
. Learning Bayesian networks Slides by Nir Friedman.
27
. Learning Bayesian networks Slides by Nir Friedman
-
date post
20-Dec-2015 -
Category
Documents
-
view
223 -
download
2
Transcript of . Learning Bayesian networks Slides by Nir Friedman.

.
Learning Bayesian networks
Slides by Nir Friedman
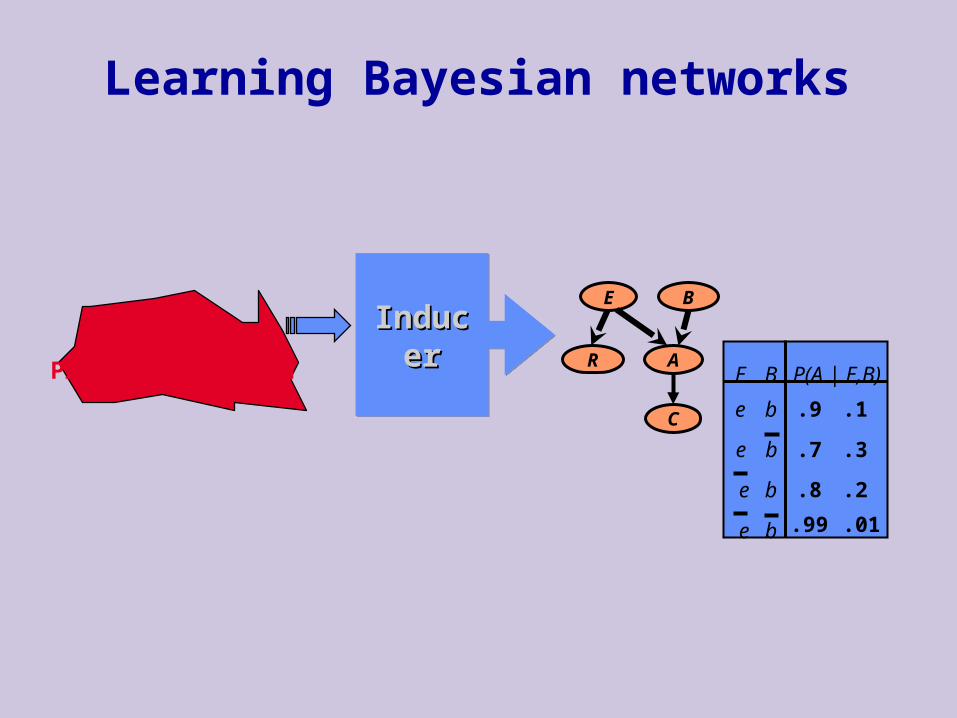
Learning Bayesian networks
InducerInducerInducerInducerData + Prior information
E
R
B
A
C .9 .1
e
b
e
.7 .3
.99 .01
.8 .2
be
b
b
e
BE P(A | E,B)

Known Structure -- Incomplete Data
InducerInducerInducerInducer
E B
A.9 .1
e
b
e
.7 .3
.99 .01
.8 .2
be
b
b
e
BE P(A | E,B)
? ?
e
b
e
? ?
? ?
? ?
be
b
b
e
BE P(A | E,B) E B
A
Network structure is specified Data contains missing values
We consider assignments to missing values
E, B, A<Y,N,N><Y,?,Y><N,N,Y><N,Y,?> . .<?,Y,Y>

Known Structure / Complete Data
Given a network structure G And choice of parametric family for P(Xi|Pai)
Learn parameters for network from complete data
Goal Construct a network that is “closest” to probability
distribution that generated the data

Maximum Likelihood Estimation in Binomial Data
Applying the MLE principle we get
(Which coincides with what one would expect)
0 0.2 0.4 0.6 0.8 1
L(
:D)
Example:(NH,NT ) = (3,2)
MLE estimate is 3/5 = 0.6
TH
H
NN
N

Learning Parameters for a Bayesian Network
E B
A
C
][][][][
]1[]1[]1[]1[
MCMAMBME
CABE
D
Training data has the form:

