

2000 KDD Cup Winners
75
Salford Systems KDD CUP 2000 WINNER Mikhail Golovnya, Dan Steinberg, Scott Cardell [email protected]
-
Upload
salford-systems -
Category
Technology
-
view
1.552 -
download
2
Transcript of 2000 KDD Cup Winners

Question 1: Given a set of page views, will the visitor view another page on the site or will the visitor leave?
Question 2: Given a set of page views, which product will the visitor view in the remainder of the session?
Question 3: Given a set of purchases over a period of time, characterize visitors who spend more than $12 (order amount) on an average order at the site?
Question 4 and 5: insight versions of questions 1 and 2
KDD-CUP: Questions

Gazelle.com is a leg-wear and leg-care web retailer
Soft-launch: Jan 30, 2000
Hard-launch: Feb 29, 2000
◦ With an Ally McBeal TV ad on 28th and strong $10 off promotion
Training set: 2 months
Test sets: one month (split into two test sets)
The GAZELLE Site

(insert decision tree process)
GAZELLE SITE LAYOUT

(insert home page image)
GAZELLE Home Page

Web Application Server:
◦ Takes care of sessionizing (unique session ID is assigned to each user’s session)
◦ Takes care of registration and logging in (unique customer ID is assigned to each registered user)
◦ Uses dynamic HTML unique page view is identified via a combination of page view template (*.jhtml or *.jsp) and query parameters (product ID, vendor ID, assortment ID, etc.)
All data supplied come directly from the web application server logs
Data Collection

Acxiom enhancements: age, gender, marital status, vehicle lifestyle, own/rent, etc.
Keynote records (about 250,000) removed. They hit the home page 3 times a minute, 24 hours
Personal information was removed, including: Names, addresses, login, credit card, phones, host name/IP, verification question/answer. Cookie, e-mail were obfuscated.
Test users were removed based on multiple criteria (e.g. credit card number) not available to competitors
Original data and aggregated data (to session level) were provided
Data Pre-processing

