
9/12. In remembrance of all the lives and liberties lost to the wars by and on terror...
39
9/12
-
date post
20-Dec-2015 -
Category
Documents
-
view
218 -
download
1
Transcript of 9/12. In remembrance of all the lives and liberties lost to the wars by and on terror...

9/12

In remembrance of all the lives and liberties lost to the wars by and on terror
Guernica,Picasso
9/12
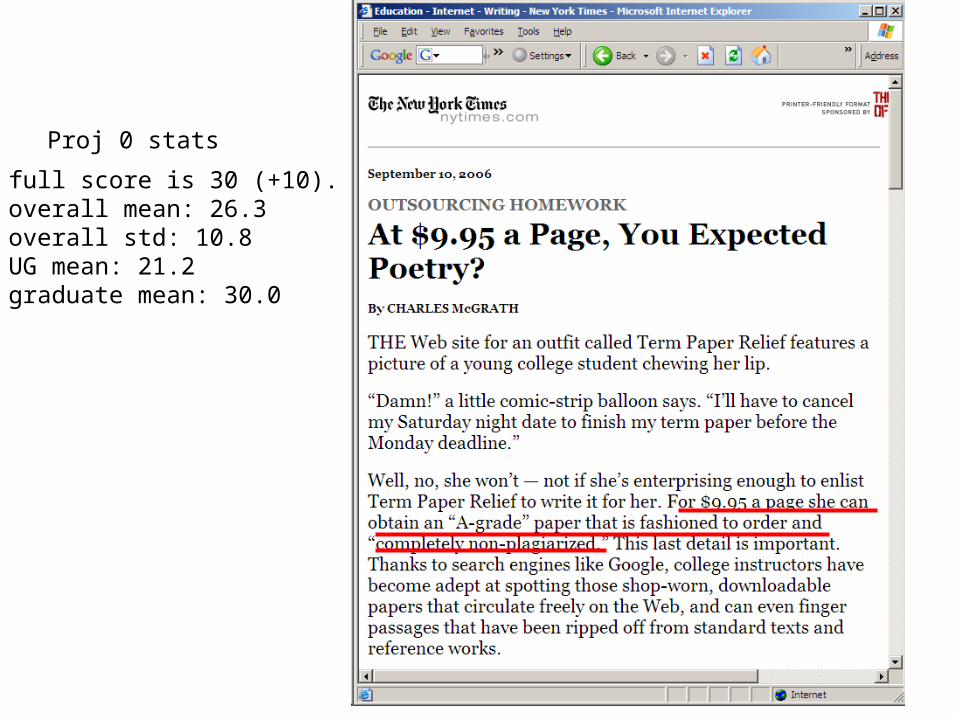
The full score is 30 (+10).The overall mean: 26.3The overall std: 10.8The UG mean: 21.2The graduate mean: 30.0
Proj 0 stats

Applying min-conflicts based hill-climbing to 8-puzzle
Local Minima
Understand the tradeoffs in defining smaller vs. larger neighborhood

Making Hill-Climbing Asymptotically Complete
• Random restart hill-climbing– Keep some bound B. When you made more than B moves, reset
the search with a new random initial seed. Start again. • Getting random new seed in an implicit search space is non-trivial!
– In 8-puzzle, if you generate a random state by making random moves from current state, you are still not truly random (as you will continue to be in one of the two components)
• “biased random walk”: Avoid being greedy when choosing the seed for next iteration – With probability p, choose the best child; but with probability (1-
p) choose one of the children randomly• Use simulated annealing
– Similar to the previous idea—the probability p itself is increased asymptotically to one (so you are more likely to tolerate a non-greedy move in the beginning than towards the end)
With random restart or the biased random walk strategies, we can solve very large problems million queen problems in under minutes!

