
1 Titanium Review: Ti Parallel Benchmarks Kaushik Datta Titanium NAS Parallel Benchmarks Kathy...
24
1 Titanium Review: Ti Parallel Benchmarks Kaushik Datta Titanium NAS Parallel Benchmarks Kathy Yelick http://titanium.cs.berkeley. edu U.C. Berkeley September 9, 2004
-
Upload
terence-higgins -
Category
Documents
-
view
221 -
download
1
Transcript of 1 Titanium Review: Ti Parallel Benchmarks Kaushik Datta Titanium NAS Parallel Benchmarks Kathy...

1Titanium Review: Ti Parallel Benchmarks Kaushik Datta
Titanium NAS Parallel Benchmarks
Kathy Yelick
http://titanium.cs.berkeley.edu
U.C. Berkeley
September 9, 2004

2Titanium Review, Sep. 9, 2004 Kaushik Datta
Benchmarks
• Current Titanium NAS benchmarks:• MG (Multigrid)• FT (Fast Fourier Transform)• CG (Conjugate Gradient- Armando)• IS (Integer Sort- Omair)• EP (Embarrassingly Parallel- Meling)
• Today’s focus is on MG and FT

3Titanium Review, Sep. 9, 2004 Kaushik Datta
Platforms
• Seaborg:• NERSC IBM SP RS/6000• 16-way SMP nodes• 375 MHz Power3 procs, 1.5 GFlops max• 64 KB L1 D-Cache, 8 MB L2 Cache
• Also briefly mention Compaq Alphaserver, AMD Opteron, and Intel Itanium II processors

4Titanium Review, Sep. 9, 2004 Kaushik Datta
MG Benchmark
• Class A problem is 4 iterations on a 2563 grid• All the computations are nearest neighbor
across 3D grids• For coarse grids, all computations are done on one
processor to minimize fine-grain communication
• Communication pattern for updating ghost cells is very regular
• Tests both the computation and communication aspects of the platform

5Titanium Review, Sep. 9, 2004 Kaushik Datta
Major MG Components
• Computation (applies 27-point 3D stencil):• ApplySmoother• EvaluateResidual• Coarsen• Prolongate
• Communication (very regular):• UpdateBorder

6Titanium Review, Sep. 9, 2004 Kaushik Datta
Possible Serial Optimizations
• In order to improve the performance of naive MG code, we first tried to make the serial code faster
• The optimizations that seemed most promising were:• Cache Blocking• Common Subexpression Elimination

7Titanium Review, Sep. 9, 2004 Kaushik Datta
Possible Serial Optimization #1- Cache Blocking
• Cache blocking attempts to take a portion of the grid (that will fit into a given level of cache) and perform all necessary computations on it before proceeding to the next cache block
• In our case, we used cubic 3D cache blocks, and varied the side length of the cube

