
› documents › 2016-ling-conference-abstracts.docx?ver=1.4 · Web view GRAMMAR SKETCH - Dallas...
40
Metroplex Conference Schedule Friday, 21 October 2016 9:00 AM – 5:00 PM 8:30- 9:00 Registration 9:00- 9:10 Welcome Dr. Doug Tiffin, GIAL Dean of Academic Affairs 9:10- 10:10 Session 1: Morphology Chair: Pete Unseth 9:10- 9:40 Erin SanGregory, GIAL Differential case marking in Wakhi 9:40- 10:10 Paul Kroeger, GIAL Expressive CV-reduplication in Kimaragang 10:10- 10:30 Break Session 2: English Syntax Semantics Chair: Shobhana Chelliah 10:30- 11:00 Carly J. Sommerlot, UTA Subject ellipsis and the left periphery in English 11:00- 11:30 Alexis Palmer, UNT Situation entity types: Automatic classification of clause-level aspect 11:30- 12:00 Dan Amy, UTA On the obligatory appositive interpretation of massive pied-piping 12:00- 1:15 Lunch Break & Poster Session Poster Laurel Smith Stvan, UTA Expressing causation: Using corpus data to distill connections from vernacular prose Poster Alberto Miras- Fernández, TA&MUC Comprehension and processing of adjectives by Spanish heritage speakers: The design of an eye tracking study Poster Elisa Gironzetti & Flavia Belpoliti, TA&MUC Written proficiency in Spanish as a heritage language: The effects of a curriculum redesign Poster Juan Pablo Orejudo González, TA&MUC La radio de todos: A heritage speakers course Poster Elaine Marie Scherrer, GIAL Collecting lexical data in a limited-access situation Poster Alexandra Peak, UNT ‘Real-life Georgia O’Keefe painting’, ‘Furburger’, ‘Mighty man noodle’, and ‘Vlad the impaler’: Conceptual metaphors for vagina and penis Poster Kent Rasmussen, UTA The functional load of tone in Bantu D30
Transcript of › documents › 2016-ling-conference-abstracts.docx?ver=1.4 · Web view GRAMMAR SKETCH - Dallas...
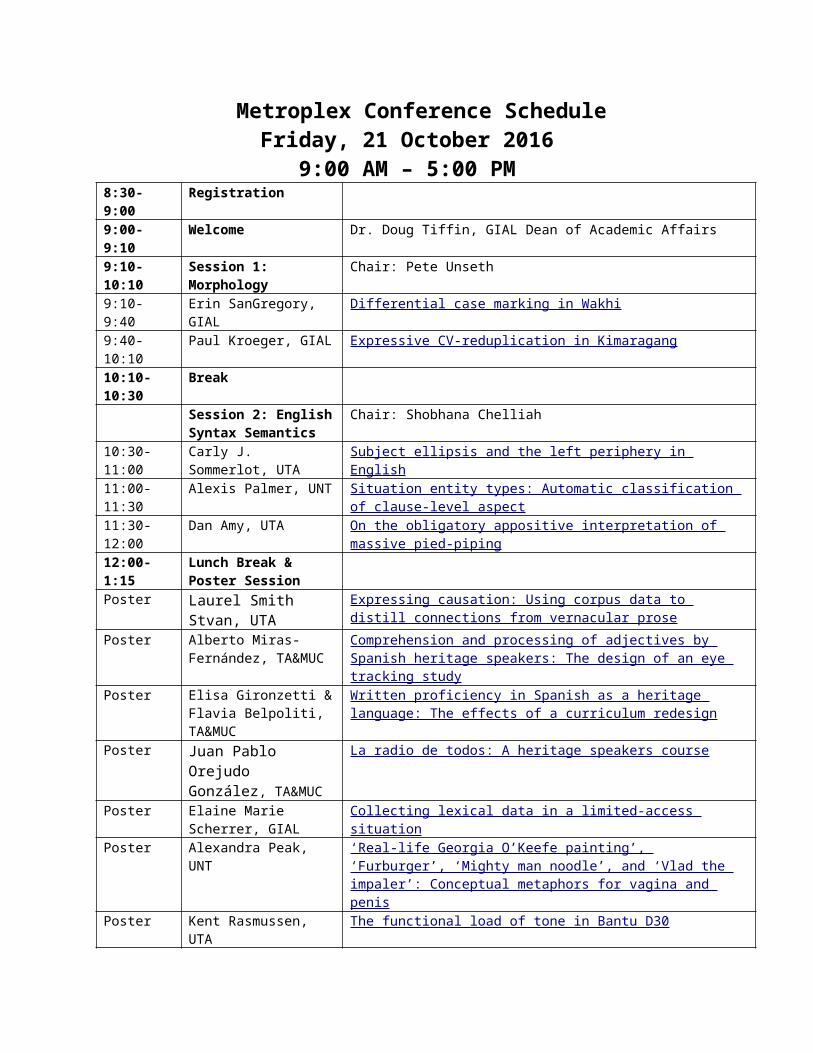
Metroplex Conference ScheduleFriday, 21 October 2016
9:00 AM – 5:00 PM8:30-9:00 Registration9:00-9:10 Welcome Dr. Doug Tiffin, GIAL Dean of Academic Affairs9:10-10:10 Session 1: Morphology Chair: Pete Unseth9:10-9:40 Erin SanGregory, GIAL Differential case marking in Wakhi9:40-10:10 Paul Kroeger, GIAL Expressive CV-reduplication in Kimaragang10:10-10:30 Break
Session 2: English Syntax Semantics
Chair: Shobhana Chelliah
10:30-11:00 Carly J. Sommerlot, UTA Subject ellipsis and the left periphery in English11:00-11:30 Alexis Palmer, UNT Situation entity types: Automatic classification of clause-level aspect11:30-12:00 Dan Amy, UTA On the obligatory appositive interpretation of massive pied-piping12:00-1:15 Lunch Break &
Poster SessionPoster Laurel Smith Stvan,
UTAExpressing causation: Using corpus data to distill connections from vernacular prose
Poster Alberto Miras-Fernández, TA&MUC
Comprehension and processing of adjectives by Spanish heritage speakers: The design of an eye tracking study
Poster Elisa Gironzetti & Flavia Belpoliti, TA&MUC
Written proficiency in Spanish as a heritage language: The effects of a curriculum redesign
Poster Juan Pablo Orejudo González, TA&MUC
La radio de todos: A heritage speakers course
Poster Elaine Marie Scherrer, GIAL
Collecting lexical data in a limited-access situation
Poster Alexandra Peak, UNT ‘Real-life Georgia O’Keefe painting’, ‘Furburger’, ‘Mighty man noodle’, and ‘Vlad the impaler’: Conceptual metaphors for vagina and penis
Poster Kent Rasmussen, UTA The functional load of tone in Bantu D30Poster Melissa Robinson, Nancy
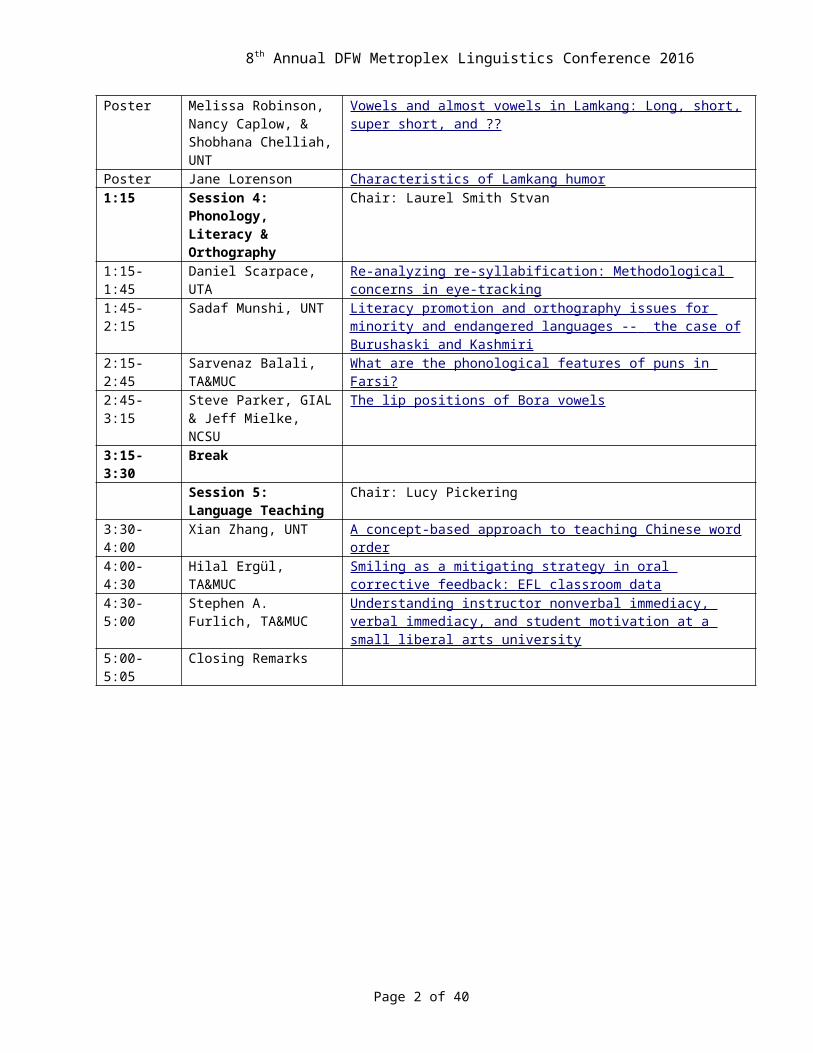
Caplow, & Shobhana Chelliah, UNT
Vowels and almost vowels in Lamkang: Long, short, super short, and ??
