![Jambalaya [yearbook] 1920 plus Medical yearbook 1920](https://static.fdocuments.in/doc/165x107/586cd4c31a28ab0b6b8bf18e/jambalaya-yearbook-1920-plus-medical-yearbook-1920.jpg)
1920 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 15,...
10
1920 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 15, NO. 8, DECEMBER 2013 Web Multimedia Object Classification Using Cross-Domain Correlation Knowledge Wenting Lu, Jingxuan Li, Tao Li, Weidong Guo, Honggang Zhang, and Jun Guo Abstract—Given a collection of web images with the corre- sponding textual descriptions, in this paper, we propose a novel cross-domain learning method to classify these web multimedia objects by transferring the correlation knowledge among dif- ferent information sources. Here, the knowledge is extracted from unlabeled objects through unsupervised learning and applied to perform supervised classification tasks. To mine more meaningful correlation knowledge, instead of using commonly used visual words in the traditional bag-of-visual-words (BoW) model, we discover higher level visual components (words and phrases) to incorporate the spatial and semantic information into our image representation model, i.e., bag-of-visual-phrases (BoP). By combining the enriched visual components with the textual words, we calculate the frequently co-occurring pairs among them to construct a cross-domain correlated graph in which the correlation knowledge is mined. After that, we investigate two different strategies to apply such knowledge to enrich the feature space where the supervised classification is performed. By transferring such knowledge, our cross-domain transfer learning method can not only handle large scale web multimedia objects, but also deal with the situation that the textual descriptions of a small portion of web images are missing. Empirical experiments on two different datasets of web multimedia objects are conducted to demonstrate the efficacy and effectiveness of our proposed cross-domain transfer learning method. Index Terms—Bag-of-Visual-Phrases Model, Correlation Knowledge, Cross-Domain, Multimedia Object Classification, Transfer Learning. I. INTRODUCTION A. Web Multimedia Object Classification M ULTIMEDIA object classification, as a crucial step of multimedia information retrieval, has found many applications such as indexing and organizing web multimedia Manuscript received November 06, 2012; revised April 02, 2013; accepted June 03, 2013. Date of publication September 05, 2013; date of current version November 13, 2013. This work was supported in part by National Social Science Fund of China under Grant No.11BJY075, National Natural Science Foundation of China under Grant No.61273217, 61175011 and 61171193, the 111 project under Grant No.B08004, and the Fundamental Research Funds for the Cen- tral Universities, and by NSF under grant HRD-0833093 and CNS-1126619, and the Army Research Office under grant W911NF-10–1-0366 and W911NF- 12–1-0431. The associate editor coordinating the review of this manuscript and approving it for publication was Prof. Alan Hanjalic. W. Lu and W. Guo are with the Capital University of Economics and Busi- ness, Beijing 100070, China (e-mail: [email protected]; [email protected]). J. Li and T. Li are with Florida International University, Miami, FL 33199 USA (e-mail: jli003@cs.fiu.edu; taoli@cs.fiu.edu). H. Zhang and J. Guo are with Beijing University of Posts and Telecommuni- cations, Beijing 100876, China (e-mail: [email protected]; [email protected]. cn). Color versions of one or more of the figures in this paper are available online at http://ieeexplore.ieee.org. Digital Object Identifier 10.1109/TMM.2013.2280895 Fig. 1. Example web images and their corresponding textual descriptions. Each row represents a class, i.e.,, a topic-related event. databases, browsing and searching web multimedia objects, multimedia information delivery and discovering interesting patterns from objects [1]. Given a collection of web images with the corresponding textual descriptions, as shown in Fig. 1, where the auxiliary textual information is often provided by web users to describe the general contents of images (i.e.,, image titles, headers and tags), a challenging question is how to perform classification tasks by leveraging both the image features and the textual information. As we all know, classic supervised learning algorithms for classification aim at training suitable classifiers using labeled data samples. However, although the textual information is often provided by web users for dramatically increased multi- media objects, true labels of web images for classification are usually difficult and expensive to obtain. Moreover, the testing data may not follow the same class labels or generative distri- butions as the labeled training data. The above two limitations could be addressed by taking the learning process into consid- eration. In the process of the human learning, besides learning the samples from new learning task, we usually apply our knowledge and experiences obtained in the previous learning processes to facilitate the new learning task. This principle is also applicable in machine learning process. For example, it might be easier for a robot to recognize “Toyota sedan” quickly if it has already known how to identify “Ford SUV” and “Benz sedan”; previous experiences in playing violin might provide some guidance to learn playing piano and sachs. Therefore, 1520-9210 © 2013 IEEE
Transcript of 1920 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 15,...

1920 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 15, NO. 8, DECEMBER 2013
Web Multimedia Object Classification UsingCross-Domain Correlation KnowledgeWenting Lu, Jingxuan Li, Tao Li, Weidong Guo, Honggang Zhang, and Jun Guo
Abstract—Given a collection of web images with the corre-sponding textual descriptions, in this paper, we propose a novelcross-domain learning method to classify these web multimediaobjects by transferring the correlation knowledge among dif-ferent information sources. Here, the knowledge is extracted fromunlabeled objects through unsupervised learning and applied toperform supervised classification tasks. To mine more meaningfulcorrelation knowledge, instead of using commonly used visualwords in the traditional bag-of-visual-words (BoW) model, wediscover higher level visual components (words and phrases)to incorporate the spatial and semantic information into ourimage representation model, i.e., bag-of-visual-phrases (BoP).By combining the enriched visual components with the textualwords, we calculate the frequently co-occurring pairs amongthem to construct a cross-domain correlated graph in whichthe correlation knowledge is mined. After that, we investigatetwo different strategies to apply such knowledge to enrich thefeature space where the supervised classification is performed. Bytransferring such knowledge, our cross-domain transfer learningmethod can not only handle large scale web multimedia objects,but also deal with the situation that the textual descriptions of asmall portion of web images are missing. Empirical experimentson two different datasets of web multimedia objects are conductedto demonstrate the efficacy and effectiveness of our proposedcross-domain transfer learning method.
Index Terms—Bag-of-Visual-Phrases Model, CorrelationKnowledge, Cross-Domain, Multimedia Object Classification,Transfer Learning.