CLICKS◦ Contains click-stream information
◦ Each record is a page view
◦ Basis for questions 1 and 2
◦ Each sequence of clicks forms a session
◦ Session continues for any page view except for the last
ORDER LINES◦ Contains order information
◦ Each record is an order line
◦ Order is a collection of order lines with the same order ID
◦ Basis for question 3
Data Sets
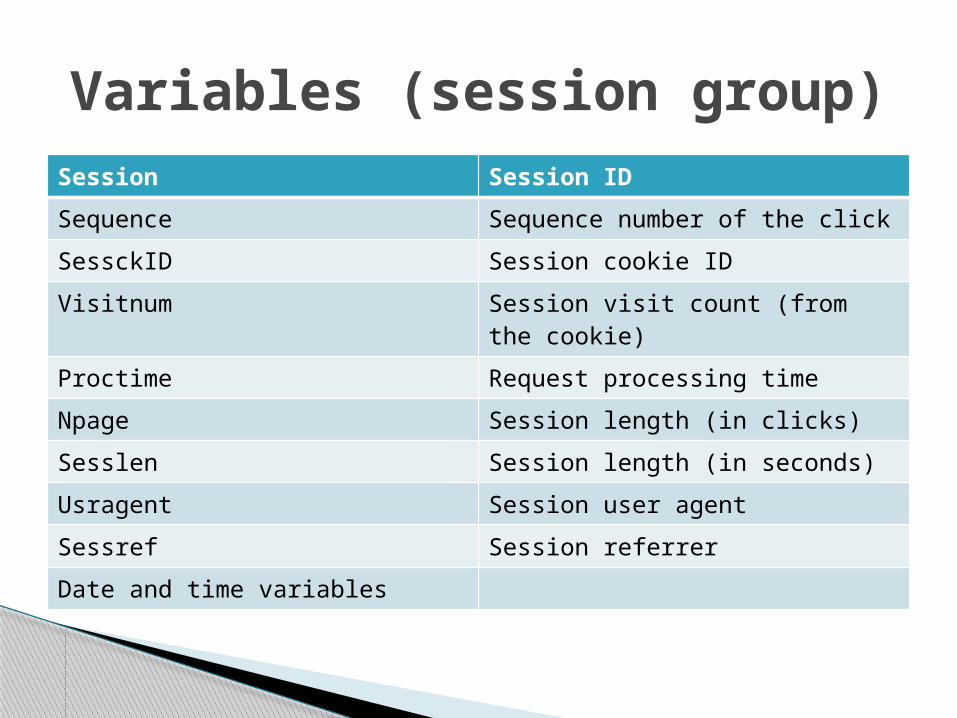
Session Session ID
Sequence Sequence number of the click
SessckID Session cookie ID
Visitnum Session visit count (from the cookie)
Proctime Request processing time
Npage Session length (in clicks)
Sesslen Session length (in seconds)
Usragent Session user agent
Sessref Session referrer
Date and time variables
