
A hybrid SVM/DDBHMM decision fusion modeling for robust continuous digital speech recognition
9
A hybrid SVM/DDBHMM decision fusion modeling for robust continuous digital speech recognition Jingwei Liu a,b, * , Zuoying Wang b , Xi Xiao b a LMIB & Department of Mathematics, Beijing University of Aeronautics and Astronautics, Beijing 100083, PR China b Department of Electronics Engineering, Tsinghua University, Beijing 100084, PR China Received 2 April 2004; received in revised form 14 December 2006 Available online 23 December 2006 Communicated by M.A.T. Figueiredo Abstract This paper proposes an improved hybrid support vector machine and duration distribution based hidden Markov (SVM/DDBHMM) decision fusion model for robust continuous digital speech recognition. We investigate the probability outputs combination of support vector machine and Gaussian mixture model in pattern recognition (called FSVM),and embed the fusion probability as similarity into the phone state level decision space of our duration distribution based hidden Markov model (DDBHMM) speech recognition system (named FSVM/DDBHMM). The performances of FSVM and FSVM/DDBHMM are demonstrated in Iris database and continuous mandarin digital speech corpus in 4 noise environments (white, volvo, babble and destroyerengine) from NOISEX-92. The experimental results show the effectiveness of FSVM in Iris data, and the improvement of average word error rate reduction of FSVM/DDBHMM from 6% to 20% compared with the DDBHMM baseline at various signal noise ratios (SNRs) from 5 dB to 30 dB by step of 5 dB. Ó 2007 Elsevier B.V. All rights reserved. Keywords: Speech recognition; Gaussian mixture model; Duration distribution based hidden Markov model (DDBHMM); Support vector machine 1. Introduction Support vector machine (SVM) is a state-of-the-art tech- nique in pattern recognition with its powerful discrimina- tive capability in linear and nonlinear classification, and is widely applied in image recognition, biomathematics, and speech recognition (Vapnik, 1995; Burges, 1998; Ben- Dor et al., 2000; Osuna et al., 1997; Ganapathiraju et al., 1998; Ganapathiraju and Picone, 2000; Ganapathiraju, 2002; Fine et al., 2001a,b, 2002; Thubthong and Kijsirikul, 2001; Clarkson and Moreno, 1999; Smith and Gales, 2002). Recently, increased research interests of SVM are mainly focused on two aspects: one of them is to modify or find new kernel functions (Wan and Campbell, 2000; Wan and Renals, 2002; Smith and Gales, 2002), and the other is to use SVMs discriminative power in hybrid sup- port vector machine and hidden Markov model (SVM/ HMM) or hybrid support vector machine and Gaussian mixture model (SVM/GMM) scheme (Ganapathiraju et al., 1998; Ganapathiraju and Picone, 2000; Gan- apathiraju, 2002; Fine et al., 2001a,b, 2002). And the first research can also be implemented in the second research to achieve classification improvement. Generally, the pro- cedure of hybrid SVM/HMM or SVM/GMM is to use HMM or GMM as the first classification stage to produce the ‘‘N-best-list’’ patterns, and utilize SVM to give a second stage decision among the ‘‘N-best-list’’ patterns, the second stage probability output or decision is continuously embed- ded in the baseline recognition processing to increase the 0167-8655/$ - see front matter Ó 2007 Elsevier B.V. All rights reserved. doi:10.1016/j.patrec.2006.12.007 * Corresponding author. Address: LMIB & Department of Mathemat- ics, Beijing University of Aeronautics and Astronautics, Beijing 100083, PR China. Tel.: +55 16 3373 9671; fax: +55 16 3373 9751. E-mail addresses: [email protected], [email protected] (J. Liu). www.elsevier.com/locate/patrec Pattern Recognition Letters 28 (2007) 912–920
-
Upload
jingwei-liu -
Category
Documents
-
view
213 -
download
1
Transcript of A hybrid SVM/DDBHMM decision fusion modeling for robust continuous digital speech recognition

www.elsevier.com/locate/patrec
Pattern Recognition Letters 28 (2007) 912–920
A hybrid SVM/DDBHMM decision fusion modelingfor robust continuous digital speech recognition
Jingwei Liu a,b,*, Zuoying Wang b, Xi Xiao b
a LMIB & Department of Mathematics, Beijing University of Aeronautics and Astronautics, Beijing 100083, PR Chinab Department of Electronics Engineering, Tsinghua University, Beijing 100084, PR China
Received 2 April 2004; received in revised form 14 December 2006Available online 23 December 2006
Communicated by M.A.T. Figueiredo
Abstract
This paper proposes an improved hybrid support vector machine and duration distribution based hidden Markov (SVM/DDBHMM)decision fusion model for robust continuous digital speech recognition. We investigate the probability outputs combination of supportvector machine and Gaussian mixture model in pattern recognition (called FSVM),and embed the fusion probability as similarity intothe phone state level decision space of our duration distribution based hidden Markov model (DDBHMM) speech recognition system(named FSVM/DDBHMM). The performances of FSVM and FSVM/DDBHMM are demonstrated in Iris database and continuousmandarin digital speech corpus in 4 noise environments (white, volvo, babble and destroyerengine) from NOISEX-92. The experimentalresults show the effectiveness of FSVM in Iris data, and the improvement of average word error rate reduction of FSVM/DDBHMMfrom 6% to 20% compared with the DDBHMM baseline at various signal noise ratios (SNRs) from �5 dB to 30 dB by step of 5 dB.� 2007 Elsevier B.V. All rights reserved.
Keywords: Speech recognition; Gaussian mixture model; Duration distribution based hidden Markov model (DDBHMM); Support vector machine
1. Introduction
Support vector machine (SVM) is a state-of-the-art tech-nique in pattern recognition with its powerful discrimina-tive capability in linear and nonlinear classification, andis widely applied in image recognition, biomathematics,and speech recognition (Vapnik, 1995; Burges, 1998; Ben-Dor et al., 2000; Osuna et al., 1997; Ganapathiraju et al.,1998; Ganapathiraju and Picone, 2000; Ganapathiraju,2002; Fine et al., 2001a,b, 2002; Thubthong and Kijsirikul,2001; Clarkson and Moreno, 1999; Smith and Gales, 2002).