I. INTRODUCTION
A. Web Multimedia Object Classification
M ULTIMEDIA object classification, as a crucial stepof multimedia information retrieval, has found many
applications such as indexing and organizing web multimedia
Manuscript received November 06, 2012; revised April 02, 2013; acceptedJune 03, 2013. Date of publication September 05, 2013; date of current versionNovember 13, 2013. This workwas supported in part byNational Social ScienceFund of China under Grant No.11BJY075, National Natural Science Foundationof China under Grant No.61273217, 61175011 and 61171193, the 111 projectunder Grant No.B08004, and the Fundamental Research Funds for the Cen-tral Universities, and by NSF under grant HRD-0833093 and CNS-1126619,and the Army Research Office under grant W911NF-10–1-0366 and W911NF-12–1-0431. The associate editor coordinating the review of this manuscript andapproving it for publication was Prof. Alan Hanjalic.W. Lu and W. Guo are with the Capital University of Economics and Busi-
ness, Beijing 100070, China (e-mail: [email protected]; [email protected]).J. Li and T. Li are with Florida International University, Miami, FL 33199
USA (e-mail: [email protected]; [email protected]).H. Zhang and J. Guo are with Beijing University of Posts and Telecommuni-
cations, Beijing 100876, China (e-mail: [email protected]; [email protected]).Color versions of one or more of the figures in this paper are available online
at http://ieeexplore.ieee.org.Digital Object Identifier 10.1109/TMM.2013.2280895
Fig. 1. Example web images and their corresponding textual descriptions. Eachrow represents a class, i.e.,, a topic-related event.
databases, browsing and searching web multimedia objects,multimedia information delivery and discovering interestingpatterns from objects [1]. Given a collection of web imageswith the corresponding textual descriptions, as shown in Fig. 1,where the auxiliary textual information is often provided byweb users to describe the general contents of images (i.e.,,image titles, headers and tags), a challenging question is howto perform classification tasks by leveraging both the imagefeatures and the textual information.As we all know, classic supervised learning algorithms for
classification aim at training suitable classifiers using labeleddata samples. However, although the textual information isoften provided by web users for dramatically increased multi-media objects, true labels of web images for classification areusually difficult and expensive to obtain. Moreover, the testingdata may not follow the same class labels or generative distri-butions as the labeled training data. The above two limitationscould be addressed by taking the learning process into consid-eration. In the process of the human learning, besides learningthe samples from new learning task, we usually apply ourknowledge and experiences obtained in the previous learningprocesses to facilitate the new learning task. This principle isalso applicable in machine learning process. For example, itmight be easier for a robot to recognize “Toyota sedan” quicklyif it has already known how to identify “Ford SUV” and “Benzsedan”; previous experiences in playing violin might providesome guidance to learn playing piano and sachs. Therefore,
1520-9210 © 2013 IEEE

LU et al.: WEB MULTIMEDIA OBJECT CLASSIFICATION USING CROSS-DOMAIN CORRELATION KNOWLEDGE 1921
Fig. 2. An example of visual phrase.
we could explore the feasibility of using some knowledgeas a “guidance” for web multimedia objects classification bytransfer learning methods.
B. Content of the Paper
Inspired by the above observation, in this paper, we proposea cross-domain transfer learning method for utilizing webmultimedia objects without true labels in performing su-pervised classification tasks. Such objects without true labelsare relatively easier to obtain from web, and could be used toextract knowledge through the unsupervised learning. Differentfrom the previously proposed multi-view learning methods[2]–[4] which process each information source separately andthen combine them together at either feature level, semanticlevel, or kernel level, we focus on the cross-domain knowledgetransfer where we first discover the correlation knowledge be-tween different domains (i.e.,, text domain and image domain)and then apply it to classification. In particular, in order todiscover the correlation knowledge, we consider the semanticcorrelation among the attributes of the data concepts and aimat finding out the “correlation” between the images and theircorresponding textual descriptions at the semantic level. Inthis case, for the text, the textual words with specific meanings(e.g.,, house, water, face, etc.) are good choices to representvarious textual descriptions of images. For the image, it isoriginally modeled as a bag of visual words, which containsvery limited semantic information because each region/patchrepresented by a visual word might come from different partsof the object. For example, as shown in Fig. 2, an individualcannot distinguish the American flag from the striped shirtand the Adidas sport shoes from visual word A, as they sharevisually-similar red-white stripes. However, the combination ofvisual word A and B, i.e.,, the visual phrase AB, can effectivelydistinguish the American flag from the other two. (Here, thedefinition of “phrase” is similar with the definition of that in[5]–[7]). Therefore, we incidentally propose a novel imagerepresentation model named bag-of-visual-phrases (BoP) torepresent images in a more meaningful and effective way.Specifically, we firstly obtain visual words via the hierarchicalclustering, and generate visual phrases by discovering thespatial co-location patterns of visual words, then add thesegenerated phrases into the vocabulary. In this way, the spatialand semantic distinguishing power of image features can beenhanced.Given the enriched visual vocabulary as well as the textual
words, we calculate the frequently co-occurring pairs amongthem to construct a cross-domain correlated graph in which thecorrelation knowledge, i.e.,, a set of strongly correlated groups(e.g.,, the collapsed buildings in image patches as well as the
textual words “house” and “damaged” in Fig. 11), is mined bya backtracking algorithm [8]. After that, in order to evaluateour proposed cross-domain learning method, we investigate twodifferent strategies (Enlarging Strategy and Enriching Strategy)to apply the correlation knowledge to enrich the feature spacefor classification.Our method can be viewed as a form of transfer learning [9],
[10], because the discovered cross-domain correlation knowl-edge provides “guidance” to learning tasks which can be facili-tated especially when the size of available labeled training sam-ples is not large enough.
C. Paper Contribution and Organization
In summary, the contribution of this paper is four-fold:• An unsupervised learning method for discoveringcross-domain correlation knowledge: We propose anovel cross-domain method to first discover the correlationknowledge between different domains via unsupervisedlearning on unlabeled data from multiple feature spaces,and then apply it to perform supervised classificationtasks. Empirical experiments demonstrate our proposedmethod outperforms the three existing multi-view learningmethods mentioned in Section II.
• A novel two-level image representation model: Unlikethe basic bag-of-visual-words (BoW) model, we discoverhigher level visual components (words and phrases) to in-corporate the spatial and semantic information into ourproposed image representation model (i.e.,, bag-of-visual-phrases (BoP)). According to the experimental results inSection V, by combining visual words with phrases, thedistinguishing power of image features is enhanced.
• Two different strategies for correlation knowledge uti-lization:We investigate two different strategies (EnlargingStrategy and Enriching Strategy) to utilize the correlationknowledge to enrich the feature space for classification. Bytransferring such knowledge, both the strategies can handlethe situation when one information source is missing, espe-cially the most common situation that the textual descrip-tions of a small portion of web images are missing.
