1001 Mips-like CPU - UCL Computer Science · 08/12/2008 1001 Mips-like CPu, Pipelining & Memory...
24
08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 1 1001 Mips-like CPU Peter Rounce [email protected]
Transcript of 1001 Mips-like CPU - UCL Computer Science · 08/12/2008 1001 Mips-like CPu, Pipelining & Memory...

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 1
1001 Mips-like CPU
Peter [email protected]

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 2
PC MUX1
0
1
Address
WriteData
MemData
Memory
InstructionRegister
Instruction[31-26]
Instruction[25-21]
Instruction[20-16]
Instruction[15-0]
MemoryDataRegister
Registers
ReadRegister 1
ReadRegister 2
WriteRegister 1
WriteData
ReadData 1
ReadData 2
SignExtend
ShiftLeft 2
B
A
ALUOut
ALUCond
ALUResult
MUX2
0
1
MUX3
0
1
MUX5
0
1
16 32
Adder
Adder
MUX0
0
1
4
MemRead
IorD
IncOrBR
IRWritePCWrite
to controlRegDst RegWrite
ALUcontrol
ALUsrcBMemToReg
to control
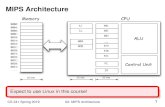
Rectangles are registers; dashed line are control signals output by control finite state machine.
A “mux” units route one of its inputs to its output selected by its control input.
MemWrite

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 3
There are 3 to 5 stages in the execution of an instruction as follows (stages 1 and 2 are always the same):-
Instruction Fetch: PC routed to memory via MUX1; memory read under control of MemRead signal; memory output stored in Instruction Register, as IRWrite is active. At same time, PC+4 produced by top left Adder unit is routed by MUX0 to PC, where it is stored at end of Fetch stage.
Decode/Reg Read: Different fields of the new instruction are fed from Instruction Register to where they are required: which ones will be used depends on the instruction opcode. The instruction opcode bits are fed to the control logic to determine the subsequent stages – the execution stages. During this stage, 2 registers are read and output , and stored in the A & B registers: these register values are read just in case they are needed.
Execution Stage: The ALU operates on its inputs> The ALU operation is determined by the state (instruction dependent) of the ALUcontrol signal lines from the control logic. One input is direct from register A. The other input is from MUX5 and is either from register B of is the sign-extended immediate field from the instruction (bits 0-15). The output from the ALU is stored in register ALUOut. Note that for memory load and store instructions, this stage generates the address to be sent to the memory. Note that for a branch instruction, the ALU “cond” output determines if the branch is to be taken, while the Adder above the ALU produces the target address of the branch, which is to routed by MUX0 to the PC under the control of the IncOrBR signal. This is the final stage of a branch.
Stage 4: For all but memory load and store instruction, the ALU result is passed from ALUout to the destination register via MUX3 with the destination register being selected by the output of MUX2. For a memory Store operation, the value (the address) in ALUout is routed to the Memory via MUX1, the value to write to memory is routed to the memory from register B, and MemWrite is activated. For a Load operation, the address in ALUout is routed via MUX1 to the memory, MemRead is activated, and the memory output value stored in the Memory Data Register.
Stage 5: This is only needed for Load instructions. The value in the Memory Data Register is routed to the destination register via MUX 3 with the destination register being selected by the output of MUX2: RegWrite is activated, of course.
Note: This CPU only does a sub-set of MIPS instructions, but shows the main features of a feasible design. The Memory in particular is assumed to be a fast on-chip static memory – usually the memory interface logic would be a little more complicated.

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 4
PCWriteIncOrBranch=0
ALUSrcB = 00ALUSrcB = 0
RegDst = 1RegWrite
MemtoReg = 0
MemWriteIorD = 1
MemReadIorD = 1
ALUSrcB = 1
RegDst=0RegWrite
MemtoReg=1
MemRead
IorD = 0IRWrite
PCWrite
Instruction fetchInstruction decode/
register fetch
Jumpcompletion
BranchcompletionExecution
Memory addresscomputation
Memoryaccess
Memoryaccess R-type completion
Write-back step
(Op = 'LW') or (Op = 'SW') (Op = R-type)
(Op
='B
EQ')
(Op
='J
' )
(Op
='SW
')
(Op
='L
W')
4
01
9862
753
Control logic Finite State Machine for the CPU design: Each circle is a control state and shows the signals active in the state.
Path for Store instruction highlighted
IncOrBranch = 1
AluControl =operation
AluControl =add
AluControl =compare
IncOrBranch=0
Reset

