
1 Sources Ferragina and Manzini, Opportunistic data structures with applications, FOCS 00 Langmead...
39
1 Sources Ferragina and Manzini, Opportunistic data structures with applications, FOCS 00 Langmead et al. Ultrafast and memory- efficient alignment of short DNA sequences to the human genome, Genome Biology 09 Burrows-Wheeler Transform the not-so-gory details CG © Ron Shamir ‘11
-
Upload
juniper-austin -
Category
Documents
-
view
218 -
download
1
Transcript of 1 Sources Ferragina and Manzini, Opportunistic data structures with applications, FOCS 00 Langmead...

1
SourcesFerragina and Manzini, Opportunistic data
structures with applications, FOCS 00Langmead et al. Ultrafast and memory-efficient
alignment of short DNA sequences to the human genome, Genome Biology 09
Burrows-Wheeler Transform
the not-so-gory details
CG © Ron Shamir ‘11

Burrows-Wheeler Transform:Cyclic shifts sorted
.the_next_text_that_i_index_i_index.the_next_text_that_index.the_next_text_that_i_next_text_that_i_index.the_text_that_i_index.the_next_that_i_index.the_next_textat_i_index.the_next_text_thdex.the_next_text_that_i_ine_next_text_that_i_index.thex.the_next_text_that_i_indext_text_that_i_index.the_next_that_i_index.the_next_that_i_index.the_next_text_the_next_text_that_i_index.t
i_index.the_next_text_that_index.the_next_text_that_i_ndex.the_next_text_that_i_inext_text_that_i_index.the_t_i_index.the_next_text_that_text_that_i_index.the_next_that_i_index.the_next_textext_that_i_index.the_next_that_i_index.the_next_text_the_next_text_that_i_index.x.the_next_text_that_i_indext_text_that_i_index.the_next_that_i_index.the_next_te

Suffix Arrays
• T[1…u] text• Suffix array A of T: sequence
lexicographically ordered suffixes of T represented by pointers to their starting points
• T=ababc A=[1,3,2,4,5]• Requires 4u bytes in practice
3

Burrows-Wheeler Transform
Forward BWT: TL
a.T T# (# unique smallest char)
b. Form conceptual matrix M: all cyclic shifts of T#, sorted lexicographically
c.Transformed text L: the last column of T. L=BWT(T)
Notation: F : first column in M
Close connection to suffix arrays!
4

Key lemmas
• In the i-th row of M, L(i) precedes F(i) in the original text: T=….L(i)F(i)….
• The i-th occurrence of char X in L corresponds to the same text character as the i-th occurrence of X in F
“last-first (LF) mapping”
5

xtietthnhdnttt__i_axx__.eee
LF mapping
._____adeeeehhiinnttttttxxx

Inverting BWT

Backward BWT:a. Compute the array C[1,…|∑|]:
C(c) is the no. of chars {#,1,.. c-1} in T C(c)+1 is the position of 1st occurrence of c in F (if any)
b. Build LF mapping LF{1,..,u+1}: LF[i]=C(L[i])+ri where ri = no of occurrences of char L[i] in the prefix L[1,i]
c. Reconstruct T backward:• s=1, T(u)=L[1]• For i=u-1,…1 do s=LF[s] and T[i]=L[s]
8

Backward BWT (1)
Compute the array C[1,…|∑|]: C(c) is the no. of chars {#,1,.. c-1} in TOcc(c,r) = no. of occurrences of c in BWT
up to but not including the element at index r
Alg Stepleft(r):1. Return C[BWT[r]]
+1+Occ[BWT[r],r]

Backward BWT (2)
a. r1; T” “b. While BWT[r]$ doc. T prepend BWT[r] to rd. rstepleft[r]e. Return T

11
Searching the Index
• Search last nucleotide and expand backwards
• Maintain interval of possible matches
BWT(acaacg$)
Search(aac, gc$aaac)