0167-8655/$ - see front matter � 2007 Elsevier B.V. All rights reserved.
doi:10.1016/j.patrec.2006.12.007
* Corresponding author. Address: LMIB & Department of Mathemat-ics, Beijing University of Aeronautics and Astronautics, Beijing 100083,PR China. Tel.: +55 16 3373 9671; fax: +55 16 3373 9751.
E-mail addresses: [email protected], [email protected](J. Liu).
Recently, increased research interests of SVM aremainly focused on two aspects: one of them is to modifyor find new kernel functions (Wan and Campbell, 2000;Wan and Renals, 2002; Smith and Gales, 2002), and theother is to use SVMs discriminative power in hybrid sup-port vector machine and hidden Markov model (SVM/HMM) or hybrid support vector machine and Gaussianmixture model (SVM/GMM) scheme (Ganapathirajuet al., 1998; Ganapathiraju and Picone, 2000; Gan-apathiraju, 2002; Fine et al., 2001a,b, 2002). And the firstresearch can also be implemented in the second researchto achieve classification improvement. Generally, the pro-cedure of hybrid SVM/HMM or SVM/GMM is to useHMM or GMM as the first classification stage to producethe ‘‘N-best-list’’ patterns, and utilize SVM to give a secondstage decision among the ‘‘N-best-list’’ patterns, the secondstage probability output or decision is continuously embed-ded in the baseline recognition processing to increase the

J. Liu et al. / Pattern Recognition Letters 28 (2007) 912–920 913
overall system accuracy (Ganapathiraju et al., 1998; Gan-apathiraju and Picone, 2000; Ganapathiraju, 2002; Fineet al., 2001a,b, 2002). Therefore, the performance ofSVM is definitely limited by the first stage filtering ofHMM or GMM baseline. In this paper, we propose amodel level fusion method, different from the sequentialhybrid scheme mentioned before, to combine the classifica-tion capability of SVM and GMM parallelly, and embed itinto our DDBHMM speech recognition system to improveits robustness in noise environments.
The fusion of SVM and GMM is motivated from boththeoretical and practical considerations. Theoretically,SVM is based on structural risk minimization (Vapnik,1995) to enlarge the boundary of any two classes in patternspace. It, therefore, uses the inter-class information; WhileGMM is powerful on modeling the intra-class information(Duda and Hart, 1973; Everitt, 1981; Rabiner, 1989;Young, 2001), the fusion model is expected to use bothinter-class and intra-class information and have a tradeoffof two classifiers’ merits. In practice, on the one hand, Fineet al find that GMM classifier is slightly better than SVM,and the errors produced by SVM and GMM classifiers areuncorrelated, which makes it possible to design an expert-like fusion model (Kittler et al., 1998). On the other hand,especially in continuous speech recognition hybrid SVM/HMM, the whole processing of aligning ‘‘N-best-list’’ (usu-ally N = 10) samples of phone states by Viterbi decoderand re-scoring by SVM is consumptive in computationtime, it is equivalent to two times recognition. WhereasFSVM/DDBHMM, directly using the probability fusionof SVM and GMM and embedding it into DDBHMM,just has one time recognition, which is hoped to save com-putation time.
The idea of parallel model combination is also used in(Kirchhoff et al., 2002), where five different articulatory fea-tures of speech signal (for example, voicing, place, manner,etc.) are trained using five parallel multi-layer-perceptrons(MLPs) and tuned to specific speech recognition tasks.However, all of the probabilities that the articulatory fea-ture is mostly similar to the articulatory classes, respec-tively, of MLPs are mapped to phone probabilities usinghigh level MLPs. In this manner, this kind of hybrid mod-eling HMM and artificial neural networks (ANN) modelalso has two steps, the first step is the parallel of MLPs,and the second step is hybrid combination. Obviously, theprocedure of Ganapathiraju’s hybrid SVM/HMM is similarto the second step of hybrid HMM/ANN, though one usesSVM to align ‘‘N-best-list’’, and the other applies high levelMLPs to balance a probability model for robust speech rec-ognition. Finally, all of their likelihoods generated by SVMand MLP are embedded into Viterbi-decoding system ofHMM model. However, the first step of FSVM/DDBHMM is a frame-level SVM/GMM parallel model,their probability outputs are weighted, combined, and theninputted into Viterbi-decoding system of HMM model.
We demonstrate the performance of FSVM in Iris data-base, a widely used benchmark database in machine learn-
ing, and show the effectiveness of FSVM/DDBHMM inboth clean and noise environments from NOISEX-92 com-pared with DDBHMM baseline.
The rest of the paper is organized as follows: Section 1briefly reviews SVM and proposes FSVM. Section 2describes the FSVM/DDBHMM architectures for speechrecognition. Section 3 introduces the experimental data-base. The experiment results are reported in Section 4.And, the discussion and conclusion are given in the lastsection.
2. SVM and FSVM model
2.1. Brief review of SVM
Based on structural risk minimization (Vapnik, 1995),SVM is designed to enlarge the boundary of any two clas-ses in pattern space by searching an optimal hyperplanethat has maximum distance to the closest points betweentwo classes which are termed support vectors. Supposethe training data is
ðx1; y1Þ; ðx2; y2Þ; . . . ; ðxm; ymÞ 2 X� f�1; 1g; ð1Þ
where x1; x2; . . . ; xm 2 Rd are the patterns, y1,y2, . . . ,ym 2{�1,1} are the targets (class labels).
