
21 st International Unicode Conference Dublin, Ireland, May 2002 1 Folded Trie: Efficient Data...
21
1 t International Unicode Conference Dublin, Ireland, May 2002 Folded Trie: Efficient Data Structure for All of Unicode Vladimir Weinstein [email protected] Globalization Center of Competency, San Jose, C
-
Upload
melvyn-lynch -
Category
Documents
-
view
219 -
download
4
Transcript of 21 st International Unicode Conference Dublin, Ireland, May 2002 1 Folded Trie: Efficient Data...

121st International Unicode Conference Dublin, Ireland, May 2002
Folded Trie: Efficient Data Structure for All of Unicode
Vladimir Weinstein
Globalization Center of Competency, San Jose, CA

221st International Unicode Conference Dublin, Ireland, May 2002
Introduction
• A lot of data for each code point
• Need appropriate data structures
• Unicode version 3.1 introduced code points into supplementary space – addressable range grew to more than a million
• Repetitive data
• Sparsely populated range, especially the supplementary space

321st International Unicode Conference Dublin, Ireland, May 2002
Data Structures
• Arrays– Advantages: very fast access time, fast write time
– Disadvantage: Unacceptable memory consumption
• Hash tables– Advantages: Easy to use, Reasonably fast, General
– Disadvantages: High overhead, complicated sequential access, slower than array lookup, data within ranges is not shared

421st International Unicode Conference Dublin, Ireland, May 2002
Data Structures (continued)
• Inversion Maps– Advantages: simple, very compact, fast boolean
operations
– Disadvantages: worse access time than arrays and possibly hash tables
• For more details see “Bits of Unicode” at http://www.macchiato.com/slides/Bits_of_Unicode.ppt

521st International Unicode Conference Dublin, Ireland, May 2002
Tries
• A trie is a structure with one or more indexes and one data storage.
• Name comes from “Information Retrieval”
• Shares repetitive data
• Good compaction
• Not appropriate for frequently changing data

621st International Unicode Conference Dublin, Ireland, May 2002
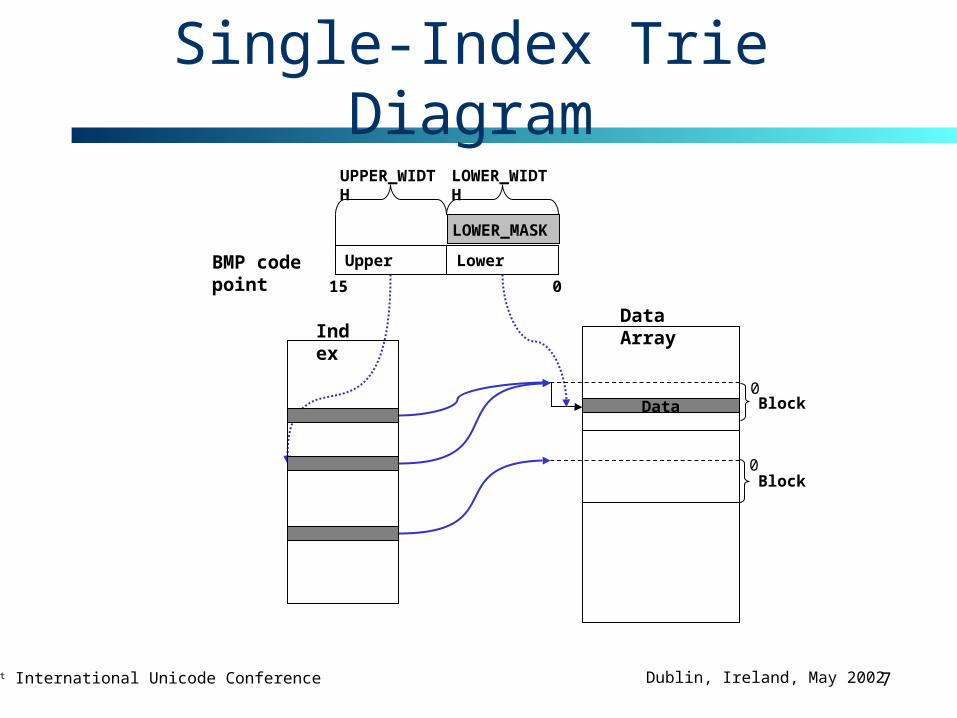
Single-Index Trie
• A trie structure with an index array and a data array.
• Advantages– Excellent size– Very good access performance (two array accesses,
shift, mask and addition)
• Disadvantages– Not appropriate for frequently changing data– Index array gets too big when dealing with
supplementary code points
721st International Unicode Conference Dublin, Ireland, May 2002
Single-Index Trie Diagram
BMP code point Upper Lower
15 0
LOWER_MASK
UPPER_WIDTH LOWER_WIDTH
IndexData Array
0
Data0
Block
Block

