
1 K-clustering in Wireless Ad Hoc Networks using local search Rachel Ben-Eliyahu-Zohary JCE and BGU...
49
1 K-clustering in Wireless Ad Hoc Networks using local search Rachel Ben-Eliyahu-Zohary JCE and BGU Joint work with Ran Giladi (BGU) and Stuart Sheiber and Philip Hendrix (Harvard)
-
Upload
fred-tibbals -
Category
Documents
-
view
214 -
download
0
Transcript of 1 K-clustering in Wireless Ad Hoc Networks using local search Rachel Ben-Eliyahu-Zohary JCE and BGU...

1
K-clustering in Wireless Ad Hoc Networks
using local search
Rachel Ben-Eliyahu-ZoharyJCE and BGU
Joint work with Ran Giladi (BGU) and Stuart Sheiber and Philip Hendrix (Harvard)

2
Cluster-based Routing Protocol
The network is divided to non overlapping sub-networks (clusters) with bounded diameter.
• Intra-cluster routing: pro-actively maintain state information for links within the cluster.
• Inter-cluster routing: use a route discovery protocol for determining routes. Route requests are propagated via peripheral nodes.

3
Cluster-based Routing Protocol
+ Limit the amount of routing information stored and maintained at individual hosts.
+ Clusters are manageable. Node mobility
events are handled locally within the clusters. Hence, far-reaching effects of topological changes are minimized.
4
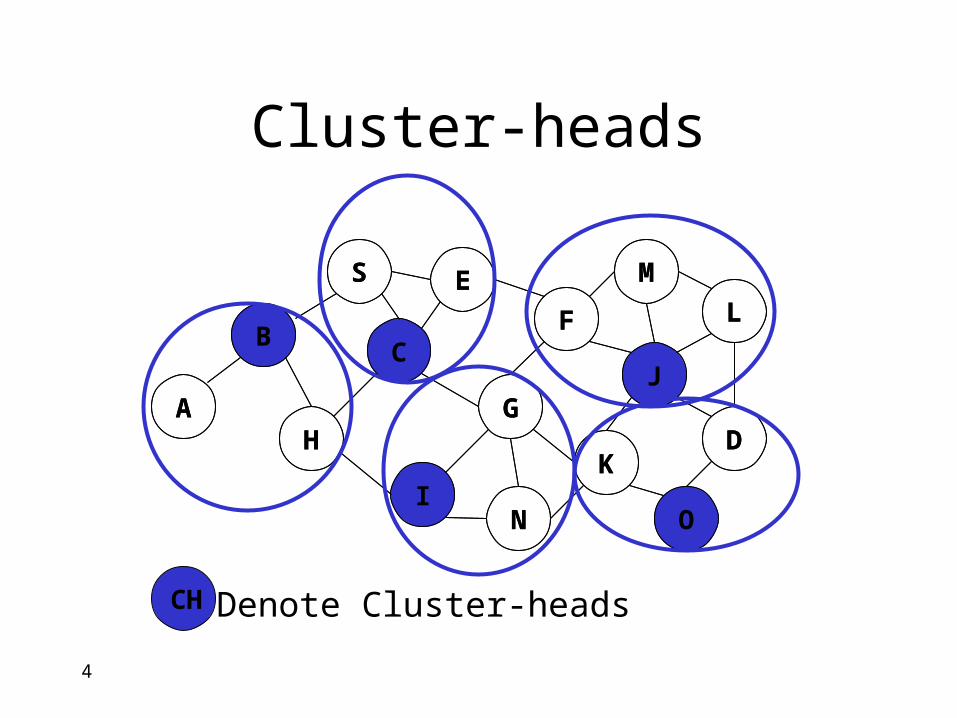
Cluster-heads
B
A
S E
F
H
J
D
C
G
IK
M
N
L
O
B
A
S E
F
H
J
D
C
G
IK
M
N
L
O
CH Denote Cluster-heads

5
K-Clustering
• Topology: the objective is to partition the network into minimum number of sub networks (clusters) with bounded diameter, k.
• A more symmetric topology than cluster heads.

