
A Micro-Benchmark Suite for Evaluating Hadoop MapReduce …...Hadoop MapReduce 5 Performance of...
38
Dip$ Shankar, Xiaoyi Lu, Md. WasiurRahman, Nusrat Islam, and Dhabaleswar K. (DK) Panda NetworkBased Compu2ng Laboratory Department of Computer Science and Engineering The Ohio State University, Columbus, OH, USA A Micro-Benchmark Suite for Evaluating Hadoop MapReduce on High-Performance Networks
Transcript of A Micro-Benchmark Suite for Evaluating Hadoop MapReduce …...Hadoop MapReduce 5 Performance of...

Dip$ Shankar, Xiaoyi Lu, Md. Wasi-‐ur-‐Rahman, Nusrat Islam, and Dhabaleswar K. (DK) Panda
Network-‐Based Compu2ng Laboratory
Department of Computer Science and Engineering The Ohio State University, Columbus, OH, USA
A Micro-Benchmark Suite for Evaluating Hadoop MapReduce on High-Performance Networks

BPOE-5 2014
Outline
• Introduc$on & Mo$va$on
• Design Considera$ons • Micro-‐benchmark Suite
• Performance Evalua$on
• Case Study with RDMA
• Conclusion & Future work
2

BPOE-5 2014
Big Data Technology - Hadoop
Hadoop Distributed File System (HDFS)
MapReduce (Cluster Resource Management & Data
Processing)
Hadoop Common/Core (RPC, ..)
Hadoop Distributed File System (HDFS)
YARN (Cluster Resource Management & Job
Scheduling)
Hadoop Common/Core (RPC, ..)
MapReduce (Data Processing)
Other Models (Data Processing)
Hadoop 1.x Hadoop 2.x
• Apache Hadoop is one of the most popular Big Data technology – Provides frameworks for large-scale, distributed data storage and
processing – MapReduce, HDFS, YARN, RPC, etc.
3
BPOE-5 2014 4
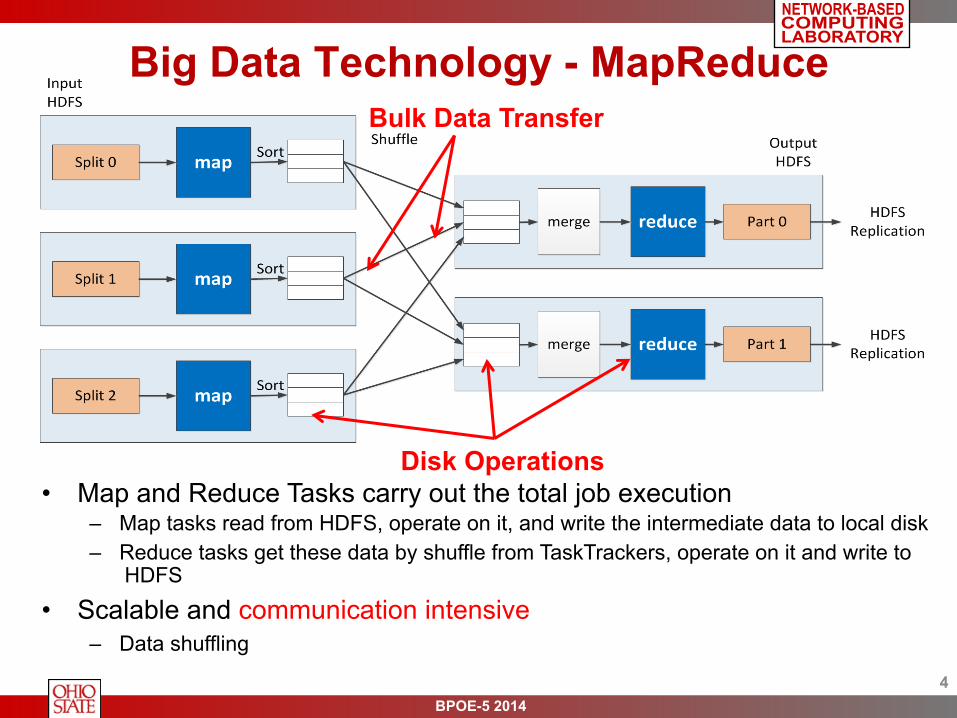
Big Data Technology - MapReduce
Disk Operations • Map and Reduce Tasks carry out the total job execution
– Map tasks read from HDFS, operate on it, and write the intermediate data to local disk – Reduce tasks get these data by shuffle from TaskTrackers, operate on it and write to
HDFS • Scalable and communication intensive
– Data shuffling
Bulk Data Transfer

BPOE-5 2014
Factors Effecting Performance of Hadoop MapReduce
5
Performance of Hadoop MapReduce is influenced by many factors • Network configuration of cluster • Multi-core architecture • Memory system • Underlying storage system
– Example: HDFS, Lustre etc.
• Controllable parameters in software – Number of Mappers and Reducers, Partitioning scheme used
• Many others …

BPOE-5 2014
Common Protocols using Open Fabrics
6 WBDB 2013
Common"Protocols"using"Open"Fabrics"
�
Applica-on&
Verbs&Sockets&
ApplicaAon"Interface"
SDP
RDMA&
SDP&
InfiniBand&Adapter&
InfiniBand&Switch&
RDMA&
IB&Verbs&
InfiniBand&Adapter&
InfiniBand&Switch&
User space
RDMA&
RoCE&
RoCE&Adapter&
User space
Ethernet&Switch&
TCP/IP&
Ethernet&Driver&
Kernel Space
Protocol"
InfiniBand&Adapter&
InfiniBand&Switch&
IPoIB&
Ethernet&Adapter&
Ethernet&Switch&
Adapter"
Switch"
1/10/40&
GigE&
iWARP&
Ethernet&Switch&
iWARP&
iWARP&Adapter&
User space IPoIB&
TCP/IP&
Ethernet&Adapter&
Ethernet&Switch&
10/40&GigEL
TOE&
Hardware"Offload"
RSockets&
InfiniBand&Adapter&
InfiniBand&Switch&
User space
RSockets&

BPOE-5 2014
Can High-Performance Networks Benefit Big Data Processing? • Previous studies: very good performance improvements for Hadoop (HDFS
/MapReduce/RPC), Spark, HBase, Memcached over InfiniBand/RoCE – Hadoop Acceleration with RDMA
• N. S. Islam, et.al., SOR-HDFS: A SEDA-based Approach to Maximize Overlapping in RDMA-Enhanced HDFS, HPDC’14
• N. S. Islam, et.al., High Performance RDMA-Based Design of HDFS over InfiniBand, SC’12 • M. W. Rahman, et.al. HOMR: A Hybrid Approach to Exploit Maximum Overlapping in
MapReduce over High Performance Interconnects, ICS’14 • M. W. Rahman, et.al., High-Performance RDMA-based Design of Hadoop MapReduce over
InfiniBand, HPDIC’13 • X. Lu, et. al., High-Performance Design of Hadoop RPC with RDMA over InfiniBand, ICPP’13
– Spark Acceleration with RDMA • X. Lu, et. al., Accelerating Spark with RDMA for Big Data Processing: Early Experiences,
HotI'14
– HBase Acceleration with RDMA • J. Huang, et.al., High-Performance Design of HBase with RDMA over InfiniBand, IPDPS’12
– Memcached Acceleration with RDMA • J. Jose, et. al., Scalable Memcached design for InfiniBand Clusters using Hybrid Transports,
Cluster’11 • J. Jose, et.al., Memcached Design on High Performance RDMA Capable Interconnects,
ICPP’11 7