The function mapping the space X�X to the space R iscalled a kernel, that is
K : X�X! R: ð2Þ
To gain a high dimensionality discriminant linear hyper-plane, the training data are first mapped into high dimen-sionality space H,
/ : X!H;
x! x ¼ /ðxÞ:ð3Þ
Thus, K(x,x 0) = (x,x 0) = (/(x),/(x 0)).Finding an optimal linear separate hyperplane f(x) =
wT/(x) + b to classify any two classes is equivalent tooptimize the following mathematical problem:
minw;b;n
1
2wTwþC
Xm
i¼1
ni
!subject to yi½wT/ðxÞ þ b�P 1� ni; ni P 0; i¼ 1; . . . ;m;
ð4Þ
where C is the penalty parameter of the error term. It’s dualproblem is
mina
1
2aTQa� eTa
� �subject to 0 6 ai 6 C; i ¼ 1; . . . ;m; yTa ¼ 0;
ð5Þ
where e is the vector of all ones, C becomes the upperbound of all variables a, and Q is an m · m positive semi-definite matrix, where

914 J. Liu et al. / Pattern Recognition Letters 28 (2007) 912–920
Qij ¼ yiyjKðxi; xjÞ ¼ yiyj/ðxiÞT/ðxjÞ: ð6Þ
Then, the solution of w is
w ¼Xm
i¼1
aiyi/ðxiÞ ð7Þ
and the decision function for binary classes is
DðxÞ ¼ sgnðwT/ðxÞ þ bÞ ¼ sgnXm
i¼1
aiyiKðxi; xÞ þ b
!: ð8Þ
For multi-class classification problem, assume that all theclasses in pattern space are denoted as
x̂ ¼ fx1; . . . ;xNg: ð9Þ
We adopt one-against–one majority voting scheme, andadopt the voting frequency as the final decision functionof SVM instead of sigmoid probability fitting (Platt,1999; Ganapathiraju et al., 1998; Ganapathiraju and Pi-cone, 2000; Ganapathiraju, 2002). That is, for any inputsample x, each two-class SVM is applied as weak classifierto determine which class x should belong to. For ith class,(N � 1) different classifiers is used to determine which classx belongs to, and there are at most (N � 1) times that x isclassified to ith class. Let Ti denote the frequency that x isclassified to ith class, we define
P svmðxijxÞ ¼T i
Nð10Þ
and the decision function of multi-SVM is
DðxÞ ¼ maxxi
P svmðxijxÞ: ð11Þ
In this paper, P(Æ), p(Æ), P(ÆjÆ) and p(ÆjÆ) are denoted as distri-bution function (df), probability density function (pdf),conditional distribution function (cdf) and conditionalprobability density function (cpdf), respectively.
In SVM-based speech recognition, two basis kernelfunctions are widely used and discussed,
• polynomial: Kðxi; xiÞ ¼ ðcxTi xj þ rÞk; c > 0,
• radial basis function(RBF): K(xi,xi) = exp(�ckxi �xjk2),c > 0,
where c, r and k are kernel parameters. The previous worksshow that RBF has better performance than polynomialkernel (Ganapathiraju et al., 1998; Ganapathiraju andPicone, 2000; Ganapathiraju, 2002; Hsu and Lin, 2002).Though finding a new kernel function is an attractiveresearch in SVM, for the first step of investigating decisionfusion model, the RBF kernel function is chosen in thispaper.
2.2. FSVM model
In pattern recognition, especially in speech recognition,GMM model is the most popular statistical parameter
model for probability density function (pdf) estimation ofstate class by mixture of several normal distributions,
pgmmðx; l;RÞ ¼XK
i¼1
wiNðx; li;RiÞ;
where Nðx; l;RÞ ¼ 1
ð2pÞd=2jRij1=2
� exp � 1
2ðx� liÞ
0R�1i ðx� liÞ
� �:
ð12Þ
This processing only considers the intra-class informationignoring the inter-class information. Since combining theinformation of intra-class and inter-class is ideally hopedto construct a more discriminative model, we propose aheuristic model to optimize the decision space of SVMand GMM, that is, for multi-class classification problem,the decision fusion function is modified as follows:
max8x2x̂ðaP svmðxjxÞ þ ð1� aÞP gmmðxjxÞÞ; ð13Þ
where a 2 [0, 1]. In the above formula, Psvm(xjx) is esti-mated by one-against–one voting method, and Pgmm(xjx)is calculated by Bayesian rule and expectation-maximiza-tion (EM) algorithm. The model with decision functionof formula (13) is named FSVM.
Since Psvm(xjx) is an estimated frequency probability,formula (13) is still a probability. In the state space of Mar-kov chain, the parallel combination of SVM and GMMwill theoretically increase the recognition rate of eachframe. In fact, let p(svm,gmm) and q(svm,gmm) denote the rec-ognition rate and error rate, respectively, of FSVM, and letpsvm, qsvm, pgmm and qgmm denote the recognition rate anderror recognition rate of SVM and GMM, respectively.For one frame of speech feature vector, the recognition rateand error rate of FSVM are as following,
pðsvm;gmmÞ ¼ 1� ð1� psvmÞð1� pgmmÞ;qðsvm;gmmÞ ¼ ð1� psvmÞð1� pgmmÞ:
ð14Þ
This model is also applied in (Kanedera et al., 1999) forband combination. We try to improve the state space rec-ognition rate of each frame in HMM, and finally improveall the performance of SVM/HMM combination model.To avoid the complexity of training SVM/HMM and esti-mating parameters of combination model, we propose astepwise modeling method (Section 5.2). Then, the theoret-ical convergence of HMM and SVM keeps on their individ-ual convergence theory, the hybrid model only combinestheir posterior probabilities in decision function in patternspace.
By Bayesian rule,
P gmmðxjxÞ ¼P ðxÞP ðxjxÞ
P ðxÞ : ð15Þ
Since P(x) has no relationship with x, we obtain that

J. Liu et al. / Pattern Recognition Letters 28 (2007) 912–920 915
arg maxx
P gmmðxjxÞ ¼ arg maxx
P gmmðxÞPðxjxÞ: ð16Þ
With strong assumption that Pgmm(x) is equal for all clas-ses, the above formula is equal to
arg maxx
P gmmðxjxÞ ¼ arg maxx
P gmmðxjxÞ
¼ arg maxx
log pgmmðxjxÞ ð17Þ
and EM algorithm is used to train the model of pgmm(xjx).Generally, it is more difficult to calculated the distributionfunction of a multi-variable normal distribution, we scalelogpgmm(xjx) by b and adopt the similarity to substitutethe formula (13) with
DðxÞ ¼ maxxðaP svmðxjxÞ þ ð1� aÞb log pgmmðxjxÞÞ; ð18Þ
i.e. the decision fusion model is constructed by two uncor-related decision surface of SVM and GMM, and b is aexperimental scale factor. In experiment, for FSVM on Irisdata, only 1-mixture GMM with full covariance matrix isinvestigated; while, for FSVM/DDBHMM in digitalspeech recognition, 12-mixtures GMM with diagonalcovariance matrices is employed.
