
4/3. (FO)MDPs: The plan General model has no initial state; complex cost and reward functions, and...
60
4/3
-
date post
19-Dec-2015 -
Category
Documents
-
view
215 -
download
1
Transcript of 4/3. (FO)MDPs: The plan General model has no initial state; complex cost and reward functions, and...

4/3

(FO)MDPs: The plan• General model has no initial
state; complex cost and reward functions, and finite/infinite/indefinite horizons
• Standard algorithms are Value and Policy iteration – Have to look at the entire state
space• Can be made even more
general with– Partial observability
(POMDPs)– Continuous state spaces – Multiple agents
(DECPOMDPS/MDPS)– Durative actions
• Conurrent MDPs• Semi-MDPs
• Directions– Efficient algorithms for special
cases• TODAY & 4/10
– Combining “Learning” of the model and “planning” with the model
• Reinforcement Learning—4/8

Markov Decision Process (MDP)
S: A set of states A: A set of actions Pr(s’|s,a): transition model
• (aka Mas,s’)
C(s,a,s’): cost model G: set of goals s0: start state : discount factor R(s,a,s’): reward model
Value function: expected long term reward from the state
Q values: Expected long term reward of doing a in s V(s) = max Q(s,a)
Greedy Policy w.r.t. a value function
Value of a policy
Optimal value function

Examples of MDPs
Goal-directed, Indefinite Horizon, Cost Minimization MDP• <S, A, Pr, C, G, s0>• Most often studied in planning community
Infinite Horizon, Discounted Reward Maximization MDP• <S, A, Pr, R, >• Most often studied in reinforcement learning
Goal-directed, Finite Horizon, Prob. Maximization MDP• <S, A, Pr, G, s0, T>• Also studied in planning community
Oversubscription Planning: Non absorbing goals, Reward Max. MDP• <S, A, Pr, G, R, s0>• Relatively recent model

SSPP—Stochastic Shortest Path Problem An MDP with Init and Goal states
• MDPs don’t have a notion of an “initial” and “goal” state. (Process orientation instead of “task” orientation)
– Goals are sort of modeled by reward functions
• Allows pretty expressive goals (in theory)
– Normal MDP algorithms don’t use initial state information (since policy is supposed to cover the entire search space anyway).
• Could consider “envelope extension” methods
– Compute a “deterministic” plan (which gives the policy for some of the states; Extend the policy to other states that are likely to happen during execution
– RTDP methods
• SSSP are a special case of MDPs where
– (a) initial state is given– (b) there are absorbing goal states– (c) Actions have costs. All states
have zero rewards• A proper policy for SSSP is a policy
which is guaranteed to ultimately put the agent in one of the absorbing states
• For SSSP, it would be worth finding a partial policy that only covers the “relevant” states (states that are reachable from init and goal states on any optimal policy)
– Value/Policy Iteration don’t consider the notion of relevance
– Consider “heuristic state search” algorithms
• Heuristic can be seen as the “estimate” of the value of a state.

<S, A, Pr, C, G, s0> Define J*(s) {optimal cost} as the
minimum expected cost to reach a goal from this state.
J* should satisfy the following equation:
Bellman Equations for Cost Minimization MDP(absorbing goals)[also called Stochastic Shortest Path]
Q*(s,a)

<S, A, Pr, R, s0, > Define V*(s) {optimal value} as the
maximum expected discounted reward from this state.
V* should satisfy the following equation:
Bellman Equations for infinite horizon discounted reward maximization MDP

<S, A, Pr, G, s0, T> Define P*(s,t) {optimal prob.} as the
maximum probability of reaching a goal from this state at tth timestep.
P* should satisfy the following equation:
Bellman Equations for probability maximization MDP

Modeling Softgoal problems as deterministic MDPs
• Consider the net-benefit problem, where actions have costs, and goals have utilities, and we want a plan with the highest net benefit
• How do we model this as MDP?– (wrong idea): Make every state in which any subset of goals hold
into a sink state with reward equal to the cumulative sum of utilities of the goals.
• Problem—what if achieving g1 g2 will necessarily lead you through a state where g1 is already true?
– (correct version): Make a new fluent called “done” dummy action called Done-Deal. It is applicable in any state and asserts the fluent “done”. All “done” states are sink states. Their reward is equal to sum of rewards of the individual states.