• A wide variety of new applications: By effectively trans-ferring the cross-domain correlation knowledge to newlearning tasks, our proposed method cannot only be ap-plied in some specific domains (e.g.,, disaster emergencymanagement), but also be used in the general domain(e.g.,, social-media images organization, etc.).
The rest of this paper is organized as follows. Section II re-views some related work. Section III presents the algorithmicdetails of the cross-domain transfer learning method. Section IVdescribes its two novel applications. Section V provides a de-tailed experimental evaluation and analysis. Finally we con-clude the paper in Section VI.
II. RELATED WORK
The previous work related to this paper involves the fol-lowing three aspects:
A. Learning From Multiple Information Sources
In many real-world applications, the data is naturallymulti-modal, in the sense that they are represented by multiple

1922 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 15, NO. 8, DECEMBER 2013
sets of features. Therefore, many research publications [2]–[4]aim at designing multi-view learning algorithms to learn classi-fiers from multiple information sources via integrating differenttypes of features together to perform classification. Besidesclassification, multi-view learning algorithms are also exploitedand applied in the field of multimedia retrieval and automaticimage annotation [11], [12].In general, multi-view learning methods can be categorized
into three different groups:1) Feature Integration: Enlarge the feature representation to
incorporate all attributes from different sources and produce aunified feature space. The advantage of feature integration isthat the unified feature representation is often more informa-tive and also allows many different data mining methods to beapplied and systematically compared. One disadvantage is theincreased learning complexity and difficulty as the data dimen-sion becomes large [2].2) Semantic Integration: Keep data intact in their original
form and computational methods are applied to each featurespace separately. Results on different feature spaces are thencombined by either voting [13], Bayesian averaging [14], or thehierarchical expert system approach [15]. One advantage of se-mantic integration is that it can implicitly learn the correlationstructure between different sets of features [4].3) Kernel Integration: A compromise between the feature
integration and the semantic integration. The idea is to keepthe feature spaces in their original forms and integrate them atthe similarity computation or the Kernel level [16]. Differentweights can be applied to different data sources.Different from the above three groups of methods which
firstly process each information source separately and thencombine them together at different levels, our method firstlydiscover the semantic correlation between different sources asknowledge and then apply it to facilitate new learning tasks.
B. Learning With Knowledge Transfer
In recent years, some works have been reported on in-corporating the prior knowledge and experience for betterlearning new tasks [9], [10], [17], or learning across differentfeature spaces by using data from one feature space to enhancethe learning tasks of other feature spaces [18]–[20]. In thesemethods, the prior knowledge and experience obtained from thesource data can provide “guidance” to perform new learningtask on target data such that the learning can be facilitatedespecially when the size of available labeled training samplesis not large enough.Different from the transfer learning [9], the knowledge ex-
traction of our method is done through unsupervised learning.From this point of view, our method is closer to the self-taughtlearning [10] and the knowledge transfer [17]. However, theknowledge extraction and utilization of our method is far dif-ferent from those in [10]. And compared with [17], our methodis a cross-domain learning approach involving both the imageand the text, while [17] deals with the textual informationonly. Moreover, in order to extract more meaningful correla-tion knowledge, we identify the correlated pairs at both theword-level and phrase-level rather than the single word-level
as in [17]. By doing this, the semantic distinguishing power ofthe correlated groups can be enhanced greatly. In addition, ourmethod differs from heterogeneous transfer learning [18], trans-lated learning [19] and SocialTransfer [20] in that the semanticcorrelation between different domains is discovered by usingunlabeled data through unsupervised learning from multiplefeature spaces and then applied such correlation knowledge tofacilitate the classification, but not from one feature space toanother feature space.
C. Image Representation Model
Existing methods for image representation can be roughlycategorized into two groups: global representation and localrepresentation. Compared with the global features (e.g.,, color,texture, edge, etc.), most of the local features are invariantto the scale, rotation, translation, affine transformation, andillumination changes [21]. Since the total number of localfeatures varies in different images, the BoW model [22], [23] isadopted to represent local features of images, and then performclassification.However, drawbacks of the BoW model mainly lie in its ig-
noring the spatial formation and lacking of semantic relation-ships (e.g.,, polysemy and synonymy). To overcome the firstdrawback, some research efforts have been reported on eitherusing the regular grid [22], spatial pyramid matching [24], orverifying geometric relationships after matching [25]; To dealwith the second drawback, some research publications in recentyears aim at designing higher-level visual representations to ex-plore the semantic relationship between visual words by fre-quent adjacent patches pairs [5], frequently co-occurring pattern[6], minimal support region [7], or defined meaningful phrases[26]. However, relatively few research efforts are made to si-multaneously and effectively address both of the above twodrawbacks as well as the background clutter problem. In thispaper, all of the above three problems can be well addressed viaour proposed BoP model.
III. CROSS-DOMAIN TRANSFER LEARNING
A. Framework Overview
Fig. 3 presents a brief framework of cross-domain transferlearning method, which is composed of three major compo-nents, i.e.,, BoP model, correlation knowledge extraction andits utilization in classification. These three components will bedescribed in the following three subsections respectively.
B. The Bag-of-Visual-Phrases (BoP) Model
1) Overview: In this section, we focus on building a novelmodel to represent images at both the word-level and thephrase-level to improve the performance of the basic BoWmodel. Fig. 4 shows the flowchart of our proposed BoP model.2) Hierarchical Clustering: In the basic BoW model,
after local feature extraction and patch/region description, theK-means clustering is applied to generate the visual wordsvocabulary. Here, all the keypoints extracted from trainingimages are grouped in a mutually exclusive fashion so that if acertain keypoint belongs to a specific cluster then it could not

LU et al.: WEB MULTIMEDIA OBJECT CLASSIFICATION USING CROSS-DOMAIN CORRELATION KNOWLEDGE 1923
Fig. 3. Framework of our proposed cross-domain transfer learning method.
Fig. 4. The flowchart of the proposed BoP model.
be assigned to another cluster. However, in the original image,each keypoint represents a certain patch/region in the originalimage, and these patches/regions represented by each keypointare often overlapped with each other or being contained inother patches/regions. Consequently, it is natural to use thehierarchical clustering to explore the semantic relationshipsamong visual words. In this paper, we group local featurekeypoints with the unsupervised agglomerative hierarchicalclustering algorithm [27] to generate the vocabulary tree inwhich each visual word acts as a node.