BPOE-5 2014
• RDMA for Apache Hadoop 2.x (RDMA-Hadoop-2.x)
• RDMA for Apache Hadoop 1.x (RDMA-Hadoop)
• RDMA for Memcached (RDMA-Memcached)
• OSU HiBD-Benchmarks (OHB)
• http://hibd.cse.ohio-state.edu
• RDMA for Apache HBase and Spark
The High-Performance Big Data (HiBD) Project
8

BPOE-5 2014
RDMA for Apache Hadoop 1.x/2.x Distributions
http://hibd.cse.ohio-state.edu
• High-Performance Design of Hadoop over RDMA-enabled Interconnects
– High performance design with native InfiniBand and RoCE support at the verbs-level for HDFS, MapReduce, and RPC components
– Easily configurable for native InfiniBand, RoCE and the traditional sockets-based support (Ethernet and InfiniBand with IPoIB)
• Current release: 0.9.9 (03/31/14) – Based on Apache Hadoop 1.2.1
– Compliant with Apache Hadoop 1.2.1 APIs and applications
– Tested with
• Mellanox InfiniBand adapters (DDR, QDR and FDR)
• RoCE support with Mellanox adapters
• Various multi-core platforms, different file systems with disks and SSDs
• RDMA for Apache Hadoop 2.x 0.9.1 is released in HiBD!
9

BPOE-5 2014 HPDIC 2013
MapReduce RDMA Design Overview
• Enables high performance RDMA communication, while supporting traditional socket interface
• JNI Layer bridges Java based MapReduce with communication library (UCR) written in native code
10
MapReduce
IB Verbs
RDMA Capable Networks
(IB, 10GE/ iWARP, RoCE ..)
OSU-IB Design
Applications
1/10 GigE Network
Java Socket Interface
Java Native Interface (JNI)
Job Tracker
Task Tracker
Map
Reduce
Design features for RDMA
¾ Prefetch/Caching of MOF
¾ In-Memory Merge
¾ Overlap of Merge &Reduce
Design Overview of MapReduce with RDMA • Enables high performance RDMA
communication, while supporting traditional socket interface
• JNI Layer bridges Java based MapReduce with communication library written in native code
• Design features – RDMA-based shuffle – Prefetching and caching map output – Efficient Shuffle Algorithms – In-memory merge – On-demand Shuffle Adjustment – Advanced overlapping
• map, shuffle, and merge • shuffle, merge, and reduce
– On-demand connection setup – InfiniBand/RoCE support
M. Wasi-ur-Rahman et al., HOMR: A Hybrid Approach to Exploit Maximum Overlapping in MapReduce over High Performance Interconnects, ICS’14
M. Wasi-ur-Rahman et al., High-Performance RDMA-based Design of Hadoop MapReduce over InfiniBand, HPDIC'13 10

BPOE-5 2014
Existing Benchmarks for Evaluating Hadoop MapReduce
11
Evaluation of performance Hadoop MapReduce job Micro-benchmarks Description
Sort Sort random data, I/O bound
TeraSort Sort in total order, Map Stage is CPU bound, Reduce Stage is I/O bound
Wordcount CPU bound, Heavy use of partitioner
Other Benchmarks Description HiBench Representative and comprehensive suite with both
synthetic micro-benchmarks and real-world workloads
MRBS Five benchmarks covering several application domains for evaluating the dependability of MapReduce systems
MRBench Focuses on processing business oriented queries and concurrent data modifications
PUMA Represents broad range of MapReduce applications with high/low computation and high/low shuffle volumes
SWIM Real life MapReduce workloads from production systems, workload synthesis and replay tools for sampling traces

BPOE-5 2014
Existing Benchmarks for Evaluating Hadoop MapReduce (contd.)
12
• All benchmarks mentioned require the involvement of HDFS or some distributed file system – Interferes in the evaluation of the MapReduce’s performance
– Hard to benchmark and compare different shuffle and sort schemes
– Benchmarks do not provision us to study different shuffle patterns and impact of network protocols on them
• Requirement: we need a way to evaluate MapReduce as an independent component ! – To illustrate performance improvement and potential of new
MapReduce designs
– To help tune internal parameters specific to MapReduce and obtain optimal performance over high-performance networks

BPOE-5 2014
Can we benefit from a stand-alone MapReduce Micro-benchmark?
13
• Can we design a simple micro-benchmark suite – That lets users and developers evaluate Hadoop MapReduce
in a stand-alone manner over different networks or protocols? – Helps tune and optimize configurable parameters based on
cluster and workload characteristics? – Helps us evaluate the performance of new or alternate
MapReduce frameworks such as our proposed MapReduce over RDMA design?
– That provisions studying the impact of different data distribution patterns, data types, etc., on the performance of the MapReduce job?
• What will be the performance of stand-alone Hadoop MapReduce when evaluated on different high-performance networks?
• Basic motivation!