Poster Jane Lorenson Characteristics of Lamkang humor1:15 Session 4: Phonology,
Literacy & OrthographyChair: Laurel Smith Stvan
1:15-1:45 Daniel Scarpace, UTA Re-analyzing re-syllabification: Methodological concerns in eye-tracking1:45-2:15 Sadaf Munshi, UNT Literacy promotion and orthography issues for minority and endangered
languages -- the case of Burushaski and Kashmiri 2:15-2:45 Sarvenaz Balali,
TA&MUCWhat are the phonological features of puns in Farsi?
2:45-3:15 Steve Parker, GIAL & Jeff Mielke, NCSU
The lip positions of Bora vowels
3:15-3:30 BreakSession 5: Language Teaching
Chair: Lucy Pickering
3:30-4:00 Xian Zhang, UNT A concept-based approach to teaching Chinese word order4:00-4:30 Hilal Ergül, TA&MUC Smiling as a mitigating strategy in oral corrective feedback: EFL
classroom data4:30-5:00 Stephen A. Furlich,
TA&MUCUnderstanding instructor nonverbal immediacy, verbal immediacy, and student motivation at a small liberal arts university
5:00-5:05 Closing Remarks
8th Annual DFW Metroplex Linguistics Conference 2016
Page 2 of 27
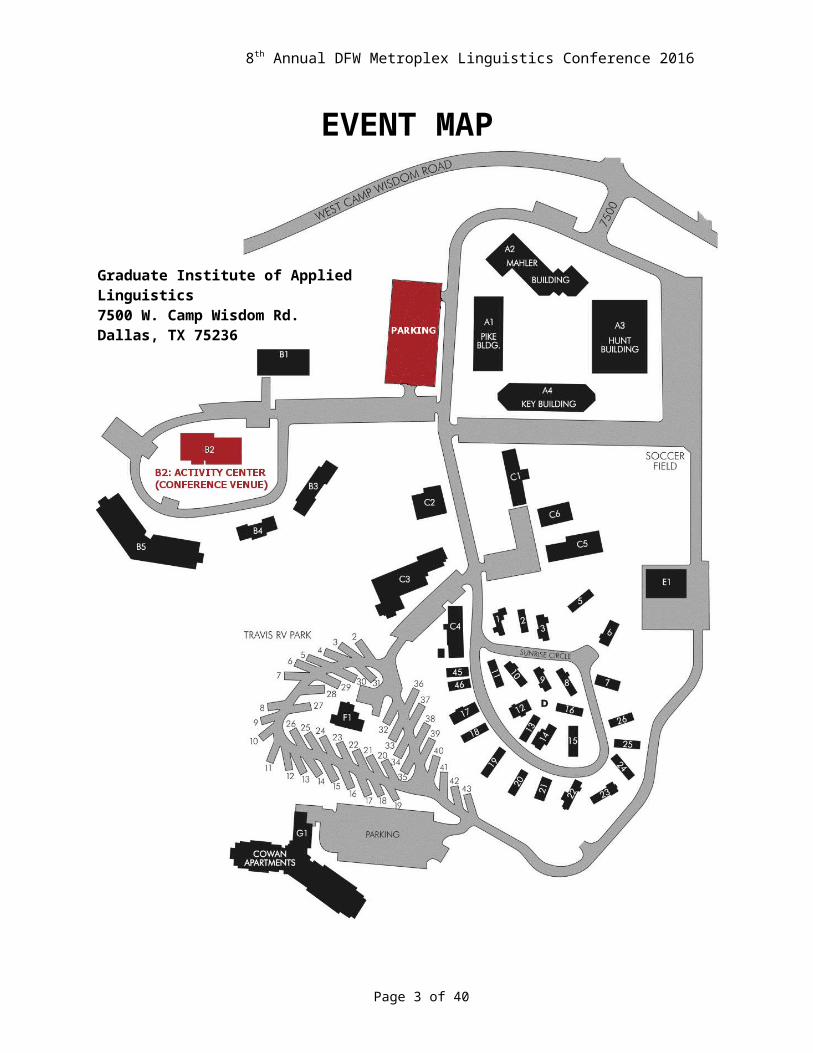
EVENT MAP
Graduate Institute of Applied Linguistics7500 W. Camp Wisdom Rd.Dallas, TX 75236
8th Annual DFW Metroplex Linguistics Conference 2016
On the obligatory appositive interpretation of massive pied-pipingDaniel Amy, UTA
In relative clause formations, additional material can be ‘pied-piped’ to the left edge of the relative clause by a wh-element (Ross, 1967). The structure in (2) depicts what Safir (1986) and Heck (2008) subcategorize as ‘heavy’ or ‘massive pied-piping’. This is compared to the wh-element only movement in (1). Safir, Heck, and others note that when massive pied-piping occurs, the relative clause must be interpreted as an appositive. This contrasts with the availability of a restrictive reading of the relative clause in other pied-piping contexts such as ‘recursive pied-piping’ by a specifier, as shown in (3). The acceptance of massive pied-piping forcing an appositive reading has not been universally accepted (Stockwell et al., 1973; Huddleston & Pullum, 2002).
(1) Reports [ [ which ]i the government prescribes the height of the lettering on the covers of t i ] are invariably boring.
(2) Reports [ [ the covers of which ]i the government prescribes the height of the lettering on t i ] are invariably boring.
(3) The student [ [whose paper ]i I read ti ] knew nothing about syntax.
This study investigates the assumption of an appositive reading of massive pied-piping with diagnostics derived from Demirdache (1991), including the availability of parasitic gap licensing, weakest crossover effects, and variable binding. While massive pied-piping constructions appear to pattern after appositive relative clauses with respect to weakest crossover and variable binding, parasitic gaps appear to be licensable in massively pied-piped structures where they are not licensed in appositives. This information suggests that, while massive pie-piping allows for and possibly prefers an appositive interpretation, it does not necessitate an appositive interpretation.
References
Demirdache, Hamida Khadiga. 1991. Resumptive chains in restrictive relatives, appositives and dislocation structures. Cambridge, MA: MIT PhD thesis.
Heck, Fabian. 2008. On pied-piping: Wh-Movement and beyond. Berlin: Mouton de Gruyter.Huddleston, Rodney D. & Geoffrey K. Pullum. 2002. The Cambridge grammar of the English language.
Cambridge, UK: Cambridge University Press.Ross, John R. 1967. Constraints on variables in syntax. Cambridge, MA: MIT PhD thesis.Safir, Ken. 1986. Relative clauses in a theory of binding and levels. Linguistic Inquiry 17(4). 663–689. Stockwell, Robert P., Paul Schacter & Barbara Hall Partee. 1973. The major syntactic structures of
English. New York: Holt, Rinehart and Winston.
Page 3 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
What are the phonological features of puns in Farsi?Sarvenaz Balali, Applied Linguistics Lab, Texas A&M University-Commerce
In this study I will examine puns in Farsi from a phonological perspective. A significant amount of research exists in the field of linguistic features of verbal humor and more specifically in regard to puns. The focus of this study will be on phonological features of puns in Farsi. In this study, I aim to point out that Farsi puns, as verbal humorous phenomena that exist in Farsi humorous texts, use the phonetic processes and have the phonological features that have been observed in puns in other languages. The main and general goal of this research is to provide additional evidence on the universality of puns and their phonological features.