N-queens vs. Boolean Satisfiability
• Given nxn board, bind assignment of positions to n queens so no queen constraints are violated
• Assign: Each queen can take values 1..8 corresponding to its position in its column
• Find a complete assignment for all queens
• The approach we discussed is called “min-conflict” search which does hill climbing in terms of number of conflicts
• Given n boolean variables and m clauses that constrain the values that those variables can take
– Each clause is of the form• [v1, ~v2, v7]• Meaning that one of those must hold
(either v1 is true or v7 is true or v2 is false)
• Find an assignment of T/F values to the n variables that ensures that all clauses are satisified
• So boolean variable is like a queen, T/F values are like queens positions; clauses are like queen constraints; number of violated clauses are like number of queen conflicts.
• You can do min-conflict search!– Extremely useful in large-scale circuit
verification etc.

“Beam search” for Hill-climbing• Hill climbing, as described, uses one seed solution that is
continually updated– Why not use multiple seeds?
• Stochastic hill-climbing uses multiple seeds (k seeds k>1). In each iteration, the neighborhoods of all k seeds are evaluated. From the neighborhood, k new seeds are selected probabilistically – The probability that a seed is selected is proportional to how good it is. – Not the same as running k hill-climbing searches in parallel
• Stochastic hill-climbing is sort of “almost” close to the way evolution seems to work with one difference– Define the neighborhood in terms of the combination of pairs of current
seeds (Sexual reproduction; Crossover)• The probability that a seed from current generation gets to “mate” to produce
offspring in the next generation is proportional to the seed’s goodness• To introduce “randomness” do mutation over the offspring
– Genetic algorithms limit number of matings to keep the num seeds the same
– This type of stochastic beam-search hillclimbing algorithms are called Genetic algorithms.

Illustration of Genetic Algorithms in Action
Very careful modeling needed so the things emerging from crossover and mutation are still potential seeds (and not monkeys typing Hamlet)Is the “genetic” metaphor reallybuying anything?

Hill-climbing in “continuous” search spaces
• Gradient descent (that you study in calculus of variations) is a special case of hill-climbing search applied to continuous search spaces
– The local neighborhood is defined in terms of the “gradient” or derivative of the error function.
• Since the error function gradient will be zero near the minimum, and higher farther from it, you tend to take smaller steps near the minimum and larger steps farther away from it. [just as you would want]
• Gradient descent is guranteed to converge to the global minimum if alpha (see on the right) is small, and the error function is “uni-modal” (I.e., has only one minimum).
– Versions of gradient-descent algorithms will be used in neuralnetwork learning.
• Unfortunately, the error function is NOT unimodal for multi-layer neural networks. So, you will have to change the gradient descent with ideas such as “simulated annealing” to increase the chance of reaching global minimum.
X
Err=|x3-a|
a1/3 xo
x1= x0 - [ d/dx[Err(x)] * alpha
-- the negative sign in front of d/dx shows That you are supposed to step in the directionOpposite to that of the gradient-- alpha is a constant that adjusts the step size
--larger the alpha, the faster the convergencebut also the higher the chance of oscillation
--The smaller the alpha, slower the convergence,but lower the chance of oscillation (around the minumum)
Example: cube rootFinding using newton-Raphson approximation
Tons of variations based on how alpha is set

The middle ground between hill-climbing and systematic search
• Hill-climbing has a lot of freedom in deciding which node to expand next. But it is incomplete even for finite search spaces.– Good for problems which have solutions, but the solutions are
non-uniformly clustered. • Systematic search is complete (because its search tree keeps
track of the parts of the space that have been visited). – Good for problems where solutions may not exist,
• Or the whole point is to show that there are no solutions (e.g. propositional entailment problem to be discussed later).
– or the state-space is densely connected (making repeated exploration of states a big issue). Smart idea: Try the middle ground between the two?

Between Hill-climbing and systematic search
• You can reduce the freedom of hill-climbing search to make it more complete– Tabu search
• You can increase the freedom of systematic search to make it more flexible in following local gradients– Random restart search

Tabu Search
• A variant of hill-climbing search that attempts to reduce the chance of revisiting the same states– Idea:
• Keep a “Tabu” list of states that have been visited in the past.
• Whenever a node in the local neighborhood is found in the tabu list, remove it from consideration (even if it happens to have the best “heuristic” value among all neighbors)
– Properties: • As the size of the tabu list grows, hill-climbing will asymptotically
become “non-redundant” (won’t look at the same state twice)
• In practice, a reasonable sized tabu list (say 100 or so) improves the performance of hill climbing in many problems

