
1 CS308 Compiler Theory. 2 Syntax-Directed Translation Grammar symbols are associated with...
95
1 CS308 Compiler Theory CS308 Compiler Theory
-
Upload
jasper-atkins -
Category
Documents
-
view
253 -
download
1
Transcript of 1 CS308 Compiler Theory. 2 Syntax-Directed Translation Grammar symbols are associated with...

1
CS308 Compiler Theory
CS308 Compiler Theory

CS308 Compiler Theory 2
Syntax-Directed Translation
• Grammar symbols are associated with attributes to associate information with the programming language constructs that they represent.
• Values of these attributes are evaluated by the semantic rules associated with the production rules.
• Evaluation of these semantic rules:– may generate intermediate codes– may put information into the symbol table– may perform type checking– may issue error messages– may perform some other activities– in fact, they may perform almost any activities.
• An attribute may hold almost any thing.– a string, a number, a memory location, a complex record.

CS308 Compiler Theory 3
Syntax-Directed Definitions and Translation Schemes
• When we associate semantic rules with productions, we use two notations:
– Syntax-Directed Definitions
– Translation Schemes
• Syntax-Directed Definitions:– give high-level specifications for translations
– hide many implementation details such as order of evaluation of semantic actions.
– We associate a production rule with a set of semantic actions, and we do not say when they will be evaluated.
• Translation Schemes:– indicate the order of evaluation of semantic actions associated with a production rule.
– In other words, translation schemes give a little bit information about implementation details.

CS308 Compiler Theory 4
Syntax-Directed Definitions
• A syntax-directed definition is a generalization of a context-free grammar in which:– Each grammar symbol is associated with a set of attributes.
– This set of attributes for a grammar symbol is partitioned into two subsets called synthesized and inherited attributes of that grammar symbol.
– Each production rule is associated with a set of semantic rules.
• Semantic rules set up dependencies between attributes which can be represented by a dependency graph.
• This dependency graph determines the evaluation order of these semantic rules.
• Evaluation of a semantic rule defines the value of an attribute. But a semantic rule may also have some side effects such as printing a value.

CS308 Compiler Theory 5
Syntax-Directed Definition -- Example
Production Semantic RulesL → E return print(E.val)
E → E1 + T E.val = E1.val + T.valE → T E.val = T.val
T → T1 * F T.val = T1.val * F.valT → F T.val = F.valF → ( E ) F.val = E.valF → digit F.val = digit.lexval
• Symbols E, T, and F are associated with a synthesized attribute val.• The token digit has a synthesized attribute lexval (it is assumed that it is
evaluated by the lexical analyzer).

CS308 Compiler Theory 6
Translation Schemes
• In a syntax-directed definition, we do not say anything about the evaluation times of the semantic rules (when the semantic rules associated with a production should be evaluated?).
• A translation scheme is a context-free grammar in which:
– attributes are associated with the grammar symbols and
– semantic actions enclosed between braces {} are inserted within the right sides of productions.
• Ex: A → { ... } X { ... } Y { ... }
Semantic Actions

CS308 Compiler Theory 7
A Translation Scheme Example
• A simple translation scheme that converts infix expressions to the corresponding postfix expressions.
E → T R
R → + T { print(“+”) } R1
R → T → id { print(id.name) }
a+b+c ab+c+
infix expression postfix expression

CS308 Compiler Theory 8
Type Checking
• A compiler has to do semantic checks in addition to syntactic checks.• Semantic Checks
– Static – done during compilation– Dynamic – done during run-time
• Type checking is one of these static checking operations.– we may not do all type checking at compile-time. – Some systems also use dynamic type checking too.
• A type system is a collection of rules for assigning type expressions to the parts of a program.
• A type checker implements a type system.• A sound type system eliminates run-time type checking for type errors.• A programming language is strongly-typed, if every program its compiler accepts will
execute without type errors.– In practice, some of type checking operations are done at run-time (so, most of the programming
languages are not strongly-typed).– Ex: int x[100]; … x[i] most of the compilers cannot guarantee that i will be between 0 and 99

CS308 Compiler Theory 9
Intermediate Code Generation
• Intermediate codes are machine independent codes, but they are close to machine instructions.
• The given program in a source language is converted to an equivalent program in an intermediate language by the intermediate code generator.
• Intermediate language can be many different languages, and the designer of the compiler decides this intermediate language.– syntax trees can be used as an intermediate language.– postfix notation can be used as an intermediate language.– three-address code (Quadraples) can be used as an intermediate language
• we will use quadraples to discuss intermediate code generation• quadraples are close to machine instructions, but they are not actual machine instructions.
– some programming languages have well defined intermediate languages.• java – java virtual machine• prolog – warren abstract machine• In fact, there are byte-code emulators to execute instructions in these intermediate languages.

