8017 25 image mining
23
Multimedia/Image Mining
-
Upload
universitas-bina-darma-palembang -
Category
Data & Analytics
-
view
74 -
download
0
Transcript of 8017 25 image mining

Multimedia/Image Mining

2
Outline of Presentation Challenges Facing Image Mining MultiMediaMiner:
Major Components Major Functional Modules
Phases Harvesting Preprocessing
• Median Filter Technique
Storing Creating a Data Cube Mining Discovering Image Retrieval
Conclusions Future Work

3
Challenges Facing Image Mining
Representing the image objects clearly and efficiently because image objects are hard to define. Thus, we have to break the image object into meaningful components such as color, texture, shape, etc…
Querying the image objects after representing them to retrieve the discovered knowledge. Below are some questions to ask...
1. how to compose an image query object? Can we use Keywords to compose a query?
2. How to compare the query image object to the objects in the database because unlike numeric or text data, exact
match can be rarely found between two image objects.
Visualization techniques to view the image components in a meaningful way such as DATA CUBES.

4
MultiMediaMiner
It is a system prototype responsible for mining multimedia information and knowledge from large multimedia databases.
It allows the users to control, combine and manipulate different types of Media.

5
MM - Major Components
Image excavator: responsible to extract images and videos from the multimedia sources.
Pre-processor: responsible to extract image features and to store pre-computed data in the database.
User interface: Used for querying.
Search engine: Responsible to match queries with the image and video features in the database

6
MM - Major Modules
MM-Characterizer : It provides users with a multi-level view of the data in the database with roll-up and drill-down capabilities. The figure describes the characteristics for two dimensions: the internet domain from which the media was extracted and the size of the media in bytes.

7
MM - Major Modules
MM-Associator : This module finds a set of association rules from the relevant sets of data in an image database.
Example: “What are relationships among still images, the frequent colors used in them, their size and the keyword sky. One possible association rule would be “if image is big and is related to sky, it is blue with possibility of 68%” or “if image is small and is related to sky, it is dark blue with a possibility of 55%. The figure shows a visualization of some association rules.

8
MM – Major Modules MM-Classifier : This module classifies multimedia data based on
some provided class labels. The result is an elegant classification of a large set of multimedia data and a characteristic description of each class. The figure below shows an output of the classifier module where a classification of images and frames based on their topic, with reference to the distribution of image format, is made for a given web site.
Chapter 9 Mining Complex Types of DataCS 785 Data Mining

9
MM - Phases Harvesting: Images are retrieved from the Web along with information
about the web pages in which they are found.
The World-Wide Web has been chosen to be the repository of images in the experiments done to build MM for the following reasons:
1. Free
2. Available
3. Has a large collection of images
4. Legal issues !!!
CT scans is an interesting application for the discovery of association rules
based on colors in these scans but getting access to CT scans from hospitals is not easy due to privacy issues.

10
MM - Phases Pre-Processing:
Images are processed to extract the following features: Color Texture Size Length Width Duration Format
Web Pages are processed to extract the following features: Internet Domain Image Popularity Page Richness Keywords

11
MM - Phases
Keywords extracted from the web pages are “cleaned” and organized into concept hierarchy.
Unnecessary words are elimimated.
Words are normalized.
WordNet is used to validate words and build the Concept Hierarchy.
WordNet , a semantic network, in version 1.6 has 95,600 different word forms organized into 71,000 word meanings interconnected with links representing subsumptions. It gives relationships between meaning of words.
WordNet can be enriched with some specific words that are not in its list such as : “Boeing 747” or “fighter F15”.
The built concept Hierarchy of words is used to browse images and select image data sets for mining.
12
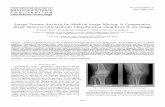
MM - Phases
Example:
By selecting a keyword “Boeing” from the hierarchy of the keywords, which is on the left of this figure, all the images associated with the word “Boeing” and its descendents are selected.