This study is based on a corpus of 150 imperfect puns extracted from Farsi humorous texts. In my analysis of the puns I specifically attempt to identify the involved phonetic processes and their frequency of occurrence in Farsi puns. Moreover, the manipulated items in the puns have been identified and are presented in order of the frequency of their manipulation. Then I have examined the manipulation threshold and the domains of manipulation within the syllable. Overall, the results of the study confirm the hypotheses formulated in previous studies, mainly Guidi (2012) which can be regarded as a synthesis of previous studies. The four phonetic processes observed in this study are substitution, addition, deletion and inversion, with substitution as the most and inversion as the least frequent. The manipulated items in order of frequency of manipulation are: Phoneme, syllable, word boundary, syllable boundary and stress. The manipulation threshold is limited to five elements and within the syllable the onset is manipulated most frequently implying that, in Farsi puns the rhyme of the syllable is preserved and can function as an essential factor in punning in Farsi. Moreover, in my analysis, whenever the syllable boundary was manipulated it did not entail manipulation of the word boundary, which is a new finding of my study.
References
Balali, S. 2011. Linguistic study of satire in five selected issues of Gol Agha Biweekly . Master’s Thesis. Tehran: Payame Noor University
Guidi, A. 2012. Are pun mechanisms universal? A comparative analysis across language families. Humor 25(3). 339–366.
Hempelmann, Christian F. 2003. Paronomasic puns: Target recoverability toward automatic generation. Ph.D. Thesis. Purdue: Purdue University.
Page 4 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
Smiling as a mitigating strategy in oral corrective feedback: EFL classroom dataHilal Ergül, Texas A&M University – Commerce
The purpose of this pilot study is to shed light on whether or not smiling can act as a mitigating strategy when teachers are giving oral corrective feedback to students in the classroom, therefore increasing the effectiveness of the feedback. As per Lyster and Ranta (1997), feedback effectiveness is operationalized in terms of uptake; an immediate repair attempt by the student, while the Facial Action Coding System (Ekman et al., 1978) is utilized to determine teachers’ facial expression during the feedback instance. The data used were collected at a private language institute in Turkey from seven EFL teachers in three adult classrooms at the intermediate level of English. A previous analysis of a non-native speaking male teacher’s corrective feedback instances has shown that when the teacher displays a genuine smile, the feedback is more effective than when s/he does not. The current study analyzes the feedback provided to students by four teachers in the first on-task interaction of each class. This pilot study may lead to experimental studies where smiling is controlled, and will have implications for pedagogical practice and humor studies.
References
Ekman, P., W. V. Friesen & J. Hager. 1978. The facial action coding system (FACS): A technique for the measurement of facial action. Palo Alto, CA: Consulting Psychologists.
Lyster, R. & L. Ranta. 1997. Corrective feedback and learner uptake. Studies in Second Language Acquisition 19(1). 37-66.
Page 5 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
Understanding instructor nonverbal immediacy, verbal immediacy, and student motivation at a small liberal arts university
Stephen A. Furlich, Department of Literature & Languages, Texas A&M [email protected]
Instructor communication behaviors and student motivation to learn relationships were studied at a small liberal arts university. Specifically, relationships between instructor nonverbal immediacy, verbal immediacy behaviors and student motivation to learn were measured. Only instructor verbal immediacy behaviors had a significant linear regression relationship result with student motivation to learn. These results from a small liberal arts university are discussed in reference to previous research that measured these variables primarily at research universities. The results and implications are addressed for instructors and administrators.
Page 6 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
Written proficiency in Spanish as a heritage language: The effects of a curriculum redesign
Elisa Gironzetti & Flavia Belpoliti, Texas A&M [email protected] & [email protected]
This study presents the preliminary results of the analysis of written texts produced by Spanish Heritage Language Learners (SHLL) in Spanish after a two-semester long program at TAMUC (Belpoliti & Gironzetti, forthcoming). The program aimed at: (1) advancing literacy in Spanish, (2) increasing management of academic registers, and (3) providing the foundation to develop and expand self-regulatory strategies for continuous language learning (Wenden, 1998; Van Lier, 2008; Duff, 2012). The analysis of students productions at four points in time (mid- and end-semester per two semesters) offers a clear picture of students’ progress in the following areas: vocabulary development (lexical variation, range, and density), grammatical complexity (number of complete sentences and clauses per sentence), and rhetoric adequacy (use of discourse markers and discourse organization).
References
Belpoliti, Flavia & Elisa Gironzetti, (forthcoming). Metaknowledge and metalinguistic strategies in the Spanish for heritage learners classroom: A curriculum redesign. Hispanic Studies Review.
Duff, Patricia. 2012. Identity, agency and SLA. In A. Mackey & S. Gass (eds.), Handbook of second language acquisition, 410-426. London: Routledge.
Van Lier, Leo. 2008. Agency in the classroom. In J. P. Lantolf & M. E. Poehner (eds.), Sociocultural theory and the teaching of second languages, 163-186. London: Equinox.
Wenden, Anita L. 1998. Metacognitive knowledge and language learning. Applied linguistics 19(4). 515-537.
Page 7 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
Expressive CV-reduplication in KimaragangPaul Kroeger, Graduate Institute of Applied Linguistics & SIL Intl.
This talk presents evidence for distinguishing several different patterns of CV-reduplication in the morphology of Kimaragang Dusun, an endangered Philippine-type language of northeastern Borneo. Many Philippine languages use CV-reduplication on the verb to mark imperfective or non-completive aspect. CV-reduplication sometimes has aspectual functions (specifically, continuous and habitual) in Kimaragang as well. I argue that a distinct pattern, “emphatic reduplication”, occurs on both nouns and verbs and contributes primarily expressive (or “affective”) meaning, rather than descriptive (truth-conditional) meaning.
Emphatic reduplication in verbs is potentially homophonous with the descriptive aspectual uses of CV-reduplication. Certain reduplicated forms, e.g. ro-rolopon ‘be devoured’, are three-ways ambiguous, allowing continuous, habitual, or emphatic readings. However, there are several morphological and syntactic criteria which allow us to distinguish emphatic reduplication from the other two categories: (i) We know that the three categories are distinct because some base forms (e.g. transitive Active Voice verbs) exhibit three distinct allomorphs: mii-tiag (continuous), mooniag (habitual), mo<ni>niag (emphatic) ‘forbid’; maa-takaw (continuous), maanakaw (habitual), ma<na>nakaw (emphatic) ‘steal’. (ii) Only emphatic reduplication allows “infixing” reduplication with consonant-initial base forms (mo<ni>niag = <REDUP>m-poN-tiag ‘forbid-AV’). (iii) Past tense inflection cannot co-occur with continuous or habitual aspect, but is common with emphatic reduplication. (iv) In several syntactic environments, continuous aspect is required but habitual and emphatic reduplication are impossible, e.g. perception complements (‘I saw NP X-ing) and picture-taking (‘I took a picture of NP X-ing).
Kaplan (2004) distinguishes “subjective” expressives (like ouch), which express the speaker’s attitudes and feelings, from “objective” expressives (like oops), which express something about situations in the external world. Kaplan claims the difference between descriptive vs. expressive meaning is not the type of information conveyed but the way in which it is conveyed (describing vs. expressing or “displaying”). Emphatic reduplication in Kimaragang has both subjective and objective expressive functions. CV-reduplication can be used subjectively in nouns to express negative attitudes toward the referent of the NP, e.g. ta-tasu ‘mangy/scrawny dog’ (from tasu ‘dog’); bo-boos (boos ‘boss’) referring to a bad-tempered boss. Subjective functions in verbs include describing unexpected or inappropriate actions, expressing disapproval, scolding, etc. (ex. 1a-b). Objective functions of emphatic reduplication in verbs include ‘begin to’ (ex. 2), ‘do briefly’, and ‘do first’ (in a sequence of actions).
Expressive reduplication is distinguished semantically from descriptive reduplication because expressive content is immune to negation and questioning (Potts 2006). Habitual and continuous aspects can be questioned and negated, but emphatic reduplication always takes scope over negation and interrogative force. In (3), for example, the speaker’s judgment that the described situation is unexpected and newsworthy cannot be interpreted as part of what is being negated. Similarly with the objective expressive functions: the ‘begin’ component of meaning can be negated when it is encoded by a separate predicate, but not when it is expressed by emphatic reduplication (4-5).
Another characteristic property of expressive meaning is that it is SCALABLE and REPEATABLE (Potts 2006). Emphatic reduplication can be used to reinforce the entailed meaning of lexical predicates without any feeling of redundancy, something not normally possible with descriptive content, as in (6a) where emphatic reduplication reinforces the lexical content of the predicate ginaray ‘wreck’. Similarly, the emphatic reduplication in (1a) reinforces the semantic contribution of the particle katoy, which indicates disapproval. Emphatic reduplication is reinforced by the verum focus clitic =i’ in in (1b, 6b). Finally, emphatic reduplication of nouns can be reinforced by emphatic reduplication of one or more verbs within the same sentence, as in (6b).