Variables (session group)
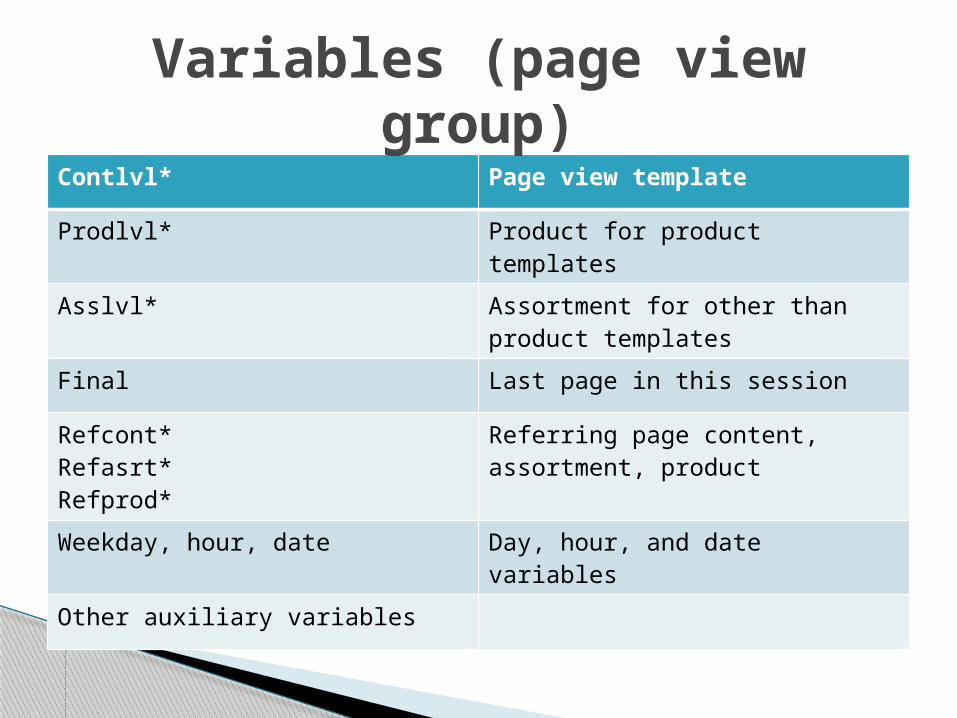
Contlvl* Page view template
Prodlvl* Product for product templates
Asslvl* Assortment for other than product templates
Final Last page in this session
Refcont*Refasrt*Refprod*
Referring page content, assortment, product
Weekday, hour, date Day, hour, and date variables
Other auxiliary variables
Variables (page view group)
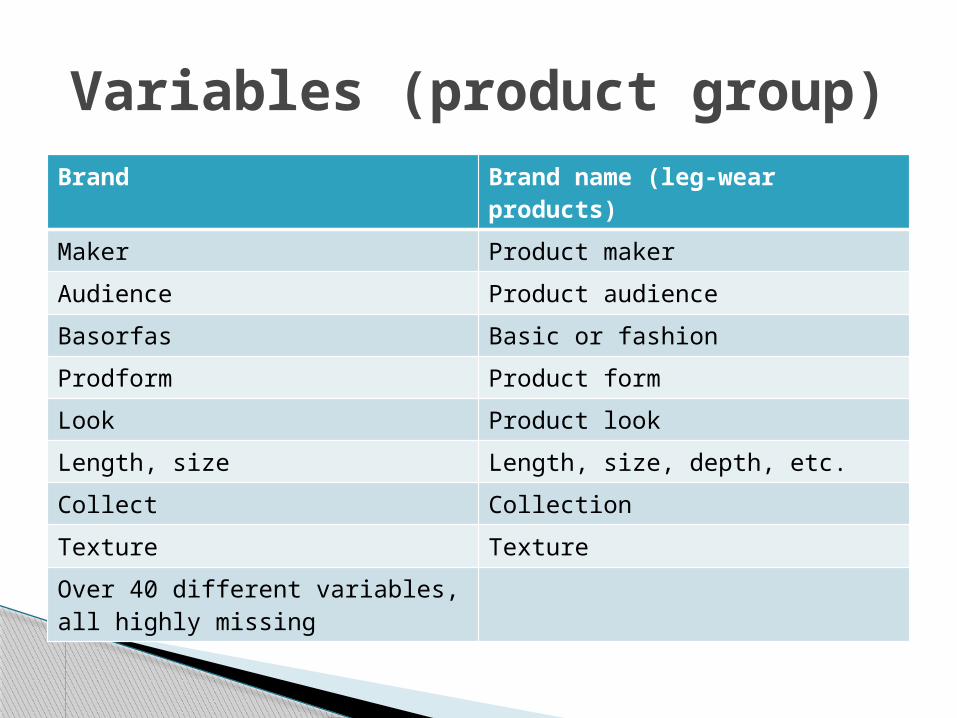
Brand Brand name (leg-wear products)
Maker Product maker
Audience Product audience
Basorfas Basic or fashion
Prodform Product form
Look Product look
Length, size Length, size, depth, etc.
Collect Collection
Texture Texture
Over 40 different variables, all highly missing
Variables (product group)