CS308 Compiler Theory 10
Three-Address Code (Quadraples)
• A quadraple is:
x := y op z
where x, y and z are names, constants or compiler-generated temporaries; op is any operator.
• But we may also the following notation for quadraples (much better notation because it looks like a machine code instruction)
op y,z,x
apply operator op to y and z, and store the result in x.
• We use the term “three-address code” because each statement usually contains three addresses (two for operands, one for the result).

CS308 Compiler Theory 11
Arrays
• Elements of arrays can be accessed quickly if the elements are stored in a block of consecutive locations.
A one-dimensional array A:
baseA low i width
baseA is the address of the first location of the array A,
width is the width of each array element.
low is the index of the first array element
location of A[i] baseA+(i-low)*width
… …

CS308 Compiler Theory 12
Arrays (cont.)
baseA+(i-low)*width
can be re-written as i*width + (baseA-low*width)
should be computed at run-time can be computed at compile-time
• So, the location of A[i] can be computed at the run-time by evaluating the formula i*width+c where c is (baseA-low*width) which is evaluated at compile-time.
• Intermediate code generator should produce the code to evaluate this formula i*width+c (one multiplication and one addition operation).

CS308 Compiler Theory 13
Two-Dimensional Arrays (cont.)
• The location of A[i1,i2] is
baseA+ ((i1-low1)*n2+i2-low2)*width
baseA is the location of the array A.
low1 is the index of the first row
low2 is the index of the first column
n2 is the number of elements in each rowwidth is the width of each array element
• Again, this formula can be re-written as
((i1*n2)+i2)*width + (baseA-((low1*n1)+low2)*width)
should be computed at run-time can be computed at compile-time

CS308 Compiler Theory 14
Multi-Dimensional Arrays
• In general, the location of A[i1,i2,...,ik] is
(( ... ((i1*n2)+i2) ...)*nk+ik)*width + (baseA-((...((low1*n1)+low2)...)*nk+lowk)*width)
• So, the intermediate code generator should produce the codes to evaluate the following formula (to find the location of A[i1,i2,...,ik]) :
(( ... ((i1*n2)+i2) ...)*nk+ik)*width + c
• To evaluate the (( ... ((i1*n2)+i2) ...)*nk+ik portion of this formula, we can use the recurrence equation:
e1 = i1
em = em-1 * nm + im

CS308 Compiler Theory 15
Translation Scheme for Arrays
S L := E { if (L.offset is null) emit(‘mov’ E.place ‘,,’ L.place)
else emit(‘mov’ E.place ‘,,’ L.place ‘[‘ L.offset ‘]’) }
E E1 + E2 { E.place = newtemp();
emit(‘add’ E1.place ‘,’ E2.place ‘,’ E.place) }
E ( E1 ) { E.place = E1.place; }
E L { if (L.offset is null) E.place = L.place)
else { E.place = newtemp();
emit(‘mov’ L.place ‘[‘ L.offset ‘]’ ‘,,’ E.place) } }

translation of flow-of-control statements
S if (E) S1
| if (E) S1 else S2
| while (E) S1
| S1 S2
S.next : the label that is attached to the first three-address code to be executed after the code for S

code for flow-of-control statements
E.code
S1.codeE.true:
. . .
to E.trueto E.false
(a) if-then
E.code
S1.codeE.true:
. . .
to E.trueto E.false
E.false:goto S.next
S2.code
(b) if-then-else
E.code
S1.codeE.true:
. . .
to E.trueto E.false
goto S.begin
S.begin:
(c) while-do
E.false:
S.next:
E.false:

利用 fall through
E E1 relop E2
{test = E1 relop E2
s = if E.true != fall and E.false != fall then gen(‘if’ test ‘goto’, E.true) || gen(‘goto’, E.false) else if (E.true != fall) then gen(‘if’ test ‘goto’, E.true) else if (E.false != fall) then gen(‘if’ ! test ‘goto’, E.false) else ‘’
E.code := E1.code || E2 .code || s}

backpatching
allows generation of intermediate code in one pass (the problem with translation scheme before is that we have inherited attributes such as S.next, which is not suitable to implement in bottom-up parsers)
idea: the labels (in the three-address code) will be filled when we know the places
• attributes: E.truelist (true exits : 真 标 号 表 ), E.falselist (false exits)

• S if E then M S1
{backpatch(E.truelist, M.quad);
S.nextlist := merge(E.falselist, S1.nextlist}
• S if E then M1 S1 N else M2 S2
{backpatch(E.truelist, M1.quad);
backpatch(E.falselist, M2.quad);
S.nextlist := merge(S1.nextlist, N.nextlist, S2.nextlist)}

CS308 Compiler Theory 21
Run-Time Environments
• How do we allocate the space for the generated target code and the data object of our source programs?
• The places of the data objects that can be determined at compile time will be allocated statically.
• But the places for the some of data objects will be allocated at run-time.
• The allocation and de-allocation of the data objects is managed by the run-time support package.– run-time support package is loaded together with the generate target code.
– the structure of the run-time support package depends on the semantics of the programming language (especially the semantics of procedures in that language).
• Each execution of a procedure is called as activation of that procedure.