Ideas for Efficient Algorithms..• Use heuristic search (and
reachability information)– LAO*, RTDP
• Use execution and/or Simulation– “Actual Execution”
Reinforcement learning (Main motivation for RL is
to “learn” the model)– “Simulation” –simulate the
given model to sample possible futures
• Policy rollout, hindsight optimization etc.
• Use “factored” representations– Factored representations
for Actions, Reward Functions, Values and Policies
– Directly manipulating factored representations during the Bellman update

Heuristic Search vs. Dynamic Programming (Value/Policy Iteration)• VI and PI approaches use
Dynamic Programming Update• Set the value of a state in
terms of the maximum expected value achievable by doing actions from that state.
• They do the update for every state in the state space– Wasteful if we know the initial
state(s) that the agent is starting from
• Heuristic search (e.g. A*/AO*) explores only the part of the state space that is actually reachable from the initial state
• Even within the reachable space, heuristic search can avoid visiting many of the states. – Depending on the quality of
the heuristic used.. • But what is the heuristic?
– An admissible heuristic is a lowerbound on the cost to reach goal from any given state
– It is a lowerbound on V*!
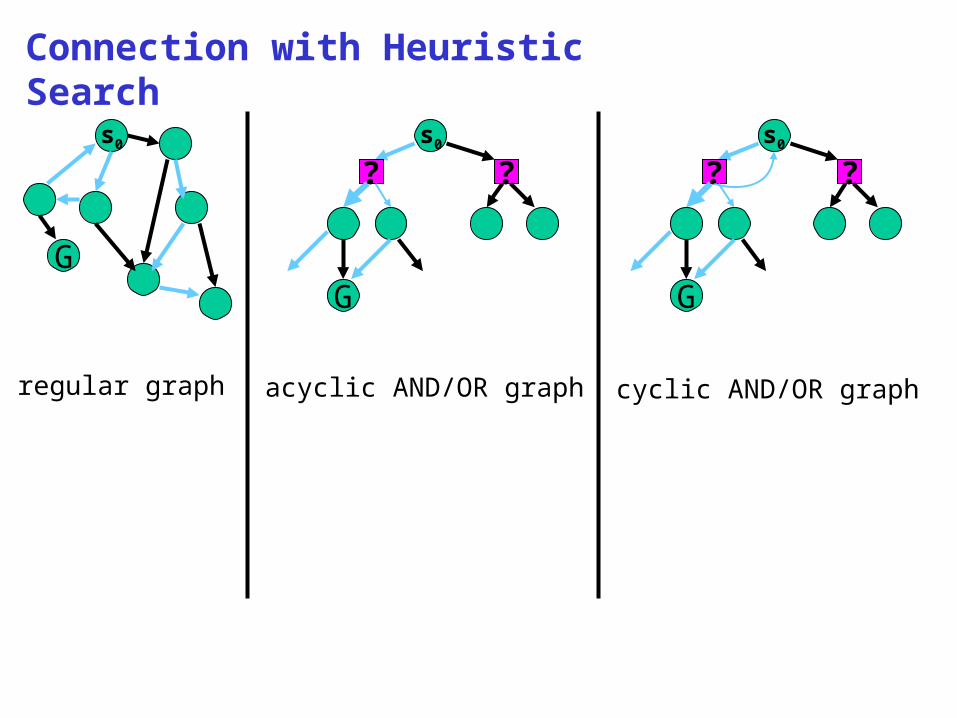
Connection with Heuristic Search
s0
G
s0
G
? ?s0
G
? ?
regular graph acyclic AND/OR graph cyclic AND/OR graph

Connection with Heuristic Search
s0
G
s0
G
? ?s0
G
? ?
regular graph
soln:(shortest) path
A*
acyclic AND/OR graph
soln:(expected shortest) acyclic graph
AO* [Nilsson’71]
cyclic AND/OR graph
soln:(expected shortest) cyclic graph
LAO* [Hansen&Zil.’98]All algorithms able to make effective use of reachability information!
Sanity check: Why can’t we handle the cycles by duplicate elimination as in A* search?

LAO* [Hansen&Zilberstein’98]
1. add s0 in the fringe and in greedy graph
2. repeat expand a state on the fringe (in greedy graph) initialize all new states by their heuristic value perform value iteration for all expanded states recompute the greedy graph
3. until greedy graph is free of fringe states
4. output the greedy graph as the final policy

LAO* [Iteration 1]
s0
G
? ?s0
add s0 in the fringe and in greedy graph

LAO* [Iteration 1]
s0
G
? ?s0
expand a state on fringe in greedy graph
? ?

