
A Family of Contextual Measures of Similarity between...
32
A Family of Contextual Measures of Similarity between Distributions with Application to Image Retrieval Florent Perronnin, Yan Liu and Jean-Michel Renders Xerox Research Centre Europe (XRCE) Textual and Visual Pattern Analysis (TVPA) group To be presented at CVPR 2009
Transcript of A Family of Contextual Measures of Similarity between...

A Family of Contextual Measures of Similarity between Distributions
with Application to Image Retrieval
Florent Perronnin, Yan Liu and Jean-Michel RendersXerox Research Centre Europe (XRCE)
Textual and Visual Pattern Analysis (TVPA) group
To be presented at CVPR 2009

Page 2 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Problem Retrieval as ranking
Ranking:
given a query, return all images in descending rank order (or at least large subset)
Rational: retrieval is highly subjective and the system cannot guess the intent of the user (which might be unclear) do not take a decision
Ranking is sufficient for browsing-type applications, i.e. retrieve a specific image or a fixed number of images
Limited practical use: in fully automatic applications: e.g. query-expansion when guarantees are required: e.g. ensure average recall of 90%
?

Page 3 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Problem Retrieval as matching
In several retrieval applications the user intent is (fairly) unambiguous:
For such problems, the user might expect a subset
of images
Matching:
given a pair of images, return a binary decision (classification)
Choosing an appropriate threshold can guarantee
on average a given: precision level: e.g. useful for query expansion recall level: e.g. retrieve 90% of duplicates
Although related, ranking and matching are different problems
logo detection
Coca-Cola brand
near-duplicate detectionImpression sunrise, Claude Monet
scene retrieval
Holiday dataset, [Jegou et al.]
document retrieval
NIST form database

Page 4 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Problem Matching and context
Given these two forms, should we declare a match? in a general context of docs: yes in the context of forms: yes in the context of US tax forms: no
Humans judge in a context
Is matching only about setting a threshold?
Different contexts can correspond to: different scales of a hierarchy: e.g. mammals, felids, cats, breeds different taxonomies: e.g. waterscape paintings vs
impressionist paintings
Different contexts can impact the cues used to judge similarity Provide different views on the same problem

Page 5 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Problem Proposed solution
Is matching only about setting a threshold? if one does not take into account the context: yes…… but taking into account the context can provide much better accuracy.
We propose a novel family of contextual measures between distributions.
Many works model images as distributions: discrete distribution: e.g. bag-of-visual-words [Sivic
& Zisserman, Csurka et al.] continuous distribution: e.g. GMM [Goldberger et al., Moreno et
al., Vasconcelos]… but our framework is not restricted to images (e.g. text, speech, etc.)
Coming back to our US tax form example: in the general context of document images: 80% match in the context of US tax forms (NIST form): 4% match

Page 6 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Outline
Definition and properties
Multinomial distributions (special cases)
Application to retrieval
Experimental validation
Conclusion

Page 7 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Definition and properties Definition
Notations: p, q: two distributions to be compared u: a context distribution f: a measure of similarity
By definition:
Interpretation: Estimate the mixture of p and u that best approximates u according to f projection
of q on the line which joins p and u ω
reflects how much p contributes to the approximation
Each similarity / distance f has its contextual counterpart.
u
pq
1-ω
ω

Page 8 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Definition and properties Basic properties
By definition in
even if f symmetric
Symmetric similarity:
if f(q,p) is maximum for p=q (the converse is not true)
and the converse seems
to hold

Page 9 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Bregman
divergences: x and y two distributions in convexIncludes Euclidean distance, Mahalanobis
distance, Kullback-Leibler
divergence, Itakura-Saito divergence
Csiszár
divergences: x and y two discrete distributions convexIncludes Manhattan distance, Kullback-Leibler
divergence, Hellinger
distance, Rényi
divergence
If f is a Bregman
or Csiszár
divergence then convex in ω
Definition and properties Convex optimization

