
1 EquiCast Scalable Multicast with Selfish Users Idit Keidar, Roie Melamed, Ariel Orda Technion.
date post
21-Dec-2015Category
view
219download
1
1
Principles of Reliable Distributed Systems
Lecture 11: Disk Paxos and
Quorum Systems
Spring 2007
Prof. Idit Keidar

2
Benign Shared Memory Model
• Shared memory registers/objects.
• Accessed by processes with ids 1,2,…
• All communication through shared memory!
• Algorithms must be wait-free: i.e., must tolerate any number of process (client) failures.

3
What is it good for?
• Message-passing systems– Registers implemented using ABD
• Storage Area Networks (SAN)– Disk functionality is limited (R/W)– Disks cannot communicate
• Large scale client/server systems– Simple servers that do not communicate with
each other scale better, manage load better

4
Consensus in Shared Memory
• A shared object supporting a method decide(vi)i returning a value di
• Satisfying:– Agreement: for all i and j di=dj
– Validity: di=vj for some j
– Termination: decide returns

5
Solving Consensus in/with Shared Memory
• Assume asynchronous shared memory system with atomic read/write registers
• Can we solve consensus?– Consensus is not solvable if even one process
can fail. Shared-memory version of [FLP]: write stands for send, read for receive.
– Yes, if no process can fail
• What about read-modify-write objects?

6
General Atomic Read-Modify-Write (RMW) Register
• Defined using a function f( )
• Given f(), RMW on register x is defined as atomically executing:
x.RMW(v):tmp x.Valx.Val f(tmp, v) /* Modify x.Val */ return tmp /* Return old Val */

7
Wait-Free Consensus with RMW Register
x.RMW(v):tmp x.Val;if (x.Val = )
x.Val vreturn tmp
Decide(inp)i:return X.RMW(inp)
Shared: X, read-modify-write register, f(Val, v) (Val = ? v : Val )Initially, X.Val=
x.Val f(tmp, v)

8
Shared Memory (SM) Paxos
• Consensus – In asynchronous shared memory – Using wait-free regular read/write registers– And (why?)
• Wait-free – Any number of processes may fail
• Unlike message-passing model (why?)
– Only the leader takes steps

9
Regular Registers
• SM Paxos can use registers that provide weaker semantics than atomicity
• SWMR regular register: a read returns– Either a value written by an overlapping write
or – The register’s value before the first write that
overlaps the read

10
write(0)
Regular versus Atomic
time
read(1)
read(0)
write(1)
time
write(1) already
happened
Regular canreturn 0
not
linearizable

11
Variables
• Reminder: Paxos variables are:– BallotNum, AcceptVal, AcceptNum
• SM version uses shared SWMR regular registers:– xi = bal, val, num, decisioni for each process i
– Initially 0,0, , 0,0, – Writeable by i, readable by all
• Each process keeps local variables b,v,n– Initially 0,0, , 0,0

12
Reminder: Paxos Phase I
• if leader (by ) thenBallotNum choose new unique ballot
send to all
• Upon receive (“prepare”, bal) from iif bal BallotNum then
BallotNum bal
send (ack, bal, AcceptNum, AcceptVal) to i
• Upon receive (ack, BallotNum, num, val) from n-t
if all vals = then myVal initial value
else myVal received val with highest num
n-t must have not moved on

13
SM Paxos: Phase I
if leader (by ) thenb choose new unique ballot
write b,v,n, to xi
read all xj’sif some xj.bal > b then start over
if all read xj.val’s = then v my initial value
else v read val with highest num
Write is like sending to all
Read instead of waiting for acks
No ack: someone
moved on!

14
Phase I Summary
• Classical Paxos: – Leader chooses new
ballot, sends to all
– Others ack if they did not move on to a later ballot
– If leader cannot get a majority, try again
– Otherwise, move to Phase 2
• SM Paxos:– Leader chooses new
ballot, writes his variable
– Leader reads to check if anyone moved on to a later ballot
– If anyone did, try again
– Otherwise, move to Phase 2

15
Reminder: Paxos Phase II
send (“accept”, BallotNum, myVal) to all
Upon receive (“accept”, b, v) with b BallotNum
AcceptNum b; AcceptVal vsend (“accept”, b, v) to all (first time only)
Upon receive (“accept”, b, v) from n-tdecide vsend (“decide”, v) to all

16
SM Paxos: Phase IILeader Cont’d
n b
write b,v,n , to xi
read all xj’s
if some xi.bal > b then start over
write b,v,n,v to xi
return v
Read to see if all would
have accepted this proposal
When don’t they?