821st International Unicode Conference Dublin, Ireland, May 2002
Double-Index Trie
• Two index arrays and a data block
• Compared to single-index trie:1. Provides better compression of the index array
2. Worse performance, but still very fast
3. Feasible for supplementary code points

921st International Unicode Conference Dublin, Ireland, May 2002
Double-Index Trie Diagram
Block
Code point Upper Middle
20 0
Index 1 Index 2
0
Index2
Lower
Data
0
Data
MIDDLE_MASK LOWER_MASK
UPPER_WIDTH MIDDLE_WIDTH LOWER_WIDTH
Index1

1021st International Unicode Conference Dublin, Ireland, May 2002
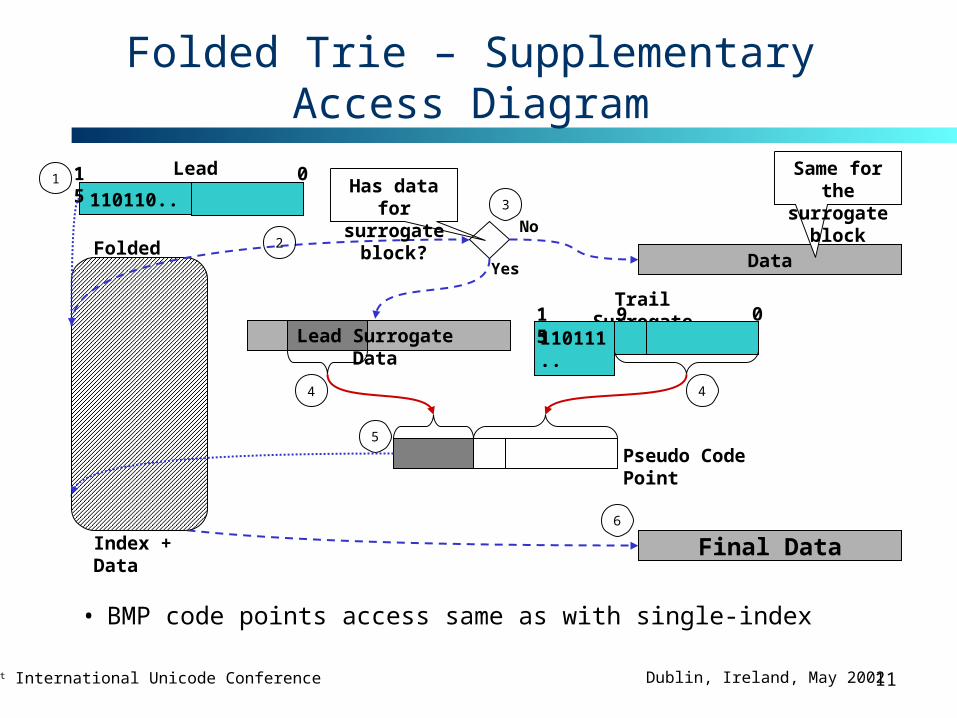
Folded Trie
• Fast access for BMP code points
• Slower access for supplementary code points, but far less frequent
• Compacts supplementary index
• Needs additional build time processing
• Fast address with UTF-16 code units– no need to construct code point
1121st International Unicode Conference Dublin, Ireland, May 2002
Folded Trie – Supplementary Access Diagram
Lead Surrogate
110110..15 0
0Trail Surrogate
110111..15 9
Pseudo Code Point
Final Data6
Folded Trie
Index + Data
5
1
2
Has data for surrogate block?
No
Yes
3
Data
Same for the surrogate block
44
Lead Surrogate Data
• BMP code points access same as with single-index

