
20151015 zagreb spark_notebooks
33
© 2015 IBM Corporation Spark and Notebooks
-
Upload
andrey-vykhodtsev -
Category
Data & Analytics
-
view
227 -
download
0
Transcript of 20151015 zagreb spark_notebooks

© 2015 IBM Corporation
Spark and Notebooks

IBM Spark © 2015 IBM Corporation
• Big Data Developers and
Apache Spark meetups
•I also participate in number
of Moscow, Ljubljana
meetups
Hello Zagreb

IBM Spark © 2015 IBM Corporation
• Goal – to get you started on Spark & Notebooks
•Overview of DataScience workflow
• General overview of notebooks
• Recap what Spark is
• Comparing existing technologies
• Languages & libraries
• Demo
Goal & Agenda

IBM Spark © 2015 IBM Corporation
Skillset of the Data Scientist
Statistician
Software Engineer
Business Analyst
Process Automation
Parallel Computing
Software Development
Database Systems
Mathematics Background
Analytic Mindset
Domain Expertise
Business Focus
Effective Communication

IBM Spark © 2015 IBM Corporation
Iterative Cycle of Data Science
Business
Understandi
ng
Analytic
Approach
Data
Requirement
s
Data
Collection
Data
Understandi
ng Data
Preparation Modelling
Evaluation
Deployment
Feedback

IBM Spark © 2015 IBM Corporation
• Data scientist needs an interactive environment to
work in
• Has to be responsive
• Has to support
• literate programming
• Reproducibility and easy to publish
• Code together with description
Why we need a notebook

IBM Spark © 2015 IBM Corporation
• In our context – interactive web env
• You input your code in cells
• Or markdown text
• Outputs are displayed on the page
• Outputs generally saved with a
notebook
What is a notebook (cont.)

IBM Spark © 2015 IBM Corporation
• Notebook server
• On large amounts of data – parallel processing
engine
• Spark in our case (no alternatives?)
• Libraries (depends on programming language)
–Machine learning
–Data munging
–Visualisation / Plotting
What do you need to run a notebook

IBM Spark © 2015 IBM Corporation
An Apache Foundation open source project.
An in-memory compute engine that works with data.
Enables highly iterative analysis on large volumes of data at scale
Unified environment for data scientists, developers and data engineers
Radically simplifies process of developing intelligent apps fueled by data.
Spark in simple words
IBM Spark © 2015 IBM Corporation
If you don’t know Spark yet,
here is how you learn
https://github.com/spark-mooc/mooc-setup

IBM Spark © 2015 IBM Corporation
What IBM has to do with Spark?

IBM Spark © 2015 IBM Corporation
Resilient distributed datasets (RDDs)
Immutable collections partitioned across cluster that can be rebuilt if a partition is lost
Created by transforming data in stable storage using data flow operators (map, filter, group-by, …)
Can be cached across parallel operations
Parallel operations on RDDs
Reduce, collect, count, save, …
Spark Programming Model

IBM Spark © 2015 IBM Corporation
Iterative & Pipeline Analysis
using Spark
Iteration 1 Iteration 2
Disk
Read
Disk
Read
Disk
Read
Disk
Write
Disk
Write
Iteration 1 Iteration 2
Disk
Read
Memory Memory
MapReduce
SystemML & Spark

IBM Spark © 2015 IBM Corporation
Spark Programming Model - Example
lines = spark.textFile(“hdfs://...”) // Base RDD
messages = lines.filter(_.startsWith(“ERROR”)) // Transformed RDD
cachedMsgs = messages.cache() // Cached RDD
cachedMsgs.filter(_.contains(“foo”)).count // Parallel Operation
cachedMsgs.filter(_.contains(“bar”)).count
Block 2
Worker
Worker
Worker
Driver tasks
results
Cache 2
Block 3
Cache 3
Block 1
Cache 1
Result: full-text search of Wikipedia in
<1 sec (vs 20 sec for on-disk data)

IBM Spark © 2015 IBM Corporation
• Zeppelin
• Jupyter
• Ipython
• spark-notebook
• scala-notebook
Notebook servers

IBM Spark © 2015 IBM Corporation
• grew out of Ipython
• Julia, Python, R
• Now many more languages (40)
•https://try.jupyter.org/
• Markdown support
• Mathjax support
Jupyter project

IBM Spark © 2015 IBM Corporation
• Simplest way is to use Anaconda Python distribution
• https://www.continuum.io/downloads
•Otherwise read installation docs
• Start pyspark with Ipython
• PYSPARK_DRIVER_PYTHON=ipython PYSPARK_DRIVER_PYTHON_OPTS="notebook --no-
browser --port 12000 --ip='0.0.0.0'" ./bin/pyspark
• Open browser
Jupyter – installation with Spark

IBM Spark © 2015 IBM Corporation
• not as easy
• install scala kernel
• https://github.com/alexarchambault/jupyter-scala
•I use cloud services for scala (see
later)
Jupyter – installing with Scala

