
1 Part 4: Compressing XML Data Managing XML and Semistructured Data.
115
1 Part 4: Compressing XML Data Managing XML and Semistructured Data
-
date post
22-Dec-2015 -
Category
Documents
-
view
221 -
download
0
Transcript of 1 Part 4: Compressing XML Data Managing XML and Semistructured Data.

1
Part 4: Compressing XML Data
Managing XML and Semistructured Data

2
In this sectionIn this section XML Compression
• Motivation• The State-of-the-Art
Queriable compressors Non-queriable compressors
Resources XMILL: An Efficient Compressor for XML Data by Liefke and Suciu,
in SIGMOD'2001 Others: XGrind, XPress, XQuec, XMLzip, … XCQ: From my publications XQZip: From my publications MQX : From my publications

3
IntroductionIntroduction More and more XML data is created
• Duplicate structures (tags, paths …)• Data inflation: data in XML is much larger than
raw data• Compression: storage and data transfer
General-purpose compressor (e.g. gzip)• Characteristics of XML data not utilized• Unqueriable

4
Compression: The ProblemCompression: The Problem
XML for exchange (space or time) But XML is verbose and inflated due to
• Duplicated tags and paths Users prefer application specific formats:
• Eg. Web Server Logs Is XML doomed to fail ? Solution: XML-specific compressor
• Non-queriable: XMill• Queriable: XQzip

5
XML-Specific CompressorsXML-Specific Compressors Unqueriable Compression (e.g. XMill):
• Full-chunked: data commonalities eliminated• Very good compression ratio
Queriable Compression (e.g. XGrind, XPRESS):• Fine-grained: data commonalities ignored• Inadequate compression ratio and time• Support simple path queries with atomic predicate

6
Issues in XML CompressionIssues in XML Compression Compression ratios, Compression time, Query Coverage, Memory
Usage…(see my survey paper in WWWJ)
Comparison of existing technologies

7
An Example:Web Server LogsAn Example:Web Server Logs
202.239.238.16|GET / HTTP/1.0|text/html|200|1997/10/01-00:00:02|-|4478|-|-|http://www.net.jp/|Mozilla/3.1[ja](I)202.239.238.16|GET / HTTP/1.0|text/html|200|1997/10/01-00:00:02|-|4478|-|-|http://www.net.jp/|Mozilla/3.1[ja](I)
<apache:entry>
<apache:host> 202.239.238.16 </apache:host>
<apache:requestLine> GET / HTTP/1.0 </apache:requestLine>
<apache:contentType> text/html </apache:contentType>
<apache:statusCode> 200</apache:statusCode>
<apache:date> 1997/10/01-00:00:02</apache:date>
<apache:byteCount> 4478</apache:byteCount>
<apache:referer> http://www.net.jp/ </apache:referer>
<apache:userAgent> Mozilla/3.1$[$ja$]$(I)</apache:userAgent>
</apache:entry>
<apache:entry>
<apache:host> 202.239.238.16 </apache:host>
<apache:requestLine> GET / HTTP/1.0 </apache:requestLine>
<apache:contentType> text/html </apache:contentType>
<apache:statusCode> 200</apache:statusCode>
<apache:date> 1997/10/01-00:00:02</apache:date>
<apache:byteCount> 4478</apache:byteCount>
<apache:referer> http://www.net.jp/ </apache:referer>
<apache:userAgent> Mozilla/3.1$[$ja$]$(I)</apache:userAgent>
</apache:entry>
ASCII File 15.9 MB (gzipped 1.6MB):
XML-ized apache web log inflates to 24.2 MB (gzipped 2.1MB):

8
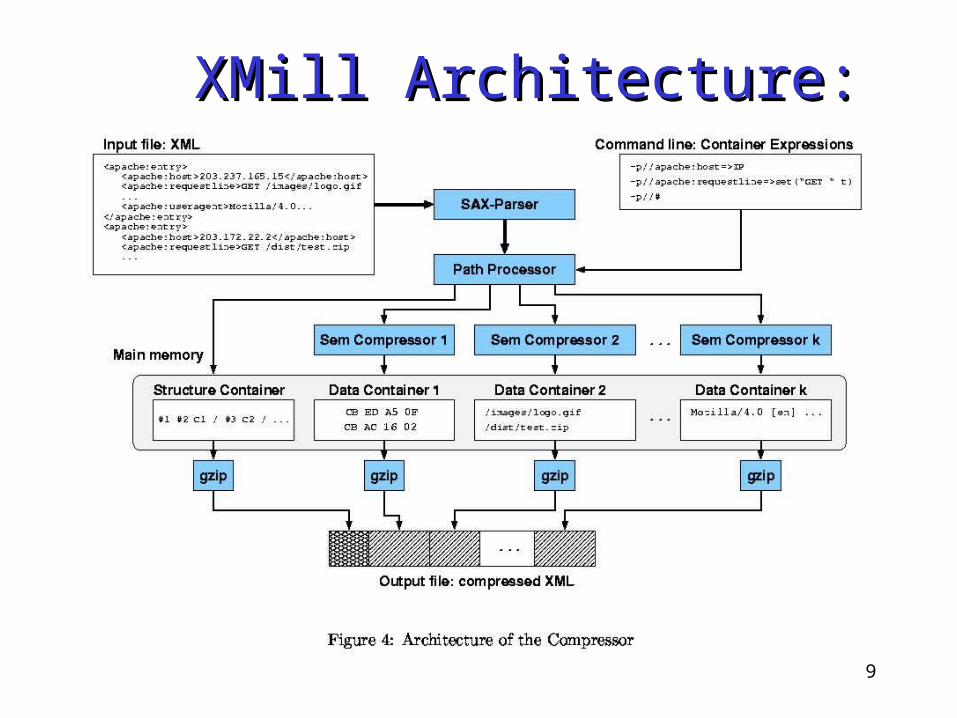
XMillXMill
First specialized compressor for XML data• SAX parser for parsing XML data• Still using gzip as its underlying compressor• Clever grouping of data into containers for compression
Compress XML via three basic techniques• Compress the structure separately from the data• Group the data values according to their types• Apply semantic (specialized) compressors:
Downloadable:• www.cs.washington.edu/homes/suciu/XMILL
9
XMill Architecture:XMill Architecture:

10
How Xmill Works: Three IdeasHow Xmill Works: Three Ideas
<apache:entry>
<apache:host> </apache:host>
. . .
</apache:entry>
<apache:entry>
<apache:host> </apache:host>
. . .
</apache:entry>
202.239.238.16
GET / HTTP/1.0
text/html
200
…
202.239.238.16
GET / HTTP/1.0
text/html
200
…
gzip Structure gzip Data
=1.75MB+
Compress the structure separately from the data:

11
How Xmill Works: Three IdeasHow Xmill Works: Three Ideas
<apache:entry>
. . .
</apache:entry>
<apache:entry>
. . .
</apache:entry>
202.23.23.16
224.42.24.55
…
202.23.23.16
224.42.24.55
…
gzip Structure gzip Data1
=1.33MB+GET / HTTP/1.0
GET / HTTP/1.1
…
GET / HTTP/1.0
GET / HTTP/1.1
…
gzip Data2
+
Group the data values according to their types:

12
How Xmill Works: Three IdeasHow Xmill Works: Three Ideas
gzip Structure + gzip c1(Data1) + gzip c2(Data2) + ... =0.82MB
Apply semantic (specialized) compressors:
Examples:• 8, 16, 32-bit integer encoding (signed/unsigned)• differential compressing (e.g. 1999, 1995, 2001, 2000, 1995, ...)• compress lists, records (e.g. 104.32.23.1 4 bytes)Need user input to select the semantic compressor

13
Path Processor – structure container:Path Processor – structure container:
Replace data value with container number (negative integer) Replace end tag with 0 Replace tags/attributes with positive integer
<Book><Title lang=“English”>Data Compression</Title>
<Author>Gray</Author>
<Author>Reiter</Author>
</Book>
<Book><Title lang=“English”>Data Compression</Title>
<Author>Gray</Author>
<Author>Reiter</Author>
</Book>
<Book><Title lang=-1>-2</Title>
<Author>-3</Author>
<Author>-3</Autor>
</Book>
<Book><Title lang=-1 0>-2 0 <Author>-3 0 <Author>-3 0 0Book = 1, Title = 2, @lang = 3, Author = 4
1 2 3 -1 0 -2 0 4 -3 0 4 -3 0 0
Fewer storage!14 bytes!
Dictionary:One more entry
for each new word
Repeated structures entries could be compressed effectively!
14
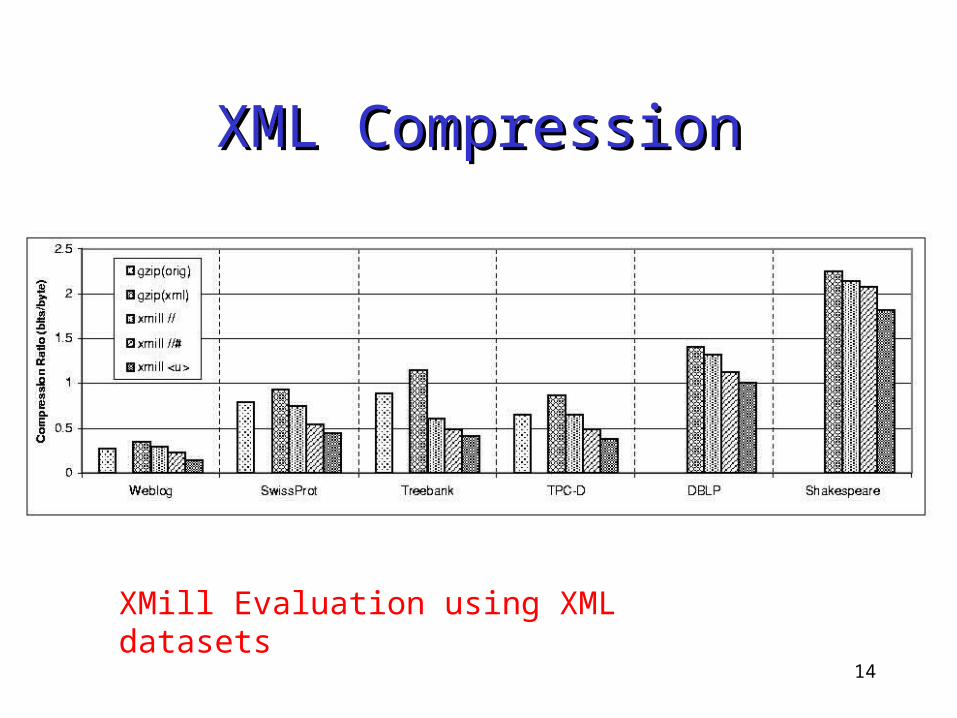
XML CompressionXML Compression
XMill Evaluation using XML datasets

15
Queriable CompressorsQueriable Compressors XQzip: queriable XML compressor (our work
[EDBT04])• Existing XML compressors (survey in[WWWJ05]):
Unqueriable (e.g. XMill [SIGMOD00]): exploit data commonalities ≥ better compression rate than gzip)
Queriable (e.g. XGrind [ICDE02], XPRESS [SIGMOD03], XQueC, XQzip [EDBT04], XCQ [KAISJ05]): compress data individually ≥ inadequate compression rate and time)
• Features of XQzip: Use the SIT to aid query evaluation Block-compression: allow data commonalities to be exploited and
used as buffers to reduce decompression overhead

16
Structure Index Tree (SIT)Structure Index Tree (SIT) Effective elimination of duplicate structures
in the XML data Merging of nodes that have
• the same incoming path• the same ordered set of paths of their descendants
SIT Construction• A linear scan of the XML document• Merging of the subtree that we are constructing
into its equivalent subtree in the base tree
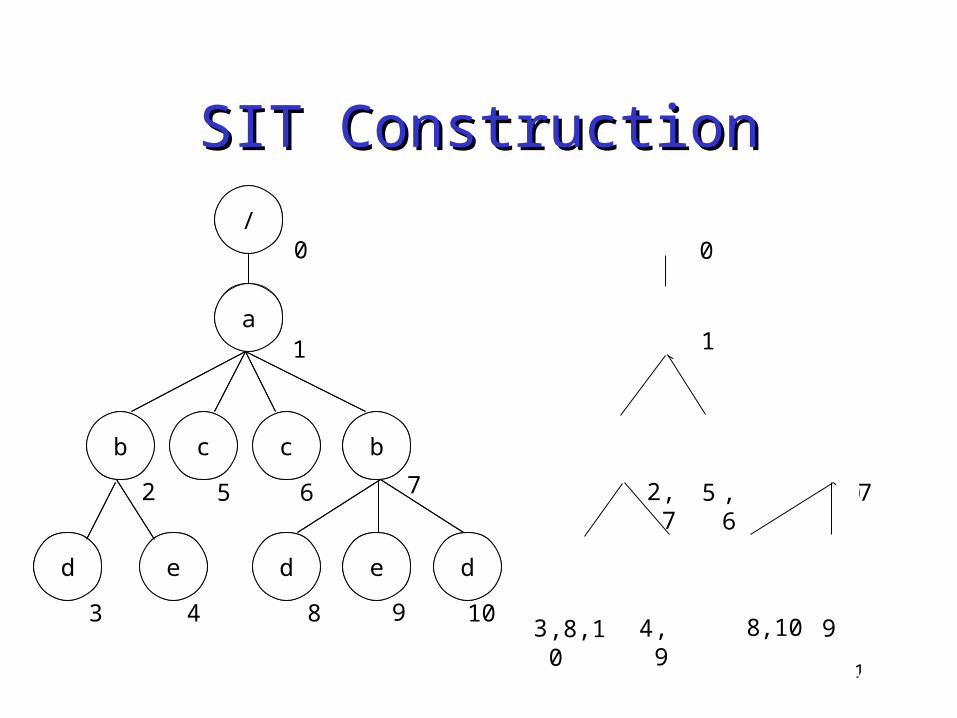
17
/
d
b
d
a
b
d e
c c
e
/
d
a
b
d e
c
e
c
d
c b
d
SIT ConstructionSIT Construction
0
1
2
3 4
5 6 7
8 9 10
0
1
2
3 4
5 6,6 7
8 9 10,8,10 ,9
,7
,10
18
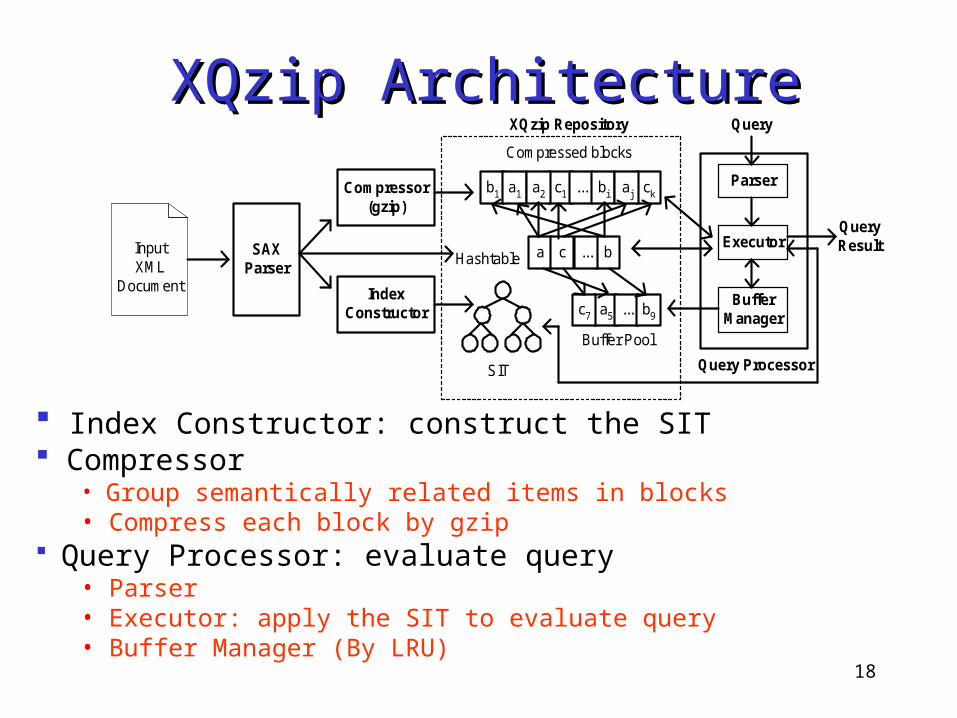
XQzip ArchitectureXQzip Architecture
InputXML
Document
SAXParser
Compressor(gzip)
IndexConstructor
b1 a1 c1a2 ... bi ckaj
a c b...
a5c7 ... b9
Parser
Executor
BufferManager
SIT
Hashtable
Compressed blocks
Query Processor
Query
QueryResult
Buffer Pool
XQzip Repository
Index Constructor: construct the SIT Compressor
• Group semantically related items in blocks• Compress each block by gzip
Query Processor: evaluate query• Parser• Executor: apply the SIT to evaluate query• Buffer Manager (By LRU)

19
SIT Construction ComplexitySIT Construction ComplexityN: Total number of elements in the input XML
document Time Complexity:
• Worst-case: O(N │SIT │)• Average-case: O(N)
Space Complexity:• Base tree and the subtree being merged: ≤ 2│SIT │• Space for storing ids of eliminated nodes: O(N)

20
Data CompressionData Compression A balance between full-chunked and fine-grained
compression• A distinct data container for each distinct element• Each container compressed (using gzip) into many smaller
blocks
Block size?• Too small: query time ↑compression ratio↓• Too large: query time ↓compression ratio↑• Only can be determined by an empirical study

