
1 A Brief Introduction to CRISP-DM. The Hard Facts About Data Enormous amounts of data are being...
54
1 A Brief Introduction to CRISP-DM
-
Upload
randolf-norton -
Category
Documents
-
view
217 -
download
0
Transcript of 1 A Brief Introduction to CRISP-DM. The Hard Facts About Data Enormous amounts of data are being...

1
A Brief Introduction toCRISP-DM

The Hard Facts About Data
• Enormous amounts of data are being stored in databases
• Businesses are increasingly becoming data-rich, yet, paradoxically, they remain knowledge-poor
“We are drowning in information, but starving for knowledge” -John Naisbett
• Unless it is used to improve business practices, data is a liability, not an asset
• Standard data analysis techniques are useful but insufficient and may miss valuable insight

Real Examples
• Consider the enormous amounts of data generated Transactional data by credit card companies Searches on Google, Yahoo, and MSN Clickstream (web) or other sensor data Europe's Very Long Baseline Interferometry (VLBI) has 16
telescopes, each of which produces 1 Gigabit/second of astronomical data over a 25-day observation session
• storage and analysis are a big problem Walmart reported to have 24 Tera-byte DB (likely even larger now)
AT&T handles billions of calls per day• data cannot be stored -- analysis must be done on the fly
Social media data

What Is Data Mining?Business Definition
• Deployment of business processes, supported by adequate analytical techniques, to:
Take further advantage of data Discover RELEVANT knowledge ACT on the results
KDD is the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data.

Application Domains (I)
• Direct marketing and retail Behavior analysis, Offer targeting, Market basket
analysis, Up-selling, etc.
• Banks and financial institutions Credit risk assessment, Fraud detection, Portfolio
management, Forecasting, etc.
• Telecommunications Churn prediction, Product/service development,
campaign management, fraud detection, etc.

Application Domains (II)
• Healthcare Public health monitoring (infectious outbreaks, etc),
Outcomes measurement (performance, cost, success rate, etc), Diagnostic help, etc.
• Pharmaceutical industry / Bio-informatics Biological activity prediction, Coding sequence
discovery, Animal tests reduction, etc.
• Insurances Cross-selling, Risk analysis, Premium setting, Claims
analysis, Fraud detection, etc.

Application Domains (III)
• Transports Network management, Booking optimization,
Customer service, etc.
• Manufacturing Load forecasting, Production management, Equipment
monitoring, Quality management, etc.
• Etc.
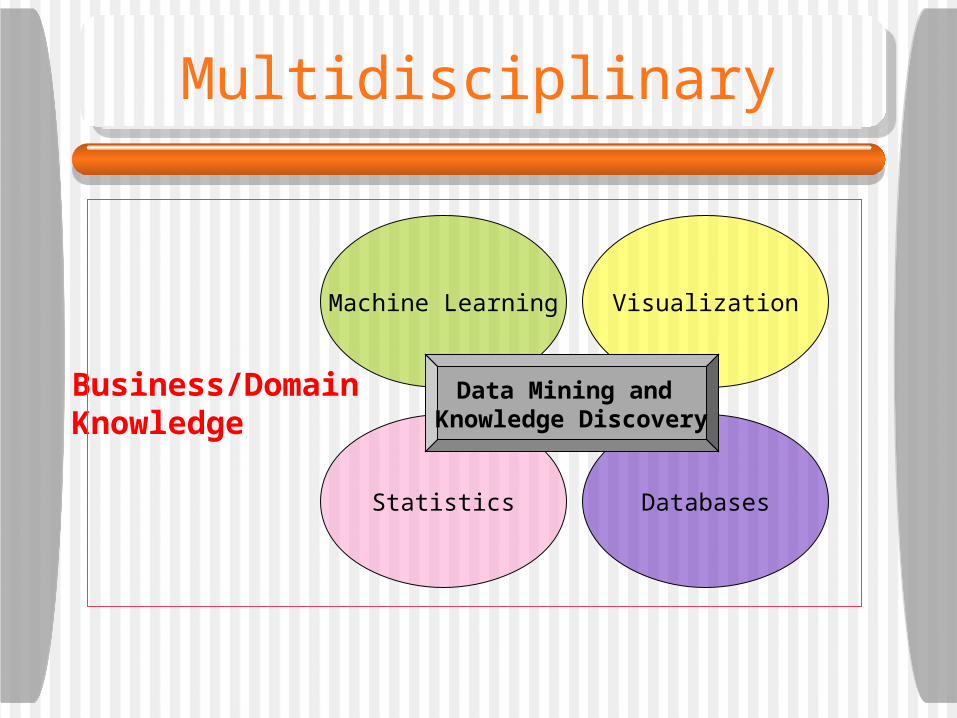
Multidisciplinary
DatabasesStatistics
VisualizationMachine Learning
Data Mining and Knowledge Discovery
Business/DomainKnowledge

