
14th IFAC (International Federation of Automatic Control) Symposium on System Identification, SYSID...
14
14th IFAC (International Federation 14th IFAC (International Federation of Automatic Control) Symposium on of Automatic Control) Symposium on System Identification, SYSID 2006, System Identification, SYSID 2006, March 29-31 March 29-31 IMPACT OF SYSTEM IDENTIFICATION METHODS IMPACT OF SYSTEM IDENTIFICATION METHODS IN METABOLIC MODELLING AND CONTROL IN METABOLIC MODELLING AND CONTROL Dr. J. Geoffrey Chase Department of Mechanical Engineering Centre for Bio-Engineering University of Canterbury Christchurch, New Zealand
-
Upload
lillian-leonard -
Category
Documents
-
view
214 -
download
0
Transcript of 14th IFAC (International Federation of Automatic Control) Symposium on System Identification, SYSID...

14th IFAC (International Federation of 14th IFAC (International Federation of Automatic Control) Symposium on Automatic Control) Symposium on System Identification, SYSID 2006, System Identification, SYSID 2006, March 29-31 March 29-31
IMPACT OF SYSTEM IDENTIFICATION IMPACT OF SYSTEM IDENTIFICATION METHODS METHODS
IN METABOLIC MODELLING AND CONTROLIN METABOLIC MODELLING AND CONTROL
Dr. J. Geoffrey ChaseDepartment of Mechanical Engineering
Centre for Bio-EngineeringUniversity of Canterbury
Christchurch, New Zealand

The SituationThe Situation Metabolic modelling can significantly improve the clinical Metabolic modelling can significantly improve the clinical
control of hyperglycaemia with control of hyperglycaemia with model-based protocols model-based protocols (e.g. (e.g. HovorkaHovorka et al. et al., 2004; Chase, 2004; Chase et al. et al., 2005), 2005)
For clinical utility, model parameters must be accurately For clinical utility, model parameters must be accurately identified for real-time prediction of response to identified for real-time prediction of response to intervention intervention
Current identification methods are mostly non-linear and Current identification methods are mostly non-linear and non-convex, and very computationally intensenon-convex, and very computationally intense
With increasing model complexity, parameter trade-off With increasing model complexity, parameter trade-off can result in problematic identification. A typical solution can result in problematic identification. A typical solution is probabilistic population fitting methods is probabilistic population fitting methods (e.g. Vicini and Cobelli, (e.g. Vicini and Cobelli, 2001; Hovorka2001; Hovorka et al. et al., 2004), 2004)
Typical clinical situation might use models and Typical clinical situation might use models and identification methods from different sources with local identification methods from different sources with local cohort/data.cohort/data.

The Problem & The The Problem & The GoalGoal Non-linear and non-convex identification methods and models Non-linear and non-convex identification methods and models
can deliver sub-optimal results, affecting control predictioncan deliver sub-optimal results, affecting control prediction– Clinically, prediction is the only Clinically, prediction is the only truetrue measure of utility measure of utility
What is the What is the clinical impactclinical impact of mixing models and identification of mixing models and identification methods (if any)?methods (if any)?– Currently, model, system ID method and control are all designed Currently, model, system ID method and control are all designed
together. together. – What happens if someone “mix and matches” without the original What happens if someone “mix and matches” without the original
designers insights or experience?designers insights or experience?
This research compares a recently introduced linear, convexThis research compares a recently introduced linear, convex integral-based methodintegral-based method and the commonly used and the commonly used non-linear non-linear recursive least squares (NRLS)recursive least squares (NRLS) identification method identification method – Using an accepted metabolic system model from one source and Using an accepted metabolic system model from one source and
clinical data from another source for “independence”clinical data from another source for “independence”– ““Independence” represents the typical clinical situation and avoids Independence” represents the typical clinical situation and avoids
the models or methods being tuned for the cohortthe models or methods being tuned for the cohort
The The goalgoal is to examine the computational cost and outcomes of is to examine the computational cost and outcomes of these different methods these different methods in a clinical control application in a clinical control application context context

