
0.- Binomial& Normal
19
VARIABLE ALEATORIA Y DISTRIBUCIÓN DE PROBABILIDAD VARIABLE ALEATORIA La definición formal de variable aleatoria requiere de ciertos conocimientos profundos de matemática, en concreto de la teoría de la medida Definición práctica. Aquí vamos a simplificar la definición diciendo que una variable aleatoria, que denotaremos como VA(x), es: a. Una característica que produce valores que dependen del azar b. Una función que asocia valores numéricos a los eventos que produce un experimento aleatorio c. Matemáticamente, cualquier función (fórmula, relación de correspondencia) que permite encontrar las probabilidades para cada uno de los valores que produce un experimento F(V (x) ), conocida como función de masa o cuantía en el caso de variables aleatorias discretas y de función de densidad, en el caso de variables aleatorias continuas. d. Toda función F(X), que tiene la propiedad de transformar una variable nominal o cualitativa, en numérica o cuantitativa, como producto de asignar valores numéricos a los eventos que tales variables generan. Ejemplo: Supóngase el experimento “atender dos parturientas primerizas para un proceso de parto”. El espacio muestral, esto es, el conjunto de resultados compuestos posibles asociados al experimento aleatorio* “tipo de parto realizado” si “C” = parto por cesárea y “V” = parto vía vaginal, sería: *Si el tipo de parto se realizara de acuerdo a las condiciones naturales aleatoria que presente la parturienta y no en función de una decisión sesgada del médico que la atienda S = {CC, CV,VC, VV} Podemos definir para el anterior experimento un evento elemental E, por ejemplo: E = “número de partos por cesárea realizados” y definir una función (relación de asociación) para la variable aleatoria, así: VA(x): S R (esto es, una función (fórmula) para valores “x” que toma la VA, tal que asocia, a un espacio muestral S, un valor numérico que se encuentra dentro del conjunto de los números reales), es decir, al realizar el experimento se puede observar que:
-
Upload
steffaniie-lopez -
Category
Documents
-
view
236 -
download
1
description
Variables de bioestadistica
Transcript of 0.- Binomial& Normal

VARIABLE ALEATORIA Y DISTRIBUCIÓN DE PROBABILIDADVARIABLE ALEATORIA
La definición formal de variable aleatoria requiere de ciertos conocimientos profundos de matemática, en concreto de la teoría de la medida
Definición práctica. Aquí vamos a simplificar la definición diciendo que una variable aleatoria, que denotaremos como VA(x), es:
a. Una característica que produce valores que dependen del azar
b. Una función que asocia valores numéricos a los eventos que produce un experimento aleatorio
c. Matemáticamente, cualquier función (fórmula, relación de correspondencia) que permite encontrar las probabilidades para cada uno de los valores que produce un experimento F(V(x)), conocida como función de masa o cuantía en el caso de variables aleatorias discretas y de función de densidad, en el caso de variables aleatorias continuas.
d. Toda función F(X), que tiene la propiedad de transformar una variable nominal o cualitativa, en numérica o cuantitativa, como producto de asignar valores numéricos a los eventos que tales variables generan.
Ejemplo:Supóngase el experimento “atender dos parturientas primerizas para un proceso de parto”. El espacio muestral, esto es, el conjunto de resultados compuestos posibles asociados al experimento aleatorio* “tipo de parto realizado” si “C” = parto por cesárea y “V” = parto vía vaginal, sería:
*Si el tipo de parto se realizara de acuerdo a las condiciones naturales aleatoria que presente la parturienta y no en función de una decisión sesgada del médico que la atienda
S = {CC, CV,VC, VV}
Podemos definir para el anterior experimento un evento elemental E, por ejemplo:E = “número de partos por cesárea realizados” y definir una función (relación de asociación) para la variable aleatoria, así: VA(x): S R (esto es, una función (fórmula) para valores “x” que toma la VA, tal que asocia, a un espacio muestral S, un valor numérico que se encuentra dentro del conjunto de los números reales), es decir, al realizar el experimento se puede observar que:
A los puntos muestrales CC 1, evento: “se observan 2 cesáreas”“ “ “ “ CV y VC 2, evento: “se observa una cesárea“ “ “ “ VV 0 , evento: “no se observan cesáreas”
luego, como el rango de esta función está dentro del conjunto de los números reales R, esto es R(x) = {0, 1, 2} por lo tanto VA(x): S R , se dice que es una variable aleatoria.