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 5
1001 Pipelining
Peter [email protected]

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 6
Pipelined Architecture
A pipelined architecture tries to use all resources in all stages but with each working on a different instruction, much as cars are built on a production line:-
F | D | E | M | W
F | D | E | M | WF | D | E | M | W
F | D | E | M | WF | D | E | M | W
F | D | E | M | W
instructions
time
All stages execute in the same time - even the instruction fetch.
If the stage time is one clock cycle, then one instruction completes every clock cycle.
All instructions have all stages even if some don’t use them, e.g. M stage
Of course, there are problems........
F - instruction Fetch
D = Decode & register read
E = execute (add, subtract)
M = Memory access
W = Result write-back stage

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 7
Problems that restrict pipeline operation
The demand for instructions is greatly increased by pipelining. Even at a low clock rate of 100 MHz, a fetch must occur every 10ns which is too fast for dynamic RAM. A cache is necessary.
At clock rates of >100 MHz (Pentium) an on-chip cache is necessary and also a second cache between CPU amd main memory, if there is to be any chance of fully utilising the pipeline capacity of the chip.
Hazards: these cause the pipeline to stall for one or more cycles.
There are 3 types of Hazard
Structural Hazards are caused when 2 or more instructions need the same resource in the same pipeline stage.
Control Hazards occur at branch/jump instructions when the next instruction to execute cannot be determined.
Data Hazards occur when the result of an early instruction is not available when needed

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 8
Structural Hazard : a very common conflict is for access to the system busses
Load/store operations need to use the system busses, and instruction fetches must be stalled at these times:-
F | D | E | M | WF | D | E | M | W
F | D | E | M | Wst | F | D | E | M | W
F | D | E | M | WF | D | E | M | W
timeinstructionsload/store
M - memory access st - stall
All instructions after the stall are delayed - the stall reduces the pipeline speed up.
Structural hazards can only be reduced by duplicating resources.
Some digital signal processors have 2 sets of system busses (one set accessing a memory containing only instructions, another set accessing a memory only containing data), so that code and data accesses can be done in parallel.This is called a Harvard Architecture: it is only used in general purpose architectures on the CPU chip to internal caches as in Pentium.

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 9
Data Hazards
F | D | E | M | Wst | F | D | E | M | W
F | D | E | M | WF | D | E | M | W
add $2, $3, $1
sub $8, $9, $2
F | D | E | M | WF | D | E | M | W
time
$2 is not updated with the result of the add by the time that the subtract needs it.
It is possible to add extra logic to the decoder to recognise such data dependencies between instructions. The subtract can then be stalled until the$1 is updated.
It is also possible to install extra hardware to remove the need to stallthe subtract: the point to note is that the result of the add is available at the ALU output when the subtraction operation starts - the result can be routed back to the ALU input so that it is available for the subtraction.

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 10
Control Hazards
F | D | E | M | W
st | st | st | st | F | D | E | M | W
bne $4, $5, +25
There are a range of other techniques to reduce control hazards: delayed branching, speculative execution, branch target buffers.
The conditional branch is a particular problem. Without special action, the result of adding the offset to PC is not written back ino PC until the R stage of the branch, so that the next fetch has to be delayed until after this. Notice that all pipelining is lost and sequential execution occurs.
F | D | E | M | W
st | st | F | D | E | M | W
bne $4, $5, +25
PC adder updates PC hereif condition is true!
One solution is to add a separate adder to the PC so that the addition can be done locally to the PC in the S stage of the branch ,with the ALU not being used, and requiring only 2 stalls:-

