

1 Processing Recursive Xquery over XML Streams: The Raindrop Approach Mingzhu Wei Ming Li Elke A....
22
1 Processing Recursive Xquery over XML Streams: The Raindrop Approach Mingzhu Wei Ming Li Elke A. Rundensteiner Murali Mani Worcester Polytechnic Institute XSDM Workshop, 2006 Supported by USA National Science Foundation
-
date post
22-Dec-2015 -
Category
Documents
-
view
217 -
download
0
Transcript of 1 Processing Recursive Xquery over XML Streams: The Raindrop Approach Mingzhu Wei Ming Li Elke A....

1
Processing Recursive Xquery over XML Streams: The Raindrop Approach
Mingzhu WeiMing Li
Elke A. RundensteinerMurali Mani
Worcester Polytechnic InstituteXSDM Workshop, 2006
Supported by USA National Science Foundation
Mingzhu Wei

2
What’s Special for XML Streams
<person>
Token-by-Token access manner
timeline
Token: not a counterpart of a self-contained tuple
Pattern Retrieval on Token Streams
<name>
Jack, Brooks
</name>
</person>
Q1: for $a in stream(“persons”)//person
return $a, $a//name
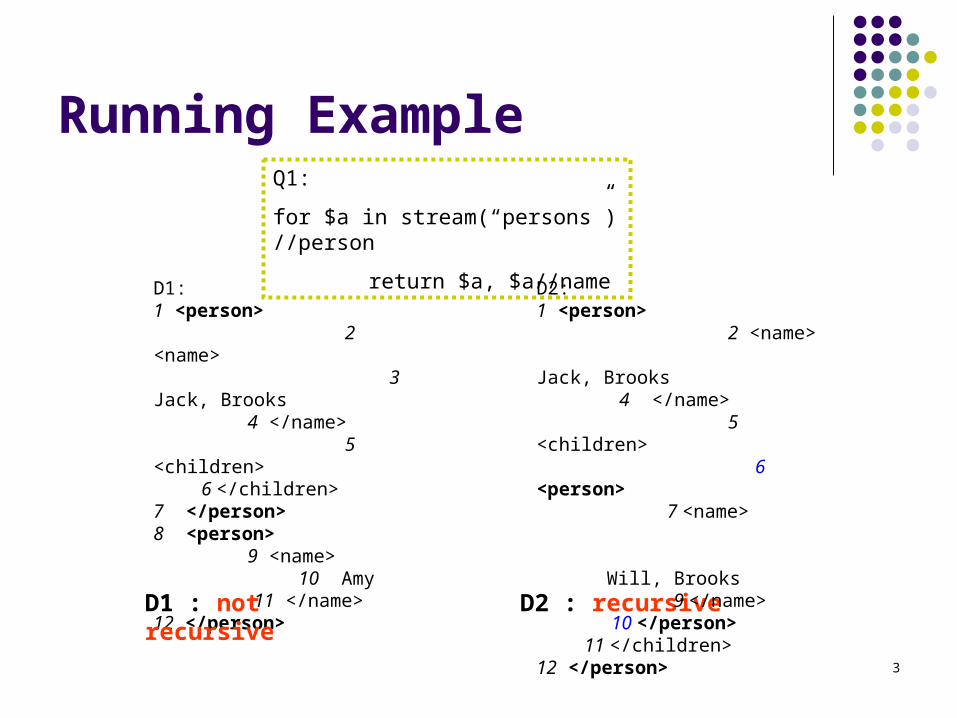
3
Running Example
D1:1 <person>
2 <name> 3
Jack, Brooks 4 </name>
5 <children>