3. DDBHMM model and modified FSVM/DDBHMM
model
3.1. DDBHMM and FSVM/DDBHMM
Hidden Markov model is one of the most successfultechniques in statistical speech recognition. SupposeO = {o1, . . . ,oT} is an observation sequence of speech fea-ture vectors, W = {w1, . . . ,wN} is the encoded speech wordsequence, where W is decomposed into a sequence of basicsounds called phones denoted Q = {Q1, . . . ,QK}. Eachphone state is a class in pattern recognition space. ands = {s1, . . . ,sK} is the corresponding duration of state Qin O, where
PNn¼1sn ¼ T . And, let c1, . . . ,cK, cK+1 denote
the state segment point. The statistical model of speech rec-ognition isbW ¼ arg max
WpðW jO; sÞ ¼ arg max
WpðO; sjW ÞpðW Þ; ð19Þ
where p(W) is determined by language model, and
pðO; sjW Þ ¼X
Q
P ðO; sjQÞP ðQjW Þ
¼X
Q
P ðO; sjQÞYKk¼1
PðQkjwkÞ; ð20Þ
where P(O,sjQ) is calculated by DDBHMM model as fol-lows. Suppose that O is conditional independent with s gi-ven Q, and s is independent with Q, we can obtain
pðO; sjQÞ ¼ maxðc1;...;cK Þ
YKk¼1
pðskÞYckþ1�1
t¼ck
pðotjQkÞ( )
: ð21Þ
There are many choices of parameter probability for p(sk),Since the observation of real sample data is located in finite
real interval, we can constrain the p(sk) as uniform distribu-tion, then
pðO; sjQÞ /YKk¼1
Yckþ1�1
t¼ck
pðotjQkÞ; ð22Þ
where p(otjQk) is modelled by GMM.As mentioned in Section 2, FSVM model combines the
similarity of SVM and GMM, we substitute p(otjQk) withformula (18), and name the modified model FSVM/DDBHMM (Ferguson, 1980; Rabiner, 1989; Young,2001; Zhao et al., 1999; Wang and Xiao, 2002).
3.2. Evaluation in continuous speech recognition
The evaluation measure adopted in this paper for speechrecognition is conventional word error rate (WER), theimprovement is evaluated by error reduction. Let H, D,S, I, T be the number of correct words, deletion words, sub-stitution words, insertion words and total number ofwords, respectively. The evaluation indexes are defined asfollows:
Word error rate ¼ Dþ I þ ST
� 100%; ð23Þ
Error reduction ¼ Baseline WER� Improved WER
Baseline WER� 100%:
ð24Þ
4. Database
The evaluation data sets consist of Iris data set andmandarin continuous digital speech corpus with NOI-SEX-92.
Iris data set is a benchmark data set in machines learn-ing and pattern recognition (Duda and Hart, 1973; Everitt,1993), downloaded from the UCI repository of machinelearning databases www.ics.uci.edu/mlearn/MLrepository(Blake and Merz, 1998). It consists of three classes (setosa,versicolor and virginica) and four measurements (Sepallength, Sepal width, Petal length, Petal width) made oneach of 150 Iris plants. Three data sets are designed to dem-onstrate FSVM. The first one, all the 150 samples are bothselected for training and testing, it is so called a ‘‘close set’’test, named Iris data-I; The second one, 50 samples of eachclass are divided into two parts, the forth 40 samples areselected for training, and the rest 10 samples are selectedfor testing, called Iris data-II; The third one is composedof 1000 subsets, each subset is generated by randomlydividing Iris data into 40 samples to 10 samples of eachclass for training and testing, totally called Iris data-III,this style of designing experiment data set also appears in(Liu, 2002).
The second data set is a clean mandarin continuous dig-ital speech corpus (Tian, 2003) involved 10 mandarin digitsof (‘‘0’’, ‘‘1’’, . . . , ‘‘9’’), where ‘‘1’’ has two pronunciations.It is recorded in clean lab environment and sampled at fre-quency of 16 kHz, and is composed of two sets – training

10 20 30 40 50 60 70 8090
91
92
93
94
95
96
97
98
99
100
Label of (C,γ)
Rec
ogni
tion
Rat
e(%
)
GMM
. SVM
+ FSVM
Fig. 1. Recognition rate of SVM GMM and FSVM on Iris data-I.
96
97
98
99
100gn
ition
Rat
e(%
)
GMM
916 J. Liu et al. / Pattern Recognition Letters 28 (2007) 912–920
set and test set. The training set consists of 80 speech filesof 4-word strings, 5-word strings and 8-word stringsrecorded by 35 female persons. The number of three lengthfiles is 28, 33, 17, respectively. The test set consists of 6speech files recorded by 2 females with 4-word, 5-wordand 8-word strings, respectively. Moreover, There are 42digital strings in each 4-word string file, 35 digital stringsin each 5-word string file, and 35 digital strings in each 8-word string file, respectively. Totally, the training digitsare 15239 and testing digits are 1230.
To evaluate the robustness of FSVM/DDBHMM innoise environment, all of the mandarin continuous digitalspeech files are added with white noise, volvo noise, babblenoise and destroyerengine noise selected from the NOI-SEX-92 noise database (Varga et al., 1992) at its originalsampling frequency of 16 kHz for global SNR ratios from�5 to +30 dB by 5 dB step. The clean data and contami-nated data are also divided as training data and test dataas previous structure. The speech signal is first processedby a pre-emphasis filter with transfer function 1–0.98z�1,subsequently, a 20 ms Hamming window is applied over10 ms shifts to extract 14-order Mel-frequency cepstralcoefficients (MFCC) and normalized energy of each frame,combined with their first and second-order differences intoa 45-dimensional vector. To reveal the inhered property ofFSVM/DDBHMM, we construct the DDBHMM modeland SVM model in clean environment, and test varioustask at different SNRs in different noise environments.
