
03 pig intro
36
Apache Pig Intro
-
Upload
subhas-kumar-ghosh -
Category
Software
-
view
163 -
download
0
Transcript of 03 pig intro

Apache Pig Intro



Data Processing Renaissance
Internet companies swimming in data• E.g. TBs/day at Yahoo!
Data analysis is “inner loop” of product innovation
Data analysts are skilled programmers

Data Warehousing …?
Scale Often not scalable enough
$ $ $ $Prohibitively expensive at web scale
• Up to $200K/TB
SQL
• Little control over execution method• Query optimization is hard
• Parallel environment• Little or no statistics• Lots of UDFs

The Map-Reduce Appeal
Scale
Scalable due to simpler design• Only parallelizable operations• No transactions
$ Runs on cheap commodity hardware
Procedural Control- a processing “pipe”SQL

Disadvantages
1. Extremely rigid data flow
Other flows constantly hacked in
Join, Union Split
M R
M M R M
Chains
2. Common operations must be coded by hand• Join, filter, projection, aggregates, sorting, distinct
3. Semantics hidden inside map-reduce functions• Difficult to maintain, extend, and optimize

Need for High-Level Languages
• Hadoop is great for large-data processing!
– But writing Java programs for everything is verbose and slow
– Not everyone wants to (or can) write Java code
• Solution: develop higher-level data processing languages
– Hive: HQL is like SQL
– Pig: Pig Latin is a bit like Perl

Pros And Cons
Need a high-level, general data flow language

Enter Pig Latin
Need a high-level, general data flow language

Hive and Pig
• Hive: data warehousing application in Hadoop
– Query language is HQL, variant of SQL
– Tables stored on HDFS as flat files
– Developed by Facebook, now open source
• Pig: large-scale data processing system
– Scripts are written in Pig Latin, a dataflow language
– Developed by Yahoo!, now open source
– Roughly 1/3 of all Yahoo! internal jobs
• Common idea:
– Provide higher-level language to facilitate large-data processing
– Higher-level language “compiles down” to Hadoop jobs

Apache Pig• Is a platform for analyzing large data sets that consists of a high-level
language for expressing data analysis programs, coupled with infrastructure for evaluating these programs.
• The salient property of Pig programs is that their structure is amenable to substantial parallelization, which in turns enables them to handle very large data sets.
• At the present time, Pig's infrastructure layer consists of a compiler that produces sequences of Map-Reduce programs, for which large-scale parallel implementations already exist (e.g., the Hadoop subproject).
• Pig's language layer currently consists of a textual language called Pig Latin, which has the following key properties:– Ease of programming. It is trivial to achieve parallel execution of simple,
"embarrassingly parallel" data analysis tasks. Complex tasks comprised of multiple interrelated data transformations are explicitly encoded as data flow sequences, making them easy to write, understand, and maintain.
– Optimization opportunities. The way in which tasks are encoded permits the system to optimize their execution automatically, allowing the user to focus on semantics rather than efficiency.
– Extensibility. Users can create their own functions to do special-purpose processing.

Running Pig
• You can execute Pig Latin statements:
– Using grunt shell or command line
$ pig ... - Connecting to ...
grunt> A = load 'data';
grunt> B = ... ;
– In local mode or hadoop mapreduce mode
$ pig myscript.pig
Command Line - batch, local mode mode
$ pig -x local myscript.pig
– Either interactively or in batch

Program/flow organization
• A LOAD statement reads data from the file system.
• A series of "transformation" statements process the data.
• A STORE statement writes output to the file system; or, a DUMP statement displays output to the screen.

Interpretation
• In general, Pig processes Pig Latin statements as follows:– First, Pig validates the syntax and semantics of all statements.
– Next, if Pig encounters a DUMP or STORE, Pig will execute the statements.
A = LOAD 'student' USING PigStorage() AS (name:chararray, age:int, gpa:float);
B = FOREACH A GENERATE name;
DUMP B;
(John)
(Mary)
(Bill)
(Joe)
• Store operator will store it in a file

Simple Examples
A = LOAD 'input' AS (x, y, z);
B = FILTER A BY x > 5;
DUMP B;
C = FOREACH B GENERATE y, z;
STORE C INTO 'output';
--------------------------------------------------------------------------
A = LOAD 'input' AS (x, y, z);
B = FILTER A BY x > 5;
STORE B INTO 'output1';
C = FOREACH B GENERATE y, z;
STORE C INTO 'output2'