BPOE-5 2014
Outline
• Introduc$on & Mo$va$on
• Design Considera$ons • Micro-‐benchmark Suite
• Performance Evalua$on
• Case Study with RDMA
• Conclusion & Future work
14
BPOE-5 2014
,QWHUPHGLDWH�'DWD�
'LVWULEXWLRQ 6L]H�DQG�QXPEHU�RI�NH\�YDOXH�SDLUV
1XPEHU�RI�PDS�DQG�
UHGXFH�WDVNV
'DWD�7\SH�RI�NH\�YDOXH�SDLUV
1HWZRUN�&RQILJXUDWLRQ
5HVRXUFH�8WLOL]DWLRQ�
�&38�QHWZRUN�
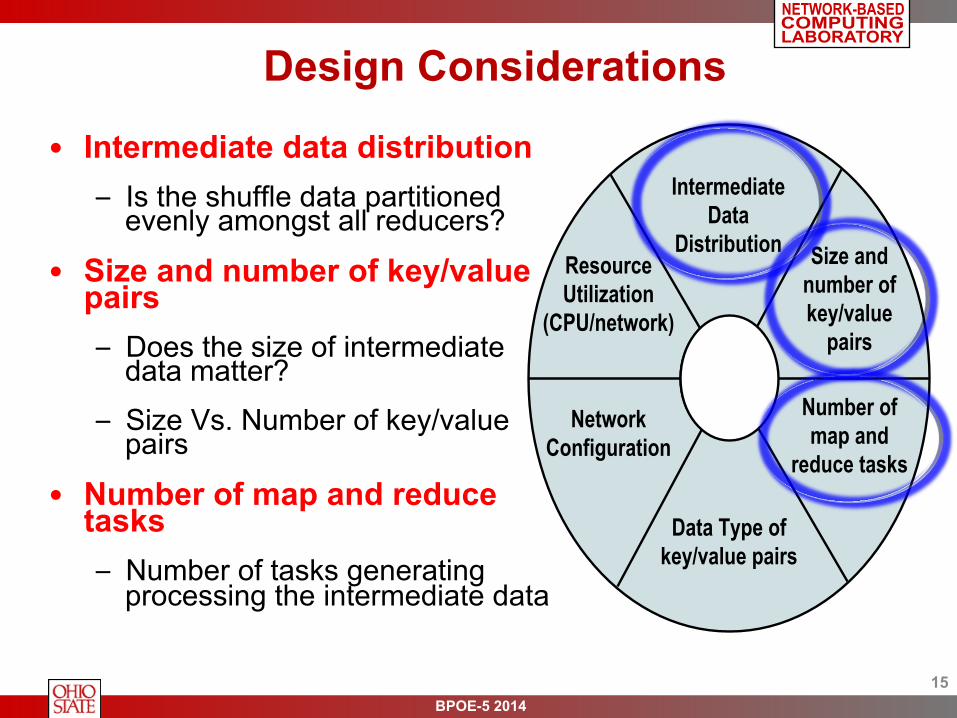
Design Considerations
15
• Intermediate data distribution – Is the shuffle data partitioned
evenly amongst all reducers?
• Size and number of key/value pairs – Does the size of intermediate
data matter?
– Size Vs. Number of key/value pairs
• Number of map and reduce tasks – Number of tasks generating
processing the intermediate data
BPOE-5 2014
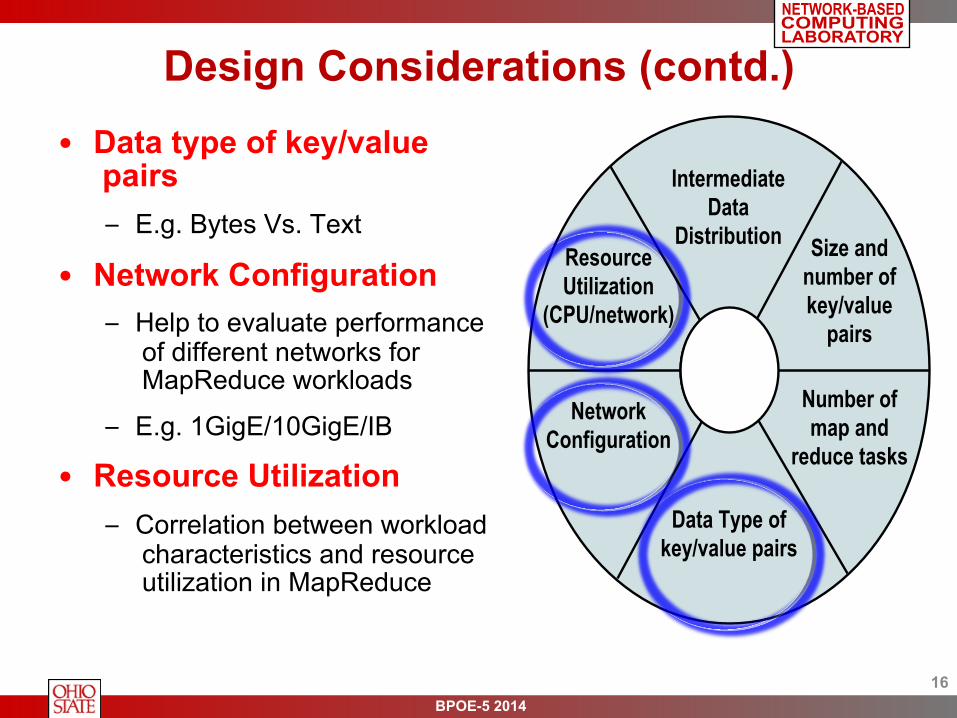
Design Considerations (contd.)
• Data type of key/value pairs – E.g. Bytes Vs. Text
• Network Configuration – Help to evaluate performance
of different networks for MapReduce workloads
– E.g. 1GigE/10GigE/IB
• Resource Utilization – Correlation between workload
characteristics and resource utilization in MapReduce
16
,QWHUPHGLDWH�'DWD�
'LVWULEXWLRQ 6L]H�DQG�QXPEHU�RI�NH\�YDOXH�SDLUV
1XPEHU�RI�PDS�DQG�
UHGXFH�WDVNV
'DWD�7\SH�RI�NH\�YDOXH�SDLUV
1HWZRUN�&RQILJXUDWLRQ
5HVRXUFH�8WLOL]DWLRQ�
�&38�QHWZRUN�

BPOE-5 2014
Outline
• Introduc$on & Mo$va$on
• Design Considera$ons • Micro-‐benchmark Suite
• Performance Evalua$on
• Case Study with RDMA
• Conclusion & Future work
17