CustID Customer ID
Nfail Number of failed logins
Sesslcnt Session login count
Account creation date/time variables
Variables (registered user group)
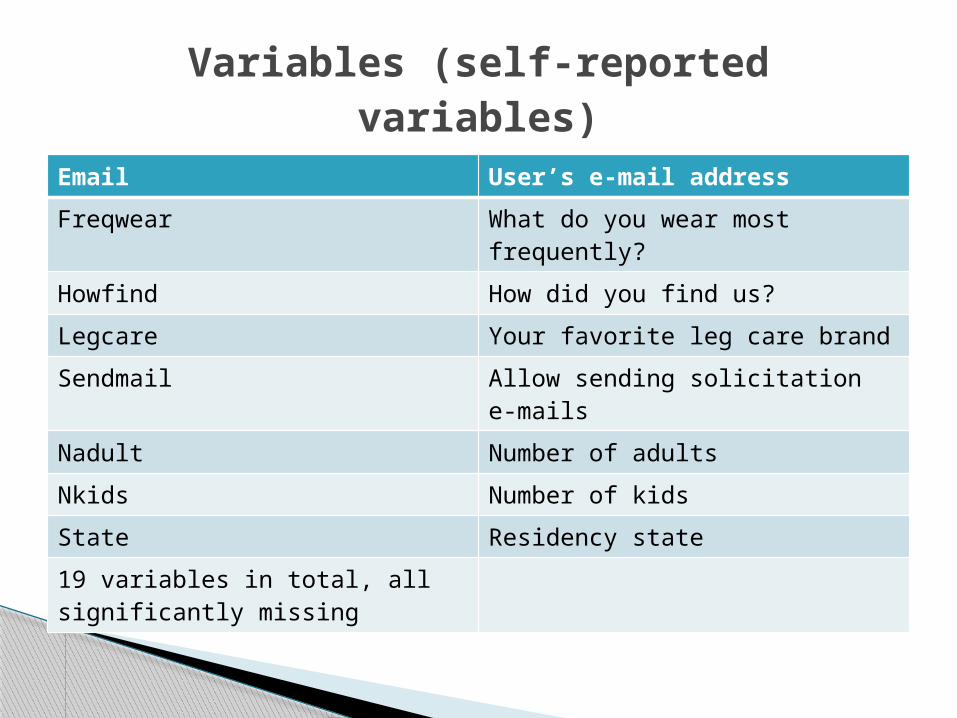
Email User’s e-mail address
Freqwear What do you wear most frequently?
Howfind How did you find us?
Legcare Your favorite leg care brand
Sendmail Allow sending solicitation e-mails
Nadult Number of adults
Nkids Number of kids
State Residency state
19 variables in total, all significantly missing
Variables (self-reported variables)
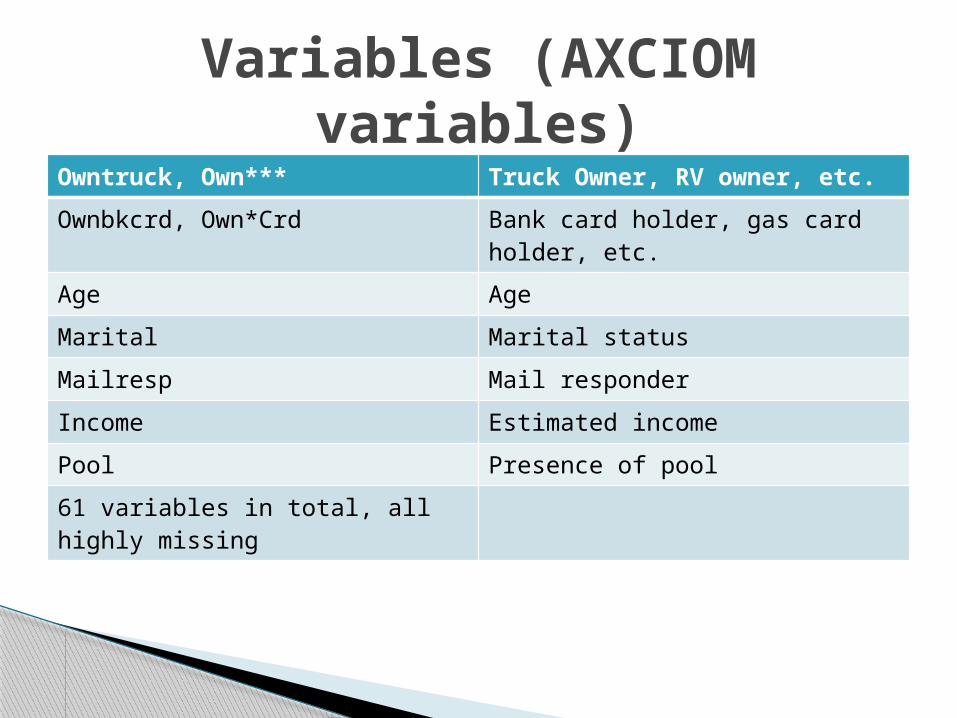
Owntruck, Own*** Truck Owner, RV owner, etc.
Ownbkcrd, Own*Crd Bank card holder, gas card holder, etc.
Age Age
Marital Marital status
Mailresp Mail responder
Income Estimated income
Pool Presence of pool
61 variables in total, all highly missing
Variables (AXCIOM variables)