IBM Spark © 2015 IBM Corporation
• Use keyboard shortcuts
• Use Markdown and markdown
help
• Mathjax for formulas
Jupyter usage - basics

IBM Spark © 2015 IBM Corporation
• Richest set of features
• Matplotlib, seaborn libs for data visualisation
• Sklearn, numpy, pandas
Languages - Python

IBM Spark © 2015 IBM Corporation
• create subplots or just plot
• plot series
• Seaborn simplifies many tasks
Matplotlib / seaborn basics

IBM Spark © 2015 IBM Corporation
• Fast schema creation
•Create pandas frame from small subset
• Convert to Spark DF
• extract schema
• sparkDF.limit(10).toPandas()
Pandas / Spark tips

IBM Spark © 2015 IBM Corporation
• Better with Zeppelin
• less libraries for plotting
Languages - Scala

IBM Spark © 2015 IBM Corporation
• Widely popular statistical
Language
•SparkR
•Ggplot2
• tried it with Data Scientist
workbench
Languages - R

IBM Spark © 2015 IBM Corporation
• Number of sandboxes available
• Recommend using Vagrant
•https://github.com/vykhand/spark-
vagrant
•Spark edX MOOC
Running locally

IBM Spark © 2015 IBM Corporation
• register for BlueMix
• Create Spark As a Service
Boilerplate
• upload files to object storage
Running jupyter in Cloud – Spark as a service

IBM Spark © 2015 IBM Corporation
• Rapidly developed product
• Notebooks
• Data wrangling
• Rstudio
• Check it out – available for preview
Running jupyter in cloud – Data Scientist workbench

IBM Spark © 2015 IBM Corporation
Demo
IBM Spark © 2015 IBM Corporation
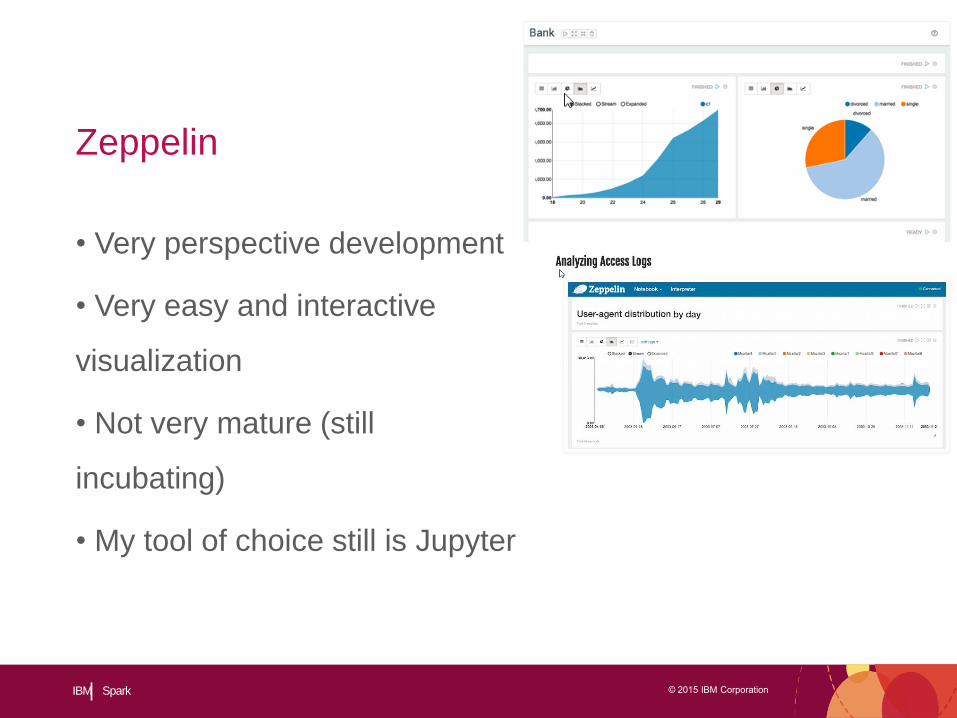
• Very perspective development
• Very easy and interactive
visualization
• Not very mature (still
incubating)
• My tool of choice still is Jupyter
Zeppelin
IBM Spark © 2015 IBM Corporation
• the fastest way is this vagrant box
• http://arjon.es/2015/08/23/vagrant-spark-zeppelin-a-toolbox-to-the-
data-analyst/
• https://github.com/arjones/vagrant-spark-zeppelin
• Install vagrant
• Install virtual box
• git clone
•Vagrant up
Zeppelin – getting started

IBM Spark © 2015 IBM Corporation
• Very pretty
• Multiple choice of interpreters,
• many interpreters per page
• configure dependencies and
execution parameters via GUI
Things I like

IBM Spark © 2015 IBM Corporation
• Fragile
• Sometimes counter-intuitive
• No obvious way to control
notebook execution
Things I don’t like

IBM Spark © 2015 IBM Corporation
demo


