BPOE-5 2014
MapReduce Micro-Benchmark Suite
18
• Evaluate the performance of stand-alone MapReduce – Does not require or involve HDFS or any distributed file
system
• Considers various factors that influence the data shuffling phase – Underlying network configuration, number of map and reduce tasks,
intermediate shuffle data pattern, shuffle data size etc.
• Currently supports three different shuffle data distribution patterns – Average data distribution: intermediate data is evenly distributed
among reduce tasks – Random data distribution: intermediate data is pseudo-randomly
distributed among reduce tasks – Skewed data distribution: intermediate data is unevenly
distributed among reduce tasks
BPOE-5 2014 19
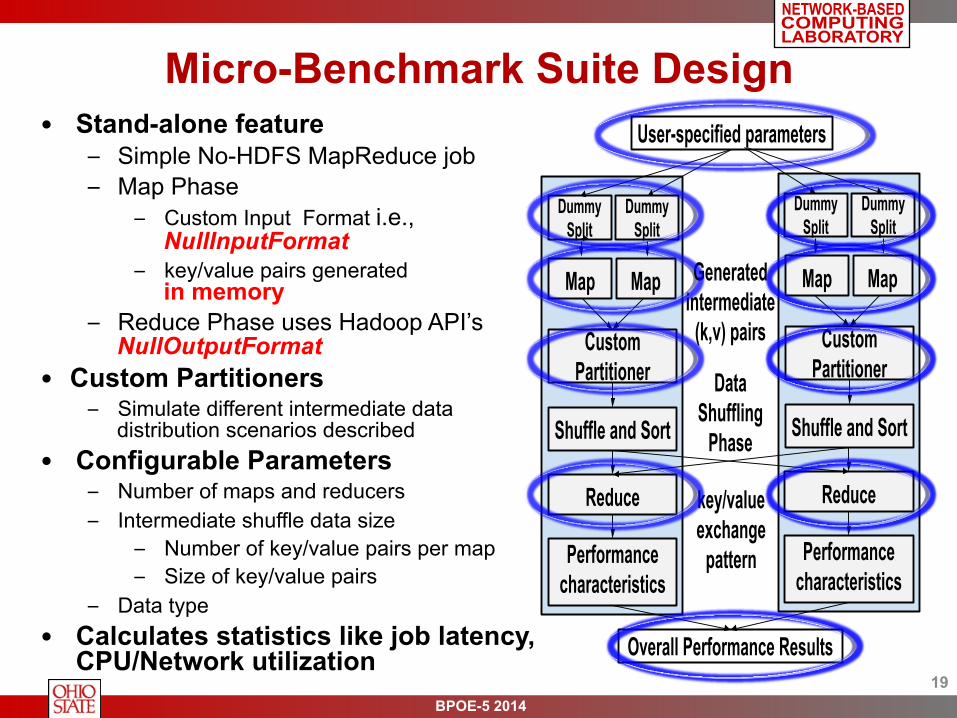
Micro-Benchmark Suite Design
&XVWRP�3DUWLWLRQHU
6KXIIOH�DQG�6RUW
5HGXFH
3HUIRUPDQFH�FKDUDFWHULVWLFV
'XPP\�6SOLW
8VHU�VSHFLILHG�SDUDPHWHUV
&XVWRP�3DUWLWLRQHU
6KXIIOH�DQG�6RUW
'XPP\�6SOLW
'XPP\�6SOLW
'XPP\�6SOLW
0DS0DS0DS 0DS
2YHUDOO�3HUIRUPDQFH�5HVXOWV
5HGXFH
3HUIRUPDQFH�FKDUDFWHULVWLFV
'DWD�6KXIIOLQJ3KDVH
*HQHUDWHG�LQWHUPHGLDWH��N�Y��SDLUV
NH\�YDOXH�H[FKDQJH�SDWWHUQ
• Stand-alone feature – Simple No-HDFS MapReduce job – Map Phase
– Custom Input Format i.e., NullInputFormat
– key/value pairs generated in memory
– Reduce Phase uses Hadoop API’s NullOutputFormat
• Custom Partitioners – Simulate different intermediate data
distribution scenarios described • Configurable Parameters
– Number of maps and reducers – Intermediate shuffle data size
– Number of key/value pairs per map – Size of key/value pairs
– Data type • Calculates statistics like job latency,
CPU/Network utilization

BPOE-5 2014
MapReduce Micro-Benchmarks
20
Three MapReduce Micro-benchmarks defined 1) MR-AVG micro-benchmark • Intermediate data is evenly distributed among reduce tasks • Custom partitioner distributes same number of intermediate
key/value pairs amongst the reducers in a round-robin fashion
• Uniform distribution and fair comparison for all runs 2) MR-RAND micro-benchmark • Intermediate data is pseudo-randomly distributed among
reduce tasks • Custom partitioner picks a reducer randomly and assigns the
key/value pair to it • Fair comparison for all runs on homogenous systems

BPOE-5 2014
MapReduce Micro-Benchmarks (contd.)
21
3) MR-SKEW micro-benchmark • Intermediate data is unevenly distributed among reduce
tasks • Custom partitioner uses fixed skewed distribution
pattern – 50% to reducer 0 – 25% to reducer 1 – 12.5% to reducer 2 – …
• Skewed distribution pattern is fixed for all runs • Fair comparison for all runs on homogenous systems

BPOE-5 2014
Outline
• Introduc$on & Mo$va$on
• Design Considera$ons • Micro-‐benchmark Suite
• Performance Evalua$on
• Case Study with RDMA
• Conclusion & Future work
22