Page 10 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Outline
Definition and properties
Multinomial distributions (special cases)
Application to retrieval
Experimental validation
Conclusion

Page 11 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
asymmetric
L2 is known to be a poor measure of distance between multinomial
distributions (Gaussian noise assumption)…
but interesting because of closed-form formula.
Using symmetric similarity is important in small dimensional spaces.
symmetric
clipped to
Multinomial distributions Euclidean distance
u
pq
1-ω
ω

Page 12 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
asymmetric symmetric
Multinomial distributions Manhattan distance
Equivalent to intersection kernel:
Weighted median problem:
Piece-wise linear convex function minimum reached at one of the valuesSolved efficiently using Hoare’s algorithm in O(D)
Page 13 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
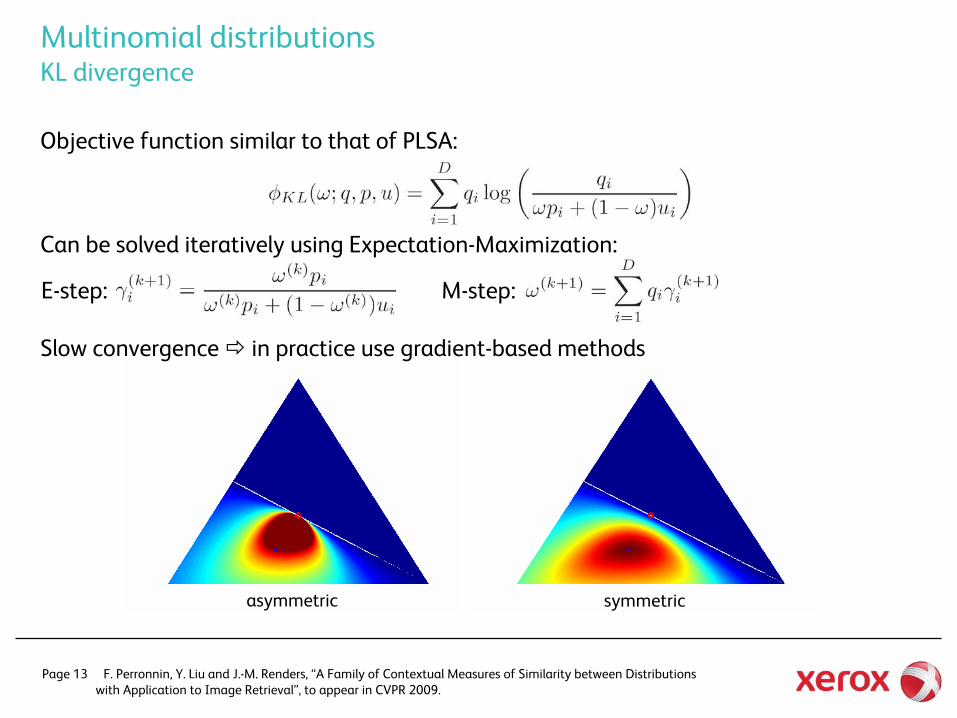
asymmetric symmetric
Multinomial distributions KL divergence
Objective function similar to that of PLSA:
Can be solved iteratively using Expectation-Maximization:
Slow convergence in practice use gradient-based methods
E-step: M-step:

Page 14 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Multinomial distributions Other distances
Hellinger’s
distance (equivalent to Bhattacharyya similarity):
Chi2 divergence:
Both lead to convex objective functions.
No special-purposed optimization algorithm gradient-based methods

Page 15 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Outline
Definition and properties
Multinomial distributions (special cases)
Application to retrieval
Experimental validation
Conclusion

Page 16 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
A single context might be insufficient for retrieval:
use different contexts for different queries
No “best”
context for a given query: broad contexts: coarse similarity increase precision at high recalls narrow contexts: fine similarity increase precision at low recalls
For each query: use contexts at multiple scales “average”
across contexts
Application to retrieval / matching Limitations of a single context
x ucats
dogs cows