21
Block SizeBlock SizeRepresentative datasets and queries: Datasets:
• Heavy text • Light text • A mix of heavy text and light text
Queries:• High Selectivity• Medium Selectivity• Low Selectivity
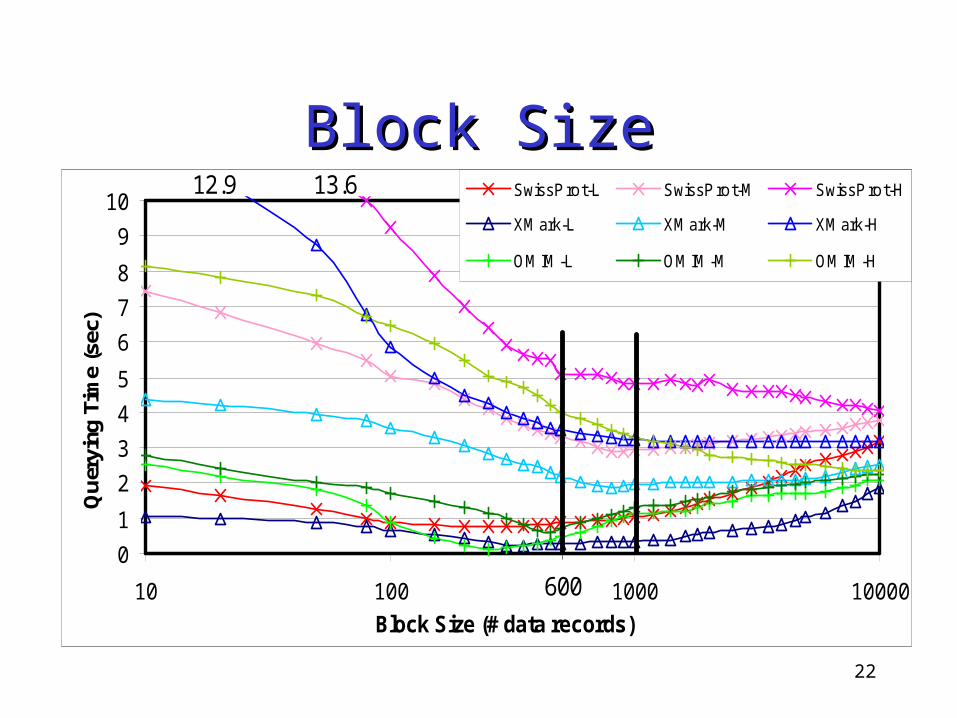
22
Block SizeBlock Size
0
1
2
3
4
5
6
7
8
9
10
10 100 1000 10000
Block Size (# data records)
Qu
eryi
ng T
ime
(sec
)
SwissP rot-L SwissP rot-M SwissP rot-H
XMark-L XMark-M XMark-H
OMIM-L OMIM-M OMIM-H
13.612.9
600

23
Structure of Compressed-DataStructure of Compressed-Data Block size?
• Determined by an empirical study• Querying Time
near-optimal range : 600-1000 data items/block (average optimal: 950)
• Compression Ratio Not improved much after 150 KB/block (usually
contain more than 1000 items)• ≥ 1000 data items/block

24
OutlineOutline
Introduction XQzip [EDBT 2004]
• Indexing
• Data Compression
• Query Evaluation
• Performance Evaluation Conclusion

25
XQzip Query CoverageXQzip Query Coverage All XPath axes except the sideways axes (e.g.
preceding, following)-siblings Multiple and nested predicates
• and / or / not expressions
Aggregations: sum, count, average, max, min Group queries: e.g. (L1 (L2 + L3 + L4))
• L1 : //a[b = “Crete”] (prefix) L2 : c• L3 : d[f/count() >100] L4 : e[//g]

26
Query EvaluationQuery Evaluation Depth-first traverse the index tree Buffer Management (LRU)
• Why buffering? Decompression Time Dominates
• Decompression avoidance

27
OutlineOutline
Introduction XQzip
• Indexing
• Data Compression
• Query Evaluation
• Performance Evaluation Conclusion
28
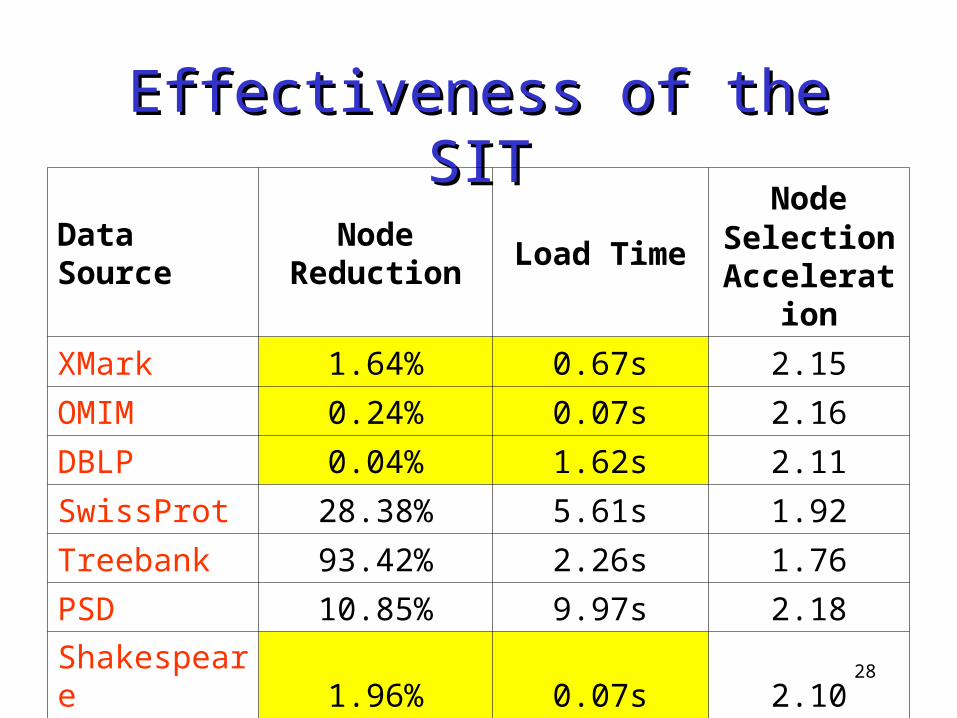
Effectiveness of the SITEffectiveness of the SIT
Data SourceNode
ReductionLoad Time
Node Selection
Acceleration
XMark 1.64% 0.67s 2.15
OMIM 0.24% 0.07s 2.16
DBLP 0.04% 1.62s 2.11
SwissProt 28.38% 5.61s 1.92
Treebank 93.42% 2.26s 1.76
PSD 10.85% 9.97s 2.18
Shakespeare 1.96% 0.07s 2.10
Lineitem 0.002% 0.42s 1.78

29
Effectiveness of the SITEffectiveness of the SIT
Index Size: less than 1% of original size Load Time: a fraction of a second Node Selection Acceleration: twice faster
than F&B-Index Construction Time: more than 3 times faster
than F&B-Index

30
Compression RatioCompression Ratio
0
10
20
30
40
50
60
70
80
90
100
XMark OMIM DBLP SwissProt Treebank PSD Shakespeare Lineitem
Data Sources
Co
mp
ressio
n R
ati
o (
%)
XQzip+ XQzip XMill gzip XGrind
XQzip is comparable to XMill and gzip,
17% better than XGrind with index size included, 42% better than XGrind without index.

31
Compression/Decompression Compression/Decompression TimeTime
XQzip (compression + index construction) is more than 5 times better than XGrind, 1.5 times worse than XMill
XQzip (index-loading + decompression) is more than 3 times better than XGrind, 1.4 times worse than XMill
32
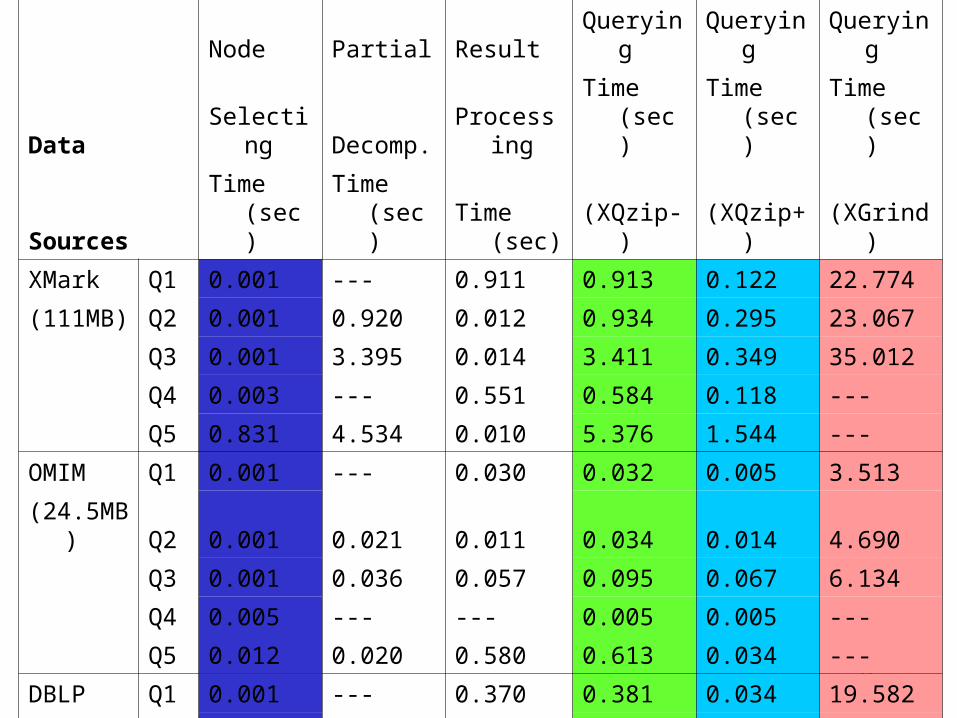
Node Partial Result Querying Querying Querying
Data Selecting Decomp. Processing Time (sec) Time (sec) Time (sec)
Sources Time (sec) Time (sec) Time (sec) (XQzip-) (XQzip+) (XGrind)
XMark Q1 0.001 --- 0.911 0.913 0.122 22.774
(111MB) Q2 0.001 0.920 0.012 0.934 0.295 23.067
Q3 0.001 3.395 0.014 3.411 0.349 35.012
Q4 0.003 --- 0.551 0.584 0.118 ---
Q5 0.831 4.534 0.010 5.376 1.544 ---
OMIM Q1 0.001 --- 0.030 0.032 0.005 3.513
(24.5MB) Q2 0.001 0.021 0.011 0.034 0.014 4.690
Q3 0.001 0.036 0.057 0.095 0.067 6.134
Q4 0.005 --- --- 0.005 0.005 ---
Q5 0.012 0.020 0.580 0.613 0.034 ---
DBLP Q1 0.001 --- 0.370 0.381 0.034 19.582
(148MB) Q2 0.001 0.330 0.013 0.345 0.029 26.108
Q3 0.033 0.391 8.997 9.541 1.543 50.344
Q4 0.001 --- 0.000 0.001 0.001 ---
Q5 0.087 1.122 0.260 1.481 0.642 ---

33
Query PreformanceQuery Preformance
Cold Buffer-pool Evaluation• 13 times better than XGrind
Warm buffer-pool Evaluation• 80 times better than XGrind
Impressive Buffer Effect!

34
Lessons on XML CompressionLessons on XML Compression Good compression ratio and time
• Comparable to that of XMill• Much better than that of XGrind (and XPRESS)
Support a very practical set of queries• A much wider range of queries than XGrind and XPRESS
Very Competitive Querying Time with Buffer• 13 time better than XGrind with cold buffer• 80 time better than XGrind with warm buffer
Limitations• Cost of building and maintenance of complex Indexes• No theoretical foundation of block size

35
XCQXCQ
XCQ Framework Experimental Results
• Compression Performance• Query Performance
Lessons and Development

36
XCQXCQ Objectives:
• Achieve Good Compression ratio Comparable to XMill Better than XGrind
• Achieve Good Query performance More efficient than XGrind Querying compressed documents with block-based partial
decompression
• But addressing issues different from XQzip Adopt minimal indexing Establish theory between selectivity and block size
37
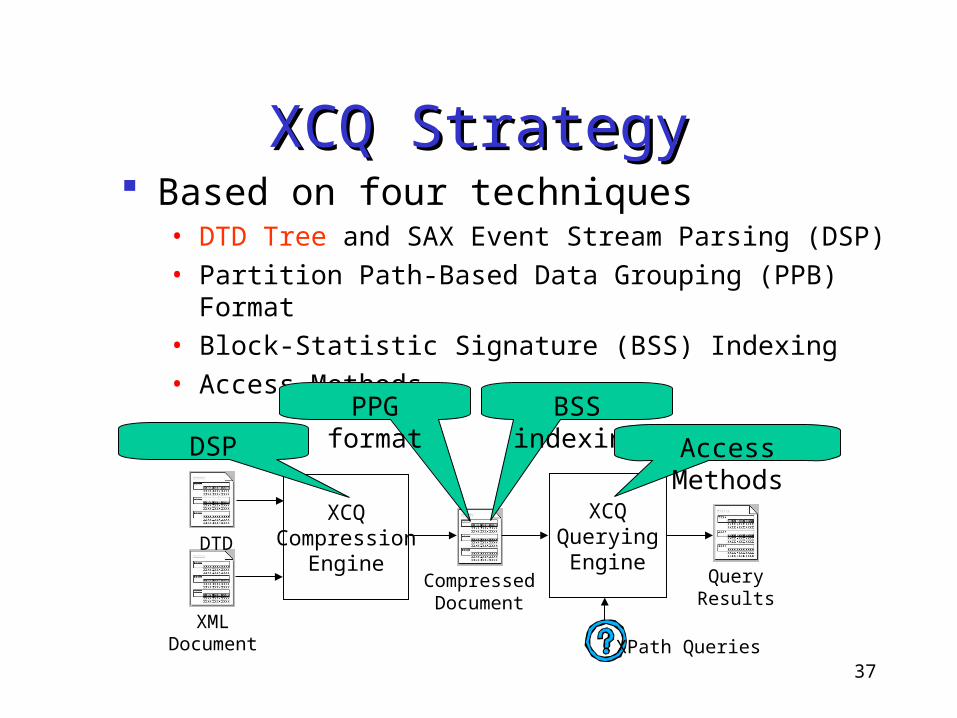
XCQ StrategyXCQ Strategy Based on four techniques
• DTD Tree and SAX Event Stream Parsing (DSP)
• Partition Path-Based Data Grouping (PPB) Format
• Block-Statistic Signature (BSS) Indexing
• Access Methods
XCQCompression
Engine
XCQQueryingEngine
DTD
XMLDocument
CompressedDocument
QueryResults
XPath Queries
DSP
PPG format BSS indexing Access
Methods

38
Technique 1 – Technique 1 – DTD Tree and SAX Event Stream Parsing (DSP)DTD Tree and SAX Event Stream Parsing (DSP)
XCQCompression
Engine
XCQQueryingEngine
DTD
XMLDocument
CompressedDocument
QueryResults
XPath Queries
DSP
PPG format BSS indexing
Access Methods

