
Functional Dependencies and Normalization for Relational Databases
date post
21-Dec-2015Category
view
228download
1
10.1
CS 728 Advanced Database Systems
Chapter 10Functional Dependencies & Normalization

10.2
Design Guidelines for Relation SchemasDesign Guidelines for Relation Schemas
1. Attributes should have clear meanings (semantics) and related attributes are grouped into single entities.
2. Avoid update anomalies by reducing redundant data.
3. Reduce the NULL values.
4. When relations are joined no spurious tuples will be generated.

10.3
Semantics of Relation AttributesSemantics of Relation Attributes
Guideline 1Guideline 1:: Design a relation schema so that it is easy to Design a relation schema so that it is easy to
explain its meaning. explain its meaning. Do not combineDo not combine attributes attributes from multiple entity types and relationship types from multiple entity types and relationship types into a single relation.into a single relation.
Design I:Design I:
STUDENT(STUDENT(STNOSTNO, Name, Address, ANO), Name, Address, ANO)ADVISOR(ADVISOR(ANOANO, Name, Address, Dept), Name, Address, Dept)
Design II:Design II:
Student-Advisor(Student-Advisor(STNOSTNO, Name, Address, ANO, , Name, Address, ANO, A-name, A-address, Dept)A-name, A-address, Dept)
Design I is better when compared with Design II.Design I is better when compared with Design II.

10.4
Update AnomaliesUpdate Anomalies
Insertion anomaliesInsertion anomalies: : In design II, if we add a new student to
Student-Advisor, we have to add data related to that student’s advisor. This information should be consistent with all other occurrences of that advisor. Note that in design II all data related to a particular advisor is repeated a number of times which equals to the number of students supervised by that advisor. In design I, only advisor number is repeated.
It is difficult to add a new advisor who have no students yet to the database. This is because we have to assign nulls to STNO and STNO is the primary key for Student-Advisor.

10.5
Update AnomaliesUpdate Anomalies
Deletion AnomaliesDeletion Anomalies If we delete the last student associated with a
particular advisor, then that advisor cannot exist in the database in design II any more.
Modification AnomaliesModification Anomalies If an advisor changes his/her address, say,
then we have to modify his/her address in all tuples.
If we miss some tuples, then we will have several addresses for the same advisor.

10.6
Update AnomaliesUpdate Anomalies
Guideline 2Guideline 2: : Design the base relation schemas so that no Design the base relation schemas so that no
insertion, deletion, or modification anomalies insertion, deletion, or modification anomalies occur. occur.
If any anomalies are present, note them clearly so If any anomalies are present, note them clearly so that the programs that update the database will that the programs that update the database will operate correctly.operate correctly.

10.7
NULL values in TuplesNULL values in Tuples
Guideline 3Guideline 3: : Avoid placing attributes in a Avoid placing attributes in a base relationbase relation whose whose
values may be null. values may be null.
If nulls are unavoidable, make sure that they If nulls are unavoidable, make sure that they apply in exceptional cases only and do not apply apply in exceptional cases only and do not apply to majority of tuples in the relation.to majority of tuples in the relation.

10.8
NULL values in TuplesNULL values in Tuples
Problems with Nulls:Problems with Nulls: Waste storage space.
Have multiple interpretations (not-applicable, not-known,…).
Create ambiguities with aggregate functions (count, avg, …)
Create ambiguities with joins.

10.9
NULL values in TuplesNULL values in Tuples
Example:Example: If only 10% of employees have phones, then
Employee(SSN, Name,…., Office-phone) is a poor design, because 90% of the last column values will be nulls;
But:But: Employee(SSN, Name, …) Phone(SSN, Office-phone)
is a better design.