Learning Parameters for a Bayesian Network
E B
A
C
Since we assume i.i.d. samples,likelihood function is
m
mCmAmBmEPDL ):][],[],[],[():(
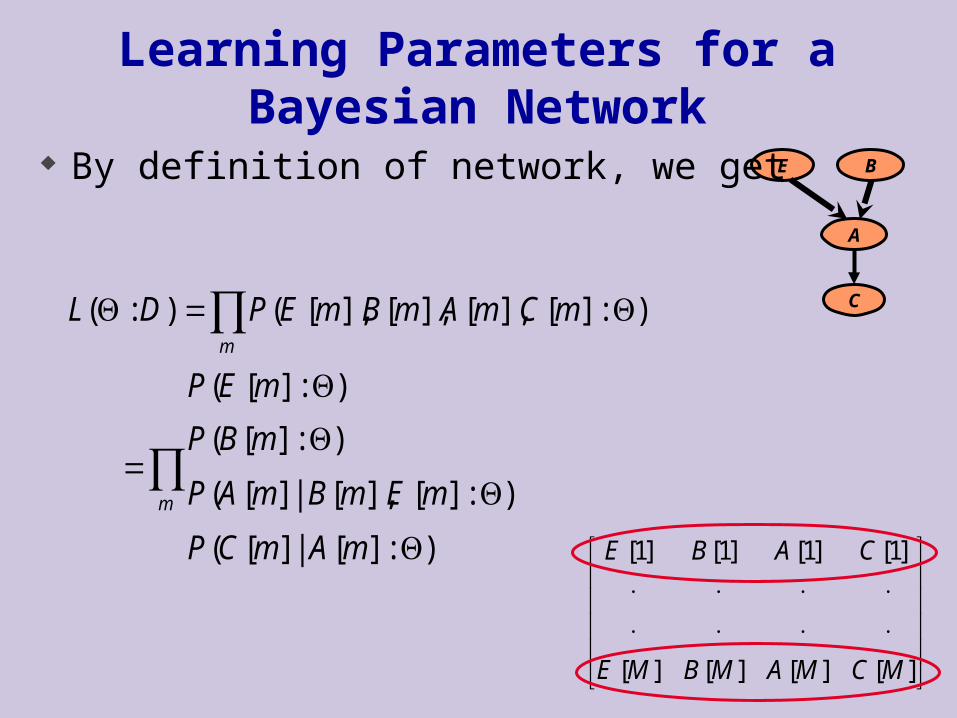
Learning Parameters for a Bayesian Network
E B
A
C
By definition of network, we get
m
m
mAmCP
mEmBmAP
mBP
mEP
mCmAmBmEPDL
):][|][(
):][],[|][(
):][(
):][(
):][],[],[],[():(
][][][][
]1[]1[]1[]1[
MCMAMBME
CABE

Learning Parameters for a Bayesian Network
E B
A
C
Rewriting terms, we get
m
m
m
m
m
mAmCP
mEmBmAP
mBP
mEP
mCmAmBmEPDL
):][|][(
):][],[|][(
):][(
):][(
):][],[],[],[():(
][][][][
]1[]1[]1[]1[
MCMAMBME
CABE

General Bayesian Networks
Generalizing for any Bayesian network:
The likelihood decomposes according to the structure of the network.
iii
i miii
m iiii
mn
DL
mPamxP
mPamxP
mxmxPDL
):(
):][|][(
):][|][(
):][,],[():( 1 i.i.d. samples
Network factorization

General Bayesian Networks (Cont.)
Complete Data Decomposition
Independent Estimation Problems
If the parameters for each family are not related, then they can be estimated independently of each other.
(Not true in Genetic Linkage analysis).

Learning Parameters: Summary
For multinomial we collect sufficient statistics which are simply the counts N (xi,pai)
Parameter estimation
Bayesian methods also require choice of priors Both MLE and Bayesian are asymptotically
equivalent and consistent.
)()(),(),(~
|ii
iiiipax paNpa
paxNpaxii
)(),(ˆ
|i
iipax paN
paxNii
MLE Bayesian (Dirichlet Prior)

Known Structure -- Incomplete Data
InducerInducerInducerInducer
E B
A.9 .1
e
b
e
.7 .3
.99 .01
.8 .2
be
b
b
e
BE P(A | E,B)
? ?
e
b
e
? ?
? ?
? ?
be
b
b
e
BE P(A | E,B) E B
A
Network structure is specified Data contains missing values
We consider assignments to missing values
E, B, A<Y,N,N><Y,?,Y><N,N,Y><N,Y,?> . .<?,Y,Y>