Page 17 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Application to retrieval / matching Multi-scale retrieval algorithm
Retrieval algorithm for a given query q:1)
Compute the similarity to all templates and keep closest.
Let be the list of indices
2)
Estimate the context :
3)
For all templates compute:
Final similarity:
Give more weight to fine similarity than to coarse similarity
High computational cost: 1 contextual similarity computation per
template per scale

Page 18 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Application to retrieval / matching Speeding-up retrieval
We introduce:
If convex we have:
Advantage: much cheaper to compute than
Example:
Two interesting cases: if
then if then
ω

Page 19 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Application to retrieval / matching Speeded-up multi-scale retrieval algorithm
Retrieval algorithm for a given query q:1)
Compute the similarity to all templates and keep closest.
Let be the list of indices
2)
Estimate the context :
3)
For all templates compute:
Final similarity:
Speed-up computation:
test

Page 20 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Application to retrieval / matching Relationship with query expansion
Query expansion (QE): query system with original image use close images to define new query re-query the system iterate (optional)
Two main differences with QE: re-estimate the context model vs
query model for QE use mostly irrelevant images vs
use (hopefully) only relevant images for QE

Page 21 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Outline
Definition and properties
Multinomial distributions (special cases)
Application to retrieval
Experimental validation
Conclusion

Page 22 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Experimental validation Holiday dataset
The Holiday dataset: 1,491 images, 500 image groupshttp://lear.inrialpes.fr/people/jegou/data.php

Page 23 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Experimental validation Holiday dataset
Bag-of-visual-words description: SIFT features extracted on dense grids at multiple scales Visual vocabulary (GMM) of approximately 4,000 visual words Each image is encoded as a histogram of soft occurrences , i.e.
a multinomial
Measure of retrieval accuracy: Average Precision (AP) Ranking: compute one AP per query and averageMatching: compute one AP for all queries

Page 24 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Experimental validation Holiday dataset
Experiments with contextual KL using a single scale: context-size has large impact on matching, smaller impact on ranking
rankmatch

Page 25 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Experimental validation Holiday dataset
Experiments with contextual KL using a single scale: context-size has large impact on matching, smaller impact on ranking different contexts bring complementary information for matching

Page 26 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Experimental validation Holiday dataset
Experiments with contextual KL averaging multiple scales: weighted average somewhat better than unweighted average for matching
rankrank
matchmatch

Page 27 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Experimental validation Holiday dataset
Experiments with different measures: large improvement for the matching problem (+20-30%) small improvement for the ranking problem (+ 1-6%) as a bonus poor measures make poor contextual measures (c.f. L2)
rank
match

Page 28 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Experimental validation Document dataset
1,400 images = 14 classes of documents x 100 documents per class
Run-length description of document images: a run is a set of consecutive pixels with the same color in a given direction histogram of run-lengths in 4 directions for black and white pixels
non-sparse histogram of 1,680 dimensions
rank
match

Page 29 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Outline
Definition and properties
Multinomial distributions (special cases)
Application to retrieval
Experimental validation
Conclusion

Page 30 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Conclusion Summary
Although ranking and matching are related, they are different problems.
Matching makes little sense if we do not specify a context.
We introduced a family of contextual measures between distributions. In our framework, each measure has its contextual counterpart.
We showed how to compute the contextual similarity in practice for several measures in the case of multinomials.
Context has modest impact on ranking but very large impact on matching.

Page 31 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Conclusion Future work
Current work restricted to distributions. How to go beyond?
How to learn a context model?
Preliminary work on hierarchical clustering: a similarity should not be more detailed than needed. adapt similarity (through context) at each level of the hierarchy

Page 32 F. Perronnin, Y. Liu and J.-M. Renders, “A Family of Contextual Measures of Similarity between Distributionswith Application to Image Retrieval”, to appear in CVPR 2009.
Questions
?


