10.10
Spurious TuplesTuples
Guideline 4Guideline 4::
Design relation schemas so that they can be Design relation schemas so that they can be joined with equality conditions on attributes that joined with equality conditions on attributes that are either primary keys or foreign keys in a way are either primary keys or foreign keys in a way which guarantees that which guarantees that no spurious no spurious tuples are tuples are generated.generated.
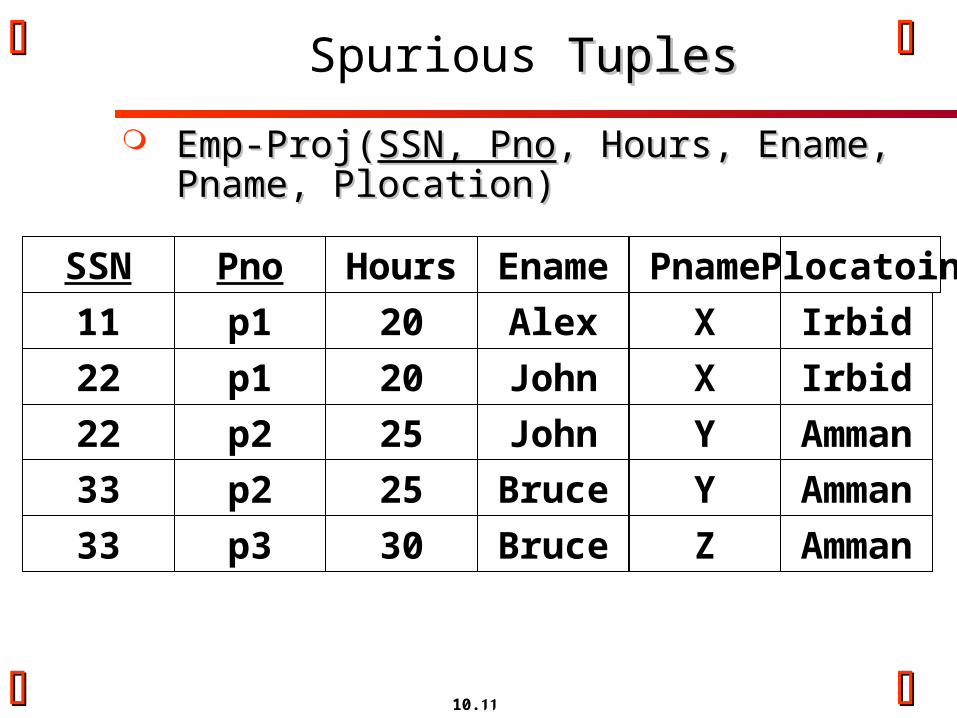
10.11
Spurious TuplesTuples
Emp-Proj(Emp-Proj(SSN, PnoSSN, Pno, Hours, Ename, Pname, , Hours, Ename, Pname, Plocation)Plocation)
SSN Pno
22
22
11 p1
p1
p2
p233
20
20
25
25
Hours
Alex
John
John
Bruce
Ename Pname
X
Y
Z
Y
Plocatoin
33 p3 30 Bruce
X
Amman
Amman
Amman
Irbid
Irbid

10.12
Spurious TuplesTuples
Emp-locs(Emp-locs(Ename, PlocationEname, Plocation)) Emp-Proj1(Emp-Proj1(SSN, PnoSSN, Pno, hours, Pname, Plocation), hours, Pname, Plocation)
Ename Plocation
Alex Irbid
John Irbid
AmmanJohn
Bruce Amman

10.13
SSN Pno
22
22
11 p1
p1
p2
p233
20
20
25
25
Hours Pname
X
Y
Z
Y
Plocatoin
33 p3 30
X
Amman
Amman
Amman
Irbid
Irbid
Spurious TuplesTuples
Emp-Proj(Emp-Proj(SSN, PnoSSN, Pno, Hours, Pname, Plocation), Hours, Pname, Plocation)

10.14
Spurious TuplesTuples
Result Result Emp-Locs Emp-Locs Emp-proj1 Emp-proj1 Then: Then: Result(Ename, Plocation, SSN, Pno, Result(Ename, Plocation, SSN, Pno,
Hours, Pname)Hours, Pname)
Ename Plocation SSN Pno Hours Pname
Alex Irbid 11 p1 20 X
Alex Irbid
11IrbidJohn
22p1 20 X
20p1 X
John Irbid 22 p1 20 X

10.15
Spurious TuplesTuples
If we combine If we combine Emp-LocsEmp-Locs and and Emp_Proj1Emp_Proj1 on on Plocation attributePlocation attribute, we will get , we will get spurious tuplesspurious tuples as as you have noticed in the previous slide. This is you have noticed in the previous slide. This is because because PlocationPlocation is the attribute which combines is the attribute which combines the two relations and it is the two relations and it is neitherneither a a primary keyprimary key nornor a a foreign keyforeign key in either Emp-Locs or Emp- in either Emp-Locs or Emp-Proj1Proj1