CS308 Compiler Theory 22
Procedure Activations
• An execution of a procedure starts at the beginning of the procedure body;
• When the procedure is completed, it returns the control to the point immediately after the place where that procedure is called.
• Each execution of a procedure is called as its activation.
• Lifetime of an activation of a procedure is the sequence of the steps between the first and the last steps in the execution of that procedure (including the other procedures called by that procedure).
• If a and b are procedure activations, then their lifetimes are either non-overlapping or are nested.
• If a procedure is recursive, a new activation can begin before an earlier activation of the same procedure has ended.

CS308 Compiler Theory 23
Activation Tree (cont.)
main
p s
q s

CS308 Compiler Theory 24
Run-Time Storage Organization
Code
Static Data
Stack
Heap
Memory locations for code are determined at compile time.
Locations of static data can also be determined at compile time.
Data objects allocated at run-time.(Activation Records)
Other dynamically allocated dataobjects at run-time. (For example,malloc area in C).

CS308 Compiler Theory 25
Activation Records
• Information needed by a single execution of a procedure is managed using a contiguous block of storage called activation record.
• An activation record is allocated when a procedure is entered, and it is de-allocated when that procedure exited.
• Size of each field can be determined at compile time (Although actual location of the activation record is determined at run-time).
– Except that if the procedure has a local variable and its size depends on a parameter, its size is determined at the run time.

CS308 Compiler Theory 26
Activation Records (cont.)
return value
actual parameters
optional control link
optional access link
saved machine status
local data
temporaries
The returned value of the called procedure is returned in this field to the calling procedure. In practice, we mayuse a machine register for the return value.
The field for actual parameters is used by the calling procedure to supply parameters to the called procedure.
The optional control link points to the activation record of the caller.
The optional access link is used to refer to nonlocal dataheld in other activation records.
The field for saved machine status holds information about the state of the machine before the procedure is called.
The field of local data holds data that local to an executionof a procedure..
Temporay variables is stored in the field of temporaries.

CS308 Compiler Theory 27
Access to Nonlocal Names
• Scope rules of a language determine the treatment of references to nonlocal names.
• Scope Rules:
– Lexical Scope (Static Scope)
• Determines the declaration that applies to a name by examining the program text alone at compile-time.
• Most-closely nested rule is used.
• Pascal, C, ..
– Dynamic Scope
• Determines the declaration that applies to a name at run-time.
• Lisp, APL, ...

CS308 Compiler Theory 28
Access Links
program main; var a:int; procedure p; var d:int; begin a:=1; end; procedure q(i:int); var b:int; procedure s; var c:int; begin p; end; begin if (i<>0) then q(i-1) else s; end; begin q(1); end;
main
access link
a:
q(1)
access link
i,b:
q(0)
access link
i,b:
s
access link
c:
p
access link
d:
AccessLinks

CS308 Compiler Theory 29
Displays
• An array of pointers to activation records can be used to access activation records.• This array is called as displays.• For each level, there will be an array entry.
1:
2:
3:
Current activation record at level 1
Current activation record at level 2
Current activation record at level 3

CS308 Compiler Theory 30
Accessing Nonlocal Variables using Display
program main; var a:int; procedure p; var b:int; begin q; end; procedure q(); var c:int; begin c:=a+b; end; begin p; end;
main
access link
a:
p
access link
b:
q
access link
c:
addrC := offsetC(D[3])addrB := offsetB(D[2])addrA := offsetA(D[1])ADD addrA,addrB,addrC
D[1]
D[2]
D[3]

31
Issue in the Design of a Code Generator
• General tasks in almost all code generators: instruction selection, register allocation and assignment.– The details are also dependent on the specifics of the intermediate representation, the target
language, and the run-time system.
• The most important criterion for a code generator is that it produce correct code.
• Given the premium on correctness, designing a code generator so it can be easily implemented, tested, and maintained is an important design goal.

32
Instruction Selection
• The nature of the instruction set of the target machine has a strong effect on the difficulty of instruction selection. For example,– The uniformity and completeness of the instruction set are important factors.
– Instruction speeds and machine idioms are another important factor.• If we do not care about the efficiency of the target program, instruction selection is
straightforward.
x = y + z LD R0, y ADD R0, R0, z ST x, R0
a = b + c LD R0, bd = a + e ADD R0, R0, c ST a, R0 LD R0, a ADD R0, R0,e ST d, R0
Redundant

33
Register Allocation
• A key problem in code generation is deciding what values to hold in what registers.
• Efficient utilization is particularly important.
• The use of registers is often subdivided into two subproblems:1. Register Allocation, during which we select the set of variables that will reside in registers
at each point in the program.
2. Register assignment, during which we pick the specific register that a variable will reside in.
• Finding an optimal assignment of registers to variables is difficult, even with single-register machine.
• Mathematically, the problem is NP-complete.

