
John Bent, Douglas Thain, Andrea Arpaci-Dusseau, Remzi Arpaci-Dusseau, and Miron Livny
Upload
dalton-locksCategory
view
219download
0
1
Storage-Aware Caching:Revisiting Caching for Heterogeneous Systems
Brian ForneyAndrea Arpaci-Dusseau Remzi Arpaci-Dusseau
Wisconsin Network DisksUniversity of Wisconsin at Madison
2
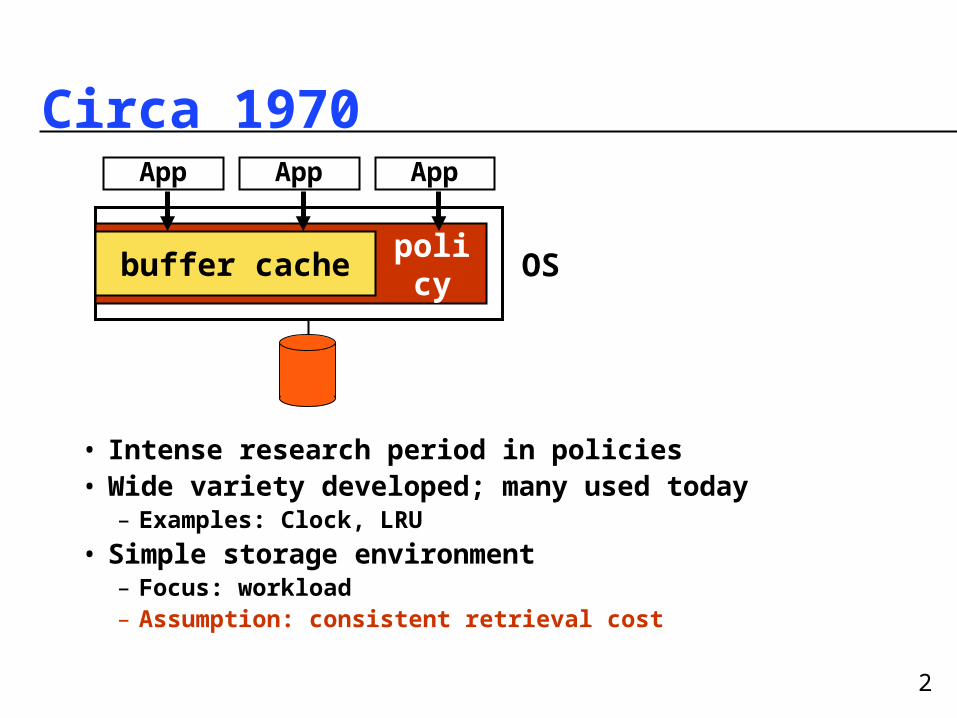
Circa 1970
OSpolic
y
• Intense research period in policies• Wide variety developed; many used today– Examples: Clock, LRU
• Simple storage environment– Focus: workload– Assumption: consistent retrieval cost
buffer cache
App AppApp

3
Today• Rich storage
environment– Devices attached
in many ways– More devices– Increased device
sophistication
• Mismatch: Need to reevaluate
LAN
WAN
policy
buffer cache
App AppApp

4
Problem illustration• Uniform workload• Two disks• LRU policy
• Slow disk is bottleneck• Problem: Policy is oblivious– Does not filter well
fast slow

5
General solution
• Integrate workload and device performance– Balance work across devices–Work: cumulative delay
• Cannot throw out:– Existing non-cost aware policy research– Existing caching software

6
Our solution: Overview• Generic partitioning framework– Old idea– One-to-one mapping: device partition– Each partition has cost-oblivious policy– Adjust partition sizes
• Advantages– Aggregates performance information– Easily and quickly adapts to workload and
device performance changes– Integrates well with existing software
• Key: How to pick the partition sizes

7
Outline
• Motivation
• Solution overview
• Taxonomy
• Dynamic partitioning algorithm
• Evaluation
• Summary

8
Partitioning algorithms
• Static– Pro: Simple– Con: Wasteful
• Dynamic– Adapts to workload• Hotspots• Access pattern changes
– Handles device performance faults
• Used dynamic