Fig. 5. An example of generating the vocabulary tree using the agglomerativehierarchical clustering algorithm.
Fig. 6. An illustration of discovering spatial co-location patterns of visualwords to generate visual phrases.
For example, in Fig. 5, the intersection of visual words “eye”,“nose” and “mouth” in K-means algorithm is zero; however, allthree words together could represent a more general semanticconcept (“face”) in the hierarchical vocabulary tree.Notice that, once no visual word in the testing image is clas-
sified as the visual word represented by a node at level , thereis no need to calculate the similarity between this testing visualword and all the other visual words in the same branch of thenode. Therefore, representing images using this kind of hierar-chical structure is more efficient in classification.3) Spatial Co-Location: The basic BoW model regards an
image as a set of inter-independent visual words, i.e.,, it assumesthat the occurrences of visual words in the image are indepen-dent. However, the hypothesis is not reasonable because somevisual words often appear together. Following this observation,we discover the co-location patterns to identify the subsets offeatures frequently located together.As shown in Fig. 6, we first scan all training images with a
sub-window to obtain the frequent visual word pairs(i.e.,, the frequency of their co-occurrences in a sub-windowexceeds a certain threshold). Notice that in this step, we onlyconsider the location information among visual words, nottheir semantic information. If the window is too small, lotsof co-location information might be lost; if the window istoo large, too much irrelevant information (e.g.,, background)would be involved and the accuracy of the co-location patterns

1924 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 15, NO. 8, DECEMBER 2013
cannot be guaranteed. In this paper, we choose the suitable sizeof the sliding sub-window according to the experiments.Notice that unlike words in text, there is no syntax informa-
tion for these visual words. Therefore, given a window withvisual words, it can be transformed into word pairs.
For example, if there are three visual words in thewindow, they can be converted into three word pairs, ,
and . Each visual word pair can be considered asa 2-itemset, but only the word pair whose frequency is higherthan the given threshold can be defined as a 2-word visualphrase.Finally, as shown in Fig. 4, the vocabulary is enriched by
these generated visual phrases which are acting as the generalvisual words in the basic BoW model. Therefore, the featurevector of an image is formed by first concatenating the his-tograms of visual words and phrases, and then performing Prin-cipal Component Analysis (PCA) on it.Obviously, the spatial and semantic distinguishing power of
image features can be enhanced via our proposed BoP model.In addition, parts of background information can be filtered.Generally speaking, objects in the same category are usuallysimilar to each other while their backgrounds often differ fromeach other. Hence, the counts of the word pairs representingobjects will be summed up and thus will be large, while thoserepresenting backgrounds will be much smaller. By specifyinga proper sliding window and a suitable frequency thresholdfor the word pairs, the frequent object-related phrases willbe maintained while parts of the infrequent background-re-lated word pairs will be excluded successfully. Therefore, ourmethod is capable of handling the background clutter problemeffectively.
C. Correlation Knowledge Extraction
Given a collection of web multimedia objects, i.e., imagesand their corresponding textual descriptions, in order to dis-cover the correlation knowledge, both image and text are repre-sented by corresponding data sources respectively. Specifically,for text, we extract features from textual descriptions assignedto the corresponding images via MALLET [28] and the tf-idfschema; For image, we adopt the classic SIFT (Scale InvariantFeature Transform) feature [21] and our BoP model together torepresent each image as a bag of visual words/phrases (i.e.,, vi-sual components), each of which describes a patch/region of theoriginal image. After that each multimedia object is representedby both visual components and textual words. Finally, we usecorrelation mining techniques to obtain the correlation knowl-edge, i.e.,, a collection of strongly correlated groups of visualcomponents and textual words.A pair of visual component and textual word is said to be
correlated if they frequently co-occur in the image and thecorresponding text. The procedure of the “visual textual”correlation knowledge extraction is described in Algorithm 1.Since the Union and Intersection of two sorted arraysand are sorted before. Assuming the size of is ,and the size of is are the most time consuming op-erations in Algorithm 1, the time complexity of this algorithmis .
Fig. 7. An illustration of finding k-Cliques in the cross-domain correlatedgraph. The highlighted parts represent two k-Cliques.
Algorithm 1 Correlation Knowledge Extraction
Input : the set of objects that contain the visualcomponent ; : the set of objects that contain thetextual word ; : a pre-defined threshold; : the sizeof the set
1 ;
2 ;
3If then
4the visual component and the textual word arecorrelated;
5return correlation ;
6end
Notice that the similar procedure could be applied toobtain the “visual visual” and “textual textual” corre-lations. Then a set of visual components and textual words
is said to be stronglycorrelated iff every pair , or , or inis correlated.In our method, to generate correlated groups, we construct
an undirected correlated graph where each node represents a vi-sual component or a textual word after identifying all the cor-related pairs, and each edge between any two nodes representsthese two nodes are correlated according to Algorithm 1. Thenwe use the backtracking algorithm [8] to find k-Cliques in thegraph , as shown in Fig. 7. Here, a clique is a maximalcomplete subgraph of three or more nodes which are also ad-jacent to all the other members of the clique. Each correlatedgroup of visual components and textual words, marked as ,is regarded as a concept with specific semantic meaning.
D. Feature Generation and Classification
The discovered correlation knowledge can be used to enrichthe feature space for classification. With such enrichment, thefeature space for web multimedia objects includes both the ac-tual components/words contained in objects and the collectionof the correlated groups.

LU et al.: WEB MULTIMEDIA OBJECT CLASSIFICATION USING CROSS-DOMAIN CORRELATION KNOWLEDGE 1925
Given a new multimedia object for classification,it can be represented as an (m+n)-dimension vector:
where andrepresent the number of visual components and textual wordsrespectively, is the number of occurrence of the j-th visual
component in i-th object , and is the number of occur-rence of the j-th textual word in . For each correlated group, we define a feature mapping value: ,
i.e., the ratio of the number of components/words shared byand to the number of components/words in . In other
words, the value of could reflect the proportion that thei-th object contains how many (not necessarily all) wordsin the correlated group . Then we investigate the followingtwo strategies to generate features for unseen data.1) Enlarging Strategy: This strategy is to insert a -di-
mension vector whose elements are the feature mappingvalue of each into the original feature vector[17], and then form an vector:
where is the total number of generated correlated groups.2) Enriching Strategy: This strategy is to enrich the original
feature space via replenishing components/words that actuallydo not appear in the object into the original feature vector.Specifically, for a certain correlated group , once the valueof is greater than a pre-defined threshold , we firstlycalculate the mean value of the number of occurrenceof the components/words shared by and (i.e.,, compo-nents/words in ), and then assign it to the remainingcomponents/words (i.e.,, components/words in )in the original feature vector. After processing all the correlatedgroups, the resulting vector is still of :
where the original values of in the above feature vector areall zeros since they actually do not appear in the object.In both of the strategies, an object may involve a concept with
specific semantic meaning if it contains some (not necessary all)of the components in the corresponding correlated group. There-fore, both the strategies can handle the situation when one in-formation source is missing. However, the first strategy enlargesthe feature dimension by simply concatenating two vectors to-gether, while the second one explores the semantic informationhidden in the correlation knowledge and consequently rendersthe features more informative.