39
Technique 1 – Technique 1 – DTD Tree and SAX Event Stream Parsing (DSP)DTD Tree and SAX Event Stream Parsing (DSP)
Purpose: • To utilize information in the associated DTD of the
document
Benefits:• Only encode the information that cannot be inferred in
the DTD
• Precise path-based grouping of data items
• Run in automated manner
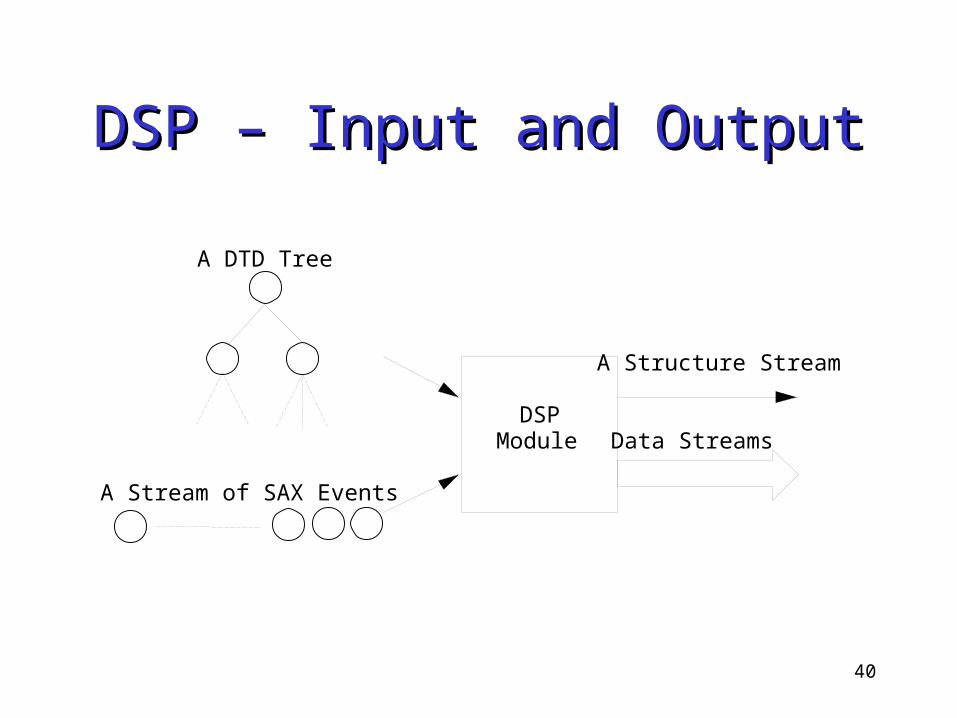
40
DSP – Input and OutputDSP – Input and Output
A DTD Tree
Data StreamsDSP
Module
A Structure Stream
A Stream of SAX Events
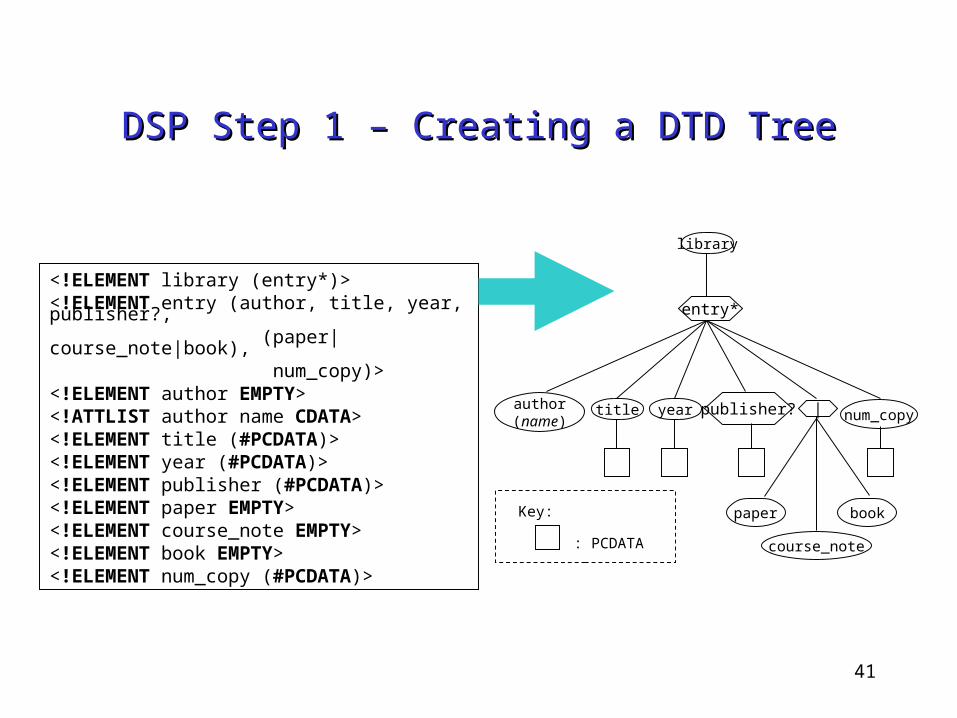
41
DSP Step 1 – Creating a DTD TreeDSP Step 1 – Creating a DTD Tree
<!ELEMENT library (entry*)><!ELEMENT entry (author, title, year, publisher?, (paper|course_note|book), num_copy)><!ELEMENT author EMPTY><!ATTLIST author name CDATA><!ELEMENT title (#PCDATA)><!ELEMENT year (#PCDATA)><!ELEMENT publisher (#PCDATA)><!ELEMENT paper EMPTY><!ELEMENT course_note EMPTY><!ELEMENT book EMPTY><!ELEMENT num_copy (#PCDATA)>
Key:
: PCDATA
library
author(name)
title year num_copy
paper
course_note
book
entry*
publisher? |
42
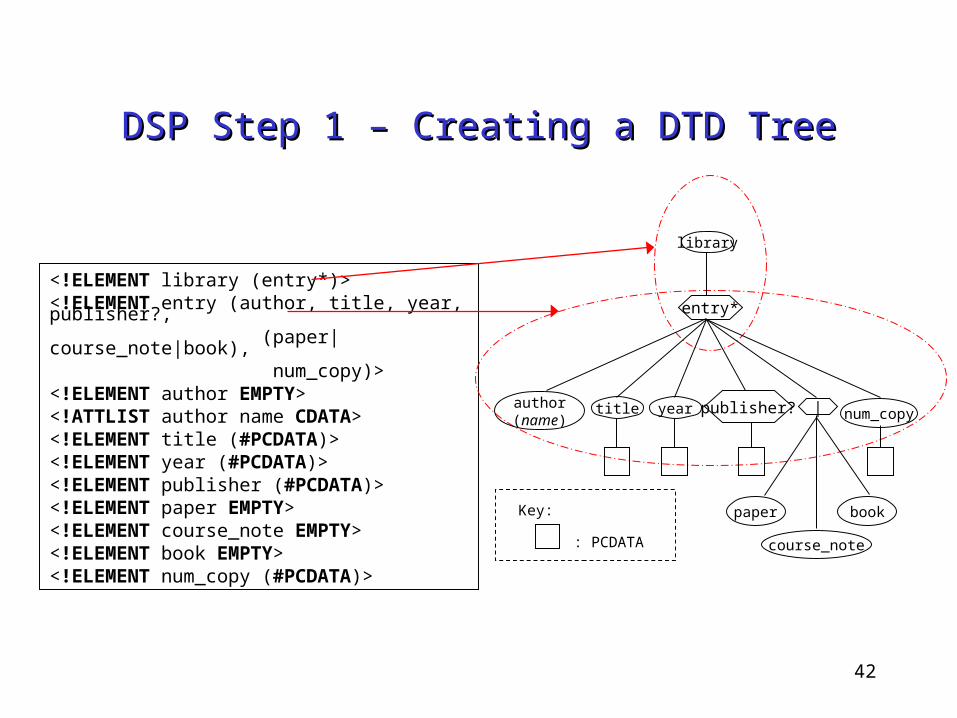
DSP Step 1 – Creating a DTD TreeDSP Step 1 – Creating a DTD Tree
<!ELEMENT library (entry*)><!ELEMENT entry (author, title, year, publisher?, (paper|course_note|book), num_copy)><!ELEMENT author EMPTY><!ATTLIST author name CDATA><!ELEMENT title (#PCDATA)><!ELEMENT year (#PCDATA)><!ELEMENT publisher (#PCDATA)><!ELEMENT paper EMPTY><!ELEMENT course_note EMPTY><!ELEMENT book EMPTY><!ELEMENT num_copy (#PCDATA)>
Key:
: PCDATA
library
author(name)
title year num_copy
paper
course_note
book
entry*
publisher? |

43
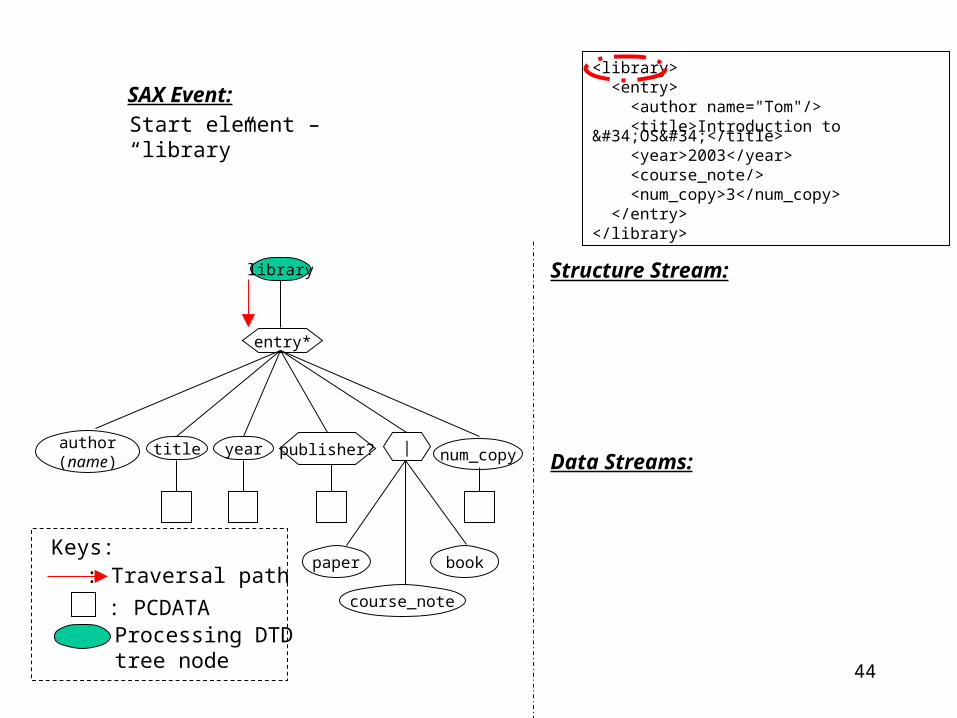
DSP Step 2 – Processing in DSP ModuleDSP Step 2 – Processing in DSP Module
How does the DSP module process the following XML document?
<library> <entry> <author name="Tom"/> <title>Introduction to "OS"</title> <year>2003</year> <course_note/> <num_copy>3</num_copy> </entry></library>
44
SAX Event:
library
author(name)
title year num_copy
paper
course_note
bookKeys:
: Traversal path
: PCDATA: Processing DTD tree node
Start element – “library”
Structure Stream:
Data Streams:
<library> <entry> <author name="Tom"/> <title>Introduction to "OS"</title> <year>2003</year> <course_note/> <num_copy>3</num_copy> </entry></library>
entry*
publisher? |
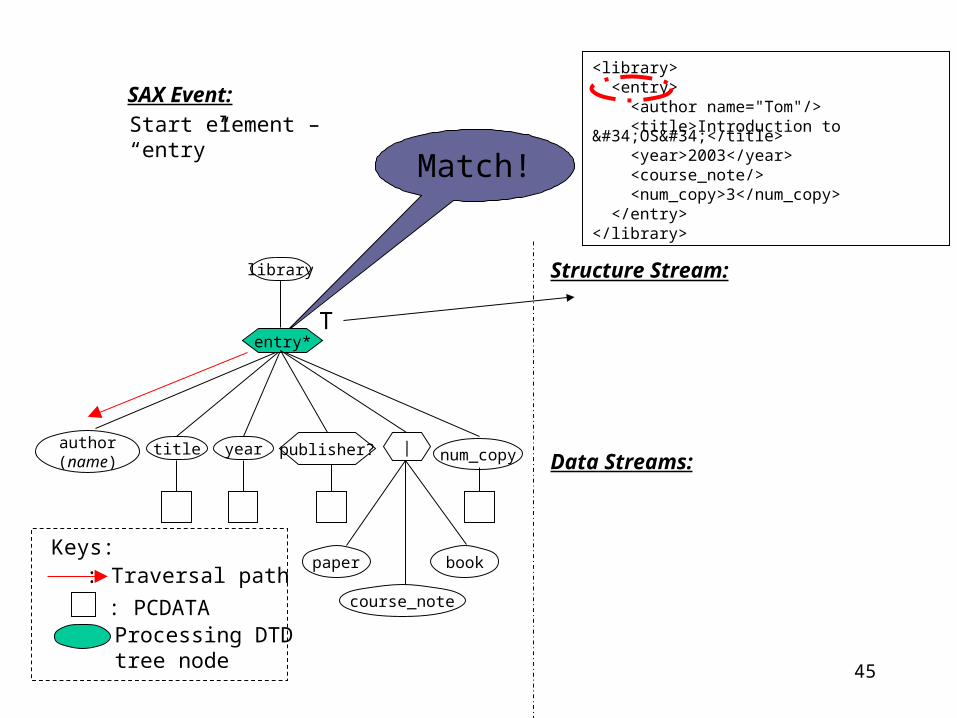
45
SAX Event:
library
author(name)
title year num_copy
paper
course_note
bookKeys:
: Traversal path
: PCDATA: Processing DTD tree node
Start element – “entry”
Structure Stream:
Data Streams:
T
Match!
<library> <entry> <author name="Tom"/> <title>Introduction to "OS"</title> <year>2003</year> <course_note/> <num_copy>3</num_copy> </entry></library>
entry*
publisher? |
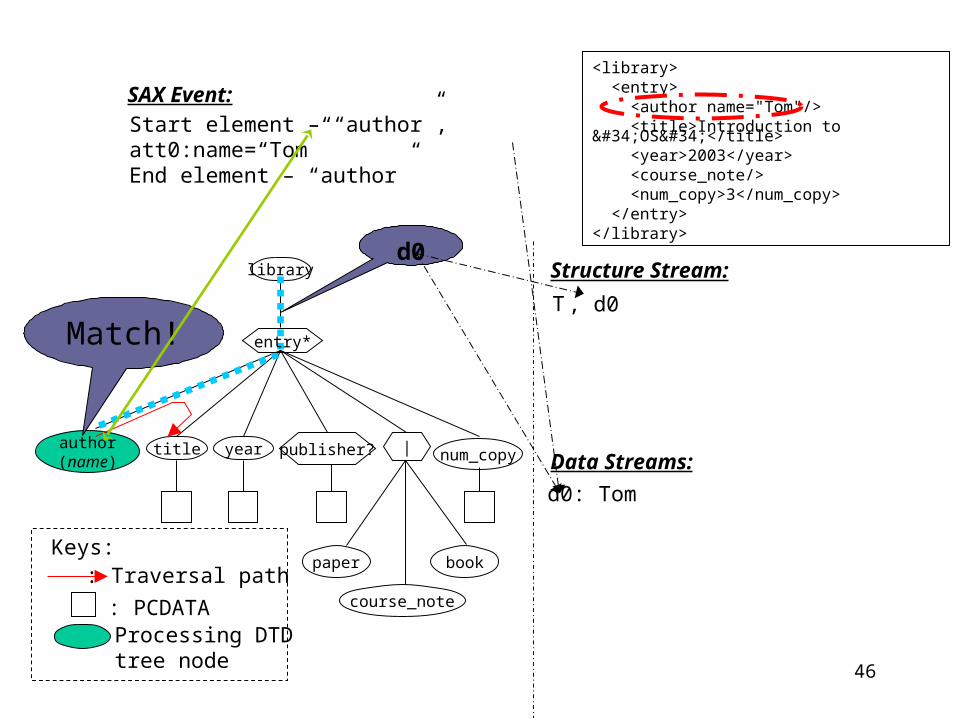
46
SAX Event:
library
author(name)
title year num_copy
paper
course_note
bookKeys:
: Traversal path
: PCDATA: Processing DTD tree node
Start element – “author”, att0:name=“Tom”End element – “author”
Structure Stream:
Data Streams:
T
Match!
d0
, d0
d0: Tom
<library> <entry> <author name="Tom"/> <title>Introduction to "OS"</title> <year>2003</year> <course_note/> <num_copy>3</num_copy> </entry></library>
entry*
publisher? |
47
SAX Event:
library
author(name)
title year num_copy
paper
course_note
bookKeys:
: Traversal path
: PCDATA: Processing DTD tree node
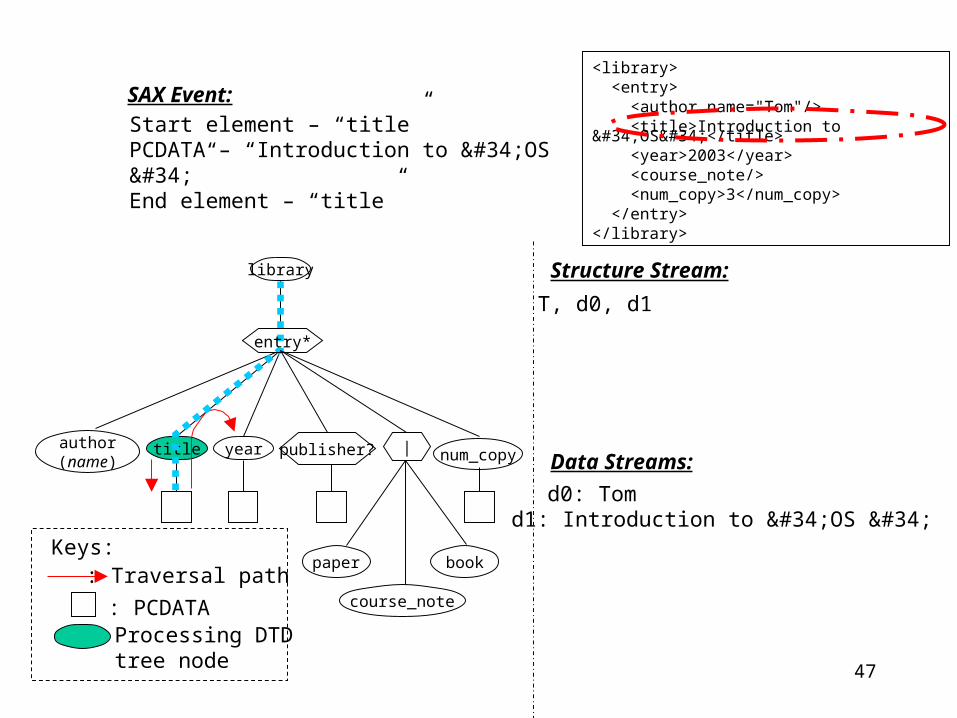
Start element – “title”PCDATA – “Introduction to "OS "”End element – “title”
Structure Stream:
Data Streams:
T, d0, d1
d0: Tomd1: Introduction to "OS "
<library> <entry> <author name="Tom"/> <title>Introduction to "OS"</title> <year>2003</year> <course_note/> <num_copy>3</num_copy> </entry></library>
entry*
publisher? |
48
SAX Event:
library
author(name)
title year num_copy
paper
course_note
bookKeys:
: Traversal path
: PCDATA: Processing DTD tree node
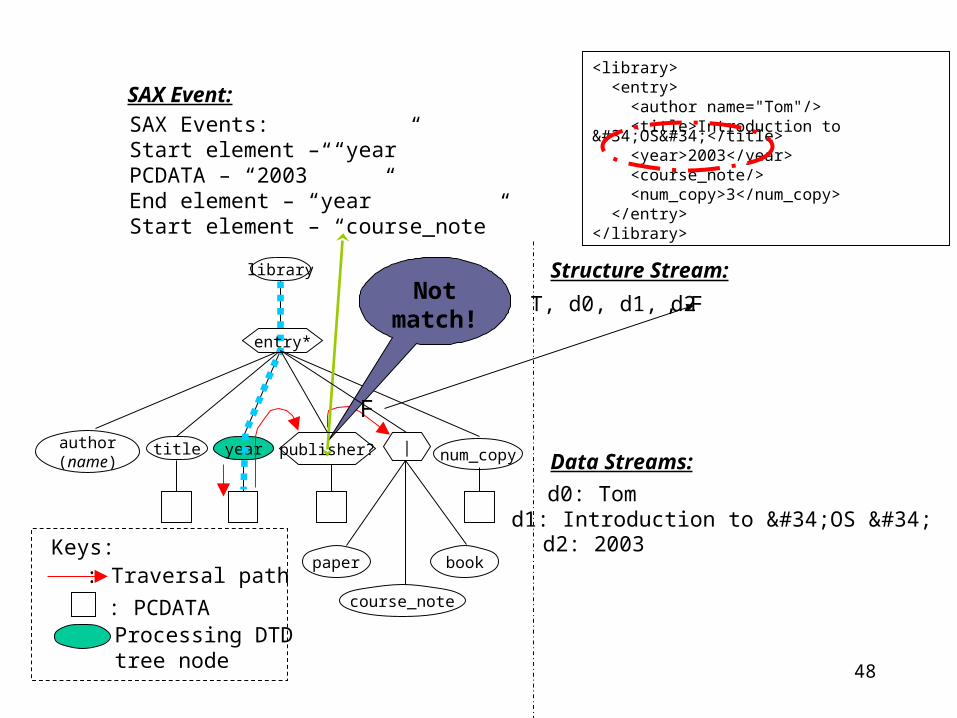
SAX Events:Start element – “year”PCDATA – “2003”End element – “year”Start element – “course_note”
Structure Stream:
Data Streams:
T, d0, d1, d2
d0: Tomd1: Introduction to "OS "d2: 2003
Not match
!
F
, F
<library> <entry> <author name="Tom"/> <title>Introduction to "OS"</title> <year>2003</year> <course_note/> <num_copy>3</num_copy> </entry></library>
entry*
publisher? |
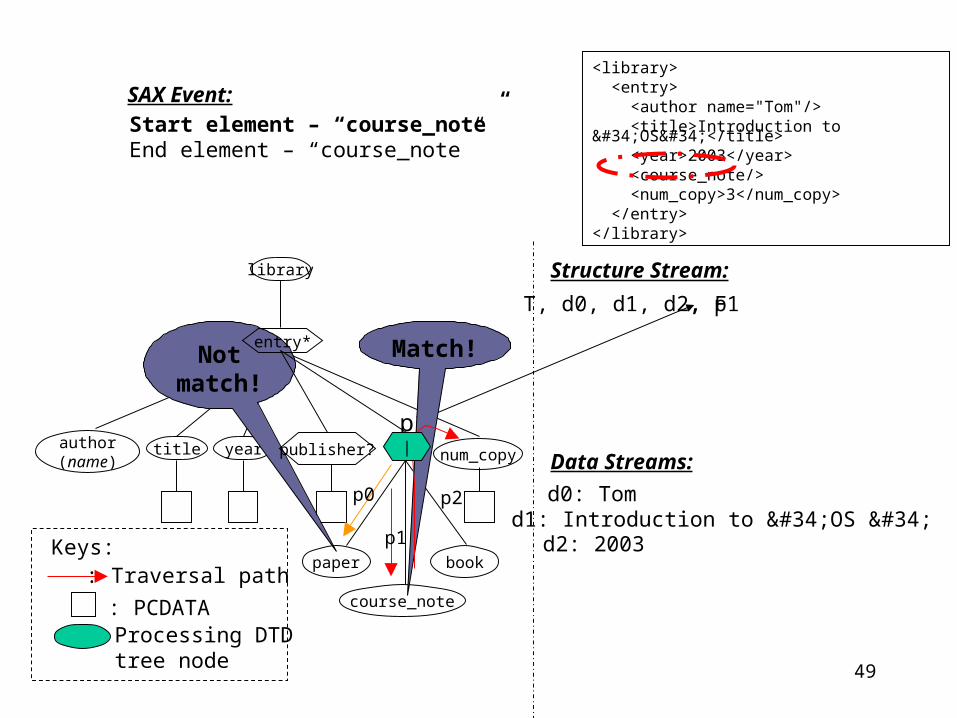
49
SAX Event:
library
author(name)
title year num_copy
paper
course_note
bookKeys:
: Traversal path
: PCDATA: Processing DTD tree node
Start element – “course_note”End element – “course_note”
Structure Stream:
Data Streams:
T, d0, d1, d2, F
d0: Tomd1: Introduction to "OS "d2: 2003
p1
Not match
!
Match!
, p1
<library> <entry> <author name="Tom"/> <title>Introduction to "OS"</title> <year>2003</year> <course_note/> <num_copy>3</num_copy> </entry></library>
p1
p0 p2
entry*
publisher? |
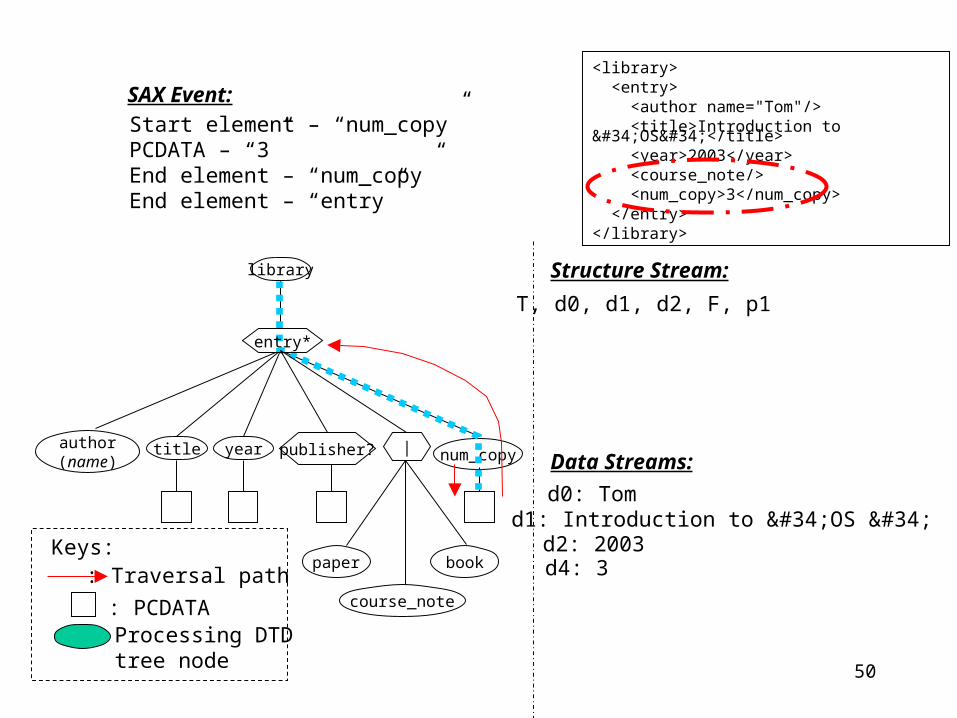
50
SAX Event:
library
author(name)
title year num_copy
paper
course_note
bookKeys:
: Traversal path
: PCDATA: Processing DTD tree node
Start element – “num_copy”PCDATA – “3”End element – “num_copy”End element – “entry”
Structure Stream:
Data Streams:
T, d0, d1, d2, F, p1
d0: Tomd1: Introduction to "OS "d2: 2003d4: 3
<library> <entry> <author name="Tom"/> <title>Introduction to "OS"</title> <year>2003</year> <course_note/> <num_copy>3</num_copy> </entry></library>
entry*
publisher? |