Detailed understanding of all initial variables (this took nearly 50% of total project time!!!)
Creating new predictors (features):◦ Slicing a variable into a set of key dimensions◦ Combining different levels into logical groups to reduce the total
number of categories◦ Combining a set of variables into one informative dimension◦ Creating new features to account for different layers of
aggregation (CLICKS vs. SESSIONS vs. ORDERS vs. USERS)
Developing the master KEEP list:◦ Separating “illegal” predictors from “legitimate” ones◦ Removing “useless” predictors (duplicates, nearly unary,
extremely missing)
Analysis Plan

Possibly dividing the large CLICKS data base into logical segments (Registered Users vs. Unregistered, Short Sessions vs. Long Sessions) with subsequent separate analyses and KEEP lists within each segment
Defining the right CART model set-up (especially for PRIORS and COSTS)
Running different CART models, analyzing the performance, revisiting all of the steps above to develop/test/reject new features
For questions 1 and 2 choose the models with the highest overall score (adjusted for the evaluation criteria)
For question 3 learn as much as possible from all of the above
Analysis Plan (cont.)

SESSION REFERRER (SESSREF)
◦ Carries on extremely useful information regarding where the user was immediately before initiating a GAZELLE session
◦ In its raw form practically useless (too many levels)
SESSION USER AGENT (USRAGENT)
◦ Provides detailed information about the user’s browser, including operating system and AOL/MSN connection
◦ Helps in identifying “artificial” users (ROBOTS)
◦ Again, practically useless in its raw form
Slicing a Variable

Referring Host (REFWEB) is one of the dimensions extracted after slicing the referrer◦ Still has thousands of distinct levels (How many web-servers are out
there?!!)
◦ Want to simplify for a more informative use
◦ Same services may have a variety of different host names
New logical groups of REFWEB:◦ Search engines (yahoo, excite, Google, etc.)
◦ Fashion sites (Fashion Mall, Shop Now)
◦ Bargain sites (Free Gifts, My Coupons, etc.)
◦ “Specialty Sites” (Winnie-Cooper!!!)
◦ NULL (session was initiated via a bookmark or direct typing in)
Combining Levels

Answer: Winnie-Cooper is a 31 year old guy who wears pantyhose and has a pantyhose site. 8,700 visitors came from his site(!)
We might and we should expect different behavior of “Winnie-Cooper” users from everyone else
Who is Winnie-Cooper?

All PRODLVL*, CONTLVL*, and ASSLVL* variables turned out to be nearly useless for direct modeling and awkward for interpretation
PRODLVL1-PRODLVL3 represent different path levels in the file system that point into individual product information
Reasonable to combine all three paths into a unique product descriptor PRODP
Similarly, generate unique assortment and content descriptors CONTP and ASSP
Finally, combine all three descriptors into a single page view descriptor (static equivalent of dynamic HTML) VIEWCAT- an extremely useful interpretation variable
Combining Variables

(insert images)
Creating New Features

Adding clicks history◦ 1-page back, 2-pages back, 3-pages back, etc.
◦ Dummies indicating if a given “epoch” page (home page, registration page, Donna Karan, etc.) has already been viewed prior to this click in the current session
◦ Counting the number of views up to this click in the session for the selected “epoch” pages
Adding session history◦ Identifying previous sessions based on either USERID (registered
users) or COOKIE (unregistered users)
◦ Collect history features from the previous sessions (first visit, ordered ever, ordered previously, viewed Donna Karan products before, etc.)
Creating New Features

Adding registration history◦ CUSTID is only defined for the session in which the user logged in
explicitly
◦ Using COOKIEID, it is possible to approximately identify anonymous sessions that belong to a registered user
◦ Define REGISTEV=YES for any session that was initiated by a registered user (even prior to the registration event)
◦ This also gives rise to additional related features (registered previously , have yet to register, etc.)
Aggregating order lines◦ Mostly for question 3: summarizing order-line characteristics to the
ORDERS and USER levels (buy socks, buy leg-care, buy black, buy fashion, etc.)
Creating New Features