Example Data Analysis Task
user url time
Amy www.cnn.com 8:00
Amy www.crap.com 8:05
Amy www.myblog.com 10:00
Amy www.flickr.com 10:05
Fred cnn.com/index.htm 12:00
url pagerank
www.cnn.com 0.9
www.flickr.com 0.9
www.myblog.com 0.7
www.crap.com 0.2
Find users who tend to visit “good” pages.
PagesVisits
. . .
. . .
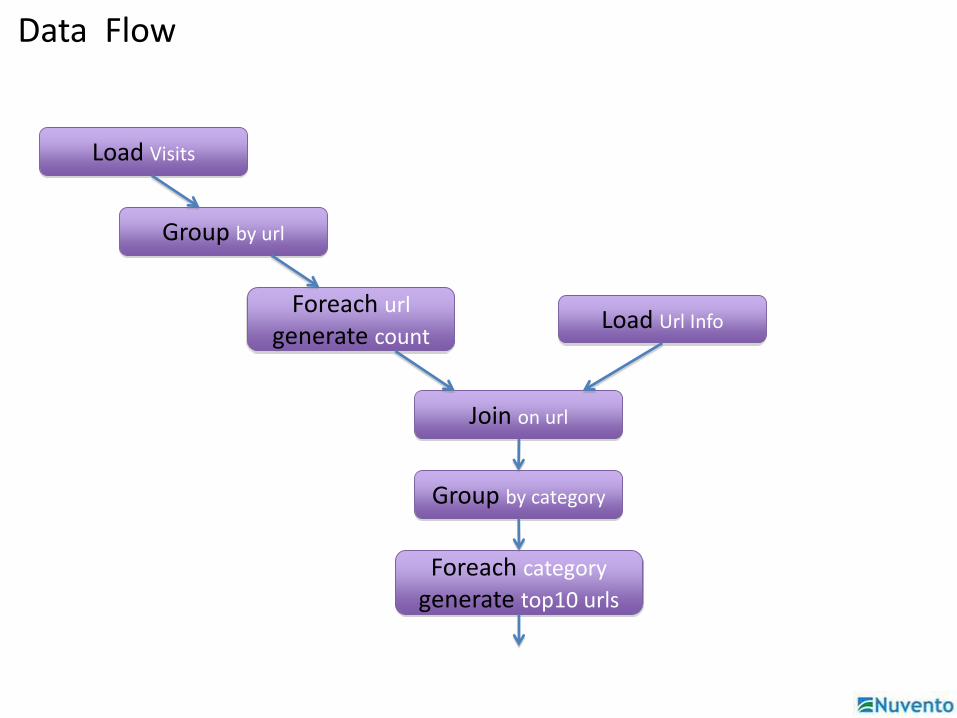
Data Flow
Load Visits
Group by url
Foreach url
generate countLoad Url Info
Join on url
Group by category
Foreach category
generate top10 urls

System-Level Dataflow
. . . . . .
Visits Pages. . .
. . .
join by url
the answer
loadload
canonicalize
compute average pagerank
filter
group by user
Pig Slides adapted from Olston et al.

How to Program this in Pig
VISITS = load ‘/user/viraj/visits.txt' as (user:chararray, url:chararray, time:chararray);
PAGES = load '/user/viraj/pagerank.txt' as (url:chararray, pagerank:float);
VISITS_PAGES = join VISITS by url, PAGES by url;
Load files for processing with appropriate types
Join them on url fields of table

How to Program this in Pig
USER_VISITS = group VISITS_PAGES by user;
USER_AVGPR = foreach USER_VISITS generate group, AVG(VISITS_PAGES.pagerank) as avgpr;
GOOD_USERS = filter USER_AVGPR by avgpr > 0.5f;
store GOOD_USERS into '/user/viraj/goodusers';
Group by user, in our case Amy, Fred
Generate an average pagerank per user
Filter records based on pagerank
Store results in hdfs

In Pig Latin
visits = load ‘/data/visits’ as (user, url, time);
gVisits = group visits by url;
visitCounts = foreach gVisits generate url, count(visits);
urlInfo = load ‘/data/urlInfo’ as (url, category, pRank);
visitCounts = join visitCounts by url, urlInfo by url;
gCategories = group visitCounts by category;
topUrls = foreach gCategories generate top(visitCounts,10);
store topUrls into ‘/data/topUrls’;

visits = load ‘/data/visits’ as (user, url, time);
gVisits = group visits by url;
visitCounts = foreach gVisits generate url, count(urlVisits);
urlInfo = load ‘/data/urlInfo’ as (url, category, pRank);
visitCounts = join visitCounts by url, urlInfo by url;
gCategories = group visitCounts by category;
topUrls = foreach gCategories generate top(visitCounts,10);
store topUrls into ‘/data/topUrls’;
Quick Start and Interoperability
Operates directly over files

visits = load ‘/data/visits’ as (user, url, time);
gVisits = group visits by url;
visitCounts = foreach gVisits generate url, count(urlVisits);
urlInfo = load ‘/data/urlInfo’ as (url, category, pRank);
visitCounts = join visitCounts by url, urlInfo by url;
gCategories = group visitCounts by category;
topUrls = foreach gCategories generate top(visitCounts,10);
store topUrls into ‘/data/topUrls’;
Quick Start and Interoperability
Schemas optional; Can be assigned dynamically

visits = load ‘/data/visits’ as (user, url, time);
gVisits = group visits by url;
visitCounts = foreach gVisits generate url, count(urlVisits);
urlInfo = load ‘/data/urlInfo’ as (url, category, pRank);
visitCounts = join visitCounts by url, urlInfo by url;
gCategories = group visitCounts by category;
topUrls = foreach gCategories generate top(visitCounts,10);
store topUrls into ‘/data/topUrls’;
User-Code as a First-Class Citizen
User-defined functions (UDFs) can be used in every construct
• Load, Store• Group, Filter, Foreach

Java vs. Pig Latin
020406080100120140160180
Hadoop Pig
1/20 the lines of code
0
50
100
150
200
250
300
Hadoop Pig
Minutes
1/16 the development time
Performance on par with raw Hadoop!
Pig Slides adapted from Olston et al.