51
DSP Step 3 – Generated OutputDSP Step 3 – Generated Output
Structure Stream
Keys for path-based grouped Data Streams:d0: /library/entry/author/@named1: /library/entry/title/text()d2: /library/entry/year/text()d3: /library/entry/publisher/text()d4: /library/entry/num_copy/text()
d0
d1
d2
d3
d4
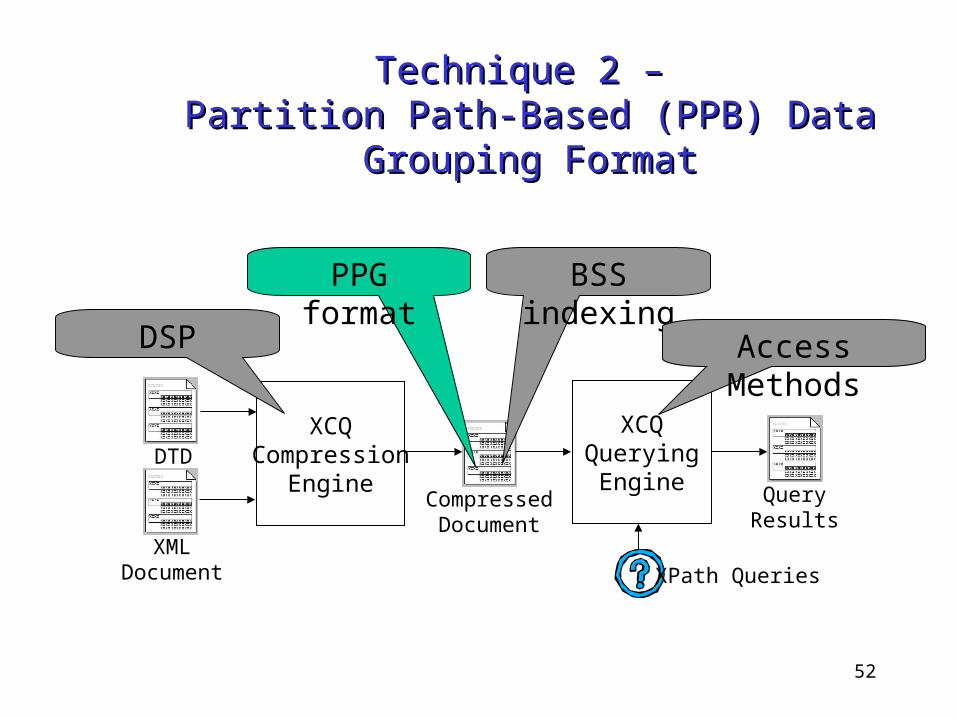
52
XCQCompression
Engine
XCQQueryingEngine
DTD
XMLDocument
CompressedDocument
QueryResults
XPath Queries
DSP
PPG format BSS indexing
Access Methods
Technique 2 – Technique 2 – Partition Path-Based (PPB) Data Grouping FormatPartition Path-Based (PPB) Data Grouping Format

53
Technique 2 – Technique 2 – Partition Path-Based Data Grouping (PPB) FormatPartition Path-Based Data Grouping (PPB) Format
Purpose: • To partition the data streams
Each block contains a number of data items Benefits:
• Can be compressed and decompressed as an individual unit
• Support partial decompression during query processing

54
Technique 2 – Technique 2 – Partition Part Based Data Grouping (PPB) FormatPartition Part Based Data Grouping (PPB) Format
Structure Stream
Keys for path-based grouped Date Streams:d0: /library/entry/author/@named1: /library/entry/title/text()d2: /library/entry/year/text()d3: /library/entry/publisher/text()d4: /library/entry/num_copy/text()
d0
d1
d2
d3
d4
55
Technique 2 – Technique 2 – Partition Part Based Data Grouping (PPB) FormatPartition Part Based Data Grouping (PPB) Format
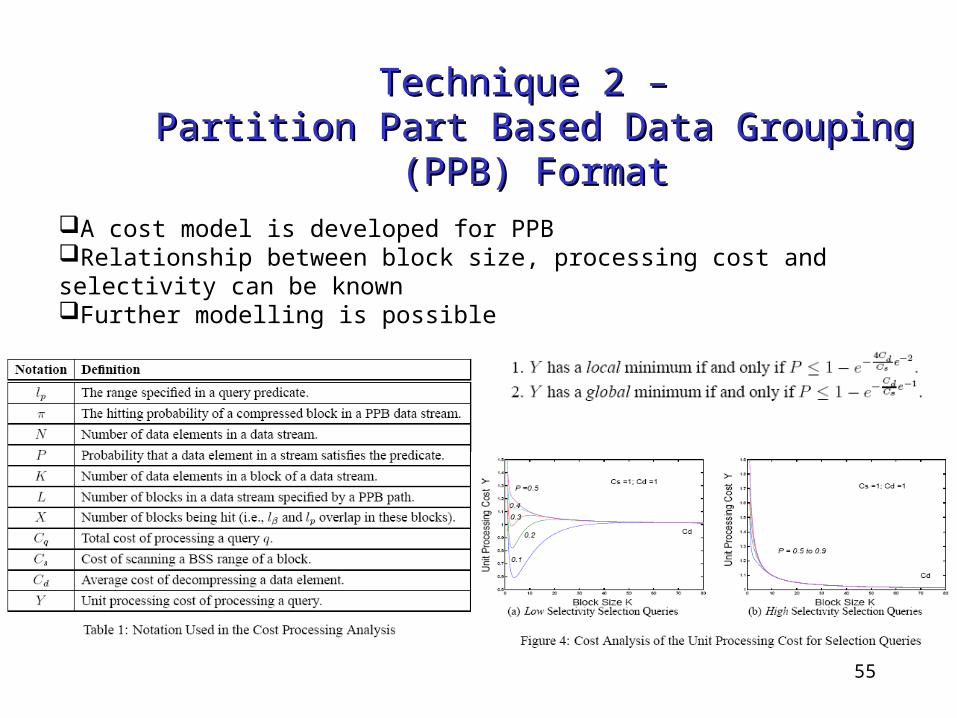
A cost model is developed for PPBRelationship between block size, processing cost and selectivity can be knownFurther modelling is possible
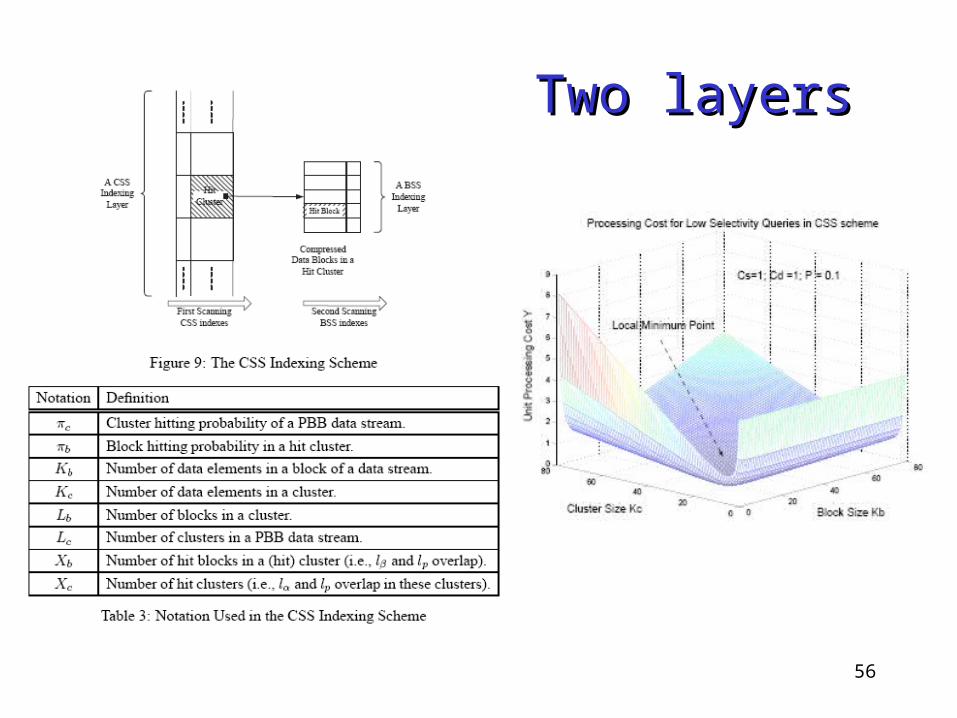
56
Two layersTwo layers
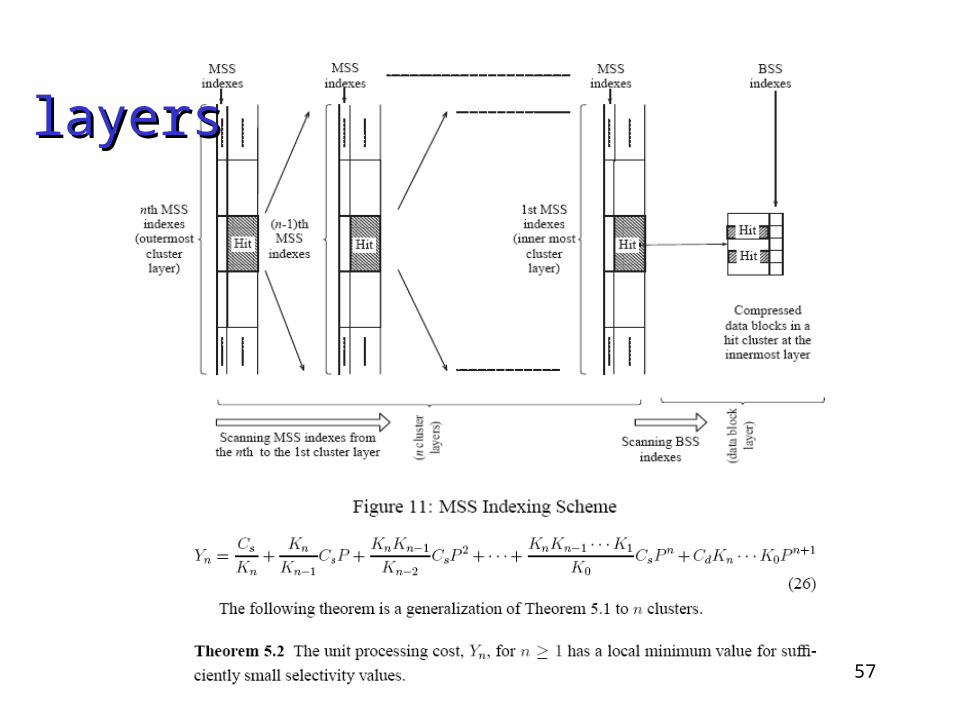
57
nn layers layers
58
Technique 3 – Technique 3 – Block-Statistic Signature (BSS) IndexingBlock-Statistic Signature (BSS) Indexing
XCQCompression
Engine
XCQQueryingEngine
DTD
XMLDocument
CompressedDocument
QueryResults
XPath Queries
DSP
PPG format BSS indexing
Access Methods