LAO* [Iteration 1]
s0
G
? ?s0
initialise all new states by their heuristic values perform VI on expanded states
? ?
h h h h
J1
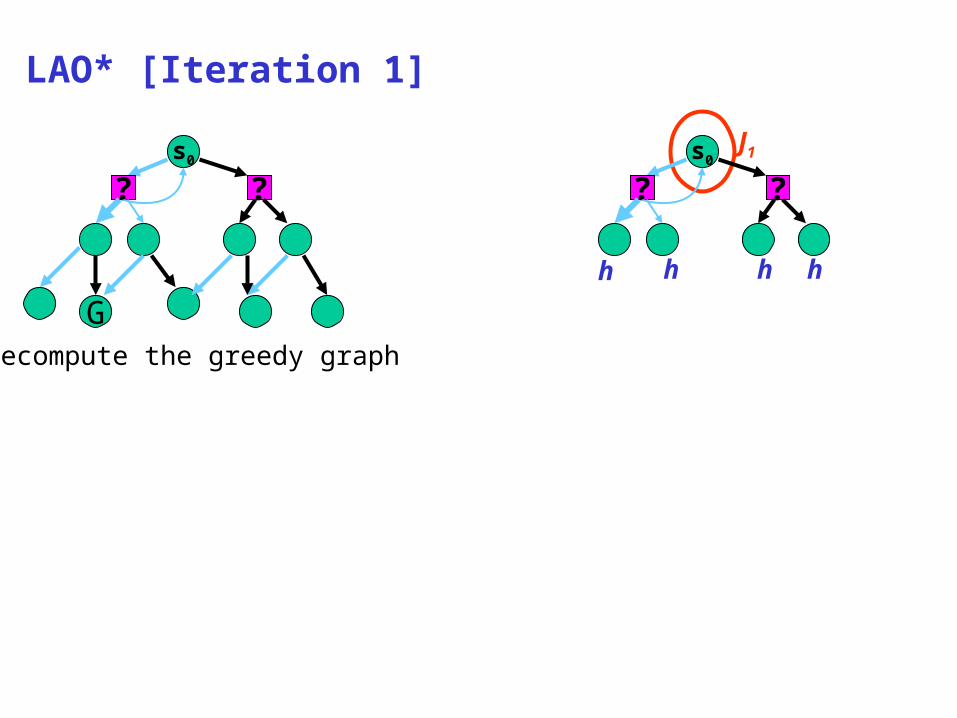
LAO* [Iteration 1]
s0
G
? ?s0
recompute the greedy graph
? ?
h h h h
J1

LAO* [Iteration 2]
s0
G
? ?s0
expand a state on the fringeinitialise new states
? ?
h h h h
J1
h h
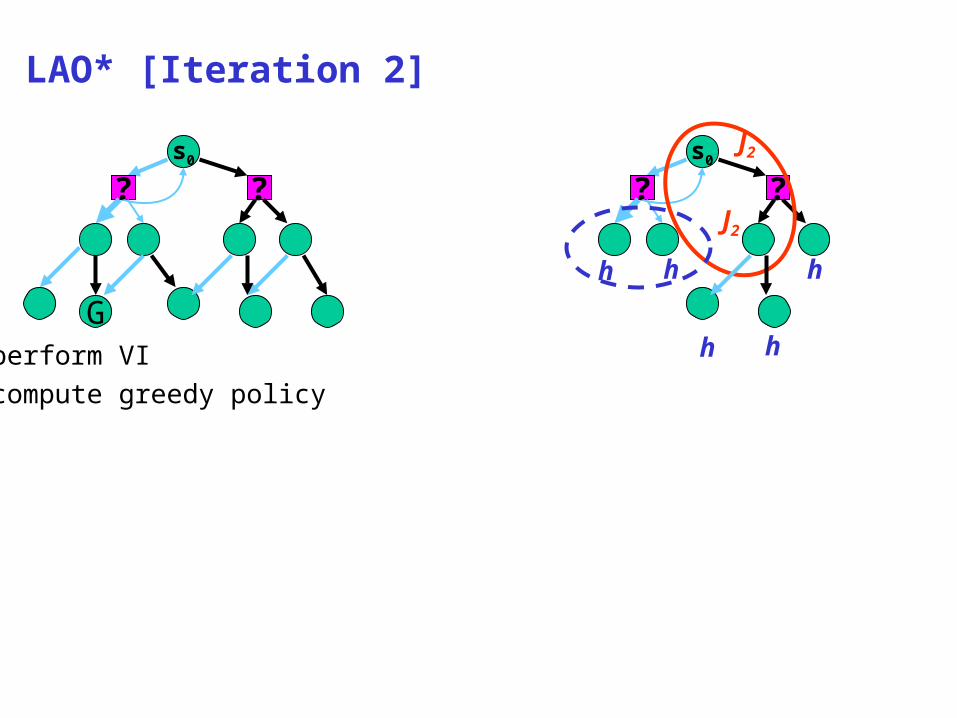
LAO* [Iteration 2]
s0
G
? ?s0
perform VIcompute greedy policy
? ?
h h h
J2
h h
J2