9
Our algorithm: Overview
1. Observe: Determine per-device cumulative delay
2. Act: Repartition cache
3. Save & reset: Clear last W requests
Observe
Act
Save & reset

10
Algorithm: Observe
• Want accurate system balance view
• Record per-device cumulative delay for last W completed disk requests– At client– Includes network time

11
Algorithm: Act• Categorize each partition
– Page consumers• Cumulative delay above threshold possible bottleneck
– Page suppliers• Cumulative delay below mean lose pages without
decreasing performance
– Neither
• Always have page suppliers if there are page consumers
Page consumer Page supplier Neither
Page consumer Page supplierNeither
Before
After

12
Page consumers
• How many pages? Depends on state:–Warming• Cumulative delay increasing• Aggressively add pages: reduce queuing
–Warm• Cumulative delay constant• Conservatively add pages
– Cooling• Cumulative delay decreasing• Do nothing; naturally decreases

13
Dynamic partitioning
• Eager– Immediately change partition sizes– Pro: Matches observation– Con: Some pages temporarily unused
• Lazy– Change partition sizes on demand– Pro: Easier to implement– Con: May cause over correction

14
Outline
• Motivation
• Solution overview
• Taxonomy
• Dynamic partitioning algorithm
• Evaluation
• Summary

15
Evaluation methodology• Simulator
• Workloads: synthetic and web
Caching, RAID-0 client
LogGP network• With endpoint contention
Disks• 16 IBM 9LZX• First-order model: queuing, seek time & rotational time

16
Evaluation methodology
• Introduced performance heterogeneity– Disk aging
• Used current technology trends– Seek and rotation: 10% decrease/year
– Bandwidth: 40% increase/year
• Scenarios– Single disk degradation: Single disk, multiple ages
– Incremental upgrades: Multiple disks, two ages
– Fault injection• Understand dynamic device performance change
and device sharing effects
• Talk only shows single disk degradation

17
Evaluated policies
• Cost-oblivious: LRU, Clock
• Storage-aware: Eager LRU, Lazy LRU, Lazy Clock (Clock-Lottery)
• Comparison: LANDLORD– Cost-aware, non-partitioned LRU– Same as web caching algorithm– Integration problems with modern OSes

18
Synthetic• Workload: Read requests, exponentially distributed around 34 KB,
uniform load across disks
• A single slow disk greatly impacts performance.• Eager LRU, Lazy LRU, Lazy Clock, and LANDLORD robust as slow disk
performance degrades
LRU-based
0
5
10
15
20
25
0 1 2 3 4 5 6 7 8 9 10
Age of slow disk (years)
Throughput (MB/s)
Eager LRULANDLORDLazy LRULRUNo cache
Clock-based
0
5
10
15
20
25
0 1 2 3 4 5 6 7 8 9 10
Age of slow disk (years)
Throughput (MB/s)
ClockLazy ClockNo cache

19
Web• Workload: 1 day image server trace at UC Berkeley, reads & writes
• Eager LRU and LANDLORD are the most robust.
020406080
100120140160180
6 6.5 7 7.5 8 8.5 9 9.5 10
Age of slow disk (years)
Throughput (MB/s)
Eager LRULazy LRU
0
20
40
60
80
100
120
140
160
180
0 1 2 3 4 5 6 7 8 9 10
Age of slow disk (years)
Throughput (MB/s)
Eager LRULANDLORDLazy LRULRUNo cache

20
Summary• Problem: Mismatch between storage
environment and cache policy– Current buffer cache policies lack device
information
• Policies need to include storage environment information
• Our solution: Generic partitioning framework– Aggregates performance information– Adapts quickly– Allows for use of existing policies
21
Questions?
More information at www.cs.wisc.edu/wind

22

23
Future work
• Implementation in Linux
• Cost-benefit algorithm
• Study of integration with prefetching and layout

24
Problems with LANDLORD
• Does not mesh well with unified buffer caches (assumes LRU)
• LRU-based: not always desirable– Example: Databases
• Suffers from a “memory effect”– Can be much slower to adapt