IV. APPLICATIONS
Based on the aforementioned algorithms, the proposed cross-domain transfer learning method can be utilized for many realworld applications. In this section, we present two typical ap-plications, both of which are difficult to be realized purely bytraditional multimedia techniques.
A. Disaster Emergency Management
Disasters such as hurricanes and earthquakes cause immensedamages in terms of physical destruction, loss of life and prop-erty around the world. In order to reduce such loss, emergencymanagers are required to not only be well prepared but also pro-vide rapid response activities [29].
In recent years, with the proliferation of smart devices, dis-aster responders and community residents are capturing footage,pictures and video of the disaster area with mobile phones andwireless tablets. Therefore, a system that can effectively inte-grate multiple information sources would greatly assist emer-gency managers in making a better assessment of a disastersituation and performing efficient and timely responses corre-spondingly. Our method can be potentially applied to disasteremergency management by effectively transferring the cross-domain correlation knowledge to disaster-related multimediaobjects classification.In order to show the capability of our method in incorporating
multiple information sources to assist emergency management,we crawled a disaster-related multimedia objects dataset fromCNN News,1 including colored web images and their corre-sponding textual descriptions about “the aftermath of disasters”.As is shown in Fig. 1, the dataset CNN News has several char-acteristics: 1) images in the same category may be differentlyvisually but quite similar in terms of semantic concepts; 2) someimages focus on the whole event whereas the others reflect onlyone single aspect of the whole event; and 3) the correspondingtextual descriptions are usually composed of several paragraphs,instead of the textual tags, which is more challenging.
B. Social-Media Images Organization
Social media platforms, such as Facebook,2 Twitter,3
LinkedIn,4 Google+,5 etc., play an increasingly important rolenowadays. As a social image hosting and video hosting website,Flickr6 is home to over eight billion of the world’s photos. Howto efficiently organize these images and videos to satisfy theneeds of quick search of web users in such huge multimediadatabases is becoming an urgent problem.In this paper, we focus on the organization of social-media
images and use a Flickr image dataset as an example. Sinceclassification is a crucial step of image retrieval and indexing,meanwhile, social media users assign text descriptions to theimages, a possible solution to the multimedia data organizationis to take both textual information and image information intoconsideration to design an effective multimedia object classifi-cation method. However, sometimes users might be interestedin images related to the weakly-defined textual topics [30]. Asshown in Fig. 8, the textual descriptions (i.e.,, in the form of tex-tual tags posted by individuals), which are provided to describethe general content of Flickr images, are sometimes ambiguous:the tag “pottedplant” might indicate that the image contains aflower of a pottedplant, a plant of a pottedplant, a pot of a pot-tedplant, a fertilizer for a pottedplant, a pot rack for displayingpottedplants, rather than a pottedplant itself. Considering theabove requirements posted by social media users, and the ca-pability of our proposed cross-domain transfer learning methodin efficiently combining the textual and image information forclassification, it can be potentially applied to social-media im-ages organization.
1http://www.cnn.com/2https://www.facebook.com3https://twitter.com/4http://www.linkedin.com/5https://plus.google.com/6http://www.flickr.com/

1926 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 15, NO. 8, DECEMBER 2013
Fig. 8. Example images and their partial corresponding textual descriptions ofthe Flickr.
V. EXPERIMENTAL EVALUATION
In this section, our experiments are divided into the fol-lowing three parts. Firstly, we introduce two different datasetsof web multimedia objects used in our experiments. Secondly,we simply introduce the experimental tools and evaluationmeasures. Finally, in order to demonstrate the efficacy andeffectiveness of our proposed BoP model and the cross-domaintransfer learning method, we report a detailed experimentalcomparison among our proposed model/method and thedifferent existing methods for web image categorization men-tioned in Section II.
A. Real World Datasets
To the best of our knowledge, there is almost no specifiedstandard test set for webmultimedia object classification. There-fore, two different types of real-world datasets of web multi-media objects are used in our experiments.CNN News (355 objects, 4 topics, 76.9 MB SIFT descrip-
tors): For this dataset, we manually collected 355 colored webimages and their corresponding textual descriptions about “theaftermath of disasters” from CNN News, which include 4 dif-ferent topics: “building collapsing”, “flood”, “oil spilling”, and“animal death”, as shown in Fig. 1. Each topic includes 101,101, 53 and 100 objects respectively, and it is split into twoparts: 176 objects (50, 50, 26, 50 from four topics respectively)are randomly selected for knowledge extraction and the rest 179objects are taken as classification data, where 91 objects are ran-domly selected for training and the rest 88 objects are taken asthe test data.Flickr (67,634 objects, 19 categories, 14.4 GB SIFT descrip-
tors): This dataset consists of 67,634 web images along withtheir corresponding textual descriptions from a public imagedataset obtained from Flickr [30] (see Fig. 8 for some exam-ples). The entire dataset includes 19 different categories (seeFig. 13). We split objects in each category into two parts, thus33,818 objects are randomly selected for the knowledge extrac-tion and the rest 33,816 objects are taken as the classificationdata, in which about 50% objects (16,909 in total) are randomlyselected for training and the rest 50% objects (16,907 in total)are taken as the test data.
B. Experimental Tools and Evaluation Measures
Vocabulary Building Tools: As we mentioned before, weadopt the hierarchical clustering to build the vocabulary. To deal
Fig. 9. Comparisons on the categorization accuracy of different vocabularysizes, and different methods for image representation. (a) Different VocabularySizes (b) Different Methods.
with the dataset—Flickr, which contains 14.4 GB SIFT descrip-tors, we use the well-accepted open source Map-Reduce [31]framework by Apache—Hadoop.7
Classification Tools: In our experiment, LIBSVM [32] is uti-lized as the base classification tool. The parameter tuning is donevia k-fold cross validation.Evaluation Measures: Due to the randomness of selecting
objects for learning and classification, we run all the experi-ments 10 trials, and take the average classification accuracy asthe performance measure in our experiments.