LAO* [Iteration 3]
s0
G
? ?s0
expand fringe state
? ?
h h
J2
h h
J2
G

LAO* [Iteration 3]
s0
G
? ?s0
perform VIrecompute greedy graph
? ?
h h
J3
h h
J3
G
J3

LAO* [Iteration 4]
s0
G
? ?s0
? ?
h
J4
h h
J4
G
J4
h
J4

LAO* [Iteration 4]
s0
G
? ?s0
? ?
h
J4
h h
J4
G
J4
h
J4
Stops when all nodes in greedy graph have been expanded

Comments
Dynamic Programming + Heuristic Search admissible heuristic ⇒ optimal policy expands only part of the reachable state space outputs a partial policy
• one that is closed w.r.t. to Pr and s0
Speedups• expand all states in fringe at once• perform policy iteration instead of value iteration• perform partial value/policy iteration • weighted heuristic: f = (1-w).g + w.h• ADD based symbolic techniques (symbolic LAO*)

How to derive heuristics?
• Deterministic shortest route is a heuristic on the expected cost J*(s)
• But how do you compute it? – Idea 1: [Most likely outcome determinization] Consider the most
likely transition for each action– Idea 2: [All outcome determinization] For each stochastic action,
make multiple deterministic actions that correspond to the various outcomes
– Which is admissible? Which is “more” informed?– How about Idea 3: [Sampling based determinization]
• Construct a sample determinization by “simulating” each stochastic action to pick the outcome. Find the cost of shortest path in that determinization
• Take multiple samples, and take the average of the shortest path.
Determinization involves converting “And” arcs in the And/Or graph to “Or” arcs

Real Time Dynamic Programming [Barto, Bradtke, Singh’95]
Trial: simulate greedy policy starting from start state;
perform Bellman backup on visited states
RTDP: repeat Trials until cost function converges
Notice that you can also do the “Trial” above by executing rather than “simulating”. In that case, we will be doing reinforcement learning. (In fact, RTDP was originally developed for reinforcement learning)

