
1 Data structures for Pattern Matching Suffix trees and suffix arrays are a basic data structure in...
32
1 Data structures for Pattern Matching Suffix trees and suffix arrays are a basic data structure in pattern matching Reported by: Olga Sergeeva, Saint Petersburg. On the materials: E.Ukkonen. On-Line Construction of Suffix Trees, 1993 Udi Manber and Gene Myers. Suffix Arrays: a New Method For On-Line String Searches, 1992 Juha Karkkainen and Peter Sanders. Simple Linear Work Suffix Array Construction, 2003.
-
Upload
dina-wilcox -
Category
Documents
-
view
234 -
download
1
Transcript of 1 Data structures for Pattern Matching Suffix trees and suffix arrays are a basic data structure in...

1
Data structures for Pattern MatchingSuffix trees and suffix arrays are a basic data structure in pattern matching
Reported by: Olga Sergeeva, Saint Petersburg.
On the materials:
E.Ukkonen. On-Line Construction of Suffix Trees, 1993Udi Manber and Gene Myers. Suffix Arrays: a New Method For On-Line String Searches, 1992Juha Karkkainen and Peter Sanders. Simple Linear Work Suffix Array Construction, 2003.

2
Suffix is a ‘concluding’ substring of the string.
If the suffixes are are organized ‘well’, the resulting construction can be very informative and can provide a good base for developing fast algorithms of working with strings.

3
Suffix tree:
Also, the marks on the edges, having a common root, begin with different symbols of our alphabet.
Suffix tree of a string is a tree with a root and marked edges, in which any concatenation of the marks along each path from the root to a leaf forms a suffix and every suffix appears once.

4
Searching in a suffix tree:
Having a suffix tree for a string S, we can easily find out if a string M is its substring. This will take us O(log |M|) operations.

5
Algorithms:
• 1973, Weiner. “Linear Pattern Matching Algorithms”.
• 1976, McCreight. “A Space-Economial Suffix Tree Construction Algorithm”.
• 1993, Ukkonen. “On-Line Construction of Suffix Trees”.

6
Ukkonen’s algorithm: implicit trees.
In general, for the suffix tree to exist, we need to add a ‘terminal’ symbol to the string (let us denote it ‘$’). Otherwise, we’ll have no means to identify the ends of the suffixes, which is desirable many algorithms.
But in the course of work we will build trees for strings without terminal symbol. Such trees are called implicit trees.

7
Ukkonen’s algorithm: idea, general description.
Let’s divide the process of constructing the tree into phases.
Starting with a tree for the first symbol, we’ll build the tree inductively, in the end of each phase having an implicit tree for a prefix of the string.

8
Ukkonen’s algorithm: possible cases of extension.When extending one suffix, we can encounter three situations: when we are just to extend a mark on an edge; when we are to add an edge (and maybe to split an existing edge into two); when nothing is needed to be done.

9
Ukkonen’s algorithm: towards improvement.
Essential: how we search the ends of the suffixes in .
We can find the end of suffix a in , walking from the root each time.
In this case, we will build from in , so the final tree will appear after operations, compared to in the naïve algorithm!
We’ll reduce this to , using some observations and techniques.

10
Ukkonen’s algorithm. Heuristics: suffix links. Suffix link – a pointer from an inner vertex with the path mark xto a vertex with mark, if it exists in a tree.
Every inner vertex has a suffix link. Moreover,
If a vertex v with path mark x is added to the tree in the extension j of the phase i+1, then s(v) either already exists in the tree or will be created in the next extension, in this phase.
So, any just created vertex has a suffix link to the ending point of the next extension. Consequently, in the end of each phase the tree has all its suffix links.

11
Ukkonen’s algorithm. Heuristics: suffix links.
Using suffix links can substantially reduce amount of search. If we maintain a pointer to the end of the longest suffix S[1..i], we will have the ending point of the previously extended suffix in the beginning of each extension . We will not move from the root every time we search for the end of the next suffix. Instead, we will get from the available ending point up to the first inner vertex v (if it’s not an inner vertex itself), walk along its suffix link s(v) and search only in the subtree of s(v).
Notice that he moment we are moving along the suffix link, the depth of v in tree, exceeds the depth of s(v) by less then 2.

12
Ukkonen’s algorithm. Heuristics: suffix links.
Using suffix links can substantially reduce amount of search. If we maintain a pointer to the end of the longest suffix S[1..i], we will have the ending point of the previously extended suffix in the beginning of each extension . We will not move from the root every time we search for the end of the next suffix. Instead, we will get from the available ending point up to the first inner vertex v (if it’s not an inner vertex itself), walk along its suffix link s(v) and search only in the subtree of s(v).
Notice that he moment we are moving along the suffix link, the depth of v in tree, exceeds the depth of s(v) by less then 2.

