn.
We apply basic named entity recogni-tion (ner) by replacing all occurrences ofanswers in the question text with singleentities (e.g., Ernest Hemingway becomesErnest Hemingway). While we experimentedwith more advanced ner systems to detectnon-answer entities, they could not handlemulti-word named entities like the book Lovein the Time of Cholera (title case) or battlenames (e.g., Battle of Midway). A simplesearch/replace on all answers in our corpusworks better for multi-word entities.
The preprocessed data are split into foldsby tournament. We choose the past two na-tional tournaments10 as our test set as wellas questions previously answered by players inBoyd-Graber et al. (2012) and assign all otherquestions to train and dev sets. History resultsare reported on a training set of 3,761 ques-tions with 14,217 sentences and a test set of699 questions with 2,768 sentences. Literatureresults are reported on a training set of 4,777questions with 17,972 sentences and a test setof 908 questions with 3,577 sentences.
Finally, we initialize the word embeddingmatrix We with word2vec (Mikolov et al., 2013)trained on the preprocessed question text inour training set.11 We use the hierarchical skip-gram model setting with a window size of fivewords.
4.2 Baselines
We pit qanta against two types of baselines:bag of words models, which enable comparisonto a standard NLP baseline, and informationretrieval models, which allow us to compareagainst traditional question answering tech-niques.
BOW The bow baseline is a logistic regres-sion classifier trained on binary unigram indi-cators.12 This simple discriminative model isan improvement over the generative quiz bowlanswering model of Boyd-Graber et al. (2012).
10The tournaments were selected because naqt doesnot reuse any questions or clues within these tourna-ments.
11Out-of-vocabulary words from the test set are ini-tialized randomly.
12Raw word counts, frequencies, and TF-IDFweighted features did not increase performance, nordid adding bigrams to the feature set (possibly becausemulti-word named entities are already collapsed intosingle words).

BOW-DT The bow-dt baseline is identicalto bow except we augment the feature set withdependency relation indicators. We includethis baseline to isolate the effects of the depen-dency tree structure from our compositionalmodel.IR-QB The ir-qb baseline maps questions toanswers using the state-of-the-art Whoosh irengine. The knowledge base for ir-qb consistsof “pages” associated with each answer, whereeach page is the union of training question textfor that answer. Given a partial question, thetext is first preprocessed using a query lan-guage similar to that of Apache Lucene. Thisprocessed query is then matched to pages usesbm-25 term weighting, and the top-ranked pageis considered to be the model’s guess. We alsoincorporate fuzzy queries to catch misspellingsand plurals and use Whoosh’s built-in query ex-pansion functionality to add related keywordsto our queries. IR-WIKI The ir-wiki modelis identical to the ir-qb model except that each“page” in its knowledge base also includes alltext from the associated answer’s Wikipediaarticle. Since all other baselines and dt-rnnmodels operate only on the question text, thisis not a valid comparison, but we offer it toshow that we can improve even this strongmodel using qanta.
4.3 DT-RNN Configurations
For all dt-rnn models the vector dimension dand the number of wrong answers per node jis set to 100. All model parameters other thanWe are randomly initialized. The non-linearityf is the normalized tanh function,13
f(v) =tanh(v)
‖tanh(v)‖. (8)
qanta is our dt-rnn model with featureaveraging across previously-seen sentences in aquestion. To obtain the final answer predictiongiven a partial question, we first generate afeature representation for each sentence withinthat partial question. This representation iscomputed by concatenating together the wordembeddings and hidden representations aver-aged over all nodes in the tree as well as the
13The standard tanh function produced heavy sat-uration at higher levels of the trees, and correctiveweighting as in Socher et al. (2014) hurt our modelbecause named entities that occur as leaves are oftenmore important than non-terminal phrases.
root node’s hidden vector. Finally, we sendthe average of all of the individual sentence fea-tures14 as input to a logistic regression classifierfor answer prediction.
fixed-qanta uses the same dt-rnn configu-ration as qanta except the answer vectors arekept constant as in the text-to-image model.
4.4 Human Comparison
Previous work provides human answers (Boyd-Graber et al., 2012) for quiz bowl questions.We use human records for 1,201 history guessesand 1,715 literature guesses from twenty-two ofthe quiz bowl players who answered the mostquestions.15
The standard scoring system for quiz bowl is10 points for a correct guess and -5 points foran incorrect guess. We use this metric to com-pute a total score for each human. To obtainthe corresponding score for our model, we forceit to imitate each human’s guessing policy. Forexample, Figure 3 shows a human answeringin the middle of the second sentence. Since ourmodel only considers sentence-level increments,we compare the model’s prediction after thefirst sentence to the human prediction, whichmeans our model is privy to less informationthan humans.