BPOE-5 2014
Experimental Setup • Hardware
– Intel Westmere Cluster (A) (Up to 9 nodes) • Each node has 8 processor cores on 2 Intel Xeon 2.67 GHz
quad-core CPUs, 24 GB main memory • Mellanox QDR HCAs (32 Gbps) + 10GigE
– TACC Stampede Cluster (B) (Up to 17 nodes) • Intel Sandy Bridge (E5-2680) dual octa-core processors,
running at 2.70GHz, 32 GB main memory • Mellanox FDR HCAs (56 Gbps)
– Performance comparisons over 1 GigE, 10 GigE, IPoIB (32 Gbps) and, IPoIB (56 Gbps)
• Software – JDK 1.7.0 – Apache Hadoop 1.2.1 – Apache Hadoop NextGen MapReduce (YARN) 2.4.1
23
BPOE-5 2014
Performance Evaluation with Different Data Distribution Patterns
0
500
1,000
1,500
2,000
2,500
3,000
3,500
4,000
16 32 64 128
Job
Exe
cutio
n T
ime(
seco
nds)
Shuffle Data Size(GB)
1GigE10GigEIPoIB (32Gbps)
0 500
1,000 1,500 2,000 2,500 3,000 3,500 4,000 4,500
16 32 64 128
Job
Exe
cutio
n T
ime(
seco
nds)
Shuffle Data Size(GB)
1GigE10GigEIPoIB (32Gbps)
24
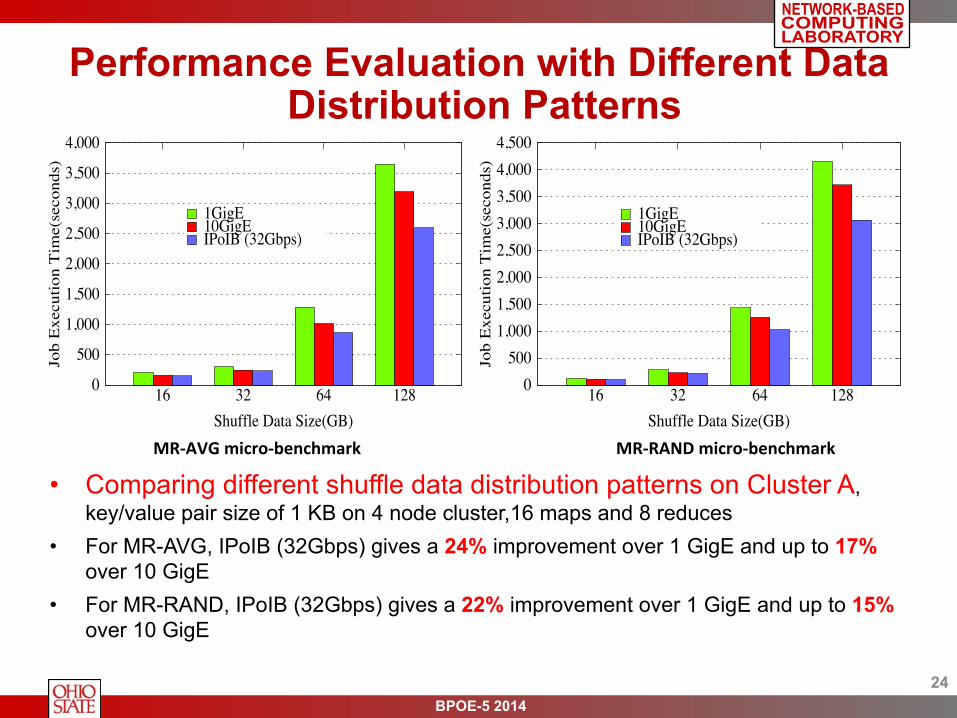
• Comparing different shuffle data distribution patterns on Cluster A, key/value pair size of 1 KB on 4 node cluster,16 maps and 8 reduces
• For MR-AVG, IPoIB (32Gbps) gives a 24% improvement over 1 GigE and up to 17% over 10 GigE
• For MR-RAND, IPoIB (32Gbps) gives a 22% improvement over 1 GigE and up to 15% over 10 GigE
MR-‐AVG micro-‐benchmark MR-‐RAND micro-‐benchmark
BPOE-5 2014
Performance Evaluation with Different Data Distribution Patterns
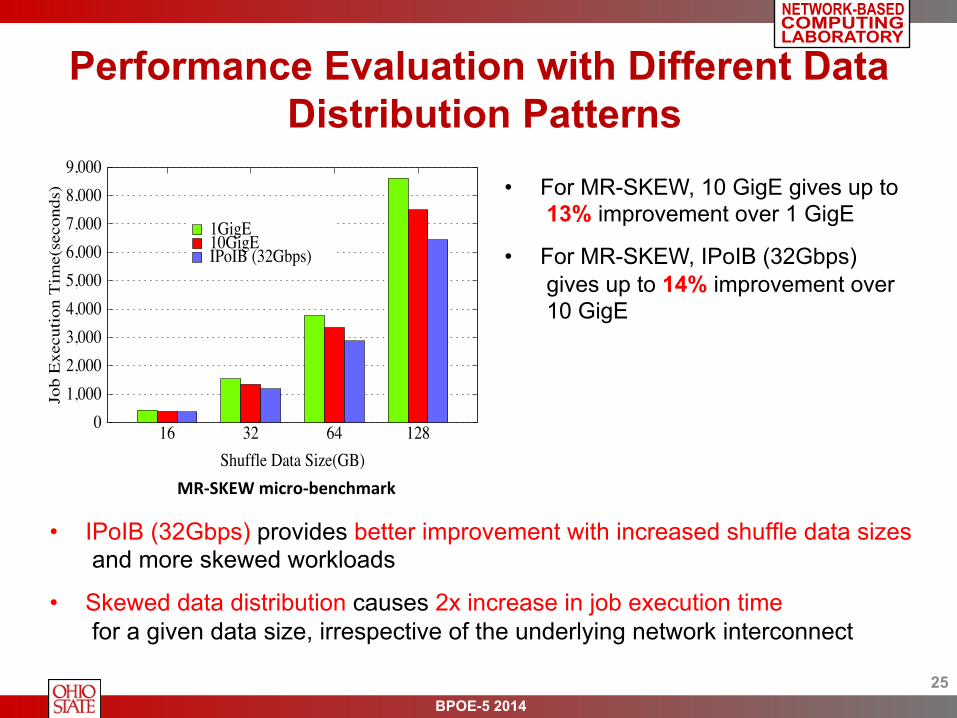
• IPoIB (32Gbps) provides better improvement with increased shuffle data sizes and more skewed workloads
• Skewed data distribution causes 2x increase in job execution time for a given data size, irrespective of the underlying network interconnect
0 1,000 2,000 3,000 4,000 5,000 6,000 7,000 8,000 9,000
16 32 64 128
Job
Exe
cutio
n T
ime(
seco
nds)
Shuffle Data Size(GB)
1GigE10GigEIPoIB (32Gbps)
MR-‐SKEW micro-‐benchmark
25
• For MR-SKEW, 10 GigE gives up to 13% improvement over 1 GigE
• For MR-SKEW, IPoIB (32Gbps) gives up to 14% improvement over 10 GigE
BPOE-5 2014
Performance Evaluation with Apache Hadoop NextGen MapReduce (YARN)
0 100 200 300 400 500 600 700 800 900
8 16 32 64 128
Job
Exec
utio
n Ti
me(
seco
nds)
Shuffle Data Size(GB)
1GigE10GigEIPoIB (32Gbps)
0 100 200 300 400 500 600 700 800 900
8 16 32 64 128
Job
Exec
utio
n Ti
me(
seco
nds)
Shuffle Data Size(GB)
1GigE10GigEIPoIB (32Gbps)
26
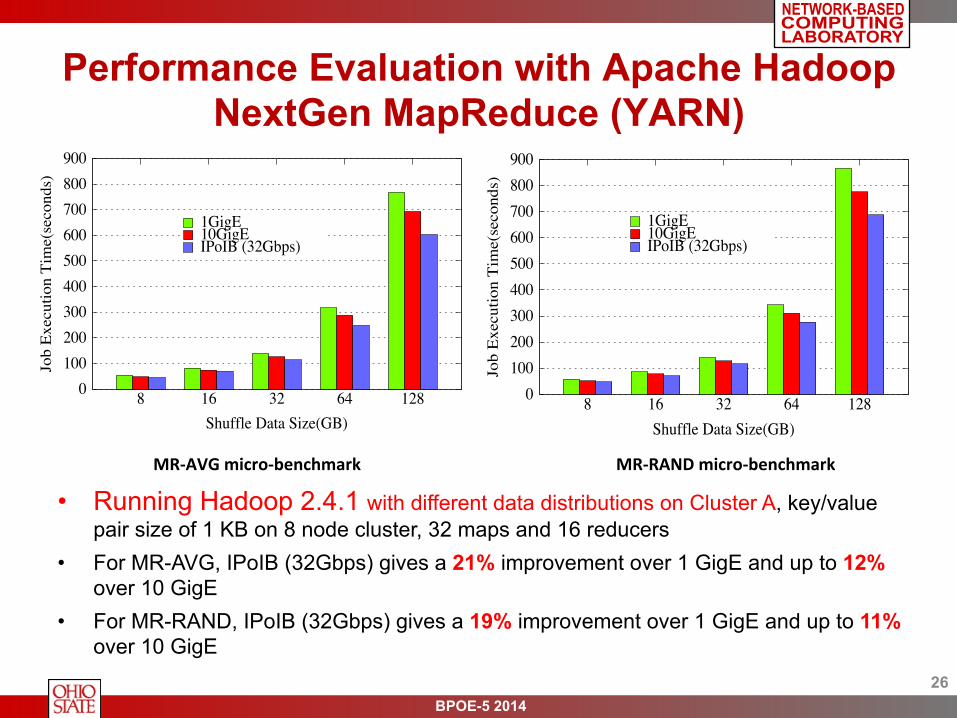
• Running Hadoop 2.4.1 with different data distributions on Cluster A, key/value pair size of 1 KB on 8 node cluster, 32 maps and 16 reducers
• For MR-AVG, IPoIB (32Gbps) gives a 21% improvement over 1 GigE and up to 12% over 10 GigE
• For MR-RAND, IPoIB (32Gbps) gives a 19% improvement over 1 GigE and up to 11% over 10 GigE
MR-‐AVG micro-‐benchmark MR-‐RAND micro-‐benchmark
BPOE-5 2014
Performance Evaluation with Apache Hadoop NextGen MapReduce (YARN)
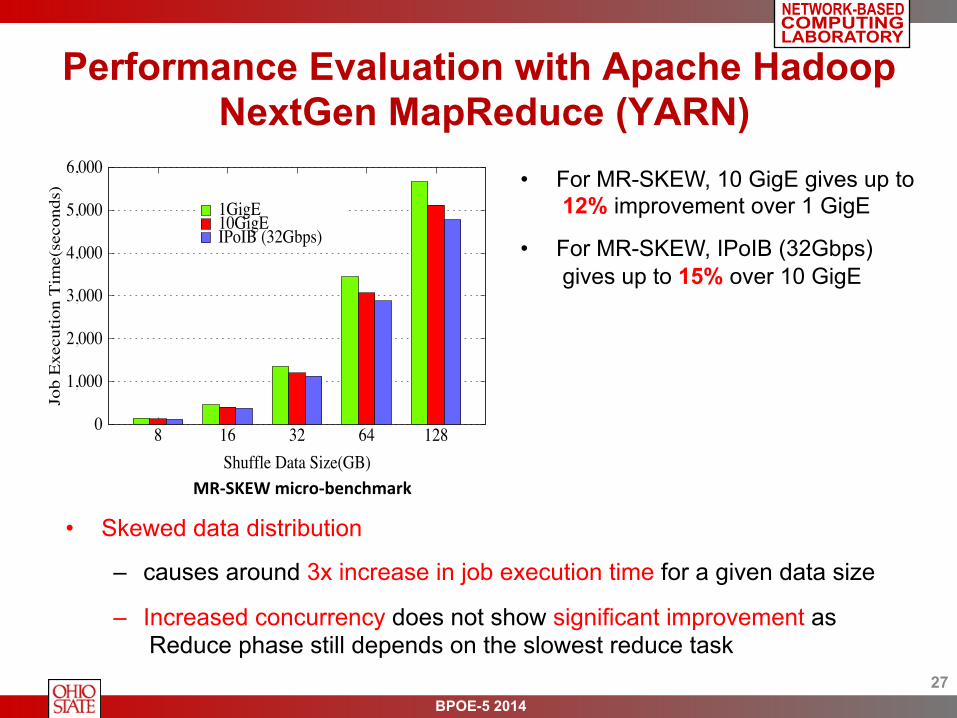
• Skewed data distribution
– causes around 3x increase in job execution time for a given data size
– Increased concurrency does not show significant improvement as Reduce phase still depends on the slowest reduce task
0
1,000
2,000
3,000
4,000
5,000
6,000
8 16 32 64 128
Job
Exe
cutio
n T
ime(
seco
nds)
Shuffle Data Size(GB)
1GigE10GigEIPoIB (32Gbps)
MR-‐SKEW micro-‐benchmark
27
• For MR-SKEW, 10 GigE gives up to 12% improvement over 1 GigE
• For MR-SKEW, IPoIB (32Gbps) gives up to 15% over 10 GigE

