
05-Unit5
43
Oracle & Distributed Databases Unit 5 Sikkim Manipal Page No. Unit 5 Distributed Databases Overview Structure: 5.1 Introduc tion Objectiv es 5.2 Distributed Processing Self Assessment Questions 5.3 Features of Distributed versus Centralized Databases Self Assessment Questions 5.4 Uses of Distributed Databases Self Assessment Questions 5.5 Distributed Database Management Systems (DDBMS) Self Assessment Questions 5.6 Reference Architecture for Distributed Databases Self Assessment Questions 5.7 Types of Data Fragmentation 5.7.1 Horizontal Fragmentation 5.7.2 Derived Horizontal Fragmentation 5.7.3 Vertical Fragmentation
-
Upload
inder-dialani -
Category
Documents
-
view
22 -
download
0
description
BC0049
Transcript of 05-Unit5

Oracle & Distributed Databases Unit 5
Sikkim Manipal Page No.
Unit 5 Distributed Databases Overview
Structure:
5.1 Introduction
Objectives
5.2 Distributed Processing
Self Assessment Questions
5.3 Features of Distributed versus Centralized Databases
Self Assessment Questions
5.4 Uses of Distributed Databases
Self Assessment Questions
5.5 Distributed Database Management Systems (DDBMS)
Self Assessment Questions
5.6 Reference Architecture for Distributed Databases
Self Assessment Questions
5.7 Types of Data Fragmentation
5.7.1 Horizontal Fragmentation
5.7.2 Derived Horizontal Fragmentation
5.7.3 Vertical Fragmentation
5.7.4 Mixed Fragmentation
Self Assessment Questions
5.8 Integrity Constraints in Distributed Databases
Self Assessment Questions
5.9 Summary
5.10 Terminal Questions
5.11 Answers to Self Assessment Questions

Oracle & Distributed Databases Unit 5
Sikkim Manipal Page No.
5.1 Introduction
A distributed database is a network of databases managed by multiple
database servers that are used together. They are not usually seen as a
single logical database. The data of all databases in the distributed
database can be simultaneously accessed and modified. The primary
benefit of a distributed database is that the data of physically separate
databases can be logically combined and potentially made accessible to all
users on a network.
Each computer that manages a database in the distributed database is
called a node. The database to which a user is directly connected is called
the local database. Any additional databases accessed by this user are
called remote databases. When a local database accesses a remote
database for information, the local database is a client of the remote server.
This is an example of client/server architecture.
While a distributed a database enables increased access to a large amount
of data across a network, it must also hide the location of the data and the
complexity of accessing it across the network. The distributed database
management system must also preserve the advantages of administrating
each local database as through it were not distributed.
Objectives:
By the end of this unit we will learn the following topics
Distributed processing
Comparison of centralized and distributed databases
Different uses of distributed databases
Discussion of Distributed DBMS
Reference Architecture for Distributed Databases
Types of Data Fragmentation
Integrity constraints in Distributed Databases

Sikkim Manipal Page No.
Oracle & Distributed Databases Unit 5
5.2 Distributed Processing
A Distributed processing system is one in which several autonomous
processors and data stores supporting processes and/or databases interact
in order to cooperate to achieve an overall goal. The processes coordinate
their activities and exchange information transferred over a communication
network.
Nowadays distributed processing is the important area of information
processing and also it is implemented using the concept of Distributed
databases. A Distributed Database is a collection of data, which belong
logically to the same system but are spread over the sites of computer
network. The two important aspects of a distributed database:
Distribution: The data are not resided in centralized place
Logical Correlation: The data are tied themselves with some properties
Let us understand the above terminologies by taking an example. Consider
a Bank Transaction. Here the bank has three branches at different locations.
At each branch the computer controls the teller terminals of the branch and
the account database of the branch. Each local branch database is termed
as SITE of the distributed database connected by a communication network.
All the local transactions are managed by these local computers and will
therefore be called as local applications. An example of local application is
a debit or a credit application performed on an account stored at the same
branch at which the application is requested.
Also there are some applications which accesses data at more than one
branch known as Global applications or Distributed applications, i.e. for
example the transfer of funds from account of one branch to an account of
other branch. This is not that simple issue as it involves updating the
databases at two different places.