Data Mining Tasks
• Summarization
• Classification / Prediction Classification, Concept learning, Regression
• Clustering
• Dependency modeling
• Anomaly detection
• Link Analysis

Summarization
• To find a compact description for a subset of the data. Producing the average down time of all plant
equipments in a given month, computing the total income generated by each sales representative per region per year
• Techniques: Statistics, Information theory, OLAP, etc.

Prediction
• To learn a function that associates a data item with the value of a response variable. If the response variable is discrete, we talk of classification learning; if the response variable is continuous, we talk of regression learning. Assessing credit worthiness in a loan underwriting business,
assessing the probability of response to a direct marketing campaign
• Techniques: Decision trees, Neural networks, Naïve Bayes, Support
vector machines, Logistic regression, Nearest-neighbors, etc.

Clustering
• To identify a set of (meaningful) categories or clusters to describe the data. Clustering relies on some notion of similarity among data items and strives to maximize intra-cluster similarity whilst minimizing inter-cluster similarity. Segmenting a business’ customer base, building a taxonomy
of animals in a zoological application
• Techniques: K-Means, Hierarchical clustering, Kohonen SOM, etc.

Dependency Modeling
• To find a model that describes significant dependencies, associations or affinities among variables. Analyzing market baskets in consumer goods
retail, uncovering cause-effect relationships in medical treatments
• Techniques: Association rules, ILP, Graphical modeling, etc.

Anomaly Detection
• To discover the most significant changes in the data from previously measured or normative values. Detecting fraudulent credit card usage, detecting
anomalous turbine behavior in nuclear plants
• Techniques: Novelty detectors, Probability density models, etc.

Data Mining Process
• CRISP-DM: Cross-Industry Standard Process for Data Mining
• Consortium effort involving: NCR Systems Engineering Copenhagen DaimlerChrysler AG SPSS Inc. OHRA Verzekeringen en Bank Groep B.V
• History: Version 1.0 released in 1999 See www.crisp-dm.org for further details

Visual Overview

Collect Initial DataInitial Data Collection Report
Describe DataData Description Report
Explore DataData Exploration Report
Verify Data Quality Data Quality Report
Summary: Phases & Tasks
BusinessUnderstanding
DataUnderstanding EvaluationData
PreparationModeling
Determine Business ObjectivesBackgroundBusiness ObjectivesBusiness Success Criteria
Situation AssessmentInventory of ResourcesRequirements, Assumptions, and ConstraintsRisks and ContingenciesTerminologyCosts and Benefits
Determine Data Mining GoalData Mining GoalsData Mining Success Criteria
Produce Project PlanProject PlanInitial Asessment of Tools and Techniques
Data SetData Set Description
Select Data Rationale for Inclusion / Exclusion
Clean Data Data Cleaning Report
Construct DataDerived AttributesGenerated Records
Integrate DataMerged Data
Format DataReformatted Data
Select Modeling TechniqueModeling TechniqueModeling Assumptions
Generate Test DesignTest Design
Build ModelParameter SettingsModelsModel Description
Assess ModelModel AssessmentRevised Parameter Settings
Evaluate ResultsAssessment of Data Mining Results w.r.t. Business Success CriteriaApproved Models
Review ProcessReview of Process
Determine Next StepsList of Possible ActionsDecision
Plan DeploymentDeployment Plan
Plan Monitoring and MaintenanceMonitoring and Maintenance Plan
Produce Final ReportFinal ReportFinal Presentation
Review ProjectExperience Documentation
Deployment

CRISP-DM Phases
• Business Understanding Initial phase Focuses on:
• Understanding the project objectives and requirements from a business perspective
• Converting this knowledge into a data mining problem definition, and a preliminary plan designed to achieve the objectives
• Data Understanding Starts with an initial data collection Proceeds with activities aimed at:
• Getting familiar with the data• Identifying data quality problems• Discovering first insights into the data• Detecting interesting subsets to form hypotheses for hidden information