BPOE-5 2014
Performance Evaluation with Varying Key/Value Pair Sizes
0 50
100 150 200 250 300 350 400
4 8 16 32
Job
Exe
cutio
n T
ime(
seco
nds)
Shuffle Data Size(GB)
1GigE10GigEIPoIB (32Gbps)
0
50
100
150
200
250
300
4 8 16 32
Job
Exe
cutio
n T
ime(
seco
nds)
Shuffle Data Size(GB)
1GigE10GigEIPoIB (32Gbps)
28
• MR-AVG on Cluster A, on 4 node cluster, 16 maps and 8 reduces • For both key/value pair sizes, IPoIB (32Gbps) gives up to
• 22-24% improvement over 1 GigE and • 10-13% improvement over 10 GigE
• Increasing key/value pair sizes lowers job execution time for a given shuffle data size
MR-‐AVG micro-‐benchmark with 100 B key/value size MR-‐AVG micro-‐benchmark with 10 KB key/value size

BPOE-5 2014
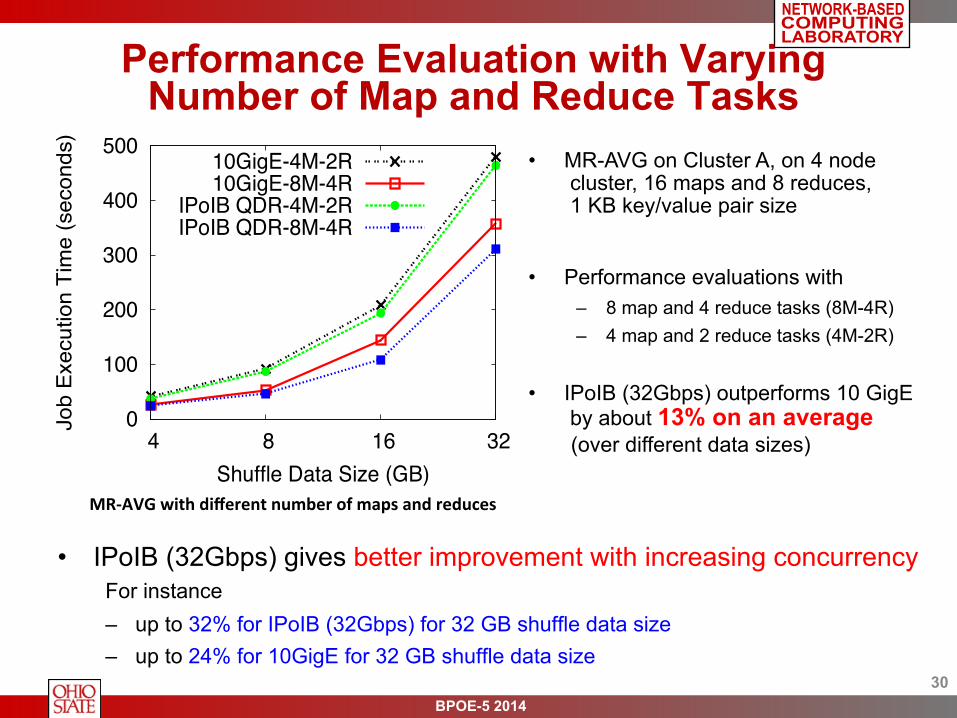
Performance Evaluation with Varying Number of Map and Reduce Tasks
• IPoIB (32Gbps) gives better improvement with increasing concurrency For instance – up to 32% for IPoIB (32Gbps) for 32 GB shuffle data size – up to 24% for 10GigE for 32 GB shuffle data size
0
100
200
300
400
500
4 8 16 32
Job
Exec
utio
n Ti
me
(sec
onds
)
Shuffle Data Size (GB)
10GigE-4M-2R10GigE-8M-4R
IPoIB QDR-4M-2RIPoIB QDR-8M-4R
MR-‐AVG with different number of maps and reduces
29
• MR-AVG on Cluster A, on 4 node cluster, 16 maps and 8 reduces, 1 KB key/value pair size
• Performance evaluations with – 8 map and 4 reduce tasks (8M-4R) – 4 map and 2 reduce tasks (4M-2R)
• IPoIB (32Gbps) outperforms 10 GigE by about 13% on an average (over different data sizes)
BPOE-5 2014
Performance Evaluation with Varying Number of Map and Reduce Tasks
• IPoIB (32Gbps) gives better improvement with increasing concurrency For instance – up to 32% for IPoIB (32Gbps) for 32 GB shuffle data size – up to 24% for 10GigE for 32 GB shuffle data size
0
100
200
300
400
500
4 8 16 32
Job
Exec
utio
n Ti
me
(sec
onds
)
Shuffle Data Size (GB)
10GigE-4M-2R10GigE-8M-4R
IPoIB QDR-4M-2RIPoIB QDR-8M-4R
MR-‐AVG with different number of maps and reduces
30
• MR-AVG on Cluster A, on 4 node cluster, 16 maps and 8 reduces, 1 KB key/value pair size
• Performance evaluations with – 8 map and 4 reduce tasks (8M-4R) – 4 map and 2 reduce tasks (4M-2R)
• IPoIB (32Gbps) outperforms 10 GigE by about 13% on an average (over different data sizes)