Min
?
?s0
Jn
Jn
Jn
Jn
Jn
Jn
Jn
Qn+1(s0,a)
Jn+1(s0)
agreedy = a2
Goala1
a2
a3
RTDP Trial
?
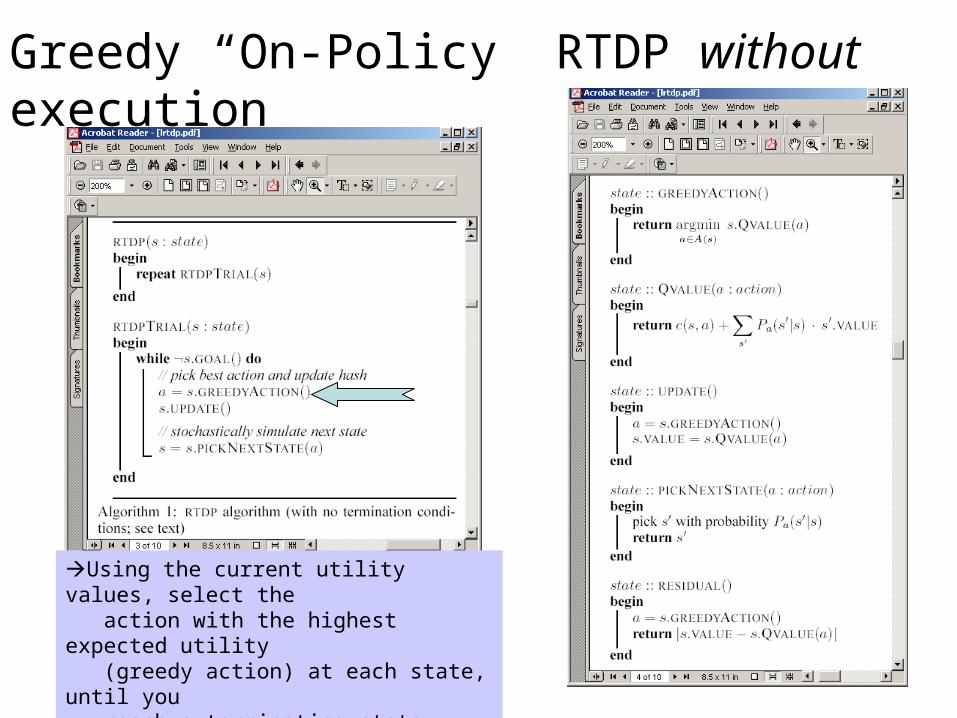
Greedy “On-Policy” RTDP without execution
Using the current utility values, select the action with the highest expected utility (greedy action) at each state, until you reach a terminating state. Update the values along this path. Loop back—until the values stabilize
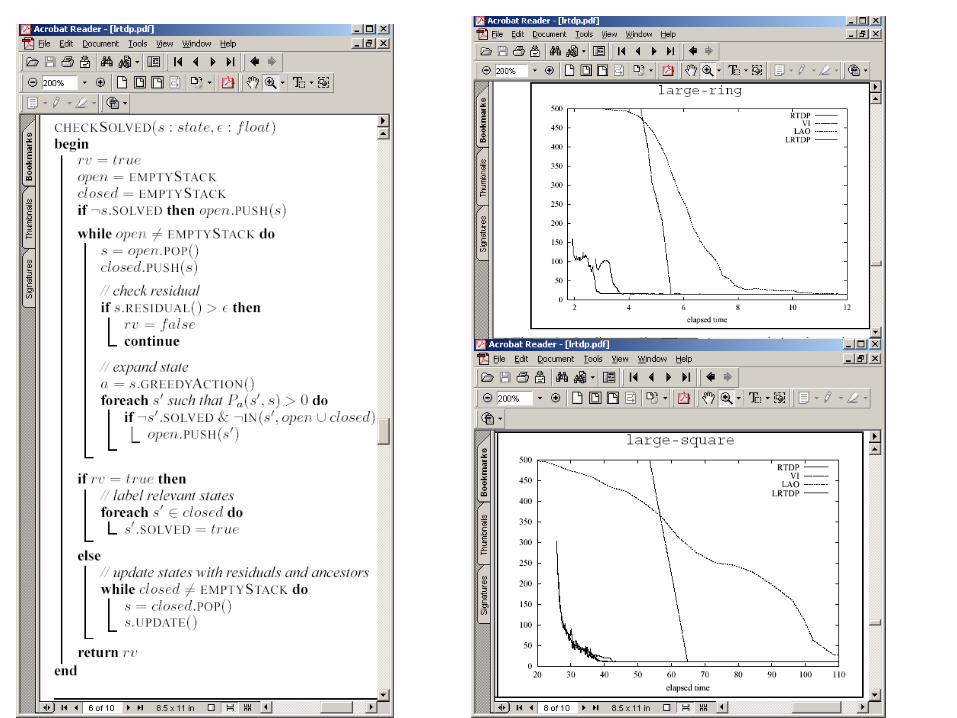

Labeled RTDP [Bonet&Geffner’03]
Initialise J0 with an admissible heuristic
• ⇒ Jn monotonically increases
Label a state as solved • if the Jn for that state has converged
Backpropagate ‘solved’ labeling Stop trials when they reach any solved state Terminate when s0 is solved
s G
high Q
costs
best action
) J(s) won’t change!
s G?
t
both s and tget solved together
high Q
costs

Properties
admissible J0 ⇒ optimal J*
heuristic-guided• explores a subset of reachable state space
anytime • focusses attention on more probable states
fast convergence • focusses attention on unconverged states
terminates in finite time

Other Advances
Ordering the Bellman backups to maximise information flow.• [Wingate & Seppi’05]• [Dai & Hansen’07]
Partition the state space and combine value iterations from different partitions.• [Wingate & Seppi’05]• [Dai & Goldsmith’07]
External memory version of value iteration• [Edelkamp, Jabbar & Bonet’07]
…

Ideas for Efficient Algorithms..• Use heuristic search (and
reachability information)– LAO*, RTDP
• Use execution and/or Simulation– “Actual Execution”
Reinforcement learning (Main motivation for RL is
to “learn” the model)– “Simulation” –simulate the
given model to sample possible futures
• Policy rollout, hindsight optimization etc.
• Use “factored” representations– Factored representations
for Actions, Reward Functions, Values and Policies
– Directly manipulating factored representations during the Bellman update