C. Experimental Results
1) BoP Model: As we all know, one of the key parameters ofthe BoW model is the size of vocabulary, which directly im-pacts its performance. Therefore, we use 6 different vocabu-lary sizes and compare the classification accuracy of 6 differentmethods, some of which are mentioned in [23]. Specifically,these methods in our experiments include: (1) K-means + BoW,i.e.,, the basic BoW model; (2) K-means + Phrase Only; (3)K-means + BoP, i.e.,, representing images by both visual wordsand phrases; (4) K-means + BoP + PCA, i.e.,, performing PCAto reduce the dimensions of the integrated features in method(3); (5) Hierarchical + BoP, i.e.,, using the hierarchical clus-tering instead of K-means in method (3); (6) our proposed BoPmodel, i.e.,, performing PCA on the features in method (5).Here, we cut the vocabulary tree generated from the hierarchicalclustering at the layer which has the same vocabulary size withK-means for comparison.As shown in Fig. 9(a), the basic BoW model achieves the
best performance when the vocabulary size is 300 (CNNNews) and 500 (Flickr) respectively, which illustrates that sizes300 and 500 are the optimal clustering size of our training
7http://hadoop.apache.org/

LU et al.: WEB MULTIMEDIA OBJECT CLASSIFICATION USING CROSS-DOMAIN CORRELATION KNOWLEDGE 1927
Fig. 10. Comparison on classification accuracy of 4 different sizes and movingsteps of the sliding sub-window. Here, represents the window size isset to and the window moves pixels each time.
datasets respectively. And from the results in Fig. 9(b), wehave the following observations: Firstly, the best results ofobject classification using single visual information (method(1) and (2)) are relatively low. However, once we representimages with both visual words and visual phrases, the ac-curacy can be improved. It shows that by combining visualwords with phrases, the distinguishing power of image featuresis enhanced. Secondly, method (5) outperforms method (3)and our proposed BoP model outperforms method (4). TheBoP model achieves the best performance with the accuracy65.9091% on CNNNews and 46.0224% on Flickr. It shows thatreplacing K-means with the hierarchical clustering providesmore semantic relationships between visual words into method(5) and (6). Thirdly, compared with method (5), the accuracyof BoP model increases about . Our proposed BoPmodel can outperform method (5) because PCA could get rid ofsome noise information which helps improve the performance.Similarly, method (4) outperforms method (3).Another two parameters in our proposed BoP model are the
frequency threshold of words pairs and the size of the slidingsub-window. In this paper, we mainly focus on demonstratingthe usefulness of phrases and the best way of identifying the firstparameter will be our future work. Based on the experimentalevaluation, the minimum support threshold of words pairs is 0.2on CNN News and 0.1 on Flickr respectively. The second pa-rameter defines the spatial neighborhoods to be involved whilemining visual phrases. Taking the average size of images intoaccount, we adopt the following 5 sizes and moving steps ofthe sliding sub-window. Here, in Fig. 10, using the above min-imum support thresholds, we present the classification accuracyof different sliding sub-windows ( indicates that thewindow size is set to and the window moves pixels eachtime). From the diagram, we observe that with the sizeand of sliding sub-window respectively, we obtain thebest classification accuracy on the two datasets. The reason forthe overall trend of each diagram rising first and then decliningis straightforward: using too small window size will omit somespatial co-location information, while using too large windowsize might involve inaccurate co-location information whichwould lead to relatively low accuracy.2) Correlation Knowledge Based Classification: The results
can be divided into the following two parts:Correlation Knowledge Extraction: There is a pre-defined
threshold when discovering the correlation knowledge. Ac-cording to the observation in our experiments, the higher thevalue is, the fewer the correlated pairs we can obtain. For the
Fig. 11. Examples of the correlated groups on CNN News.
Fig. 12. The confusion tables of accuracy of 4 topics under different for CNNNews. (a) . (b) . (c) .
dataset CNN News, based on experimental evaluation, the cor-related groups are generated with a threshold . Fig. 11shows some example results of the correlated groups obtainedin our mining process,8 where each row represents a correlatedgroup. From the results, we observe that each correlated groupof visual components and textual words can be regarded as aconcept with specific semantic meaning.Feature Generation and Classification: An important pa-
rameter of the Enriching Strategy is the pre-defined threshold. If is always the same for all object categories, it may notbe robust enough for classification due to the various of ob-ject categories. Therefore, We further compare the classificationperformance on each category under different thresholds . Theconfusion tables of accuracy under different for datasets CNNNews and Flickr are shown in Figs. 12 and 13. Here, each blackpart represents the best classification performance. From the re-sults, we observe that: (1) Our proposed correlation knowledgebased classification method achieves its best performance ontwo datasets when is 0.8 and 0.9 respectively; (2) In Fig. 12(b),the topic 1 and 3 achieve best results when is 0.8, whereas inFigs. 12(c) and 12(a), topic 2 and 4 obtains its best performancewhen is 0.9 and 0.7 respectively. And the similar observationscould be obtained in Fig. 13.Finally, we compare our proposed two correlation knowledge
based classification methods with the base line classificationmethods without using such knowledge. The experimental re-sults using different information sources are shown in Table I.From the results, we have the following observations: (1) theclassification results are significantly improved using the cor-relation knowledge; and (2) the Enriching Strategy beats theEnlarging Strategy for the reason that the Enriching Strategycould benefit from the semantic information hidden in the knowl-edge and consequently renders the features more informative
8Due to the space limit, we only present part of the experimental results ob-tained on CNN News here. Similar results can be obtained on Flickr.
1928 IEEE TRANSACTIONS ON MULTIMEDIA, VOL. 15, NO. 8, DECEMBER 2013
Fig. 13. The confusion tables of accuracy of 19 categories under different forFlickr. (a) . (b) . (c) .
TABLE ICOMPARISON OF CLASSIFICATION ACCURACY THE RESULTS WITH ARE
SIGNIFICANTLY BETTER THAN THE OTHERS (UNDER ), AND THERESULTS OF ENRICHING STRATEGY SHOWN HERE ARE THE BEST ACCURACY
ON TWO DATASETS WHEN IS 0.8 AND 0.9 RESPECTIVELY
whereas the first strategy only makes use of raw knowledge in-formation.3) Cross-Domain Transfer Learning: For further compar-
ison, we firstly implement three existing multi-view learningmethods for classification mentioned in the first part ofSection II, and then compare their classification performance
Fig. 14. Comparison among different multi-view methods. The results of En-riching Strategy shown here are the best accuracy on two datasets when is 0.8and 0.9 respectively.