BPOE-5 2014
Performance Evaluation with Different Data Types
0 200 400 600 800
1000 1200 1400 1600 1800
4 8 16 32 64
Job
Exec
utio
n Ti
me
(sec
onds
)
Shuffle Data Size (GB)
1GigE10GigE
IPoIB (32Gbps)
0 200 400 600 800
1000 1200 1400 1600 1800
4 8 16 32 64
Job
Exec
utio
n Ti
me
(sec
onds
)
Shuffle Data Size (GB)
1GigE10GigE
IPoIB (32Gbps)
31
• MR-RAND on Cluster A, key/value pair size of 1 KB on 4 node cluster, 16 maps and 8 reducers
• For both BytesWritable and Text Data Type, IPoIB (32Gbps) shows,
• significant improvement potential for larger data sizes over 10 GigE on an average
• similar improvement potential to both types
MR-‐RAND micro-‐benchmark with BytesWritable MR-‐RAND micro-‐benchmark with Text
BPOE-5 2014
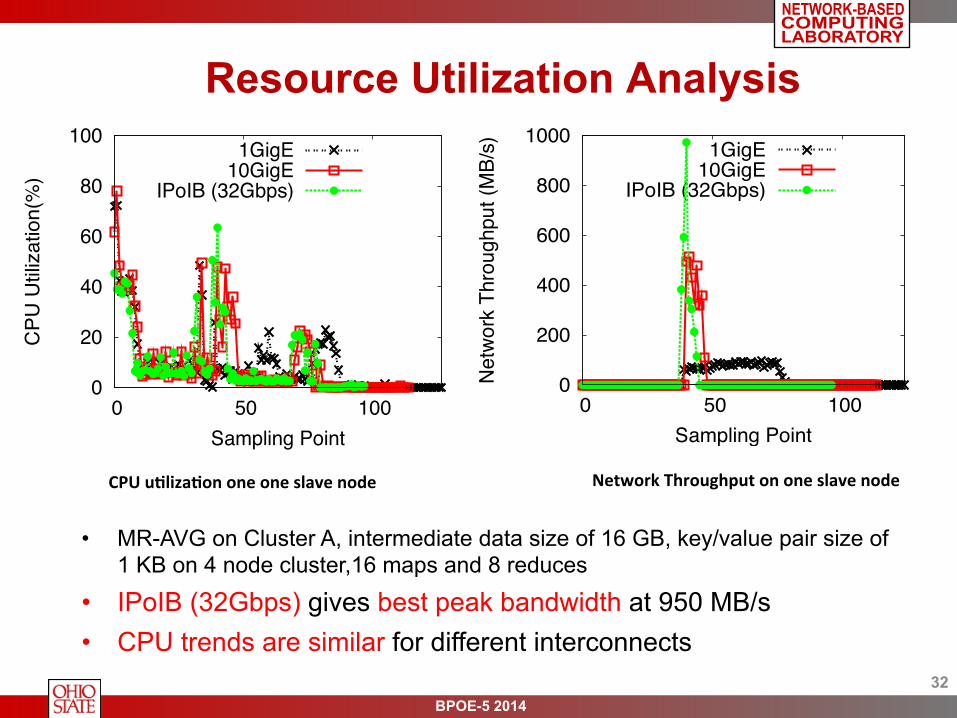
Resource Utilization Analysis
0
20
40
60
80
100
0 50 100
CPU
Util
izat
ion(
%)
Sampling Point
1GigE10GigE
IPoIB (32Gbps)
0
200
400
600
800
1000
0 50 100
Netw
ork
Thro
ughp
ut (M
B/s)
Sampling Point
1GigE10GigE
IPoIB (32Gbps)
32
• MR-AVG on Cluster A, intermediate data size of 16 GB, key/value pair size of 1 KB on 4 node cluster,16 maps and 8 reduces
• IPoIB (32Gbps) gives best peak bandwidth at 950 MB/s • CPU trends are similar for different interconnects
CPU uPlizaPon one one slave node Network Throughput on one slave node