Observación: Si se pueden conocer todos los valores que puede tomar una variable aleatoria, y además tenemos (conocemos o se puede determinar) la probabilidad de cada uno de esos valores, y estos valores los podemos representar mediante una tabla, gráfico o fórmula, se dice entonces que estamos en presencia de lo que normalmente se conoce como distribución de probabilidades, en donde la variable aleatoria no es más que la función (fórmula) a la cual se han asociado números reales (eventos numéricos) que dependen del azar…

Se puede concluir entonces que la variable aleatoria no es más que la función que está asociada a un experimento aleatorio, y la distribución de probabilidades no es más que una tabla, gráfico o fórmula que presenta de manera ordenada el comportamiento de todas las probabilidades para cada uno de los eventos que produce la variable aleatoria
Tomando esto como punto de partida analicemos como ejemplo el siguiente experimento ya conocido: el lanzamiento de una moneda.
Como se recordará encontrar la probabilidad de obtener una cara sería fácil como producto de aplicar una definición clásica de probabilidades, esto es P(A) = ½ = 0.5 = 50%, pero ¿Qué pasaría si ahora en vez de lanzar una moneda lanzáramos 4 de ellas, y en vez de observar una cara estuviésemos interesados en observar 2? ¿Por quienes estaría conformado el espacio muestral?. A fin de visualizar mejor los resultados elaboremos un diagrama de árbol, y pongamos atención a las siguientes observaciones:
Solución por diagrama de árbol
A AAAA 4C4 = 1A
B AAAB 4C3 = 4A
A AABA B
B AABB 4C2 = 6A
A ABAAA
B ABABB
A ABBAB
B ABBB 4C1 = 40
A BAAA A
B BAABA
A BABAB
B BABBB
A BBAAA
B BBABB
A BBBAB
B BBBB 4C0 = 1
Luego, P(2A) = 6/16 = 3/8 = 0.375 = 37.5%
Pues, todavía se ve fácil, pero, ¿Qué pasaría si en lugar de 4, fueran 10, 20, 100 monedas ó más?, ¿Cómo podríamos encontrar las probabilidades si se deseara observar 4, 7 ó más caras?
Una solución podría facilitarse si pudiésemos conocer como se distribuyen sus probabilidades… ¿porqué?, veámoslo a continuación, no sin antes clasificar las variables aleatorias y definir lo que se ha de entender en probabilidades por función de distribución

TIPOS DE VARIABLE ALEATORIA
Las variables aleatorias pueden clasificarse según el recorrido o rango Rx, así:
a) Si Rx es un subconjunto discreto, como en nuestro ejemplo, la variable recibe el nombre de variable aleatoria discreta o VAD
Otros ejemplos serían:
Personas que mejoran su salud al administrarles determinada medicina Cantidad de leucocitos por campo encontrados en muestras de orina de niños
enfermos Nuevos casos de SIDA observados cada mes durante “Y” año, etc. pero,
b) Si su recorrido no es un conjunto numerable*, entonces la variable recibe el nombre de variable aleatoria continua o VAC (en este caso, intuitivamente implica que el conjunto de posibles valores de la variable abarca a todo un intervalo de números reales. Ejemplo, sea VA(x) la variable que asigna el peso a un neonato; supóngase que la normalidad de la variable oscila entre 5.75 y 9.15 lbs; luego, como teóricamente todo valor entre dichos extremos es posible, se dice entonces que la variable aleatoria es continua.
Ejemplos de VAC:
Cantidad de colesterol observado en personas de entre 40 y 60 años Perímetro cefálico de 50 recién nacidos Tamaño de “X” plantas después de 15 días de germinación, etc.
FUNCIÓN DE DISTRIBUCIÓN
Cuando para c/una de las anteriores variables es posible encontrar todos los valores que asumen las mismas, o bien es posible definir una función que permitiese conocer o determinar dichos valores, y se ordenan estos en una tabla de frecuencias o en una gráfica, a tal función, que muestra el comportamiento ordenado de las probabilidades que tienen cada uno de los eventos mutuamente excluyentes que produce la variable aleatoria, se le conoce como distribución de probabilidad, la cual recibe a la vez diferente nombre en función de si la variable aleatoria es discreta o continua, a saber:
a) Función de Masa o Cuantía, si se tratase de una variable aleatoria discreta; luego, una función de masa o cuantía es aquella función que recoge todos los valores que asume una VAD, o
b) Función de Densidad, si se tratase de una variable aleatoria continua, o sea, una función de densidad es aquella función que recoge todos los valores que se asocian a una VAC
De lo anterior se puede ver que una función de distribución de probabilidades no es más que aquella función (fórmula) que permite obtener las probabilidades de todos aquellos eventos que produce un experimento aleatorio. Y recordando que la probabilidad puede expresarse en términos de frecuencia relativa P(E)= n/N, se puede decir entonces que una distribución de probabilidad también es un arreglo ordenado de todas las probabilidades que asumen los eventos (indicadores de la variable aleatoria),y que están representados ya sea por una tabla, gráfica o una fórmula.