25
Disk aging of an IBM 9LZXAge (years) Bandwidth (MB/s) Avg. seek time
(ms)Avg. rotational delay (ms)
0 20.0 5.30 3.00
1 14.3 5.89 3.33
2 10.2 6.54 3.69
3 7.29 7.27 4.11
4 5.21 8.08 4.56
5 3.72 8.98 5.07
6 2.66 9.97 5.63
7 1.90 11.1 6.26
8 1.36 12.3 6.96
9 0.97 13.7 7.73
10 0.69 15.2 8.59

26
Web without writes• Workload: Web workload where writes are replaced with reads
• Eager LRU and LANDLORD are the most robust.
0
20
40
60
80
100
120
140
160
180
6 6.5 7 7.5 8 8.5 9 9.5 10
Age of slow disk (years)
Throughput (MB/s)
Eager LRULazy LRU
0
20
40
60
80
100
120
140
160
180
0 1 2 3 4 5 6 7 8 9 10
Age of slow disk (years)
Throughput (MB/s)
Eager LRULANDLORDLazy LRULRUNo cache

27

28
Problem illustration
OS
Applications
Fast Slow
Disks

29
Problem illustration
OS
Applications
Fast Slow
Disks

30
Lack of information
buffer cacheOS
Applications
Disks
DFSes, NAS, &new devices
drivers

31
Solution: overview
• Partition the cache– One per device– Cost-oblivious
policies (e.g. LRU) in partitions
– Aggregate device perf.
• Dynamically reallocate pages
buffer cachepolic
y

32
Forms of dynamic partitioning
• Eager– Change sizes
33
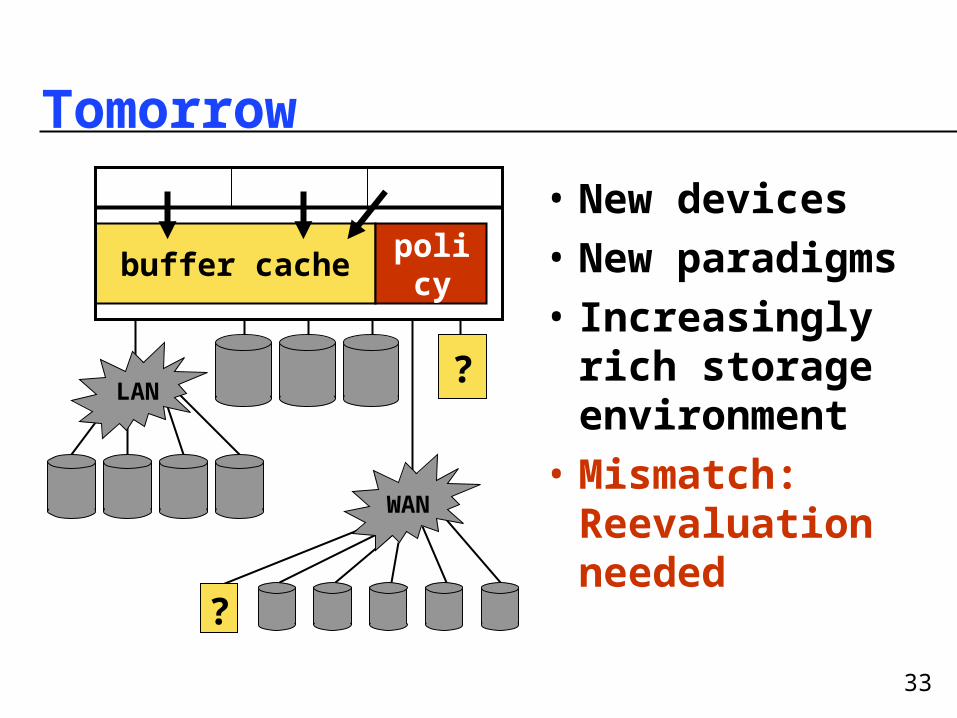
Tomorrow
• New devices
• New paradigms
• Increasingly rich storage environment
• Mismatch: Reevaluation needed
LAN
WAN
buffer cachepolic
y
?
?

34
WiND project
• Wisconsin Network Disks
• Building manageabledistributed storage
• Focus: Local-areanetworked storage
• Issues similar in wide-area


