8Titanium Review, Sep. 9, 2004 Kaushik Datta
Possible Serial Optimization #1- Cache Blocking
• Cache blocking seems to help slightly on the Itanium II, but not on the Power3
Power3 Running Time
00.5
11.5
22.5
33.5
4
Side Length of Cubic Cache Block
Tim
e (s
ec.)
applySmoother
evaluateResidual
Itanium II Running Time
00.5
11.5
22.5
3
Side Length of Cubic Cache Block
Tim
e (s
ec.)
applySmoother
evaluateResidual
9Titanium Review, Sep. 9, 2004 Kaushik Datta
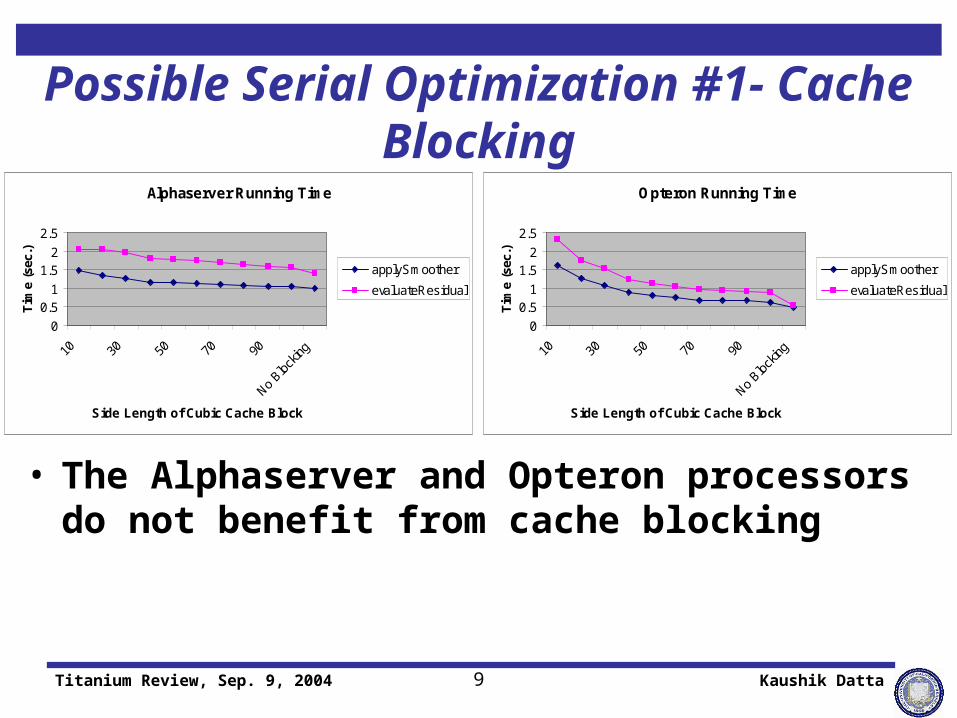
Possible Serial Optimization #1- Cache Blocking
• The Alphaserver and Opteron processors do not benefit from cache blocking
Alphaserver Running Time
0
0.51
1.52
2.5
Side Length of Cubic Cache Block
Tim
e (s
ec.)
applySmoother
evaluateResidual
Opteron Running Time
0
0.51
1.52
2.5
Side Length of Cubic Cache Block
Tim
e (s
ec.)
applySmoother
evaluateResidual

10Titanium Review, Sep. 9, 2004 Kaushik Datta
Possible Serial Optimization #2- Common Subexpression Elimination
• CSE is a technique to reduce the flop count by memoizing results
• However, it may not always reduce the overall running time, since each pencil through the grid needs to be traversed twice• The first traversal is done to memoize certain results• The second traversal then uses these results to compute
the final answer

11Titanium Review, Sep. 9, 2004 Kaushik Datta
Possible Serial Optimization #2- Common Subexpression Elimination
• CSE does a good job at lowering the running time, partially because it reduces the Flop count
• Note: The Fortran MG benchmark uses CSE
Power3 Running Time
00.5
11.5
22.5
MG Component
Tim
e (s
ec.)
Regular
CSE
Power3 FP Operations
050
100150200250300350400
MG Component
Mil
lio
ns
of
FP
Op
erat
ion
s
Regular
CSE

12Titanium Review, Sep. 9, 2004 Kaushik Datta
Chosen Serial Optimizations
• Based on these results, we kept the CSE optimization, but omitted any type of cache blocking
• This mimics the Fortran code

13Titanium Review, Sep. 9, 2004 Kaushik Datta
Parallel Optimizations
• Have each processor block communicate with only 6 nearest neighbors instead of 27 to update its border (Dan)
• Eliminate “static” timers• This gets rid of a level of indirection• Dan reduced false sharing in static variables by grouping
each processor’s static variables together
• Force bulk arraycopy by using contiguous array buffers (manual packing/unpacking)
• Use the “local” keyword to let each processor know that all its computations are local

14Titanium Review, Sep. 9, 2004 Kaushik Datta
Seaborg SMP Performance of MG Class A Problem
• Titanium does about as well as Fortran up to the 16 processor case
• Our serial tuning seems to be successful in this case
Time on Single SMP of Seaborg
0
5
10
15
20
25
serial 1x1 1x2 1x4 1x8 1x16
Processor Configuration
Tim
e (s
ec.) Fortran
Ti 32-bit gls
Ti 32-bit mcs
Speedup on Single SMP of Seaborg
0
2
4
6
8
10
12
14
serial 1x1 1x2 1x4 1x8 1x16
Processor Configuration
Sp
eed
up Fortran
Ti 32-bit gls
Ti 32-bit mcs

15Titanium Review, Sep. 9, 2004 Kaushik Datta
FT Benchmark
• Class A problem is 6 iterations of 2562 x 128 problem
• Each 3D FFT is performed as 3 separate 1D FFTs and 2 transposes
• 1D FFTs:• All are local• Currently are library calls (using FFTW)
• Transposes:• One local transpose and one all-to-all transpose• All-to-all transpose tests machine bisection bandwidth