FÓRMULA DE LA DISTRIBUCIÓN DE PROBABILIDADES PARA UNA VA(x)

Si x es una variable aleatoria discreta, entonces la distribución de probabilidades de la VAD viene dada por la sumatoria de la función de masa o cuantía, así:
Pero, Si x es una variable aleatoria continua entonces la distribución de probabilidades viene dada por la integral de la función de densidad, esto es:
Si x es una variable aleatoria continua
DISTRIBUCIÓN DE PROBABILIDAD PARA VARIBALES ALEATORIAS DISCRETAS
No es más que una tabla que presenta el ordenamiento de las probabilidades de todos los eventos mutuamente excluyentes que puede asumir una variable aleatoria, asociada a un experimento aleatorio, y que permite determinar cuál es el comportamiento de la variable (espacio muestral o población) en función de las probabilidades. Esto es importante, ya que significa que si pudiéramos conocer el comportamiento de una población en términos de las probabilidades, entonces podríamos calcular las probabilidades para un subconjunto de valores (muestra) que se derivaran de ella. Para comprenderlo mejor volvamos a nuestro caso
¿Qué pasaría si quisiéramos encontrar las probabilidades para cada uno de los eventos? haciéndolo y ordenándolas tendríamos los siguientes resultados
FUNCIÓN DE MASA O CUANTÍA PARA DISTINTOS COMPORTAMIENTOS DEDISTRIBUCIÓN DE PROBABILIDADES DE VARIABLES ALEATORIAS DISCRETAS.
Según sean los comportamientos de las distribuciones de probabilidad, existen ya modelos, a los cuales se les ha determinada una función matemática específica, en el caso de VA(x) las más estudiadas son:
Distribución de probabilidad Uniforme
Significa que todos los puntos muestrales tienen igual probabilidad de ocurrir, ejem. En el lanzamiento de un dado, o el lanzamiento de una moneda, o al contestar una pregunta de selección múltiple, o la probabilidad de un sujeto de pertenecer a determinado grupo sanguíneo.
Distribución de probabilidad Binomial ó P(Y=y) = nCy . Py . Qn-y
Si la probabilidad para un evento puede ser determinada a partir de sólo dos posibles resultados, uno de los cuales denominaremos probabilidad de éxito, y al otro probabilidad de frecaso. Ejem. Determinar para una muestra la probabilidad de encontrar determinado
N°Caras
Pm P(E)Distribución gráfica de P(E) observaciones
0 1 1/16 P(e) F(y)=Σf(m) 6 5 4 3 2 1 V(y)
0 1 2 3 4 Caras observadas
La función de distribución de probabilidad no es más que la sumatoria de la función de Masa o cuantía, esta última a su vez es la fórmula que permite obtener la probabilidad Para cada uno de los eventos que asume la variable aleatoria discreta, esto es:
ó sea P(E1) + P(E2) + …… + P(En)
Fórmula que dependerá del comportamiento de las probabilidades de VA(x)
1 4 4/162 6 6/163 4 4/164 1 1/16
total 16 1.00
¿Qué pasaría si en lugar de 4, fueran 10, 20, 100 monedas ó más?

grupo sanguíneo sabiendo que en la población sus indicadores son A=27%, B=10%, AB=13% y O=50%
Distribución de probabilidad Binomial negativa
Importante, en el caso de la probabilidad binomial, para determinar el orden en que pueden ocurrir las probabilidades para un punto muestral o evento específico
Distribución de probabilidad de Poisson
en el caso de necesitar encontrar probabilidades para un tamaño grande de muestra (matemáticamente, podríamos decir, cuándo n tiende a infinito) y un pequeño valor de variable aleatoria con una probabilidad muy pequeña (matemáticamente, se podría decir, cuando P tiende a cero)
Distribución de probabilidad Geométrica
Distribución de probabilidad Hipergeométrica
Distribución de probabilidad Zeta
LA DISTRIBUCIÓN BINOMIAL
La distribución binomial es una distribución de probabilidad discreta del número de éxitos en una secuencia de “n” experimentos independientes, cada uno de los cuales tiene probabilidad “P” de ocurrir. La función de masa para la distribución de probabilidad binomial viene dada por:
P(Y=y) = nCy . Py . Qn-y
PERO, ¿En qué consiste el Experimento Binomial?
La variable aleatoria binomial y su distribución están basadas en un experimento que satisface las siguientes condiciones:
El experimento consiste en una secuencia de n intentos,donde n se fija antes del experimento.
Los intentos son idénticos, y cada uno de ellos puede resultar en dos posibles resultados, que se denotan por éxito (P) o fracaso (Q, ) luego (P(P)+P(Q)=1
Los intentos (ensayos) son independientes: el resultado de cualquier intento en particularNO influye sobre el resultado de cualquier otro intento.