Page 8 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
() a. Aso no weeg, minaan katoy dialo bu-buak-o’ modsu.not.exist ASP water AUX.PST PTCL 3sg DUP-waste.OV AV.bathe‘There is no water left, he wasted it when he was bathing.’
b. “Aku mangakan do sungot” ka dialo, dot mina<nga>ngakan=i’.NEG.1sg AV.eat ACC sago.grub say 3sg COMP <DUP>AV.PST.eat=FOC‘He said, “I’m not going to eat sago grubs,” but he did eat them.’
() Ru-rumangkama no diiri i bayag di iyay.DUP-AV.creep ASP this NOM sweet.potato GEN mother‘Mother’s sweet-potato plants are beginning to spread.’
() Okon.ko’ ki-k<in>asut-Ø dialo it kasut yo,NEG DUP-<PST>shoe-OV 3sg NOM shoe 3sg.GEN
nisawit nogi sid kayab.PST.IV.hang PRTCL LOC shoulder‘He didn’t wear his shoes on his feet, he hung them over his shoulder instead.’
() a. Ru-rumangkama no diiri i bayag di iyay.DUP-AV.creep ASP this NOM sweet.potato GEN mother‘Mother’s sweet-potato plants are beginning to spread.’
b. Tumimpuun no rumangkama i bayag di iyay.AV.begin ASP AV.creep NOM sweet.potato GEN mother‘Mother’s sweet-potato plants are beginning to spread.’
() a. Okon ko’ tumimpuun nogi rumangkama i bayag di iyay, oleed no diiri.‘Mother’s sweet-potato plants are not beginning to spread, it has been a long time already.’
b. *Okon ko’ ru-rumangkama nogi i bayag di iyay, oleed no diiri.(intended meaning as in a)
() a. Ginaray no i bo-bosikal di Uddui…worn.out already NOM DUP-bicycle GEN (name)‘Uddui’s bicycle is a wreck, (…but it can still get to the paddy field.)’
b. Bu-buka-a’ dialo it odia nga’ ga-gata=i’ bala’ iri.DUP-open-OV.ATEMP 3sg NOM gift but DUP-frog=FOC MIR this‘He/she opened the present, and it was a frog!’
Page 9 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
Characteristics of Lamkang humorJane Lorenson, University of North Texas
The Lamkang project team at the University of North Texas has recorded several folk tales of the Lamkang, a tribe in northeast India. The humorous tales exhibit several key differences from Western humor. This poster explores the ways in which Lamkang humor differs from Western humor in its treatment of death and injury, in its treatment of hero/anti-hero characters, and in its personalization of the objects of the humor. The stories discussed in this poster center on a character named Benglam, a folk hero who also serves as the object of affectionate ridicule in the stories elicited from native speakers.
Page 10 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
Comprehension and processing of adjectives by Spanish heritage speakers: The design of an eye tracking study
Alberto Miras-Fernández, Texas A&M [email protected]
This poster presents the design of an eye tracking study that focuses on Spanish heritage speakers’ comprehension and processing of Spanish adjective meaning according to their placement in the noun phrase (Demonte, 1999), in line with findings by Foucart and Frenck-Mestre (2012). Thirty Spanish heritage speakers belonging to three different sociolinguistic generations (Valdes, 2001) and a control group of 10 Spanish native speakers will be presented with a matching visual-reading task. Each task consists of 60 trials, each showing an image and a sentence in Spanish. Participants have to decide whether the image represents the meaning expressed by the noun phrase. The 60 sentence-image trials consist of the following: a) 20 noun phrases constructed by combining 10 nouns with 10 critical adjectives (adjectives that change their meaning depending on their placement in the noun phrase) in pro- and post-nominal position (e.g., un gran carro and un carro grande) that match the meaning expressed by the picture; b) 20 noun phrases constructed by combining 10 nouns with 10 critical adjectives in pro- and post-nominal position that do not match the meaning expressed by the picture; c) 10 noun phrases constructed by combining 10 nouns with 10 distractor adjectives in pro- and post-nominal position (e.g., *un rojo libro and un libro rojo) that match the meaning expressed by the picture; and d) 10 noun phrases constructed by combining 10 nouns with 10 distractor adjectives in pro- and post-nominal position that do not match the meaning expressed by the picture. For each participant, the following metrics will be recorded: correct and incorrect answers; response time; eye tracking data for the two areas of interest, the noun phrase and the image. The data thus obtained will be quantitatively and qualitatively analyzed in order to find similarities and/or differences among native and heritage speakers, and different generations of heritage speakers of Spanish in the comprehension of adjective meaning, response time, and gaze behavior.
References
Demonte, V. 1999. A Minimal account of Spanish adjective position and interpretation. En Franco, J., Landa, A. & Martín, J. Grammatical Analyses in Basque and Romance Linguistics 45-75.
Foucart, A. & C. Frenck-Mestre. 2012. Can late L2 learners acquire new grammatical features? Evidence from ERPs and eye-tracking. Journal Of Memory And Language 66. 226-248. doi:10.1016/j.jml.2011.07.007.
Valdés, G. 2001. Heritage language students: Profiles and possibilities. In J. K. Peyton, D. A. Ranard, & S. McGinnis (eds.), Heritage languages in America: Preserving a national resource, 37-77. McHenry, IL: Delta Systems Co.
Page 11 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
Literacy promotion and orthography issues for minority and endangered languages –the case of Burushaski and Kashmiri
Sadaf Munshi, University of North [email protected]
As far as measures for preservation, promotion and revitalization of endangered and minority languages are concerned, Kashmiri and Burushaski present two very interesting cases. The two languages differ considerably in terms of the total number of speakers, in terms of whether or not they have a written body of literature claiming a historical and/or cultural prestige, and in terms of institutional support for native language literacy – factors that could significantly define their status as “endangered” or minority languages. Despite many differences, both the languages are facing certain challenges pertaining to the unresolved and often contentious issue of orthography which directly affect their potential and potency to survive the influences of rapid language shift, multilingualism and globalization. This poses serious problems for any ongoing attempts towards language promotion and revitalization.
Burushaski is a linguistic isolate, mainly spoken in the Hunza, Nagar and Yasin valleys of Gilgit-Baltistan (Pakistan), and by a small number of people in Srinagar, the summer capital of Indian-administered state of Jammu & Kashmir. It has approximately 100,000 speakers which are more or less evenly distributed in terms of the three major regional dialects; there are about 300 speakers of Burushaski in Srinagar. Until recently, the only materials available on the Burushaski language were studies by linguists, anthropologists and sociologists which talk about the grammar of the language and/or about Burushaski culture and society in a language other than Burushaski. In 2010, a full-fledged documentation project on the language was started by the author with the help of an award under the NSF-DEL program (although work on the project had already started in 2003). While work on the project continued over the years, it was discovered that orthography issues posed a serious problem. While several attempts have been made by various scholars to propose a writing system for the language, owing to a variety of reasons which pertain to language ideology, regional rivalries, and differential preferences for a Nastaliq (Arabic-based) as opposed to a Roman alphabet, no single proposal has yet been agreed upon.
As far as learnability, usability and potency of a script are concerned, the proposals for Burushaski writing system pose a variety of problems. These include: choice of Unicode non-compliant symbols causing problems in usability; use of a large number of diacritics which are neither learner-friendly nor computer-friendly; use of symbols that are practically redundant given the choice of a script; and use of variant spellings (i.e., different symbols for same sounds or same symbol for different sounds) leading to confusion across speakers. In order to address various technical, scientific and learnability concerns, the author offered two new proposals – one each based on Persio-Arabic and Roman alphabet. The proposals were discussed with various native speakers generating a strong feedback and input regarding their advantages and/or drawbacks.
Unlike Burushaski, Kashmiri (a language belonging to the Dardic group of Indo-Aryan languages) is spoken by about 5 million people. While majority of the speakers live in the Kashmir valley (India), substantial number of speakers also like in Pakistan-administered Kashmir and many different parts of the world. Kashmiri is perhaps the only language among the Dardic group which has a rich body of literature dating back to the 13th century. Yet, a majority of the speakers are illiterate in their first language. Because of lack of institutional support, especially in the past, and owing to political and ideological reasons, the language has suffered enormously. Furthermore, Kashmiri writers belonging to different religious communities have chosen to use two different writing systems (based on Devanagri and Persio-Arabic) as opposed to one common, standardized system, leading to a communication barrier with speakers who do not know a particular writing system. Dominance of languages such as Urdu/Hindi and English and a large-scale migration out of the homeland has set additional challenges in terms of rapid language shift among the younger generation who find it either challenging or unattractive to learn the language. In absence of availability of language learning materials away from Kashmir and limited
Page 12 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
exposure to the language, few children of expatriate Kashmiris end up learning their heritage language, let alone be willing to deal with additional scripts or read in two writing systems
Considering the two situations, it seems that a solution which is sensitive to the sociolinguistics, ideological as well as the ongoing technological issues, is long awaited. Adopting a Roman-based alphabet as opposed to any of the other competing writing systems has demonstrably been more preferable among the younger generation, especially among the expatriates. This, however, has its own cost which will be discussed at length in this presentation.