34
A Simple Target Machine Model
• Our target computer models a three-address machine with load and store operations, computation operations, jump operations, and conditional jumps.
• The underlying computer is a byte-addressable machine with n general-purpose registers.
• Assume the following kinds of instructions are available:– Load operations
– Store operations
– Computation operations
– Unconditional jumps
– Conditional jumps

Basic Blocks and Flow Graphs
• Introduce a graph representation of intermediate code that is helpful for discussing code generation– Partition the intermediate code into basic blocks
– The basic blocks become the nodes of a flow graph, whose edges indicate which blocks can follow which other blocks.
CS308 Compiler Theory 35

Optimization of Basic Blocks
• Local optimization within each basic block
• Global optimization– which looks at how information flows among the basic blocks of a
• This chapter focuses on the local optimization
CS308 Compiler Theory 36

DAG Representation of Basic Blocks
• Construct a DAG for a basic block1. There is a node in the DAG for each of the initial values of the variables appearing in the
basic block.
2. There is a node N associated with each statement s within the block. The children of N are those nodes corresponding to statements that are the last definitions, prior to s, of the operands used by s.
3. Node N is labeled by the operator applied at s, and also attached to N is the list of variables for which it is the last definition within the block.
4. Certain nodes are designated output nodes. These are the nodes whose variables are live on exit from the block; that is, their values may be used later, in another block of the flow graph.
CS308 Compiler Theory 37

Finding Local Common Sub expressions
• How about if b and d are live on exit?
CS308 Compiler Theory 38

Dead Code Elimination
• Delete from a DAG any root (node with no ancestors) that has no live variables attached.
• Repeated application of this transformation will remove all nodes from the DAG that correspond to dead code.
• Example: assume a and b are live but c and e are not.
– e , and then c can be deleted.
CS308 Compiler Theory 39

The Use of Algebraic Identities
• Eliminate computations
• Reduction in strength
• Constant folding• 2*3.14 = 6.28 evaluated at compile time
• Other algebraic transformations– x*y=y*x
– x>y and x-y>0
– a= b+c; e=c+d+b; e=a+d;
CS308 Compiler Theory 40

Representation of Array References
• x = a[i]
• a[j]=y
• killed node
CS308 Compiler Theory 41

Reassembling Basic Blocks From DAG 's
CS308 Compiler Theory 42
b is not live on exit
b is live on exit

Register and Address Descriptors
• Descriptors are necessary for variable load and store decision.
• Register descriptor– For each available register
– Keeping track of the variable names whose current value is in that register
– Initially, all register descriptors are empty
• Address descriptor– For each program variable
– Keeping track of the location (s) where the current value of that variable can be found
– Stored in the symbol-table entry for that variable name.
CS308 Compiler Theory 43

The Code-Generation Algorithm
• Function getReg(I)– Selecting registers for each memory location associated with the three-address instruction I.
• Machine Instructions for Operations– For a three-address instruction such as x = y + z, do the following:
1. Use getReg(x = y + z) to select registers for x, y, and z. Call these Rx, Ry, and Rz .
2 . If y is not in Ry (according to the register descriptor for Ry) , then issue an instruction
LD Ry , y' , where y' is one of the memory locations for y (according to the address descriptor for y) .
3. Similarly, if z is not in Rz , issue an instruction LD Rz, z’ , where z’ is a location for z.
4. Issue the instruction ADD Rx , Ry , Rz.
CS308 Compiler Theory 44

CS308 Compiler Theory 45

Peephole Optimization
• The peephole is a small, sliding window on a program.
• Peephole optimization, is done by examining a sliding window of target instructions and replacing instruction sequences within the peephole by a shorter or faster sequence, whenever possible.
• Peephole optimization can be applied directly after intermediate code generation to improve the intermediate representation.
CS308 Compiler Theory 46

Eliminating Unreachable Code
• An unlabeled instruction immediately following an unconditional jump may be removed.
• This operation can be repeated to eliminate a sequence of instructions.
CS308 Compiler Theory 47

Flow-of- Control Optimizations
• Unnecessary jumps can be eliminated in either the intermediate code or the target code by peephole optimizations.
CS308 Compiler Theory 48
Suppose there is only one jump to L1

Algebraic Simplification and Reduction in Strength
• Algebraic identities can be used to eliminate three-address statements– x = x+0; x=x*1
• Reduction-in-strength transformations can be applied to replace expensive operations– x2 ; power(x, 2); x*x
– Fixed-point multiplication or division; shift
– Floating-point division by a constant can be approximated as multiplication by a constant
CS308 Compiler Theory 49

Use of Machine Idioms
• The target machine may have hardware instructions to implement certain specific operations efficiently.
• Using these instructions can reduce execution time significantly.
• Example: – some machines have auto-increment and auto-decrement addressing modes.
– The use of the modes greatly improves the quality of code when pushing or popping a stack as in parameter passing.
– These modes can also be used in code for statements like x = x + 1 .
CS308 Compiler Theory 50