6
Problem Statement
• Minimum k-clustering: given a graph G = (V,E) and a positive integer k, find the smallest value of ƒ such that there is a partition of V into ƒ disjoint subsets V1,…,Vƒ and diam(G[Vi]) <= k for i = 1…ƒ.
• The algorithmic complexity of k-clustering is known to be NP-complete for simple undirected graphs.

7
K-clustering K = 3
1
1
1 1
2
1
2
2
1
2
12
2
2
2
2

8
System Model
Two general assumptions regarding the state of the network’s communication links and topology:
1. The network may be modeled as an unit disk graph.
2. The network topology remains unchanged throughout the execution of the algorithm.
9
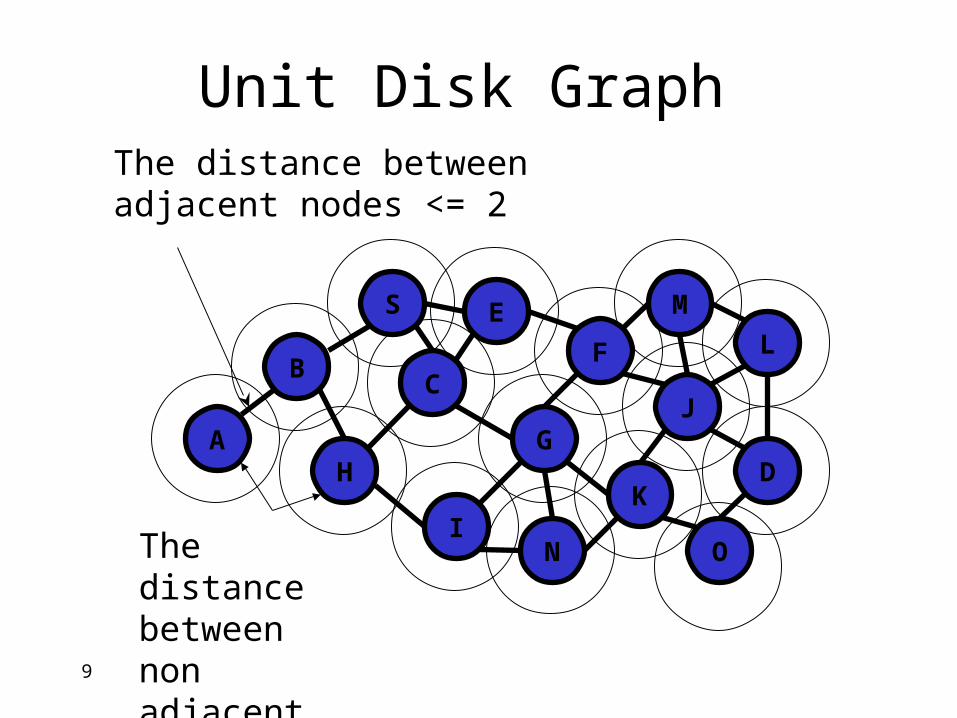
Unit Disk Graph
B
A
S E
F
H
J
D
C
G
IK
M
N
L
O
B
A
S E
F
H
J
D
C
G
IK
M
N
L
O
The distance between adjacent nodes <= 2
The distance between non adjacent nodes is > 2

10
Contribution of Fernandess and
Malkhi
A two phase distributed asynchronous polynomial approximation for k-clustering where k > 1 that has a competitive worst case ratio of O(k):
First phase – constructs a spanning tree of the network.
Second phase – partitions the spanning tree into sub-trees with bounded diameter.

11
Second Phase: K-sub-treeGiven a tree T=(V,E) the algorithm finds a sub-tree
whose diameter exceeds k, it then detaches the highest child of the sub-tree and repeats over on the reduced tree.
k
k- r
detach highest sub-tree
root of the sub-tree
sub-treesub-tree

12
Random DecentRANDOM_DESCENT(problem,terminate)returns solution stateinputs: problem, a problem
termination condition, a condition for stoppinglocal vars: current, a solution state
next, a solution state
current ← Initial State (problem(
while (not terminate) next ← a selected neighbor of current
∆ E← Value(next) - Value(current) if ∆ E <0 then current ←next