13
Ukkonen’s algorithm. Heuristics: suffix links.
Using suffix links can substantially reduce amount of search. If we maintain a pointer to the end of the longest suffix S[1..i], we will have the ending point of the previously extended suffix in the beginning of each extension . We will not move from the root every time we search for the end of the next suffix. Instead, we will get from the available ending point up to the first inner vertex v (if it’s not an inner vertex itself), walk along its suffix link s(v) and search only in the subtree of s(v).
Notice that he moment we are moving along the suffix link, the depth of v in tree, exceeds the depth of s(v) by less then 2.

14
Ukkonen’s algorithm: jumping over edges.
Still, there are unnecessary steps. We walk along edges in the sub tree of s(v), in series comparing symbols to the searched mark, as if we were checking if a way, corresponding to this mark, exists in the tree.
But it exists, and all we need to do is to find its ending point. That’s why we can restrict ourselves to choosing the right edge in a vertex (comparing the first symbols), end jump to the next vertex along this edge, or find the sought point on the edge, if its mark is long enough.

15
Ukkonen’s algorithm: jumping over edges.
Still, there are unnecessary steps. We walk along edges in the sub tree of s(v), in series comparing symbols to the searched mark, as if we were checking if a way, corresponding to this mark, exists in the tree.
But it exists, and all we need to do is to find its ending point. That’s why we can restrict ourselves to choosing the right edge in a vertex (comparing the first symbols), end jump to the next vertex along this edge, or find the sought point on the edge, if its mark is long enough.

16
Ukkonen’s algorithm: jumping over edges.
Still, there are unnecessary steps. We walk along edges in the sub tree of s(v), in series comparing symbols to the searched mark, as if we were checking if a way, corresponding to this mark, exists in the tree.
But it exists, and all we need to do is to find its ending point. That’s why we can restrict ourselves to choosing the right edge in a vertex (comparing the first symbols), end jump to the next vertex along this edge, or find the sought point on the edge, if its mark is long enough.

17
Ukkonen’s algorithm: current results.
Theorem. In the improved algorithm, every phase takes time.
Cons. The current version of Ukkonen’s algorithm terminates in .

18
Ukkonen’s algorithm: the last observations.
•To keep the labels on the marks is insufficient, because their overall length doesn’t have to be linear. We can replace the labels with indices, indicating the beginning and the end of the substring in S.

19
Ukkonen’s algorithm: the last observations.
•To keep the labels on the marks is insufficient, because their overall length doesn’t have to be linear. We can replace the labels with indices, indicating the beginning and the end of the substring in S.
•The first time in the phase we find out, that in the current extension nothing is to be done, we can complete with the phase. So a phase is a consequency of extensions, which use the first (prolonging a mark) and the second (branching off) rules.

20
Ukkonen’s algorithm: the last observations.
•To keep the labels on the marks is insufficient, because their overall length doesn’t have to be linear. We can replace the labels with indices, indicating the beginning and the end of the substring in S.
•The first time in the phase we find out, that in the current extension nothing is to be done, we can complete with the phase. So a phase is a consequency of extensions, which use the first (prolonging a mark) and the second (branching off) rules.
•A leaf cannot become an inner vertex.
•During the phase, we add the same symbol to edge marks.

21
Ukkonen’s algorithm: the last observations.
•To keep the labels on the marks is insufficient, because their overall length doesn’t have to be linear. We can replace the labels with indices, indicating the beginning and the end of the substring in S.
•The first time in the phase we find out, that in the current extension nothing is to be done, we can complete with the phase. So a phase is a consequency of extensions, which use the first (prolonging a mark) and the second (branching off) rules.
•A leaf cannot become an inner vertex.
•During the phase, we add the same symbol to edge marks.
•We will ‘split’ or ‘do nothing’ only with the suffixes, not processed in the previous phase (those, to which we applied ‘do nothing’) – in the other cases we prolong a leaf.

22
Ukkonen’s algorithm: time estimation.
Theorem. Ukkonen’s algorithm terminates in O(n) time.

23
Ukkonen’s algorithm: difficulties of implementation.
Problems of working with suffix trees:
• Dependency on the length of the alphabet
• No ‘locality’ – bad for paging
• Number of ‘children’ ranges for different vertices – no general ways of representation:
• Arrays for vertices near to the root.
• Linked lists for the leaves.
• Balanced trees and hashing for the middle vertices.
As a result, the structure becomes even more complicated.