10.16
Bad Tables (1)Bad Tables (1)
Alternative designs for a product database:Alternative designs for a product database:
(1) (1) Products(Prod_no, Prod_name, Price,
Manu_id) Manufacturers (Manu_id, Manu_name,
Address)
(2) (2) Prod_Manu (Prod_no, Prod_name, Price,
Manu_id, Manu_name, Address)

10.17
Bad Tables (2)Bad Tables (2)
Problems with the second design: Problems with the second design:
RedundancyRedundancy --- the name and address of each --- the name and address of each manufacturer will be repeated once for each manufacturer will be repeated once for each product made by the manufacturer. product made by the manufacturer. more storage space needed potential inconsistency (update anomalies)

10.18
Bad Tables (3)Bad Tables (3)
Insertion anomaliesInsertion anomalies --- a manufacturer's name and --- a manufacturer's name and address cannot be recorded in the database if it address cannot be recorded in the database if it does not make at least one product (because does not make at least one product (because Prod_noProd_no is part of the primary key). is part of the primary key).
Deletion anomaliesDeletion anomalies --- If we delete all products --- If we delete all products made by a manufacturer, we will unintentionally made by a manufacturer, we will unintentionally lose track of the manufacturer's name and lose track of the manufacturer's name and address.address.
The first design does not have similar problems.The first design does not have similar problems. The challenge is to identify bad relations and The challenge is to identify bad relations and
convert them into good relations. convert them into good relations.

10.19
Functional DependenciesFunctional Dependencies
RR: Relation schema.: Relation schema.
r(R)r(R): Relation instance: Relation instance
A1, A2, …, AnA1, A2, …, An: Attributes which belong to : Attributes which belong to universal relation.universal relation.
X, YX, Y: Sets of attributes.: Sets of attributes.

10.20
Functional DependenciesFunctional Dependencies
A A functional dependencyfunctional dependency ( (X X Y Y), between ), between XX and and YY specifies a constraint on the possible tuples specifies a constraint on the possible tuples that can form a relation instance that can form a relation instance rr of of RR..
The constraint states that for any two tuples The constraint states that for any two tuples t1t1 and and t2t2 in in rr such that such that t1[X] = t2[X]t1[X] = t2[X], then , then t1[Y] = t1[Y] = t2[Y]t2[Y]
This means that the This means that the YY component of a tuple in component of a tuple in rr depends ondepends on (or determined by) the values of the (or determined by) the values of the XX component of that tuple in component of that tuple in rr..
Or the values of the Or the values of the XX component of a tuple in r component of a tuple in r uniquely or functionallyuniquely or functionally determines the values of determines the values of YY component. component.

10.21
Functional DependenciesFunctional Dependencies
X is said to X is said to functionally determinefunctionally determine Y (or Y is Y (or Y is functionally dependentfunctionally dependent on X) if for every on X) if for every legal legal relation instance r(R), for any two tuples t1 and t2 relation instance r(R), for any two tuples t1 and t2 in r(R), we have in r(R), we have t1[X] = t2[X] , then t1[Y] = t2[Y]
X X R denotes that X is a subset of the attributes R denotes that X is a subset of the attributes of Rof R
X X Y denotes that X functionally determines Y. Y denotes that X functionally determines Y.

10.22
Functional DependenciesFunctional Dependencies
Note that:Note that: if X is a candidate key then X Y is correct
for any subset of attributes of R. if X Y, this does not say whether Y X is
correct or not. Student(Student(SSNSSN, STNO, Name, Major), STNO, Name, Major)
SSN Name t1(91910, 980090012, Ahmed, …..) t2(91910, 980090012, Ahmed, …..)
STNO Major t10((980090012,…, Math) t12(980090012, …, Math)
SSN {SSN, Name, STNO, Major}

10.23
Manager DeptManage1 1
Functional DependenciesFunctional Dependencies
Manager(Manager(SSNSSN, Name, …. , Name, …. DeptDept)) SSN {Name, Dept} (correct)
SSN uniquely determines the Name and Dept
Dept SSN (correct) Dept uniquely determines the SSN
Name SSN (incorrect)

10.24
Functional DependenciesFunctional Dependencies
FD is a property of the meaning or semantics of FD is a property of the meaning or semantics of attributesattributes
FD is specified as a constraint on R, all FD is specified as a constraint on R, all extensions of R (i.e. r(R)) should specify that extensions of R (i.e. r(R)) should specify that constraint (constraint (legal extensionslegal extensions); otherwise r(R) are ); otherwise r(R) are called illegal extensionscalled illegal extensions
Note that we cannot infer FDs from r(R)Note that we cannot infer FDs from r(R)

