
1 The Performance Potential for Single Application Heterogeneous Systems Henry Wong* and Tor M....
32
1 The Performance Potential for Single Application Heterogeneous Systems Henry Wong* and Tor M. Aamodt § *University of Toronto § University of British Columbia
-
Upload
trevor-richards -
Category
Documents
-
view
214 -
download
0
Transcript of 1 The Performance Potential for Single Application Heterogeneous Systems Henry Wong* and Tor M....

1
The Performance Potential for Single Application Heterogeneous Systems
Henry Wong* and Tor M. Aamodt§
*University of Toronto§University of British Columbia
2
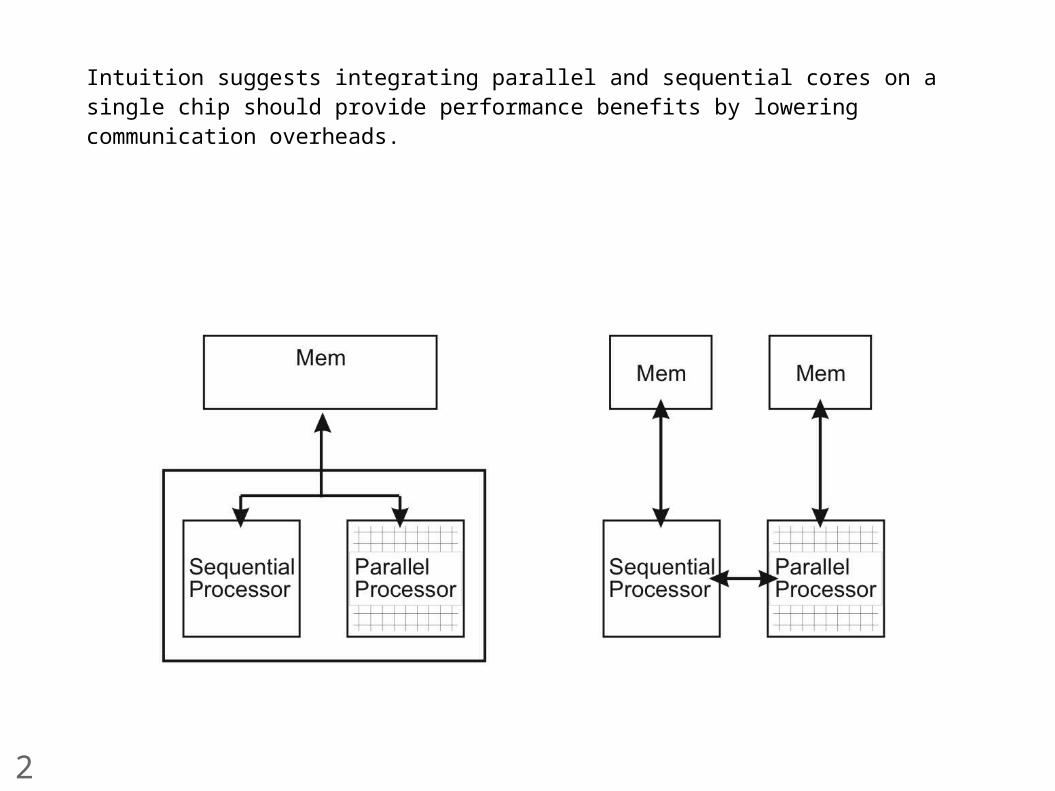
Intuition suggests integrating parallel and sequential cores on a single chip should provide performance benefits by lowering communication overheads.

3
This work: Perform limit study of heterogeneous architecture performance when running a single general purpose application.
Two main results:
• Single thread performance (read-after-write latency) of GPUs ought to improve for GPUs to accelerate a wider set of non-graphics workloads.
• Putting CPU and accelerator on single chip does not seem to improve performance “much” versus separate CPU and accelerator.

4
OutlineIntroduction
Background:
- GPU Computing / Heterogeneous
- Barrel processing (relevant to GPUs)
Limit Study Model
- Sequential and Parallel Models
- Dynamic programming algorithm
- Modeling Bandwidth
Results