Page 13 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
La radio de todos: A heritage speakers courseJuan Pablo Orejudo González, Texas A&M University-Commerce
Heritage Spanish speakers are a heterogeneous group situated outside the standard definition of second language learners (Valdés, 2000). Designing and implementing specific curriculum, materials and resources for Heritage speakers is fundamental as most teaching resources have focused on second language teaching, which does not support heritage learner language development (Durán-Cerdá, 2008). The project La Radio de Todos is a radio program in Spanish created by students to be broadcast on local radios and the Internet. It supports heritage learners’ main pedagogical needs: grammar development, academic writing, and effective communication with Spanish speakers in a formal context (Burgo, 2015; Potowsky, 2005). Students are divided in groups according to the roles expected in a radio program (news researcher, writer, editor, anchor, etc.), and they work on creating a weekly program. This project allows students to advance their language abilities in a formal register while offering them a broad and real-life context in which actively engage with their communities (Wu & Chang, 2010).
References
Burgo, C. 2015. Grammar teaching approaches for heritage learners of Spanish. Learn language, explore cultures, transform lives, 217-233.
Durán-Cerda, D. 2008. Strengthening “la identidad” in the heritage learner classroom: Pedagogical approaches. Hispania 91(1) Spanish Language Learning: Policy, Practice and Performance, 42-51.
Potowsky, K. 2005. Fundamentos de la enseñanza del español a hispanohablantes en los Estados Unidos. Madrid: Arco libros.
Valdés, G. 2000. Introduction. Spanish for native speakers: AATSP professional development series handbook for teachers K16, 1-20. Orlando, FL: Harcourt College.
Wu, M. & T. Chang. 2010. Heritage language teaching and learning through a macro-approach. Working Papers in Education Linguistics 25(2). 23-33.
Page 14 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
Situation entity types: Automatic classification of clause-level aspectAlexis Palmer, University of North Texas
[email protected]*This talk presents joint work with Annemarie Friedrich and Manfred Pinkal*
Approaches to the computational analysis of discourse are sensitive to different aspects of textual structure. We have begun to investigate a new way of approaching the task, following Smith's (2003) work on Discourse Modes. One component of this approach is the automatic labeling of clauses with their situation entity type, capturing aspectual phenomena at the clause level which are relevant for interpreting both semantics at the clause level and discourse structure. I will introduce a new corpus of texts from 13 genres (40,000 clauses) annotated with situation entity types, as well as lexical aspect of the main verb, genericity of the main referent, and habituality of the clause. I will also describe a system for automatic labeling of new clauses of English text. Our sequence labeling approach uses distributional information in the form of Brown clusters, as well as syntactic-semantic features targeted to the task. The system is robust across genres, reaching accuracies of up to 76%.
References
Carlota S. Smith. 2003. Modes of discourse. Cambridge University Press.
Page 15 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
The lip positions of Bora vowelsSteve Parker, Graduate Institute of Applied Linguistics
Jeff Mielke, North Carolina State [email protected] & [email protected]
Bora is a Witotoan language spoken by about 750 persons in the Amazon jungle of Peru and 100 in Colombia. Its phonemic vowels are /i e a o ɨ ɯ/, where /ɨ/ is high, central, unrounded and /ɯ/ is high, back, unrounded (Thiesen and Weber 2012). A contrast between a central and a back vowel which are otherwise identical is theoretically significant since it shows that the binary feature [ back] is too weak to encode all phonological contrasts along the front/back dimension. The tongue positions of Bora vowels have been acoustically confirmed with measurements of F1-F3 (Parker 2001). What is lacking is an instrumental analysis of lip positions. Impressionistically all of the Bora vowels except /o/ are articulated with unrounded lips. However, Ladefoged and Maddieson (1996) note that high back unrounded vowels in languages such as Japanese involve a gesture of lip compression or inrounding. Consequently, an important research question is whether the distinction between /ɨ/ and /ɯ/ in Bora can be relegated to a difference in lip positions rather than to a primary contrast in tongue backness? To test this hypothesis, we obtained video recordings of native speakers on location in a Bora village (6 males and 7 females). In order to facilitate measurements, four brightly colored dots were placed on each person’s lips: one in the middle of the upper lip, one in the middle of the lower lip, and one on each side corner (forming a diamond). The preliminary statistical results indicate that the segments /i e a ɨ ɯ/ are all produced with identical lip positions, whereas /o/ is the only vowel that is clearly rounded in any way.
The importance of these findings is that they present a challenge for distinctive feature models which claim that vowel systems cannot contrast more than two degrees of tongue backness, exemplified by Selkirk (1993) and Duanmu (2016). In Selkirk’s approach, non-front vowels of the same height must differ in some tongue root or labial setting. The data on Bora vowels which we summarize here confirm the need for a three-way phonological distinction between front, central, and back tongue positions, as posited by Clements (1991) and Ladefoged and Maddieson (1996). While several reports of languages of this type rely primarily on informal descriptions, our study provides empirical data ruling out the possibility that vowels such as /ɨ/ and /ɯ/ can be distinguished by a feature of lip rounding in this case.
References
Clements, George N. 1991. Place of articulation in consonants and vowels: A unified theory. Working Papers of the Cornell Phonetics Laboratory 5. 77-123. Ithaca, New York: Cornell University.
Duanmu, San. 2016. A theory of phonological features. Oxford: Oxford University Press.Ladefoged, Peter & Ian Maddieson. 1996. The sounds of the world’s languages. Malden, Massachusetts
and Oxford: Blackwell.Parker, Steve. 2001. The acoustic qualities of Bora vowels. Phonetica 58. 179-195.Selkirk, Elisabeth. 1993. [Labial] relations. Unpublished ms. University of Massachusetts Amherst. Thiesen, Wesley & David Weber. 2012. A grammar of Bora, with special attention to tone (SIL
International Publications in Linguistics 148). Dallas: SIL International.
Page 16 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
‘Real-life Georgia O’Keefe painting’, ‘Furburger’, ‘Mighty man noodle’, and ‘Vlad the impaler’: Conceptual metaphors for vagina and penis
Alexandra Peak University of North [email protected]
The third wave of feminism aims to break down existing gender roles and categorization based solely on sex or gender, allowing for gender to be fluid and a choice/performance, rather than linked to biology (Eckert and McConnell-Ginet 2003). At the beginning of this movement, Cameron (1992) investigated the underlying cultural and conceptual constructs of gender and sexuality in her study of terms for penis generated by college-aged students. She organized the terms into metaphorical categories (e.g., TOOLS and ANIMALS), which are used to understand the world, mapping women’s and men’s place onto it (Lakoff 1987; 1993). Cameron found that the terms for penis fit into the overarching conceptual metaphors of SEX IS CONQUERING, MEN ARE DOMINANT, and WOMEN ARE PASSIVE.
The present study adapts Cameron’s methods to investigate if the conceptual metaphors for penis that surfaced in her study 25 years ago are still salient today. For comparison, terms for vagina were also collected. The data comes from 16 males and 36 females who responded to an online survey yielding a total of 461 terms for penis and 289 terms for vagina. When applicable, the terms for penis were put into metaphorical categories based on Cameron’s (1992) classifications; terms for vagina were categorized based on the semantic categories outlined in Braun and Kitzinger (2001). New metaphorical categories were created for terms that were not collected in either of these studies. Some of these new categories include OTHER BODY PARTS and PLANT LIFE for penis and EXCRETIONS, LOCATIONS (including EMPTY SPACE), DESIRED ITEMS, MONEY AND JEWELS, and SEDUCTION for vagina.
The data suggests that the terms for vagina are more pejorative than the terms for penis: 48% versus .04% respectively. The metaphorical categories for vagina are also more negative than those for penis. As expected, data from participants aged 35-54 fits more into the categories established by Cameron (1992), while participants aged 18-34 generated novel terms that often referred to contemporary culture, such as Gyrados’ Bubblebeam and sonic screwdriver. Females generated more terms for vagina, yet contrary to the results in Cameron (1992), there was no gender difference in the number of terms for penis. Terms for vagina from women mostly fell into the category of PERSONAL TERMS, which include nicknames given to genitalia such as ‘Judy’ or ‘Princess pussy,’ while men offered more terms of ‘desirability’ such as ‘nectar of the Gods’ or ‘buried treasure.’ Dissimilar to Cameron (1992), the majority of terms for penis were categorized into either WEAPONS or TOOLS. These include terms such as ‘Hammer of Thor’ or ‘Destroyer of worlds.’