Sikkim Manipal Page No.
Oracle & Distributed Databases Unit 5
We can now summarize the above aspects and let us reform the definition
of the distributed database as a collection of data, which are distributed over
different computers of a computer network. Each site of the network has
autonomous processing capability and can perform local applications and
also it participates at least in one global application, which requires
accessing data at several sites using a communication subsystem. The
most important aspect expected from the system is the cooperation between
the autonomous sites.
Self Assessment Questions 5.2
1. The two important aspects of a distributed database are –––––––– and
–––––––– .
2. In distributed databases, all the local transactions are managed by local
computers and will therefore be called as ––––––––.
5.3 Features of Distributed versus Centralized databases
It is better if we look at the typical features of the centralized database and
compare them with the corresponding features of distributed databases.
The following table gives the comparative study of the main features.
Sl.No Features Centralized databases Distributed databases
1 Centralized control
The idea of centralization is much emphasized here.Here a Database administrator (DBA) takes care about the safety of the data
Here the idea of distribution of the data is considered. A hierarchical approach of administration like Global administrator, local administrator is incorporated.
2 Data independence
Data independence means that the actual organization of the data is transparent to the programmer. Here a notion called Conceptual schema is used which gives the conceptual view of the data.
Here a notion called Distribution transparency is used which makes the program unaffected by the movement of the data from one site to another.

Oracle & Distributed Databases Unit 5
Sikkim Manipal Page No.
3 Reduction of redundancy
Here the redundancy is reduced as far as possible.
Here the redundancy is an added feature as the locality of applications is increased if the data is replicated at all sites where the applications needed it and also the reliability of the application can be increased.
4 Complex physical structures and efficient access
The efficient access of the data is supported by the complex physical data structures like secondary indexes, interfile chains and so on.
Here Complex physical structures will not support the efficient data access as the data is distributed. This can be solved using the concepts like local and global optimization, which determines the optimum procedure for accessing the data at different sites.
5 Integrity, Recovery and Concurrency control
Here this problem can be solved easily as it is controlled at one point. Transaction atomicity is the concept used for this purpose i.e the sequence of operations performed either completely or not performed at all.
Here it is difficult as the transactions may be initiated at different sites simultaneously. Special algorithms have to be used to take care about this aspect.
6 Privacy and Security
Maintained by centralized data base administrator.
Maintained by Local Data Base Administrators at different sites
Self Assessment Questions 5.3
1. A hierarchical approach of administration like Global administrator, local
administrator is incorporated in –––––––– databases.
2. –––––––– means that the actual organization of the data is transparent
to the programmer.
5.4 Uses of Distributed Databases
There are several reasons why distributed databases are developed. The
following is a list of the main motivations.
Organizational and economic reasons
Usage and interconnection of existing databases
Incremental growth of an organization
Reduced communication overhead

Oracle & Distributed Databases Unit 5
Sikkim Manipal Page No.
Performance aspects
Increased reliability and availability
Organizational and economic reasons: Many organizations are decentral-
ized, and a distributed database approach fits more naturally the structure of
the organization. With the recent developments in computer technology, the
economy-of-scale motivation for having large, centralized computer centers
is becoming questionable. The organizational and economic motivations are
probably the most important reason for developing distributed databases.
Interconnection of existing databases: Distributed databases are the nat-
ural solution when several databases already exist in an organization and
the necessity of performing global applications arises. In this case, the
distributed database is created bottom-up from the preexisting local
databases. This process may require a certain degree of local restructuring;
however, the effort which is required by this restructuring is much less than
that needed for the creation of a completely new centralized database.
Incremental growth: If an organization grows by adding new, relatively
autonomous organizational units (new branches, new warehouses, etc.),
then the distributed database approach supports a smooth incremental
growth with a minimum degree of impact on the already existing units.
Reduced communication overhead: In a geographically distributed data-
base like the database of Example 1.1, the fact that many applications are
local clearly reduces the communication overhead with respect to a
centralized database. Therefore, the maximization of the locality of
applications is one of the primary objectives in distributed database design.
Performance considerations: The existence of several autonomous
processors results in the increase of performance through a high degree of
parallelism. This consideration can be applied to any multiprocessor system,