Register Allocation and Assignment
• Efficient utilization of registers is vitally important in generating good code.
• This section presents various strategies for deciding at each point in a program :– what values should reside in registers (register allocation) and
– in which register each value should reside (register assignment) .
CS308 Compiler Theory 51

Usage Counts
• Keeping a variable x in a register for the duration of a loop L– Save one unit for each use of x
– save two units if we can avoid a store of x at the end of a block.
• An approximate formula for the benefit to be realized from allocating a register x within loop L is
CS308 Compiler Theory 52
where use(x, B) is the number of times x is used in B prior to any definition of x, live(x, B) is 1 if x is live on exit from B and is assigned a value in B, and live(x, B) is 0 otherwise.

Code optimization
• Elimination of unnecessary instructions
• Replacement of one sequence of instructions by a faster sequence of instructions
• Local optimization
• Global optimizations– based on data flow analyses
CS308 Compiler Theory 53

Causes of Redundancy
• Redundant operations are– at the source level
– a side effect of having written the program in a high-level language
• Each of high-level data-structure accesses expands into a number of low-level arithmetic operations
• Programmers are not aware of these low-level operations and cannot eliminate the redundancies themselves.
• By having a compiler eliminate the redundancies– The programs are both efficient and easy to maintain.
CS308 Compiler Theory 54

Common Subexpressions
• Common subexpression– Previously computed
– The values of the variables not changed
• Local:
CS308 Compiler Theory 55

Common Subexpressions
• Global
CS308 Compiler Theory 56

Copy Propagation
• Copy statements or Copies– u = v
CS308 Compiler Theory 57

Dead-Code Elimination
• Live variable– A variable is live at a point in a program if its value can be used subsequently;
– otherwise, it is dead at that point.
• Constant folding– Deducing at compile time that the value of an expression is a constant and using the
constant instead
CS308 Compiler Theory 58

CS308 Compiler Theory 59

Code Motion
• An important modification that decreases the amount of code in a loop
• Loop-invariant computation– An expression that yields the same result independent of the number of times a loop is
executed
• Code Motion takes loop-invariant computation before its loop
CS308 Compiler Theory 60
while (i <= limit-2)
t = limit -2while (i <= t)

Induction Variables and Reduction in Strength
• Induction variable– For an induction variable x, there is a positive or negative constant c such that each time x is
assigned, its value increases by c
• Induction variables can be computed with a single increment (addition or subtraction) per loop iteration
• Strength reduction– The transformation of replacing an expensive operation, such as multiplication, by a heaper
one, such as addition
• Induction variables lead to – strength reduction
– eliminate computation
CS308 Compiler Theory 61
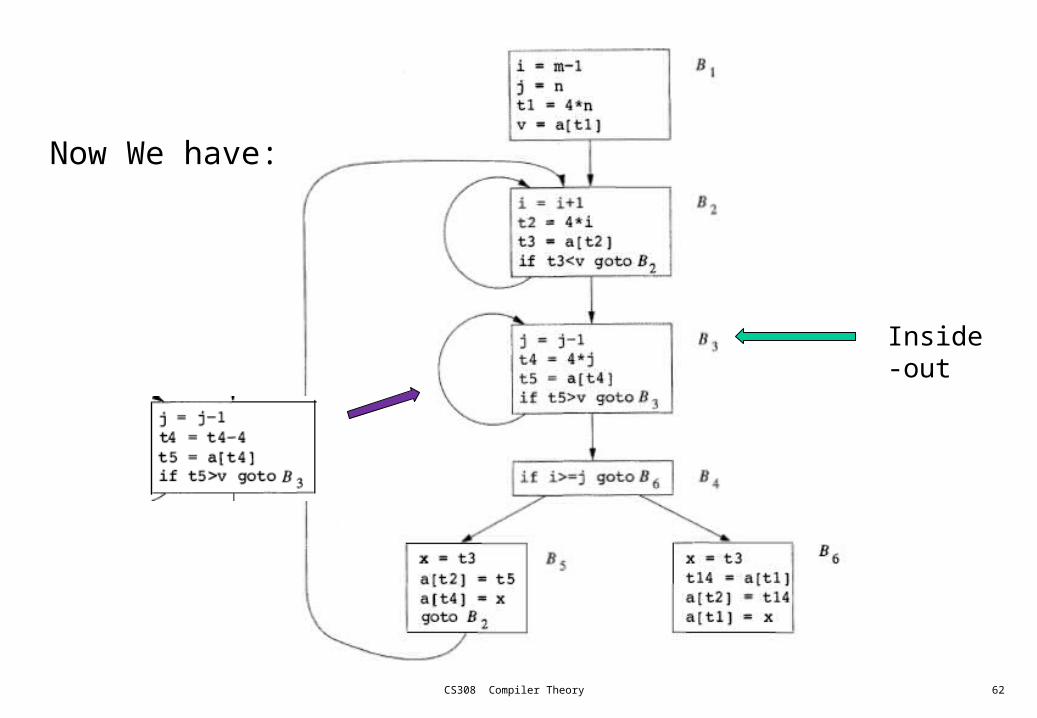
Now We have:
CS308 Compiler Theory 62
Inside-out