6 </children>7 </person>8 <person> 9 <name> 10 Amy 11 </name>12 </person>
D1 : not recursive D2 : recursive
Q1:
for $a in stream(“persons”)//person
return $a, $a//nameD2:1 <person>
2 <name> Jack,
Brooks 4 </name>
5 <children> 6 <person>
7 <name>
Will, Brooks 9 </name> 10 </person>11 </children>
12 </person>
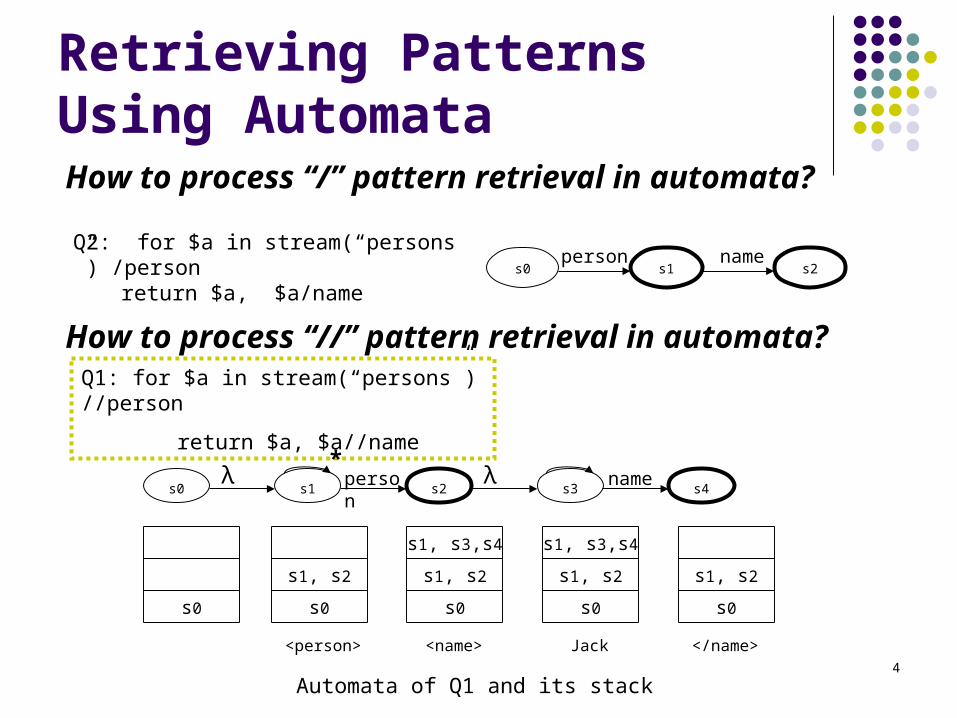
4
Retrieving Patterns Using Automata
Q2: for $a in stream(“persons”) /personreturn $a, $a/name s0
persons1
names2
How to process “/” pattern retrieval in automata?
How to process “//” pattern retrieval in automata?
λs0 s1
persons2
λs3
names4
Automata of Q1 and its stack
<person> <name>
s0
s1, s2
s0
s1, s2
s0
s1, s3,s4
s1, s2
s0
s1, s3,s4
Jack </name>
s1, s2
s0
Q1: for $a in stream(“persons”)//person
return $a, $a//name*
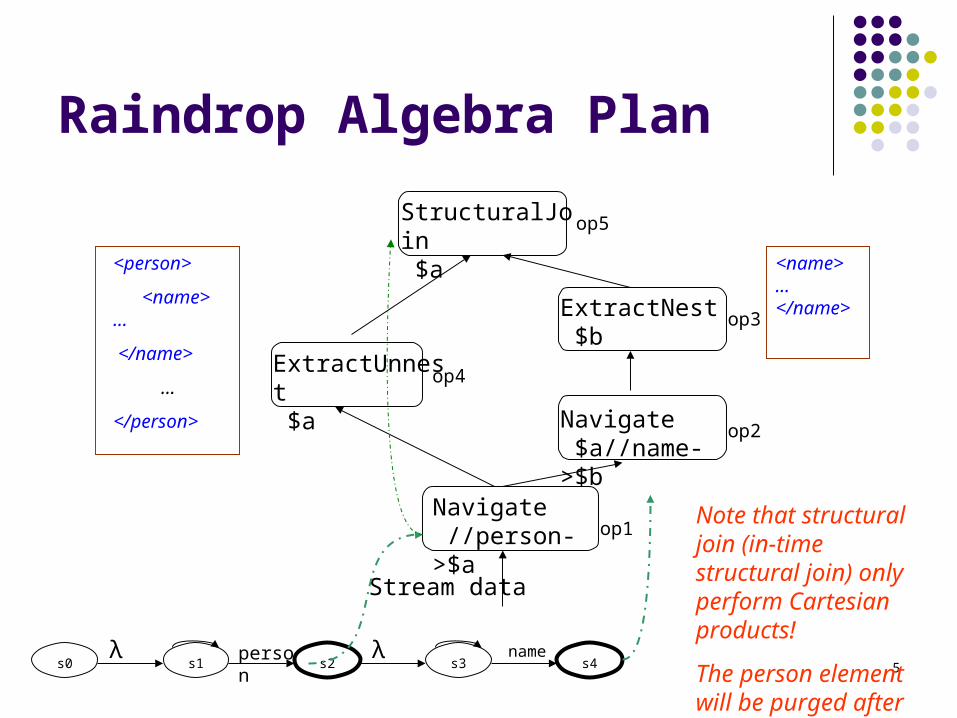
5
Raindrop Algebra Plan
Stream data
op1
op5
λs0 s1
person
s2λ
s3name
s4
op2
op4
op3
ExtractUnnest $a
Navigate //person->$a
Navigate $a//name->$b
ExtractNest $b
StructuralJoin $a
<person>
<name> …
</name>
…
</person>
<name>…</name>
Note that structural join (in-time structural join) only perform Cartesian products!
The person element will be purged after generating output!