10.25
Student(SSN, STNO, Name, Major)FD 1
FD 2
Diagrammatic Representation of FDs
SSN SSN STNO, NAME, MAJOR STNO, NAME, MAJOR
STNO STNO SSN, NAME, MAJOR SSN, NAME, MAJOR

10.26
Inference Rules for Functional Inference Rules for Functional DependenciesDependencies
Let Let F: set of functional dependencies defined on R F+ (Closure of F): is the set of all functional
dependencies that can be defined on R The closure of F is the set of all FDs that are
logically implied by F The closure of F is denoted by FThe closure of F is denoted by F++
F+ = { X Y | F ╞ X Y} A BIG FA BIG F++ may be derived from a small F may be derived from a small F
For R(A, B, C) and F = {A B, B C} F+ = {A B, B C, A C, A A, B
B,C C, AB AB, AB A, AB B, ... }

10.27
Inference Rules for Functional Inference Rules for Functional DependenciesDependencies
Emp-Dept(Emp-Dept(SSNSSN, Ename, Bdate, Address, , Ename, Bdate, Address, Dnumber, Dname, MGR-SSN)Dnumber, Dname, MGR-SSN)F = {
SSN {Ename,Bdate,Address,Dnumber}, Dnumber {Dname, MGR-SSN}}
We can infer the following FDs:We can infer the following FDs: SSN SSN (Reflexive) SSN Ename (Decomposition) SSN {Dname, MGR-SSN} (Transitive)
We usually write We usually write F F ╞╞ X X Y Y to denote that the to denote that the FD FD X X YY is inferred from is inferred from FF
X, Y are subsets of attributes X, Y are subsets of attributes

10.28
Functional DependencyFunctional Dependency
Several equivalent definitions:Several equivalent definitions: X Y in R iff for any t1, t2 in r(R), if t1
and t2 have the same X-value, then t1 and t2 also have the same Y-value
X Y in R iff there exist no t1, t2 in r(R) such that t1 and t2 have the same X-value but different Y-values
X Y in R iff for each X-value, there corresponds to a unique Y-value.

10.29
Functional DependencyFunctional Dependency
Question: if all X-values are different in all Question: if all X-values are different in all possible r(R), does X possible r(R), does X Y in R? Y in R?
Theorem 1Theorem 1:: If X is a superkey of R and Y is any subset of
R, then X Y in R
Note that X Note that X Y in R is a property that must be Y in R is a property that must be true for all possible legal r(R), not just for the true for all possible legal r(R), not just for the present r(R)present r(R)

10.30
Functional DependencyFunctional Dependency
Example: which is true? Example: which is true? A B C DA B C D A A B B a1 b1 c1 d1 a1 b1 c1 d1 A A C C a1 b2 c1 d2 C a1 b2 c1 d2 C A A a2 b2 c2 d2 A a2 b2 c2 d2 A D D a2 b3 c2 d3 B a2 b3 c2 d3 B D D a3 b3 c2 d4 a3 b3 c2 d4 AB AB D D
AB AB C C AB AB CD CD

10.31
Identify Functional DependencyIdentify Functional Dependency
FD created by assertionsFD created by assertions. . Employees(SSN, Name, Years_of_emp,
Salary, Bonus)
Assertion:Assertion: Employees hired the same year have the same
salary
This assertion impliesThis assertion implies: : Years_of_emp Salary

10.32
Inference RulesInference Rules
IR1: Reflexive Rule (IR1: Reflexive Rule ( منعكسمنعكس)) Y X, then X Y e.g.
SSN SSN {P#, S#, Qty} Qty
IR2: Augmentation Rule IR2: Augmentation Rule زيادةزيادة)))) { X Y} ╞ XZ YZ e.g.: F = {SSN Address}
F ╞ {SSN, Name} {Address, Name}

10.33
Inference RulesInference Rules
IR3: Transitive rule: (IR3: Transitive rule: (متعّد�يمتعّد�ي)) {X Y, Y Z} ╞ X Z e.g. F = {SSN Dnumber, Dnumber Dname}
F ╞ SSN Dname
IR4: Decomposition Rule: (IR4: Decomposition Rule: (حّل�ل� �حّل�لالت ((الت X {Y, Z} ╞ X Y and ╞ X Z e.g. F = {SSN {Ename,BDate,Address, Dnumber}}
F ╞ SSN Ename ╞ SSN Bdate ╞ SSN Address ╞ SSN Dnumber