Alg Exactmatch ( P[1,p] )
1. cP[p]; spC[c]+1; epC[c+1]+1; ip-1
2. While sp<ep and i1 do3. c P[i]4. sp C[c] + Occ(c,sp) + 15. ep C[c] + Occ(c,ep) + 16. i i-17. Return sp, ep

Computing Occ(c,r)
1. Precompute Occ(c,r) naively for each c,r -
Time O(||u), but space O(||ulogu), for text of length u
2. Precompute Occ(c,r) only for r=j*p When Occ(c,r) is needed – if r not
available go back to the previous multiple of p and add
Time O(||u) to preprocess, O(p) to compute
Space O((||ulogu)/p)

Computing the Text location of an exact match
• Problem: Exactmatch P gives row(s) in M that begin with the query – need to find their offset - location in the text
• Solution: – mark some rows with pre-calculated
offsets. – In search, if row is not marked, do
Stepleft k times until finding a marked row with offset o; report o+k
• Time/space tradeoff

Burrows & Wheeler
• David Wheeler (1927-2004)– Educated in Math, Cambridge– First PhD in the world in CS (51)– Invented the subroutine– Cambridge prof. active in cryptography
• Michael Burrows (~1963- )– PhD Cambridge– Worked in DEC, Microsoft, now Google– Co-developed the AltaVista search engine
• Burrows M, Wheeler D (1994), A block sorting lossless data compression algorithm, Technical Report 124, Digital Equipment Corporation

April 27, 2005 Rupali Patwardhan, Capstone Presentation
16
Motif Discovery in Protein Sequences using Messy
de Bruijn Graph
Rupali Patwardhan
Advisors:
Dr. Mehmet Dalkilic
Dr. Haixu Tang

April 27, 2005 Rupali Patwardhan, Capstone Presentation17
What is a motif? • A repeating pattern
• VSKLIPKNRLMISTEWRSLGQQSPGWMHYMP
• VMLPKDIAKLVPKTHLMSTEWRNRLGVQQSQG
• SGVPRLLTASREWRNLGEPFIDQIHYSPRYAD
• YRHVMLPKAMSTEWRSLGLKNPETGTLRILQE
• GLGITQSLGWSREWRHTLGEPHILLFKREKDYQ

April 27, 2005 Rupali Patwardhan, Capstone Presentation18
Why are motifs interesting?
• They represent regions that have been conserved through evolution
• So those regions are likely to be important for the function of the protein (e.g. an active site)
• Motifs can be used to classify proteins into families based on their functions, or predict the function of a new protein

April 27, 2005 Rupali Patwardhan, Capstone Presentation19
What is a de Bruijn Graph?A graph whose nodes are
subsequences of same length (l- tuples) and whose edges indicate the subsequences of the two connected nodes overlap
E.g. An edge ACAT CATS represents the sequence “ACATS”

April 27, 2005 Rupali Patwardhan, Capstone Presentation20
CDEFBCDEABCD
ABCDEFG
DEFG

April 27, 2005 Rupali Patwardhan, Capstone Presentation21
Applying this to Identify Repeating Subsequences
• If we have a set of sequences, we can go on adding corresponding nodes and edges to our de Bruijn graph.
• If any sub-sequence is repeated, the corresponding edge will already be present in that graph.
• So we just increment the weight of that edge.• Eventually the edges corresponding to highly
repeated sequences will have higher weights.• Now we can find the motif by simply following
the graph along these edges with weights above a specified threshold .