Oracle & Distributed Databases Unit 5
Sikkim Manipal Page No.
and not only to distributed databases. However, distributed databases have
the advantage in that the decomposition of data reflects application
dependent criteria which maximize application locality; in this way the
mutual interference between different processors is minimized.
Reliability and availability: The distributed database approach, especially
with redundant data, can be used also in order to obtain higher reliability
and availability. However, obtaining this goal is not straightforward and
requires the use of techniques which are still not completely understood.
The autonomous processing capability of the different sites does not by
itself guarantee a higher overall reliability of the system, but it ensures a
graceful degradation property; in other words, failures in a distributed
database can be more frequent than in a centralized one because of the
greater number of components, but the effect of each failure is confined to
those applications which use the data of the failed site, and complete
system crash is rare.
Self Assessment Questions 5.4
1. The –––––––– and economic motivations are probably the most
important reason for developing distributed databases.
2. The –––––––– approach supports a smooth incremental growth with a
minimum degree of impact on the already existing units.
3. The existence of several –––––––– results in the increase of
performance through a high degree of parallelism.
5.5 Distributed Data Base Management Systems (DDBMS)
A Distributed Database Management System helps in the creation and
management of distributed databases. The software requirements for
building a distributed database are:
The Database Management Component (DB)

Oracle & Distributed Databases Unit 5
Sikkim Manipal Page No.
The Data Communication Component (DC)
The Data Dictionary (DD), which gives the idea of data distribution in the
entire network.
The Distributed Database Component (DDB)
The figure 5.1 can show the interaction between the above components.
The services supported by the above components are
Remote database access to an application program.
Some degree of distribution transparency
Support for database administration and control
Support for concurrency control and recovery of distributed transactions
The different types of the Distributed database accesses available
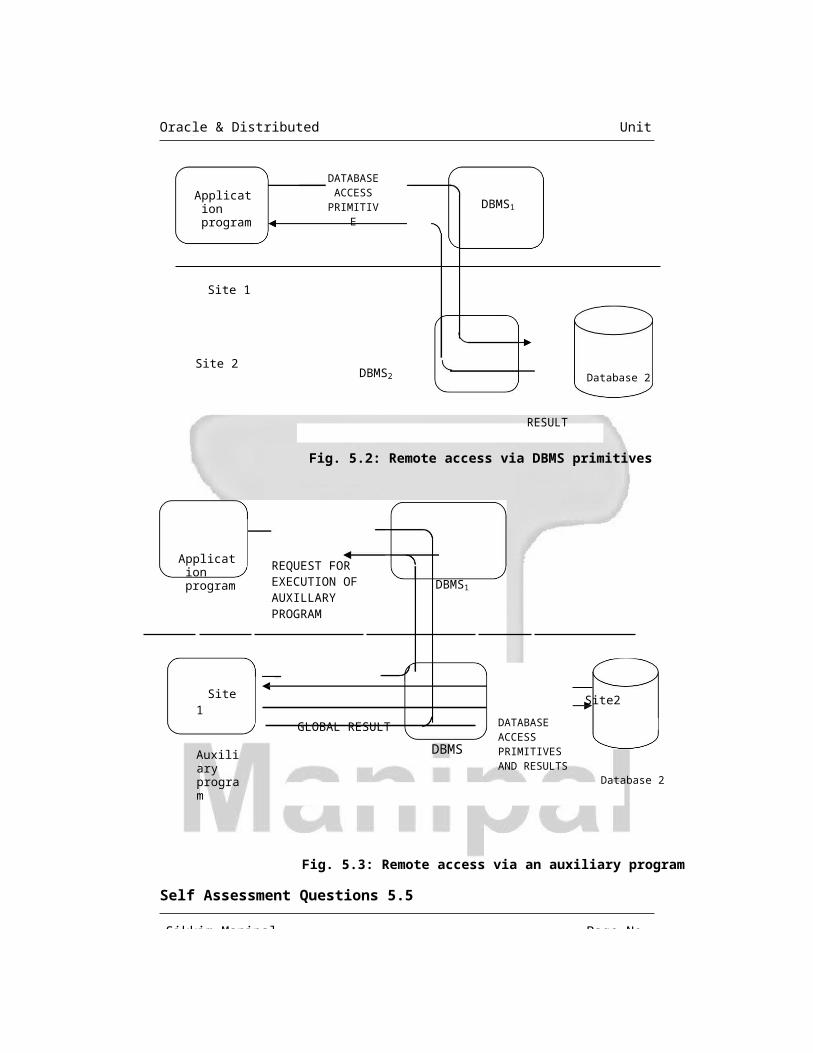
a. Remote access via DBMS primitives: Here the application issues a
request, which refers to remote data. Fig 5.2 shows this scenario. This
request is automatically routed by the DDBMS to the site where the data
is located; then it is executed and the corresponding result is returned.
b. Remote access via auxiliary program: Here the application requires
the auxiliary program to be executed at the remote site, which accesses
the remote database and returns the result to requesting application.
Fig. 5.3 gives the exact picture about the concept.