1221st International Unicode Conference Dublin, Ireland, May 2002
ICU Implementation: UTrie
• ICU implementation is called UTrie
• Stores either 16 bit or 32 bit wide data (extensible in the future)
• Up to 256K different data elements
• Can be frozen and reused as memory mapped image for fast startup
• Using UTrie requires custom code
More about ICU at the end of presentation

1321st International Unicode Conference Dublin, Ireland, May 2002
Range Enumeration
• Allows enumerating over a set of contiguous maximal ranges of same data elements
• Elements can be preprocessed by additional callback
• Saves time when processing the whole Unicode range by efficiently walking the trie structure
start
limit Element 3
Element 2
Element 2
Element 2
Element 2
Element 2
Element 2
Element 1start-1
limit-1

1421st International Unicode Conference Dublin, Ireland, May 2002
Latin-1 Fast Path
• Build time option
• Allows direct array access for the Latin-1 range (0x00-0xFF)
• Latin-1 range is not compressed if this option is used
• Appropriate when access for Latin-1 range is critical– collation

1521st International Unicode Conference Dublin, Ireland, May 2002
• Normalization data is stored using UTries
• For example, main data has the following format
Example: Normalization Data
Extra data index Combining class BCK FWD QC_MAYBE
31 15 7 6 5 3
Combines back
Combines forward
Can be either:-index to variable length data- first part of supplementary lookup value-Special handling indicator (Hangul, Jamo)
QC_NO
0
Values for normalization quick check
• Variable-length data contains composition and decomposition info

1621st International Unicode Conference Dublin, Ireland, May 2002
Example: Character Properties Data
• The result of UTrie lookup is an index
• Double indexing allows for even better compression, since many code points have the same property value
• UTrie data width is 16 bit (thousands of data entries), while the property data width is 32 bits (few hundred unique data words).
Index Data
Folded Trie
16 bits
Property data
32 bits

1721st International Unicode Conference Dublin, Ireland, May 2002
International Components for Unicode
• International Components for Unicode(ICU) is a library that provides robust and full-featured Unicode support
• Several library services use the common UTrie implementation
• Wide variety of supported platforms • open source (X license – non-viral)• C/C++ and Java versions• http://oss.software.ibm.com/icu/

1821st International Unicode Conference Dublin, Ireland, May 2002
Conclusion
• UTrie data structure provides good compression with fast access
• The main constraint for usage is the nature of the data that needs to be stored
• Designed for repetitive and sparse data

1921st International Unicode Conference Dublin, Ireland, May 2002
Q & A

2021st International Unicode Conference Dublin, Ireland, May 2002
Folding and Surrogate Access
• Folding process compacts the index for supplementaries and moves it right above the BMP index
• Access in ICU4C:– Define a C callback, invoked when special lead
surrogate is detected
– Manually detect special lead surrogates
• In ICU4J, provide a subclass with a method that detects special lead surrogates

2121st International Unicode Conference Dublin, Ireland, May 2002
Summary
• Introduction: Storing Unicode data
• Types of data structures
• Tries
• Single-index trie
• Double-index trie
• Folded trie
• Usage of folded trie in normalization
• Usage of folded trie for character properties


