ModelModel The model chosen for comparison is loosely based on the The model chosen for comparison is loosely based on the
2-compt. minimal model (2CMM) first proposed by 2-compt. minimal model (2CMM) first proposed by Caumo & Cobelli (1993)Caumo & Cobelli (1993)– Well documented model that is widely used as a foundationWell documented model that is widely used as a foundation
Main change is the 3 insulin compartments for the Main change is the 3 insulin compartments for the remote effects of insulin on glucose remote effects of insulin on glucose distribution/transport, disposal and EGP introduced by distribution/transport, disposal and EGP introduced by Hovorka et al. (2002)Hovorka et al. (2002)– Similar model has been used clinically for controlSimilar model has been used clinically for control
Comprises 6 compartments in total Comprises 6 compartments in total – 2 glucose compartments 2 glucose compartments gg11(t)(t) and and gg22(t)(t)
– 3 insulin action compartments 3 insulin action compartments QQDD(t)(t), , QQTT(t)(t) and and QQEGPEGP(t)(t)
– 1 plasma insulin compartment 1 plasma insulin compartment I(t)I(t) ))

Integral-Based Parameter Integral-Based Parameter FittingFitting
A “minimal” approach to identification is used with most A “minimal” approach to identification is used with most model constantsmodel constants identified identified a prioria priori from literature results from literature results– Selection of population valued constants is a major issue in biomedical modeling Selection of population valued constants is a major issue in biomedical modeling
as it assumes the parameter is not highly sensitive to resultsas it assumes the parameter is not highly sensitive to results
– This assumption may not be true in all clinical scenarios or cohortsThis assumption may not be true in all clinical scenarios or cohorts
– Required in many cases to ensure the model is identifiable from the available Required in many cases to ensure the model is identifiable from the available datadata
The remaining insulin sensitivities The remaining insulin sensitivities SSI,DI,D,, SSI,T I,T and and SSI,EGPI,EGP are identified as time- are identified as time-
varying varying model parameters model parameters driving the model dynamics driving the model dynamics (details in the paper)(details in the paper)
This approach minimises total computational cost while enabling individual This approach minimises total computational cost while enabling individual model constants to be varied for more optimised prediction and fit model constants to be varied for more optimised prediction and fit (e.g. Hann(e.g. Hann et et
al.al., 2005), 2005)
What is the effect of mixing this approach and this model?What is the effect of mixing this approach and this model?– Would be an “easy” combination for an independent researcherWould be an “easy” combination for an independent researcher
– Will all assumptions on constant parameters hold?Will all assumptions on constant parameters hold?
– Can we identify despite inaccessible, unmeasurable compartments?Can we identify despite inaccessible, unmeasurable compartments?

Integral-Based Parameter Integral-Based Parameter FittingFitting
SSI,DI,D,, SSI,T I,T and and SSI,EGP I,EGP are defined piecewise constant over a time are defined piecewise constant over a time
period of 60mins using Heaviside step functions, period of 60mins using Heaviside step functions, H(t).H(t).
N
iiiijIjI EGPTDttHttHSS
1)1(,,, and , j where))()((
Definition of the distribution of these parameters are arbitrary i.e. Definition of the distribution of these parameters are arbitrary i.e. cubic, quadratic etc.cubic, quadratic etc.– Approach allows constants to define variation and be pulled out of Approach allows constants to define variation and be pulled out of
integralsintegrals
22ndnd order polynomial interpolation is assumed between glucose order polynomial interpolation is assumed between glucose measurements in the accessible glucose compartment measurements in the accessible glucose compartment gg11(t)(t)
– Error using this approximation has been shown to be minimal Error using this approximation has been shown to be minimal (Hann et (Hann et
al., 2005)al., 2005)

Integral-Based Parameter Integral-Based Parameter FittingFitting
Inaccessible glucose compartmentInaccessible glucose compartment gg22(t)(t) modelled using a 2 modelled using a 2ndnd order order
Lagrange polynomial approximation to analytical solution for this Lagrange polynomial approximation to analytical solution for this immeasurable compartment (fortunately, it’s a simple enough immeasurable compartment (fortunately, it’s a simple enough dynamic)dynamic)
Within a time period of [Within a time period of [tt00 t tff ], an arbitrary number of equations can ], an arbitrary number of equations can
be generated by integration of model equations over different time be generated by integration of model equations over different time periodsperiods
The non-linear model thus decomposes into a linear equation The non-linear model thus decomposes into a linear equation system in unknown constants defining parameters to be identified system in unknown constants defining parameters to be identified – Resulting least squares solution is starting point independent and Resulting least squares solution is starting point independent and
convex!convex!
bEGPStgtgtgSA bEGPIfTI T,21202, )( )( )(
dSC DI ,