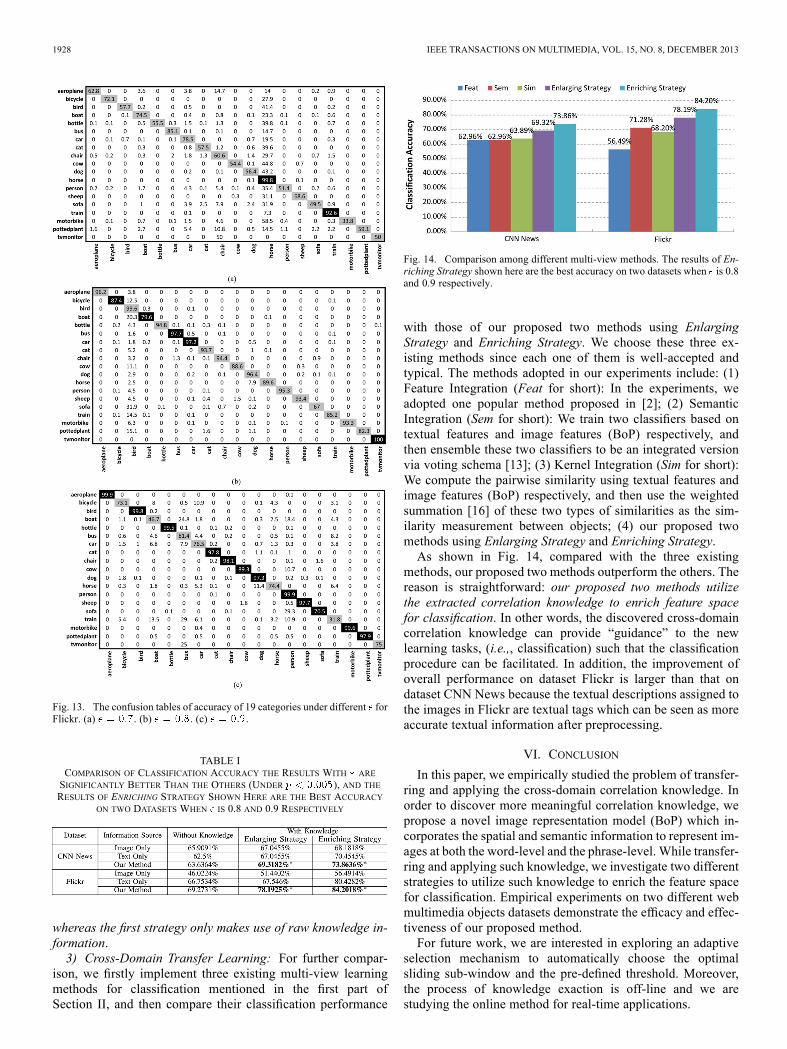
with those of our proposed two methods using EnlargingStrategy and Enriching Strategy. We choose these three ex-isting methods since each one of them is well-accepted andtypical. The methods adopted in our experiments include: (1)Feature Integration (Feat for short): In the experiments, weadopted one popular method proposed in [2]; (2) SemanticIntegration (Sem for short): We train two classifiers based ontextual features and image features (BoP) respectively, andthen ensemble these two classifiers to be an integrated versionvia voting schema [13]; (3) Kernel Integration (Sim for short):We compute the pairwise similarity using textual features andimage features (BoP) respectively, and then use the weightedsummation [16] of these two types of similarities as the sim-ilarity measurement between objects; (4) our proposed twomethods using Enlarging Strategy and Enriching Strategy.As shown in Fig. 14, compared with the three existing
methods, our proposed two methods outperform the others. Thereason is straightforward: our proposed two methods utilizethe extracted correlation knowledge to enrich feature spacefor classification. In other words, the discovered cross-domaincorrelation knowledge can provide “guidance” to the newlearning tasks, (i.e.,, classification) such that the classificationprocedure can be facilitated. In addition, the improvement ofoverall performance on dataset Flickr is larger than that ondataset CNN News because the textual descriptions assigned tothe images in Flickr are textual tags which can be seen as moreaccurate textual information after preprocessing.
VI. CONCLUSION
In this paper, we empirically studied the problem of transfer-ring and applying the cross-domain correlation knowledge. Inorder to discover more meaningful correlation knowledge, wepropose a novel image representation model (BoP) which in-corporates the spatial and semantic information to represent im-ages at both the word-level and the phrase-level. While transfer-ring and applying such knowledge, we investigate two differentstrategies to utilize such knowledge to enrich the feature spacefor classification. Empirical experiments on two different webmultimedia objects datasets demonstrate the efficacy and effec-tiveness of our proposed method.For future work, we are interested in exploring an adaptive
selection mechanism to automatically choose the optimalsliding sub-window and the pre-defined threshold. Moreover,the process of knowledge exaction is off-line and we arestudying the online method for real-time applications.

LU et al.: WEB MULTIMEDIA OBJECT CLASSIFICATION USING CROSS-DOMAIN CORRELATION KNOWLEDGE 1929
REFERENCES[1] Z. Yin, R. Li, Q. Mei, and J. Han, “Exploring social tagging graph for
web object classification,” in Proc. ACM SIGKDD, 2009, pp. 957–966.[2] L. Wu, S. Oviatt, and P. Cohen, “Multimodal integration-a statistical
view,” IEEE Trans. Multimedia, vol. 1, no. 4, pp. 334–341, 1999.[3] Y. Wu, E. Chang, K. Chang, and J. Smith, “Optimal multimodal fusion
for multimedia data analysis,” in Proc. ACM Multimedia, 2004, pp.572–579.
[4] T. Li and M. Ogihara, “Semisupervised learning from different infor-mation sources,” Knowl. Inf. Syst., vol. 7, no. 3, pp. 289–309, 2005.
[5] Q. Zheng, W. Wang, andW. Gao, “Effective and efficient object-basedimage retrieval using visual phrases,” in Proc. ACMMultimedia, 2006,pp. 77–80.
[6] S. Zhang, Q. Tian, G. Hua, Q. Huang, and S. Li, “Descriptive visualwords and visual phrases for image applications,” in Proc. ACM Mul-timedia, 2009, pp. 75–84.