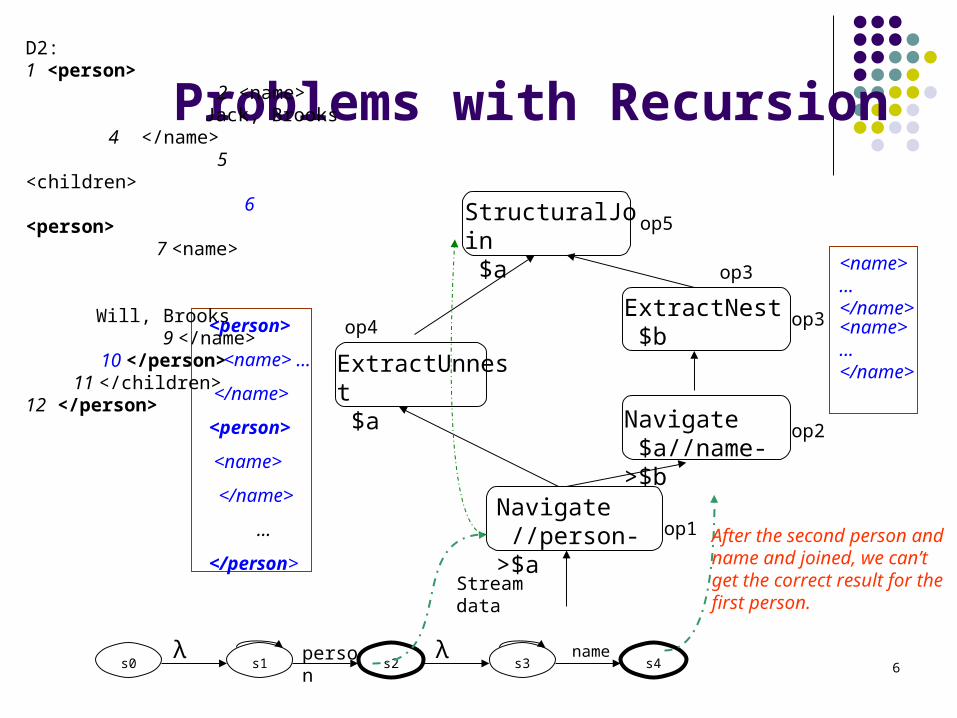
6
Problems with Recursion
Stream data
op1
op5
λs0 s1
person
s2λ
s3name
s4
op2
op4 op3
ExtractUnnest $a
Navigate //person->$a
Navigate $a//name->$b
ExtractNest $b
StructuralJoin $a
<person>
<name> …
</name>
<person>
<name>
</name>
…
</person>
<name>…</name>
<name>…</name>
D2:1 <person>
2 <name> Jack, Brooks 4 </name>
5 <children> 6 <person>
7 <name>
Will, Brooks 9 </name> 10 </person>11 </children>
12 </person>
After the second person and name and joined, we can’t get the correct result for the first person.
op3

7
Goals
How to correctly process recursive data and recursive queries?
How to guarantee that data is output as early as possible?
When data is non-recursive, how to make the cost of the plan as cheap as possible?

8
Recursive-Mode Operators Each operator has recursive mode operator Associate IDs with elements
Each element is associated with a triple (startID, endID, level) Given two elements and the corresponding triples, we can de
termine ancestor-descendent and parent-child relationships.
1 <person>2
<name>
Jack 4 </name>
5 <children>
6 <person>
7 <name>
Amy 9 </name> 10 </person>11 </children>
12 </person>
1, 12, 1
2, 4, 2
9
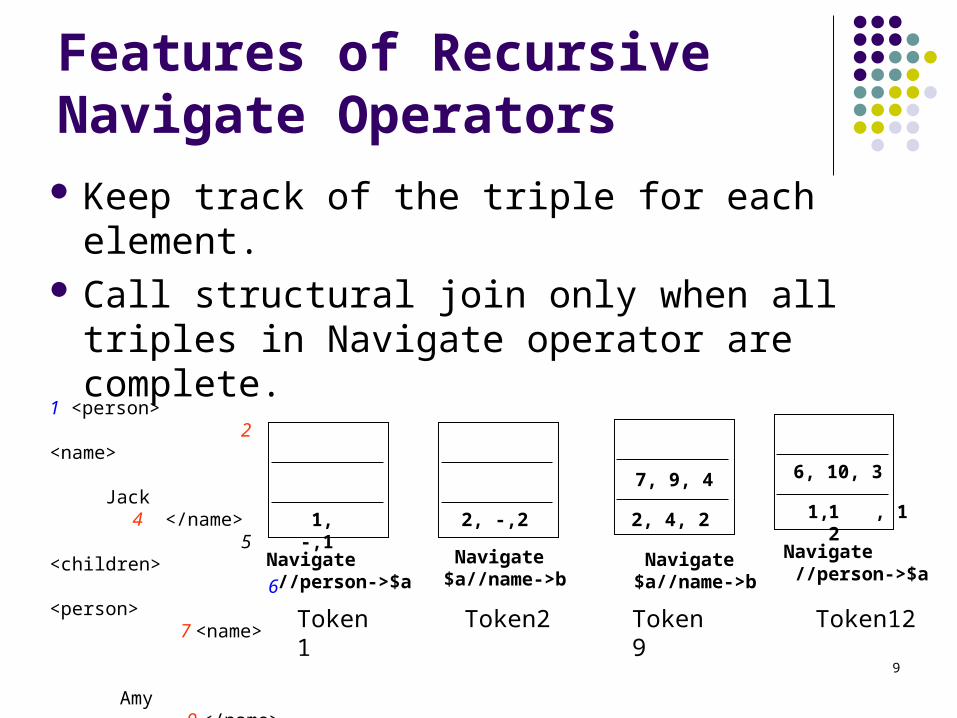
Features of Recursive Navigate Operators Keep track of the triple for each element. Call structural join only when all triples in
Navigate operator are complete.