Data-Flow Analysis
• Techniques that derive information about the flow of data along program execution paths
• Examples– One way to implement global common sub expression elimination requires us to determine
whether two identical expressions evaluate to the same value along any possible execution path of the program.
– If the result of an assignment is not used along any subsequent execution path, then we can eliminate the assignment as dead code.
CS308 Compiler Theory 63

Reaching Definitions
• A definition d reaches a point p if there is a path from the point immediately following d to p, such that d is not "killed" along that path.
• A definition of a variable x is killed if there is any other definition of x anywhere along the path.
• Conservative– if we do not know whether a statement s is assigning a value to x, we must assume that it
may assign to it.
CS308 Compiler Theory 64

Live-Variable Analysis
• In live-variable analysis we wish to know for variable x and point p whether the value of x at p could be used along some path in the flow graph starting at p. If so, we say x is live at p; otherwise, x is dead at p.
• Definitions:
1. defB: the set of variables defined in B prior to any use of that variable in B
2. useB: the set of variables whose values may be used in B prior to any
definition of the variable.
CS308 Compiler Theory 65

Available Expressions
• An expression x + y is available at a point p :– if every path, from the entry node to p evaluates x + y, and after the last such evaluation
prior to reaching p, there are no subsequent assignments to x or y.
• A block kills expression x + y :– if it assigns (or may assign) x or y and does not subsequently recompute x + y.
• A block generates expression x + y :– if it definitely evaluates x + y and does not subsequently define x or y.
CS308 Compiler Theory 66

Available Expressions
• Let
IN[B] be the set of expressions that are available before B
OUT[B] be the same for the point following the end of B
e_genB be the expressions generated by B
e_killB be the set of expressions killed in B
• Then
• For all basic blocks B other than ENTRY
CS308 Compiler Theory 67

Partial-Redundancy Elimination
• Minimize the number of expression evaluations
• Consider all possible execution sequences in a flow graph, and look at the number of times an expression such as x + y is evaluated.
• By moving around the places where x + y is evaluated and keeping the result in a temporary variable when necessary, we often can reduce the number of evaluations of this expression along many of the execution paths.
CS308 Compiler Theory 68

The Sources of Redundancy
CS308 Compiler Theory 69

Anticipation of Expressions
• An expression b + c is anticipated at point p if all paths leading from the point p eventually compute the value of the expression b + c from the values of b and c that are available at that point.
• When we insert expressions, we should ensure that no extra operations are executed. That is, copies of an expression must be placed only at program points where the expression is anticipated.
CS308 Compiler Theory 70

Loops in Flow Graphs
• Loops are important because programs spend most of their time executing them
• Optimizations that improve the performance of loops can have a significant impact.
CS308 Compiler Theory 71

Dominators
• Say node d of a flow graph dominates node n, written d dom n, if every path from the entry node of the flow graph to n goes through d.
• Every node dominates itself.
Which nodes are
dominated by
each node?
CS308 Compiler Theory 72

Finding Dominators
CS308 Compiler Theory 73
}
}
}
;)(
;
{
)(
)(}{
{
}{
;
{
;
;)(}{
}{)(
)(
0
0
00
NewDnD
TRUEChange
ThenNewDnDIf
pDnNewD
nNnFor
FALSEChange
ChangeWHILE
TRUEChange
NnDnNnFor
nnD
nPp

Edges in a Depth-First Spanning Tree
• Advancing edges: going from a node m to a proper descendant of m in the tree
• Retreating edges: going from a node m to an ancestor of m in the tree (possibly to m itself) .
• Cross edges: edges m n such that neither m nor n is an ancestor of the other in the DFST
CS308 Compiler Theory 74

Back Edges and Reducibility
• A back edge is an edge a b whose head b dominates its tail a.
• For any flow graph, every back edge is retreating, but not every retreating edge is a back edge.
• A flow graph is said to be reducible if all its retreating edges in any depth-first spanning tree are also back edges.
CS308 Compiler Theory 75

Natural Loops
• A natural loop is defined by two essential properties.
1 . It must have a single-entry node, called the header.
This entry node dominates all nodes in the loop, or it would not be the sole entry to the loop.
2. There must be a back edge that enters the loop header.
Otherwise, it is not possible for the flow of control to return to the header directly from the "loop" ; i.e., there really is no loop.
CS308 Compiler Theory 76