Oracle & Distributed Databases Unit 5
Sikkim Manipal Page No.
Terminals
Local Database 1
DB DCDDB
DD
Site 1
Site 2
Local Database 1
DB DCDDB
DD
Terminals
Fig. 5.1: Components of a commercial DDBMS

Oracle & Distributed Databases Unit 5
Sikkim Manipal Page No.
Application program
DATABASE ACCESS
PRIMITIVE DBMS1
Site 1
Site 2DBMS2 Database 2
RESULT
Fig. 5.2: Remote access via DBMS primitives
Application program
REQUEST FOR EXECUTION OF AUXILLARY PROGRAM
DBMS1
Site 1
Auxiliary program
GLOBAL RESULT
DBMS
DATABASE ACCESS PRIMITIVES AND RESULTS
Site2
Database 2
Fig. 5.3: Remote access via an auxiliary program
Self Assessment Questions 5.5
1. A –––––––– helps in the creation and management of distributed
databases.

Oracle & Distributed Databases Unit 5
Sikkim Manipal Page No.
2. An application requires the –––––––– to be executed at the remote site,
which accesses the remote database and returns the result to
requesting application.
5.6 Reference Architecture for Distributed Databases
Here we have suggested reference architecture for the distributed
databases as shown in the figure 5.4. The different levels are conceptually
helpful to understand the functioning of the whole system. The various
stages of the architecture are as follows.
Global Schema: defines all the data, which are contained in the
distributed database as if it is a centralized system. Here a set of global
relations is used.
Fragmentation Schema: Each global relation is split into several non-
overlapping portions that are called as Fragments. The mapping
between the global relations and fragments is defined in the
Fragmentation Schema. It is a one to many relations such that several
fragments correspond to one global relation but only one global relation
corresponds to one fragment. They are indicated as Ri, the ith fragment
of the global relation R.
Allocation Schema: The fragments are really the logical portions of the
global relation, which are physically dispersed at different sites of the
network. This schema defines at which site(s) a fragment is allocated. It
is to be noted that depending upon the requirement more than one
fragment may be allocated at a site. So this mapping determines
whether the system is a Redundant or a Non Redundant System.
Local Mapping Schema: We have already described the relationships
between the objects at the three top levels of this architecture. These
three levels are site independent; therefore, they do not depend on the

Oracle & Distributed Databases Unit 5
Sikkim Manipal Page No.
data model of the local DBMSs. At a lower level, it is necessary to map
the physical images to the objects that are manipulated by the local
DBMSs. This mapping is called a local mapping schema and depends
on the type of local DBMS; therefore in a heterogeneous system we
have different types of local mappings at different sites.
Global schema
Fragmentation schema
Allocation schema
Local mapping schema 1
Local mapping schema 2
Other sites
DBMS of site 1 DBMS of site 2
Local DB1
Local DB2
Fig. 5.4: A reference architecture for distributed databases
This architecture provides a very general conceptual framework for
understanding distributed databases. The three most important objectives
that motivate the features of this architecture are the separation of data
fragmentation and allocation, the control of redundancy, and the
independence from local DBMSs.

Sikkim Manipal Page No.
Oracle & Distributed Databases Unit 5
Separating the concept of data fragmentation from the concept of
data allocation: This separation allows us to distinguish two different
levels of distribution transparency, namely fragmentation transparency
and location transparency. Fragmentation transparency is the highest
degree of transparency and consists of the fact that the user or
application programmer works on global relations. Location
transparency is a lower degree of transparency and requires the user or
application programmer to work on fragments instead of global relations;
however, he or she does not know where the fragments are located.
Explicit control of redundancy: The reference architecture provides
explicit control of redundancy at the fragment level.
Independence from local DBMSs: This feature, called local mapping
transparency, allows us to study several problems of distributed
database management without having to take into account the specific
data models of local DBMSs. Another type of transparency, which is
strictly related to location transparency, is replication transparency.
Replication transparency means that the user is unaware of the
replication of fragments.
Self Assessment Questions 5.6
1. Each global relation is split into several non-overlapping portions that
are called as –––––––– .
2. –––––––– transparency is a lower degree of transparency and requires
the user or application programmer to work on fragments instead of
global relations.
3. –––––––– transparency means that the user is unaware of the
replication of fragments.