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 11
Pipeline Speed-up: this is a measure of the improvement from pipelining
speed up = average instruction time without pipeliningaverage instruction time with pipelining
This can be shown by quite simple mathematics to be:-number of pipeline stages
1+∑( _ * _ )hazard frequency stall cyclei
Example: 5 stage pipeline speed-up (1) without and (2) with attention to reducing hazards
It is obvious that reducing hazard frequecies and the stalls incurred is important.
Hazard Type Hazard Frequency Stall Cycle Stall Cycle reducedStructural Hazards 30% 1 1Data Hazards 10% 2 0Control Hazards 20% 4 1
(1) speed up = 1+ 0.3* 1 + 0.2 *1 + 0.2*4 2.3
=5 5
= 2.17
(2) speed-up = 5 1.5 = 3.33 ( a 50 % improvement over 2.17)

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 12
Memory Management
Peter [email protected]

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 13
Memory Protection
This address restriction is done by Memory Management hardware:-
CPUMemory
ManagementAddress Bus Address Bus
Memory & I/O Interfaces
Restrict addresses that an application can access:-
• Limits application to its own code and data
• Prevents access to other programs and OS
• Prevents access to I/O addresses
This Memory Management hardware does address translation as well.
Hardware protection is secure: it is only “poor” software that allows security attacks to succeed!

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 14
Memory Protection + Address Translation:Creation of illusion that program has all the memory to itself
Logical addresses mapped by
address translation to physical addresses
Program, users & CPU’sview of memory used by Program X
Solution: have logical addresses used by program and CPU ; have physical addresses to access memoryUse Address translation to turn logical address into physical address.
Physical memory is sharedwith other programs/processesand with Operating System
Logical Memorye.g. for Program X
Code
Data
Stack
Unused by Program X
Physical Memory of system
Program X
Program Y
O/S
Actual memoryused by Program

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 15
Address Translation: basis of Memory Protection and Memory Management
Logical address Address programmed into code and used by CPUCPU outputs Logical address on to CPU address BusCPU only knows about Logical addresses
Logical address where CPU considers data/instruction to be storedPhysical address address where data/instruction is really stored
MMU = Memory Management Unit Pentium MMU is on same chip as CPU
Note:Physical addresses are never stored in the program, only appear on address bus not data bus.
CPU MMU MemoryLogical Address Bus Physical Address Bus
Data bus
Logical address Physical addressMMUtranslation
Bus ErrorBus Error Exception

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 16
Memory Protection: exception to CPU if address output by CPU >= limit register contents
Several processes J,B,X…. in main memory
Base-Limit Registers - Memory Protection + Address Translation
Translation: Logical Address + Base Register Physical Address
BaseRegister
LimitRegister
Process J
Process X
Process B
addresses
Process X is to run
Lowest physical address of X set in Base Register
Length of X set in Limit Register
All processes have logical addresses starting at 0.
MMU has 2 registers set by Operating System
Simple, old system, that demonstrates address translation process!
Note: Memory Management unit is addressable by O/S only.

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 17
More ComplexAddress Translation Example
Translation information created when program is loaded by O/S from disk into memory.It is written into MMU by O/S prior to running process: MMU registers have addresses.
Process X Code
Process X Data
Process X Stack
Logical Memory
00000000
2000000030000000
FFFF0000
Logical addresses Process X Code
Process X Data
Process X Stack
Physical Memory
Translationsperformed by MMUwhen process X is
executed
Translations
Block Logical address range Physical Address Range TranslationCode 00000000-1FFFFFFF 70000000-9FFFFFFF add 70000000Data 20000000-2FFFFFFF 40000000-5FFFFFFF add 20000000Stack FFFF0000-FFFFFFFF 3FFF0000-3FFFFFFF sub C0000000
Address range of Logical Memoryis full address range of CPU. Physical memory is usually smaller.Pentium Logical Address Space is 4Gbytes but most users has 128Mbytes or less of physical memory

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 18
Page-Based Memory Management - The standard memory management system
Page 1Page 2Page 3Page 4Page 5Page 6
Page 1Page 2Page 3Page 4Page 5Page 6
Process:Logical memory Physicalmemory
Translations only exist for Logical pages that are valid for process:few, if any programs use all of Logical Address Space.
Attempt to access Logical address with no translation to physical memorygenerates an exception to the CPU and the process is Terminated.
Program divided into equal size units: pages.
Page size is always small and a power of 2: 256, 512,….
Each page has separate translation to Physical memory.
Translation information for program keptin a “page table.”
There is a page table for each process.
Page table can be very large