10.34
Inference RulesInference Rules
IR5: Union (Additive) Rule:IR5: Union (Additive) Rule: {X Y, X Z} ╞ X {Y, Z} e.g.
F = {SSN Ename, SSN Bdate} F ╞ SSN {Ename, Bdate}
IR6: Pseudo-transitive Rule: IR6: Pseudo-transitive Rule: {X Y, WY Z} ╞ WX Z e.g.
F = { SSN STNO, {Major, STNO} Name} F ╞ {Major, SSN} Name

10.35
Closure of AttributesClosure of Attributes
How to determine if F How to determine if F ╞╞ X X Y is true? Y is true?
Method 1:Method 1: Compute F+
If X Y F+, then F ╞ X Y
Problem: Problem: Computing F+ could be very expensive!

10.36
Closure of AttributesClosure of Attributes
Method 2:Method 2:
Compute X+ : the closure of X under F
X+ denotes the set of attributes that are functionally determined by X under F.
X+ = { Y | X Y F+ }
Theorem: Theorem: X Y F+ if and only if Y X+

10.37
Algorithm for Computing XAlgorithm for Computing X++
Input: Input: a set of FDs F, a set of attributes X in R
Output:Output: X+
BeginBegin X+ = X; Repeat
oldX+ = X+ for each FD Y Z in F do
– if Y X+ then X+ = X+ Z; until (X+ = oldX+ )
endend

10.38
Algorithm for Computing XAlgorithm for Computing X++
Example: Example: R(A, B, C, G, H, I) = ABCGHI X = AG F = {A B, CG HI, B H, A C }
Compute XCompute X++ = (AG) = (AG)++
Initialization: Initialization: X+ = AG;

10.39
Algorithm for Computing XAlgorithm for Computing X++
11stst iteration: iteration: consider A B:
since A is a subset of X+, X+ = ABG; consider CG HI:
since CG is not a subset of X+, X+ = ABG;
consider B H: since B is a subset of X+, X+ = ABGH;
consider A C: since A is a subset of X+, X+ = ABCGH;
XX+ + is changed from is changed from AGAG to to ABCGHABCGH

10.40
Algorithm for Computing XAlgorithm for Computing X++
22ndnd iteration: iteration: consider A B:
since A is a subset of X+, X+ = ABCGH; consider CG HI:
since CG is a subset of X+, X+ = ABCGHI; consider B H:
since B is a subset of X+, X+ = ABCGHI; consider A C:
since A is a subset of X+, X+ = ABCGHI; XX++ is changed from is changed from ABCGHABCGH to to ABCGHIABCGHI

10.41
Algorithm for Computing XAlgorithm for Computing X++
3rd iteration:3rd iteration: consider each FD in F again, but there is no
change to X+, exit
Result:Result: (AG)+ = ABCGHI.
The performance of the algorithm is sensitive to The performance of the algorithm is sensitive to
the order of FDs in Fthe order of FDs in F

10.42
Algorithm for Computing XAlgorithm for Computing X++
Theorem:Theorem: Given R(A1, ..., An) and a set of FDs F in R,
K R is a
superkey if K+ = {A1, ..., An};
candidate key if K is a superkey and for any proper subset X of K, X+ {A1, ..., An}.

10.43
Algorithm for Computing XAlgorithm for Computing X++
Continue the above example: Continue the above example: AG is a superkey of R since
(AG)+ = ABCGHI.
Since A+ = ABCH, G+ = G, neither A nor G is a superkey.
Hence, AG is a candidate key

10.44
Normal Forms Based on Primary KeysNormal Forms Based on Primary Keys
Normalization of data:Normalization of data: is a process during which unsatisfactory
relation schemas are decomposed by breaking up their attributes into smaller relation schemas that posses desirable properties
We normalize data for several reasons one of them is to avoid update anomalies
We haveWe have First Normal Form (1NF) Second Normal Form (2NF) Third Normal Form (3NF) Boyce-Codd Normal Form (BCNF) (a
stronger definition of 3NF) All the above normal forms are based on
functional dependencies.