The resulting distributions are shown in Fig-ure 4—our model does better than the averageplayer on history questions, tying or defeat-ing sixteen of the twenty-two players, but itdoes worse on literature questions, where itonly ties or defeats eight players. The figureindicates that literature questions are harderthan history questions for our model, which iscorroborated by the experimental results dis-cussed in the next section.
5 Discussion
In this section, we examine why qanta im-proves over our baselines by giving examplesof questions that are incorrectly classified byall baselines but correctly classified by qanta.We also take a close look at some sentences thatall models fail to answer correctly. Finally, wevisualize the answer space learned by qanta.
14Initial experiments with L2 regularization hurt per-formance on a validation set.
15Participants were skilled quiz bowl players and arenot representative of the general population.

History Literature
Model Pos 1 Pos 2 Full Pos 1 Pos 2 Full
bow 27.5 51.3 53.1 19.3 43.4 46.7bow-dt 35.4 57.7 60.2 24.4 51.8 55.7ir-qb 37.5 65.9 71.4 27.4 54.0 61.9fixed-qanta 38.3 64.4 66.2 28.9 57.7 62.3qanta 47.1 72.1 73.7 36.4 68.2 69.1
ir-wiki 53.7 76.6 77.5 41.8 74.0 73.3qanta+ir-wiki 59.8 81.8 82.3 44.7 78.7 76.6
Table 1: Accuracy for history and literature at the first two sentence positions of each questionand the full question. The top half of the table compares models trained on questions only, whilethe IR models in the bottom half have access to Wikipedia. qanta outperforms all baselinesthat are restricted to just the question data, and it substantially improves an IR model withaccess to Wikipedia despite being trained on much less data.
200
150
100
50
0
50
100
150
200
Sco
re D
iffe
rence
History: Model vs. Human
Model loses
Model wins 400
300
200
100
0
100
200Sco
re D
iffe
rence
Literature: Model vs. Human
Model loses
Model wins
Figure 4: Comparisons of qanta+ir-wiki to human quiz bowl players. Each bar represents anindividual human, and the bar height corresponds to the difference between the model score andthe human score. Bars are ordered by human skill. Red bars indicate that the human is winning,while blue bars indicate that the model is winning. qanta+ir-wiki outperforms most humanson history questions but fails to defeat the “average” human on literature questions.
A minor character in this play can be summonedby a bell that does not always work; that characteralso doesn’t have eyelids. Near the end, a womanwho drowned her illegitimate child attempts to stabanother woman in the Second Empire-style 3 roomin which the entire play takes place. For 10 points,Estelle and Ines are characters in which existentialistplay in which Garcin claims “Hell is other people”,written by Jean-Paul Sartre?
Figure 3: A question on the play “No Exit”with human buzz position marked as 3. Sincethe buzz occurs in the middle of the secondsentence, our model is only allowed to see thefirst sentence.
5.1 Experimental Results
Table 1 shows that when bag of words andinformation retrieval methods are restricted toquestion data, they perform significantly worsethan qanta on early sentence positions. The
performance of bow-dt indicates that whilethe dependency tree structure helps by itself,the compositional distributed representationslearned by qanta are more useful. The signif-icant improvement when we train answers aspart of our vocabulary (see Section 3.2) indi-cates that our model uses answer occurrenceswithin question text to learn a more informa-tive vector space.
The disparity between ir-qb and ir-wikiindicates that the information retrieval modelsneed lots of external data to work well at allsentence positions. ir-wiki performs betterthan other models because Wikipedia containsmany more sentences that partially match spe-cific words or phrases found in early clues thanthe question training set. In particular, it isimpossible for all other models to answer cluesin the test set that have no semantically similar

or equivalent analogues in the training ques-tion data. With that said, ir methods canalso operate over data that does not follow thespecial constraints of quiz bowl questions (e.g.,every sentence uniquely identifies the answer,answers don’t appear in their correspondingquestions), which qanta cannot handle. Bycombining qanta and ir-wiki, we are able toleverage access to huge knowledge bases alongwith deep compositional representations, giv-ing us the best of both worlds.
