
1 Fast and Efficient Partial Code Reordering Xianglong Huang (UT Austin, Adverplex) Stephen M....
29
1 Fast and Efficient Partial Code Reordering Xianglong Huang (UT Austin, Adverplex) Stephen M. Blackburn (Intel) David Grove (IBM) Kathryn McKinley (UT Austin)
-
Upload
harold-gallagher -
Category
Documents
-
view
222 -
download
4
Transcript of 1 Fast and Efficient Partial Code Reordering Xianglong Huang (UT Austin, Adverplex) Stephen M....

1
Fast and EfficientPartial Code Reordering
Xianglong Huang (UT Austin, Adverplex)Stephen M. Blackburn (Intel)David Grove (IBM)Kathryn McKinley (UT Austin)

2
Software Trends
• By 2008, 80% of software will be written in Java or C#. [Gartner report]
• Java and C# are coming to your OS soon - Jnode, Singularity
• Advantages of modern programming languages: – Productivity, security, reliability…
• Performance?
3
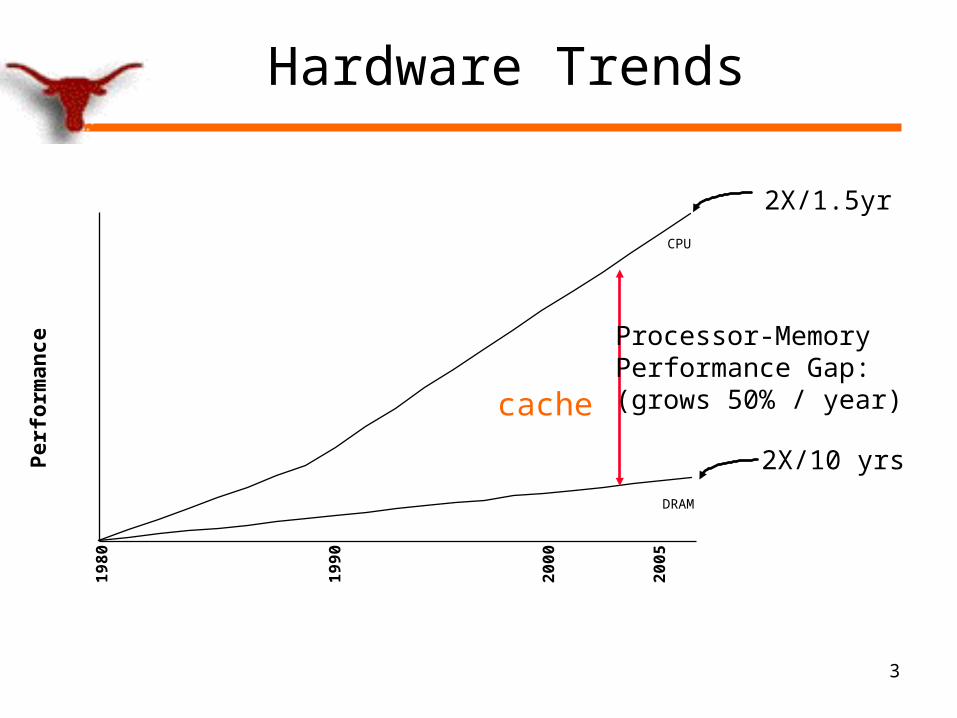
Hardware Trends
2X/1.5yr
2X/10 yrs
1980
1990
2000
DRAM
CPU
Processor-MemoryPerformance Gap:(grows 50% / year)
Per
form
ance
cache
2005

4
Fully Associative IL1
-2.0%
0.0%
2.0%
4.0%
6.0%
8.0%
10.0%
12.0%
14.0%
16.0%
18.0%
antlr
bloa
tfo
pjyt
hon
pmd
xalan
_201
_com
press
_202
_jess
_209
_db
_213
_java
c
_222
_mpe
gaud
io
_228
_jack
pseu
dojb
b
geo
mea
n
Imp
rove
men
t o
ver
bas
e ca
se
Fully Associative IL1
Improvement Potential
Base case: JikesRVM default with separate code space
. Cache configuration: 32K IL1 direct map, 512K L2(small programs on a big cache)