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 19
Page-based translation: Page Tablein general more complicated than shown here
Translation information for program kept in page table
There is a page table for each process.
Part of Page Table for a processwith 100016 byte pages:.
Logical page No Logical Addresses Physical Addresses
0 0000 - 0FFF 1A000 - 1AFFF 1 1000 - 1FFF 3000 - 3FFF 2 2000 - 2FFF 9000 - 9FFF 3 3000 - 3FFF 123000 - 123FFF 4 4000 - 4FFF E8000 - E8FFF 5 5000 - 5FFF 4B000 - 4BFFF
Physical addresses are allocated by O/S as program loaded into memory:their values depend on what space is free at that time. O/S builds table.
Logical memory Spaceof Program
conceptually divided into pages
Page 0
Page 1
Page 2
Page 3
Page 4
Page 5
more pages
From logical address, MMU gets page number and looks up table.Pentium:Page size - 100016
Max No. of logical pages for one program is 10000016

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 20
Advantages of Paging
• Can load program into available space in memory without need to coalesce free space into single block of free space. Get page from disk put in any free page in memory
•Can load several programs into memory at same time and run them although programs’ memory addresses are the same
[these are logical addresses which are translated to different physical addresses.(each program has its own separate page table)]
•compiler does not need to know memory addresses in which program will run: compiler always use same memory addresses whatever the programlets operating system create translation map on loading program.
•parts of logical address space unused by program have no mapping in tableand do not occupy memory.
•MMU generates an exception signal to CPU if access made to unused memoryand program aborted (bus error) [part of protection system]
•page table kept in memory - read from memory by MMU, when process is scheduled to run

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 21
What’s the use of address translation?
Better use of MemoryCan load programme into available space.
O/S can access all addresses but User processes can only access a restricted set of adddresses
Simpler compilationcompiler can compile all programs in same way with same logical addresses[O/S sets up different translation for each programme loaded]
Protection of rest of memory translations only for valid program addressesgenerate exception to terminate programme if
invalid logical address sent to MMU
Prevents user program from accessing I/O interfaces and O/S code& data[no valid translation provided to I/O addresses or O/S addresses]
Program is prevented from making changes to the page table: no mapping to memory holding page table

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 22
Logical page No Logical Addresses Physical Addresses
.
. 9616 96000 - 96FFF 19000 -19FFF 9716 97000 - 97FFF swapped to disk 9816 98000 - 98FFF not used by program .
Part of the page table for a
process
accesses to page 9616 are translated by MMU and memory accessed
an access to page 9816 MMU generates an exception to CPUO/S analyses exception and aborts program.
an access to page 9716 MMU generates an exception to CPUO/S analyses exception and loads page fromdisk into memory and process re-started.
Virtual Memory an extension to paging
not all of program has to be in memory for program to runkeep some pages of program on disk and load as required to memory.

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 23
Virtual Memory
MMUCPUMainMemory
Swap Spaceon Disk
Virtual Memory
Swap space is an area of a hard disk set asidefor holding pages of memory swapped out to provide spacefor loading pages of another program
Virtual memory allows for better use of the available memory:
Large programs can be run on small memories: possibly more slowly.
More programs can have active pages loaded into memory.
Thrashing: available physical pages too few – no free pageslots of swapping of pages as O/S scheduler switches between processesperformance drops because of disk access overheadsrun fewer programs or add more memory

08/12/2008 1001 Mips-like CPu, Pipelining & Memory Management 24
A CPU running address translation needs 2 or more modes of operation:-e.g. a kernel or supervisor modefor the operating system
a user modefor application processes.
[Pentium has 4 modes or levels - with the Pentium everything is more complex]
Signal output by CPU indicates processor mode: signal is used by external hardware to enable/disable access to parts of the system.[MMU uses signal to distinguish between operating system and user process accesses.]Mode held in bit in CPU register: only writeable in Supervisor Mode or on System Call
This mode switch is madeeasy by the CPU.
CPU in supervisor
mode
CPU in supervisor
mode
CPU in usermode
This switch is only allowed via a system call instruction, which forces a switch to small number of predefined addresses in the O/S.Process cannot switch the state and keep running.The O/S is always entered on this switch.
Protection System
Must stop user mode process acquiring supervisor mode status.
Identification of O/S accesses from User Accesses