17
Why Read Twice?
readwrite(b) write read
readwrite(b’>b)
write(b’) did not complete
write(b’>b)read
read does not see b’

18
Adding The Non-Leader Code
while (true)
if leader (by ) then
[ leader code from previous slides ]
else
read xld ,were ld is leader
if xld.decision ≠ then
return xld.decision
start over means go here

19
Liveness
• The shared memory is reliable
• The non-leaders don’t write– They don’t even need to be “around”
• The leader only fails if another leader competes with it– Contention– By , eventually only one leader will compete

20
Validity
• Leader always proposes its own value or one previously proposed by an earlier leader– Regular registers suffice

21
Agreement
readwrite(b) write read write decision
no write(b’) for b’>b
completed
write(b’>b) read
read does not see any b’>b
write
read sees value written
with b
writes value written with b

22
Homework Question
• Formally write down agreement proof– Hint: look at first decided value, prove by
induction that all subsequent decisions the same

23
Termination
• When one correct leader exists– It eventually chooses a higher b than all those
written– No other process writes– So it decides
• Any number of processes can fail• How can it be possible? Didn’t we show a
majority of correct processes is needed?

24
Optimization
• As in the message passing case….
• The first write does not write consensus values
• A leader running multiple consensus instances can perform the first write once and for all and then perform only the second write for each consensus instance

25
Leases
• We need eventually accurate leader ()– But what does this mean in shared memory?
• We would like to have mutual exclusion– Not fault-tolerant!
• Lease: fault-tolerant, time-based mutual exclusion– Live but not safe in eventual synchrony model

26
Using Leases
• A client that has something to write tries to obtain the lease – Lease holder = leader– May fail…
• Example implementation:– Upon failure, backoff period
• Leases have limited duration, expire• When is mutual exclusion guaranteed?

27
Lock versus Lease
• Lock is blocking– Using locks is not wait-free– If lock holder fails, we’re in trouble
• Lease is non-blocking– Lease expires regardless whether holder fails
• Lock is always safe– Never two lock-holders
• Lease is not – Good for indulgent algorithms, like Paxos

28
Disk Paxos
[Gafni,Lamport 00]

29
Data-centric Replication
• A fixed collection of persistent data items accessed by transient clients
• Data items have limited functionality– E.g., read/write registers, or– An object of a certain type
• Data items can fail
• Cannot communicate with one another

30
System Model: Fault-Prone Memory
• n fault-prone shared-memory objects– called base objects– or n servers or disks storing base objects– t out of n can fail
• m processes (clients) – any number can fail (wait free)

31
Disk Paxos
• Implementing consensus using n > 2t fault-prone disks (crash failures)
• Solution combines:– m-process shared memory Paxos and– ABD-like emulation of shared registers from
fault-prone ones
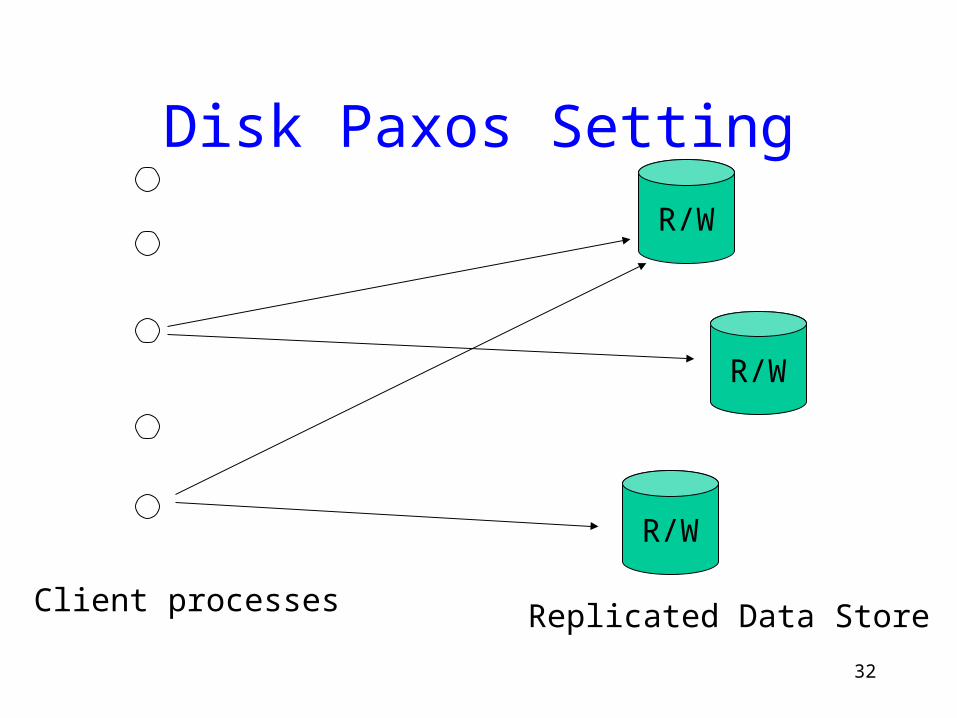
32
Disk Paxos Setting
R/W
R/W
R/W
Replicated Data StoreClient processes