5.2 Where the Attribute Space HelpsAnswer Questions
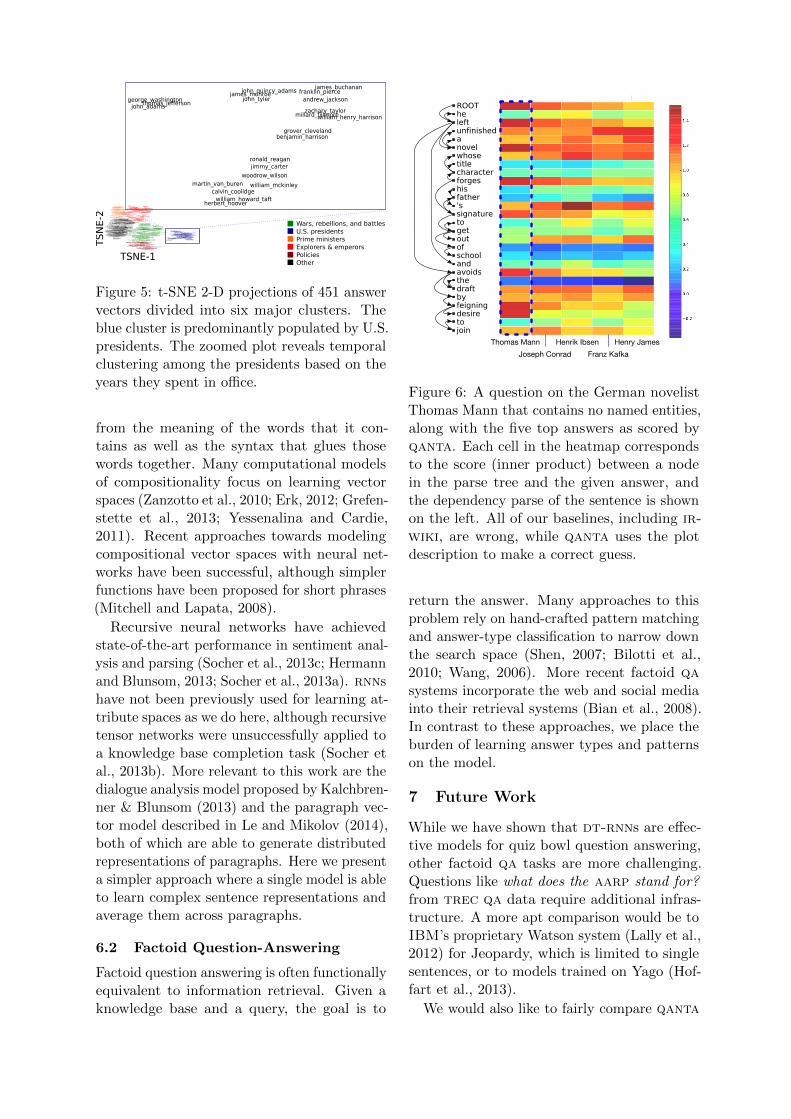
We look closely at the first sentence from aliterature question about the author ThomasMann: “He left unfinished a novel whose titlecharacter forges his father’s signature to getout of school and avoids the draft by feigningdesire to join”.
All baselines, including ir-wiki, are unableto predict the correct answer given only thissentence. However, qanta makes the correctprediction. The sentence contains no namedentities, which makes it almost impossible forbag of words or string matching algorithms topredict correctly. Figure 6 shows that the plotdescription associated with the “novel” nodeis strongly indicative of the answer. The fivehighest-scored answers are all male authors,16
which shows that our model is able to learn theanswer type without any hand-crafted rules.
Our next example, the first sentence in Ta-ble 2, is from the first position of a questionon John Quincy Adams, which is correctly an-swered by only qanta. The bag of wordsmodel guesses Henry Clay, who was also a Sec-retary of State in the nineteenth century andhelped John Quincy Adams get elected to thepresidency in a “corrupt bargain”. However,the model can reason that while Henry Claywas active at the same time and involved inthe same political problems of the era, he didnot represent the Amistad slaves, nor did henegotiate the Treaty of Ghent.
5.3 Where all Models Struggle
Quiz bowl questions are intentionally written tomake players work to get the answer, especiallyat early sentence positions. Our model fails to
16three of whom who also have well-known unfinishednovels
answer correctly more than half the time afterhearing only the first sentence. We examinesome examples to see if there are any patternsto what makes a question “hard” for machinelearning models.
Consider this question about the Italian ex-plorer John Cabot: “As a young man, thisnative of Genoa disguised himself as a Muslimto make a pilgrimage to Mecca”.
While it is obvious to human readers thatthe man described in this sentence is not actu-ally a Muslim, qanta has to accurately modelthe verb disguised to make that inference. Weshow the score plot of this sentence in Figure 7.The model, after presumably seeing many in-stances of muslim and mecca associated withMughal emperors, is unable to prevent thisinformation from propagating up to the rootnode. On the bright side, our model is able tolearn that the question is expecting a humananswer rather than non-human entities like theUmayyad Caliphate.