BPOE-5 2014
Outline
• Introduc$on & Mo$va$on
• Design Considera$ons • Micro-‐benchmark Suite
• Performance Evalua$on
• Case Study with RDMA
• Conclusion &Future Work
33
BPOE-5 2014
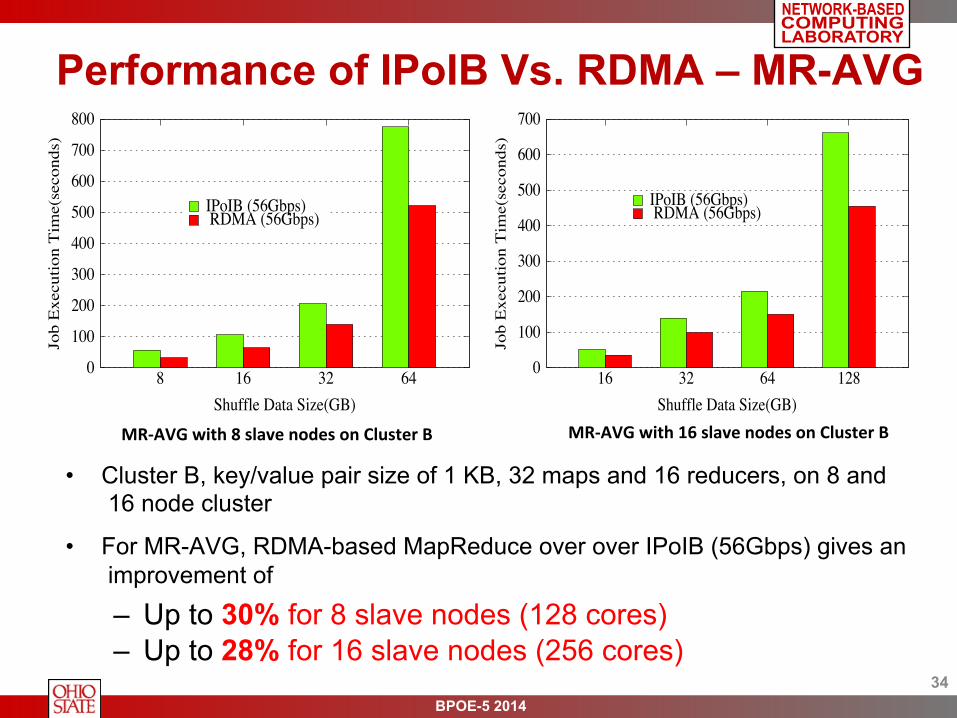
Performance of IPoIB Vs. RDMA – MR-AVG
• Cluster B, key/value pair size of 1 KB, 32 maps and 16 reducers, on 8 and 16 node cluster
• For MR-AVG, RDMA-based MapReduce over over IPoIB (56Gbps) gives an improvement of
– Up to 30% for 8 slave nodes (128 cores) – Up to 28% for 16 slave nodes (256 cores)
0
100
200
300
400
500
600
700
800
8 16 32 64
Job
Exe
cutio
n T
ime(
seco
nds)
Shuffle Data Size(GB)
IPoIB (56Gbps) RDMA (56Gbps)
0
100
200
300
400
500
600
700
16 32 64 128
Job
Exe
cutio
n T
ime(
seco
nds)
Shuffle Data Size(GB)
IPoIB (56Gbps) RDMA (56Gbps)
MR-‐AVG with 8 slave nodes on Cluster B MR-‐AVG with 16 slave nodes on Cluster B
34
BPOE-5 2014
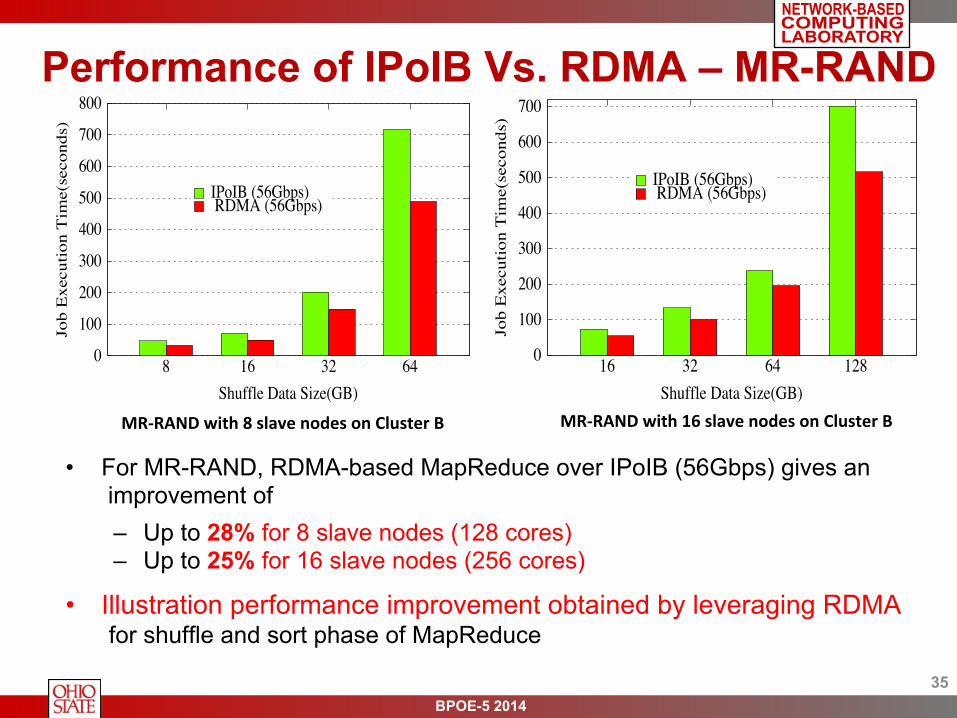
Performance of IPoIB Vs. RDMA – MR-RAND
• For MR-RAND, RDMA-based MapReduce over IPoIB (56Gbps) gives an improvement of – Up to 28% for 8 slave nodes (128 cores) – Up to 25% for 16 slave nodes (256 cores)
• Illustration performance improvement obtained by leveraging RDMA for shuffle and sort phase of MapReduce
0
100
200
300
400
500
600
700
800
8 16 32 64
Job
Exe
cutio
n T
ime(
seco
nds)
Shuffle Data Size(GB)
IPoIB (56Gbps) RDMA (56Gbps)
0
100
200
300
400
500
600
700
16 32 64 128
Job
Exe
cutio
n T
ime(
seco
nds)
Shuffle Data Size(GB)
IPoIB (56Gbps) RDMA (56Gbps)
MR-‐RAND with 8 slave nodes on Cluster B MR-‐RAND with 16 slave nodes on Cluster B
35

BPOE-5 2014
Outline
• Introduc$on & Mo$va$on
• Design Considera$ons • Micro-‐benchmark Suite
• Performance Evalua$on
• Case Study with RDMA
• Conclusion & Future work
36

BPOE-5 2014
Conclusion and Future Work • Study of factors that can significantly impact performance
of Hadoop MapReduce (like network protocol etc.)
• Design, development and implementation of a micro- benchmark suite for stand-alone MapReduce – Help developers enhance their MapReduce designs – Support for both Hadoop 1.x and 2.x
• Performance evaluations with our micro-benchmark suite over different interconnects on modern clusters
• Future Work – Enhance micro-benchmark suite to real-world workloads – Investigate more data types – Make the micro-benchmarks publicly available through the HiBD
project (OHB) 37

BPOE-5 2014
Thank You! {shankard, luxi, rahmanmd, islamn, panda}
@cse.ohio-‐state.edu
Network-‐Based Compu$ng Laboratory h\p://nowlab.cse.ohio-‐state.edu/
The High-‐Performance Big Data Project h\p://hibd.cse.ohio-‐state.edu/
38


