5
New and Better Opportunities
• Virtual machine monitors application behavior at runtime
• Dynamic recompilation– With dynamic feedback– Allocates instructions at runtime

6
Previous Work on Instruction Locality
• Static schemes– Static profile calling correlation and reorder
code at compile and link time [Pettis and Hansen 90]
– Cache coloring [Hashemi et al 97]
– Profile procedure interleaving [Gloy et al. 99]
– Static schemes are not flexible
• Dynamic scheme– JIT code reordering [Chen et al. 97]
– Used as our base case

7
Optimizations in Virtual Machine
• Static instruction allocation used at runtime, – e.g. Just-in-time
compilations – Invocation order
CompilerMemory Manager
Runtime
StaticOptimizations

8
Optimizations in Virtual Machine
• Dynamic instruction allocation/reordering adapt to the program behavior with low overhead
CompilerMemory Manager
Runtime
StaticOptimization

9
Opportunity for Instruction Locality
• Dynamic detection of hot methods, hot basic blocks
• Dynamic recompilation relocates methods at runtime

10
PCR Optimizations
• Reduce instruction capacity misses– Code space – Method separation– Code splitting
• Reduce instruction conflict misses– Code padding

11
PCR System
JikesRVM componentInput/Output
Optimized method
Baseline method
Data
BaselineCompiler
SourceCode
ExecutingCode
AdaptiveSampler Optimizing
Compiler
HotMethods
12
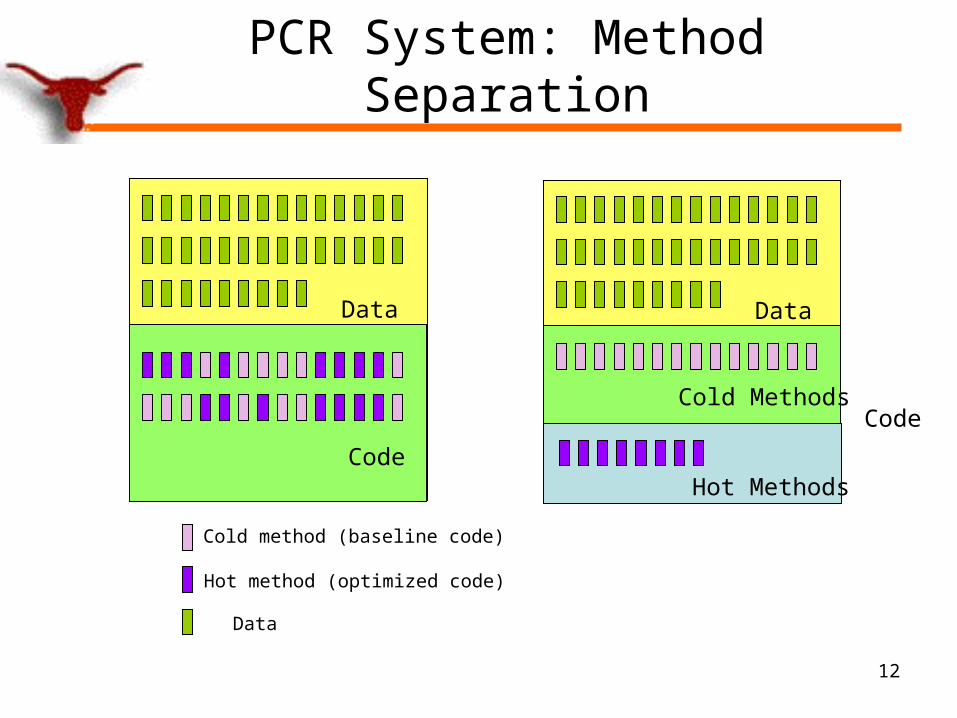
PCR System: Method Separation
Hot method (optimized code)
Cold method (baseline code)
Data
Data
Code
Data
Hot Methods
Cold MethodsCode

13
PCR System: Code Splitting
• Online edge profile identifies hot basic blocks in a method
• Code reordering moves hot basic blocks to the beginning of a method
• Code splitting to separate hot/cold basic blocks inside the heap
Cold basic blocks
Hot basic blocks
Method A:

14
PCR System: Code Splitting
Data
Hot Blocks
Cold Methods
Cold Blocks
Hot methods (optimized code)
Cold methods (baseline code)
Data Cold basic blocks
Hot basic blocks
Data
Hot Methods
Cold Methods

15
PCR Optimizations
• Reduce instruction capacity misses– Code Space – Method separation– Code splitting
• Reduce instruction conflict misses– Code padding

16
PCR System: Code Padding
BaselineCompiler
SourceCode
BinaryCode
AdaptiveSampler Optimizing
Compiler
Hot MethodsDynamic
Call Graph
JikesRVM componentInput/Output

17
PCR System: Code Padding
Method A() {
…
classC.B();
…
}
A
B
Conflict
A B
Dynamic Call Graph

18
Methodology
• Java virtual machine: Jikes RVM• Various Architectures
– x86 (Pentium 4)– PowerPC– Simulator: Dynamic SimpleScalar
• Use direct-mapped I-cache– Shorter latency– More conflict misses
19
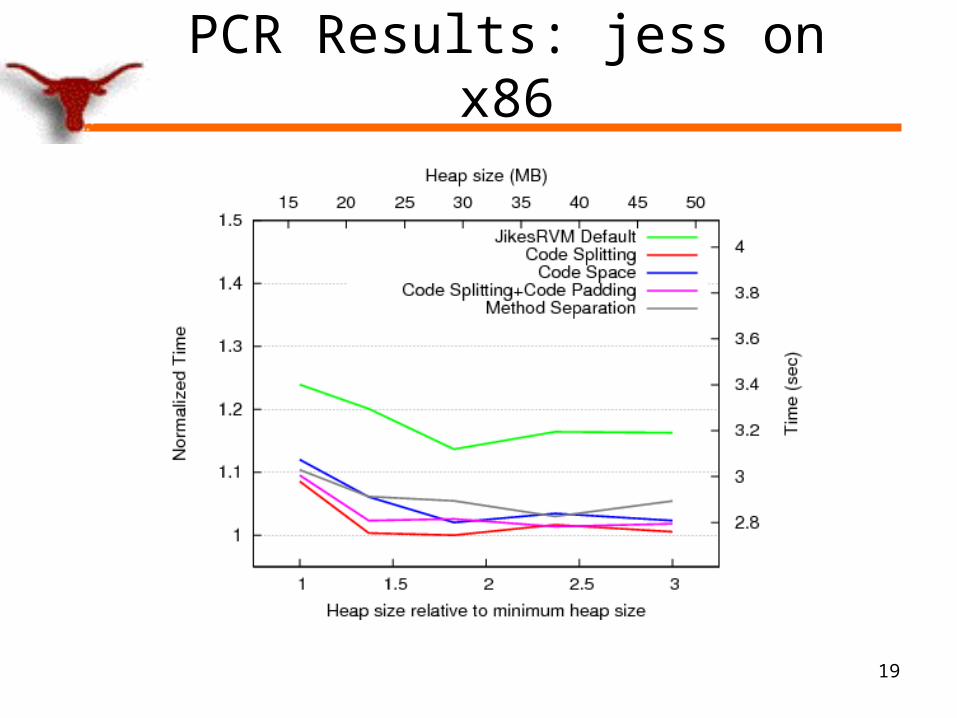
PCR Results: jess on x86

20
PCR Results: fop on x86

21
-10.0%
-5.0%
0.0%
5.0%
10.0%
15.0%
20.0%
Imp
rovem
en
t o
ver
co
de s
pace
Code Splitting
Code Padding + Splitting
Fully Associative IL1
Impact of Code Padding
Base case: JikesRVM default + a separate code space. Cache configuration: 32K IL1 direct map, 512K L2

22
Conclusion
• Code space improve program performance by 6% (up to 30%) (Pentium 4)
• PCR has negligible overhead• PCR no obvious performance improvement
– On Pentium 4, no improvement on average– In simulation,
• PCR has 14% for one program• Not consistent, no improvement on average.
• Potential opportunities for dynamic optimizations