13
MM – Phases
Images also have to be preprocessed in order to remove or to reduce the noise which occur mainly during the image capture. The Median filter technique proves to perform well. Let’s Consider this example:
123 125 126 130 140
122 124 126 127 135
118 120150
125 134
119 115 119 123 133
111 116 110 120 130
Steps:1. The pixel value 150 does not represent its surroundings.2. We have to sort neighbors of 150 in a numerical order.
If we choose to use 3*3 square neighborhood, the neighborhood values in sorted order will be:
115, 119, 120, 123, 124, 125, 126, 127, and 150.3. Calculate the median and replace 150 by the median value.
14
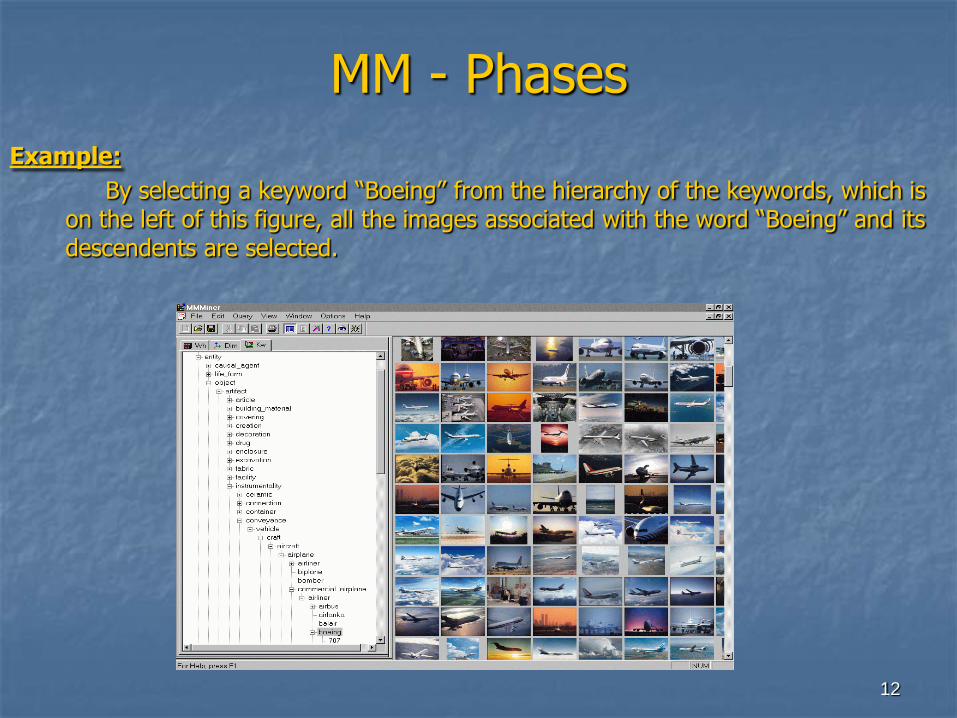
MM - Phases
The figures of the coins below shows the image of coins before and after applying the median filter to it.
Before After

15
MM - Phases
Storing: Information or Meta-data extracted from the images and the web pages containing these images are stored in the database.
The image is not stored by itself in the database. Only its feature descriptors are stored in the database.
Since the World-Wide Web is the source of images and because it has dynamic structure ; i.e. some new images may appear and some images may disappear. Thus, the descriptors of those images who disappear arediscarded from the database.

16
MM - Phases Creating a Data Cube: A Multimedia data cube is created based on
different dimensions (features stored in database).
In reality it is impossible for the physical data cube to hold more than a given number of dimensions because the size of the cube grows exponentially with the number of dimensions. That is, each time a dimension is added, the size of the cube is multiplied by the number of distinct values in the new dimension.
For example, the number of dimensions of color by itself = 256 and there are other features having large number of dimensions. So, how the data cube addresses this problem of dimensionality? Compromise is the solution.