Random restart search
Variant of depth-first search where
• When a node is expanded, its children are first randomly permuted before being introduced into the open list– The permutation may
well be a “biased” random permutation
• Search is “restarted” from scratch anytime a “cutoff” parameter is exceeded– There is a “Cutoff”
(which may be in terms of # of backtracks, #of nodes expanded or amount of time elapsed)
•Because of the “random” permutation, every time the search is restarted, you are likely to follow different paths through the search tree. This allows you to recover from the bad initial moves.
•The higher the cutoff value the lower the amount of restarts (and thus the lower the “freedom” to explore different paths).
•When cutoff is infinity, random restart search is just normal depth-first search—it will be systematic and complete•For smaller values of cutoffs, the search has higher freedom, but no guarantee of completeness
•A strategy to guarantee asymptotic completeness:
•Start with a low cutoff value, but keep increasing it as time goes on.
•Random restart search has been shown to be very good for problems that have a reasonable percentage of “easy to find” solutions (such problems are said to exhibit “heavy-tail” phenomenon). Many real-world problems have this property.

Leaving goal-based search…
• Looked at– Systematic Search
• Blind search (BFS, DFS, Uniform cost search, IDDFS)• Informed search (A*, IDA*; how heuristics are made)
– Local search• Greedy (Hill climbing)• Asymptotically complete (Hill climbing with random restart;
biased random walk or simulated annealing)• Multi-seed hill-climbing
– Genetic algorithms…

Deterministic Planning
• Given an initial state I, a goal state G and a set of actions A:{a1…an}
• Find a sequence of actions that when applied from the initial state will lead the agent to the goal state.
• Qn: Why is this not just a search problem (with actions being operators?)– Answer: We have “factored” representations of states
and actions. • And we can use this internal structure to our advantage in
– Formulating the search (forward/backward/insideout)– deriving more powerful heuristics etc.

State Variable Models
• World is made up of states which are defined in terms of state variables– Can be boolean (or multi-ary or continuous)
• States are complete assignments over state variables– So, k boolean state variables can represent how
many states?
• Actions change the values of the state variables– Applicability conditions of actions are also specified in
terms of partial assignments over state variables

Why is this more compact?(than explicit transition
systems)• In explicit transition systems actions are represented as state-
to-state transitions where in each action will be represented by an incidence matrix of size |S|x|S|
• In state-variable model, actions are represented only in terms of state variables whose values they care about, and whose value they affect.
• Consider a state space of 1024 states. It can be represented by log21024=10 state variables. If an action needs variable v1 to be true and makes v7 to be false, it can be represented by just 2 bits (instead of a 1024x1024 matrix)– Of course, if the action has a complicated mapping from states to
states, in the worst case the action rep will be just as large– The assumption being made here is that the actions will have effects on
a small number of state variables.
These were discussed orally but were not shown in the class

Blocks world
State variables: Ontable(x) On(x,y) Clear(x) hand-empty holding(x)
Stack(x,y) Prec: holding(x), clear(y) eff: on(x,y), ~cl(y), ~holding(x), hand-empty
Unstack(x,y) Prec: on(x,y),hand-empty,cl(x) eff: holding(x),~clear(x),clear(y),~hand-empty
Pickup(x) Prec: hand-empty,clear(x),ontable(x) eff: holding(x),~ontable(x),~hand-empty,~Clear(x)
Putdown(x) Prec: holding(x) eff: Ontable(x), hand-empty,clear(x),~holding(x)
Initial state: Complete specification of T/F values to state variables
--By convention, variables with F values are omitted
Goal state: A partial specification of the desired state variable/value combinations --desired values can be both positive and negative
Init: Ontable(A),Ontable(B), Clear(A), Clear(B), hand-empty
Goal: ~clear(B), hand-empty
All the actions here have only positive preconditions; but this is not necessary