5
Graphics Processing Unit (GPU)
PolygonsTexturesLights

6
Programmable GPU
• Rendering pipeline
• Polygons go in
• Pixels come out
• DX10 has 3 programmable stages
7
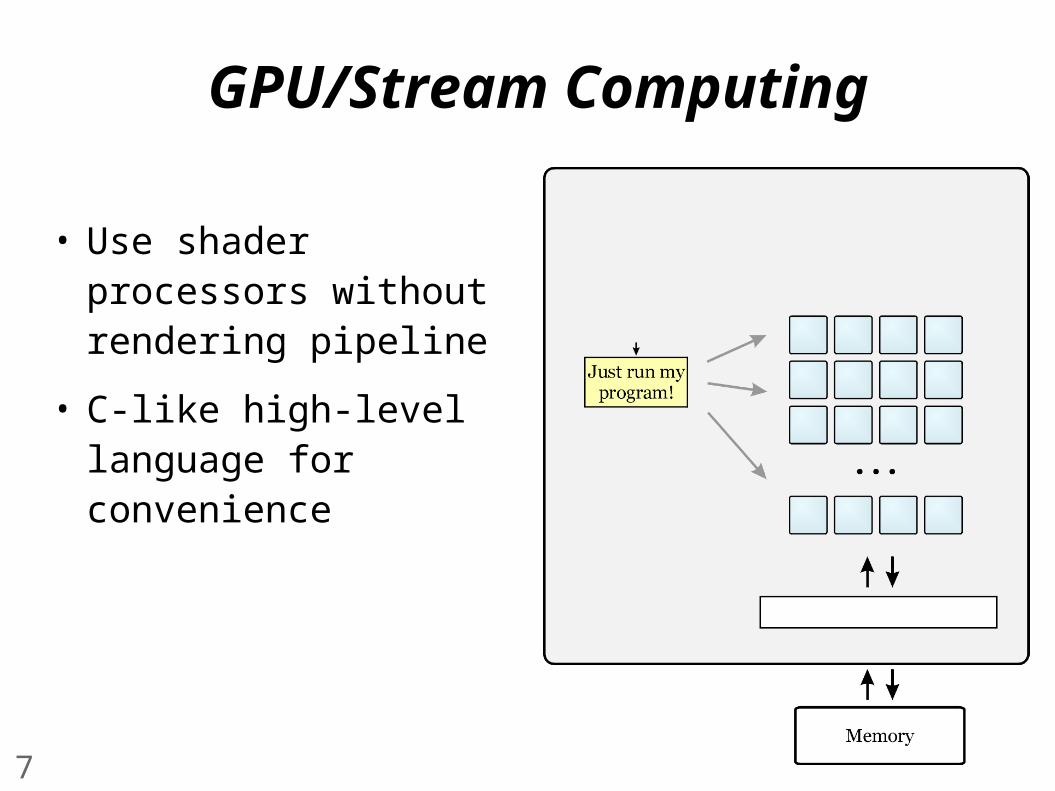
GPU/Stream Computing
• Use shader processors without rendering pipeline
• C-like high-level language for convenience
8
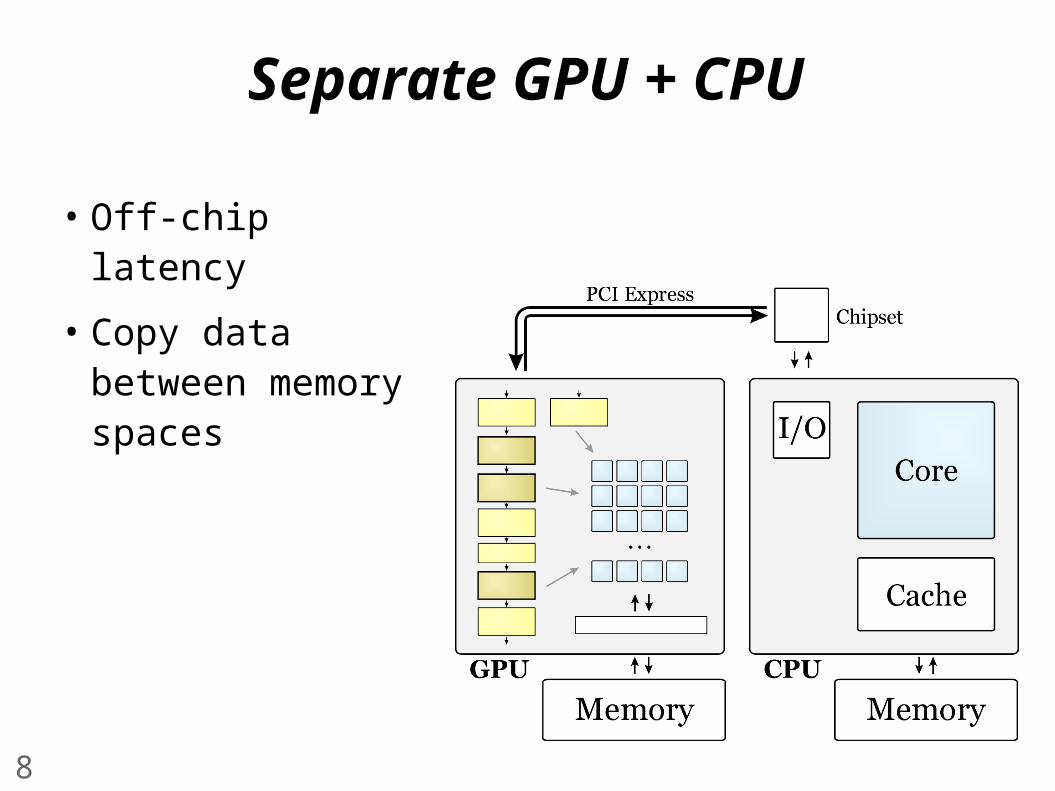
Separate GPU + CPU
• Off-chip latency
• Copy data between memory spaces