PIG vs Java M/R
• Java M/R
– Better tuning ability for advance users
• faster execution
• Better resource utilization
– Code duplication across multiple M/R jobs
• Complex data analysis typically require workflow of M/R jobs
• PIG
– Insulates users from Hadoop complexity
• including version updates
– Increases programmer productivity
• small learning curve
• Less lines of code
– Opens the M/R programming system to non-programmers

Pig takes care of…
• Schema and type checking
• Translating into efficient physical dataflow
– (i.e., sequence of one or more MapReduce jobs)
• Exploiting data reduction opportunities
– (e.g., early partial aggregation via a combiner)
• Executing the system-level dataflow
– (i.e., running the MapReduce jobs)
• Tracking progress, errors, etc.

Using Pig• Pig runs as a client-side application.
• Even if you want to run Pig on a Hadoop cluster, there is nothing extra to install on the cluster: – Pig launches jobs and
– interacts with HDFS from your workstation
• Pig has two execution types or modes: – local mode and
– MapReduce mode
• Local:– In local mode, Pig runs in a single JVM and accesses the local filesystem.
– This mode is suitable only for small datasets and when trying out Pig.
– The execution type is set using the -x or -exectype option.
– To run in local mode, set the option to local: pig -x local
– This starts Grunt, the Pig interactive shell
• MapReduce mode:– In MapReduce mode, Pig translates queries into MapReduce jobs and runs them on a
Hadoop cluster.
– Once you have configured Pig to connect to a Hadoop cluster, you can launch Pig, setting the -x option to mapreduce, or omitting it entirely, as MapReduce mode is the default: pig

Implementation
cluster
Hadoop Map-Reduce
Pig
SQL
automaticrewrite +optimize
or
or
user
Pig is open-source.
http://incubator.apache.org/pig

Compilation into Map-Reduce
Load Visits
Group by url
Foreach url
generate countLoad Url Info
Join on url
Group by category
Foreach category
generate top10(urls)
Map1
Reduce1Map2
Reduce2
Map3
Reduce3
Every group or join operation forms a map-reduce boundary
Other operations pipelined into map and reduce phases

Pig Latin = Sweet Spot between SQL & Map-Reduce
SQL Pig Map-Reduce
Programming style Large blocks of declarative
constraints
“Plug together pipes”
Built-in data
manipulations
Group-by, Sort, Join, Filter,
Aggregate, Top-k, etc...
Group-by, Sort
Execution model Fancy; trust the query optimizer
Simple, transparent
Opportunities for
automatic
optimization
Many
Few (logic buried in map()
and reduce())
Data Schema Must be known at table creation
Not required, may be defined
at runtime

From Pig Latin to Map Reduce
Parser
ScriptA = load
B = filter
C = group
D = foreach
Logical PlanSemanticChecks
Logical PlanLogicalOptimizer
Logical Plan
Logical toPhysicalTranslatorPhysical Plan
PhysicalTo MRTranslator
MapReduceLauncher
Jar to
hadoop
Map-Reduce Plan
Logical Plan ≈
relational algebra
Plan standard optimizations
Physical Plan = physical operators to be executed
Map-Reduce Plan = physical operators broken into Map, Combine, and Reduce stages

Running Pig Programs• There are three ways of executing Pig programs, all of which work in both
local and MapReduce mode:
• Script
– Pig can run a script file that contains Pig commands.
– For example, pig script.pig runs the commands in the local file script.pig.
– Alternatively, for very short scripts, you can use the -e option to run a script specified as a string on the command line.
• Grunt
– Grunt is an interactive shell for running Pig commands.
– Grunt is started when no file is specified for Pig to run, and the -e option is not used.
– It is also possible to run Pig scripts from within Grunt using run and exec.
• Embedded
– You can run Pig programs from Java using the PigServer class, much like you can use JDBC to run SQL programs from Java.
– For programmatic access to Grunt, use PigRunner.

Grunt
• Grunt has line-editing facilities like those found in GNU Readline(used in the bash shell and many other command-line applications).
• For instance, the Ctrl-E key combination will move the cursor to the end of the line.
• Grunt remembers command history and you can recall lines in the history buffer using Ctrl-P or Ctrl-N (for previous and next)
• or, equivalently, the up or down cursor keys.
• Another handy feature is Grunt’s completion mechanism, which will try to complete Pig Latin keywords and functions when you press the Tab key.
• You can customize the completion tokens by creating a file named autocomplete and placing it on Pig’s classpath.

End of session
Day – 3: Apache Pig Intro


