On the asymmetry of init/goal states• Goal state is partial
– It is a (seemingly) good thing • if only m of the k state variables are mentioned in a goal specification, then upto 2k-m
complete state of the world can satisfy our goals!
• ..I say “seeming” because sometimes a more complete goal state may provide hints to the agent as to what the plan should be
– In the blocks world example, if we also state that On(A,B) as part of the goal (in addition to ~Clear(B)&hand-empty) then it would be quite easy to see what the plan should be..
• Initial State is complete– If initial state is partial, then we have “partial observability” (i.e., the agent doesn’t
know where it is!)• If only m of the k state variables are known, then the agent is in one of 2k-m states!• In such cases, the agent needs a plan that will take it from any of these states to a goal
state– Either this could be a single sequence of actions that works in all states (e.g. bomb in the toilet
problem)– Or this could be “conditional plan” that does some limited sensing and based on that decides
what action to do • ..More on all this during the third class
• Because of the asymmetry between init and goal states, progression is in the space of complete states, while regression is in the space of “partial” states (sets of states). Specifically, for k state variables, there are 2k complete states and 3k “partial” states
– (a state variable may be present positively, present negatively or not present at all in the goal specification!)

Progression:
An action A can be applied to state S iff the preconditions are satisfied in the current stateThe resulting state S’ is computed as follows: --every variable that occurs in the actions effects gets the value that the action said it should have --every other variable gets the value it had in the state S where the action is applied
Ontable(A)
Ontable(B),
Clear(A)
Clear(B)
hand-empty
holding(A)
~Clear(A)
~Ontable(A)
Ontable(B),
Clear(B)
~handempty
Pickup(A)
Pickup(B)
holding(B)
~Clear(B)
~Ontable(B)
Ontable(A),
Clear(A)
~handempty

Generic (progression) planner
• Goal test(S,G)—check if every state variable in S, that is mentioned in G, has the value that G gives it.
• Child generator(S,A)– For each action a in A do
• If every variable mentioned in Prec(a) has the same value in it and S
– Then return Progress(S,a) as one of the children of S» Progress(S,A) is a state S’ where each state variable v has
value v[Eff(a)]if it is mentioned in Eff(a) and has the value v[S] otherwise
• Search starts from the initial state

9/14

Planning vs. Search: What is the difference? (revisited)
• Search assumes that there is a child-generator and goal-test functions which know how to make sense of the states and generate new states
• Planning makes the additional assumption that the states can be represented in terms of state variables and their values
– Initial and goal states are specified in terms of assignments over state variables• Which means goal-test doesn’t have to be a blackbox procedure
– That the actions modify these state variable values • The preconditions and effects of the actions are in terms of partial assignments over state variables
– Given these assumptions certain generic goal-test and child-generator functions can be written
• Specifically, we discussed one Child-generator called “Progression”, another called “Regression” and a third called “Partial-order”
• Notice that the additional assumptions made by planning do not change the search algorithms (A*, IDDFS etc)—they only change the child-generator and goal-test functions
– In particular, search still happens in terms of search nodes that have parent pointers etc. • The “state” part of the search node will correspond to
– “Complete state variable assignments” in the case of progression– “Partial state variable assignments” in the case of regression– “A collection of steps, orderings, causal commitments and open-conditions in the case of partial order planning

CSE 574: Planning & Learning Subbarao Kambhampati
Checking correctness of a plan:The State-based approaches
Progression Proof: Progress the initial state over the action sequence, and see if the goals are present in the result
At(A,E)At(R,E)At(B,E)
Load(A)
progress
Load(B)At(B,E)At(R,E)
In(A)
In(A)At(R,E)
In(B)
progress
Regression Proof: Regress the goal state over the action sequence, and see if the initial state subsumes the result
regressAt(A,E)At(R,E)At(B,E)
Load(A) Load(B)At(B,E)At(R,E)
In(A)
In(A)In(B)
regress
CSE 574: Planning & Learning Subbarao Kambhampati
Checking correctness of a plan:The Causal Approach
Causal Proof: Check if each of the goals and preconditions of the action are
» “established” : There is a preceding step that gives it
» “unclobbered”: No possibly intervening step deletes it Or for every preceding step that deletes it, there exists another step
that precedes the conditions and follows the deleter adds it back.
Causal proof is– “local” (checks correctness one condition at a time)
– “state-less” (does not need to know the states preceding actions)
» Easy to extend to durative actions
– “incremental” with respect to action insertion
» Great for replanning
Contd..
Load(B)Load(A)
In(A)
In(B)At(B,E)
At(R,E)
At(A,E)
At(R,E)
At(A,E)
At(B,E)
At(R,E)
In(A)
~At(A,E)
In(B)~At(B,E)
The three different child-generator functions (progression, regressio and partial order planning) correspond to three different ways of proving the correctness of a plan
Notice the way the proof of causal correctness is akin to the proof of n-queens correctness.. If there are no conflicts, it is a solution