10 20 30 40 50 60 70 8093
94
95
Label of (C,γ)
Rec
o
. SVM
+ FSVM
Fig. 2. Recognition rate of SVM GMM and FSVM on Iris data-II.
10 20 30 40 50 60 70 8087
88
89
90
91
92
93
94
95
96
97
98
Label of (C,γ)
Rec
ogni
tion
Rat
e(%
)
GMM
. SVM
+ FSVM
Fig. 3. Average recognition rate of SVM GMM and FSVM on Iris data-III.
5. Experiment results
5.1. FSVM on Iris data
To demonstrate the performance of FSVM, three experi-ments are executed on Iris data I, Iris data II, Iris data III,respectively, and 1-mixture GMM with full covariancematrix is employed in this experiment. While trainingSVM model, all the samples are scaled into [�1,1], and thedomains of cost parameter C and kernel parameter c are con-strained in the following lattices: C = {2�4,2�3,2�2, . . . , 24}and c = {2�4,2�3,2�2, . . . , 24}.
Beyond all doubt, the domain of a 2 [0, 1] in formula(16) can guarantee the best recognition rate with FSVM.However, a more deeper consideration of machine learningis that there also exits overfitting problem especially inparameter training of pattern recognition. We show therecognition rate of SVM, FSVM with a 2 {0.05,0.1, . . . ,0.95} and GMM separately to demonstrate FSVM canprovide tradeoff classification result between SVM andGMM, and achieve better result than both of themsometimes.
The recognition rate on Iris data I, Iris data II and Irisdata III are shown in Figs. 1–3, respectively. In the threefigures, the parameter lattice of the ith element in C andthe jth element in c is labeled as the (i * 9 + j)th elementof (C,c) and taken as x-axis. We adopt b = 0.1 in all of

Table 2The average WER reduction (%) of different size SVM/DDBHMM overclean and all SNRs from �5 dB to 30 dB by 5 dB step with b = 1/40
Model 32-FSVM/DDBHMM
64-FSVM/DDBHMM
128-FSVM/DDBHMM
Imp. WER 8.03 7.26 7.47
J. Liu et al. / Pattern Recognition Letters 28 (2007) 912–920 917
the three experiments, and perform SVM without cross-validation.
As shown in Fig. 1, a ‘‘close set’’ experiment case, allinformation of classes in pattern space makes SVM outper-form GMM in some appropriate parameter cases. FSVMwith a 2 {0.05, 0.1, . . . , 0.95} outperforms both of SVMand GMM mostly. This demonstrates that FSVM can pro-vide more discriminative optimization decision surfacethan both of SVM and GMM.
In ‘‘open set’’ cases of Figs. 2 and 3, the statistical infor-mation of class is missing in training set to some extent,SVM performs worse than GMM, and FSVM enhancesthe performance of SVM. Ideally, it is expected to exhibitthis kind of tradeoff ability in more complex pattern recog-nition task to improve the worse performance of SVM orGMM.
As studied by Duda (1973), Everitt (1993) and Liu(2002), figures of any two dimensions of Iris data show thatthe structure of Iris data is almost separate in patternspace, but it is not true in MFCC of speech signal, asshown in (Ganapathiraju, 2002) the first two cepstral coef-ficients are highly overlapped for all vowels in theSWITCHBOARD corpus, which is also a speech cor-pus. We, then, demonstrate FSVMs discriminative powerin continuous digital speech recognition in the FSVM/DDBHMM scheme in the next section.
5.2. FSVM/DDBHMM in continuous digital speech
recognition
In our mandarin digital speech recognition system, eachsyllable of 11 pronunciation syllable of digits (‘‘0’’, ‘‘1’’, . . . ,‘‘9’’) are divided into Consonant/Vowel (C/V) structure, abi-phone structure. Each consonant phone is modelled by 2sub-phone states, and vowel phone is modelled by 4 sub-phone states. In addition, a phone state is reserved forsilence state. Hence, there are totally 67 phone states inDDBHMM baseline speech recognition system.
To evaluate the performance of FSVM/DDBHMM, theparameters of DDBHMM and FSVM/DDBHMM classifi-ers are trained in clean environment. The contaminatedspeech at different SNRs in different noises are tested bythe uniform model trained in clean environment. To
Table 1The average improvement of WER reduction (abbr. Imp. WER) (%) of continfrom NOISEX-92 at SNRs from �5 dB to 30 dB by 5 dB step, respectively
SNR (dB) Clean 30 25 20
DDBHMM 2.78 2.85 3.50 5.7
32-FSVM/DDBHMM 2.56 2.78 3.18 4.8Imp. WER 7.91 2.45 9.14 16.2
64-FSVM/DDBHMM 2.76 2.70 3.33 5.1Imp. WER 0.72 5.26 4.86 10.8
128-FSVM/DDBHMM 2.55 2.71 3.39 5.3Imp. WER 8.27 4.91 3.14 7.6
VQ sizes for SVM training are 32, 64, 128, respectively, with b = 1/40.
emphasize the role of GMM and compute practicable,the domain of combination factor parameter is constrainedinto a 2 {0,0.1, . . . , 1.0}, and the SVM searching latticesare constrained into c = {2�4,2�3, . . . , 1, . . . , 24} and C ={2�4,2�3, . . . , 24}.
Considering the complexity of training SVM/HMM, wepropose a stepwise combination method. The scheme ofFSVM/DDBHMM is constructed as follows.
5.2.1. Experiment I
• Using Viterbi algorithm, the DDBHMM system isrecursively trained both for model parameters andphone state samples alignment. As training modelparameters in DDBHMM, the samples for SVM arealso calculated by K-means algorithm, three sizes of32, 64 and 128 Vector Quantization (VQ) codebooksare generated and scaled into [�1,1] for SVM modeling.The parameter of a is estimated in clean training data indomain of a 2 {0,0.1, . . . , 1.0}, according with maximiz-ing the WER reduction in clean training data.