La probabilidad de éxito es constante de un intento a otro.
Por lo tanto, si un problema que requiere del cálculo de probabilidades puede plantearse en estos términos, su solución podría obtenerse por medio de la fórmula de Bernoulli, POR EJEMPLO, para el caso del experimento de la moneda, si por alguna razón se deseara encontrar la probabilidad de sacar 5 caras y 7 coronas en

12 lanzamientos, ¿podría hacerse por un análisis Binomial? ¿Porqué? Pues porque revisando las características se puede observar que:
1.- se requiere hacer una secuencia de 12 ensayos.
2.- los ensayos (experimentos) serían idénticos: “lanzar una moneda a lo vez”, lo cual sólo podría dar 2 resultados: o cae cara o NO cae cara, siendo P= ”cae cara” , el éxito y Q = “cae corona, o NO cara” el fracaso… en este punto es importante aclarar que el éxito o fracaso viene definido por el evento de interés, y/o por el investigador, quien previamente ha de determinar a qué suceso le llamará éxito y a qué, fracaso
3.- los ensayos son idénticos (lanzar una moneda tras otra) pero el hecho de que el resultado de un “n1” sea cara no implica que el resultado de un n2 también será cara, o será afectado, esto es: tenga más o menos probabilidad de ocurrir lo que nos indica que los ensayos son independientes, y por último
4.- la probabilidad de éxito es constante, ya que dado que sólo puede caer cara o corona,
entonces P(E)=1/2 = 0.5 ( a este respecto es importante hacer notar que no siempre la probabilidad de éxito viene dada por la probabilidad clásica, sino que esta puede ser dada por la probabilidad frecuencial observada del fenómeno o incluso por la probabilidad empírica o personal; en este sentido, la probabilidad de éxito puede ser obtenida por:
a) Referencia estadísticab) Sondeo o estudio pilotoc) Planteamiento de hipótesisd) Probabilidad clásica usando Métodos de conteo e) Asunción o presunción de P=Qf) Otras formas (determinación a partir de indicadores, etc.)
Solución: extrayendo los datos tenemos que n = 12; y = 5 y P = 0.5, entonces aplicando la fórmula de Bernoulli:
La media y la varianza para una distribución binomial se obtienen, respectivamente así: μ = nP; σ = nPQ, luego para nuestro caso se tendría que:
μ = 12(0.5) = 6 y σ = 12(0.5)(0.5) = 3
EJEMPLO 2.- supóngase que como producto de una investigación se observa que un 15% de las estudiantes universitarias de “Y” universidad sale embarazada antes de terminar su tercer año de estudios, y que él 75% de ellas deja el estudio como consecuencia de la situación, si para efectos de evaluar el fenómeno, ud toma
0.193359375

aleatoriamente y sin que se sepa 25 señoritas de nuevo ingreso, y se dispone a llevar el control respectivo, ¿Qué probabilidad tiene de observar al final de 3 años que:
a) 5 señoritas salgan embarazadasb) Al menos 2 señoritas dejen de estudiar por salir embarazadasc) A lo sumo 3 se embaracen pero no dejen de estudiar
¿Qué probabilidad hay que al tomar una muestra de 15 señoritas que desertaron del estudio se observe que:
a) dos lo hayan hecho por haber salido embarazadasb) a lo sumo 3 hayan abandonado los estudios por embarazoc) ninguna lo hizo por embarazo
Ahora bien, ¿Qué pasaría si en vez de tomar una muestra de 15, tomásemos como observación las 600 que ingresan en “Y” facultad, y que se sabe que sólo el 3.5% de las estudiantes deja de estudiar como consecuencia de un embarazo? Que la binomial ya no nos es tan útil ni viable su cálculo, por lo que la probabilidad es mejor calcularla a partir de la distribución de Poisson, pero ¿Qué es la distribución de Poisson?, veámoslo a continuación
LA DISTRIBUCIÓN DE POISSON
En teoría de probabilidad y estadística, la distribución de Poisson es una distribución de probabilidad discreta. Expresa la probabilidad de un número de eventos ocurriendo en un tiempo fijo si estos eventos ocurren con una tasa media conocida, y son independientes del tiempo desde el último evento. En términos concretos la probabilidad viene definida por la función de masa
en dónde: Su media y su varianza son: ; y:
e es el base del logaritmo natural (e = 2.71828...), k es el número de ocurrencias de un evento, k! es el factorial de k, λ es un número real positivo, equivalente al número esperado de ocurrencias
durante un intervalo dado. Por ejemplo, si los eventos ocurren de media cada 4 minutos, y se está interesado en el número de eventos ocurriendo en un intervalo de 10 minutos, se usaría como modelo una distribución de Poisson con λ = 2.5, ya que 10min/4min = 2.5
Por ejemplo, si 2% de los niños en cierta unidad de salud adquieren X problema de salud, obténgase la probabilidad de que 5 de 400 niños atendidos en esa unidad de salud tengan el problema de salud X.