1, -,1 2, -,2 2, 4, 2
7, 9, 4
1 <person>2
<name>
Jack 4 </name>
5 <children>
6 <person>
7 <name>
Amy 9 </name> 10 </person>11 </children>
12 </person>
Navigate //person->$a
Navigate $a//name->b
Navigate $a//name->b
Token1 Token2 Token 9
6, 10, 3
Navigate //person->$a
12
Token12
1, , 1

10
Features of Recursive Extract Operators
ExtractUnnest Compose the tokens into tuples Associate ID information for each corresponding e
lement ExtractNest
Collect the tokens and creates one tuple for the whole collection.
Move the groupby functionality to the top structural join
11
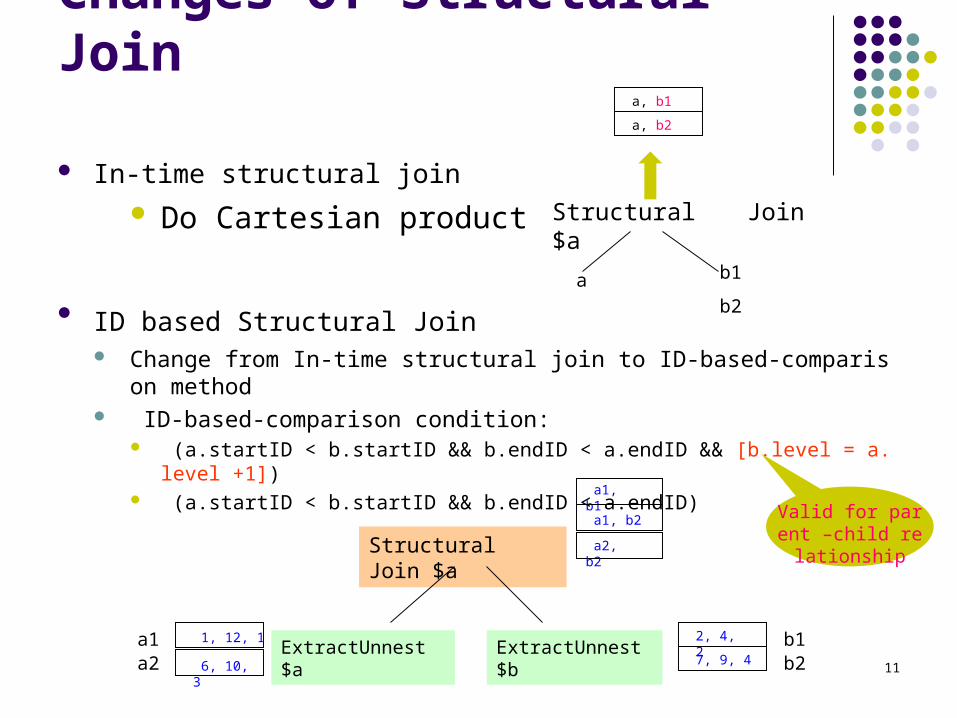
Changes of Structural Join
In-time structural join
Do Cartesian product