Initial CLICKS data base had about 900,000 records and 220 variables
After the filtration and adding new features the number of variables grew up to 450
Dividing CLICKS into segments seems justifiable
A CART run with DEPTH=2 reveals that SEQUENCE=1 is the root splitter for both question 1 and 2
There is something special about the first click!
Dividing CLICKS into Segments

(insert tables)
Conclusion: usually the first click also becomes the last (come and leave!)
Dividing CLICKS into Segments

Again, running CART DEPTH=2 on SEQUENCE>1 shows that the next split separates registered ever users from non-registered
Median session length (after removing lengths 1): ◦ Never registered 8◦ Registered at some point 26
Naturally, a registered user will have a longer session than a non-registered user
Similarly, CART finds additional splits on SEQUENCE=2, SEQUENCE=[3,4,5], and SEQUENCE>5
Dividing CLICKS into Segments

(insert image)
Dividing CLICKS into Segments

Complete CLICKS data set should be used for training to exploit all available information
However, the evaluation criterion for question 1 is referring to the SESSION level: will the SESSION continue?
Prior Probabilities should be set manually to SESSION level values to adjust CART to the evaluation criterion
Since we have 5 different partitions of the CLICKS database, 5 different sets of Prior Probabilities must be specified
Prior Probabilities

(insert image)
The “majority rule” is very hard to beat!
Entry Point Clicks

Checking rules for the right child of the root split
(insert image)
Root split separates crawlers, robots, and unusual browsers
Entry Point Clicks

Node Report- Further insight into the root splitter
(insert image)
The root splitter is very powerful
The root splitter is also quite “unique”
Entry Point Clicks

Checking the second split
(insert image)
Second split distinguishes ever registered users from anonymous users
Entry Point Clicks

(insert image)
This node has the largest probability of exit
This segment gives the best predictive power
Registered Users

Root split separates “killer” pages from “killing” pages
(insert images)
Registered Users

(insert image)
Still quite difficult to predict!
Short Sessions

Again, root split separates “killer” pages from “killing” pages!
(insert image)
This variable might be difficult to interpret
CONTP1 could be used instead- much easier to interpret
Short Sessions

(insert image)
The tree is large, yet it is extremely difficult to predict!
Middle Size Sessions

(insert image)
Still a very hard prediction problem
Long Sessions

QUESTION: Given a set of page views, which product brand (Hanes, Donna Karan, American Essentials, or None) will the visitor view in the remainder of the session?
Evaluation Criterion: ◦ 2 units if the session visited the predicted brand;
◦ 1 unit if the session did not visit any of the three brands and the prediction was none;
◦ O units otherwise;
◦ All sessions of length 1 will be excluded
Question 2