More examples of impressive answers byqanta as well as incorrect guesses by all sys-tems are shown in Table 2.
5.4 Examining the Attribute Space
Figure 5 shows a t-SNE visualization (Van derMaaten and Hinton, 2008) of the 451 answersin our history dataset. The vector space isdivided into six general clusters, and we focusin particular on the us presidents. Zoomingin on this section reveals temporal clustering:presidents who were in office during the sametimeframe occur closer together. This observa-tion shows that qanta is capable of learningattributes of entities during training.
6 Related Work
There are two threads of related work relevantto this paper. First, we discuss previous ap-plications of compositional vector models torelated NLP tasks. Then, we examine existingwork on factoid question-answering and reviewthe similarities and differences between thesetasks and the game of quiz bowl.
6.1 Recursive Neural Networks forNLP
The principle of semantic composition statesthat the meaning of a phrase can be derived
TSNE-1
TSNE-2
Wars, rebellions, and battlesU.S. presidentsPrime ministersExplorers & emperorsPoliciesOther
tammany_hall
calvin_coolidge
lollardy
fourth_crusade
songhai_empire
peace_of_westphalia
inca_empire
atahualpa
charles_sumner
john_paul_jones
wounded_knee_massacre
huldrych_zwingli
darius_i
battle_of_ayacucho
john_cabotghana
ulysses_s._grant
hartford_conventioncivilian_conservation_corps
roger_williams_(theologian)
george_h._pendleton
william_mckinley
victoria_woodhull
credit_mobilier_of_america_scandal henry_cabot_lodge,_jr.
mughal_empire
john_marshall
cultural_revolution
guadalcanal
louisiana_purchase
night_of_the_long_knives
chandragupta_maurya
samuel_de_champlain
thirty_years'_war
compromise_of_1850
battle_of_hastings
battle_of_salamis
akbar
lewis_cass
dawes_plan
hernando_de_soto
carthage
joseph_mccarthy
maine
salvador_allende
battle_of_gettysburg
mikhail_gorbachev
aaron_burr
equal_rights_amendment
war_of_the_spanish_succession
coxey's_army
george_meade
fourteen_points
mapp_v._ohiosam_houston
ming_dynasty
boxer_rebellion
anti-masonic_party
porfirio_diaz
treaty_of_portsmouth
thebes,_greece
golden_horde
francisco_i._madero
hittites
james_g._blaineschenck_v._united_states
caligula
william_walker_(filibuster)
henry_vii_of_england
konrad_adenauer
kellogg-briand_pact
battle_of_culloden
treaty_of_brest-litovsk
william_penn
a._philip_randolph
henry_l._stimson
whig_party_(united_states)
caroline_affairclarence_darrow
whiskey_rebellion
battle_of_midway
battle_of_lepanto
adolf_eichmann
georges_clemenceau
battle_of_the_little_bighornpontiac_(person)
black_hawk_war
battle_of_tannenberg
clayton_antitrust_act
provisions_of_oxford
battle_of_actium
suez_crisis
spartacus
dorr_rebellion
jay_treaty
triangle_shirtwaist_factory_fire
kamakura_shogunate
julius_nyerere
frederick_douglass
pierre_trudeau
nagasaki
suleiman_the_magnificent
falklands_war
war_of_devolution
charlemagne
daniel_boone
edict_of_nantes
harry_s._truman
shaka
pedro_alvares_cabral
thomas_hart_benton_(politician)
battle_of_the_coral_sea
peterloo_massacre
battle_of_bosworth_field
roger_b._taney
bernardo_o'higgins
neville_chamberlain
henry_hudson
cyrus_the_great
jane_addams
rough_riders
james_a._garfield
napoleon_iii
missouri_compromise
battle_of_leyte_gulf
ambrose_burnside
trent_affair
maria_theresa
william_ewart_gladstone
walter_mondale
barry_goldwaterlouis_riel
hideki_tojo
marco_polo
brian_mulroney
truman_doctrine
roald_amundsen
tokugawa_shogunate
eleanor_of_aquitaine
louis_brandeis
battle_of_trenton
khmer_empire
benito_juarez
battle_of_antietam
whiskey_ring
otto_von_bismarck
booker_t._washington
battle_of_bannockburneugene_v._debs
erie_canal
jameson_raid
green_mountain_boys
haymarket_affair
finland
fashoda_incident
battle_of_shiloh
hannibal
john_jay
easter_rising
jamaica
brook_farm
umayyad_caliphate
muhammad
francis_drake
clara_barton
shays'_rebellionverdun
hadrianvyacheslav_molotovoda_nobunaga
canossa
samuel_gompers