24
Suffix array:
An array, containing the suffixes in lexicographic order.
The idea belongs to Udi Manber and Gene Myers (1993, “Suffix Arrays: a New Method For On-Line String Searches”).
They proposed an algorithm of direct constructing the array in O(n*log n) time. This algorithm not only built the array, but on the way gathered some additional information. Manber and Myers also presented an algorithm of search, using this information, for a pattern P in O(|P| + log m) time.

25
Suffix array construction: idea.
As with the trees, we build the array inductively, greatly using it’s structure. Initially, we have an array with unordered suffixes. Beginning with sorting the suffixes by the first symbol (which is linear in the string’s length), every phase we twice the number the suffixes are sorted on.
After the phase H, the suffixes are organized into buckets, holding suffixes with the same H first symbols.
If A(i) is the suffix in the first bucket, A(i-H) should be first in its 2H-bucket. We can move it to the beginning of its 2H-bucket, and mark this fact. For every bucket, we need to know the number of suffixes in this bucket that have already beer moved and placed in 2H-order. The algorithm basically scans the suffixes as they appear in the H-order and for each A(i) it moves A(i-H) (if it exists) to the next available place in its bucket.

26
‘Skew’ algorithm: structure
• Construct the suffix array of the suffixes, starting at positions
i = 1, 2 (mod 3). This is done by reduction to the suffix array construction of a string of two thirds the length, which is solved recursively.
• Construct the suffix array of the remaining suffixes using the result of the first step.
• Merge the suffix arrays into one.

27
The skew algorithm: example

28
The skew algorithm: example

29
The skew algorithm: example

30
The skew algorithm: example
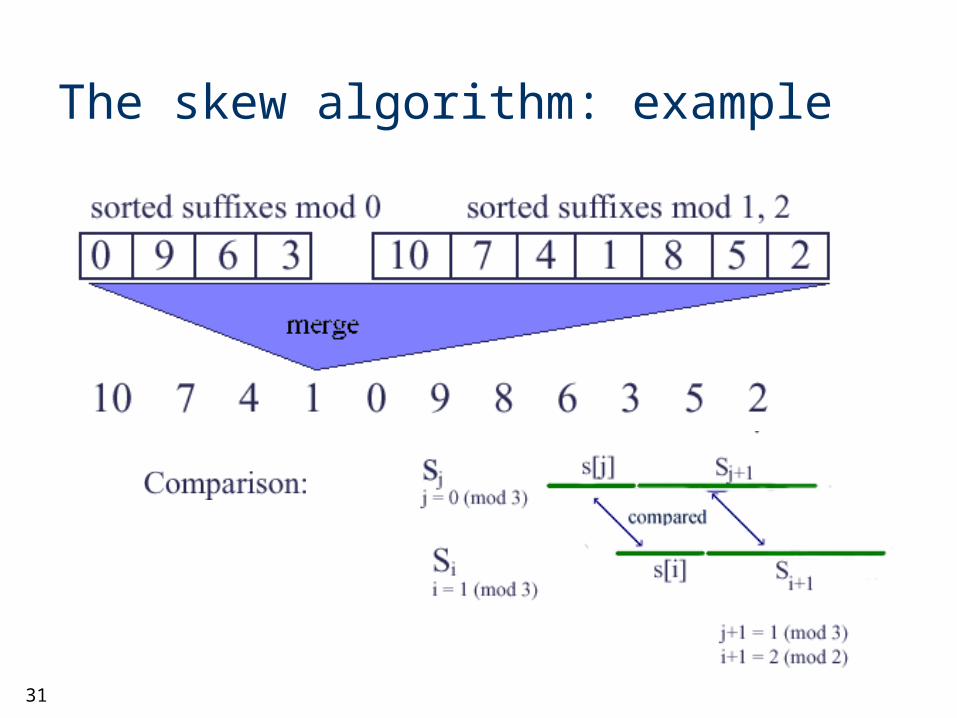
31
The skew algorithm: example

32
Literature
E.Ukkonen. On-Line Construction of Suffix Trees, 1993Udi Manber and Gene Myers. Suffix Arrays: a New Method
For On-Line String Searches, 1992Juha Karkkainen and Peter Sanders. Simple Linear Work
Suffix Array Construction, 2003.
Martin Farach. Optimal Suffix Tree Construction with Large Alphabets, 1997
Dan Gusfield. Algorithms on Strings, Trees, and Sequences. Computer science and computational biology


