Solución: dado que el número de ocurrencias del evento es k = 5, mientras que el número esperado de veces que ocurra como promedio el evento es = nP = 400(0.02) = 8; entonces, la probabilidad según Poisson sería:
y sustituyendo valores 0.091603661

Ejemplo de aplicación: solucionemos ahora nuestro anterior problema de partida para el tema, esto es: ¿Qué probabilidad habría, en el caso de las universitarias que abandonan sus estudios como consecuencia de embarazo, que 10 de las 600 que ingresan en “Y” facultad, se observe que dejen de estudiar por tal motivo, dado que un nuevo estudio poblacional indique que sólo el 3.5% de la población lo hace por causa del embarazo de la estudiante?
Ahora K = 10, y como puede calcular = nP = 600(0.035) = 21; luego:
P(10;21) = 2110 e-21/10! = 0.003485345168P(10;21) = 0.35%
Observación sobre el uso de la distribución de Poisson
La distribución de Poisson puede ser vista como un caso limitante de la distribución binomial, es decir, que una distribución binomial en la que y P 0 se puede aproximar por una distribución de Poisson de valor = Np.
La distribución de Poisson se aplica a varios fenómenos discretos de la naturaleza cuando la probabilidad de ocurrencia del fenómeno es constante en el tiempo o el espacio. (esto es, aquellos fenómenos que ocurren 0, 1, 2, 3, ... veces durante un periodo definido de tiempo o en una área determinada). Ejemplos de eventos que pueden ser modelados por esta distribución serían:
El número de autos que pasan a través de un cierto punto en una ruta (suficientemente distantes de los semáforos) durante un periodo definido de tiempo.
El número de errores de ortografía que uno comete al escribir una única página. El número de llamadas telefónicas en una central telefónica por minuto. El número de animales muertos encontrados por unidad de longitud de ruta. El número de mutaciones de determinada cadena de ADN después de cierta cantidad de radiación. El número de estrellas en un determinado volumen de espacio. La distribución de receptores visuales en la retina del ojo humano.
Nota: La distribuciones Poisson son funciones probabilísticas infinitamente divisibles.
DISTRIBUCIÓN DE PROBABILIDAD PARA VARIBALES ALEATORIAS CONTINUAS
Como distribución de probabilidad, estamos siempre ante una tabla, fórmula o una gráfica que nos proporciona probabilidades o frecuencias relativas; la diferencia reside en que ahora no hablamos de la probabilidad de un punto o valor, sino de la probabilidad de un valor o punto entre dos puntos o valores cualesquiera.
Las distribuciones de variable continua más importantes son las siguientes:
Distribución uniforme Distribución normal (o de gauss)
Distribución gamma Distribución exponencial
Se denomina DISTRIBUCIÓN DE VARIABLE CONTINUA a aquella que puede tomar cualquiera de los infinitos valores existentes dentro de un intervalo. En el caso de variable continua la distribución de probabilidad es la integral de la función de densidad, por lo que tenemos entonces que:

Distribución Pareto Distribución ji-cuadrada Distribución t de Student Distribución Laplace
Distribución beta Distribución de Cauchy Distribución F de Snedecor-Fisher
LA DISTRIBUCIÓN NORMAL Y LA NORMAL UNITARIA
La distribución normal, llamada distribución de Gauss o distribución gaussiana, es la distribución de probabilidad que con más frecuencia aparece en estadística y teoría de probabilidades. Esto se debe a dos razones fundamentalmente:
Su función de densidad es simétrica y con forma de campana, lo que favorece su aplicación como modelo a gran número de variables estadísticas.
Es, además, límite de otras distribuciones y aparece relacionada con multitud de resultados ligados a la teoría de las probabilidades gracias a sus propiedades matemáticas.
La función de densidad está dada por:
Muchas variables aleatorias continuas presentan una función de densidad cuya gráfica tiene forma de campana. La importancia de la distribución normal se debe principalmente a que hay muchas variables asociadas a fenómenos naturales que siguen el modelo de la normal:
Caracteres morfológicos y antropométricos de los individuos Indicadores de laboratorio clínico: glucosa, hemoglobina, colesterol, etc. Caracteres fisiológicos como el efecto de un fármaco Caracteres sociológicos como el consumo de cierto producto por un mismo grupo de individuos Caracteres psicológicos como el cociente intelectual, etc.