ID based Structural Join Change from In-time structural join to ID-based-comparison method ID-based-comparison condition:
(a.startID < b.startID && b.endID < a.endID && [b.level = a.level +1]) (a.startID < b.startID && b.endID < a.endID)
Structural Join $a
a b1
b2
a, b1
a, b2
Structural Join $a
ExtractUnnest $a2, 4, 2
7, 9, 4
1, 12, 1
a1, b1
ExtractUnnest $b 6, 10, 3
a1, b2
a2, b2
Valid for parent –child relationship
a1a2
b1b2
12
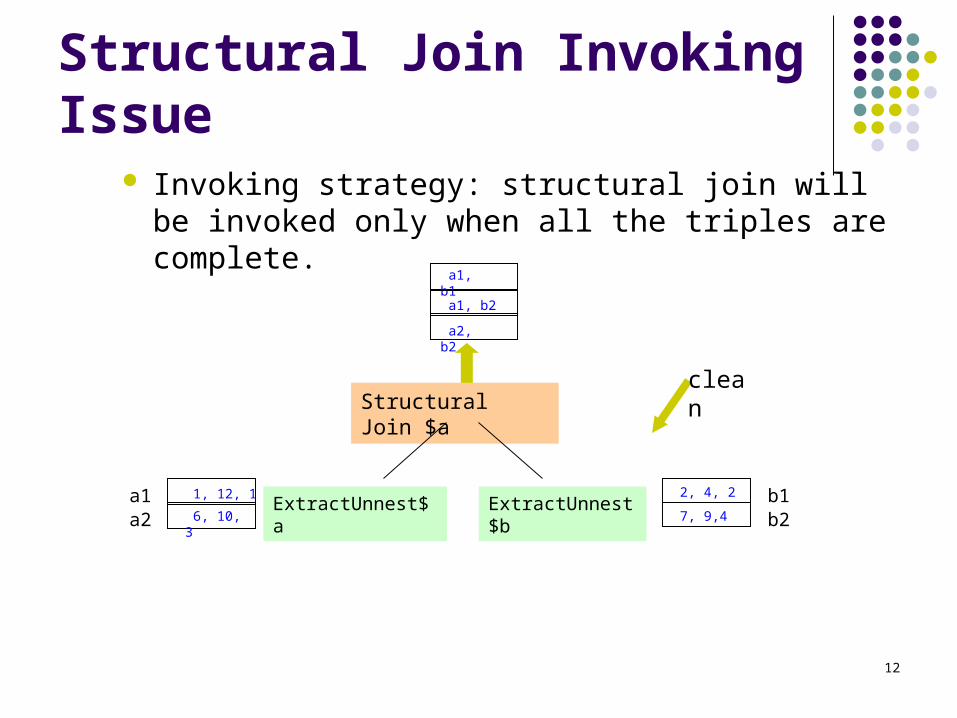
Structural Join Invoking Issue Invoking strategy: structural join will be invoked only
when all the triples are complete.
Structural Join $a
ExtractUnnest$a2, 4, 2
7, 9,4
1, 12, 1
a1, b1
ExtractUnnest$b 6, 10, 3
a1, b2
a2, b2
a1a2
b1b2
clean
13
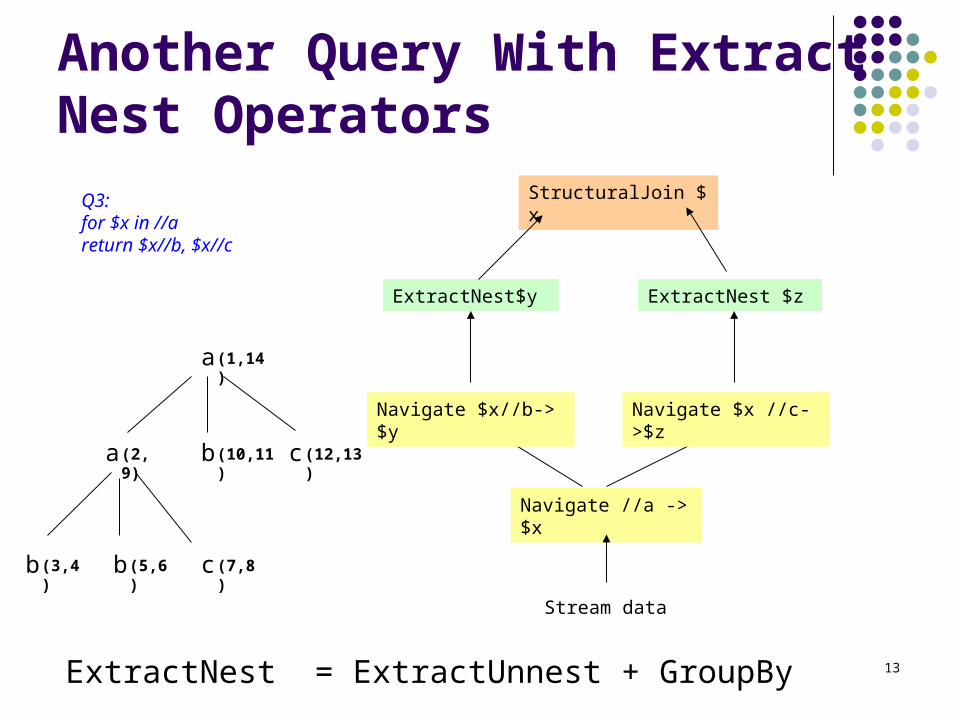