Regression:
A state S can be regressed over an action A (or A is applied in the backward direction to S)Iff: --There is no variable v such that v is given different values by the effects of A and the state S --There is at least one variable v’ such that v’ is given the same value by the effects of A as well as state SThe resulting state S’ is computed as follows: -- every variable that occurs in S, and does not occur in the effects of A will be copied over to S’ with its value as in S -- every variable that occurs in the precondition list of A will be copied over to S’ with the value it has in in the precondition list
~clear(B) hand-empty
Putdown(A)
Stack(A,B)
~clear(B) holding(A)
holding(A) clear(B) Putdown(B)??
Termination test: Stop when the state s’ is entailed by the initial state sI
*Same entailment dir as before..

Regression vs. Reversibility
• Notice that regression doesn’t require that the actions are reversible in the realworld – We only think of actions in the reverse direction during
simulation– …just as we think of them in terms of their individual effects
during partial order planning• Normal blocks world is reversible (if you don’t like the
effects of stack(A,B), you can do unstack(A,B)). However, if the blocks world has a “bomb” the table action, then normally, there won’t be a way to reverse the effects of that action. – But even with that action we can do regression– For example we can reason that the best way to make table go-
away is to add “Bomb” action into the plan as the last action• ..although it might also make you go away

Progression vs. RegressionThe never ending war.. Part 1
• Progression has higher branching factor
• Progression searches in the space of complete (and consistent) states
• Regression has lower branching factor
• Regression searches in the space of partial states– There are 3n partial states (as
against 2n complete states)
~clear(B)hand-empty
Putdown(A)
Stack(A,B)
~clear(B)holding(A)
holding(A)clear(B) Putdown(B)??
Ontable(A)
Ontable(B),
Clear(A)
Clear(B)
hand-empty
holding(A)
~Clear(A)
~Ontable(A)
Ontable(B),
Clear(B)
~handempty
Pickup(A)
Pickup(B)
holding(B)
~Clear(B)
~Ontable(B)
Ontable(A),
Clear(A)
~handempty
You can also do bidirectional search stop when a (leaf) state in the progression tree entails a (leaf) state (formula) in the regression tree