ESTANDARIZACIÓN DE LA DISTRIBUCIÓN NORMAL(origen de la distribución normal)
Para una mejor comprensión de este tema, partamos de un poco de historia. Realmente, fue un trabajo de más de 200 años para descubrirla y establecer su ecuación: la ley normal
La distribución normal se conoce como la curva de Gauss o campana de Gauss, famoso matemático alemán del siglo 19. Su origen viene de la observación de un estadístico francés del siglo 18, Abraham de Moivre, que, entre otras cosas, actuaba como consultor para temas de juegos. Observó que al lanzar una moneda, la probabilidad de obtener “cara” (o “cruz”) en N tirada tenía una representación gráfica con una curva suave a medida que N se hacía grande. Ver las gráficas siguientes:

Distribución Binomial hacia la Distribución Normal
En los gráficos presentados, la altura de cada barra representa la probabilidad de que ocurra el evento (sale “cara” al lanzar una moneda) de N veces que lanzamos la moneda (hemos cogido, N=2; N=4; N=12). Si la moneda no está trucada, la probabilidad de que salga “cara” al lanzarla es del 50% (p=0,5). Este fenómeno sigue una distribución conocida como la Binomial.
De Moivre explicó que si pudiéramos encontrar una ecuación para la curva que se define, entonces se solucionaría más fácilmente el cálculo de probabilidades de que aparezca “x”, (o más “caras”) al lanzar N veces una moneda. y eso fue una de sus metas sin imaginar que esta peculiar forma de campana también se había detectado, en el siglo 17, por Galileo en el análisis de errores de medición de observaciones astronómicas; errores atribuibles a la instrumentación y a los observadores. Galileo Notó que estos errores eran simétricos y que los pequeños errores eran más frecuentes que los errores grandes. De ahí, se plantearon varias hipótesis sobre la distribución de los errores de medición. No obstante ambas observaciones y trabajos, fue solo a principio del siglo 19th que se descubrió que estos errores seguían una distribución normal.
Dos matemáticos establecieron de manera independiente su fórmula: Adrian en 1808 y Gauss en 1809 quien fue el que al final dio su nombre a la más famosa de las distribuciones estadísticas ya que numerosos fenómenos naturales se ajustan a ella y que presenta unas propiedades sumamente interesantes. Pero, ¿Qué fue lo que en realidad determinaron estos matemáticos? Saquemos nosotros nuestras propias reflexiones, a saber:
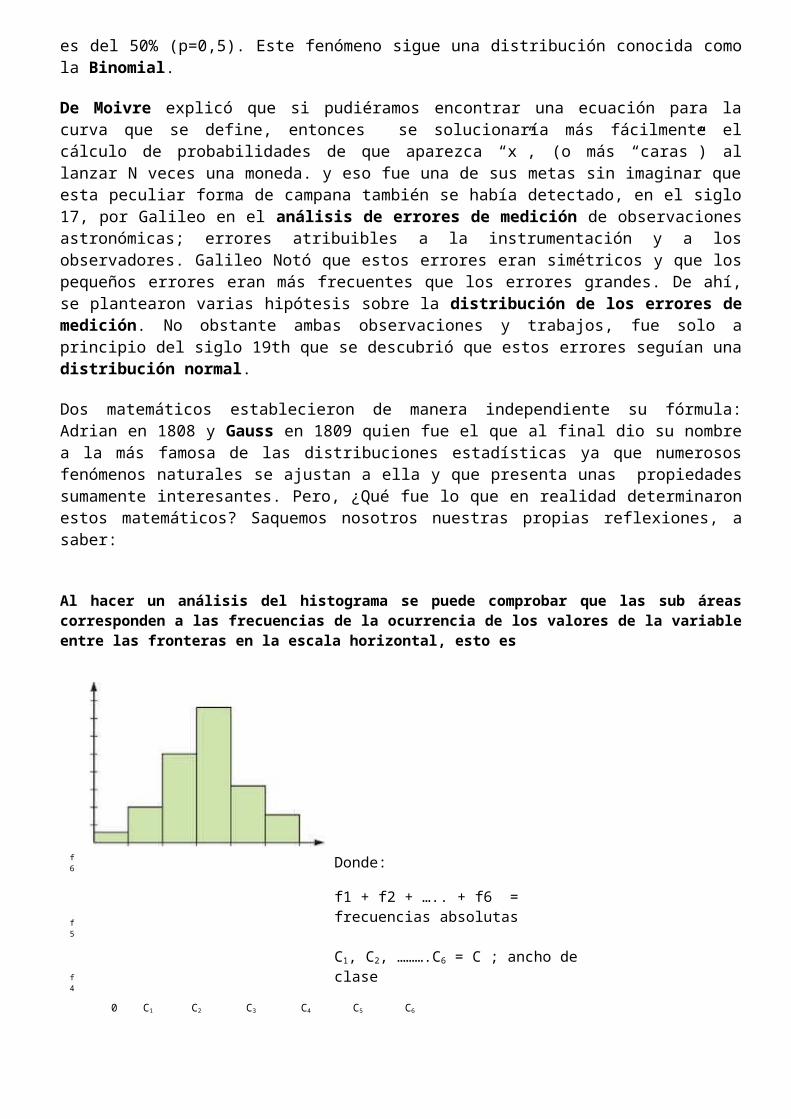
Al hacer un análisis del histograma se puede comprobar que las sub áreas corresponden a las frecuencias de la ocurrencia de los valores de la variable entre las fronteras en la escala horizontal, esto es

f6
f5
f4
f3f2
f1
Donde:
f1 + f2 + ….. + f6 = frecuencias absolutas
C1, C2, ……….C6 = C ; ancho de clase
A1, A2, ……..A6 = áreas correspondientes a cada clase
0 C1 C2 C3 C4 C5 C6
La frecuencia relativa de la ocurrencia de los valores especificados vendrá dada por la proporción del área total del histograma que cae entre esos puntos. En otras palabras las frecuencias relativas para cada clase representan una proporción del histograma, o sea: A = fi x C y como:
f1 + f2 + ….. + f6 = F, es igual al total de frecuencias, entonces la frecuencia relativa de la clase 1 es:
frc = f1 / F , que es igual a la probabilidad de ocurrencia de la clase 1, lo cual puede expresarse también por medio de las áreas, esto es:
AT = A1 + A2 + …. + A6, pero del gráfico se puede ver que A =f ixC, por lo que sustituyendo, tenemos que:
AT = f1xC + f2xC + …. + f6xC , que escrito abreviadamente usando la definición de sumatoria, nos da:
AT = C fi , y como fi = F, entonces AT = CF, por lo que finalmente, para una proporción (frecuencia relativa de área) de A, por ejemplo A1 se puede ver que:
A1 / AT sería lo mismo que Cf1 /CF y simplificado: A1 / AT = f1 / F = frc es decir
A1/AT = frc = f1/F O sea que A1/AT ; f1/F representan la frecuencia relativa de la ocurrencia de los valores que se encuentran en cada rectángulo del histograma, entre fi las verticales levantadas en Ai
Ahora bien, un análisis final se puede hacer, y es el hecho de que a medida en que se aumente el número de intervalos hacia el infinito, reduciéndose su ancho de clase, y aumentando el número de valores de la variable, el histograma tomará la forma de una curva suave, ver figuras siguientes:

y que son el tipo de gráfica que reflejan generalmente las distribuciones de variables aleatorias continuas con tendencia normal por ejemplo, la estatura de una población
Sobre estos tipos de distribución que tienen tendencia normal, podemos sacar algunas conclusiones importantes:
a) Son simétricas respecto de su media, por lo tanto la media, la mediana y la moda son iguales.
b) Si se han graficado las frecuencias relativas, el área total bajo la curva y sobre el eje horizontal, es igual a 1, por cuanto se trata de una distribución de probabilidades y porque fr = fi/N
c) Si se levantan perpendiculares a una distancia de una, dos y/o tres desviaciones típicas, en ambas direcciones, entonces el área encerrada entre estas perpendiculares será aproximadamente del 68.23, 95 y 99.7% aproximada y respectivamente en función del área total
d) La frecuencia relativa (probabilidad) de la ocurrencia de los valores entre 2 puntos cualesquiera sobre el eje horizontal es igual al área total limitada por las rectas perpendiculares levantadas en esos dos puntos , la curva y el eje horizontal. Esto es:
fr (ab)= AT ; probabilidad de que ocurran los valores comprendidos entre a y b
AT
a b
que como ya se ha dicho antes tiene como función la expresión matemática , a la cual si
damos distintos valores de “x” para unos valores de y determinados paramétricamente, podemos generar unos intervalos de confianza o probabilísticos Z, donde Z es un valor asociado a cierto nivel de confianza de que determinada cantidad de población se halla dentro de determinado intervalo
Dado lo anterior se puede afirmar que la “curva normal” queda definida entonces por los parámetros μ y σ, y de acuerdo a esta última característica tendremos una familia de distribuciones según ellas (ver figura) , en donde μ desplaza la curva hacia la derecha cuando crece (asimetría); y σ la hace más achatada cuando crece (curtosis), luego cuando μ=0 y σ=1, tenemos el caso particular de distribución llamada distribución normal unitaria o estándar.