9
Single-Chip
• Lower latency
• Single memory address space: Share data, don't copy

10
Sequential Performance of Parallel Processor
• Contemporary GPUs have slow single thread performance.
• “Designed for cache miss” => use “barrel processing” to hide off-chip latency.
• This impacts minimum read-to-write latency for a single thread.
• Not an issue if you have 106 pixels each requiring 100 instruction long thread.

11
Sequential Performance of Parallel Processor
• GPUs can do many operations per clock cycle
• Nvidia G80 needs 3072 independent instructions every 24 clocks to keep pipelines filled
• Can model G80 as executing up to 3072 independent scalar instructions every 24 clocks
• For single thread CPU produces results ~100x faster:
• 2 IPC * 2 clock speed * 24 instruction latency
• Parallel Instruction Latency = ratio of read-to-write latency of dependent instructions on parallel processor (measured in CPU clock cycles) to CPU CPI.

12
Limit Study
• Optimistic abstract model of GPU and CPU
• “ILP limit study”-type trace analysis with optimistic assumptions.
• Assume constant CPI (=1.0) for sequential core.
• Parallel processor is ideal data flow processor, but with read-after-write latency some multiple of the sequential core clock.
• Parallel processor has unlimited parallelism
• Optimally schedule instructions on cores using dynamic programming algorithm.

13
Trace Analysis Assumptions
• Perfect branch prediction
• Perfect memory disambiguation
• Remove stack-pointer dependencies
• Remove induction variable dependencies by removing all instructions that depend (dynamically) only on compile time constants.

14
Scheduling a Trace
15
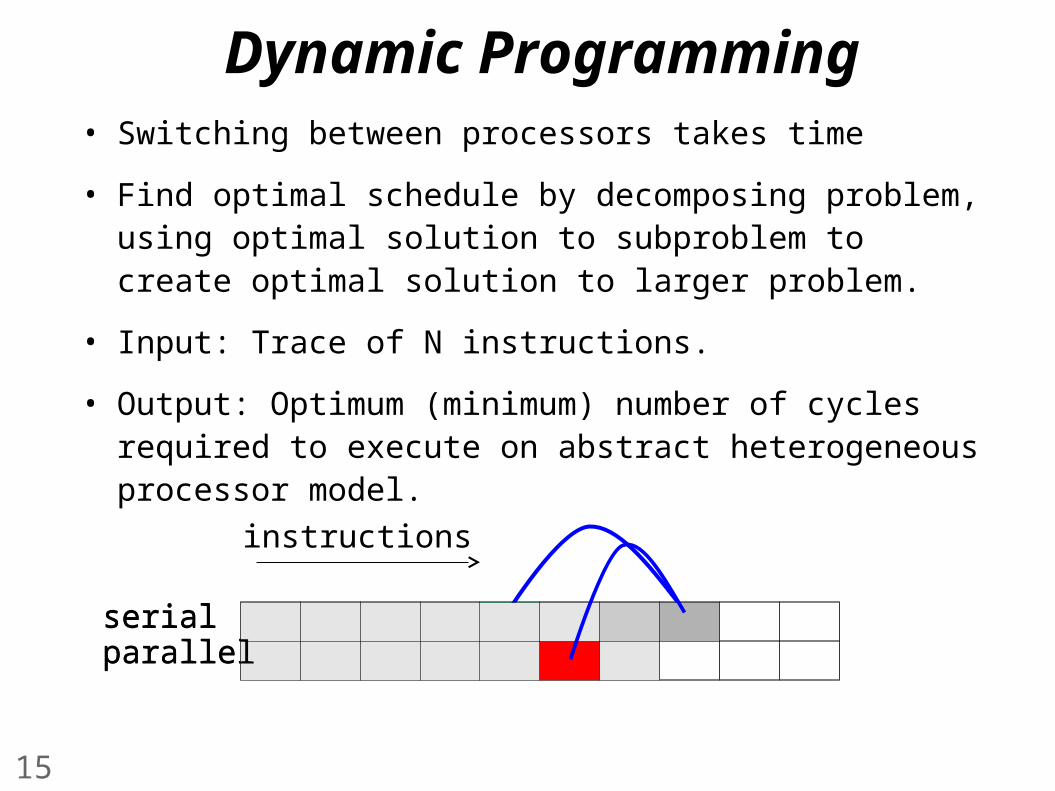
Dynamic Programming• Switching between processors takes time
• Find optimal schedule by decomposing problem, using optimal solution to subproblem to create optimal solution to larger problem.
• Input: Trace of N instructions.
• Output: Optimum (minimum) number of cycles required to execute on abstract heterogeneous processor model.
serialparallelserialparallel
instructions