battle_of_bunker_hillbattle_of_plassey
david_livingstone
solonpericles
tang_dynasty
teutonic_knights
second_vatican_council
alfred_dreyfus
henry_the_navigator
nelson_mandela
peasants'_revolt
gaius_marius
getulio_vargas
horatio_gates
john_t._scopes
league_of_nations
first_battle_of_bull_run
alfred_the_great
leonid_brezhnev
cherokee
long_march
emiliano_zapata
james_monroe
woodrow_wilson
vandals
william_henry_harrison
battle_of_puebla
battle_of_zama
justinian_i
thaddeus_stevens
cecil_rhodes
kwame_nkrumah
diet_of_worms
george_armstrong_custer
battle_of_agincourt
seminole_wars
shah_jahan
amerigo_vespucci
john_foster_dulles
lester_b._pearson
oregon_trail
claudius
lateran_treaty
chester_a._arthur
opium_wars
treaty_of_utrechtknights_of_labor
alexander_hamilton
plessy_v._ferguson
horace_greeley
mary_baker_eddy
alexander_kerensky
jacquerie
treaty_of_ghentbay_of_pigs_invasion
antonio_lopez_de_santa_anna
great_northern_war
henry_i_of_england
council_of_trent
chiang_kai-shek
samuel_j._tilden
fidel_castro
wilmot_proviso
yuan_dynasty
bastille
benjamin_harrison
war_of_the_austrian_successioncrimean_war
john_brown_(abolitionist)
teapot_dome_scandal
albert_b._fall
marcus_licinius_crassus
earl_warren
warren_g._harding
gunpowder_plot
homestead_strike
samuel_adams
john_peter_zenger
thomas_paine
free_soil_party
st._bartholomew's_day_massacre
arthur_wellesley,_1st_duke_of_wellington
charles_de_gaulle
leon_trotsky
hugh_capet
alexander_h._stephens
haile_selassie
william_h._seward
rutherford_b._hayes
safavid_dynasty
muhammad_ali_jinnah
kulturkampf
maximilien_de_robespierre
hubert_humphrey
luddite
hull_house
philip_ii_of_macedon
guelphs_and_ghibellines
byzantine_empire
albigensian_crusade
diocletian
fort_ticonderoga
parthian_empire
charles_martel
william_jennings_bryan
alexander_ii_of_russia
ferdinand_magellan
state_of_franklin
ivan_the_terrible
martin_luther_(1953_film)
millard_fillmore
francisco_franco
aethelred_the_unready
ronald_reagan
benito_mussolini
henry_clay
kitchen_cabinet
black_hole_of_calcutta
ancient_corinth
john_wilkes_booth
john_tyler
robert_walpole
huey_long
tokugawa_ieyasu
thomas_nast
nikita_khrushchev
andrew_jackson
portugal
labour_party_(uk)
monroe_doctrine
john_quincy_adams
congress_of_berlin
tecumseh
jacques_cartier
battle_of_the_thames
spanish_civil_war
ethiopia
fugitive_slave_laws
john_a._macdonald
council_of_chalcedon
pancho_villa
war_of_the_pacific
george_wallace
susan_b._anthony
marcus_garvey
grover_clevelandjohn_hay
george_b._mcclellan
october_manifesto
vitus_bering
john_hancock
william_lloyd_garrison
platt_amendment
mary,_queen_of_scots
first_triumvirate
francisco_vasquez_de_coronado
margaret_thatcher
sherman_antitrust_act
hanseatic_league
henry_morton_stanley
july_revolution
stephen_a._douglas
xyz_affair
jimmy_carter
francisco_pizarro
kublai_khan
vasco_da_gama
sparta
battle_of_caporetto
ostend_manifesto
mustafa_kemal_ataturk
peter_the_great
gang_of_four
battle_of_chancellorsville
david_lloyd_george
cardinal_mazarin
embargo_act_of_1807
brigham_young
charles_lindbergh
hudson's_bay_company
attila
paris_commune
jefferson_davis
amelia_earhart
mali_empire
adolf_hitler
benedict_arnold
camillo_benso,_count_of_cavour
meiji_restoration
black_panther_party
mark_antony
franklin_pierce
molly_maguires
zachary_taylor
han_dynasty
adlai_stevenson_ii
james_k._polk
douglas_macarthur
boston_massacre
toyotomi_hideyoshi
greenback_party
second_boer_warthird_crusade
james_buchanan
john_sherman
george_washington
wars_of_the_roses
atlantic_charter
eleanor_roosevelt
congress_of_vienna
john_wycliffe
winston_churchill
emilio_aguinaldo
miguel_hidalgo_y_costilla
second_bank_of_the_united_states
council_of_constance
seneca_falls_convention
first_crusade
spiro_agnew
taiping_rebellion
mao_zedong
paul_von_hindenburg
albany_congress
jawaharlal_nehru
battle_of_blenheim
ethan_allen
antonio_de_oliveira_salazar
herbert_hoover
pepin_the_short
indira_gandhi
william_howard_taftthomas_jefferson
gamal_abdel_nasser
oliver_cromwell
salmon_p._chase