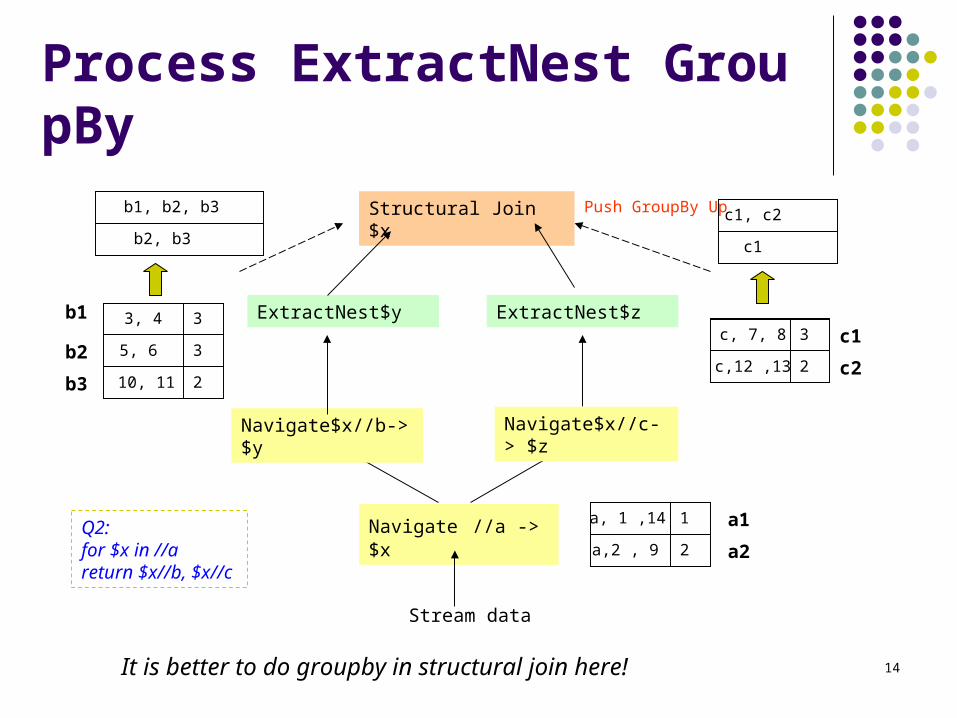
Another Query With ExtractNest Operators
StructuralJoin $x
ExtractNest$y ExtractNest $z
Navigate //a -> $x
Stream data
Navigate $x //c->$z
Q3:for $x in //areturn $x//b, $x//c
ExtractNest = ExtractUnnest + GroupBy
Navigate $x//b-> $y
a
a b c
b b c
(1,14 )
(2, 9) (10,11) (12,13 )
(3,4) (5,6) (7,8)
14
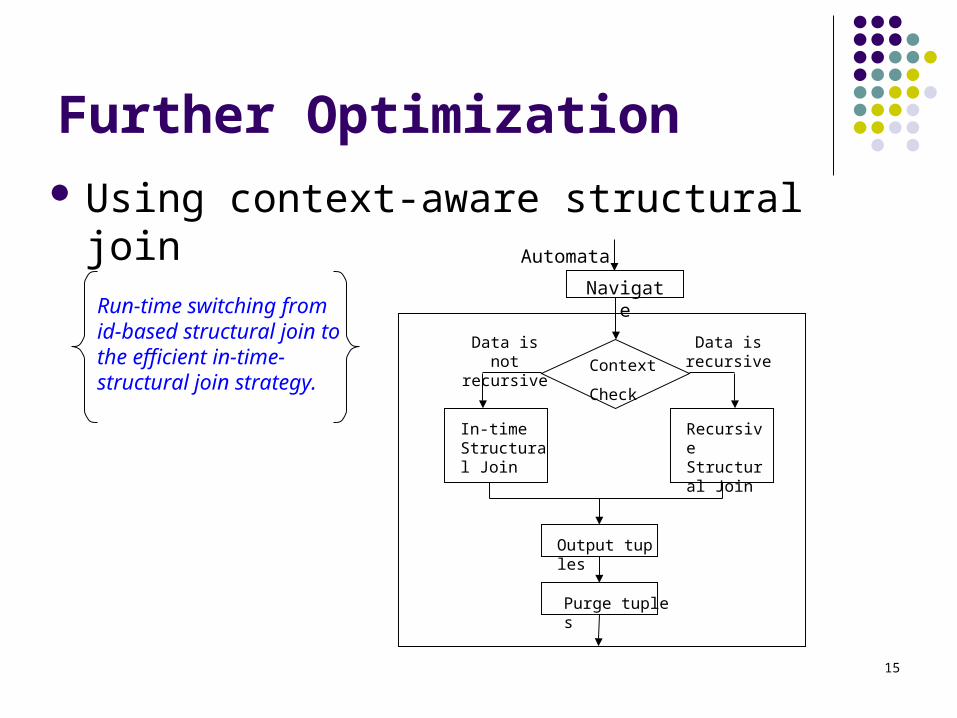
Process ExtractNest GroupBy
Structural Join $x
ExtractNest$y
Navigate //a -> $x
Navigate$x//b-> $y
Stream data
3, 4
5, 6
10, 11
3
3
2
c, 7, 8
c,12 ,13
3
2
1
2a,2 , 9
a, 1 ,14
c1
c1, c2
b2, b3
b1, b2, b3 Push GroupBy Up
Navigate$x//c-> $z
ExtractNest$z
Q2:for $x in //areturn $x//b, $x//c
It is better to do groupby in structural join here!