16

17
Bandwidth
Latency of mode switch depends upon amount of data consumed on new processor produced by old processor. Use earliest-deadline-first scheduling. Simple model of bandwidth, e.g., max 32-bits every 8 cycles. Allow overlap of computation with communication.
Iterative model: Use average mode switch latency from last iteration as fixed mode switch latency for next iteration. Results based upon actual implied latency of last iteration.

18
• PTLSim (x86-64): micro-op traces
• SimPoint (phase classification): ~12 x 10M instruction segments.
• Benchmarks: Spec 2000, PhysicsBench, SimpleScalar (used as a benchmark), microbenchmarks.
Experiment Setup

19
Average Parallelism
As in prior ILP limit studies: lots of parallelism.
20
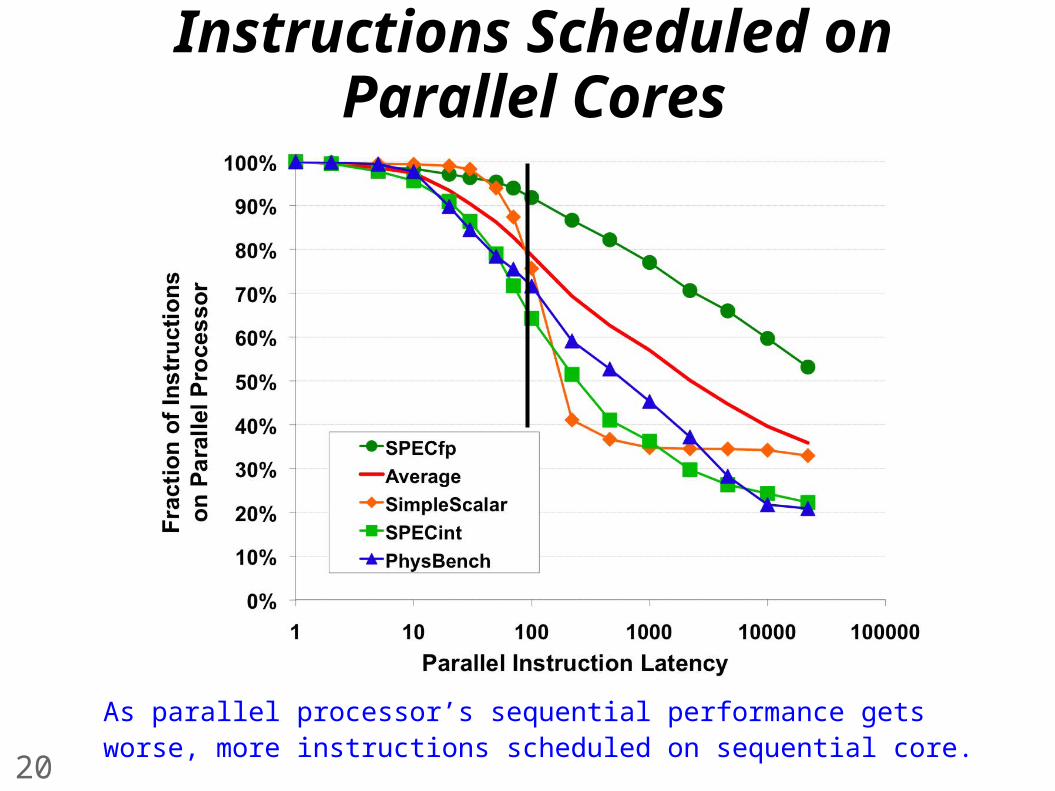
Instructions Scheduled on Parallel Cores
As parallel processor’s sequential performance gets worse, more instructions scheduled on sequential core.