Clinical DataClinical Data
Patient data (Patient data (nn=7) was chosen from an intensive care unit =7) was chosen from an intensive care unit
hyperglycaemia control trial hyperglycaemia control trial (Chase et al., 2005)(Chase et al., 2005)
Each set of patient data spans 10hrs with glucose Each set of patient data spans 10hrs with glucose
measurements at 0.5hr intervals. measurements at 0.5hr intervals.
– Average glucose levels are ~ 6mmol/L (range ~4-10 mmol/) Average glucose levels are ~ 6mmol/L (range ~4-10 mmol/)
Prediction window is Prediction window is 1hr1hr following hourly clinical interventions following hourly clinical interventions
Median APACHE II = 23, inter-quartile range = 19-25Median APACHE II = 23, inter-quartile range = 19-25

Results: Model FitResults: Model Fit
Model fit errorsModel fit errors
– Patient 2 (highest RMSE Patient 2 (highest RMSE
0.80mmol/l0.80mmol/l, error SD , error SD
0.59mmo/l0.59mmo/l))
– Patient 5 (smallest RMSE Patient 5 (smallest RMSE
0.15mmol/l0.15mmol/l, error SD , error SD
0.08mmol/l0.08mmol/l))
0 100 200 300 400 500 600-2.5
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2
Patient 2
Patient 5
Patient 1,3,4,6,7
Model fit mean absolute percent error (MAPE) for cohort Model fit mean absolute percent error (MAPE) for cohort ranges from 2.4-7.4% which is ranges from 2.4-7.4% which is withinwithin reported sensor error reported sensor error
Residual plot of model fit to patient data

Results: PredictionResults: Prediction
Model prediction Model prediction
errorserrors
– MAE for cohort is MAE for cohort is
1.03mmol/l, error SD is 1.03mmol/l, error SD is
0.78mmol/l0.78mmol/l
– RMSE is 1.31mmol/l, RMSE is 1.31mmol/l,
MAPE MAPE 20.21%20.21%
– Very variable depending Very variable depending
on the patient and/or on the patient and/or
timetime Prediction MAPE Prediction MAPE exceedsexceeds the reported sensor error the reported sensor error Errors are mostly at or within sensor error or very wideErrors are mostly at or within sensor error or very wide
Residual plot of model prediction to patient data
100 150 200 250 300 350 400 450 500 550 600-4
-3
-2
-1
0
1
2
3
4
Patient 2Patient 5Patients 1,3,4,6,7
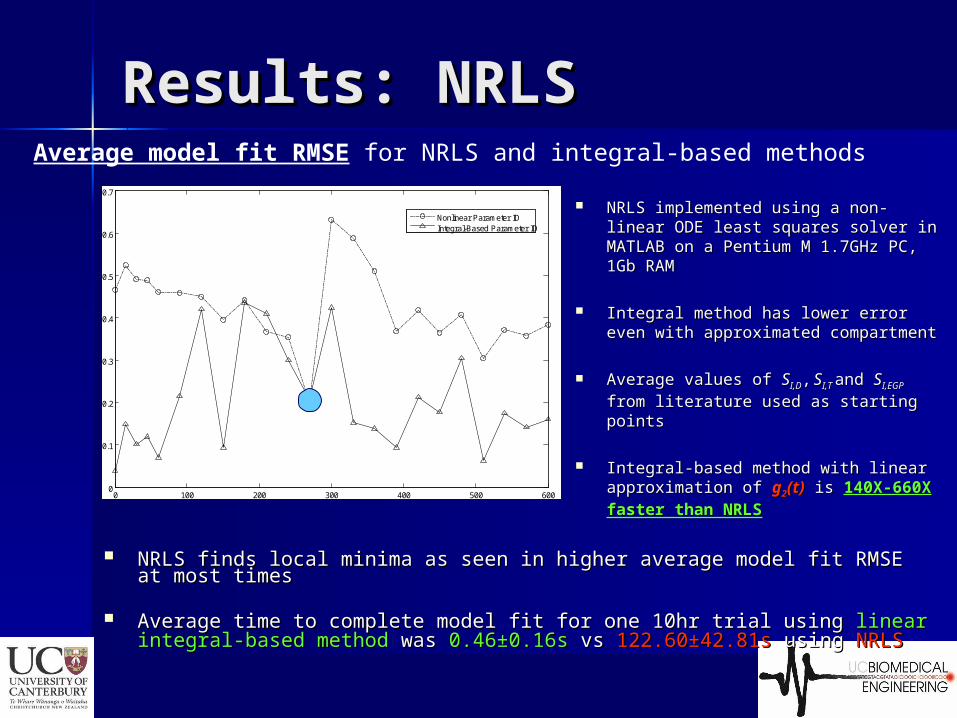
Results: NRLSResults: NRLS
NRLS implemented using a non-linear NRLS implemented using a non-linear ODE least squares solver in MATLAB ODE least squares solver in MATLAB on a Pentium M 1.7GHz PC, 1Gb RAMon a Pentium M 1.7GHz PC, 1Gb RAM
Integral method has lower error even Integral method has lower error even with approximated compartmentwith approximated compartment
Average values of Average values of SSI,DI,D,, SSI,T I,T and and SSI,EGP I,EGP
from literature used as starting from literature used as starting pointspoints
Integral-based method with linear Integral-based method with linear approximation of approximation of gg22(t)(t) is is 140X-660X140X-660X faster than NRLSfaster than NRLS
0 100 200 300 400 500 6000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Nonlinear Parameter IDIntegral-Based Parameter ID
NRLS finds local minima as seen in higher average model fit RMSE at NRLS finds local minima as seen in higher average model fit RMSE at most timesmost times
Average time to complete model fit for one 10hr trial using Average time to complete model fit for one 10hr trial using linear linear integral-based methodintegral-based method was was 0.460.46±0.16s±0.16s vs vs 122.60±42.81s122.60±42.81s using using NRLSNRLS
Average model fit RMSE for NRLS and integral-based methods