Factored Representations: Actions
• Actions can be represented directly in terms of their effects on the individual state variables (fluents). The CPTs of the BNs can be represented compactly too!– Write a Bayes Network relating the value of fluents at
the state before and after the action• Bayes networks representing fluents at different time points
are called “Dynamic Bayes Networks”• We look at 2TBN (2-time-slice dynamic bayes nets)
• Go further by using STRIPS assumption– Fluents not affected by the action are not represented
explicitly in the model– Called Probabilistic STRIPS Operator (PSO) model

Action CLK




Factored Representations: Reward, Value and Policy Functions
• Reward functions can be represented in factored form too. Possible representations include– Decision trees (made up of fluents)– ADDs (Algebraic decision diagrams)
• Value functions are like reward functions (so they too can be represented similarly)
• Bellman update can then be done directly using factored representations..


SPUDDs use of ADDs

Direct manipulation of ADDs in SPUDD




FF-Replan: A Baseline for Probabilistic Planning
Sungwook YoonAlan fern
Robert Givan
FF-Replan : Sungwook Yoon

Replanning Approach
• Deterministic Planner for Probabilistic Planning?
• Winner of IPPC-2004 and (unofficial) winner of IPPC-2006
• Why was it conceived?• Why it worked?
– Domain by domain analysis
• Any extension?
FF-Replan : Sungwook Yoon

IPPC-2004 Pre-released Domains
BlocksworldBoxworld
FF-Replan : Sungwook Yoon

IPPC Performance Test
-Client Server Interaction-The problem definition is known apriori-Performance is recorded in the server log-For one problem, 30 repetitive test is conducted
FF-Replan : Sungwook Yoon
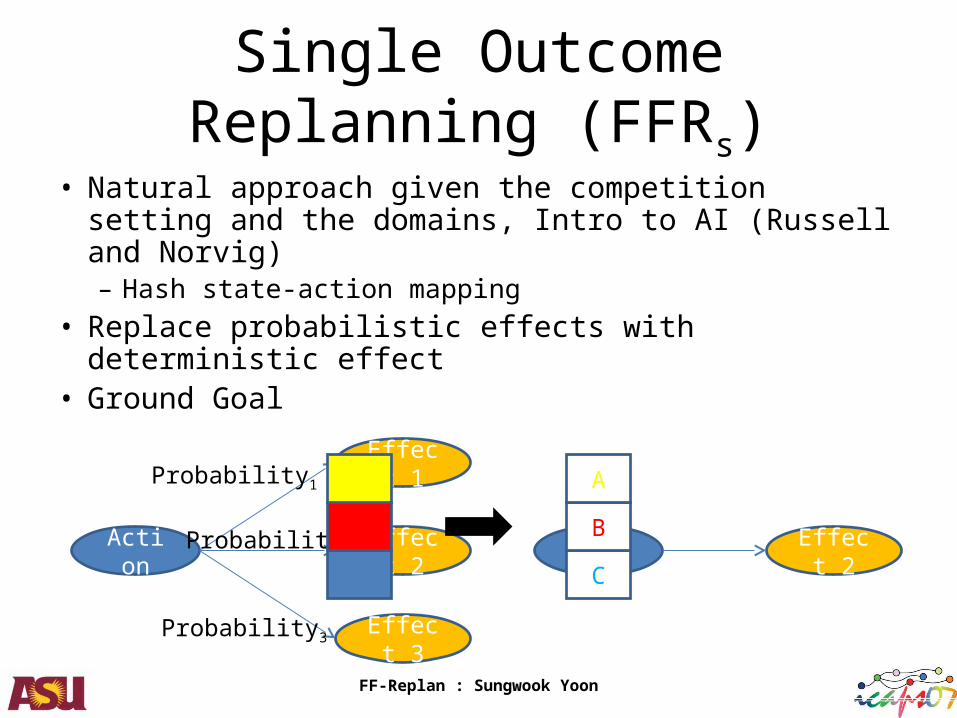
Single Outcome Replanning (FFRs)
• Natural approach given the competition setting and the domains, Intro to AI (Russell and Norvig)– Hash state-action mapping
• Replace probabilistic effects with deterministic effect• Ground Goal
Action
Effect 1
Effect 2
Effect 3
Probability1
Probability2
Probability3
Action Effect 2C
B
A
FF-Replan : Sungwook Yoon

IPPC-2004 Domains
BlocksworldBoxworldFileworldTireworldTower of HanoiZenoTravelExploding Blocksworld
FF-Replan : Sungwook Yoon