CRISP-DM Phases
• Data Preparation Covers all activities to construct the final dataset (data that will be fed
into the modeling tool(s)) from the initial raw data Data preparation tasks are likely to be performed multiple times, and
not in any prescribed order Tasks include table, record, and attribute selection, as well as
transformation and cleaning of data for modeling tools
• Modeling Various modeling techniques are selected and applied, and their
parameters are calibrated to optimal values Typically, there are several techniques for the same data mining
problem type Some techniques have specific requirements on the form of data,
therefore, stepping back to the data preparation phase is often needed

CRISP-DM Phases
• Evaluation At this stage, a model (or models) that appears to have
high quality, from a data analysis perspective, has been built
Before proceeding to final deployment of the model, it is important to more thoroughly evaluate the model, and review the steps executed to construct the model, to be certain it properly achieves the business objectives
A key objective is to determine if there is some important business issue that has not been sufficiently considered
At the end of this phase, a decision on the use of the data mining results should be reached

CRISP-DM Phases
• Deployment Creation of the model is generally not the end of the project Even if the purpose of the model is to increase knowledge of the data,
the knowledge gained will need to be organized and presented in a way that the customer can use it
Depending on the requirements, the deployment phase can be as simple as generating a report or as complex as implementing a repeatable data mining process
In many cases it will be the customer, not the data analyst, who will carry out the deployment steps
However, even if the analyst will not carry out the deployment effort it is important for the customer to understand up front what actions will need to be carried out in order to actually make use of the created models

The Missing Link
Monitoring
Closing the Loop
Changes in dataChanges in environment
How do I know my model remains valid and applicable?
When should I update my model(s)?
How do I update my model(s)?

Data Mining Myths (I)
• Data Mining produces surprising results that will utterly transform your business Reality:
• Early results = scientific confirmation of human intuition.
• Beyond = steady improvement to an already successful organisation.
• Occasionally = discovery of one of those rare « breakthrough » facts.
• Data Mining techniques are so sophisticated that they can substitute for domain knowledge or for experience in analysis and model building Reality:
• Data Mining = joint venture.
• Close cooperation between experts in modeling and using the associated techniques, and people who understand the business.

Data Mining Myths (II)
• Data Mining is useful only in certain areas, such as marketing, sales, and fraud detection Reality:
• Data mining is useful wherever data can be collected.
• All that is really needed is data and a willingness to « give it a try. » There is little to loose…
• Only massive databases are worth mining Reality:
• A moderately-sized or small data set can also yield valuable information.
• It is not only the quantity, but also the quality of the data that matters (characterising mutagenic compounds)

Data Mining Myths (III)
• The methods used in Data Mining are fundamentally different from the older quantitative model-building techniques Reality:
• All methods now used in data mining are natural extensions and generalisations of analytical methods known for decades.
• What is new in data mining is that we are now applying these techniques to more general business problems.
• Data Mining is an extremely complex process Reality:
• The algorithms of data mining may be complex, but new tools and well-defined methodologies have made those algorithms easier to apply.
• Much of the difficulty in applying data mining comes from the same data organisation issues that arise when using any modeling techniques.

Food for Thought
• “Data mining can't be ignored -- the data is there, the methods are numerous, and the advantages that knowledge discovery brings to a business are tremendous.”
• “People who can't see the value in data mining as a concept either don't have the data or don't have data with integrity.”
• “Data mining is quickly becoming a necessity, and those who do not do it will soon be left in the dust. Data mining is one of the few software activities with measurable return on investment associated with it.”

Data Mining Deliverables
• Provides additional insight about the data and the business
• Provides scientific confirmation of empirical/intuitive business observations
• Discovers new, subtle pieces of business knowledge
In that order !

Key Success Factors
• Have a clearly articulated business problem that needs to be solved and for which Data Mining is the adequate technology
• Ensure that the problem being pursued is supported by the right type of data of sufficient quality and in sufficient quantity
• Recognise that Data Mining is a process with many components and dependencies
• Plan to learn from the Data Mining process whatever the outcome

Conclusion
• Data Mining transforms data into actions• Data Mining is hard work
It is a process, not a single activity Most companies are clueless and DM is an
afterthought Plan to learn through the process Think big, start small
• Data Mining is FUN!