• In classification procedure in various noise environmentat different SNRs, each frame of speech is calculated byFSVM/DDBHMM using formula (17) with estimated a.In this stage, the speech vector is scaled only in SVMmodel. It does not need to be scaled in GMM. And,we choose b = 1/40 in this section.
The experiment results of different VQ size and differentnoises at different SNRs are listed in Table 1, the averageWER reductions for FSVM/DDBHMM over clean andall SNRs are listed in Table 2, and the comparison ofDDBHMM and FSVM/DDBHMM are also calculated.
Since the combination parameter a is estimated fromclean environmental training data, Table 1 demonstratesthat combination SVM/DDBHMM can improve the
uous digital strings with noises (white, volvo, babble and destroyerengine)
15 10 5 0 �5
4 12.22 28.37 46.28 60.85 73.57
1 10.93 24.43 43.05 60.24 70.530 10.56 13.89 6.98 1.00 4.13
2 10.68 24.05 42.59 58.92 70.030 12.60 15.23 7.97 3.17 4.81
0 10.99 24.09 41.65 58.30 70.717 10.07 15.09 10.00 4.19 3.89
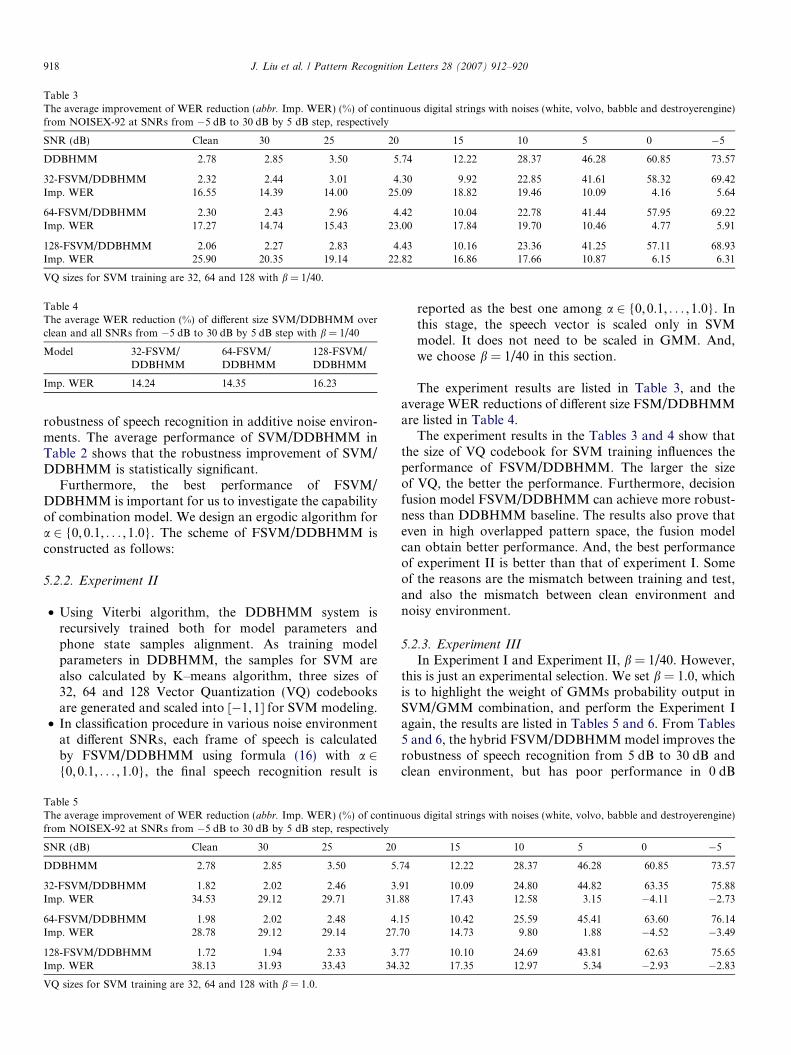
Table 3The average improvement of WER reduction (abbr. Imp. WER) (%) of continuous digital strings with noises (white, volvo, babble and destroyerengine)from NOISEX-92 at SNRs from �5 dB to 30 dB by 5 dB step, respectively
SNR (dB) Clean 30 25 20 15 10 5 0 �5
DDBHMM 2.78 2.85 3.50 5.74 12.22 28.37 46.28 60.85 73.57
32-FSVM/DDBHMM 2.32 2.44 3.01 4.30 9.92 22.85 41.61 58.32 69.42Imp. WER 16.55 14.39 14.00 25.09 18.82 19.46 10.09 4.16 5.64
64-FSVM/DDBHMM 2.30 2.43 2.96 4.42 10.04 22.78 41.44 57.95 69.22Imp. WER 17.27 14.74 15.43 23.00 17.84 19.70 10.46 4.77 5.91
128-FSVM/DDBHMM 2.06 2.27 2.83 4.43 10.16 23.36 41.25 57.11 68.93Imp. WER 25.90 20.35 19.14 22.82 16.86 17.66 10.87 6.15 6.31
VQ sizes for SVM training are 32, 64 and 128 with b = 1/40.
Table 4The average WER reduction (%) of different size SVM/DDBHMM overclean and all SNRs from �5 dB to 30 dB by 5 dB step with b = 1/40
Model 32-FSVM/DDBHMM
64-FSVM/DDBHMM
128-FSVM/DDBHMM
Imp. WER 14.24 14.35 16.23
918 J. Liu et al. / Pattern Recognition Letters 28 (2007) 912–920
robustness of speech recognition in additive noise environ-ments. The average performance of SVM/DDBHMM inTable 2 shows that the robustness improvement of SVM/DDBHMM is statistically significant.
Furthermore, the best performance of FSVM/DDBHMM is important for us to investigate the capabilityof combination model. We design an ergodic algorithm fora 2 {0, 0.1, . . . , 1.0}. The scheme of FSVM/DDBHMM isconstructed as follows:
5.2.2. Experiment II
• Using Viterbi algorithm, the DDBHMM system isrecursively trained both for model parameters andphone state samples alignment. As training modelparameters in DDBHMM, the samples for SVM arealso calculated by K–means algorithm, three sizes of32, 64 and 128 Vector Quantization (VQ) codebooksare generated and scaled into [�1,1] for SVM modeling.