23
Thank you!
• Questions?
CompilerGarbage collector
Runtime
StaticOptimization

24
Cache: Small vs. Large
IL1 DL1 L2Size Assoc Latency Size Assoc Latency Size Asso
cLatenc
y
8K 1 2 8K 2 2 128K
2 5
16K 1 2 16K
2 3 256K
2 8
64K 1 4 64K
2 4 512K
2 10
Cacti, 90nm technology, 3GHz frequency

25
Cache-Size Comparison
_213_javac
0
5
10
15
20
25
30
35
40
45
50
Tota
l Cyc
les
(in b
illio
ns)
_202_jess
0
5
10
15
20
25
30
35
40
45
50
Tota
l Cyc
les
(in b
illio
ns)
26
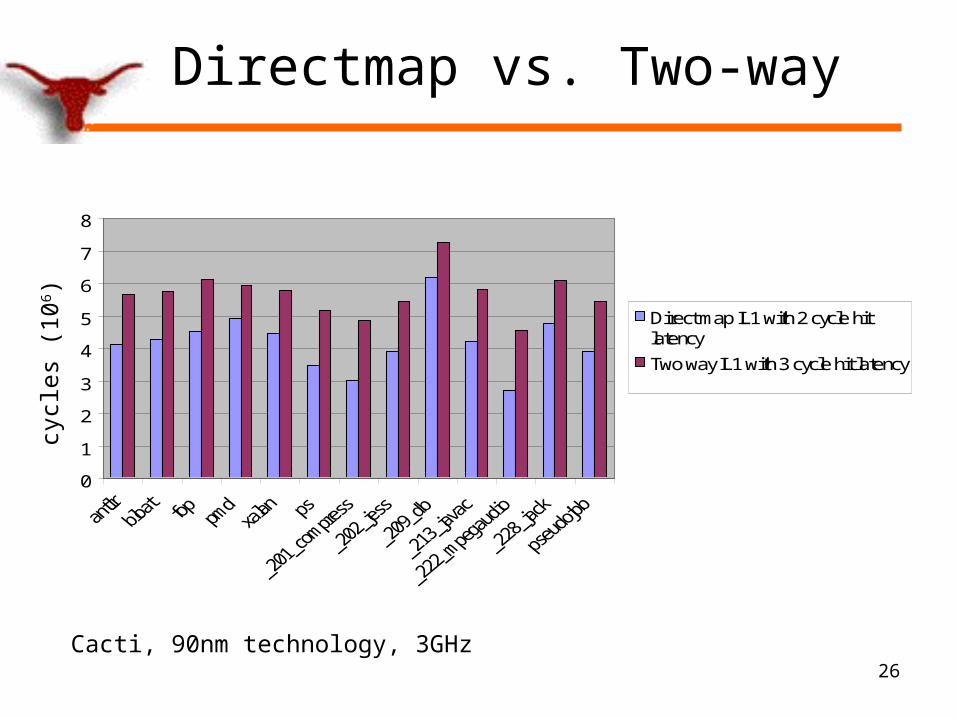
Directmap vs. Two-way
0
1
2
3
4
5
6
7
8
Direct map IL1 with 2 cycle hitlatency
Two way IL1 with 3 cycle hit latency
cycl
es (
106 )
Cacti, 90nm technology, 3GHz

27
Improving Performance
• Classic optimizations not sufficient!• Different programming styles
– Automatic memory management– Pointer data structures– Many small methods
• Optimization costs incurred at runtime• Virtual Machine (VM) adds complexity
– Class loading, memory management, Just-in-time compiler…

28
Instruction Locality
• Instructions have better locality?– More instruction accesses – About same # of data cache misses
• Penalty in pipelined processor– Create bubbles in the pipeline
• Instruction locality can be more critical

29
Locality Impact On Performance
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
2005 2010?
Waiting for L2misses
Waiting for L1misses
Other executiontime
Geometric mean of five Java programs
Locality is key to performance
23.2%
40.1%
25.1%
48.3%
Exe
cutio
n T
ime
Dis
trib
utio
n


