April 27, 2005 Rupali Patwardhan, Capstone Presentation22
PAKA ARCDAKAR KARC
RCDECDEK
1 1 11
11
1. PAKARCDEKD1. PAKARCDEKD
DEKD

April 27, 2005 Rupali Patwardhan, Capstone Presentation23
PAKA ARCDAKAR KARC
RCDECDEK
DEKH
1 1 12
21
1. PAKARCDEKD1. PAKARCDEKD
2. NARCDEKHKH2. NARCDEKHKH
DEKD
EKHK KHKH111
NARC
1

April 27, 2005 Rupali Patwardhan, Capstone Presentation24
PAKA ARCDAKAR KARC
RCDECDEK
DEKH
1 1 12
21
1. PAK1. PAKARCDEKARCDEKDD
2. N2. NARCDEKARCDEKHKHHKH
DEKD
EKHK KHKH111
NARC
1

April 27, 2005 Rupali Patwardhan, Capstone Presentation25
Making them Messy • In the context of protein sequences, some
amino acid residues can be substituted by some others without affecting the function of the protein.
• So a sequence could be considered 'similar' to an edge even though its not identical.
• Similarity between amino acid residues is determined using standard scoring matrices, such as BLOSUM62.
• In that case, we increment weights of all edges that represent sequences that are ‘similar’ to the one in question.

April 27, 2005 Rupali Patwardhan, Capstone Presentation26
Example
• Consider the same 2 sequences as before, but with K replaced by R in one of them.
• PAKARCDERD• NARCDEKHKH
• As per BLOSUM62, K R substitution has a positive substitution score.

April 27, 2005 Rupali Patwardhan, Capstone Presentation27
PAKA ARCDAKAR KARC
RCDECDER
CDEK
1 1 12
11
PAKPAKARCDARCDEERRDD NNARCDARCDEEKKHKHHKH
DERD
KHKHDEKH EKHK1 111
NARC
1
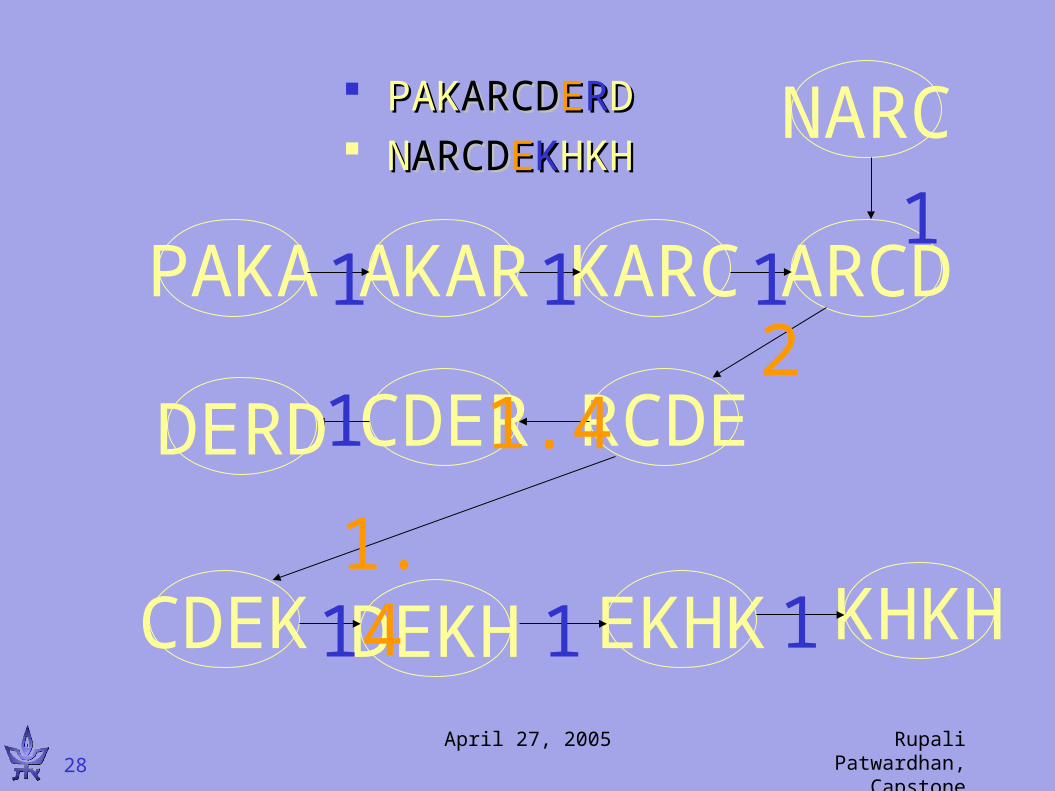
April 27, 2005 Rupali Patwardhan, Capstone Presentation28
PAKA ARCDAKAR KARC
RCDECDER
CDEK
1 1 12
1.41
PAKPAKARCDARCDEERRDD NNARCDARCDEEKKHKHHKH
DERD
KHKHDEKH EKHK1 111.4
NARC
1