More on Data Mining
• KDnuggets News, software, jobs, courses, etc.www.KDnuggets.com
• ACM SIGKDD Data mining associationwww.acm.org/sigkdd

Sample Applications

Retail

The Situation
• Potential applications: Associations of products that sell together Segmentation of customers
• Short audit: Nice DWH, only 2 years old, not fully
populated Limited data on purchases and subscriptions

Summarization / Aggregation
• Revenue distribution 80% generated by 41.5% of subscribers 60% generated by 18.3% of subscribers 42.9% generated by top 5 products
• Simple customer classes Over 65 years old most profitable Under 16 years old least profitable
• Birthdate filled-in for only about 10% of subscribers!

Product Association
• About 21% of subscribers buy P4, P7 and P9 P4 is most profitable product P7 is ranked 6th P9 is ranked 15th with only 2%
of revenue
• Several possible actions Make a bundle offering of these products Cross-sell from P9 to P4 Temptation to remove P9 should be resisted

Clustering
30% of customers whobuy a single yearly
product
!!!

Summary of Findings
• Data Mining found: A small percentage of the customers is responsible for a large
share of the sales Several groups of « strongly-connected » articles A sizeable group of subscribers who buy a single article
• What was learned? First 2 findings: « we knew that! » (BUT: scientific confirmation
of business observation) 3rd finding: « we could target these customers with a special
offer! » Lack of relevant data: the structure is in place but not being used
systematically

Family History

Finding Affinities
Metrics generally depend on the nature of the attribute (e.g.,
nominal, real, string)
Star Wars Family Tree

Total Affinities(Thicker lines indicate stronger affinities --- Highly connected group )
CHARACTERISTICSName, Sex, Hometown, Occupation,
Political Affiliation, Children

More Than 2 Affinities
Seems to be an important link
CHARACTERISTICSName, Sex, Hometown, Occupation,
Political Affiliation, Children

Occupational Affinity Network
Moisture FarmersMoisture Farmers
Jedi KnightsJedi KnightsStronger Affinity
between Luke and Obi-Wan because
they were both Jedi Knights and
Jedi Masters

Birthday Networks(Two or more affinities)
Twins!
Close relatives that share birthdays
Duplicate individual

Given Name Network (One or more affinities)
Interesting! both husband and wife’s maternal grandfathers
share the same first and middle names.
InterestingNaming Pattern
Through generations
More neatNaming Patterns…
Relatives sharing the same middle names

Record Linkage

Record Linkage
• The process of identifying similar people
• Essential for exchanging and/or merging pedigrees
• MAL4:6 uses the individuals and their relatives as found in their pedigrees

Challenges
• Each relationship/attribute is treated equally• Weights
Version 0.1 used feature selection instead of continuous weights
Weights would allow MAL4:6 to use all of the data in a pedigree to a degree (TBD by MAL4:6)
• Naturally Skewed Data #NonMatches >> #Matches Learners tend to over learn the majority class

Similarity
• Attributes: A = {A1,A2,…An}, Ai would be a piece of information (e.g., date of birth)
• For each Ai, simAi is the similarity metric associated with Ai
• Let x = < A1 : a1x, A2 : a2
x,…, An : anx > denote an individual where aj
x
is the value of Aj for x <firstname: John, lastname: Smith,…>
• Let R= {R0,R1,…Rm} be a set of functions that map an individual to one of its relatives

Structured Network
FatherIndividual
Similarity Scores
SpouseWeights
Match MisMatch
ij
i

Results
• Genealogical database from the LDS Church’s Family History Department (~5 million individuals)
• ~16,000 labeled data instances
Precision: 88.9% Recall: 93.8%

E-Commerce

Search Term Analysis
• Prior to April 2005 Search terms used prior to April
contained very few unique keywords
Most common keywords used were words in the actual domain name
Significant surge in April 2005Significant surge in April 2005 Diversification of the search terms, often corresponding to new Diversification of the search terms, often corresponding to new
products/offersproducts/offers Doubling of number of unique visitorsDoubling of number of unique visitors
What happened? What happened? Search Engine Optimization (SEO)Search Engine Optimization (SEO)!!

Shipping Policy
• August 2005 Change shipping policy Highly visible, lower, free+
• Impact on abandoned carts? Not significant
Before-After PurchasesBefore-After Purchases Marked increase in number of Marked increase in number of
purchases in all categoriespurchases in all categories 100% increase for high-end 100% increase for high-end
category (free shipping)category (free shipping) Can’t infer causality BUT clear Can’t infer causality BUT clear
indication of some effectindication of some effect


