59
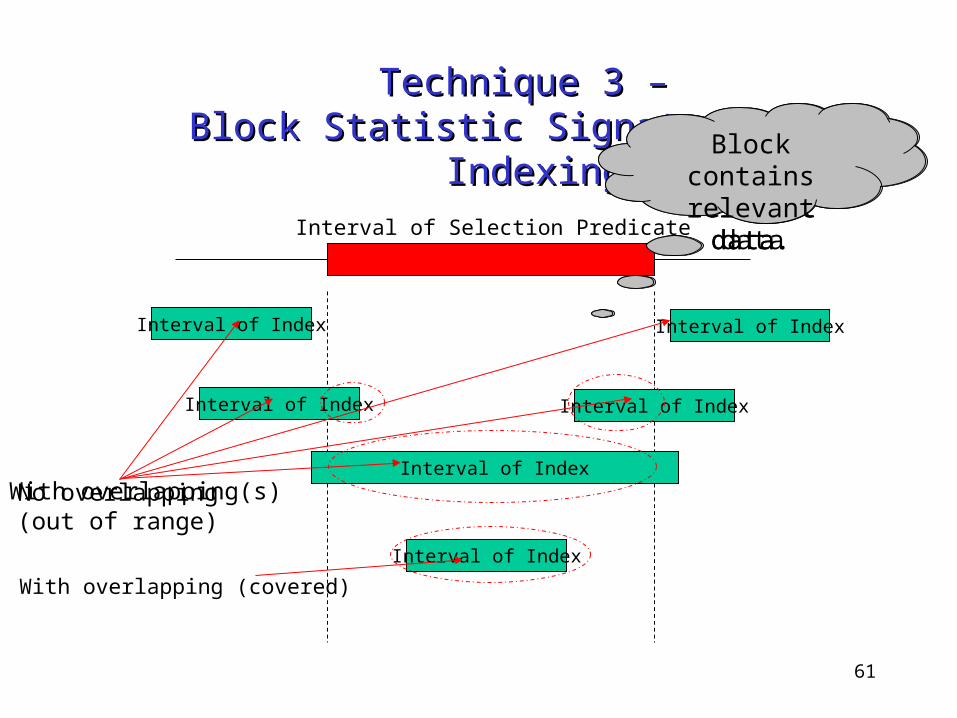
Technique 3 – Technique 3 – Block-Statistic Signature (BSS) IndexingBlock-Statistic Signature (BSS) Indexing
Purpose: To avoid accessing of non-relevant data blocks during querying• I/O cost• Decompression overhead• Time to scan the data inside the block
Details• Statistic summary (signature) for each block
Min, Max, Sum and Count
• Benefit: Little amount of processing time and storage space
• Research status: Supporting numerical data only
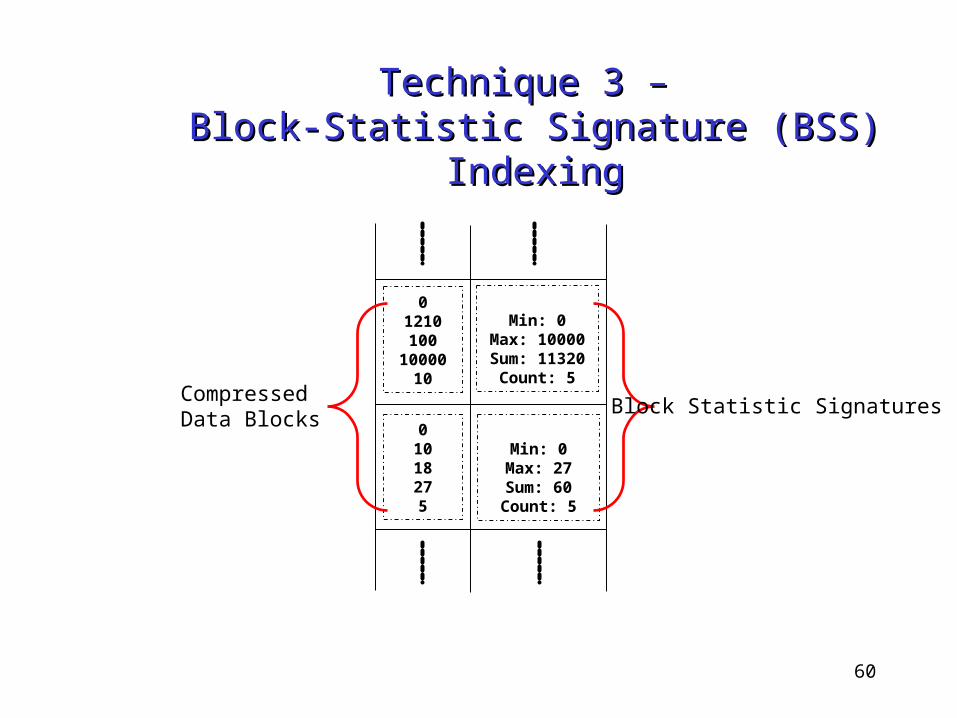
60
Technique 3 – Technique 3 – Block-Statistic Signature (BSS) IndexingBlock-Statistic Signature (BSS) Indexing
012101001000010
01018275
Min: 0Max:
10000Sum: 11320
Count: 5
Min: 0Max: 27Sum: 60Count: 5
CompressedData Blocks
Block Statistic Signatures
61
Technique 3 – Technique 3 – Block Statistic Signature (BSS) IndexingBlock Statistic Signature (BSS) Indexing
Interval of Index Interval of Index
Interval of Index Interval of Index
Interval of Index
Interval of Index
Interval of Selection Predicate
No overlapping (out of range)
Block contains no relevant
data.
Block contains relevant data
With overlapping(s)
With overlapping (covered)
Block contains relevant data.

62
Technique 4 – Technique 4 – Access MethodsAccess Methods
XCQCompression
Engine
XCQQueryingEngine
DTD
XMLDocument
CompressedDocument
QueryResults
XPath Queries
DSP
PPB format BSS indexing
Access Methods

63
Technique 4 – Technique 4 – Access MethodsAccess Methods
Purpose• For realizing partial decompression during query
processing
4 types of queries• Selection queries
• Structural queries
• Structure-based aggregation queries
• Path-based aggregation queries

64
Technique 4 – Technique 4 – Access Methods: Selection QueriesAccess Methods: Selection Queries
//entry[author/@name=“Jess” and publisher/text()=“ABC”]
Structure Stream
Keys for path-based grouped Date Streams:d0: /library/entry/author/@named1: /library/entry/title/text()d2: /library/entry/year/text()d3: /library/entry/publisher/text()d4: /library/entry/num_copy/text()
d0
d1
d2
d3
d4

65
Technique 4 – Technique 4 – Access Methods: Structural QueriesAccess Methods: Structural Queries
/library/entry/author
Structure Stream
Keys for path-based grouped Date Streams:d0: /library/entry/author/@named1: /library/entry/title/text()d2: /library/entry/year/text()d3: /library/entry/publisher/text()d4: /library/entry/num_copy/text()
d0
d1
d2
d3
d4

66
Technique 4 – Technique 4 – Access Methods: Structure-Based Aggregation QueriesAccess Methods: Structure-Based Aggregation Queries
count(//entry)
Structure Stream
Keys for path-based grouped Date Streams:d0: /library/entry/author/@named1: /library/entry/title/text()d2: /library/entry/year/text()d3: /library/entry/publisher/text()d4: /library/entry/num_copy/text()
d0
d1
d2
d3
d4

67
Technique 4 – Technique 4 – Access Methods: Path-Based Aggregation QueriesAccess Methods: Path-Based Aggregation Queries
sum(//num_copy/text()=1)
Structure Stream
Keys for path-based grouped Date Streams:d0: /library/entry/author/@named1: /library/entry/title/text()d2: /library/entry/year/text()d3: /library/entry/publisher/text()d4: /library/entry/num_copy/text()
d0
d1
d2
d3
d4
68
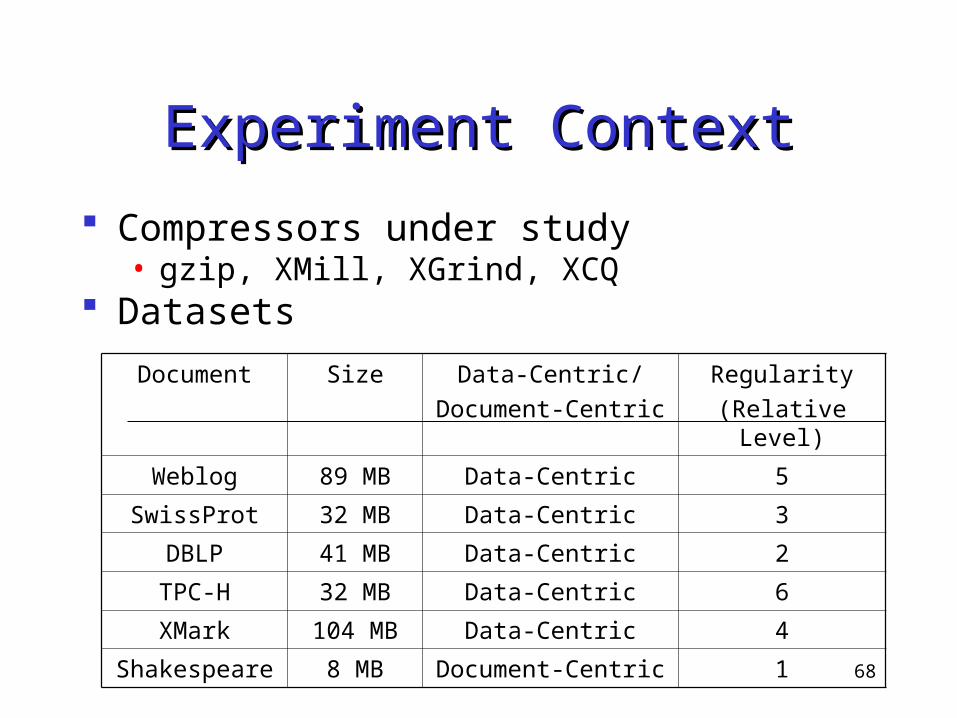
Experiment ContextExperiment Context
Compressors under study• gzip, XMill, XGrind, XCQ
Datasets
Document Size Data-Centric/
Document-Centric
Regularity
(Relative Level)
Weblog 89 MB Data-Centric 5
SwissProt 32 MB Data-Centric 3
DBLP 41 MB Data-Centric 2
TPC-H 32 MB Data-Centric 6
XMark 104 MB Data-Centric 4
Shakespeare 8 MB Document-Centric 1

69
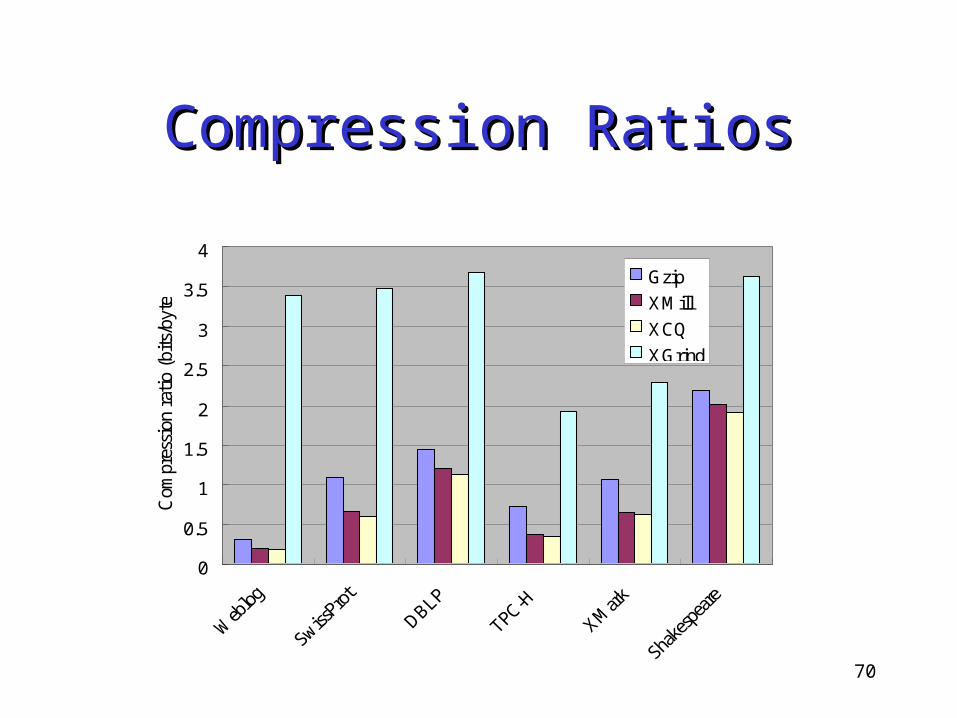
Experiment – Experiment – Compression PerformanceCompression Performance
Compression Performance• gzip, XMill, XCQ (No Partition) and XGrind• Scalability• XCQ
Partitioning BSS Indexing overhead
Objective:
Comparable to XMill and better than XGrind
70
Compression RatiosCompression Ratios
0
0.5
1
1.5
2
2.5
3
3.5
4
Com
pres
sion
rat
io (
bits
/byt
e)
Gzip
XMill
XCQ
XGrind
71
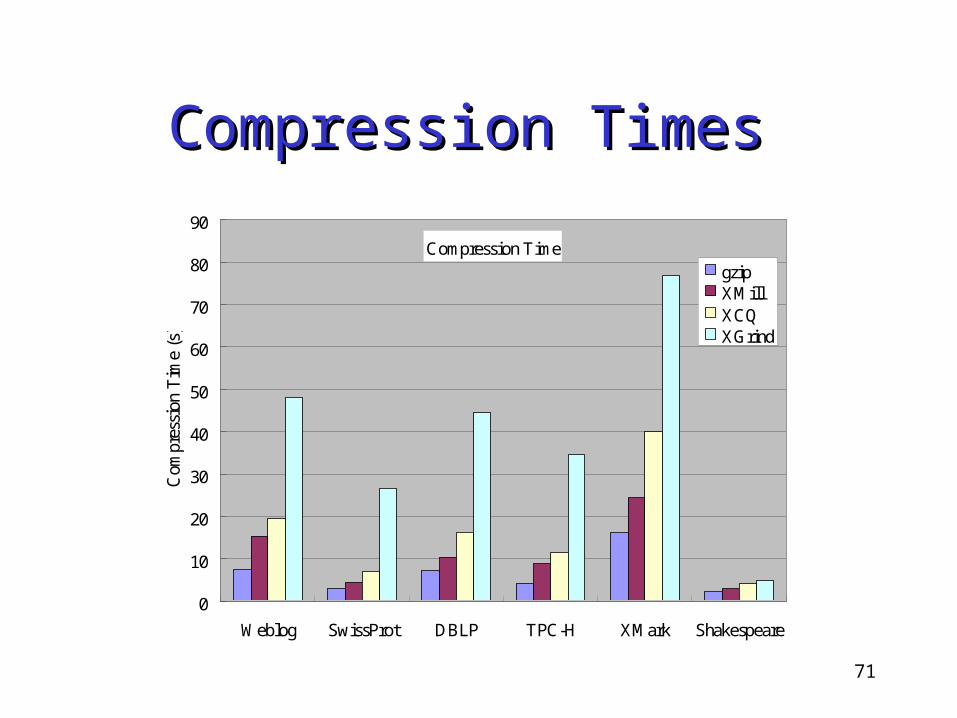
Compression TimesCompression Times
Compression Time
0
10
20
30
40
50
60
70
80
90
Weblog SwissProt DBLP TPC-H XMark Shakespeare
Com
pres
sion
Tim
e (s
)
gzipXMillXCQXGrind
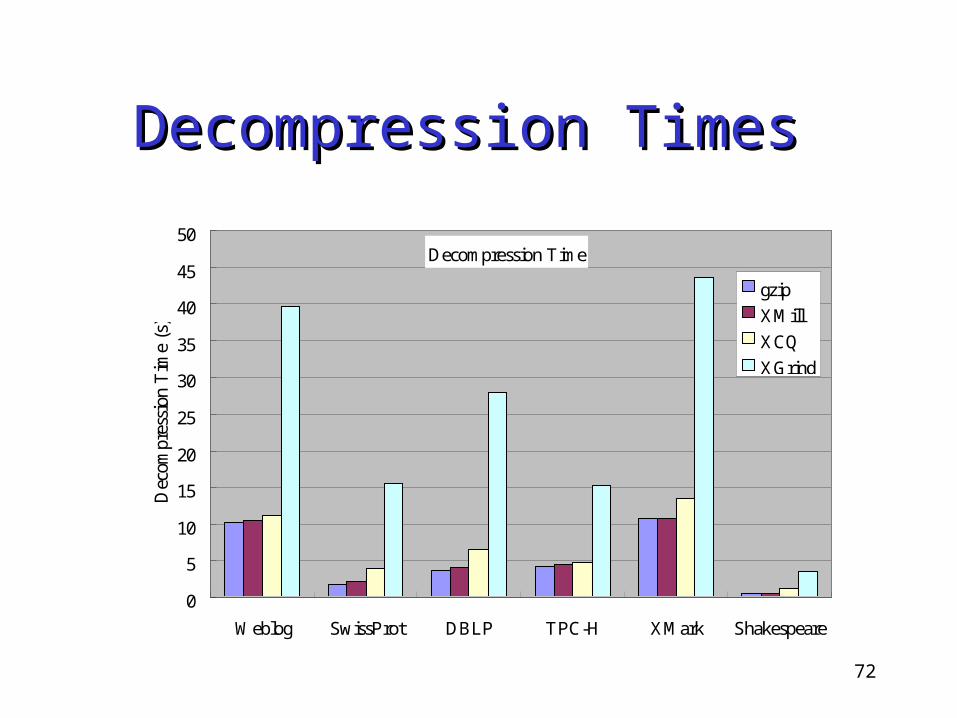
72
Decompression TimesDecompression Times
Decompression Time
0
5
10
15
20
25
30
35
40
45
50
Weblog SwissProt DBLP TPC-H XMark Shakespeare
Dec
ompr
essi
on T
ime
(s)
gzip
XMill
XCQ
XGrind