13
Initial State

14
Initial State (k=2)

15
K is even (e.g. 2)

16
K = 2 (cont.)
17
K = 2 (cont.)
18
K = 2 (cont.)

19
K = 2 (cont.)

20
K = 2 Total: 8 clusters

21
A better State

22
Random DecentRANDOM_DESCENT(problem,terminate)returns solution stateinputs: problem, a problem
termination condition, a condition for stoppinglocal vars: current, a solution state
next, a solution state
current ← Initial State (problem(
while (not terminate) next ← a selected neighbor of current
∆ E← Value(next) - Value(current) if ∆ E <0 then current ←next
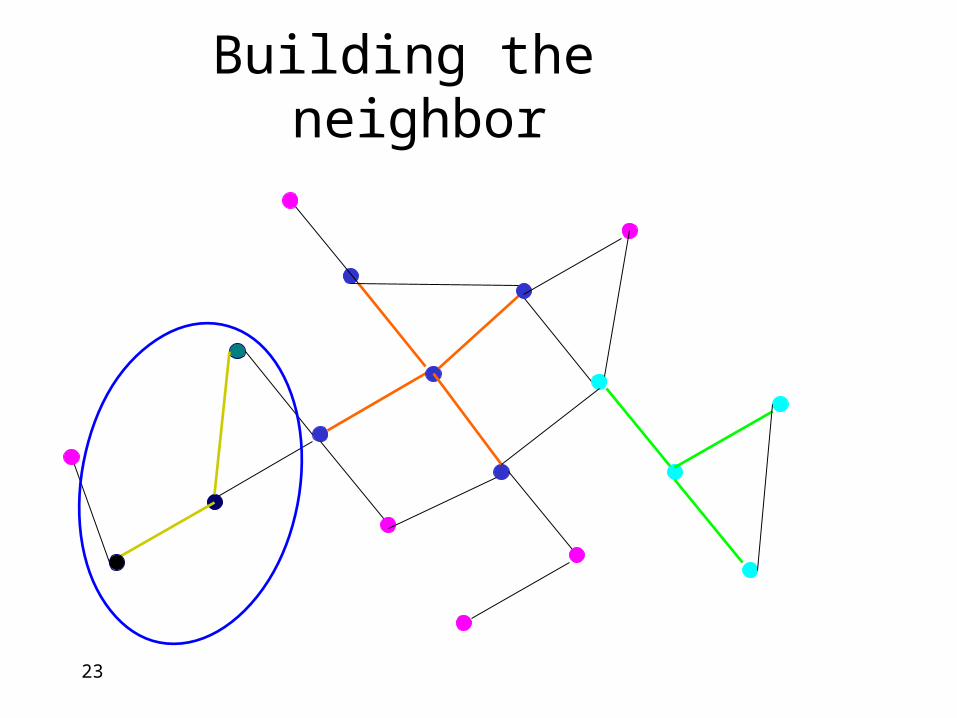
23
Building the neighbor