The results suggest that many of the gender boundaries that the third wave of feminism has tried to break down persist in the terms for penis and are also present in the terms for vagina. Lakoff’s (1987) conceptual metaphor PHYSICAL APPEARANCE IS PHYSICAL FORCE, which he suggests is encompassed in the “logic of rape,” also surfaces in the data from this study. More importantly, this sexism occurs in the terms provided by both males and females.
References
Braun V. & C. Kitzinger. 2001. “Snatch”, “hole”, or “honey-pot”? Semantic categories and the problem of nonspecificity in female gender slang. The Journal of Sex Research 38(2). 146-158.
Cameron, D. 1992. Naming of parts: Gender, culture, and terms for the penis among American college students. American Speech 67(4). 367-382.
Eckert, P. and S. McConnell-Ginet. 2003. Language and gender, 2nd edn. New York: Cambridge University Press.
Lakoff, G. 1993. The contemporary theory of metaphor. In A. Ortony (ed.), Metaphor and thought, 2nd edn. Cambridge: Cambridge University Press, 202-251.
Lakoff, G. 1987. The metaphorical logic of rape. Metaphor and Symbolic Activity 2(1). 73-79.
Page 17 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
The functional load of tone in Bantu D30Kent Rasmussen, UT [email protected]
Some 80% of African languages are tonal (Heine & Leyew 2008). While it is broadly understood that tone is more important in a given language than in another, there remains no useful metric to determine the functional load of tone. That is, given that a language uses consonants, vowels, and tone to distinguish one word (or its usage) from another, how important is tone to communicating these distinctions?
One might think that one could simply count the inventory of contrasts, but this is often unhelpful. For instance, Congo Swahili [swc] has by one count 28 consonants and five vowels, while six Bantu D30 languages show 26-33 consonants each and seven or nine vowels. With more vowels and comparable consonant inventories, compared to Swahili. these languages also make use of tone, while Swahili does not.
This paper demonstrates another methodology for evaluating the functional load of tone, through a comparative analysis of four of these Bantu D30 languages. Despite the similarity in number of segmental and tone contrasts across these languages, this study reveals differences in how each is used across the languages.
The summary in (1) shows pronominal systems in columns, decreasing dependence on tone (and increasing in dependence on segments) from left to right. That is, Bɨra [brf] is segmentally fully specified for all persons, while Budu [buu] is fully distinctive on a segmental level, but depends on a default null pronoun for 3s. Mbo [zmw] and Ndaka [ndk] each have two null pronouns, which are distinct one from the other by tone alone. Furthermore, Ndaka has another set of pronouns distinguished only by tone. Ndaka leans further on tone through a number of tonally minimal root pairs, such as in (2) and (3). Cognates for these verb roots in the other languages either have not been found, or are segmentally distinct.(1) Bound subject pronouns in Bantu D30 languages
[ndk] [zmw] [buu] [brf]n- [L] m- [L] m- [L] nɨ- [L] I∅- [L] ∅- [L] w- [L] ʉ- [L] you.sg∅- [H] ∅- [H] ∅- [H] a- [L] he/shek- [H] t- [H] k- [H] kɨ- [L] wen- [H] n- [H] n- [H] ɓʉ- [H] you.plɓ- [H] ɓ- [H] ɓ- [H] ɓa- [H] they
(2) [ndk] high/rising tonal minimal pair between verb rootsa. kɔjana [˨˨˨ ˨˧˦˥ ˨˨
˨]to prepare food
b. kɔjana [˨˨˨ ˥˥˥ ˨˨˨] to be tired(3) [ndk] low/high tonal minimal pair between verb roots
a. komijo [˧˧˧ ˧˧˧ ˧˧˧] to swallowb. komijo [˨˨˨ ˦˦˦ ˨˨˨] to squeeze,press
References
Heine, Bernd & Zelealem Leyew. 2008. Is Africa a linguistic area? In Heine, Bernd & Derek Nurse (eds). A linguistic geography of Africa, 15-35. Cambridge: Cambridge University Press.
Page 18 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
Vowels and almost vowels in Lamkang: Long, short, super short, and ??Melissa Robinson, University of North Texas
Nancy Caplow, Oklahoma State University, StillwaterShobhana Chelliah, University of North Texas
[email protected]; [email protected]; [email protected]
Lamkang is an ethnically Naga Tibeto-Burman language of the Kuki-Chin subgroup and is spoken in Chandel District, Manipur, India by approximately 3000 people. A close phonetic examination of Lamkang reveals four characteristic vowel lengths: long vowels (typically l 21 ms); short vowels (typically 122 ms); super short vowels (typically – 3 ms); and incipient vowels (typically – 2 msec). Long and short vowels contrast phonemically as in (1) and (2).
(1) a. [com] 'mix as in rice or lentils' ( 29 ms) versusb. [com] ‘pick' ( 10 ms)
(2) a. [tuŋ] 'ride as in a car or on a horse' (20 ms) versusb. [tuŋ] 'later' (5 ms)
What we are calling super short vowels are vocalic segments occurring with agreement prefixes (e.g., mV- ‘first person object’). This is usually schwa but sometimes a short [i] or [a] due to front/back harmony with the root vowel. An example is provided in (3).
(3) mətəkyɔːnm- t- kyoonOBJ:1 INV catch ‘You are catching me’
Lamkang exhibits an additional vowel like segment which breaks up CCCC prefix sequences as in (4) - (5).
(4) məkəptsorrə m- k- p- cor -raOBJ:1 SUBJ:3 CAUS soak FUT‘He will soak me’
(5) mtəpniːtsaːklamm- t- pnii- -cak -lamOBJ:1 INV laugh -MID SBJ:3.PL‘They are laughing at me’
This presentation will illustrate these four phonetic vowel length contrasts using annotated PRAAT waveforms and spectrograms and will provide representative examples of each vowel type in Lamkang words.
Page 19 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
Differential case marking in WakhiErin SanGregory, Graduate Institute of Applied Linguistics
Some languages that use case to mark nominals exhibit a phenomenon known as DIFFERENTIAL CASE MARKING. Differential case marking is the general term for a particular class of regular alternations in the case assigned to a core argument in a clause. Malchukov & de Swart (2009: 341) identify two main types of case alternations. In SPLIT ALTERNATIONS, an individual verb assigns a case value other than the expected one to a core argument (e.g., quirky case). In FLUID ALTERNATIONS, a core argument of a verb may receive a different case value in different contexts based on the transitivity parameters of the clause.
This paper focuses on differential case marking in Wakhi, a Pamir language of the Indo-Iranian family that has at least six and perhaps as many as eight cases. Wakhi exhibits two types of fluid case alternations: DIFFERENTIAL SUBJECT MARKING (DSM) and DIFFERENTIAL OBJECT MARKING (DOM). Both types alternate between the nominative and accusative cases.
DSM in Wakhi manifests as accusative case on subjects. However, it is highly restricted, occurring only on 1SG and 2SG pronominal subjects in the past tense, as seen in examples (1) and (2). It occurs on A regardless of whether the sentence has a highly-affected P (e.g. second instance of maʐ ‘1SG.ACC’ in (2)) or a less-affected P (eg. tao ‘2SG.ACC’ in (1)), and it also occurs on S (e.g. first instance of maʐ ‘1SG.ACC’ in (2)). Contrary to appearances and expectations raised by areal features, DSM in Wakhi is not split ergativity because (1) case marking and verbal agreement patterns provide strong evidence for an accusative system, and (2) in an ergative system, neither S nor P should take the same case as A (as happens in Wakhi). Following Donohue & Donohue’s (2016) analysis of DSM in Bumthang, I propose that a complex set of syntactic, semantic, and discourse factors, namely focus, realis, person, number, telicity, agentivity, and volitionality, may be responsible for conditioning the appearance of accusative vs. nominative subjects in Wakhi. I have organized these factors into a binary decision tree and a feature matrix that can be used to analyze occurrences of DSM in my corpus of collected texts and ultimately to determine whether this set of factors is sufficient for predicting when DSM occurs in Wakhi.
In contrast to DSM, DOM in Wakhi is quite unrestricted, occurring on nouns and pronouns alike in both the past and non-past tenses. When looking at nouns, DOM appears to involve the nominative and accusative cases (e.g. ʝəɯ ‘cow.NOM’ in (3) and ʝəɯ-i ‘cow-ACC’ in (4)); however, pronouns alternate between their basic suppletive accusative form (e.g. tao ‘2SG.ACC’ in (5)), and the suppletive form inflected with the nominal accusative suffix -i (e.g. tao-i ‘2SG.ACC-ACC’ in (6)), which suggests that there may be two accusative cases in Wakhi. Bashir (2009: 828) essentially takes this approach, although with different terminology. Malchukov & de Swart (2009: 345) note that transitivity is nearly always a factor in DOM, and they single out Hopper & Thompson’s (1980) parameters related to O-individuation (animacy, definiteness, and specificity) as the factors that are most often involved in conditioning asymmetric DOM systems, of which Wakhi is one. I intend to use a feature matrix to chart these O-individuation parameters in my analysis of DOM in Wakhi texts so I can determine which factor or combination of factors is most relevant in conditioning DOM in Wakhi.