代码优化 – 补充
• 局部优化• 循环优化

(1)i:=m-1 (2)j:=n(3)t1:=4*n (4)v:=a[t1]
(5)i:=i+1 (6)t2:=4*i(7)t3:=a[t2] (8)if t3<v goto(5)
(9)j:=j-1 (10)t4:=4*j(11)t5:=a[t4] (12)if t5>v goto(9)
(13)if i>=j goto(23)
(14)t6:=4*i (15)x:=a[t6](16)t7:=4*i (17)t8:=4*j(18)t9:=a[t8] (19)a[t7]:=t9(20)t10:=4*j (21)a[t10]:=x(22)goto (5)
(23)t11:=4*i (24)x:=a[t11](25)t12:=4*i (26)t13:=4*n(27)t14:=a[t13] (28)a[t12]:=t14(29)t15:=4*n (30)a[t15]:=x
B1
B2
B3
B4
B5 B6

局部优化
局部优化就是基本块内的优化。局部优化包括以下几种方法:1. 合并已知量2. 删除公共子表达式3. 删除无用赋值4. 删除死代码

1. 合并已知量
对于语句:A := OP B 或 A := B OP C
若 B 和 C 为常数,则编译时可将 A 的值计算出来,存放在临时单元T 中,相应语句换成:
A := T

2. 删除公共子表达式
对于语句:A := B + C*DU := V – C*D
如果两个语句之间 C 和 D 的值未改变,则第二个语句可使用第一个语句的计算结果 T :
A := B + C*DU := V – T

3. 删除无用赋值
如有语句:A := B + C……A := M + N
在两个语句之间没有使用过 A ,则第一个语句可以删除:……A := M + N

4. 删除死代码
语句:if B then S1 else S2
如果 B 的值固定为“真”或“假”,则其中一个分支永远不会执行,这些分支的代码时“死代码”,可以删除。

例题:
(1) F:=1 (2) C:=F+E (3) D:=F+3(4) B:=A*A (5) G:=B-D (6) H:=E(7) I:=H*G (8) J:=D/4 (9) K:=J+C(10) L:=H (11) L:=I-J第一步:合并已知量,由 (1) F:=1 ,可得:(1) F:=1 (2) C:=1+E (3) D:=4(4) B:=A*A (5) G:=B-4 (6) H:=E(7) I:=H*G (8) J:=1 (9) K:=2+E(10) L:=H (11) L:=I-1

第二步:删除公共子表达式,由 (6) 将 (7) 改为:(1) F:=1 (2) C:=1+E (3) D:=4(4) B:=A*A (5) G:=B-4 (6) H:=E(7) I:=E*G (8) J:=1 (9) K:=2+E(10) L:=H (11) L:=I-1第三步:删除无用赋值 (10) ;其它可能的无用赋值 (1) 、 (2) 、 (3) 、 (6) 、 (8) 。(4) B:=A*A (5) G:=B-4 (7) I:=E*G(9) K:=2+E (11) L:=I-1
循环 / 全局 优化循环优化是一种重要的全局优化方法。循环是程序中重复执行的代码序列,一个程序运行的大部分时间是用在循环上的,因此循环优化对提高程序的执行效率具有非常重要的意义。循环优化包括以下几种方法:1. 代码外提2. 强度削弱3. 删除归纳变量

对 x:=op y 或 x:=y op z ,如果 y 、 z 均为循环不变量(常数或定值点在 L 之外),则该运算为循环不变运算,优化时将该运算提到循环入口结点之前所增设的结点中去。
1. 代码外提

基本归纳变量: i := i c ( c 为常数)同族归纳变量: j := c1*i c2 ( c1 、 c2 为常数)基本归纳变量 i 每循环一次增加或减少 c ,与 i 同族的归纳变量 j 相应增加或减少 c1*c 。因此,计算 j 的乘法可由加法来代替: j := j + c1*c ( c1*c 为常数)
2. 强度削弱

用同族归纳变量作为判断条件,如基本归纳别无它用,则可将其删除。例如: j = 10 * i + 5 ,判断条件为 i > 10 ,则将 i > 10 改为 j > 105 ,同时删除 i 相关的语句。
3. 删除归纳变量

全局优化实例
(1)i:=1
(2)if i>10 goto (16)
(3)t1:=2*j (4)t2:=10*i(5)t3:=t2+t1 (6)t4:=a0-11(7)t5:=2*j (8)t6:=10*i(9)t7:=t6+t5 (10)t8:=a0-11 (11)t9:=t8[t7] (12)t10:=t9+1(13)t4[t3]:=t10 (14)i:=i+1(15)goto (2)
(16) …...
B1
B2
B3
B4