battle_of_austerlitz
benjamin_disraeli
gadsden_purchase
girolamo_savonarola
treaty_of_tordesillas
battle_of_marathon
elizabeth_cady_stanton
battle_of_kings_mountainchristopher_columbus
william_the_conqueror
battle_of_trafalgar
charles_evans_hughes
cleisthenes
william_tecumseh_sherman
mobutu_sese_seko
prague_spring
babur
peloponnesian_war
jacques_marquette
nero
paraguay
hyksos
martin_van_buren
bonus_army
charles_stewart_parnell
edward_the_confessor
bartolomeu_dias
salem_witch_trials
battle_of_the_bulge
john_adams
maginot_line
henry_cabot_lodge
giuseppe_garibaldi
daniel_webster
john_c._calhoun
treaty_of_waitangi
zebulon_pike
genghis_khan
calvin_coolidgewilliam_mckinley
james_monroe
woodrow_wilson
william_henry_harrison
benjamin_harrison
millard_fillmore
ronald_reagan
john_tyler andrew_jacksonjohn_quincy_adams
grover_cleveland
jimmy_carter
franklin_pierce
zachary_taylor
james_buchanan
george_washington
herbert_hooverwilliam_howard_taft
thomas_jefferson
martin_van_buren
john_adams
Figure 5: t-SNE 2-D projections of 451 answervectors divided into six major clusters. Theblue cluster is predominantly populated by U.S.presidents. The zoomed plot reveals temporalclustering among the presidents based on theyears they spent in office.
from the meaning of the words that it con-tains as well as the syntax that glues thosewords together. Many computational modelsof compositionality focus on learning vectorspaces (Zanzotto et al., 2010; Erk, 2012; Grefen-stette et al., 2013; Yessenalina and Cardie,2011). Recent approaches towards modelingcompositional vector spaces with neural net-works have been successful, although simplerfunctions have been proposed for short phrases(Mitchell and Lapata, 2008).
Recursive neural networks have achievedstate-of-the-art performance in sentiment anal-ysis and parsing (Socher et al., 2013c; Hermannand Blunsom, 2013; Socher et al., 2013a). rnnshave not been previously used for learning at-tribute spaces as we do here, although recursivetensor networks were unsuccessfully applied toa knowledge base completion task (Socher etal., 2013b). More relevant to this work are thedialogue analysis model proposed by Kalchbren-ner & Blunsom (2013) and the paragraph vec-tor model described in Le and Mikolov (2014),both of which are able to generate distributedrepresentations of paragraphs. Here we presenta simpler approach where a single model is ableto learn complex sentence representations andaverage them across paragraphs.
6.2 Factoid Question-Answering
Factoid question answering is often functionallyequivalent to information retrieval. Given aknowledge base and a query, the goal is to
Thomas MannJoseph Conrad
Henrik IbsenFranz Kafka
Henry James
Figure 6: A question on the German novelistThomas Mann that contains no named entities,along with the five top answers as scored byqanta. Each cell in the heatmap correspondsto the score (inner product) between a nodein the parse tree and the given answer, andthe dependency parse of the sentence is shownon the left. All of our baselines, including ir-wiki, are wrong, while qanta uses the plotdescription to make a correct guess.
return the answer. Many approaches to thisproblem rely on hand-crafted pattern matchingand answer-type classification to narrow downthe search space (Shen, 2007; Bilotti et al.,2010; Wang, 2006). More recent factoid qasystems incorporate the web and social mediainto their retrieval systems (Bian et al., 2008).In contrast to these approaches, we place theburden of learning answer types and patternson the model.
7 Future Work
While we have shown that dt-rnns are effec-tive models for quiz bowl question answering,other factoid qa tasks are more challenging.Questions like what does the aarp stand for?from trec qa data require additional infras-tructure. A more apt comparison would be toIBM’s proprietary Watson system (Lally et al.,2012) for Jeopardy, which is limited to singlesentences, or to models trained on Yago (Hof-fart et al., 2013).