[7] Y. Zheng, M. Zhao, S. Neo, T. Chua, and Q. Tian, “Visual synset:Towards a higher-level visual representation,” in Proc. IEEE CVPR,2008, pp. 1–8.
[8] C. Bron and J. Kerbosch, “Algorithm 457: Finding all cliques of anundirected graph,” ACM.
[9] R. Raina, A. Ng, and D. Koller, “Constructing informative priors usingtransfer learning,” in Proc. ICML, 2006, pp. 713–720.
[10] R. Raina, A. Battle, H. Lee, B. Packer, and A. Ng, “Self-taughtlearning: Transfer learning from unlabeled data,” in Proc. ICML,2007, pp. 759–766.
[11] H. Li, J. Tang, G. Li, and T. Chua, “Word2image: Towards visual in-terpreting of words,” in Proc. ACM Multimedia, 2008, pp. 813–816.
[12] J. Hare and P. Lewis, “Automatically annotating the mir flickr dataset,”in Proc. Multimedia Information Retrieval, 2010.
[13] R. Carter, I. Dubchak, and S. Holbrook, “A computational approach toidentify genes for functional RNAS in genomic sequences,” NucleicAcids Res., vol. 29, no. 19, p. 3928, 2001.
[14] C. Bishop, Pattern Recognition and Machine Learning. New York,NY, USA: Springer, 2006.
[15] M. Jordan and R. Jacobs, “Hierarchical mixtures of experts and the EMalgorithm,” Neural Computat., vol. 6, no. 2, pp. 181–214, 1994.
[16] B. Schölkopf and A. Smola, Learning With Kernels: Support VectorMachines, Regularization, Optimization, and Beyond. Cambridge,MA, USA: MIT Press, 2002.
[17] J. Zhang and S. Shakya, “Knowledge transfer for feature generation indocument classification,” in Proc. ICMLA, 2009, pp. 255–260.
[18] Y. Zhu, Y. Chen, Z. Lu, S. Pan, G. Xue, Y. Yu, and Q. Yang, “Heteroge-neous transfer learning for image classification,” inProc. AAAI, 2011.
[19] W. Dai, Y. Chen, G. Xue, Q. Yang, and Y. Yu, “Translated learning:Transfer learning across different feature spaces,” in Proc. NIPS 2008,2008, pp. 353–360.
[20] S. Roy, T. Mei, W. Zeng, and S. Li, “Socialtransfer: Cross-domaintransfer learning from social streams for media applications,” in Proc.ACM Multimedia, 2012, pp. 649–658.
[21] D. Lowe, “Distinctive image features from scale-invariant keypoints,”Int. J. Comput. Vision, vol. 60, no. 2, pp. 91–110, 2004.
[22] L. Fei-Fei, Visual Recognition: Computational Models and HumanPsychophysics, California Institute of Technology, 2005.
[23] T. Tuytelaars, C. Lampert, M. Blaschko, and W. Buntine, “Unsuper-vised object discovery: A comparison,” Int. J. Comput. Vision, vol. 88,no. 2, pp. 284–302, 2010.
[24] S. Lazebnik, C. Schmid, and J. Ponce, “Beyond bags of features: Spa-tial pyramid matching for recognizing natural scene categories,” inProc. IEEE CVPR, 2006, vol. 2, pp. 2169–2178.
[25] K. Palander and S. Brandt, “Epipolar geometry and log-polar transformin wide baseline stereo matching,” in Proc. IEEE ICPR, 2009, pp. 1–4.
[26] M. Sadeghi and A. Farhadi, “Recognition using visual phrases,” inProc. IEEE CVPR, 2011, pp. 1745–1752.
[27] J. Han and M. Kamber, Data Mining: Concepts and Techniques. SanFrancisco, CA, USA: Morgan Kaufmann, 2006.
[28] A. McCallum, MALLET: A Machine Learning for Language Toolkit,2002.
[29] L. Zheng, C. Shen, L. Tang, T. Li, S. Luis, S. -C. Chen, and V. Hris-tidis, “Using data mining techniques to address critical information ex-change needs in disaster affected public-private networks,” in Proc.ACM SIGKDD, 2010, pp. 125–134.
[30] M. Allan and J. Verbeek, “Ranking user-annotated images for multiplequery terms,” in Proc. British Machine Vision Conf., Sep. 2009.
[31] J. Dean and S. Ghemawat, “Mapreduce: Simplified data processing onlarge clusters,” Commun. ACM, vol. 51, no. 1, pp. 107–113, 2008.
[32] C. Chang and C. Lin, “LIBSVM: A library for support vector ma-chines,”ACMTrans. Intell. Syst. Technol., vol. 2, pp. 27:1–27:27, 2011.
Wenting Lu received the doctor’s degree fromBeijing University of Posts and Telecommunications(BUPT) in 2012. She studied as a visiting Ph.D.student in Florida International University from2010–2012. She is currently a lecturer of CapitalUniversity of Economics and Business (CUEB).Her research interests include information retrieval,multimedia data mining and its applications.
Jingxuan Li is currently pursuing the Ph.D. de-gree in the School of Computing and InformationSciences at Florida International University (FIU),Miami, FL, USA. He has been a research assistantwith the School of Computing and InformationSciences at FIU, since 2009. His research interestsinclude data mining, information retrieval, and thesocial network data analysis.
Tao Li received the Ph.D. degree in computer sci-ence from University of Rochester, Rochester, NY,in 2004. He is currently an Associate Professor withthe School of Computing and Information Sciences,Florida International University, Miami. His researchinterests are data mining, computing system manage-ment, information retrieval, and machine learning.
Weidong Guo is currently a professor and thedirector of the Department of E-commerce, CapitalUniversity of Economics and Business (CUEB). Hisresearch interests include technology innovation andE-commerce.
Honggang Zhang received the BS degree fromShandong University in 1996, and the Master andPhD degree from BUPT in 1999 and 2003 respec-tively. He worked as a visiting scholar in CarnegieMellon University (CMU) from 2007–2008. Heis currently an associate professor and director ofweb search center at BUPT. His research interestsinclude image retrieval, computer vision and patternrecognition.
Jun Guo received B.E. and M.E. degrees fromBUPT, China in 1982 and 1985, respectively, and thePh.D. degree from the Tohuku-Gakuin University,Japan in 1993. At present he is a professor andthe dean of School of Information and Communi-cation Engineering, BUPT. His research interestsinclude pattern recognition, information retrieval,content based information security, and networkmanagement.


