• In classification procedure in various noise environmentat different SNRs, each frame of speech is calculatedby FSVM/DDBHMM using formula (16) with a 2{0,0.1, . . . , 1.0}, the final speech recognition result is
Table 5The average improvement of WER reduction (abbr. Imp. WER) (%) of continfrom NOISEX-92 at SNRs from �5 dB to 30 dB by 5 dB step, respectively
SNR (dB) Clean 30 25 20
DDBHMM 2.78 2.85 3.50 5.
32-FSVM/DDBHMM 1.82 2.02 2.46 3.Imp. WER 34.53 29.12 29.71 31.
64-FSVM/DDBHMM 1.98 2.02 2.48 4.Imp. WER 28.78 29.12 29.14 27.
128-FSVM/DDBHMM 1.72 1.94 2.33 3.Imp. WER 38.13 31.93 33.43 34.
VQ sizes for SVM training are 32, 64 and 128 with b = 1.0.
reported as the best one among a 2 {0,0.1, . . . , 1.0}. Inthis stage, the speech vector is scaled only in SVMmodel. It does not need to be scaled in GMM. And,we choose b = 1/40 in this section.
The experiment results are listed in Table 3, and theaverage WER reductions of different size FSM/DDBHMMare listed in Table 4.
The experiment results in the Tables 3 and 4 show thatthe size of VQ codebook for SVM training influences theperformance of FSVM/DDBHMM. The larger the sizeof VQ, the better the performance. Furthermore, decisionfusion model FSVM/DDBHMM can achieve more robust-ness than DDBHMM baseline. The results also prove thateven in high overlapped pattern space, the fusion modelcan obtain better performance. And, the best performanceof experiment II is better than that of experiment I. Someof the reasons are the mismatch between training and test,and also the mismatch between clean environment andnoisy environment.
5.2.3. Experiment III
In Experiment I and Experiment II, b = 1/40. However,this is just an experimental selection. We set b = 1.0, whichis to highlight the weight of GMMs probability output inSVM/GMM combination, and perform the Experiment Iagain, the results are listed in Tables 5 and 6. From Tables5 and 6, the hybrid FSVM/DDBHMM model improves therobustness of speech recognition from 5 dB to 30 dB andclean environment, but has poor performance in 0 dB
uous digital strings with noises (white, volvo, babble and destroyerengine)
15 10 5 0 �5
74 12.22 28.37 46.28 60.85 73.57
91 10.09 24.80 44.82 63.35 75.8888 17.43 12.58 3.15 �4.11 �2.73
15 10.42 25.59 45.41 63.60 76.1470 14.73 9.80 1.88 �4.52 �3.49
77 10.10 24.69 43.81 62.63 75.6532 17.35 12.97 5.34 �2.93 �2.83

Table 6The average WER reduction (%) of different size SVM/DDBHMM overclean and all SNRs from �5 dB to 30 dB by 5 dB step with b = 1.0
Model 32-FSVM/DDBHMM
64-FSVM/DDBHMM
128-FSVM/DDBHMM
Imp. WER 16.84 14.79 18.63
J. Liu et al. / Pattern Recognition Letters 28 (2007) 912–920 919
and �5 dB. The overall average result with b = 1.0 is betterthan experimental result with b = 1/40 in Experiment I. Inaddition, The average result with b = 1.0 is even betterthan the result with b = 1/40 in Experiment II.
Since, The relative WER improvement of hybridFSVM/DDBHMM in Experiment I and Experiment II ispositive, it is more robust than the DDBHMM baseline.Therefore, b plays an important role in our hybrid model.If the robustness of all dB is considered, the selection of b isalso a tradeoff strategy. To solve the deficiency, the noisycontaminated speech signal should be performed noiseadaptation to abate the difference between clean environ-ment and noisy environment and Experiment II is justthe upper bound of hybrid model with b = 1/40.
6. Conclusion and discussion
In this paper, a decision fusion model of GMM andSVM is investigated, and an FSVM/DDBHMM schemeis proposed for speech recognition. We demonstrate theeffectiveness of the two model in Iris data and mandarincontinuous digital speech corpus in various noise environ-ments at different SNRs level. Experimental results showthe inspiring conclusion that FSVM performs well in differ-ent pattern recognition tasks, and FSVM/DDBHMM out-performs DDBHMM baseline. Also, the best performanceof FSVM/DDBHMM in our test data is computed andcompared with the clean training combination model.Since modeling SVM depends on VQ algorithm to obtainrepresentative samples, HMM with GMM performs betterthan SVM in continuous large size corpus speech recogni-tion task. Also, the optimization of scale factor b is a com-putation consumption procedure and a balance of trade-offwith global robustness at all SNR levels.
The future research works focus on combining differentkernel functions with GMM and apply them in FSVM/DDBHMM scheme, performing more experiments in dif-ferent noise environments, for example, Aurora noise data-base, the more important, adaptively training FSVM/DDBHMM in different environments at different SNRs,combine our model with speech enhancement technique,optimize the combination parameters, and apply FSVM/DDBHMM in large vocabulary continuous speech recog-nition in real noise environment.
Acknowledgements
This project was supported by China Postdoctoral Sci-ence Foundation and National ‘‘863’’ Plan (No.
2001AA114071). Thanks for the valuable discussion withDr. DaQuan Jiang of Peking University and the help ofDr. and Prof. Chih-Jen Lin of National Taiwan Universitywith his useful libsvm-2.5 tools. Authors are grateful toanonymous reviewers for their comments which improvethe presentation of this paper.
References
Ben-Dor, A., Bruhn, L., Friedman, N., et al., 2000. Tissue classificationwith gene expression profiles. Proc. 4th Annual Internat. Conf. onComputational Molecular Biology (RECOMB). Universal AcademyPress, Tokyo.
Blake, C., Merz, C., 1998. UCI Repository of Machine LearningDatabases. <http://www.ics.uci.edu/mlearn/MLRepository.html>.