Learning Parameters from Incomplete Data
Incomplete data: Posterior distributions can become interdependent Consequence:
ML parameters can not be computed separately for each multinomial
Posterior is not a product of independent posteriors
X
Y|X=Hm
X[m]
Y[m]
Y|X=T

Learning Parameters from Incomplete Data (cont.).
In the presence of incomplete data, the likelihood can have multiple global maxima
Example: We can rename the values of hidden variable
H If H has two values, likelihood has two global
maxima
Similarly, local maxima are also replicated Many hidden variables a serious problem
H Y

Gradient Ascent:Follow gradient of likelihood w.r.t. to parameters
L(
|D)
MLE from Incomplete Data Finding MLE parameters: nonlinear optimization problem

L(
|D)
Expectation Maximization (EM):Use “current point” to construct alternative function (which is “nice”) Guaranty: maximum of new function is better scoring than the current point
MLE from Incomplete Data Finding MLE parameters: nonlinear optimization problem

MLE from Incomplete Data
Both Ideas:Find local maxima only.Require multiple restarts to find approximation to the global maximum.

Gradient Ascent
Main result
Theorem GA:
)],[|,(1)|(log
,,
mopaxPDP
iimpaxpax iiii
Requires computation: P(xi,pai|o[m],) for all i, m
Inference replaces taking derivatives.

Gradient Ascent (cont)
m pax ii
moPmoP ,
)|][()|][(
1
m paxpax iiii
moPDP
,,
)|][(log)|(log
ii pax
moP
,
)|][(
How do we compute ?
Proof:

=1
Gradient Ascent (cont)
Since:
ii pax
ii opaxP
','
),,','(
ii pax ','
iindi
ndii
d paxPopaPopaxoP
),'|'()|,'(),,','|(
ii iipax pax
ndiii
ndii
d opaPpaxPopaxoP
, ','
)|,(),|(),,,|(
ii iiiipax pax
ii
pax
opaxPoP
, ','','
)|,,()|(
ipaix
opaxPoP ii,
)|,,()|(

Gradient Ascent (cont)
Putting all together we get
m paxpax iiii
moP
moP
DP
,,
)|][(
)|][(
1)|(log
m pax
ii
ii
mopaxP
moP ,
)|][,,(
)|][(
1
m pax
ii
ii
mopaxP
,
)],[|,(
)],[|,(1)|(log
,,
mopaxPDP
iimpaxpax iiii

Expectation Maximization (EM) A general purpose method for learning from incomplete dataIntuition: If we had access to counts, then we can estimate
parameters However, missing values do not allow to perform counts “Complete” counts using current parameter assignment

Expectation Maximization (EM)
1.30.41.71.6
X Z N (X,Y )X Y #H
THHT
Y
??HTT
TT?TH
HTHT
HHTT
P(Y=H|X=T, Z=T, ) = 0.4
Expected CountsP(Y=H|X=H,Z=T,) = 0.3
Data
Current model
These numbers are placed for illustration; they have not been computed.
X
YZ

EM (cont.)
TrainingData
X1 X2 X3
H
Y1 Y2 Y3
Initial network (G,0)
Expected CountsN(X1)N(X2)N(X3)N(H, X1, X1, X3)N(Y1, H)N(Y2, H)N(Y3, H)
Computation
(E-Step)
Reparameterize
X1 X2 X3
H
Y1 Y2 Y3
Updated network (G,1)
(M-Step)
Reiterate

Expectation Maximization (EM)
In practice, EM converges rather quickly at start but converges slowly near the (possibly-local) maximum.
Hence, often EM is used few iterations and then Gradient Ascent steps are applied.

Final Homework
Question 1: Develop an algorithm that given a pedigree input, provides the most probably haplotype of each individual in the pedigree. Use the Bayesian network model of superlink to formulate the problem exactly as a query. Specify the algorithm at length discussing as many details as you can. Analyze its efficiency. Devote time to illuminating notation and presentation.
Question 2: Specialize the formula given in Theorem GA for in genetic linkage analysis. In particular, assume exactly 3 loci: Marker 1, Disease 2, Marker 3, with being the recombination between loci 2 and 1 and 0.1- being the recombination between loci 3 and 2.
1. Specify the formula for a pedigree with two parents and two children.
2. Extend the formula for arbitrary pedigrees.
Note that is the same in many local probability tables.


