73
Experiment – Experiment – Compression PerformanceCompression Performance
Compression Performance• gzip, XMill, XCQ and XGrind• Scalability• XCQ
Partitioning BSS Indexing overhead
Result:
Comparable to XMill
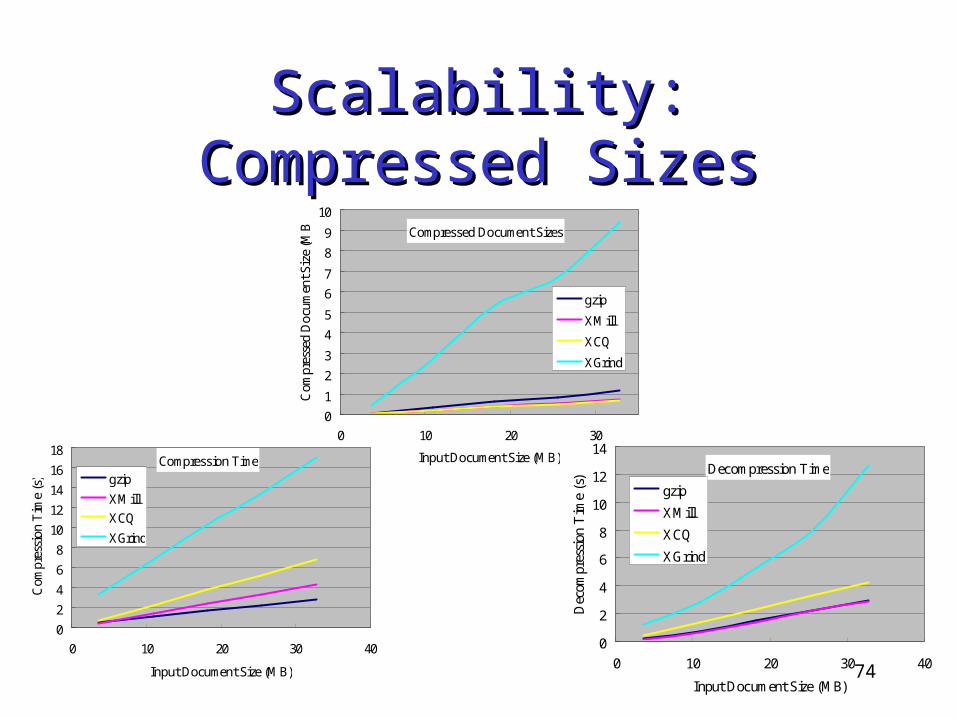
74
Scalability: Compressed SizesScalability: Compressed Sizes
Compressed Document Sizes
0
1
2
3
4
5
6
7
8
9
10
0 10 20 30
Input Document Size (MB)
Com
pres
sed
Doc
umen
t Siz
e (M
B)
gzip
XMill
XCQ
XGrind
Compression Time
0
2
4
6
8
10
12
14
16
18
0 10 20 30 40
Input Document Size (MB)
Com
pres
sion
Tim
e (s
) gzip
XMill
XCQ
XGrind
Decompression Time
0
2
4
6
8
10
12
14
0 10 20 30 40
Input Document Size (MB)
Dec
ompr
essi
on T
ime
(s)
gzip
XMill
XCQ
XGrind

75
Experiment – Experiment – Compression PerformanceCompression Performance
Compression Performance• gzip, XMill, XCQ (No Partition) and XGrind• Scalability• XCQ
Partitioning BSS Indexing
Result:
Overheads introduced are low
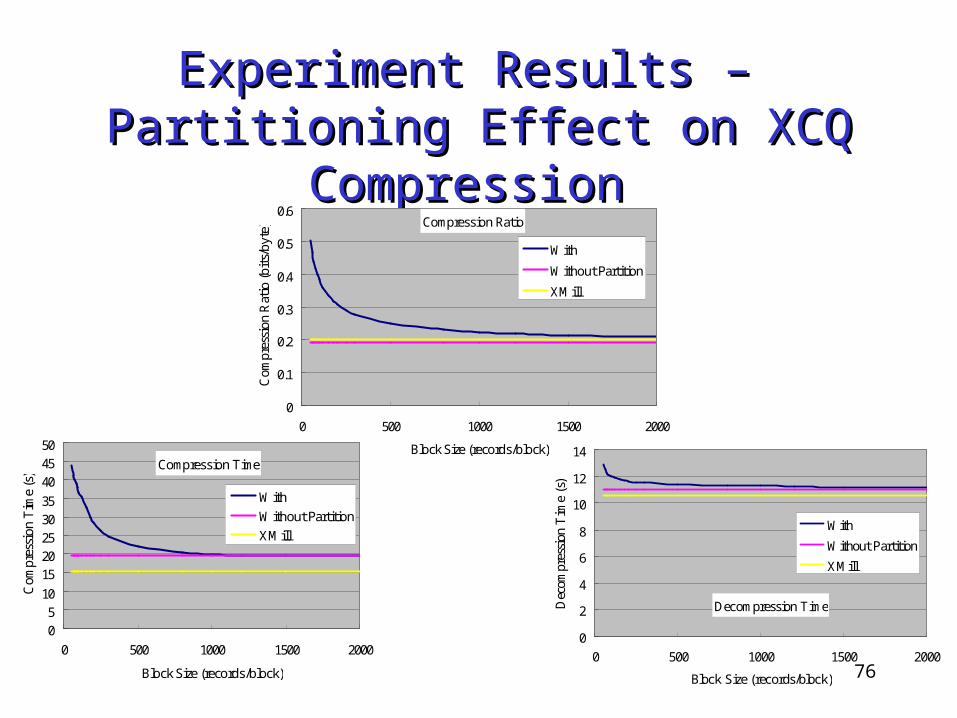
76
Experiment Results – Experiment Results – Partitioning Effect on XCQ CompressionPartitioning Effect on XCQ Compression
Compression Ratio
0
0.1
0.2
0.3
0.4
0.5
0.6
0 500 1000 1500 2000
Block Size (records/block)
Com
pres
sion
Rat
io (b
its/
byte
)With
Without Partition
XMill
Compression Time
05
10
1520253035
404550
0 500 1000 1500 2000
Block Size (records/block)
Com
pres
sion
Tim
e (s
)
With
Without Partition
XMill
Decompression Time
0
2
4
6
8
10
12
14
0 500 1000 1500 2000
Block Size (records/block)
Dec
ompr
essi
on T
ime
(s)
With
Without Partition
XMill
77
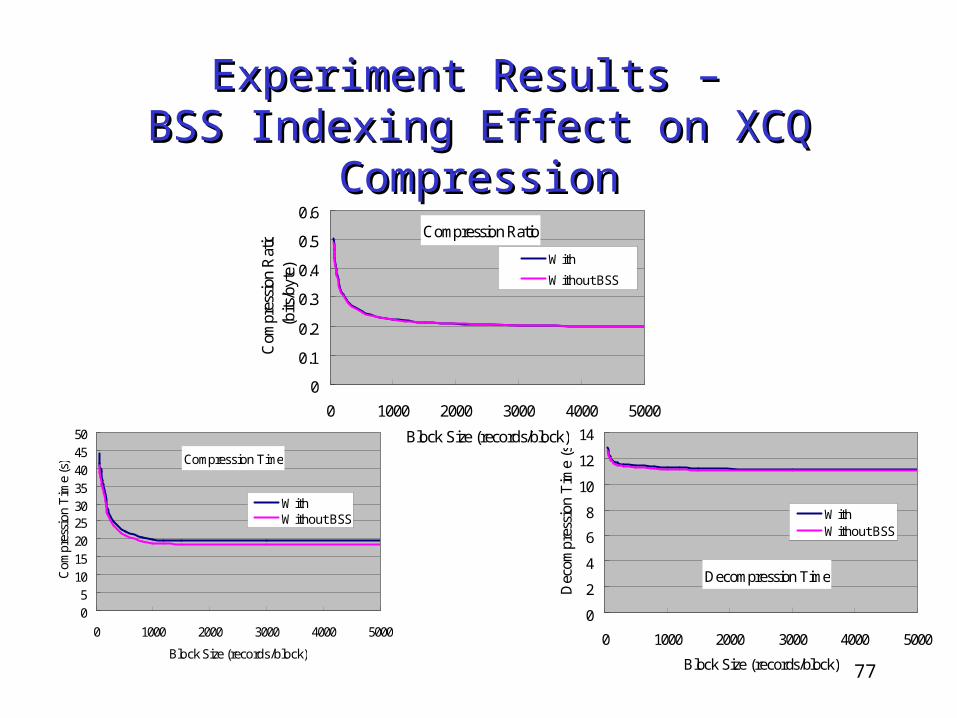
Experiment Results – Experiment Results – BSS Indexing Effect on XCQ CompressionBSS Indexing Effect on XCQ Compression
Compression Ratio
0
0.1
0.2
0.3
0.4
0.5
0.6
0 1000 2000 3000 4000 5000
Block Size (records/block)
Com
pres
sion
Rat
io(b
its/b
yte)
With
Without BSS
Compression Time
05
101520253035404550
0 1000 2000 3000 4000 5000
Block Size (records/block)
Com
pres
sion
Tim
e (s
)
WithWithout BSS
Decompression Time
0
2
4
6
8
10
12
14
0 1000 2000 3000 4000 5000
Block Size (records/block)
Dec
ompr
essi
on T
ime
(s)
WithWithout BSS
78
Experiment – Experiment – Compression PerformanceCompression Performance
Query Performance• Different block sizes have impact!• XCQ vs XGrind
Result:
Choose a good block size
79
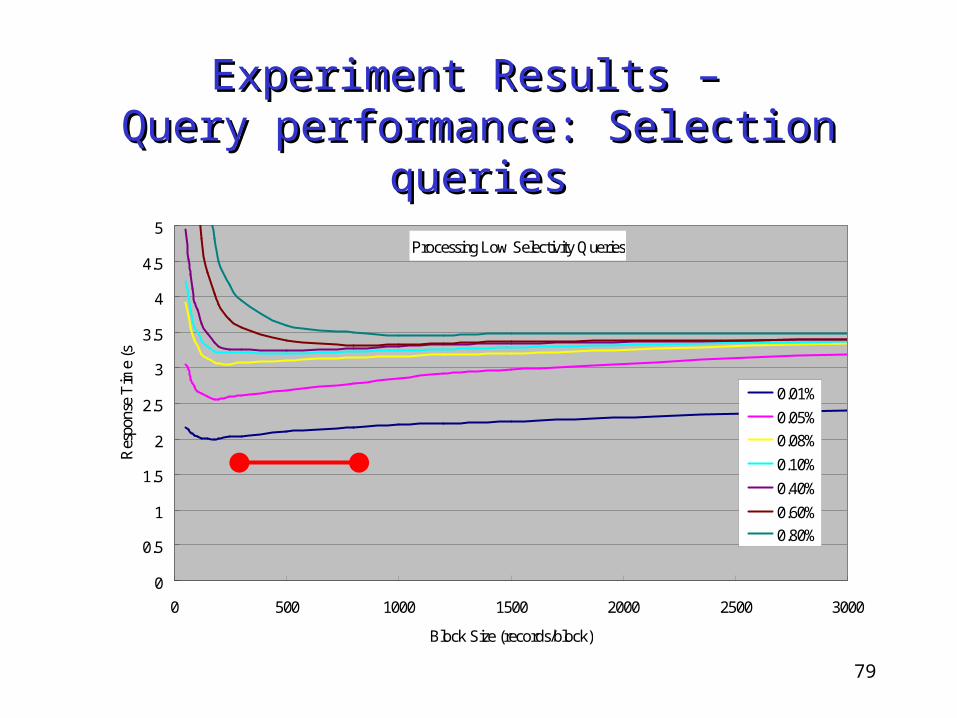
Experiment Results – Experiment Results – Query performance: Selection queriesQuery performance: Selection queries
Processing Low Selectivity Queries
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
0 500 1000 1500 2000 2500 3000
Block Size (records/block)
Res
pons
e T
ime
(s)
0.01%
0.05%
0.08%
0.10%
0.40%
0.60%
0.80%
80
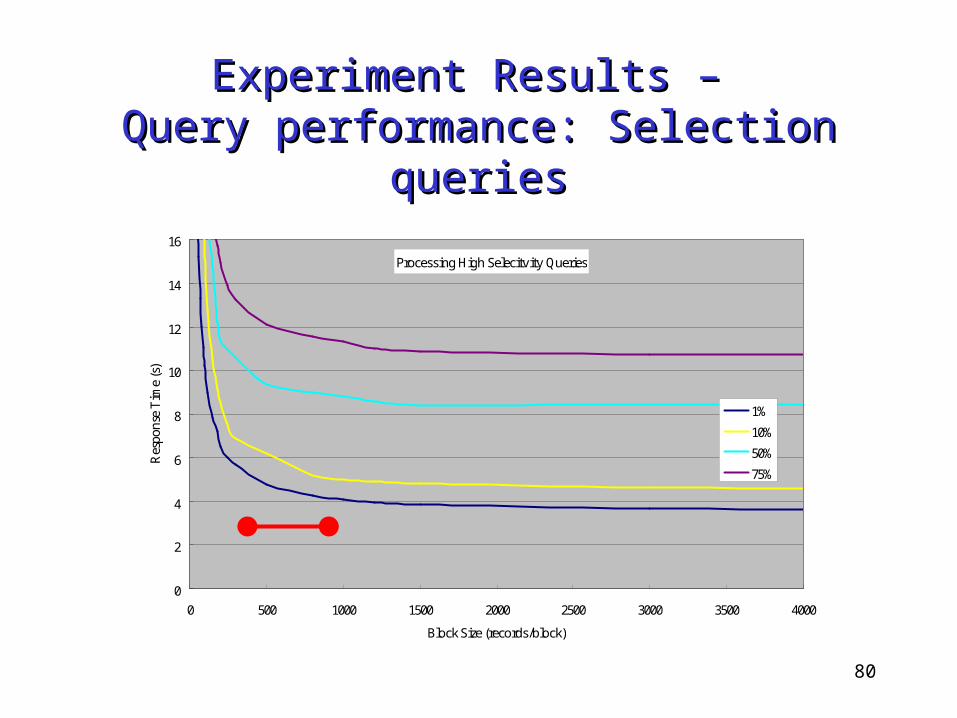
Experiment Results – Experiment Results – Query performance: Selection queriesQuery performance: Selection queries
Processing High Selecitvity Queries
0
2
4
6
8
10
12
14
16
0 500 1000 1500 2000 2500 3000 3500 4000
Block Size (records/block)
Res
pons
e T
ime
(s)
1%
10%
50%
75%
81
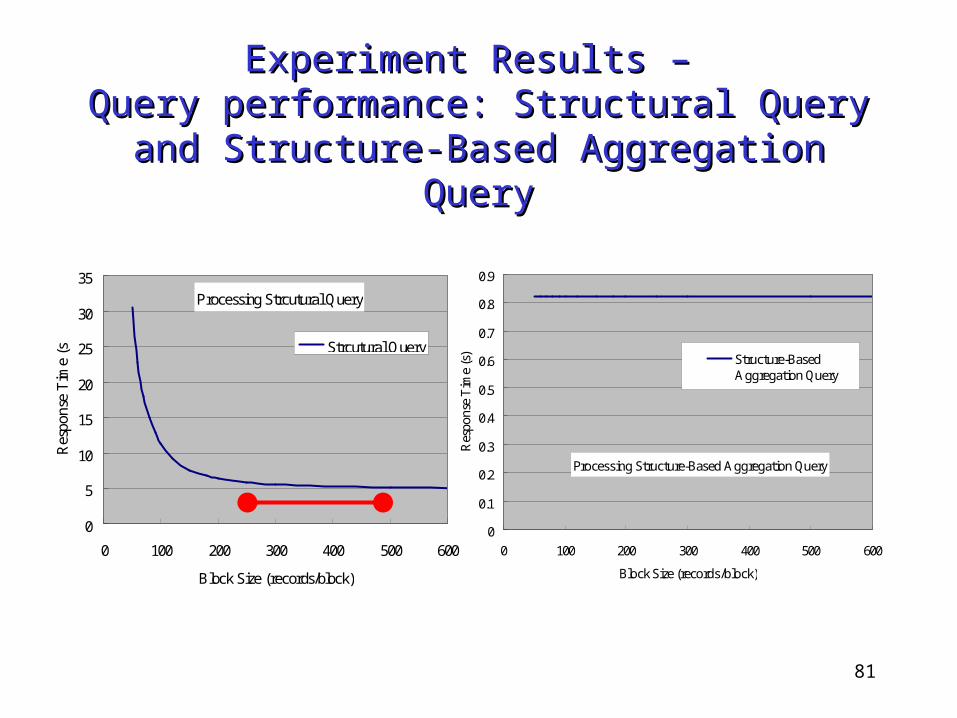
Experiment Results – Experiment Results – Query performance: Structural Query and Structure-Query performance: Structural Query and Structure-
Based Aggregation QueryBased Aggregation Query
Processing Strcutural Query
0
5
10
15
20
25
30
35
0 100 200 300 400 500 600
Block Size (records/block)
Res
pons
e T
ime
(s) Strcutural Query
Processing Structure-Based Aggregation Query
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
0 100 200 300 400 500 600
Block Size (records/block)
Res
pons
e T
ime
(s) Structure-Based
Aggregation Query
82
Experiment Results – Experiment Results – Query performance: Query performance:
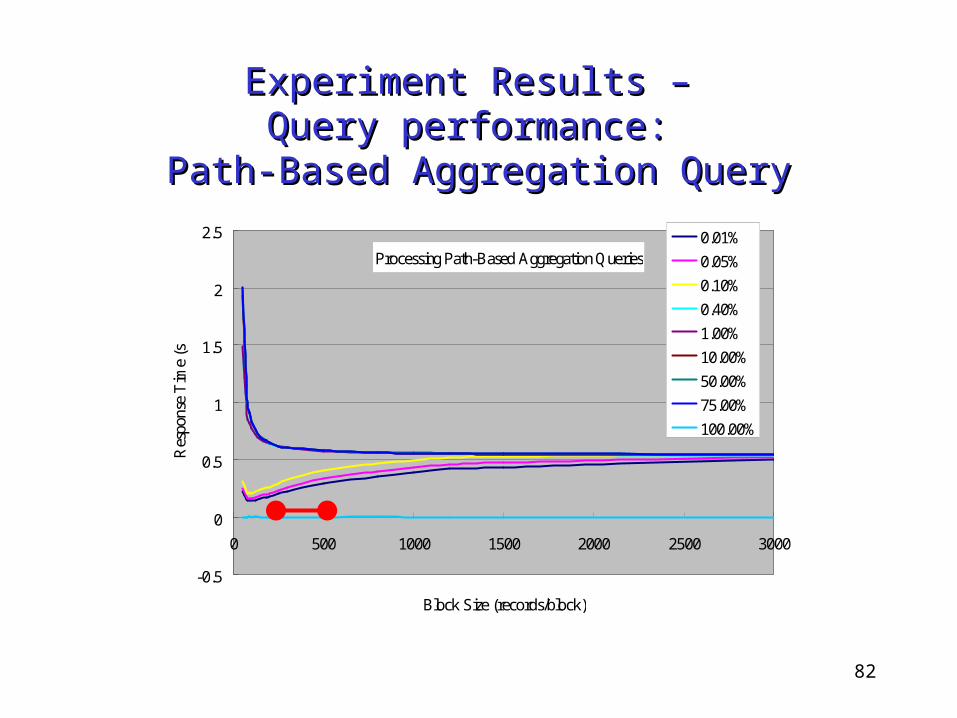
Path-Based Aggregation QueryPath-Based Aggregation Query
Processing Path-Based Aggregation Queries
-0.5
0
0.5
1
1.5
2
2.5
0 500 1000 1500 2000 2500 3000
Block Size (records/block)
Res
pons
e T
ime
(s)
0.01%
0.05%
0.10%
0.40%
1.00%
10.00%
50.00%
75.00%
100.00%