17
MM - Phases
The third column in the table below represents the compromise.

18
MM - Phases
The number of dimensions is still too large to be handled by a data cube. So, many data cubes needed in the implementation of MM-Miner:
1st cube holds the color and the texture dimensions.
2nd cube holds mainly the size, length, and width dimensions.
3rd cube holds the dimensions of the remaining features.
It is impossible to discover the correlation, if it exists, between different dimensions in different cubes such as the color and the size because data mining algorithms work at one cube at a time. What is the solution? Overlap. To have an overlap:
4th cube needed having dimensions from the above 3 cubes.
The internet domain and the size dimensions have to exist in all the 4 cubes.

19
MM - Processes
Mining: Data Mining algorithms and OLAP technology are used to discover implicit knowledge like classification of images based on their multimedia features, correlation between multimedia features, etc…
Discovering: Classification, Association, and Summarization of image data is discovered. Moreover, Slicing, Dicing, Drilling-down and Rolling-up allow identifying specific images by clusters.
Image Retrieval: After the data mining process filters out the interesting images, these images and the web pages containing them can be retrieved now.
20
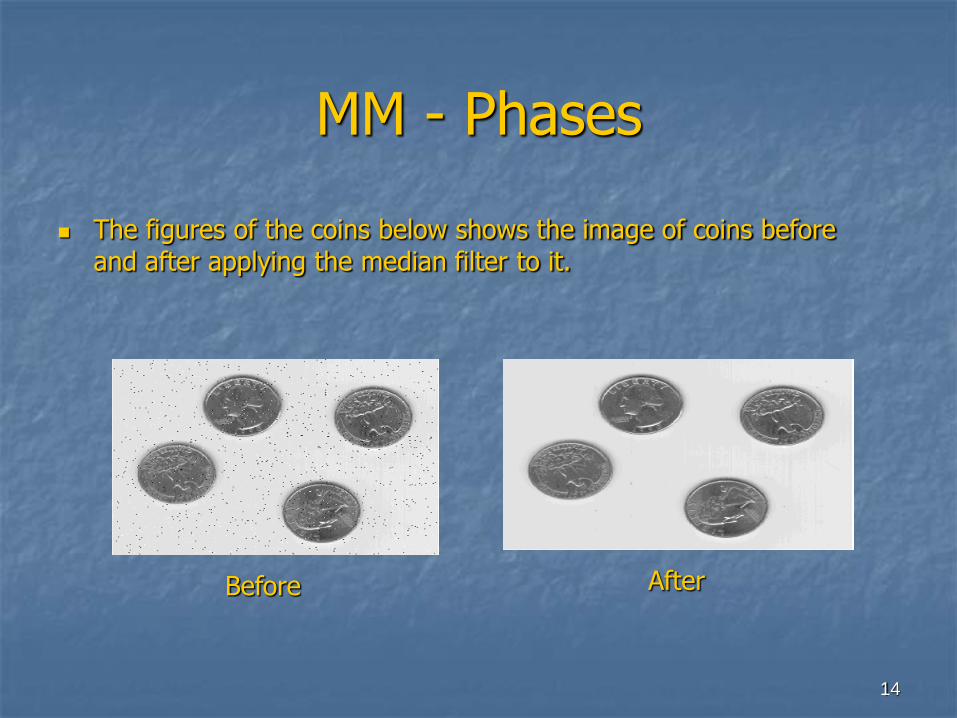
MM – Phases (Summary)
WWW
Media Descriptors
Data CubeDimensions
Mining Engine
Discoveries
Database

21
Conclusions
The user interface of the 3 major modules of MultiMediaMiner allows interactive mining.
Tradeoff exists to implement the data Cube.Keywords are not represented in the data cube.Choose only the most frequent values of some features
such as color, texture, etc… in order to reduce the number of dimensions.
Designing many data cubes instead of just one data cube.
Noise must be removed before storing the descriptors of the image in the database.

22
Future Work
A new model for data cube materialization is under study.
Adding a clustering module which would group images into different clusters based on their features.
Enhancing the system to work not only with images and videos but with audio data as well.

23
THE END