IPPC-2004 Results
NMRC J1 Classy NMR mGPT C FFRS FFRA
BW 252 270 255 30 120 30 210 270
Box 134 150 100 0 30 0 150 150
File - - - 3 30 3 14 29
Zeno - - - 30 30 30 0 30
Tire-r - - - 30 30 30 30 30
Tire-g - - - 9 16 30 7 7
TOH - - - 15 0 0 0 11Exploding - - - 0 0 0 3 5
Human Control Knowledge 2nd Place Winners
LearnedKnowledge
NMR Non-Markovian Reward Decision Process Planner
Classy Approximate Policy Iteration with a Policy Language Bias
mGPT Heuristic Search Probabilistic Planning
C Symbolic Heuristic Search
Numbers : Successful Runs

Reason of the Success
• Determinization and efficient pre-processing of complex planning language– Input language is quite complex (PPDDL)– Classic planning has developed efficient preprocessing
techniques on complex input language and scales well– Grounding goal also helped
• Classic planning takes hard time dealing with lifted goals
• The domains in the competition– 17 of 20 problems were dead-end free– Amenable to Replanning approach
FF-Replan : Sungwook Yoon
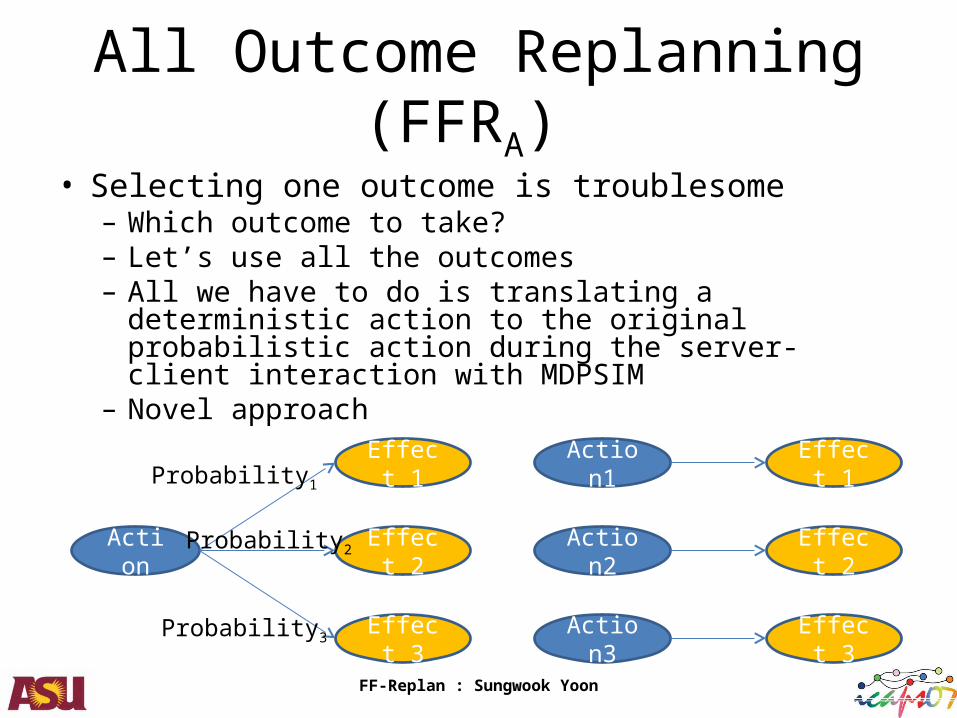
All Outcome Replanning (FFRA)
• Selecting one outcome is troublesome– Which outcome to take?– Let’s use all the outcomes– All we have to do is translating a deterministic action to
the original probabilistic action during the server-client interaction with MDPSIM
– Novel approach
Action
Effect 1
Effect 2
Effect 3
Probability1
Probability2
Probability3
Action1 Effect 1
Action2 Effect 2
Action3 Effect 3
FF-Replan : Sungwook Yoon