83
Experiment – Experiment – Compression PerformanceCompression Performance
Query Performance• Different block sizes• XCQ vs XGrind
Objective:
How to choose a good block size?
A few hundred elements

84
Experiment – Experiment – Compression PerformanceCompression Performance
Query Performance• Different block sizes• XCQ vs XGrind
Objective:
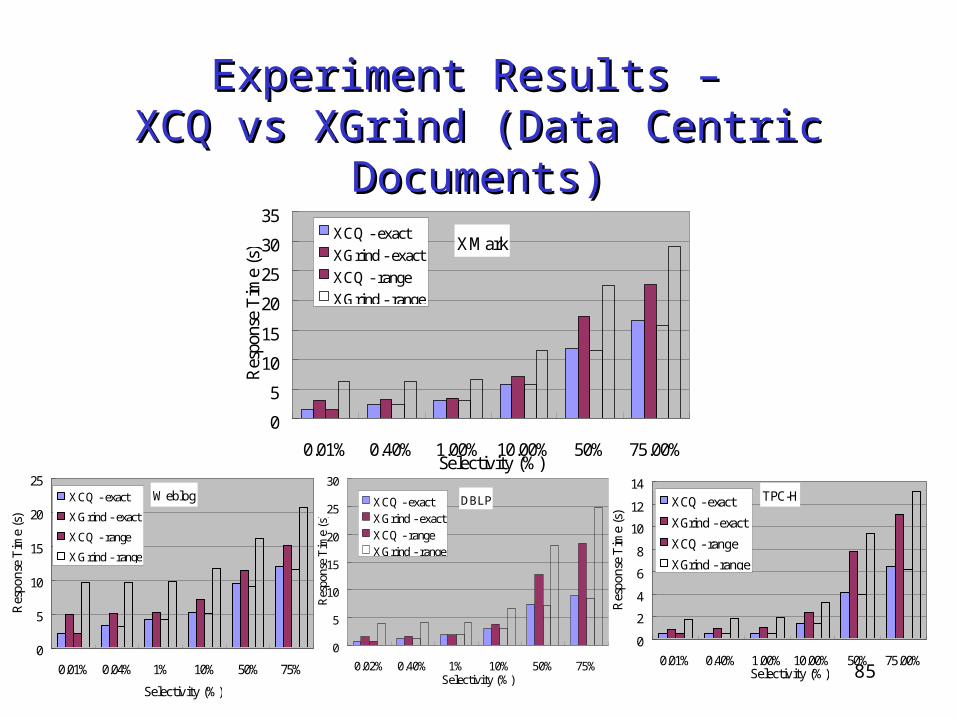
More efficient query performance
85
Experiment Results – Experiment Results – XCQ vs XGrind (Data Centric Documents)XCQ vs XGrind (Data Centric Documents)
TPC-H
0
2
4
6
8
10
12
14
0.01% 0.40% 1.00% 10.00% 50% 75.00%Selectivity (%)
Res
pons
e T
ime
(s)
XCQ - exact
XGrind - exact
XCQ - range
XGrind - range
XMark
0
5
10
15
20
25
30
35
0.01% 0.40% 1.00% 10.00% 50% 75.00%Selectivity (%)
Res
pons
e T
ime
(s)
XCQ - exact
XGrind - exact
XCQ - range
XGrind - range
Weblog
0
5
10
15
20
25
0.01% 0.04% 1% 10% 50% 75%
Selectivity (%)
Res
pons
e T
ime
(s)
XCQ - exact
XGrind - exact
XCQ - range
XGrind - range
DBLP
0
5
10
15
20
25
30
0.02% 0.40% 1% 10% 50% 75%Selectivity (%)
Res
pons
e T
ime
(s)
XCQ - exactXGrind - exactXCQ - rangeXGrind - range
86
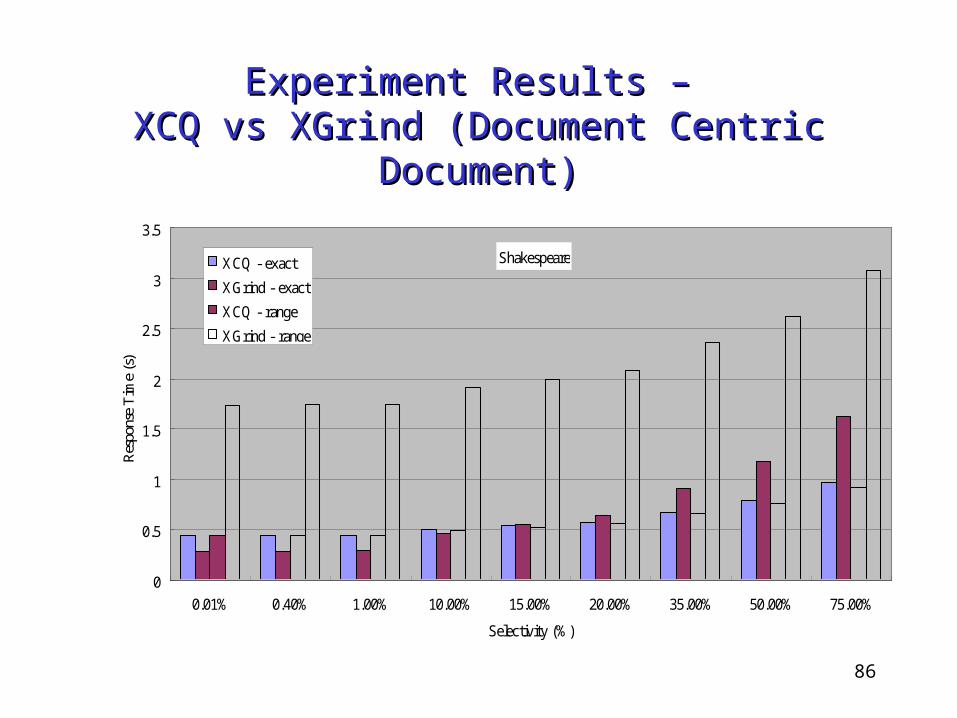
Experiment Results – Experiment Results – XCQ vs XGrind (Document Centric Document)XCQ vs XGrind (Document Centric Document)
Shakespeare
0
0.5
1
1.5
2
2.5
3
3.5
0.01% 0.40% 1.00% 10.00% 15.00% 20.00% 35.00% 50.00% 75.00%
Selectivity (%)
Res
pons
e T
ime
(s)
XCQ - exact
XGrind - exact
XCQ - range
XGrind - range

87
Lessons and DevelopmentLessons and Development XCQ Framework
• Developed techniques DSP PPG document format BSS indexing Access methods
Benefits of XCQ from experimental results• Simple Indexing, Mathematical Foundation• Compression performance
Comparable to XMill
• Query performance Better than XGrind for Data-Centric Documents Comparable to XGrind for Document-Centric Document

88
Multi-query evaluation of Multi-query evaluation of Compressed Data over networkCompressed Data over network
Widespread XML documents in remote locations• Large scale • XML verbosity
Traditional XML query processing• One by one on a standalone system• Original result fragments or whole documents are forwarded.
Heavy bandwidth costs for Internet or Poor processing
efficiency Motivations:
• Provide efficient query evaluation on compressed XML data
• Reduce bandwidth consumption in result publication
89
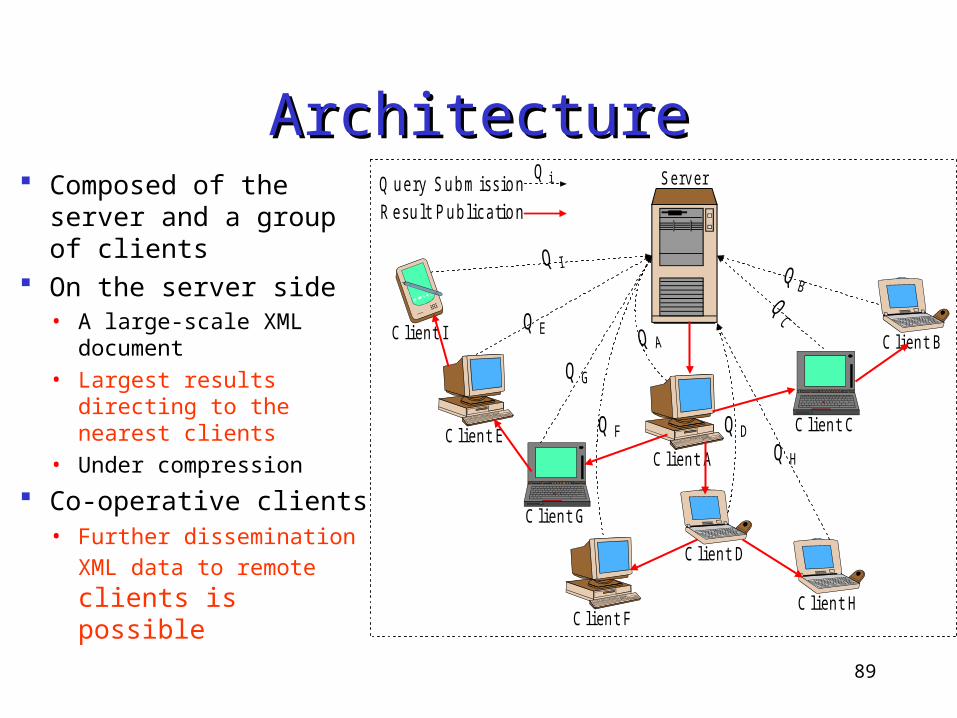
ArchitectureArchitecture Composed of the server
and a group of clients On the server side
• A large-scale XML document
• Largest results directing to the nearest clients
• Under compression
Co-operative clients• Further dissemination
XML data to remote clients is possible C lient F
C lient B
C lient D
C lient I
C lient G
C lient A
C lient H
C lient EC lient C
Q u e ry S u b m is s io n
Q I
Q E
Q G
Q F
Q A
Q D
Q H
QB
QC
Q i Server
R e s u lt P u b lic a tio n

90
Preliminaries- XPressPreliminaries- XPress XPress
• For tags reverse arithmetic encoding Encoded into numerical intervals
• For text dictionary & huffman encoder
• Compared with XGrind Higher compression ratio More efficient query evaluation
• Less decompression need

91
Preliminaries-Interval EncodingPreliminaries-Interval Encoding
Reverse arithmetic encoding • Adopted to compress tags in XPress
Element a b c
Probability 0.3 0.3 0.4
Original interval
[0.0, 0.3)
[0.3, 0.6) [0.6, 1.0)

92
Preliminaries-Interval EncodingPreliminaries-Interval Encoding
Reverse arithmetic encoding • Adopted to compress tags in XPress
• The interval of “/a/c” is
[0.6+0.4*0.0, 0.6+0.4*0.3) = [0.6, 0.72)
Element a b c
Probability 0.3 0.3 0.4
Original interval
[0.0, 0.3)
[0.3, 0.6) [0.6, 1.0)
Original interval of c

93
Preliminaries-Interval EncodingPreliminaries-Interval Encoding
Reverse arithmetic encoding • Adopted to compress tags in XPress
• The interval of “/a/c” is
[0.6+0.4*0.0, 0.6+0.4*0.3) = [0.6, 0.72)
Element a b c
Probability 0.3 0.3 0.4
Original interval
[0.0, 0.3)
[0.3, 0.6) [0.6, 1.0)
Probability of c

94
Preliminaries-Interval EncodingPreliminaries-Interval Encoding
Reverse arithmetic encoding • Adopted to compress tags in XPress
• The interval of “/a/c” is
[0.6+0.4*0.0, 0.6+0.4*0.3) = [0.6, 0.72)
Element a b c
Probability 0.3 0.3 0.4
Original interval
[0.0, 0.3)
[0.3, 0.6) [0.6, 1.0)
Original interval of a

95
Preliminaries-Interval EncodingPreliminaries-Interval Encoding
Reverse arithmetic encoding • Adopted to compress tags in XPress
• The interval of “/a/c” is
[0.6+0.4*0.0, 0.6+0.4*0.3) = [0.6, 0.72)• The interval of “//c” is [0.6, 1.0)
Element a b c
Probability 0.3 0.3 0.4
Original interval
[0.0, 0.3)
[0.3, 0.6) [0.6, 1.0)

96
Preliminaries-Interval EncodingPreliminaries-Interval Encoding Reverse arithmetic encoding
• Adopted to compress tags in XPress
• The interval of “/a/c” is [0.6+0.4*0.0, 0.6+0.4*0.3) = [0.6, 0.72)
• The interval of “//c” is [0.6, 1.0)• “//c” is a suffix of “/a/c”
The interval of “//c” contains the interval of “/a/c”
Element a b c
Probability 0.3 0.3 0.4
Original interval
[0.0, 0.3)
[0.3, 0.6) [0.6, 1.0)

97
Preliminaries-XML ContainmentPreliminaries-XML Containment
Query Evaluation on compressed document• XP{/, //, *}
• Query QA, QB submitted by client CA and CB

98
Preliminaries-XML ContainmentPreliminaries-XML Containment
Query Evaluation on compressed document• XP{/, //, *}
• Query QA, QB submitted by client CA and CB
XPath Containment• If QA’s result is always
contained by QB’s for every XML document, then QB contains QA.

99
Preliminaries-XML ContainmentPreliminaries-XML Containment
Query Evaluation on compressed document• XP{/, //, *}
• Query QA, QB submitted by client CA and CB
XPath Containment• If QA’s result is always
contained by QB’s for every XML document, then QB contains QA.
Application in our scenario• If QB contains QA, then result of QA can be published by CB.
• Classify queries based on the containment relationship

100
Our approachOur approach
Query-Index-Tree (QIT) QIT Construction Multi-Query Evaluation Sub-Index Construction for Clients