10.45
Normal Forms Based on Primary KeysNormal Forms Based on Primary Keys
Forth Normal Form (4NF) Based on multivalued dependencies.
Fifth Normal Form (5NF) based on join dependencies.
Aside:Aside: Student-Adv(STNO, StName, Major,…, Ano,
Aname, …) Has several problems
Student(STNO, StName, Major, …, Ano) Advisor(Ano, Aname, ….)
Pay the price of expensive joins

10.46
Basic DefinitionsBasic Definitions
R = {A1, …, An)R = {A1, …, An) Superkey:Superkey: is set of attributes S is set of attributes S R and t1[S] R and t1[S]
t2[S] t2[S] i =1, ..., n. S may contain redundant i =1, ..., n. S may contain redundant attributes.attributes.
Key (K):Key (K): is a superkey with no redundant is a superkey with no redundant attributes, i.e. removal of any attribute from K attributes, i.e. removal of any attribute from K will no longer make it a superkey.will no longer make it a superkey.
Candidate Key:Candidate Key: if a relation has more than one if a relation has more than one key, each is called a candidate key. One of these key, each is called a candidate key. One of these keys is arbitrarily chosen as a keys is arbitrarily chosen as a primary keyprimary key..
Prime Attribute:Prime Attribute: is an attribute which is a member is an attribute which is a member of any key (primary or candidate); other attributes of any key (primary or candidate); other attributes are called are called nonprimenonprime attributes. attributes.

10.47
Basic DefinitionsBasic Definitions
Student(Student(SSNSSN, , STNOSTNO, Name, Address, Salary), Name, Address, Salary) Superkeys
{SSN,Name}/{SSN,STNO,Name,Address,Salary} Candidate keys
{SSN, STNO}; Primary Key
SSN Prime Attribute:
SSN and STNO Nonprime Attributes:
{Name, Address, Salary}

10.48
1NF (First Normal Form)1NF (First Normal Form)
A relation schema R is in 1NF if every attribute A relation schema R is in 1NF if every attribute of R takes only single and atomic values.of R takes only single and atomic values.
Domains of attributes must include only Domains of attributes must include only atomic atomic valuesvalues and that the value of any attribute in a and that the value of any attribute in a tuple must be a tuple must be a single valuesingle value from the domain of from the domain of that attribute. that attribute.
In other words, In other words, multivaluedmultivalued and and composite composite attributesattributes are disallowed. are disallowed.

10.49
1NF (First Normal Form)1NF (First Normal Form)
Student(Student(STNOSTNO, StName, {Course(CNO, Ctitle)}, StName, {Course(CNO, Ctitle)}
The set braces The set braces {}{} identify the attribute Course as identify the attribute Course as multivaluedmultivalued
The set braces The set braces ()() identify the attribute Course as a identify the attribute Course as a compositecomposite attribute attribute
Because of the last attribute (Course), the Student Because of the last attribute (Course), the Student relation schema is relation schema is notnot in 1NF. in 1NF.

10.50
1NF (First Normal Form)1NF (First Normal Form)
Student(Student(STNOSTNO, StName, {Course(CNO, Ctitle)}, StName, {Course(CNO, Ctitle)}
To normalize it to 1NF: To normalize it to 1NF: Student(STNO, StName, CNO, Ctitle)
this is not a good representation because it has many disadvantages. Replication of Course information and student information. Combining attributes which belong to two separate entities (namely student and course) into a single relation schema.

10.51
1NF (First Normal Form)1NF (First Normal Form)
Student(Student(STNOSTNO, StName, {Course(CNO, Ctitle)}, StName, {Course(CNO, Ctitle)}
Student(STNO, StName, CNO) Course(CNO, Ctitle)
this design suffers from drawback that student information has to be repeated in the student relations several times (in fact a number of times that is equal to the number of courses taken by that student).

10.52
1NF (First Normal Form)1NF (First Normal Form)
Student(Student(STNOSTNO, StName, {Course(CNO, Ctitle)} , StName, {Course(CNO, Ctitle)}
Student(STNO, StName) Course(CNO, Ctitle) Study(STNO, CNO)
This is the best representation because we have reduced the duplication.