For the given (truncated) session only 8 outcomes are possible in the remainder of the session:
◦ None brands are visited◦ Only Hanes visited◦ Only Donna Karan visited◦ Only American Essentials visited◦ Only Hanes and Donna Karan ◦ Only Donna and American Essentials◦ Only Hanes and American Essentials◦ All three visited
Thus we have 8- level target that should be mapped into 4 distinct levels for final prediction and scoring
Defining the Target “Single event” Will use directly
-O-H-D-A
-HD-DA-HA-AHD“Double or Triple” Must convert to “single”
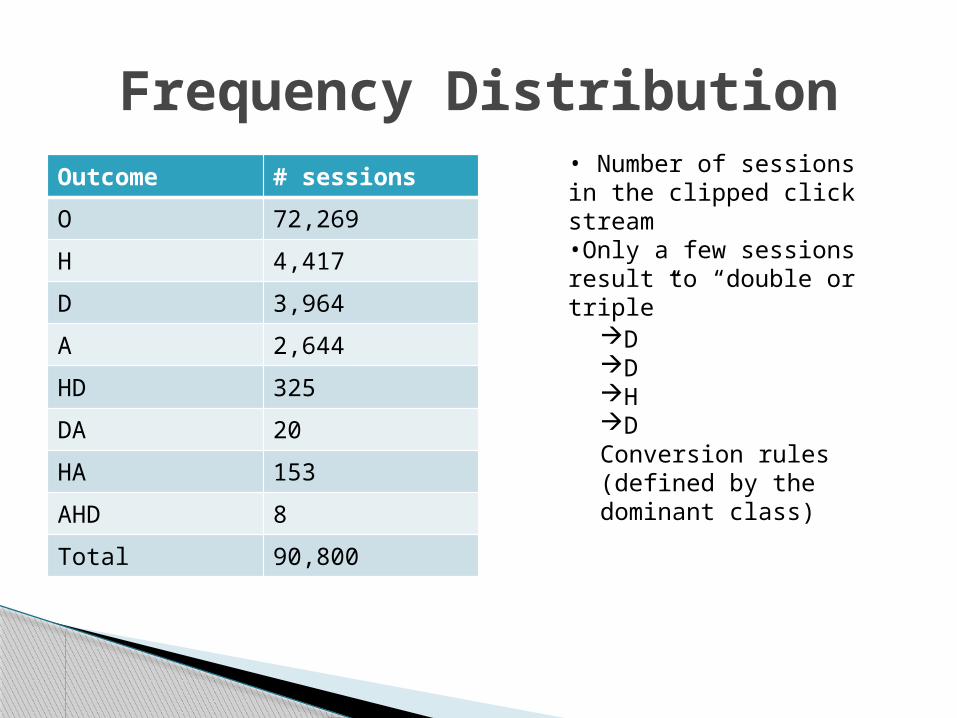
Outcome # sessions
O 72,269
H 4,417
D 3,964
A 2,644
HD 325
DA 20
HA 153
AHD 8
Total 90,800
Frequency Distribution• Number of sessions in the clipped click stream•Only a few sessions result to “double or triple”
DDHDConversion rules (defined by the dominant class)

Costs must be used to incorporate the evaluation criterion
(insert table)
Cost Matrix

The segmentation is done using the same technique that was used in Question 1 segmentation
(insert image)
Segmentation of CLICKS

First we try GINI splitting rule
(insert image)
The tree is big, but the accuracy is low
Entry Point Clicks

Now let’s try TWOING
(insert image)
All red nodes predict NONE
Smaller tree, better accuracy
Entry Point Clicks

Now focus on DONNA views
(insert image)
Now all red nodes predict DONNA
Entry Point Clicks

Variable Importance clarifies which variables have the largest predictive power
(insert image)
Entry Point Clicks

Using TWOING splitting rule
(insert image)
Short sessions are the easiest to predict
Short Sessions

For SEQUENCE=5 and above
(insert image)
Longer sessions are becoming quite challenging
Long Sessions

In the evaluation, each session with at least 2 clicks is randomly clipped to a shorter length
This means that a session of length T>1 is clipped to length S with probability 1/(T-1) for S=1,…,T-1
For each terminal node in a CART tree the training cases must be weighted by the appropriate clipping probability when calculating the within-node probabilities
Predict OTHER is its revised probability was more than twice that of the highest probability brand; otherwise, the highest probability brand was predicted
Final Scoring

Characterize visitors who spend more than $12 on an average order at the site
Small dataset of 3,465 purchases 1,831 customers
Insight question- no test set
Submission requirement:◦ Report of up to 1,000 words and 10 graphs
◦ Business users should be able to understand report
◦ Observations should be correct and interesting average order
◦ tax>$2 implies heavy spender is not interesting nor actionable
Question 3

(insert graph)
Order Traffic

(insert images)
Self-Reported Variables

(insert graphs)
AXCIOM Insights

(insert graph)
Promotions Low Spender

(insert graph)
Session History is Important

(insert graphs)
Expensive vs. Cheap Products

Orders come from different cities:◦ 80% of orders coming from San Francisco and Chicago are
heavy spenders
◦ 40% of orders coming from New York are heavy spenders
◦ Orders coming from elsewhere have only 25% of heavy spenders
Color makes the difference- buying black products implies heavy spender
Color is also related to city: orders from large cities have higher percent of black color
City Makes the Difference