Familia de distribuciones normales
Frecuentemente, es con la CNU que se obtienen probabilidades para cualquier variable aleatoria continua en estudio que tenga esta tendencia o comportamiento normal, y en lugar de utilizar la fórmula matemática (función de densidad) se puede recurrir a unas tablas en que se nos proporcionan las áreas bajo la curva normal para un valor definido de “z”. Antes de hacerlo y para hacerlo (calcular probabilidades usando la CNU) es importante aclarar que para convertir una variable aleatoria X en una variable aleatoria Z, es necesario estandarizar o tipificar los valores de la Variable X, lo cual se puede hacer procediendo de la siguiente manera:
,
se dice entonces, que se ha tipificado o estandarizado la variable X, si sustituimos X en Z, esto gráficamente es:
La anterior gráfica (distribución Z) tienen las siguientes características:
Se puede encontrar la probabilidad de que “z” tome un valor entre dos puntos cualesquiera del eje “z” encontrando el área limitada por las perpendiculares levantadas en estos puntos, la curva y el eje horizontal
Como ya se mencionó antes, en lugar de usar la fórmula de la distribución
podemos hacer uso de tablas para valores estandarizados,

(véase la página siguiente): en donde los interceptos de z representan las áreas bajo la distribución normal unitaria, el eje Z, y la perpendicular z=0, y la perpendicular levantada a una distancia Zi, área que a su vez representa las probabilidades de ocurrencia del intervalo de valores que caen entre z=0 y z=zi;
Veamos algunos ejemplos para una mejor comprensión:
Ej.1.- Encontrar a partir de la distribución normal unitaria, el área bajo la curva, por encima del eje “z” entre z=0 y Z = 2.21
Paso1: hacemos un esquema para visualizar el área
Paso2: buscamos en la tabla de “áreas bajo la curva normal tipificada de 0 a Z, el intercepto entre Z=2.2 y Z=0.01 (ver tabla) y se observa que da: 0.48645 lo que puede interpretarse como: “hay la probabilidad de que al tomar una “z” al azar esta se encuentre entre 0 y 2.21 es del 48.645% aproximadamente.
0 2.21
Ej.2.- encontrar el área comprendida entre Z = 1.25 y Z = 2.75
Paso1: hacemos un esquema para visualizar el área
Paso2: buscamos en la tabla de “áreas bajo la curva normal tipificada de 0 a Z, el valor de A1=Az -1.25 y A2=Az2.75 tenemos que: Paso3: AT = A1 + A2 = 0.39435 + 0.49702 AT = 0.89137 P=89.137% aproximadamente
-1.25 0 2.75
Ej.3.- aplicación de DNU a una variable aleatoria continua real
A2A1

Si las estaturas de X población indican una tendencia con comportamiento normal con μ de 1.67 y σ de 6 cms. a) ¿Qué probabilidad tendría un sujeto tomado al azar de dicha población de tener una estatura comprendida entre la media y 1.6 m?, b) ¿Qué probabilidad tendría un sujeto de que su estatura este entre los 1.55 m y la estatura promedio? Y c) ¿Qué probabilidad tendría de tener una estatura entre 1.60 y 1.70m?
Solución del literal c): puesto que los valores dados corresponden a una variable continua X, tendríamos que hacerlo por integración, pero dado que ya existe un modelo estandarizado para una variable aleatoria continua Z, en donde las probabilidades ya están determinadas para cada valor que esta asuma, entonces mejor transformamos la variable aleatoria X a Variable aleatoria Z, proceso que
denominaremos Estandarización de X, y que podemos hacer de la siguiente manera: , por lo que sustituyendo tenemos que:
Si X = 1.60 entonces Z = (1.60 – 1.67)/0.06 = 1.1666666… -1.17Si X = 1.70 entonces Z = (1.70 – 1.67)/0.06 = 0.50
Luego trasladamos los datos a un esquema de DNU procedemos a realizar el cálculo de probabilidades, esto es:
AT = Az1 + Az2 = 0.37900 + 0.19146
AT = 0.57046
Y por lo tanto P(1.6X1.7) 57.05%
-1.17 0 0.5
EJERCICIOS PARA QUE LOS HAGA EL ESTUDIANTESupóngase que la población del problema anterior son de los 287 estudiantes de bioestadística que realizaron la PBANIPs y que por alguna razón estamos interesados en seleccionar un estudiante al azar, entonces: ¿Qué probabilidad tendría este de:
a) Tener una estatura menor de 1.58 m?b) Estar entre los 1.7 y los 1.8 m?c) Ser mayor de 1.85 m o menor de 1.55 m? d) Ser mayor de 1.569 m pero menor de 1.635 m?e) Qué porcentaje tendría una estatura mayor que 1.72 m?f) Cuántos se esperaría tengan una estatura superior a los 1.65 m?g) Qué porcentaje está entre 1.75 y 1.87?h) Cuantos son menores de 1.66 m?i) Cuántos son altos
Az1 Az2
AT


