16Titanium Review, Sep. 9, 2004 Kaushik Datta
Major FT Components
• Computation:• 1D FFTs (part of 3D FFT)• Evolve• Checksum
• Communication:• Transposes (part of 3D FFT)
• Both:• Setup

17Titanium Review, Sep. 9, 2004 Kaushik Datta
Serial FT Optimizations
• Removed an unnecessary transpose in the 3D FFT
• Memoized the time evolution array to reduce the Flop count

18Titanium Review, Sep. 9, 2004 Kaushik Datta
Seaborg SMP Performance of FT Class A Problem
• Titanium does slightly better than Fortran, but we are calling FFTW library
• We will compare each component of the benchmark separately
Total Time (using FFTW for Ti)
0
10
20
30
40
50
60
serial 1x1 1x2 1x4 1x8 1x16
Processor Configuration
Tim
e (s
ec.)
Fortran
Ti 32-bit gls
Total Speedup (using FFTW for Ti)
0
2
4
6
8
10
12
serial 1x1 1x2 1x4 1x8 1x16
Processor Configuration
Sp
eed
up
Fortran
Ti 32-bit gls

19Titanium Review, Sep. 9, 2004 Kaushik Datta
Seaborg SMP Performance of Setup
• Setup creates distributed arrays and memoizes an array used in later computations
• This method is only called once, but still needs tuning
Setup Time
0
2
4
6
8
10
serial 1x1 1x2 1x4 1x8 1x16
Processor Configuration
Tim
e (s
ec.)
Fortran
Ti 32-bit gls
Setup Speedup
0
10
20
30
40
50
serial 1x1 1x2 1x4 1x8 1x16
Processor Configuration
Sp
eed
up
Fortran
Ti 32-bit gls

20Titanium Review, Sep. 9, 2004 Kaushik Datta
Seaborg SMP Performance of 1D FFTs
• The Titanium code calls the FFTW library in this case
• We are in the process of converting the FFT into pure Titanium code
1D FFT Time (using FFTW for Ti)
0
10
20
30
40
50
serial 1x1 1x2 1x4 1x8 1x16
Processor Configuration
Tim
e (s
ec.)
Fortran
Ti 32-bit gls
1D FFT Speedup (using FFTW for Ti)
0
5
10
15
20
serial 1x1 1x2 1x4 1x8 1x16
Processor Configuration
Tim
e (s
ec.)
Fortran
Ti 32-bit gls

21Titanium Review, Sep. 9, 2004 Kaushik Datta
Seaborg SMP Performance of Transpose
• The Titanium and Fortran perform similarly using shared memory
• Note: The Fortran code does cache blocking for the local transpose (possible Ti optimization)
Transpose Time
00.5
11.5
22.5
33.5
4
1x2 1x4 1x8 1x16
Processor Configuration
Tim
e (s
ec.) Fortran Global
Fortran Local
Ti 32-bit gls Global
Ti 32-bit gls Local

22Titanium Review, Sep. 9, 2004 Kaushik Datta
Seaborg SMP Performance of Evolve
• Evolve consists of purely local FP computations• The Titanium code performs slightly worse than
the Fortran code, but scales better
Evolve Time
0
1
2
3
4
5
6
7
serial 1x1 1x2 1x4 1x8 1x16
Processor Configuration
Tim
e (s
ec.)
Fortran
Ti 32-bit gls
Evolve Speedup
02468
10121416
serial 1x1 1x2 1x4 1x8 1x16
Processor Configuration
Sp
eed
up
Fortran
Ti 32-bit gls

23Titanium Review, Sep. 9, 2004 Kaushik Datta
Conclusion
• On Seaborg, Titanium serial and SMP performance is slightly worse than or comparable to Fortran with MPI in most cases

24Titanium Review, Sep. 9, 2004 Kaushik Datta
Future Work
• Examine and tune the multinode performance of the MG and FT benchmarks
• Convert the FT benchmark into pure Titanium (instead of calling FFTW)
• Start profiling and tuning the serial versions of the CG, IS, and EP benchmarks
• Check the performance of the benchmarks across several different platforms







![DESIGN FACTORS FOR PARALLEL PROCESSING BENCHMARKS - … · Ideally, one would like benchmarks that are pertinent, accepted, and simple [6]. But at present, accurate prediction from](https://static.fdocuments.in/doc/165x107/5e164b07f429cd06db11633b/design-factors-for-parallel-processing-benchmarks-ideally-one-would-like-benchmarks.jpg)