24
Building the neighbor

25
Building the neighbor

26
Building the neighbor

27
Building the neighbor
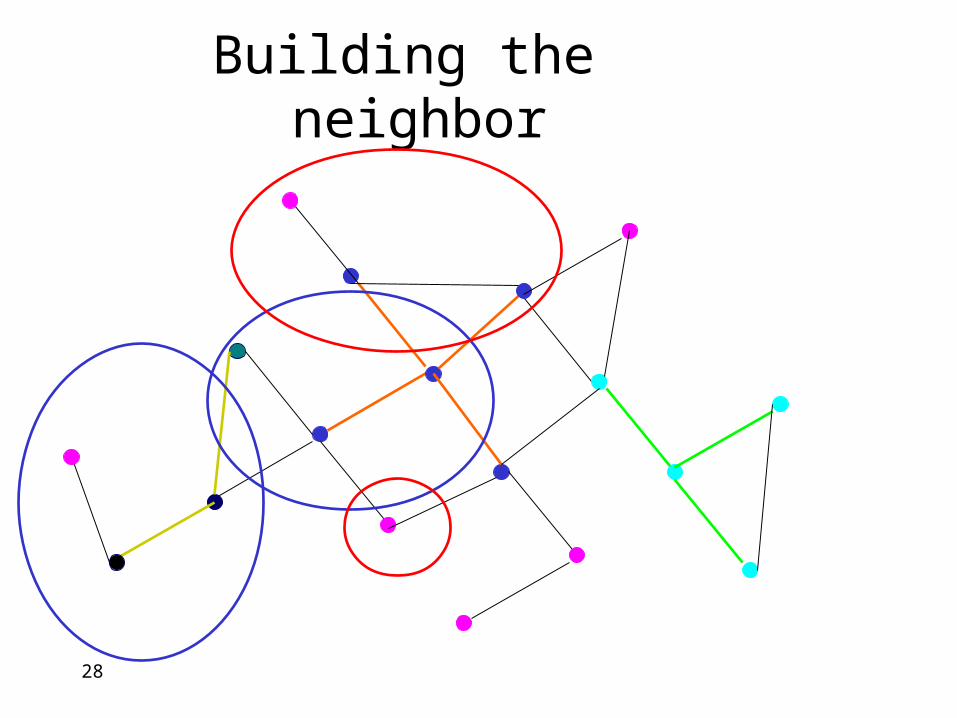
28
Building the neighbor

29
For Odd k:

30
K is odd (e.g. 3)

31
K is odd (e.g. 3)

32
Random DecentRANDOM_DESCENT(problem,terminate)returns solution stateinputs: problem, a problem
termination condition, a condition for stoppinglocal vars: current, a solution state
next, a solution state
current ← Initial State (problem(
while (not terminate) next ← a selected neighbor of current
∆ E← Value(next) - Value(current) if ∆ E <0 then current ←next

33
Experimental Evaluation
• Randomly Generated Graphs
• Grid Graphs

34
Randomly Generated Graphs
• Parameters: – n – number of nodes– l – length of a unit
• Graph Generation: - n points are placed randomly on a 1X1
square- two vertices are connected iff the distance between them is less than l.

35
400 nodes, k=5

36
Results

37
Experiments on Grids

38
Theorem: The number of nodes in a maximal cluster in a greed:
• If K is even,
• If k is odd,
12
)12(21)21(212/
1
2/
1
2
kikikkk
i
k
i
k
kkk
kikikk kk
i
k
i
2
1
4
)1)(1(21221)21(21
22
1
1
2
1
1
e.g. 13 if k=4
e.g. 8 if k=3

39
A maximal cluster on grid
x+y=r
x+y=r+k
x-y=s
x-y=s-k
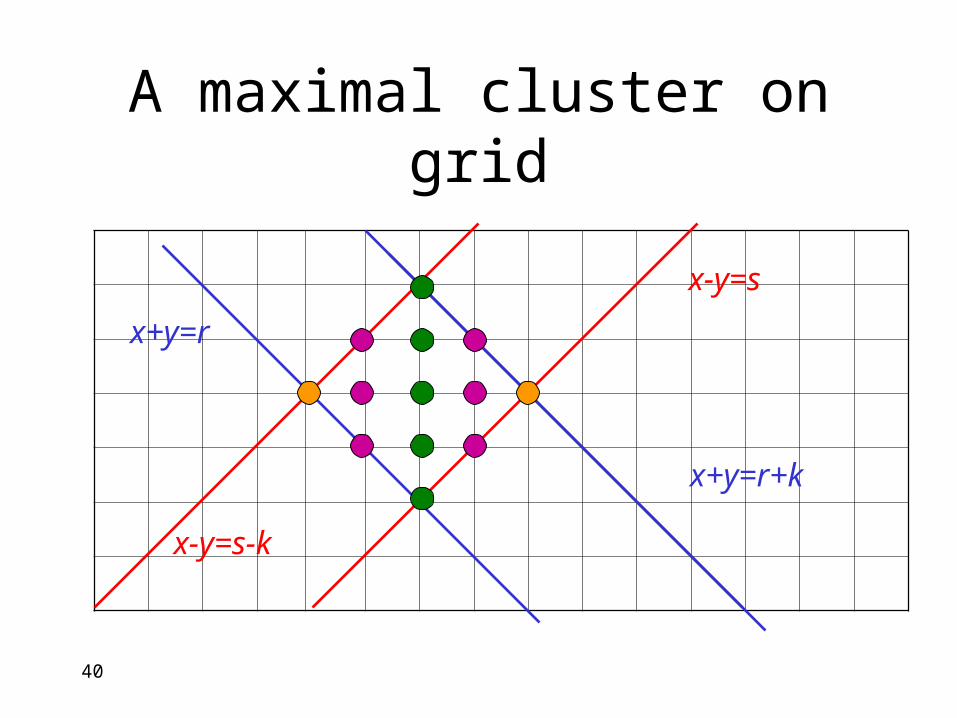
40
A maximal cluster on grid
x+y=r
x+y=r+k
x-y=s
x-y=s-k