Sikkim Manipal Page No.
Oracle & Distributed Databases Unit 5
5.7 Types of Data Fragmentation
There are two different types of fragmentation. Horizontal and Vertical
fragmentation can decompose the global relations into fragments. We will
first consider these two types of fragmentation separately and then consider
the more complex fragmentation, which can be obtained by applying a
composition of both.
In all types of fragmentation, a fragment can be defined by an expression in
a relational language (we will use relational algebra), which takes global
relation as operands and produces the fragment as result. For example, if a
global relation contains data about employees, a fragment which contains
only data about employees who work at department D1 can be obviously
defined by a selection operation on the global relation.
Some rules, which must be followed when defining fragments
Completeness Condition: All the data of the global relation must be
mapped into the fragments; i.e., it must not happen that a data item that
belongs to a global relation does not belong to any fragment.
Reconstruction Condition: It must always be possible to reconstruct
each global relation from its fragments. The necessity of this condition is
obvious in fact, only fragments are stored in the distributed database,
and global relation has to be built through this reconstruction operation if
necessary.
Disjoint Condition: It is convenient that fragments be disjoint, so that
the replication of data can be controlled explicitly at the allocation level.
5.7.1 Horizontal Fragmentation
Horizontal Fragmentation consists of partitioning the tuples of a global
relation into subsets; this is clearly useful in distributed databases, where
each subset can contain data that have common geographical properties. It

Oracle & Distributed Databases Unit 5
Sikkim Manipal Page No.
can be defined by expressing each fragment as a selection operation on the
global relation.
Example: let a global relation be
SUPPLIER (SNUM, NAME, CITY)
Then the horizontal fragmentation can be defined in the following way:
SUPPLIER1 = SLCITY =”Manipal” SUPPLIER
SUPPLIER2 = SLCITY =”Udupi” SUPPLIER
Now let us verify whether this fragmentation fulfills the conditions stated
earlier.
The completeness condition: If “Manipal” and “Udupi” are the only
possible values of the CITY attribute, then it satisfies this condition.
The reconstruction condition: can be verified easily, because it is always
possible to reconstruct the SUPPLIER global relation through the following
operation.
SUPPLIER = SUPPLIER1 UN SUPPLIER2
The disjoint ness condition is clearly verified.
Qualification: The predicate, which is used in the selection operation and
defines a fragment, is called as Qualification. For instance, in the above
example the qualifications
q1 : CITY = “Manipal”
q2 : CITY = “Udupi”
We can generalize from the above example that in order to satisfy the
completeness condition, the set of qualifications of all fragments must be
complete, at least with respect to the set of allowed values. The
reconstruction condition is always satisfied through the union operation, and
the disjoint ness condition requires that qualifications be mutually exclusive.

Oracle & Distributed Databases Unit 5
Sikkim Manipal Page No.
5.7.2 Derived Horizontal Fragmentation
This is a type of fragmentation, which is derived from the horizontal
fragmentation of another relation.
Example: Consider a global relation
SUPPLY (SNUM, PNUM, DEPTNUM, QUAN)
where SNUM is a supplier number. If it is required that a fragment has to
contain the tuples for suppliers, which are in a given city, and then we have
to go for derived fragmentation. A semi-join operation with the fragments
SUPLIER1 and SUPLIER2 is needed in order to determine the tuples of
SUPPLY, which correspond to the suppliers in a given city. The derived
fragmentation of SUPPLY can be therefore defined as follows:
SUPPLY1 = SUPPLY SJSNUM=SNUMSUPPLIER1
SUPPLY2 = SUPPLY SJSNUM=SNUMSUPPLIER2
The reconstruction of the global relation SUPPLY can be performed
through the union operation as was shown for SUPPLIER.
The completeness of the above fragmentation requires that there be no
supplier numbers in the SUPPLY relation, which are not contained also in
the SUPPLIER relation. This is a typical, and reasonable, integrity constraint
for this database and usually is called as the referential integrity
constraint.
The disjoint ness condition is satisfied if a tuple of the SUPPLY relation
does not correspond to two tuples of the SUPPLIER relation that belong to
two different fragments. In this case this condition is easily verified, because
the supplier numbers are unique keys of the SUPPLIER relation.
5.7.3 Vertical Fragmentation
The Vertical fragmentation of a global relation is the subdivision of its
attributes into groups; fragments are obtained by projecting the global
relation over each group. This can be useful in distributed databases where