33
Disk Paxos Data Structures
m processes
n disks
1
2
3
4
5
b,v,n,d
1 2 3
Process i can write block[i][j], for each disk j, can read all blocks
x2
b,v,n,d b,v,n,d

34
Read Emulation
• In order to read xi
– Issue read block[i][j], for each disk j– Wait for majority of disks to respond– Choose block with largest b,n
• Is this enough?– How did ABD’s read emulation work?

35
does not find a written
copy,returns 0
write(0)
One Read Round Enough for Regular
time
read(1)
read(0)
write(1)
time
returning 0 is OK for regular
finds a copy that was written

36
Write Emulation
• In order to write xi
– Issue write block[i][j], for each disk j– Wait for majority of disks to respond
• Is this enough?

37
Quorum Systems
Generalization of Majority

38
Why Majority?
• In indulgent algorithms (e.g., Paxos) we assumed a majority of the processes are correct.
• But what we really need is:
If Q1, Q2 are sets of processes that can decide
whenever all processes in P-Q1 or P-Q2 crash,
then Q1 and Q2 intersect.

39
1st Generalization: Weighted Voting [Gifford 79]
• Each process has a weight.– Like share-holders in a corporation.
• In order to make progress, need “votes” from a set of processes that have a majority of the weights (shares).
• Special cases:– Each process has weight 1 – majority.– One process has all the weights – singleton.

40
Definition of Quorum System
• A quorum system over a universe U of n processes is a collection of subsets of U (called quorums) such that every two quorums intersect.
• Examples: – Singleton: QS = {{pi}}
– Majority: QS = {Q U: |Q| > n/2}

41
The Grid Quorum System
• A quorum consists of one row plus one cell from each row above it.
p1 p2 p3 p4 p5
p6 p7 p8 p9 p10
p11 p12 p13 p14 p15
p16 p17 p18 p19 p20
p21 p22 p23 p24 p25

42
Advantages of Quorum Systems
• Availability– Allow faulty/slow servers to be avoided (up to
a certain threshold)
• Load balancing– Each server participates only in a fraction of
quorums and therefore is accessed only a fraction of overall accesses
• Fundamental tradeoff: load vs. availability

43
Coteries and Domination
• A coterie is a quorum system in which no quorum is a subset of another quorum.– Obtained from a quorum system by removing
supersets and keeping only minimal quorums
• A coterie QS dominates a coterie QS’ if every quorum Q’QS’ is a superset of some quorum in Q QS
• A non-dominated coterie is not dominated

44
Quorum Sizes
• Majority: O(n)
• Grid: O(Sqrt(n))
• Primary Copy: O(1)
• Weighted Majority: varies

45
The Load of a Quorum System
• The probability of accessing the busiest server in the best case, i.e., using a strategy that minimizes the load, and when no failures occur
• An access strategy for QS is a probability distribution for accessing the quorums in QS
• The load of a server under a strategy is the probability that this server is in the accessed quorum

46
Availability of a Quorum System
• The resilience f of QS is the number of failures QS is guaranteed to survive– After f failures there is always a live quorum
• Failure probability– Assume that each server fails independently
with probability p
– Fp(QS) is the probability that all quorums in QS are hit, i.e., no quorum survives

47
Examples
• Majority– Best availability (smallest failure rate) for p<½– Worst availability for p > ½– Load is close to ½
• Singleton– Fp = p (optimal when p > ½)– Load is 1
• Grid– Load O(1/Sqrt(n))– Resilience of Sqrt(n)-1– Failure probability goes to 1 as n grows

48
Course Summary

49
Main Topics
• State machine replication for consistency and availability.– Uses Atomic Broadcast.– Uses Consensus.
• Asynchronous Message-Passing Models– Consensus impossible– Solvable with eventual synchrony, failure detectors S, – In two communication rounds in “fast” case
• Shared memory– Convenient model– Can be emulated using message-passing– Good for “data-centric” replication

50
Course Summary (What I Hope You Learned…)
• Distributed systems are subtle.– It’s very easy to get things wrong– Lesson: don’t design a distributed system
without proving the algorithm first!
• Redundancy is the key to reliability.– Multiple replicas: 2t+1, 3t+1, etc.
• Strong consistency is attainable but costly and has scalability limitations.

51
Have a Great August!


