IPPC-2006 Domains• Blocksworld• Exploding
Blocksworld• ZenoTravel• Tireworld• Elevator• Drive• PitchCatch• Schedule• Random
• Randomly generate syntactically correct domain– E.g., Don’t delete facts that are not in
the precondition• Randomly generate a state
– This is initial state• Take random walk from the state, using
the random domain• The resulting state is a goal state
– There is at least a path from the initial state to the goal state
• If the probability of the path is bigger than α, then stop, otherwise take a random walk again
• Special reset action is provided that take any state to the initial state
FF-Replan : Sungwook Yoon
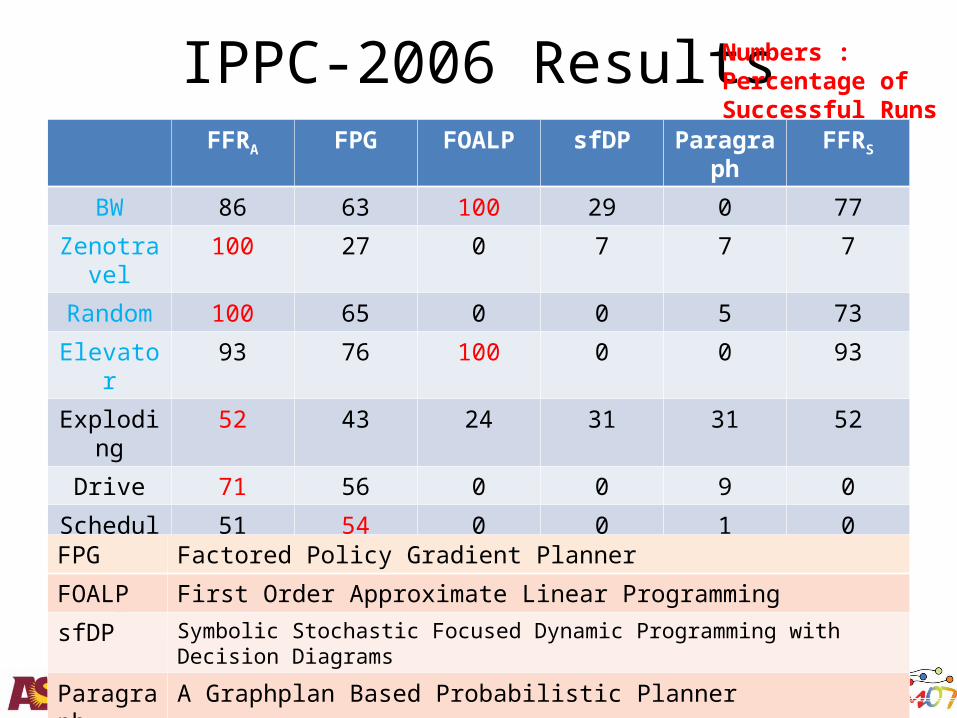
IPPC-2006 ResultsFFRA FPG FOALP sfDP Paragraph FFRS
BW 86 63 100 29 0 77
Zenotravel
100 27 0 7 7 7
Random 100 65 0 0 5 73
Elevator 93 76 100 0 0 93
Exploding 52 43 24 31 31 52
Drive 71 56 0 0 9 0
Schedule 51 54 0 0 1 0
PitchCatch 54 23 0 0 0 0
Tire 82 75 82 0 91 69FPG Factored Policy Gradient Planner
FOALP First Order Approximate Linear Programming
sfDP Symbolic Stochastic Focused Dynamic Programming with Decision Diagrams
Paragraph A Graphplan Based Probabilistic Planner
Numbers : Percentage ofSuccessful Runs

Discussion• Novel all-outcome replanning technique
outperforms naïve replanner
• The replanner performed well even on the “real” probabilistic domains– Drive– The complexity of the domain might have contributed
to this phenomenon• Replanner did not win the domains where it is
supposed to be very best– Blocksworld
FF-Replan : Sungwook Yoon

Weakness of the Replanning
• Ignorance of the probabilistic effects– Try not to use actions with detrimental effects– Detrimental effects can sometimes easily be found
• Ignorance of prior planning during replanning– Plan Stability Work by Fox, Gerevini, Long and
Serina• No learning
– There is an obvious learning opportunity, since it solves a problem repetitively
FF-Replan : Sungwook Yoon

Potential improvements
• Intelligent Replanning
• Policy rollout• Policy learning• Hindsight
Optimization
• During (determinized) planning, when it meets the previous seen state, stop planning– May reduce the
replanning time
State
FF Replan
Average
Select Max
A1 A2
Reward
FF Replan
Average
Reward
• Hashing state-action mapping can be viewed as partial policy
• Currently, the mapping is always fixed
• When there is a failure, we can update the policy, that is, give penalty to the state-actions in the failure trajectory
• During planning, try not to use those actions in those states– E.g., after explosion in the
exploding-blocksworld, do not use putdown action
state
action
Action outcome that really will happen
Goal StateFF-Replan : Sungwook Yoon


