Is it the model or Is it the model or method?method?
Care must be taken not to over fit Care must be taken not to over fit available data with model dynamics. available data with model dynamics.
For this cohort, the 1-compt. glucose For this cohort, the 1-compt. glucose model has significantly smaller model has significantly smaller prediction errors for a given set of prediction errors for a given set of parametersparameters
This result is due to differences in This result is due to differences in model dynamics and ability to fit the model dynamics and ability to fit the observed behaviour, observed behaviour, independent of independent of fitting methodfitting method
However, model constants were However, model constants were average average a prioria priori values and not values and not further optimisedfurther optimised
Hence the level of prediction Hence the level of prediction accuracy reported may be expectedaccuracy reported may be expected
100 150 200 250 300 350 400 450 500 550 6000.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2-compartment glucose modelChase et al. model(1-compartment glucose model)
Average model prediction RMSE with 1-compt. glucose model (Chase et al., (Chase et al., 2005)2005)
A convex identification method exposes the model prediction A convex identification method exposes the model prediction errors, identifying potential inadequacies in model dynamics errors, identifying potential inadequacies in model dynamics and/or constantsand/or constants

Some ConclusionsSome Conclusions Cohort model fit RMSE and MAPE were lower using linear integral-based Cohort model fit RMSE and MAPE were lower using linear integral-based
method compared to NRLS – for the same modelmethod compared to NRLS – for the same model
Model complexity can be extended (i.e. multiple compartments) without Model complexity can be extended (i.e. multiple compartments) without significantly affecting identification computation time significantly affecting identification computation time Integrals can be Integrals can be used for simple inaccessible compartments using approximationsused for simple inaccessible compartments using approximations
Fitted parameters were all within reported physiological rangesFitted parameters were all within reported physiological ranges
Issues:Issues:– Different model dynamics and parameters may work better for different Different model dynamics and parameters may work better for different
cohorts or situations – cohorts or situations – the comparison is not “complete” and this work is the comparison is not “complete” and this work is presented to show the potential impactspresented to show the potential impacts
– A priori A priori global identifiability should always be considered. global identifiability should always be considered. Not all models are Not all models are globally identifiable for all parametersglobally identifiable for all parameters..
Linear, integral-based method shown to have lower computational cost Linear, integral-based method shown to have lower computational cost leading to increased PI speedleading to increased PI speed
A convex method can identify potential areas of model difficulty or which A convex method can identify potential areas of model difficulty or which other parameters may need to be identified in place of a population other parameters may need to be identified in place of a population value.value.

AcknowledgementsAcknowledgements
Maths and Stats Gurus
Dr Dom LeeDr Bob Broughton Dr Chris Hann
Prof Graeme Wake
Thomas LotzJessica Lin & AIC3
AIC2 & Dr. Geoff Shaw
Jason Wong & AIC4 AIC1
The Danes
Prof Steen Andreassen
Dunedin
Dr Kirsten McAuley Prof Jim Mann


