101
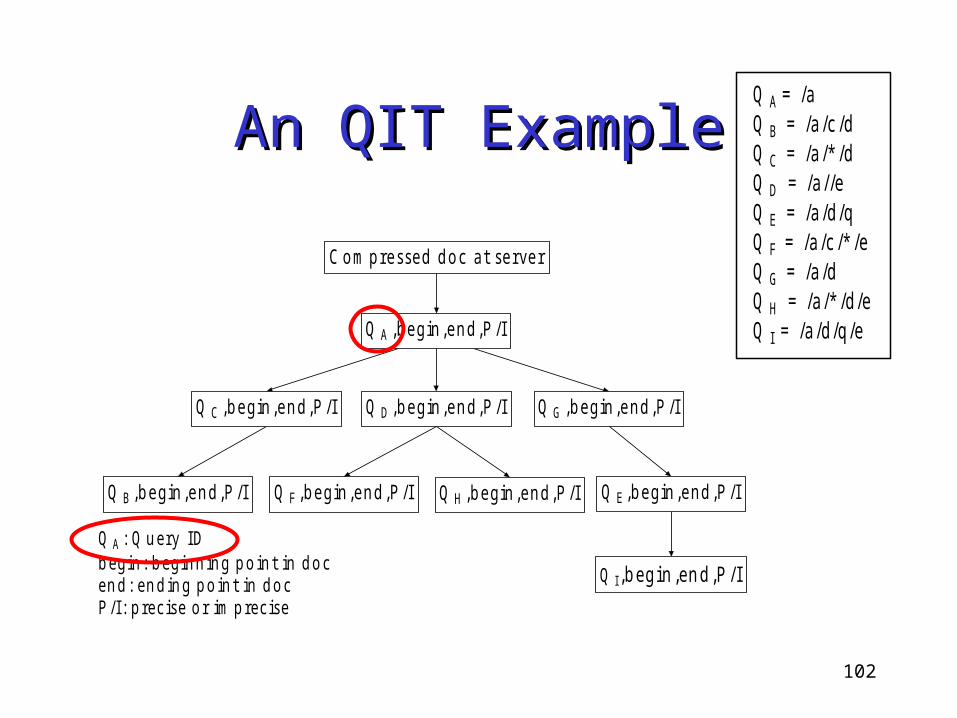
Query-Index-Tree (QIT)Query-Index-Tree (QIT)
Built at the server side• Each node corresponds to a query
• Explore containment relationship Among ancestors and descendants
• Remark all result locations as indices
Target• based on the hierachical level of QIT
Evaluate queries Route result fragments
102
An QIT ExampleAn QIT Example
Q A ,b e gin ,e n d ,P /I
Q A : Q u e ry IDb e g in : b e g in n in g p o in t in d o ce n d : e n d in g p o in t in d o cP /I: p re c is e o r im p re c is e
Q C ,b e gin ,e n d ,P /I Q D ,b e gin ,e n d ,P /I Q G ,b e gin ,e n d ,P /I
Q B ,b e gin ,e n d ,P /I Q F ,b e gin ,e n d ,P /I Q H ,b e gin ,e n d ,P /I Q E ,b e gin ,e n d ,P /I
Q I,b egin ,en d ,P /I
C o m p re sse d d o c a t se rve r
Q A = /a Q B = /a /c /d Q C = /a /* /d Q D = /a //e Q E = /a /d /q Q F = /a /c /* /e Q G = /a /d Q H = /a /* /d /e Q I = /a /d /q /e
103
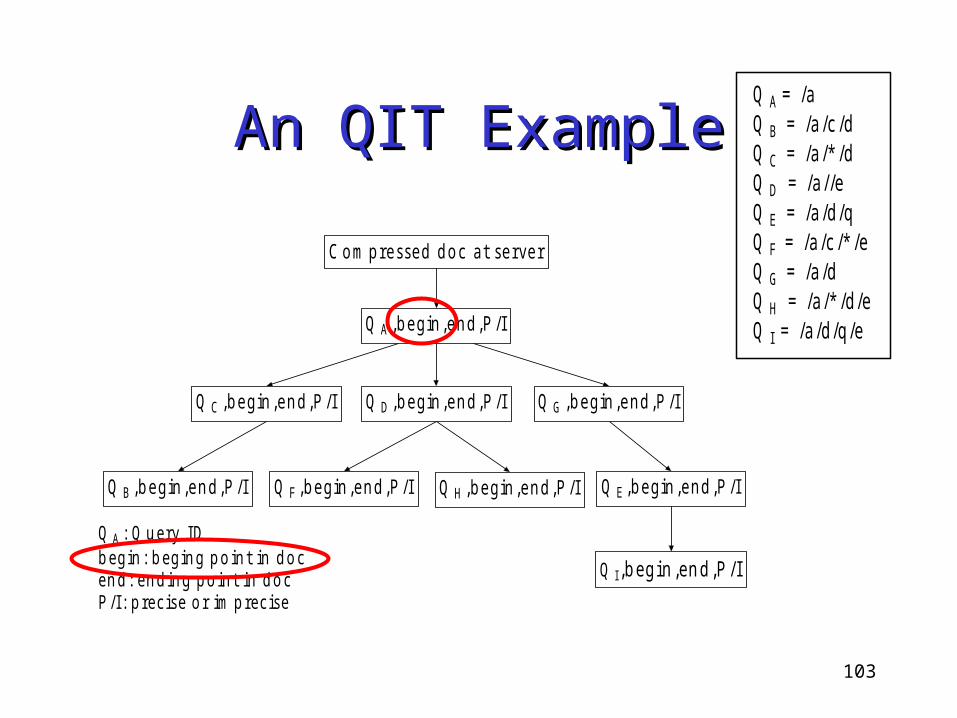
An QIT ExampleAn QIT Example
Q A ,b e gin ,e n d ,P /I
Q A : Q u e ry IDb e g in : b e g in g p o in t in d o ce n d : e n d in g p o in t in d o cP /I: p re c is e o r im p re c is e
Q C ,b e gin ,e n d ,P /I Q D ,b e gin ,e n d ,P /I Q G ,b e gin ,e n d ,P /I
Q B ,b e gin ,e n d ,P /I Q F ,b e gin ,e n d ,P /I Q H ,b e gin ,e n d ,P /I Q E ,b e gin ,e n d ,P /I
Q I,b egin ,en d ,P /I
C o m p re sse d d o c a t se rve r
Q A = /a Q B = /a /c /d Q C = /a /* /d Q D = /a //e Q E = /a /d /q Q F = /a /c /* /e Q G = /a /d Q H = /a /* /d /e Q I = /a /d /q /e

104
An QIT ExampleAn QIT Example
Q A ,b e gin ,e n d ,P /I
Q A : Q u e ry IDb e g in : b e g in g p o in t in d o ce n d : e n d in g p o in t in d o cP /I: p re c is e o r im p re c is e
Q C ,b e gin ,e n d ,P /I Q D ,b e gin ,e n d ,P /I Q G ,b e gin ,e n d ,P /I
Q B ,b e gin ,e n d ,P /I Q F ,b e gin ,e n d ,P /I Q H ,b e gin ,e n d ,P /I Q E ,b e gin ,e n d ,P /I
Q I,b egin ,en d ,P /I
C o m p re sse d d o c a t se rve r
Q A = /a Q B = /a /c /d Q C = /a /* /d Q D = /a //e Q E = /a /d /q Q F = /a /c /* /e Q G = /a /d Q H = /a /* /d /e Q I = /a /d /q /e
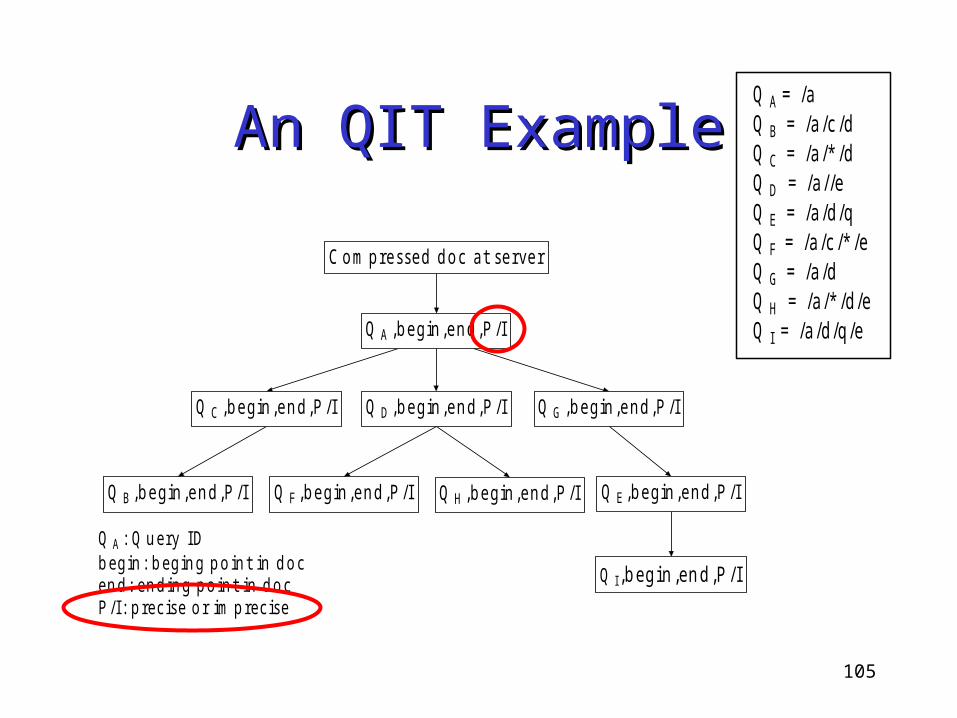
105
An QIT ExampleAn QIT Example
Q A ,b e gin ,e n d ,P /I
Q A : Q u e ry IDb e g in : b e g in g p o in t in d o ce n d : e n d in g p o in t in d o cP /I: p re c is e o r im p re c is e
Q C ,b e gin ,e n d ,P /I Q D ,b e gin ,e n d ,P /I Q G ,b e gin ,e n d ,P /I
Q B ,b e gin ,e n d ,P /I Q F ,b e gin ,e n d ,P /I Q H ,b e gin ,e n d ,P /I Q E ,b e gin ,e n d ,P /I
Q I,b egin ,en d ,P /I
C o m p re sse d d o c a t se rve r
Q A = /a Q B = /a /c /d Q C = /a /* /d Q D = /a //e Q E = /a /d /q Q F = /a /c /* /e Q G = /a /d Q H = /a /* /d /e Q I = /a /d /q /e

106
QIT ConstructionQIT Construction
Recursive classification
All submitted queries
is a descendant set of root

107
QIT ConstructionQIT Construction
Recursive classification
QA contains
all other queries

108
QIT ConstructionQIT Construction
Recursive classification
Recursive classification
in QA’s descendant set
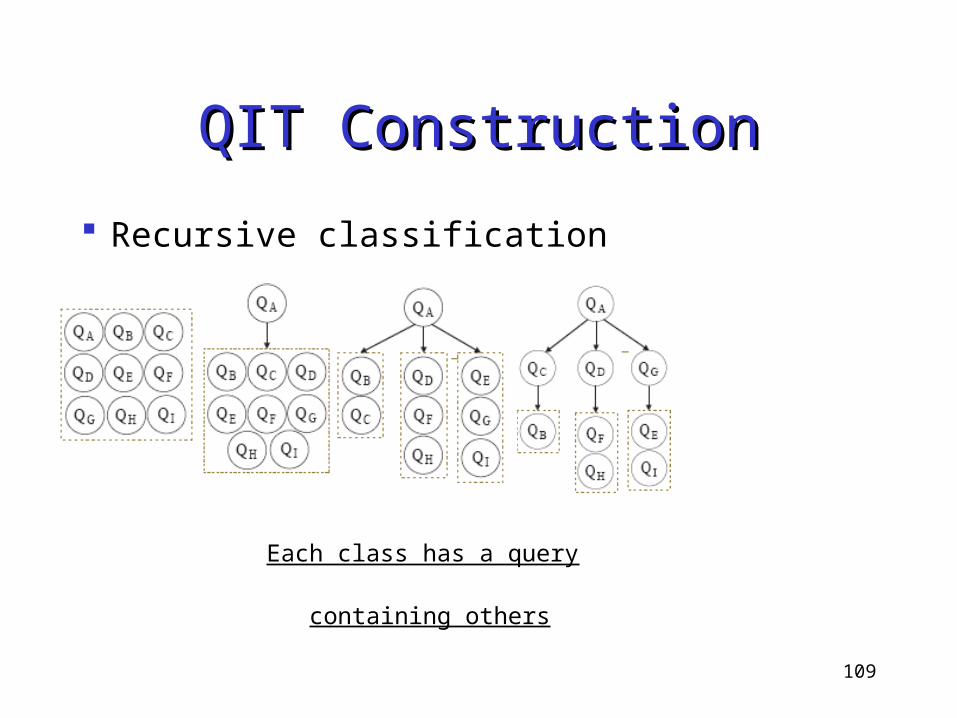
109
QIT ConstructionQIT Construction
Recursive classification
Each class has a query
containing others
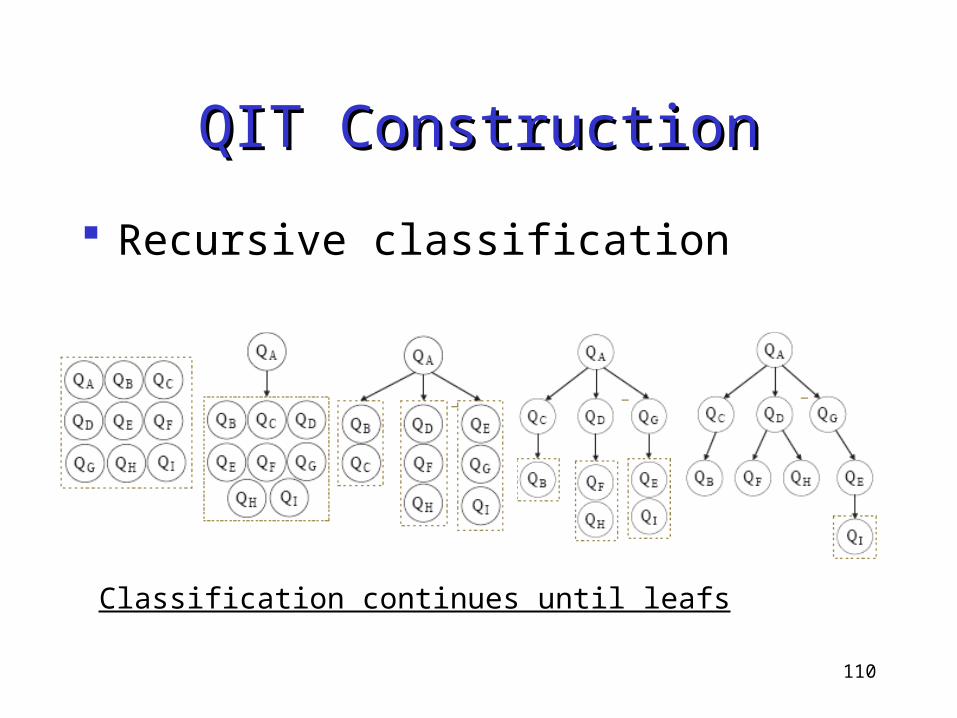
110
QIT ConstructionQIT Construction
Recursive classification
Classification continues until leafs

111
Preprocess for Multi-Query Preprocess for Multi-Query EvaluationEvaluation
On server side, Over compressed document• How to evaluate queries using QIT• How to support intermediate clients to locate results
Tags are encoded into intervals• To avoid decompression in query processing• Interval translation
Simple path interval Complex path simple paths intervals
• Examples “/a/b//c/d” “/a/b” & “/c/d” “/a/b/*/c/d” “/a/b”, “*” & “/c/d”
112
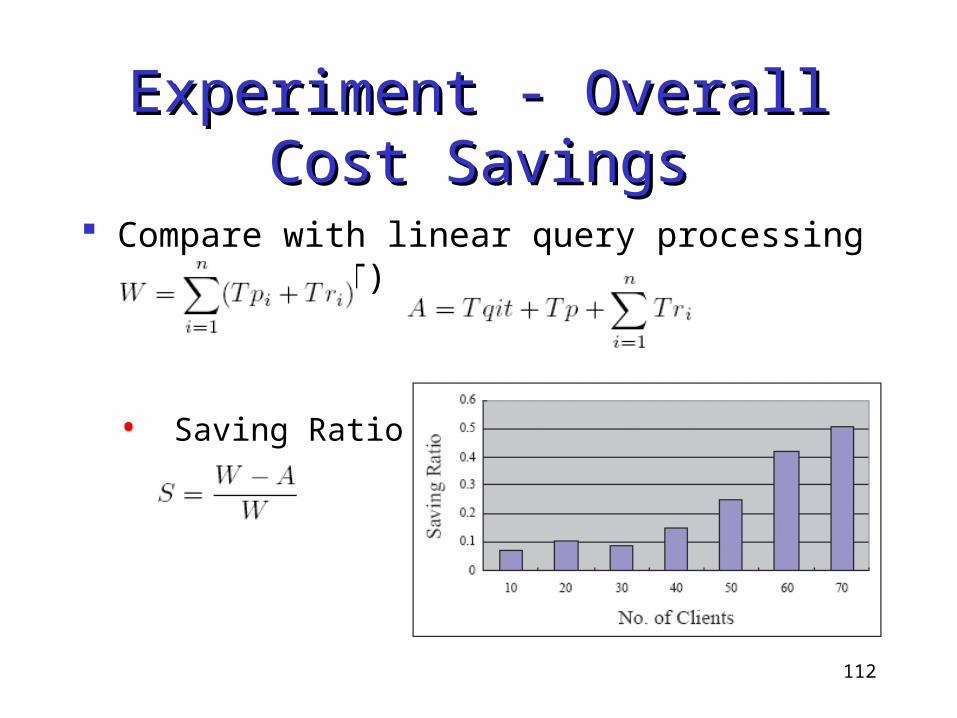
Experiment - Overall Cost Experiment - Overall Cost SavingsSavings
Compare with linear query processing (without QIT)
•
• Saving Ratio

113
Collaborative ProcessingCollaborative Processing
A co-operative framework for multi-query processing over compressed XML data
Keep results under compression to save bandwidth Bring forward QIT and building algorithm Future work
• QIT is not enough for handling complex XPath
• Subscribed queries and non-subscribed queries.
• XPath queries and XPath FT queries

114
Papers: CompressionPapers: Compression XMILL: An Efficient Compressor for XML Data by Liefke and Suciu, in
SIGMOD'2001 P. M. Tolani and J. R. Haritsa. XGRIND: A Query-friendly XML Compressor.
IEEE ICDE Conf., pp. 225-234, 2002. M. Girardot and N. Sundaresan. Millau: an encoding format for efficient
representation and exchange of XML over the Web. WWW Conf., pp. 747-765, 2000.
H. Ishikawa, S. Yokoyama, S. Isshiki and M. Ohta. Project Xanadu: XML- and Active-Database-Unified Approach to Distributed E-Commerce. Int. Workshop on DEXA, 2001.
A.Arion, A. Bonifati, G. Costa, S. D’Aguanno, I. Manolescu, A. Pugliese, Efficient Query Evaluation over XML Compressed Data, EDBT 2004.
JunKi Min, MyungJae Park, ChinWan Chung, XPRESS: A Queriable Compression for XML Data, EDBT 2004.

115
Our publications for XML compressionOur publications for XML compression• Xiaoling WANG, Aoying ZHOU, Juzhen HE and Wilfred NG.
MQX: Multi-Query Processing Engine for Compressed XML Data. International Conference on Information Retrieval. ACM SIGIR 2007, Amsterdam, Holland (Demonstration Paper), pp. 897, (2007).
• Wilfred NG, Ho-Lam LAU and Aoying ZHOU. Divide, Compress and Conquer: Querying XML via Partitioned Path-Based Compressed Data Blocks. Accepted and to appear: World Wide Web Journal, (2006).
• Juzhen HE, Wilfred NG, Xiaoling WANG and Aoying ZHOU. An Efficient Co-operative Framework for Multi-Query Processing over Compressed XML Data. International Conference of Database Systems for Advanced Applications. DASFAA 2006, Lecture Notes in Computer Science Vol. 3882, Singapore, pp. 218-232, (2006).
• Wilfred NG, Wai-Yeung LAM, Peter WOOD and Mark LEVENE. XCQ: A Queriable XML Compression System. Accepted and to appear: An International Journal of Knowledge and Information Systems, (2005).
• Wilfred NG, Wai-Yeung LAM and James CHENG. Comparative Analysis of XML Compression Technologies. Accepted and to appear: World Wide Web Journal: Internet and Web Information Systems, (2005).
• James CHENG and Wilfred NG. XQzip: Querying Compressed XML Using Structural Indexing. International Conference on Extending Database Technology EDBT 2004, Lecture Notes of Computer Science Vol.2992, Heraklion, Crete, Greece, page 219-236, (2004).
• Wai-Yeung LAM, Wilfred NG, Peter WOOD and Mark LEVENE. XCQ: XML Compression and Querying System. Poster Proceedings of the World Wide Web WWW'2003, Budapest, (2003).


