Oracle & Distributed Databases Unit 5
Sikkim Manipal Page No.
each group of attributes can contain data that have common geographical
properties. The fragmentation is correct; if each attribute is mapped into at
least one attribute of the fragments; moreover, it must be possible to
reconstruct the original relation by joining the fragments together.
Example: Consider a global relation
EMP (EMPNUM, NAME, SAL, TAX, MGRNUM, DEPTNUM)
A vertical fragmentation of this relation can be defines as
EMP1=PJ EMPNUM,NAME, MGRNUM, DEPTNUM EMP
EMP2=PJ EMPNUM, SAL,TAX EMP
The reconstruction of relation EMP can be obtained as
EMP=EMP1JN EMPNUM=EMPNUM EMP2
This is because; EMPNUM is a key of EMP.
Let us draw some important points to be noted from this example.
The purpose of including the key of the global relation into each
fragment is to ensure the reconstruction property.
An alterative way to provide the reconstruction property is to generate
tuple identifiers that are used as system-controlled keys. This can be
convenient in order to avoid the replication of large keys; moreover,
users cannot modify tuple identifiers.
Let us finally consider the problem of fragment disjoint ness. First, we have
seen that at least the key should be replicated in all fragments in order to
allow reconstruction. In fact, if we include the same attribute in two different
vertical fragments, we know exactly that the column that corresponds to this
attribute.
For example, consider the following vertical fragmentation of relation EMP:
EMP1 = PJEMPNUM,NAME,MGRNUM,DEPTNUM EMP
EMP2 = PJEMPNUM,NAME,SAL,TAX EMP
Oracle & Distributed Databases Unit 5
Sikkim Manipal Page No.
The attribute NAME is replicated in both fragments. We can remove this
attribute when we reconstruct relation EMP through an additional projection
operation.
EMP = EMP1 JNEMPNUM=EMPNUM PJEMPNUM, SAL, TAX EMP2
5.7.4 Mixed Fragmentation
The fragments that are obtained by the above fragmentation operations are
relations themselves, so that it is possible to apply the fragmentation
operations recursively, provided that the correctness conditions are satisfied
each time. The reconstruction can be obtained by applying the
reconstruction rules in reverse order.
Example: Consider the same global relation
EMP (EMPNUM, NAME, SAL, TAX, MGRNUM, DEPTNUM)
The following is a mixed fragmentation, which is obtained by applying the
vertical fragmentation of the previous example, followed by a horizontal
fragmentation on DEPTNUM:
EMP1 = SLDEPTNUM10 PJEMPNUM, NAME, MGRNUM, DEPTNUM EMP
EMP2 = SL10<DEPTNUM20 PJEMPNUM, NAME, MGRNUM, DEPTNUM EMP
EMP3 = SLDEPTNUM>20 PJEMPNUM, NAME, MGRNUM, DEPTNUM EMP
EMP4 = PJEMPNUM, NAME, SAL , TAX EMP
EMP
v
EMP4
h
EMP1 EMP2 EMP3
Fig. 5.5: The fragmentation tree of relation EMP

Oracle & Distributed Databases Unit 5
Sikkim Manipal Page No.
The reconstruction of relation EMP is defined by the following expression:
EMP = UN (EMP1, EMP2, EMP3) JNEMPNUM = EMPNUM
PJEMPNUM, SAL, TAX EMP4
A fragmentation tree can conveniently represent mixed fragmentation (as
shown in the above figure). In a fragmentation tree, the root corresponds to
a global relation, the leaves corresponds to the leaves correspond to the
fragments, and the intermediate nodes correspond to the intermediate
results of the fragment-defining expressions.
The EXAMPLE_DDB:
The following codes shows the global and fragmentation schemata of
EXAMPLE_DDB. Most of the global relations of EXAMPLE_DDB and their
fragmentation have been already introduced. A DEPT relation, horizontally
fragmented into three fragments on the value of the DEPTNUM attribute, is
added.
Global schema
EMP (EMPNUM, NAME, SAL, TAX, MGRNUM, DEPTNUM)
DEPT (DEPTNUM, NAME, AREA, MGRNUM)
SUPPLIER (SNUM, PNUM, DEPTNUM, QNUM)
Fragmentation schema
EMP1 = SLDEPTNUM 10 PJEMPNUM, NAME, MGRNUM, DEPTNUM(EMP)
EMP2 = SL10<DEPTNUM 20 PJEMPNUM, NAME, MGRNUM, DEPTNUM(EMP)
EMP3 = SLDEPTNUM >20 PJEMPNUM, NAME, MGRNUM, DEPTNUM(EMP)
EMP4 = PJEMPNUM, NAME, SAL, TAX(EMP)
DEPT1= SLDEPTNUM10(DEPT)
DEPT2= SL10<DEPTNUM20(DEPT)
DEPT3= SLDEPTNUM>20(DEPT)
SUPPLIER1 = SLCITY = “SF” (SUPPLIER)
SUPPLIER2 = SLCITY = “LA” (SUPPLIER)