41
A maximal cluster – k is even
x+y=r
x+y=r+4
x-y=s
x-y=s-4

42
A maximal cluster – k is odd
x+y=r
x+y=r+3
x-y=s
x-y=s-3

43
In general, number of nodes in a maximal cluster:• If K is even,
• If k is odd,
12
)12(21)21(212/
1
2/
1
2
kikikkk
i
k
i
k
kkk
kikikk kk
i
k
i
2
1
4
)1)(1(21221)21(21
22
1
1
2
1
1
e.g. 13 if k=4
e.g. 8 if k=3
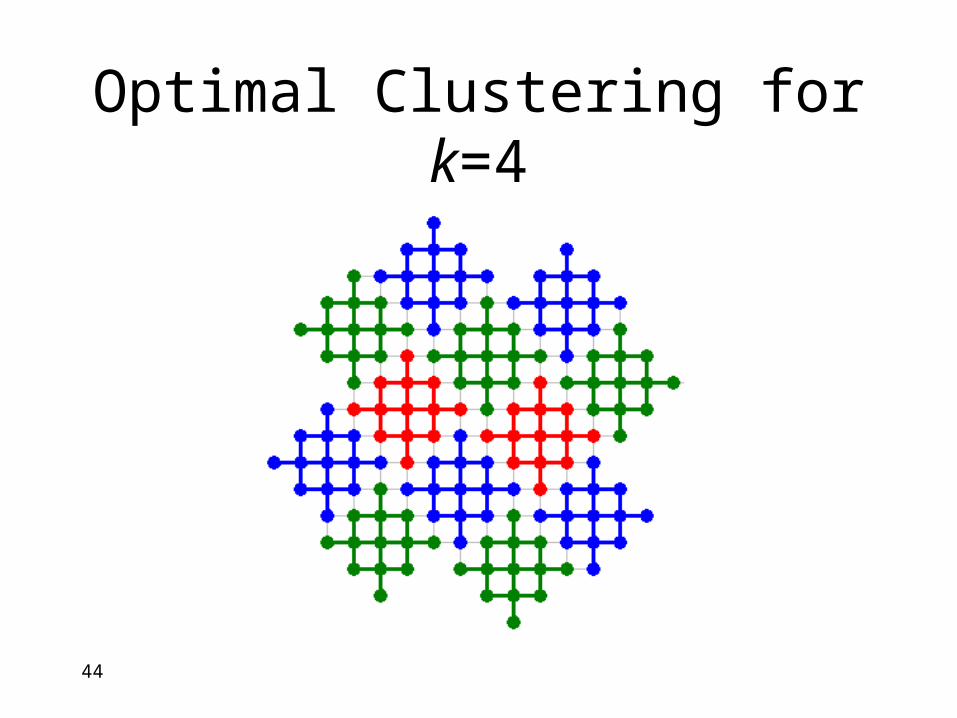
44
Optimal Clustering for k=4

45
Optimal Clustering for k=3

46

47
Related Work
• Local search techniques were used for network partitioning
• Simulated annealing and genetic algorithms
• Was tested on a very limited network size : 20-60 nodes.
• We present solid criteria for evaluating the local search

48
Conclusions
• A new local search algorithm for k-clustering was introduced
• It outperforms existing distributed algorithm for large k and dense networks.
• Grids can be built using optimal clustering
• Clustering on grids needs improvement.

49
Future Work
• Check a distributed version of local search
• Change the algorithm for local search• Find an efficient way to fix a solution –
e.g. by merging small clusters• Use local search for other optimization
problems in networking


