1. 代码外提
(3)
(6)
(7)
(10)
(1)i:=1
(2)if i>10 goto (16)
(3)t1:=2*j (4)t2:=10*i(5)t3:=t2+t1 (6)t4:=a0-11(7)t5:=2*j (8)t6:=10*i(9)t7:=t6+t5 (10)t8:=a0-11 (11)t9:=t8[t7] (12)t10:=t9+1(13)t4[t3]:=t10 (14)i:=i+1(15)goto (2)
(16) …...
B1
B2
B3
B4
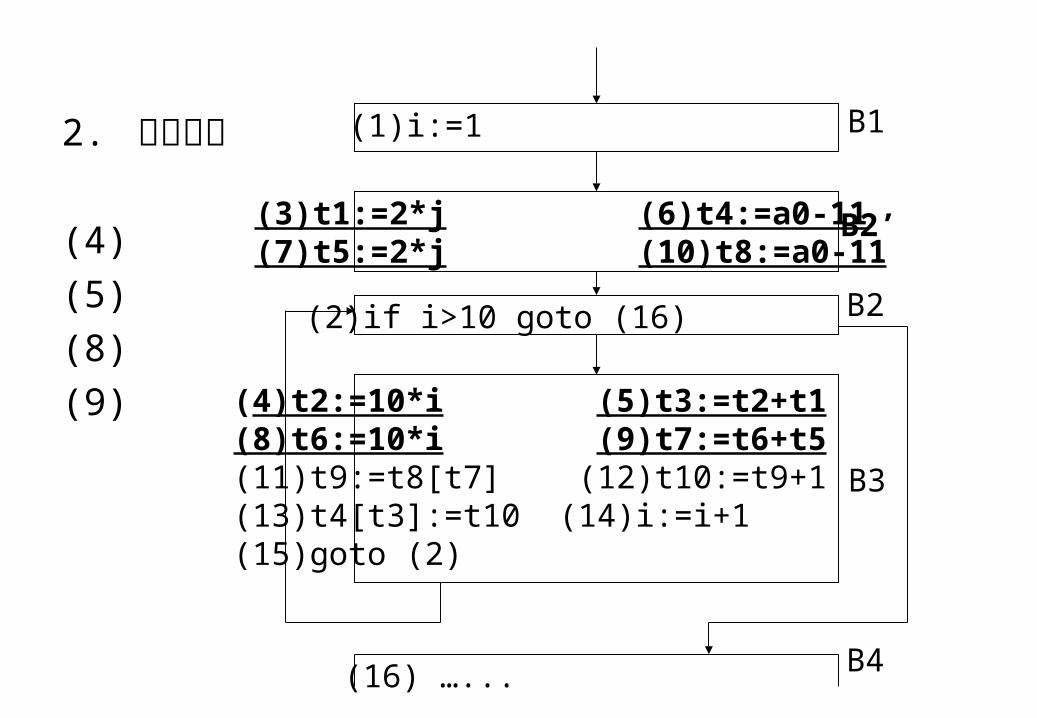
2. 强度削弱
(4)
(5)
(8)
(9)
(1)i:=1
(4)t2:=10*i (5)t3:=t2+t1 (8)t6:=10*i (9)t7:=t6+t5(11)t9:=t8[t7] (12)t10:=t9+1(13)t4[t3]:=t10 (14)i:=i+1(15)goto (2)
(16) …...
(2)if i>10 goto (16)
(3)t1:=2*j (6)t4:=a0-11(7)t5:=2*j (10)t8:=a0-11
B1
B2’
B2
B3
B4

3. 删除归纳变量
(2)
(14)
(1)i:=1
(4’)t2:=t2+10 (5’)t3:=t3+10(8’)t6:=t6+10 (9’)t7:=t7+10(11)t9:=t8[t7] (12)t10:=t9+1(13)t4[t3]:=t10 (14)i:=i+1(15)goto (2)
(16) …...
(2)if i>10 goto (16)
(3)t1:=2*j (6)t4:=a0-11(7)t5:=2*j (10)t8:=a0-11(4)t2:=10*i (5)t3:=t2+t1 (8)t6:=10*i (9)t7:=t6+t5
B1
B2’
B2
B3
B4

4. 其它优化 (1)i:=1
(4’)t2:=t2+10 (5’)t3:=t3+10 (8’)t6:=t6+10 (9’)t7:=t7+10(11)t9:=t8[t7] (12)t10:=t9+1(13)t4[t3]:=t10 (15)goto (2’’)
(16) …...
(2’’)if t3>s goto (16)
(3)t1:=2*j (6)t4:=a0-11(7)t5:=2*j (10)t8:=a0-11(4)t2:=10*i (8)t6:=10*i(5)t3:=t2+t1 (9)t7:=t6+t5(2’)s:=100+t1
B1
B2’
B2
B3
B4

5. 其它优化后 (1)i:=1
(5’)t3:=t3+10 (9’)t7:=t7+10(11)t9:=t8[t7] (12)t10:=t9+1(13)t4[t3]:=t10 (15)goto (2’’)
(16) …...
(2’’)if t3>s goto (16)
(3)t1:=2*j (6)t4:=a0-11(7)t5:=2*j (10)t8:=a0-11(4)t2:=10*i (8)t6:=10*i(5)t3:=t2+t1 (9)t7:=t6+t5(2’)s:=100+t1
B1
B2’
B2
B3
B4


