Oracle & Distributed Databases Unit 5
Sikkim Manipal Page No.
SUPPLY1 = SUPPLY SJSNUM=SNUMSUPPLIER1
SUPPLY2 = SUPPLY SJSNUM=SNUMSUPPLIER2
Self Assessment Questions 5.7
1. Horizontal and Vertical fragmentation can decompose the ––––––––
relations into fragments.
2. –––––––– fragmentation consists of partitioning the tuples of a global
relation into subsets.
3. The Vertical fragments are obtained by –––––––– the global relation
over each group.
4. The reconstruction of mixed fragmentation can be obtained by applying
the –––––––– rules in reverse order.
5.8 Integrity Constraints in Distributed Databases
When an update performed by a database application violates an integrity
constraint, the application is rejected and thus the correctness of data is
preserved. A typical example of integrity constraint is referential integrity,
which requires that all values of a given attribute of a relation exist also in
some other relation. This constraint is particularly useful in distributed
databases, for ensuring the correctness of derived fragmentation. For
example, since the SUPPLY relation has a fragmentation which is derived
from that of SUPPLIER relation by means of a semi-join on the SUPNUM
attribute, it is required that all values of SUPNUM in SUPPLY be present
also in SUPPLIER.
Integrity constraints can be enforced automatically by adding to application
programs some code for testing whether the constraint is violated. If so, the
program execution is suspended and all actions already performed by it are
cancelled, if necessary.
One of the most serious disadvantages of integrity constraints is the loss in
performance that is due to the execution of the integrity tests; this loss is

Oracle & Distributed Databases Unit 5
Sikkim Manipal Page No.
very important in distributed databases. The major problems in applying
integrity checking might increase the need of accessing remote sites. It is
necessary to consider also integrity checking in the design of the distribution
of database.
Self Assessment Questions 5.8
1. A typical example of integrity constraint is ––––––––, which requires that
all values of a given attribute of a relation exist also in some other
relation.
2. The major problems in applying integrity checking might increase the
need of accessing –––––––– sites.
5.9 Summary
By the discussions made in this unit you have come to know the importance
of data distribution and distributed processing. Also we have discussed
about the software requirement for managing the distributed database. In
this unit we have studied reference architecture for distributed database.
Also the different types of fragmentation techniques are discussed. We have
also seen some demonstration examples. Some ideas about integrity
constraints are given.
5.10 Terminal Questions
1. How might a distributed database designed for a LAN differ from one
designed for a WAN?
2. Differentiate between features of the centralized database and
distributed databases
3. Discuss the relative advantages of centralized and distributed databases
4. Name the different types of accesses available in distributed databases
5. Explain how the following differ: fragmentation transparency, replication
transparency and location transparency

Oracle & Distributed Databases Unit 5
Sikkim Manipal Page No.
6. When is it useful to have replication or fragmentation of data? Explain
your answer
5.11 Answers to Self Assessment Questions
Answers to Self Assessment Questions 5.2
1. Distribution and Logical Correlation
2. Local applications
Answers to Self Assessment Questions 5.3
1. distributed
2. Data independence
Answers to Self Assessment Questions 5.4
1. organizational
2. distributed database
3. autonomous processors
Answers to Self Assessment Questions 5.5
1. Distributed Database Management System
2. Auxiliary program
Answers to Self Assessment Questions 5.6
1. Fragments
2. Location
3. Replication
Answers to Self Assessment Questions 5.7
1. global
2. Horizontal
3. projecting
4. reconstruction
Answers to Self Assessment Questions 5.8
1. referential integrity
2. remote


