Examples
(1) Ø wind-i Ø, tao bə pəlis-əv wind-i, jan=ət rən.[they]see-PST [you] 2SG.ACC also police-PL.ACC see-PST then=2SG.SAGR
flee.PST'They (the police) saw you, and you also saw the police, and you fled.'
Page 20 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
(2) waxt-i ki wuçənvit, maʐ naod-i, wɔz ja ðaibə
time-SPECADVLZR blood become.PST 1SG.ACC cry-PST then DEM3man also
airɔn wərəʝn-i, jane wɔz wəzd-i pas tsə maʐ-ən mahzaratsurprisedremain-PST that.isagain come-PST again from1SG-ABL forgivenesstʃald-i: baxʃiʃ tsar, maʐ tao dəʃt-i.want-PST excuse do.2SG.IMP 1SG.ACC 2SG.ACC hit-PST'When it started bleeding, I cried; then that guy was also surprised, that is, then he came again and sought forgiveness from me: Forgive [me], I hit you.'
(3) rəʈʂ a=ʝəɯ ʂkurg.go.2SG.IMP EMPH=cow.NOM search.2SG.IMP'Go look for that cow.'
(4) jəm kaʂ ki rəʂt tr-əm ʂapt nag, əm ʂapt əmDEM1 boy ADVLZR go.3SG.SAGR over.to-DEM1 wolf direction
DEM1wolf DEM1ʝəɯ-i lətsər-t, jan əm kaʂ-i wədər-t.cow-ACC leave-3SG.SAGR then DEM1 boy-ACC grab-3SG.SAGR‘When this boy went over in the direction of the wolf, the wolf left the cow and then grabbed the boy.’
(5) waxt-i ki rən=ət, pəlis-əʃ tao win-di, nəi?time-SPECADVLZR flee.PST=2SG.SAGR police-PL 2SG.ACC see-PST no‘When you fled, the police saw you, no?’
(6) ti vrət tao-i win-d.2SG.GEN brother 2SG.ACC-ACC see-3SG.SAGR‘Your brother sees you.’
References
Bashir, Elena. 2009. Wakhi. In Gernot Windfuhr (ed.), The Iranian languages, 825-861. London: Routledge.
Donohue, Cathryn & Mark Donohue. 2016. On ergativity in Bumthang. Language 92(1). 179-188.Hopper, Paul J. & Sandra A. Thompson. 1980. Transitivity in grammar and discourse. Language 56(2).
251-299.Malchukov, Andrej & Peter de Swart. 2009. Differential case marking and actancy variations. In Andrej
Malchukov & Andrew Spencer (eds.), The Oxford handbook of case (Oxford Handbooks in Linguistics), 339-355. Oxford: Oxford University Press.
Page 21 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
Re-analyzing re-syllabification: methodological concerns in eye-trackingDaniel Scarpace, University of Texas at Arlington
The visual world paradigm for eye-tracking is a useful methodology for studying word activation in spoken word recognition among other subfields of psycholinguistics. The advantage to this methodology that stands out the most is the transparency of its analysis. Unlike other psycholinguistic behavioral measures, such as forced-choice accuracy data or reaction times in priming experiments, there is little to no interpretation of eye-tracking data as eye movements correspond directly to real-time activation of words in the mental lexicon. A fixation at a particular image means that this word has been activated in the speaker’s lexicon. Additionally, these eye movements are well predicted by continuous mapping models such as TRACE and Shortlist (Allopenna et al 1998, McClelland and Elman, 1986, Norris 1994). However, a complication occurs when analyzing eye-tracking data in the aggregate (across windows) for statistical analysis: the most traditional methodology averages eye-movements across tokens and trials (e.g. McMurray et al 2009, Tremblay 2011), leading to the question, do the patterns presented in an aggregated analysis reflect what occurs in individual trials, or indeed, in any individual trial?
In this paper I discuss a comparison between several different methodologies for analyzing eye-tracking data, including the traditional window analysis, the growth curve analysis, the onset contingent analysis, through estimating divergences, and my own (more descriptive) trial-by-trial analysis. Much of this analysis has been done through custom Python and R scripts, as well as the R package eyetrackingR (Dink & Ferguson 2015). The dataset for analysis is from an eyetracking study on phrases that have been affected by the process of resyllabification of consonants across word boundaries, where syllable and word boundaries are misaligned (e.g. las alas ‘the wings’ as [la.s#á.las] in Spanish). This particular process is especially relevant for this analysis due to the high likelihood of ‘switches’ between fixations onto lexical targets and competitors, which creates a problem for aggregated analyses, which are more accurate in experiments where time is important. The comparisons between the methodologies re-present the importance of reporting multiple types of analyses but also for ensuring that our statistical results actually represent how participants actually perform in the experiment.
References
Allopenna, P., J. Magnuson & M. Tanenhaus. 1998. Tracking the time course of spoken word recognition using eye movements: Evidence for continuous mapping models. Journal of Memory and Language 38. 419-439.
Dink, J. W. & B. Ferguson. 2015. EyetrackingR: An R Library for eye-tracking data analysis. Retrieved from http://www.eyetrackingr.com.
McClelland, J. L. & J. L. Elman. 1986. The TRACE model of speech perception. Cognitive psychology 18(1). 1-86.
McMurray, B, M. Tanenhaus & R. Aslin. 2009. Within-category VOT affects recovery from “lexical” garden paths: Evidence against phoneme-level inhibition. Journal of Memory and Language 60. 65-91.
Norris, D. 1994. Shortlist: A connectionist model of continuous speech recognition. Cognition 52(3). 189-234.
Tremblay, A. 2011. Proficiency assessment standards in second language acquisition research. Studies in Second Language Acquisition 33(3). 339-372.
Page 22 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
Collecting lexical data in a limited-access situationElaine Marie Scherrer, Graduate Institute of Applied Linguistics
The poster presentation will explain in detail a word collection workshop held for the Gemzek language group of Cameroon which took place in 2015. Because of restricted access to the home area, the workshop was held with diaspora Gemzek speakers living in the relatively secure town of Ngaounderé, none of whom had had access to the Gemzek literacy efforts taking place in the home area. I wished to use the Rapid Word Collection method as outlined at http://www.rapidwords.net/, but the circumstances created a variety of obstacles to implementing this in the usual way. Because of the lack of training in Gemzek literacy, in computer skills, and because of lack of funding, we had to find a way to adapt the RWC method to our particular situation.
The presentation will give a brief explanation of the need for this adaptation and a brief summary of the RWC method. Outlines will detail the various logistics of the workshop, the background of the participants, the methods used to collect data, and a section on how we used the French translation of the semantic domains list created by Ron Moe (available at http://rapidwords.net/fr/resources/files/questionnaire-collecte-rapide-de-mots ). There will also be a reporting of the results of the workshop and an evaluation of what could have been done better.
The poster will also include a few color pictures of the event. A handout will be available that also includes information on RWC resources and a sample from the semantic domains questionnaire.
Page 23 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
Subject ellipsis and the left periphery in EnglishCarly J. Sommerlot, University of Texas at Arlington
Despite being characterized as a non-pro-drop language, subjects in English can be elided in a variety of contexts:
(1) Remember Tyke? (He) Lived next door to Mom? (Du Bois et al 2000; SBCSAE 006) (2) (It) Looks like rain. (Quirk et al 1985: 896)
One syntactic approach to subject ellipsis contends that sentences like (1)-(2) are root clauses that are not embedded under any type of additional functional layer such as CP (Cardinaletti 1997, 2004; Haegeman 2013). Given this, Haegeman (2013) proposes that subject ellipsis is simply a consequence of Chomsky’s (2001) Phase Theory, which allows for the left edge of a root clause to be phonologically not spelled-out. Evidence that sentences with subject ellipsis are root clauses that contain no additional left-peripheral functional structures comes from the observation that subject ellipsis does not occur in embedded clauses and is incompatible with with topicalization:
(3) *This book, (I) don’t like. (Haegeman 2013: 104)
While Haegeman’s analysis offers an elegant account of the ungrammaticality of examples like (3), it makes the prediction that subject ellipsis should always be impossible if there is syntactic material to the left of the presumed position of the elided subject. This appears to be incorrect. A review of corpus data reveals a number of examples where subject ellipsis occurs with a left-peripheral wh-phrase:
(4) How (can we) explain its worship in New York and nationwide? (Davies 2015; COCA)
This talk discusses examples like (4) in detail. Additional evidence from subject-auxiliary inversion and quantifier scope are also discussed as further evidence that subject ellipsis is compatible with additional material to the left of the presumed position of the elided subject. The evidence reviewed in this talk thus suggests the need for a revision to Haegeman’s account of subject ellipsis.