b1
b2
b3
c1
c2
a1
a2
15
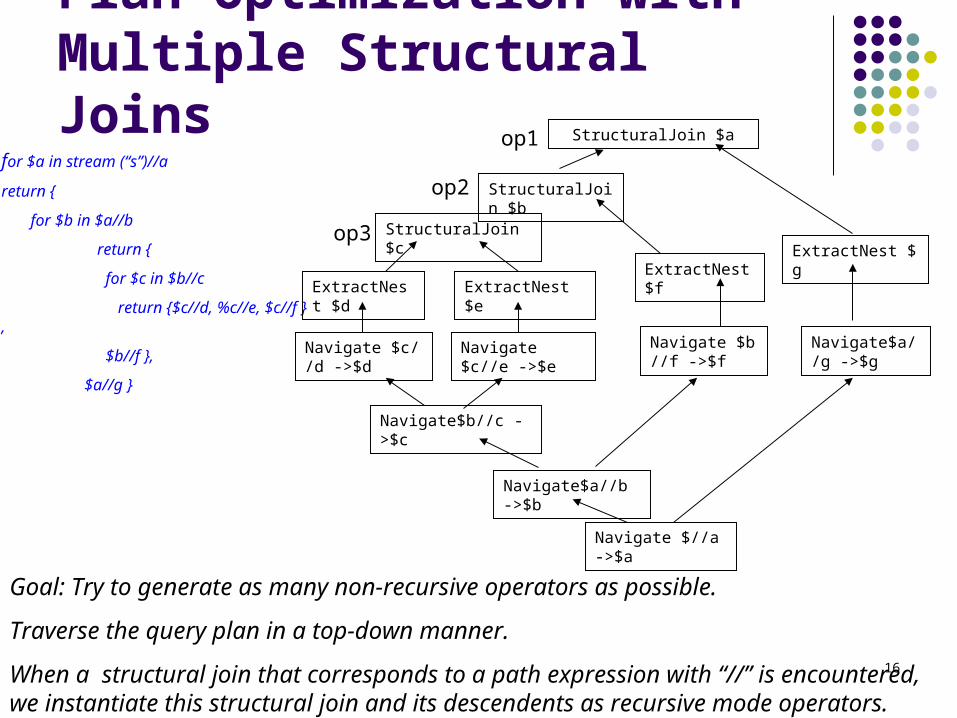
Further Optimization Using context-aware structural join
Context
Check
Automata
Recursive Structural Join
In-time Structural Join
Output tuples
Purge tuples
Navigate
Data is recursive
Data is not recursive
Run-time switching from id-based structural join to the efficient in-time- structural join strategy.
16
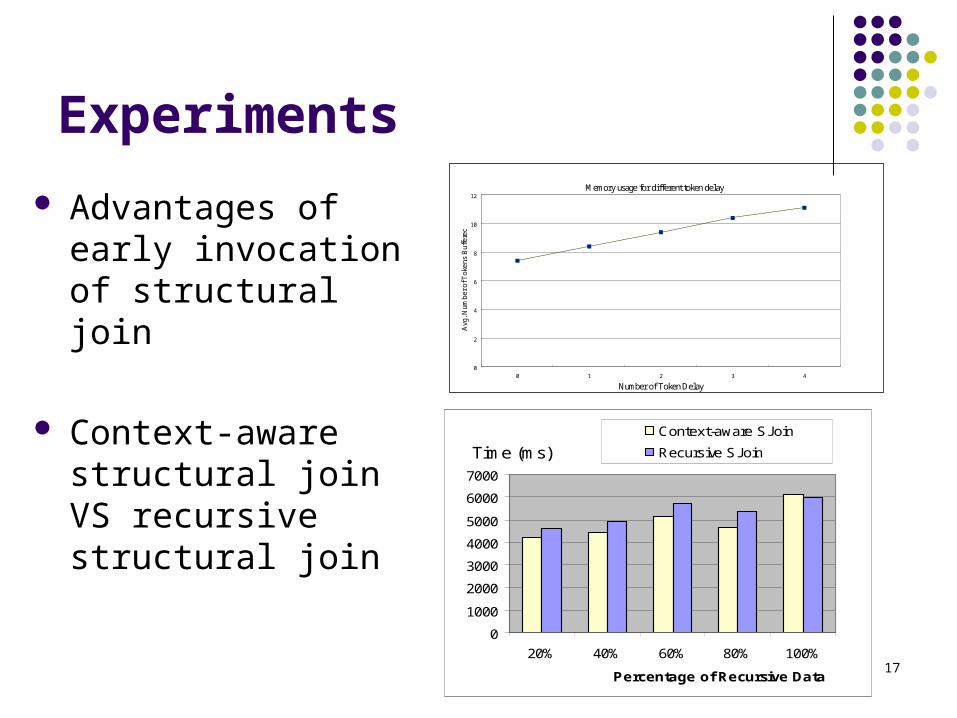
Plan Optimization with Multiple Structural Joins
for $a in stream (“s”)//a
return {
for $b in $a//b
return {
for $c in $b//c
return {$c//d, %c//e, $c//f },
$b//f },
$a//g }
StructuralJoin $a
ExtractNest $g
StructuralJoin $b
StructuralJoin $c
Navigate$a//g ->$g
ExtractNest $f
op1
ExtractNest $d
ExtractNest $e
Navigate $//a ->$a
Navigate$a//b ->$b
Navigate$b//c ->$c
Navigate $c//d ->$d
Navigate$c//e ->$e
Navigate $b//f ->$f
op2
op3
Goal: Try to generate as many non-recursive operators as possible.