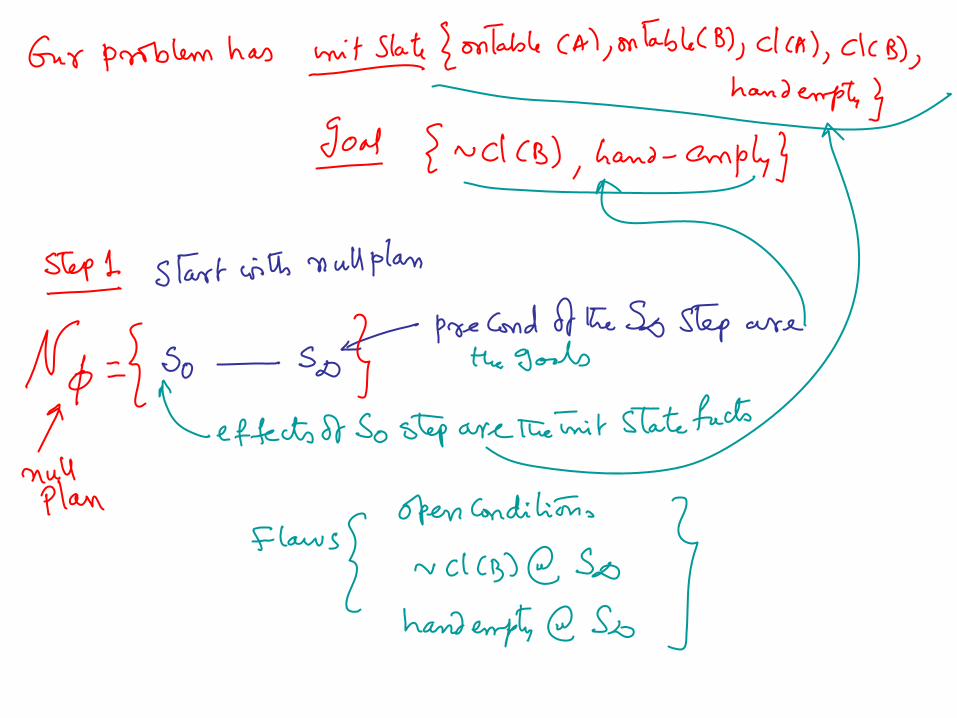
Plan Space Planning: Terminology
• Step: a step in the partial plan—which is bound to a specific action• Orderings: s1<s2 s1 must precede s2• Open Conditions: preconditions of the steps (including goal step)• Causal Link (s1—p—s2): a commitment that the condition p, needed at s2
will be made true by s1– Requires s1 to “cause” p
• Either have an effect p• Or have a conditional effect p which is FORCED to happen
– By adding a secondary precondition to S1• Unsafe Link: (s1—p—s2; s3) if s3 can come between s1 and s2 and undo p
(has an effect that deletes p). • Empty Plan: { S:{I,G}; O:{I<G}, OC:{g1@G;g2@G..}, CL:{}; US:{}}

Algorithm
1. Let P be an initial plan2. Flaw Selection: Choose a flaw f (either
open condition or unsafe link)3. Flaw resolution:• If f is an open condition, choose an action S that achieves f• If f is an unsafe link, choose promotion or demotion• Update P• Return NULL if no resolution exist4. If there is no flaw left, return P else go to 2.
S0
S1
S2
S3
Sinf
p
~p
g1
g2g2oc1
oc2
q1
Choice points• Flaw selection (open condition? unsafe link?)• Flaw resolution (how to select (rank) partial plan?)
• Action selection (backtrack point)• Unsafe link selection (backtrack point)
S0
Sinf
g1
g2
1. Initial plan:
2. Plan refinement (flaw selection and resolution):
POP background




S_infty < S2

For two days in May, 1999, an AI Program called Remote Agentautonomously ran Deep Space 1 (some 60,000,000 miles from earth)
Real-time ExecutionAdaptive Control
Hardware
Scripted
Executive
GenerativePlanner &Scheduler
Generative Mode Identification
& Recovery
Scripts
Mission-levelactions &resources
component models
ESL
Monitors
GoalsGoals
1999: Remote Agent takes Deep Space 1 on a galactic ride
If it helps take away some of the pain, you may note that the remote agent used a form of partial order planner!

Relevance, Rechabililty & Heuristics
• Progression takes “applicability” of actions into account
– Specifically, it guarantees that every state in its search queue is reachable
• ..but has no idea whether the states are relevant (constitute progress towards top-level goals)
• SO, heuristics for progression need to help it estimate the “relevance” of the states in the search queue
• Regression takes “relevance” of actions into account
– Specifically, it makes sure that every state in its search queue is relevant
• .. But has not idea whether the states (more accurately, state sets) in its search queue are reachable
• SO, heuristics for regression need to help it estimate the “reachability” of the states in the search queue
Reachability: Given a problem [I,G], a (partial) state S is called reachable if there is a sequence [a1,a2,…,ak] of actions which when executed from state I will lead to a state where S holdsRelevance: Given a problem [I,G], a state S is called relevant if there is a sequence [a1,a2,…,ak] of actions which when executedfrom S will lead to a state satisfying (Relevance is Reachability from goal state)
Since relevance is nothing but reachability from goal state, reachability analysis can form the basis for good heuristics