References
Cardinaletti, A. 1997. Subjects and clause structure. The new comparative syntax, ed. by L. Haegeman, 33–63.
Cardinaletti, A. 2004. Towards a cartography of subject positions. The structure of CP and IP: The cartography of syntactic structures 2. 115-165.
Chomsky, N. 2001. Derivation by phase. In Michael Kenstowicz (ed.), Ken Hale: A life in language , 1-52.
Davies, M. 2015. The corpus of contemporary American English: 520 million words, 1990-present. http://corpus.byu.edu/coca/.
Du Bois, J.W., W. L. Chafe, C. Meyer, S. A. Thompson, R. Englebretson, and N. Martey. (2000). Santa Barbara corpus of spoken American English, Part 1. Philadelphia: Linguistic Data Consortium.
Haegeman, L. 2013. The syntax of registers: Diary subject omission and the privilege of the root. Lingua 130. 88-110.
Quirk, R., S. Greenbaum, G. Leech & J. Svartvik. 1985. A comprehensive grammar of the English language (Vol. 397). London: Longman.
Page 24 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
Expressing causation: Using corpus data to distill connections from vernacular proseLaurel Smith Stvan, UT Arlington
Motivation: This project examines how types of polysemy can reinforce the way speakers understand and discuss causality. When polysemous terms have related senses found in the same domain, contexts often give few clues for disambiguation. Thus lay terms in health discussions can show multiple senses not recognized as polysemes. While numerous studies have looked at creating and teaching technical medical terminology, there is little examination of vernacular terms used in discussing health concepts. Even though most speakers are not doctors, they take part daily in reading about and discussing food, sleep, exercise, and illness (cf. Rueda-Baclig & Florencio 2003). The prevalence of such conversations, and the ordinariness of the words involved, leads to aspects of lexical misinterpretation--such as conflation--not being captured and studied.
Case studies of individual polysemy pairs have shown lexical conflation for fat, sugar, salt, cold, health literacy, and stress (Stvan 2007, 2008, 2010). For fat, previous analyses showed that people conflate the adjective fat describing bodies and the food component fat. As a consequence, utterances reveal that people assume they cannot get a fat body if they eat fat-free food, while disregarding the possibility of becoming fat by eating other high-calorie ingredients. For sugar, people tracking blood sugar levels often focus only on the sugar that they eat, and not on carbohydrates with other names, which can equally affect blood sugar. Such conflated senses lead to very different preventive behaviors. I suggest that these word pairs having the same shape leads people to think the referents are identical, seeing one instance as leading to the other instance. This paper explores whether we can see this borne out by finding other, overt statements of causality in the texts used with these pairs.
Methodology: Five polysemy pairs hypothesized to implicate causation were compared (cold[ADJ]/cold[N]; cholesterol[N1]/cholesterol[N2]; fat[N]/ fat[ADJ]; stress[N1]/ stress[N2]; sugar[N1]/sugar[N2]). Queries were made from the Corpus of American Discourses on Health (CADOH), a collection of texts from 1990-2016, including ads, blogs and comment threads, listservs, online forums, trade magazines, newspapers, letters to the editors, novels, transcripts from TV and radio broadcasts, and focus group discussions. Causation predicates are an open-ended set; Mihéăilă et al. (2013), for example, found 347 unique triggers of causality in just 19 biomedical journal articles. So rather than querying with each possible predicate (e.g., brings about, causes, develops into, is a ticket to, leads to, triggers) the methodology was to identify instances of the pairs of polysemous terms in vicinity of each other. A dataset of utterances with these pairs was collected. A context width of up to 20 words between the pair, and 20 words before and after, was scanned for causality predicates, and the most frequent pairs and predicates were ranked. Examples (1)-(4) show representative polysemy pairs underlined and causal predicates capitalized.
Findings: Lexical conflation of polysemy pairs was found in fiction and naturally occurring recorded conversations. In addition to the pairs being used to express causality, they show up in metadiscussions that raised the causality as a myth in order to dispute it. For stress, three senses appeared, underscoring the misunderstandings that can arise when working to “reduce stress.” Knowing that such confusion occurs, healthcare providers may need to spend more time overtly separating these concepts in discussions on preventive health. Conflation has ramifications for public health policy, too. Identifying conflated senses reveals a linguistic aspect that can reinforce naturalized cultural beliefs about the causes of health and illness.
Examples
1) When you eat ice cream, the fat in the ice cream becomes fat in your body. So if you eat a lot of ice cream, you might BECOME fat. If you don’t, you’re gonna stay skinny.” (Movie script, 2006)
Page 25 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
2) “barefoot on winter nights: If you CATCH cold and die from cold feet, you'll be put into a box and buried deep, deep under” (Short fiction, 1990)
3) Sure, they're packed with cholesterol. But scientists now know that eating cholesterol doesn't necessarily RESULT IN high levels of harmful cholesterol in the blood, where the damage is done.(Weekly magazine, 2003)
4) Actually, you could GET a bigger rise in blood sugar after eating potatoes -- a baked potato, say -- than you do from eating pure table sugar.(TV news show, 2004)
References
Bradford Hill, Austin. 1965. The environment and disease: Association or causation? Proceedings of the Royal Society of Medicine 58(5). 295-300.
Lucas, Robyn M. & Anthony J. McMichael. 2005. Association or causation: Evaluating links between ‘environment and disease.’ Bulletin of the World Health Organization 83(10). 792-795.
Mihéăilă, Claudiu, Tomoko Ohta, Sampo Pyysalo, and Sophia Ananiadou. 2013. BioCause: Annotating and analysing causality in the biomedical domain. BMC Bioinformatics 14: 2.
Rueda-Baclig, Maria J. & Cecilia A. Florencio. 2003. Lay conceptions of hypertension and its significance to clients and professionals in nutrition and heath. Journal of Human Nutrition and Dietetics 16. 457-466.
Stvan, Laurel Smith. 2007. Lexical conflation and edible iconicity: Two sources of ambiguity in American vernacular health terminology. Communication & Medicine 4(2). 189-199.
Stvan, Laurel Smith. 2008. Health literacy: A single meaning or three senses conflated? The language of health care: Proceedings of the 1st International Conference on Language and Health Care, 1-13. IULMA: University of Alicante.
Stvan, Laurel Smith. 2013. Stress Management: Corpus-based insights into vernacular interpretations of stress. Communication & Medicine 10(1). 13-25.
Page 26 of 27

8th Annual DFW Metroplex Linguistics Conference 2016
A concept-based approach to teaching Chinese word orderXian Zhang, University of North Texas
Inspired by Jean Piaget, Pienemann (1989) argued that L2 learning must follow some specific developmental stages. These stages are sequential and cannot be overridden by quality of instruction (the Teachability Hypothesis, Pienemann, 1987). Based on an extended version of Lexical Functional Grammar, Pienemann, Biase, and Kawaguchi (2005) proposed the Topic Hypothesis, which claims that all learners must progress through three stages in acquiring Chinese syntax: SVO (Stage 2)Adj.+SVO (State 3)OSV(Stage 4). However, Vygotsky (1978) argued that psychological development is neither predetermined nor universal. Instead, it depends on the quality of social affordance (e.g. cognitive tools) made available to learners (Ratner, 2002). Following Gal’perin’s (1970) Systemic Theoretical Instruction, this paper presents the results of a study that supports Vygotsky’s contention that properly organized instruction can determine development. Two beginning Chinese learners at Stage 2 (SVO stage) received instruction that taught both Stage 3 OSV and Stage 2 Adj.+SVO simultaneously. Results of spontaneous speech production tasks in the post-test and delayed post-test indicate that these learners were capable of producing both OSV and Adj.+SVO after instruction.
References
Gal'perin, P. I. 1970. An experimental study in the formation of mental actions. In E. Stones (ed.), Reading in educational psychology: Learning and teaching, 142-154. New York, NY: Barnes & Noble.
Pienemann, M. 1987. Determining the influence of instruction on L2 speech processing. Australian Review of Applied Linguistics 10. 83–113.
Pienemann, M. 1989. Is language teachable? Psycholinguistic experiments and hypotheses. Applied Linguistics 1. 52-79.
Pienemann, M., B. Di Biase & S. Kawaguchi. 2005. Extending Processability Theory. In M. Pienemann (ed.), Cross-linguistic aspect of Processability Theory, 199-251. Amsterdam: John Benjamins.
Ratner, C. 2002. Cultural psychology: Theory and method. New York: Plenum.Vygotsky, L. S. 1978. Mind in society. Cambridge, MA: Harvard University Press.
Page 27 of 27


