We would also like to fairly compare qanta

AkbarShah Jahan
MuhammadBabur
Ghana
Figure 7: An extremely misleading questionabout John Cabot, at least to computer models.The words muslim and mecca lead to threeMughal emperors in the top five guesses fromqanta; other models are similarly led awry.
with ir-wiki. A promising avenue for futurework would be to incorporate Wikipedia datainto qanta by transforming sentences to looklike quiz bowl questions (Wang et al., 2007) andto select relevant sentences, as not every sen-tence in a Wikipedia article directly describesits subject. Syntax-specific annotation (Sayeedet al., 2012) may help in this regard.
Finally, we could adapt the attribute spacelearned by the dt-rnn to use information fromknowledge bases and to aid in knowledge basecompletion. Having learned many facts aboutentities that occur in question text, a dt-rnncould add new facts to a knowledge base orcheck existing relationships.
8 Conclusion
We present qanta, a dependency-tree recursiveneural network for factoid question answeringthat outperforms bag of words and informa-tion retrieval baselines. Our model improvesupon a contrastive max-margin objective func-tion from previous work to dynamically updateanswer vectors during training with a singlemodel. Finally, we show that sentence-levelrepresentations can be easily and effectivelycombined to generate paragraph-level represen-
Q he also successfully represented the amistadslaves and negotiated the treaty of ghent andthe annexation of florida from spain during hisstint as secretary of state under james monroe
A john quincy adams, henry clay, andrew jack-son
Q this work refers to people who fell on theirknees in hopeless cathedrals and who jumpedoff the brooklyn bridge
A howl, the tempest, paradise lostQ despite the fact that twenty six martyrs were
crucified here in the late sixteenth century itremained the center of christianity in its coun-try
A nagasaki, guadalcanal, ethiopiaQ this novel parodies freudianism in a chapter
about the protagonist ’s dream of holding alive fish in his hands
Abilly budd, the ambassadors, all my sons
Q a contemporary of elizabeth i he came to powertwo years before her and died two years later
Agrover cleveland, benjamin harrison, henrycabot lodge
Table 2: Five example sentences occuring atthe first sentence position along with their topthree answers as scored by qanta; correct an-swers are marked with blue and wrong answersare marked with red. qanta gets the firstthree correct, unlike all other baselines. Thelast two questions are too difficult for all ofour models, requiring external knowledge (e.g.,Freudianism) and temporal reasoning.
tations with more predictive power than thoseof the individual sentences.
Acknowledgments
We thank the anonymous reviewers, StephanieHwa, Bert Huang, and He He for their insight-ful comments. We thank Sharad Vikram, R.Hentzel, and the members of naqt for pro-viding our data. This work was supported bynsf Grant IIS-1320538. Boyd-Graber is alsosupported by nsf Grant CCF-1018625. Anyopinions, findings, conclusions, or recommen-dations expressed here are those of the authorsand do not necessarily reflect the view of thesponsor.

References
Yoshua Bengio, Rejean Ducharme, Pascal Vincent, andChristian Jauvin. 2003. A neural probabilistic lan-guage model. JMLR.
Jiang Bian, Yandong Liu, Eugene Agichtein, andHongyuan Zha. 2008. Finding the right facts inthe crowd: factoid question answering over socialmedia. In WWW.
Matthew W. Bilotti, Jonathan Elsas, Jaime Carbonell,and Eric Nyberg. 2010. Rank learning for factoidquestion answering with linguistic and semantic con-straints. In CIKM.
Jordan Boyd-Graber, Brianna Satinoff, He He, andHal Daume III. 2012. Besting the quiz master:Crowdsourcing incremental classification games. InEMNLP.
Marie-Catherine De Marneffe, Bill MacCartney, Christo-pher D Manning, et al. 2006. Generating typeddependency parses from phrase structure parses. InLREC.
John Duchi, Elad Hazan, and Yoram Singer. 2011.Adaptive subgradient methods for online learningand stochastic optimization. JMLR, 999999:2121–2159.
Katrin Erk. 2012. Vector space models of word mean-ing and phrase meaning: A survey. Language andLinguistics Compass.
Christoph Goller and Andreas Kuchler. 1996. Learningtask-dependent distributed representations by back-propagation through structure. In Neural Networks,1996., IEEE International Conference on, volume 1.
Edward Grefenstette, Georgiana Dinu, Yao-ZhongZhang, Mehrnoosh Sadrzadeh, and Marco Baroni.2013. Multi-step regression learning for composi-tional distributional semantics. CoRR.