Leg-care products are more expensive◦ 75% of leg-care orders were above $12 threshold◦ Only 25% of leg-wear orders were above $12
Pantyhose are more expensive than socks
Hanes and Donna Karan imply heavy spenders
American Essentials imply low spenders
Trivial Insights

Referrals from Shopnow or Fashion Mall imply heavy spenders, whereas MyCoupons are low spenders
Work Dress business casual or business imply heavy spender
Sunday and Monday are heavy spender days
Income makes the difference, but not much:◦ 40% of very high income users are high spenders
◦ 32% of very low income are also high spenders
◦ Only 25% are high spenders for everyone else
Additional Insights

AOL users tend to spend less
◦ 20% of AOL users are high spenders
◦ 29% of the remaining users are high spenders
◦ This might also be explained by the lack of testing GAZELLE site on the AOL browsers (incompatibility issues)
Luxury vehicle implies heavy spender (slightly)
Additional Insights

(insert graph)
Using CART to Check Income

WEB MINING BASICS

(insert image)
Raw Web Log

The parts marked in red might safely be removed
Normally want to remove all graphic content queries like◦ GIF and JPG files◦ Other unnecessary content
May reduce the size of the raw web log up to 5 times
The resulting web log now contains only the most important pieces of information
Cleaning Web Log

(insert image)
Clean Web Log

The clean web log is still not suitable for any data processing since each row basically represents a set of characters
Need to convert each legitimate line into a delimited list of data fields
Want to choose a delimiter that never occurs in the raw web log
Will have to drop all corrupt log entries
Splitting Web Log

(insert image)
Web Log in CSV Format

Each line (entry) in a web log corresponds to a single resource request
A user normally issues a set of logically connected requests called SESSION
Multiple users may share the same time frame intermixed log entries
HTTP protocol is MEMORYLESS need to solve the problem of identifying different sessions
Sessionizing Web Log

Using COOKIES to mark client’s station◦ Might be disabled by “paranoid” clients
◦ Might be deleted or “exhausted”
Using URL encoding◦ Requires dynamic HTML (ASP, JSP, Servlets)
Using pure web log heuristics◦ Mostly matching on IP-address, user agent, and referrer fields
◦ May be done on any server that supports extended log format
◦ Somewhat imprecise in identifying sessions under certain “unfavorable” conditions
Possible Ways to Sessionize

Identifying END OF SESSION event◦ Widely used 30-minute standard does not always work
Proxy Servers◦ Multiple users may share the same IP address◦ Cached requests are “forever lost” for the server’s log◦
Dynamic IP addresses◦ A single user might have different IP address within the same session
Spiders and Robots◦ Completely violate any human “logic” and may generate a lot of
“false” or “huge” sessions
Smart heuristic programming may reduce the ambiguity down to as low as 5%
Difficulties with Heuristic Sessionizing

(insert image)
Sessionized Web Log

The “referrer” field provides extremely valuable information about the user
“Referrer” links back to the previous request
Empty “referrer” indicates that the request was initiated from a bookmark or by direct typing of the URL
Non empty “referrer” either links back to the previous resource requested from the server or gives the URL of the “outside” resource that the user was accessing immediately before initiating the current session
Not easy to use directly: too many distinct values
Notes on REFERRER

Referrer just like any other URL might be decomposed into the following pieces◦ Protocol used (http, https, etc.)
◦ Site (domain name of the server)
◦ Domain (com, edu, uk, etc.)
◦ Resource (including path relative to the server)
◦ Port (usually missing for default assignment)
◦ Query string
Should consider grouping “sites into logical segments (search engines, specialty sites, etc.)
May require further processing of the “resource” and “query string” (key-words, categories, etc.)
Processing REFERRER

(insert image)
Processed REFERRER


