21
Parallelism on Parallel Processor
As parallel processor’s sequential performance gets worse, work scheduled on parallel core needs to be more parallel.

22
Speedup over Sequential Core
Applications exist with enough parallelism to fully utilize GPU function units.
GPU
GPU

23
Speedup over Sequential Core
“General Purpose” Workloads: Performance limited by sequential performance (read-after-write latency) of parallel cores.
GPU
GPU

24
Slowdown of infinite communication cost (NoSwitch)
Up to 5x performance improvement versus infinite cost. Communication cost matters most for GPU like parallel instruction latency. So, put on same chip?

25
Slowdown due to 100,000 cycles of mode-switch latency
Can achieve 85% of the performance of single-chip with large (but not infinite) mode switch latency.

26
Mode Switches
Number of mode switches decreases with increasing mode switch cost.
More mode switches occur at intermediate values of parallel instruction latency.
zero cycles
10 cycles
1000 cycles
27
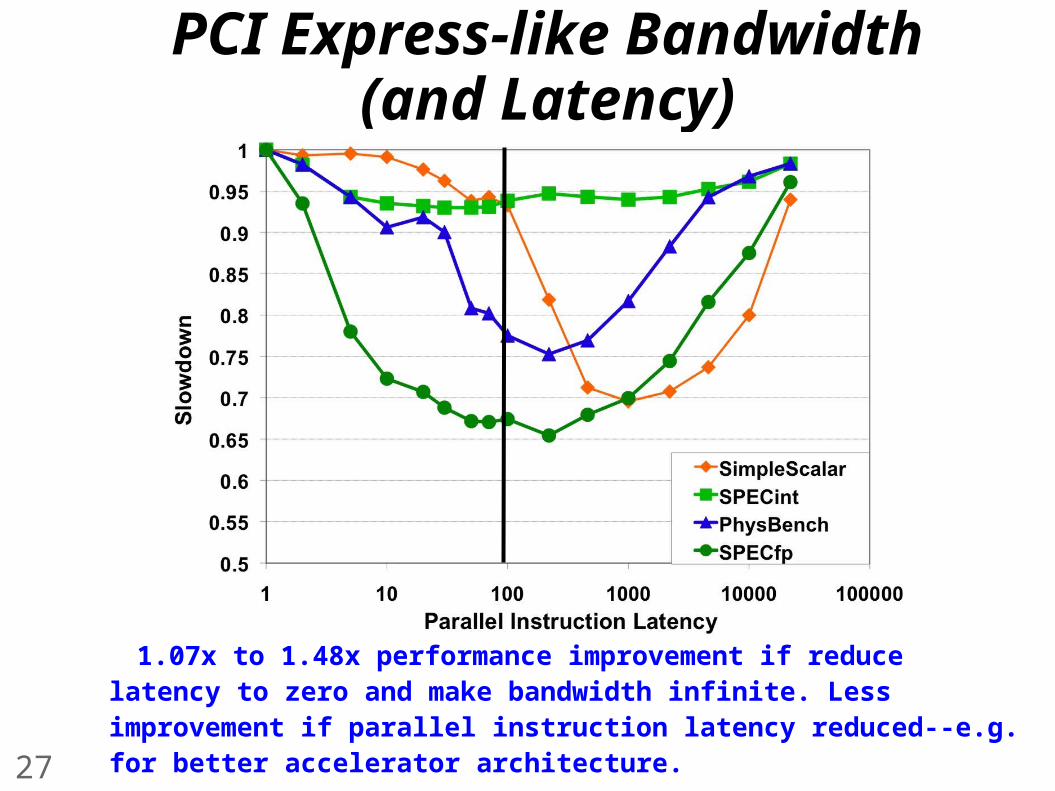
PCI Express-like Bandwidth (and Latency)
1.07x to 1.48x performance improvement if reduce latency to zero and make bandwidth infinite. Less improvement if parallel instruction latency reduced--e.g. for better accelerator architecture.

28
Conclusions & Caveats
• GPUs could tackle more general-purpose applications if single thread performance was better.
• Performance improvement due to integrating CPU and accelerator on single chip (versus separate CPU and accelerator) does not appear staggering. Bandwidth has greater impact than latency.
• Caveats:
• It’s a limit study.
• Heterogeneous may still make sense for other reasons… e.g., if cheaper to add parallel cores than another chip sockets, power, etc…

29
Future Work
• Control dependence analysis
• Model interesting design points in more detail

30
Bandwidth sensitivity for GPU-like parallel instruction latency

31
Proportion of instructions on parallel processor

32
Slowdown of infinite communication
Twophase shows strong sensitivity to communication latency for widely varying parallel instruction latency


