Karl Moritz Hermann and Phil Blunsom. 2013. TheRole of Syntax in Vector Space Models of Composi-tional Semantics. In ACL.
Karl Moritz Hermann, Edward Grefenstette, and PhilBlunsom. 2013. ”not not bad” is not ”bad”: Adistributional account of negation. Proceedings of theACL Workshop on Continuous Vector Space Modelsand their Compositionality.
Karl Moritz Hermann, Dipanjan Das, Jason Weston,and Kuzman Ganchev. 2014. Semantic frame iden-tification with distributed word representations. InACL.
Johannes Hoffart, Fabian M Suchanek, Klaus Berberich,and Gerhard Weikum. 2013. Yago2: A spatially andtemporally enhanced knowledge base from wikipedia.Artificial Intelligence, 194:28–61.
Mohit Iyyer, Peter Enns, Jordan Boyd-Graber, andPhilip Resnik. 2014. Political ideology detectionusing recursive neural networks.
Nal Kalchbrenner and Phil Blunsom. 2013. Recurrentconvolutional neural networks for discourse compo-sitionality. Proceedings of the 2013 Workshop onContinuous Vector Space Models and their Composi-tionality.
Adam Lally, John M Prager, Michael C McCord,BK Boguraev, Siddharth Patwardhan, James Fan,Paul Fodor, and Jennifer Chu-Carroll. 2012. Ques-tion analysis: How watson reads a clue. IBM Journalof Research and Development.
Quoc V Le and Tomas Mikolov. 2014. Distributedrepresentations of sentences and documents.
Tomas Mikolov, Kai Chen, Greg Corrado, and Jef-frey Dean. 2013. Efficient estimation of wordrepresentations in vector space. arXiv preprintarXiv:1301.3781.
Jeff Mitchell and Mirella Lapata. 2008. Vector-basedmodels of semantic composition. In ACL.
Mark Palatucci, Dean Pomerleau, Geoffrey E. Hinton,and Tom M. Mitchell. 2009. Zero-shot learning withsemantic output codes. In NIPS.
P. Pasupat and P. Liang. 2014. Zero-shot entity extrac-tion from web pages. In ACL.
Asad B Sayeed, Jordan Boyd-Graber, Bryan Rusk, andAmy Weinberg. 2012. Grammatical structures forword-level sentiment detection. In NAACL.
Dan Shen. 2007. Using semantic role to improve ques-tion answering. In EMNLP.
Richard Socher, Jeffrey Pennington, Eric H. Huang,Andrew Y. Ng, and Christopher D. Manning. 2011.Semi-Supervised Recursive Autoencoders for Predict-ing Sentiment Distributions. In EMNLP.
Richard Socher, John Bauer, Christopher D. Manning,and Andrew Y. Ng. 2013a. Parsing With Composi-tional Vector Grammars. In ACL.
Richard Socher, Danqi Chen, Christopher D. Manning,and Andrew Y. Ng. 2013b. Reasoning With NeuralTensor Networks For Knowledge Base Completion.In NIPS.
Richard Socher, Alex Perelygin, Jean Y Wu, JasonChuang, Christopher D Manning, Andrew Y Ng, andChristopher Potts. 2013c. Recursive deep models forsemantic compositionality over a sentiment treebank.In EMNLP.
Richard Socher, Quoc V Le, Christopher D Manning,and Andrew Y Ng. 2014. Grounded compositionalsemantics for finding and describing images withsentences. TACL.
Nicolas Usunier, David Buffoni, and Patrick Gallinari.2009. Ranking with ordered weighted pairwise clas-sification. In ICML.
Laurens Van der Maaten and Geoffrey Hinton. 2008.Visualizing data using t-sne. JMLR.
Mengqiu Wang, Noah A. Smith, and Teruko Mita-mura. 2007. What is the Jeopardy model? a quasi-synchronous grammar for QA. In EMNLP.

Mengqiu Wang. 2006. A survey of answer extractiontechniques in factoid question answering. Computa-tional Linguistics, 1(1).
Jason Weston, Samy Bengio, and Nicolas Usunier. 2011.Wsabie: Scaling up to large vocabulary image anno-tation. In IJCAI.
Ainur Yessenalina and Claire Cardie. 2011. Compo-sitional matrix-space models for sentiment analysis.In EMNLP.
Fabio Massimo Zanzotto, Ioannis Korkontzelos,Francesca Fallucchi, and Suresh Manandhar. 2010.Estimating linear models for compositional distribu-tional semantics. In COLT.


