April 27, 2005 Rupali Patwardhan, Capstone Presentation29
Adjusting the weights to account for messiness
• Suppose edge A is under consideration, and edges B and C originating from the same node as A are similar to A.
WA’ WA + WB*s(A,B) + WC*s(A,C)

April 27, 2005 Rupali Patwardhan, Capstone Presentation30
Limitation of this Approach• The motif should have at least a few
continuous amino acid residues • So the method may fail if the motif
consists of alternate residues • E.g. AxAxCxDxAxGxC (x could be any
residue) or AxCDxGxRGxC, since these motifs would not lead to high-weight edges in the de Bruijn graph
• The problem is due to the need for overlaps, which is inherent nature of de Bruijn Graphs

April 27, 2005 Rupali Patwardhan, Capstone Presentation31
Gapped Version
• For each node, we also create nodes obtained by applying a gap mask (or “Dont care” mask) on that node
• We currently restrict the maximal number of “Dont cares” in a node to 2
• There are 10 such masks

April 27, 2005 Rupali Patwardhan, Capstone Presentation32
Gapped Version
• Let ‘1’ represent a conserved amino acid and ‘0’ represent a gap or “Don’t care”
• Then the 10 masks can be represented as:1111, 0111, 1110, 1011, 1101, 1100, 0011, 1001, 0110, 1010, 0101

April 27, 2005 Rupali Patwardhan, Capstone Presentation33
Masking Example
• If ANCD is the node that we are applying the mask to
• ANCD * 1001 = AxxD• ANCD * 1101 = ANxD• ANCD * 1011 = AxCD

April 27, 2005 Rupali Patwardhan, Capstone Presentation34
ARCDRCDM1
1. ….ARCDM…1. ….ARCDM…
2. ….ANCDE…2. ….ANCDE…
3. ….ASCDT…3. ….ASCDT…
ANCDNCDE1
ASCD SCDT1

April 27, 2005 Rupali Patwardhan, Capstone Presentation35
AxCD xCDx1
1. ….ARCDM…1. ….ARCDM…
2. ….ANCDE…2. ….ANCDE…
3. ….ASCDT…3. ….ASCDT…
AxCD xCDx1
AxCD xCDx1

April 27, 2005 Rupali Patwardhan, Capstone Presentation36
AxCD xCDx
1. ….ARCDM…1. ….ARCDM…
2. ….ANCDE…2. ….ANCDE…
3. ….ASCDT…3. ….ASCDT…
AxCD xCDx
AxCD xCDx
3

AxCDxxGH
ANCDAxCDANxDANxxxxCDAxxDxNCxAxCxxNxD
CDEFCxEFCDxFCDxxxxEFCxxFxDExCxExxDxF
NCDENxDENCxENCxxxxDENxxExCDxNxDxxCxE
DEFGDxFGDExGDExxxxFGDxxGxEFxDxFxxExG
EFGHExGHEFxHEFxxxxGHExxHxFGxExGxxFxH
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.

Protein binding microarrays
• Measure TF binding to many sequences.
38
(berger et al. 06)

Sequence design using de Bruijn graphs
• Complete de Bruijn graphs represent all k-mers (by edges).
• The graph is strongly connected, and each vertex is degree-balanced.
• An Euler tour traverses each edge exactly once.
• The resulting tour corresponds to a de Bruijn sequence.
39


