Subgoal interactionsSuppose we have a set of subgoals G1,….Gn
Suppose the length of the shortest plan for achieving the subgoals in isolation is l1,….ln We want to know what is the length of the shortest plan for achieving the n subgoals together, l1…n
If subgoals are independent: l1..n = l1+l2+…+ln If subgoals have +ve interactions alone: l1..n < l1+l2+…+ln If subgoals have -ve interactions alone: l1..n > l1+l2+…+ln
If you made “independence” assumption, and added up the individual costs of subgoals, then your resultant heuristic will be perfect if the goals are actually independent inadmissible (over-estimating) if the goals have +ve interactions un-informed (hugely under-estimating) if the goals have –ve interactions
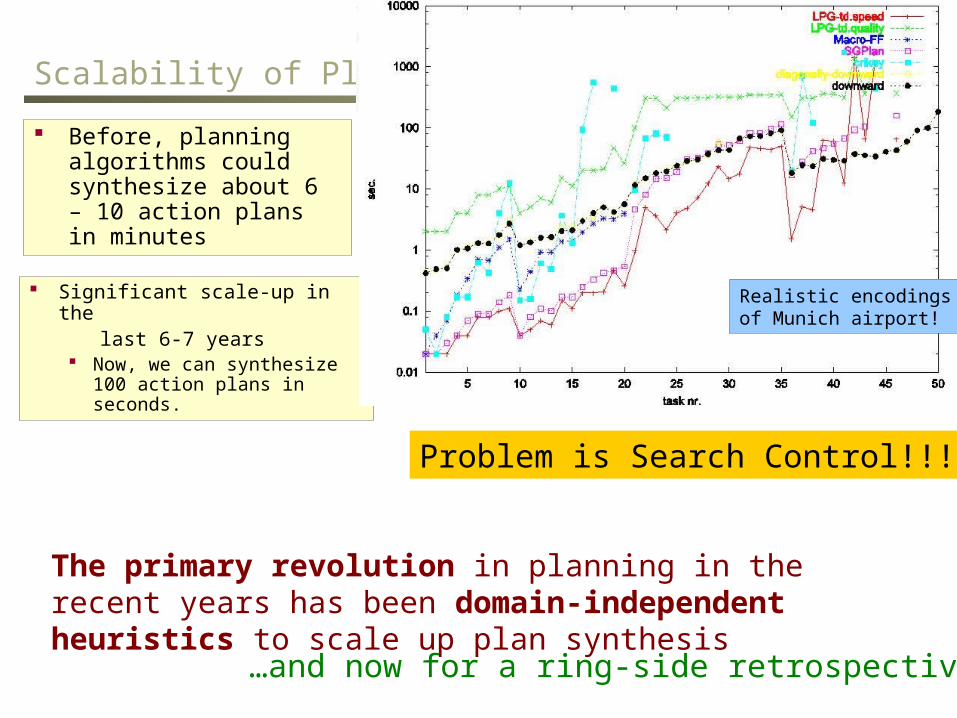
Scalability of Planning
Before, planning algorithms could synthesize about 6 – 10 action plans in minutes
Significant scale-up in the last 6-7 years
Now, we can synthesize 100 action plans in seconds.
Realistic encodings of Munich airport!
The primary revolution in planning in the recent years has been domain-independent heuristics to scale up plan synthesis
Problem is Search Control!!!
…and now for a ring-side retrospective

Planning Graph Basics– Envelope of Progression Tree
(Relaxed Progression)• Linear vs. Exponential Growth
– Reachable states correspond to subsets of proposition lists
– BUT not all subsets are states
• Can be used for estimating non-reachability
– If a state S is not a subset of kth level prop list, then it is definitely not reachable in k steps
p
pq
pr
ps
pqr
pq
pqs
p
psq
ps
pst
pqrs
pqrst
A1A2
A3
A2A1A3
A1A3
A4
A1A2
A3
A1
A2A3A4 [ECP, 1997]
![Pablo Picasso, 1881-1973 [Read-Only] - cusd80.com · Pablo Picasso, 1881-1973. The Lovers, 1923 Three Musicians, 1932. Guernica, painted for the Spanish Pavilion of the 1937 Worlds](https://static.fdocuments.in/doc/165x107/5ac883c07f8b9a6b578c3224/pablo-picasso-1881-1973-read-only-picasso-1881-1973-the-lovers-1923-three.jpg)

