Traverse the query plan in a top-down manner.
When a structural join that corresponds to a path expression with “//” is encountered, we instantiate this structural join and its descendents as recursive mode operators.
17
Experiments
Advantages of early invocation of structural join
Context-aware structural join VS recursive structural join
Memory usage for different token delay
0
2
4
6
8
10
12
0 1 2 3 4
Number of Token Delay
Avg
. Num
ber o
f To
kens
Buf
fere
dTime (ms)
0
1000
2000
3000
4000
5000
6000
7000
20% 40% 60% 80% 100%
Percentage of Recursive Data
Context-aware SJoin
Recursive SJoin
18
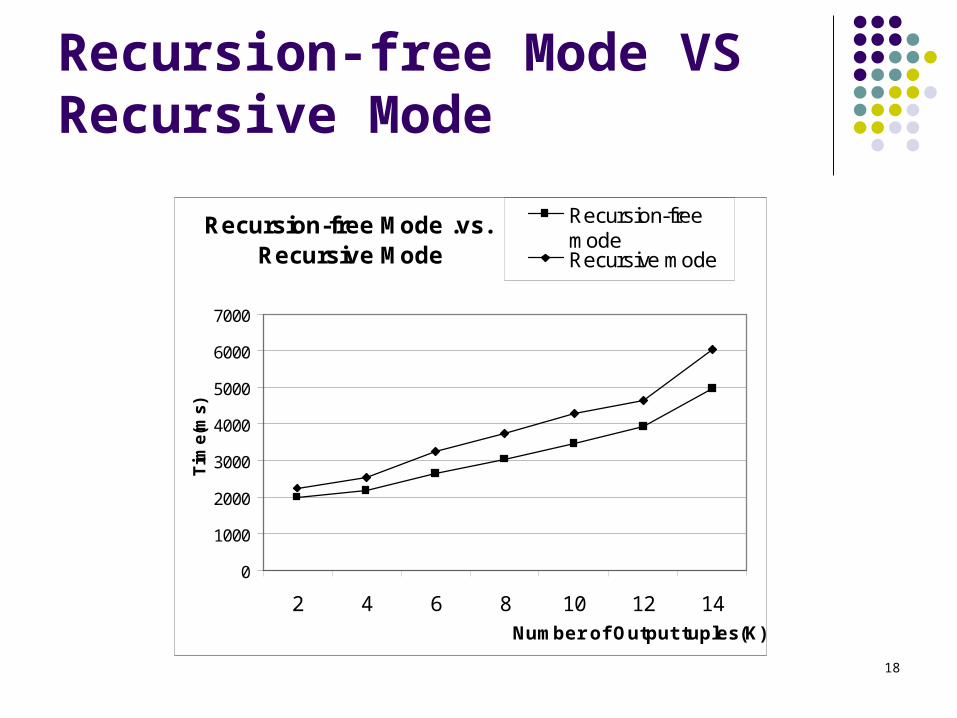
Recursion-free Mode VS Recursive Mode
Recursion-free Mode .vs. Recursive Mode
0
1000
2000
3000
4000
5000
6000
7000
2 4 6 8 10 12 14Number of Output tuples(K)
Tim
e(m
s)Recursion-freemodeRecursive mode

19
Related work
Stack-Tree-Anc[AJK02] Use stack to store the chain of ancestor candidates Can be combined to our system
Transducer-based XML query processor[LPY02] FSA without stack are not sufficient for handling recursion.
YFilter: NFA-based path navigation [DF03] Do not guarantee that the structural join is processed at firs
t possible moment

20
Conclusions
Propose a new class of stream operators for recursive XQuery stream processing
Propose a context-aware structural join Use cheaper algebra operators whenever
possible in plan generation Illustrate performance benefits with little
overhead in experiments

22


