Burges, C.J.C., 1998. A tutorial on support vector machines for patternrecognition. Data Min. Knowledge Discovery 2, 121–167.
Clarkson, P., Moreno, P.J., 1999. On the use of support vector machinesfor phonetic classification. In: Proc. Internat. Conf. on Acoustics,Speech and Signal Processing, vol. 2, pp. 585–588.
Duda, R., Hart, P., 1973. Pattern Classification and Scene Analysis. JohnWilley & Sons, New York.
Everitt, B.S., 1981. Finite Mixture Distribution. Chapman and Hall.Everitt, B.S., 1993. Cluster Analysis, third ed. John Wiley & Sons, New York.Ferguson, J.D., 1980. Variable duration models for speech. In: Ferguson,
J.D. (Ed.), Proc. Symposium on the Application of Hidden MarkovModels to Text and Speech. Institute for Defense Analyses Commu-nications Research Division, Princeton, New Jersey, pp. 143–179.
Fine, S., Navratil, J., Gopinath, R.A., 2001a. Hybrid GMM/SVMapproach to speaker identification. In: Proc. Internat. Conf. onAcoustics, Speech and Signal Processing, Salt Lake Utah, USA.
Fine, S., Navratil, J., Gopinath, R.A., 2001b. Enhancing GMM scoresusing SVM hints. In: The 7th European Conf. on Speech Communi-cation and Technology, pp. 1757–1760.
Fine, S., Saon, G., Gopinath, R.A., 2002. Digit recognition in noisyenvironments via a sequential GMM/SVM system. In: Proc. Internat.Conf. on Acoustics, Speech and Signal Processing, pp. 49–52.
Ganapathiraju, A., 2002. Support Vector Machines for Speech Recogni-tion. Dissertation of Mississippi State, Mississippi, May 2002.
Ganapathiraju, A., Picone, J., 2000. Hybrid SVM/HMM architectures forspeech recognition. Processings of the Defence Hub 5 Workshop,College Park, Maryland, USA, May 2000.
Ganapathiraju, A., Hamaker, J., Picone, J., 1998. Support vectormachines for speech recognition. In: Proc. Internat. Conf. on SpokenLanguage Processing, Sydney, Australia, pp. 2923–2926.
Hsu, C.W., Lin, C.J., 2002. A comparison of methods for multi-classsupport vector machines. IEEE Trans. Neural Networks 13, 415–425.
Kanedera, N., Arai, T., Hermansky, H., Pavel, M., 1999. On the relativeimportance of various components of the modulation spectrum forautomatic speech recognition. Speech Comm. 28 (1), 43–55.
Kirchhoff, K., Fink, G.A., Sagerer, G., 2002. Combining acoustic andarticulatory feature information for robust speech recognition. SpeechComm. 37 (3–4), 303–319.
Kittler, J., Hatef, M., Duin, R.P.W., Matas, J., 1998. On combiningclassifiers. IEEE Trans. Pattern Anal. Machine Intell. 20 (3), 226–239.
Liu, J.W., 2002. DTW-similarity-based Statistical Learning Method and itsApplication in Pattern Recognition. Dissertation of Peking University.
Osuna, E., Freund, R., Girosi, F., 1997. Training support vectormachines: An application to face detection. In: Proc. CVPR’97, PuertoRico, June 17–19, 1997.
Platt, J.C., 1999. Probabilistic output for support vector machines andcomparisons to regularized likelihood methods. In: Smola, AlexanderJ., Barlett, Peter, Scholkopf, Bernhard, Schuurmans, Dale (Eds.),Advances in Large Margin Classifiers. MIT Press.
Rabiner, L.R., 1989. A tutorial on hidden Markov models and selectedapplications in speech recognition. Proc. IEEE 77 (2), 257–286.

920 J. Liu et al. / Pattern Recognition Letters 28 (2007) 912–920
Smith, N.D., Gales, M.J.F., 2002. Using SVMs and discriminative modelsfor speech recognition. In: Proc. Internat. Conf. on Acoustics, Speechand Signal Processing, pp. 77–80.
Thubthong, N., Kijsirikul, B., 2001. Support vector machines for Thaiphoneme recognition. Int. J. Uncertain. Fuzz. 9 (6), 803–813.
Tian, Y., 2003. The Robustness of Voice Activity Detection in NoisyEnvironment. Dissertation of Tsinghua University.
Vapnik, V., 1995. The Nature of Statistical Learning Theory. Springer-Verlag, New York, NY, USA.
Varga, A., Steenneken, H.J.M., Tomlinson, M., Jones, D., 1992. TheNOISEX-92 study on the effect of additive noise on automatic speechrecognition. Documentation Included in the NOISEX-92 CD-ROMs.
Wan, V., Campbell, W.M., 2000. Support vector machines for speakerverification and identification. In: Proc. Neural Networks for SignalProcessing, vol. X, pp. 775–784.
Wan, V., Renals, S., 2002. Evaluation of Kernel methods for speakerverification and identification. In: Proc. Internat. Conf. on Acoustics,Speech and Signal Processing, vol. 1, pp. 669–672.
Wang, Z.Y., Xiao, X., 2002. The inhomogeneous hidden Markov modelsand its training and recognition algorithms of speech recognition.International Symposium Conference on Spoken Language Process-ing, Taipei, p. 137 (paper INV1).
Young, S., 2001. Statistical modelling in continuous speech recognition.In: Proc. Internat. Conf. on Uncertainty in Artificial Intelligence,Seattle, WA, August 2001.
Zhao, Q.W., Wang, Z.Y., Lu, D.J., 1999. A study of duration incontinuous speech recognition based on DDBHMM. In: The 6thEuropean Conf. on Speech Communication and Technology, pp.1511–1514.







![A Fusion of ICA and SVM for Detection Computer Attacks...implements an anomaly detection model using one-class SVM. Finally, the third type [18] establishes multi-class SVM at the](https://static.fdocuments.in/doc/165x107/5fe5fdcc6be2c9621839e96f/a-fusion-of-ica-and-svm-for-detection-computer-implements-an-anomaly-detection.jpg)