10.53
Second Normal Form (2NF)Second Normal Form (2NF)
Prime attributePrime attribute --- an attribute in any candidate --- an attribute in any candidate key.key.
Y is Y is fullyfully functionally dependent on X if functionally dependent on X if X X Y Y and and no properno proper subset of X functionally determines subset of X functionally determines YY
FD X FD X Y is a Y is a fullyfully functional dependency if functional dependency if removalremoval of any attribute of any attribute AA from from XX means that the means that the dependency does not hold any more. In other dependency does not hold any more. In other words (X - {A}) does not determine Ywords (X - {A}) does not determine Y
A FD X A FD X Y is a Y is a partialpartial FD if exist some FD if exist some attribute attribute AA which belongs to which belongs to XX and (X - {A}) and (X - {A}) Y still holdsY still holds

10.54
Second Normal Form (2NF)Second Normal Form (2NF)
General Definition of 2NFGeneral Definition of 2NF A relation schema R is in 2NF if every
nonprime attribute A in R is not partially dependent on any key of R
(i.e. if every nonprime attribute is fully functionally dependent on every key of R)

10.55
Second Normal Form (2NF)Second Normal Form (2NF)
Emp-Proj(Emp-Proj(SSN, PnumberSSN, Pnumber, Hours, Ename, Pname, , Hours, Ename, Pname, Plocation)Plocation) FD1: {SSN, Pnumber} Hours (FD) FD2: SSN Ename (PD) FD3: Pnumber {Pname, Plocation} (PD) Because of FD2 and FD3 Emp-Proj is not in
2NF 2NF Normalization2NF Normalization
Emp(SSN, Ename) Proj(Pnumber, Pname, Plocation) Work(SSN, Pnumber, Hours)

10.56
Second Normal Form (2NF)Second Normal Form (2NF)
Consider Consider Bank-Loans (Bank_name, Assets,
Headquarter, Loan_no, Customer_name, Amount),
FD1: Bank_name {Assets, Headquarter} FD2: {Bank_name, Loan_no}
{Customer_name, Amount} Because if FD1, Bank-Loans is not in 2NF.
2NF Normalization2NF Normalization Banks(Bank_name, Assets, Headquarter) Loans(Bank_name, Loan_no,
Customer_name, Amount)

10.57
Second Normal Form (2NF)Second Normal Form (2NF)
2NF is not good enough:2NF is not good enough: A relation schema in 2NF can still have serious
redundancy problem as well as insertion and deletion anomalies.
Consider Consider PartsParts((Part_noPart_no, Name, Location, Unit_price, , Name, Location, Unit_price, Manu_id, Manu_name, Manu_AddressManu_id, Manu_name, Manu_Address)) It is obvious that Parts is in 2NF
Redundancy and various anomalies are introduced by Manu_id {Manu_name, Manu_Address}

10.58
Second Normal Form (2NF)Second Normal Form (2NF)
ConsiderConsider EMP_DEPT(SSN, EName, BDate, Address,
DNo, DName, DMGRSSN)
It is obvious that EMP_DEPT is in 2NF
Redundancy and various anomalies are introduced by DNo {DName, DMGRSNN}

10.59
Third Normal Form (3NF)Third Normal Form (3NF)
Transitive DependencyTransitive Dependency a FD X Y in R is transitive if exist some set
of attributes Z that is not a subset of any key of R and both X Z and Z Y hold.
A relation schema R is in A relation schema R is in 3NF3NF if it is in if it is in 2NF2NF and and no nonprimeno nonprime attribute A of R is attribute A of R is transitively transitively dependentdependent on a key of R on a key of R

10.60
Third Normal Form (3NF)Third Normal Form (3NF)
A relation schema R is in 3NF if for every FD A relation schema R is in 3NF if for every FD X X A A, where , where AA is a single attribute, is a single attribute, at least oneat least one of of the following is true: the following is true:
(a) A X (Trivial dependency - Reflexive);
(b) A is a prime;
(c) X is a superkey

10.61
Third Normal Form (3NF)Third Normal Form (3NF)
R is R is notnot in 3NF if a in 3NF if a non-primenon-prime non-trivially non-trivially depends on a depends on a non-superkeynon-superkey. .
If R in 3NF, it should not have a If R in 3NF, it should not have a nonkeynonkey attribute attribute functionally determined by another functionally determined by another nonkey nonkey attributeattribute (or by a set of nonkey attributes) (or by a set of nonkey attributes)

10.62
Third Normal Form (3NF)Third Normal Form (3NF)
General Definition of 3NF:General Definition of 3NF: A relation schema R is in 3NF if, whenever a
nontrivial functional dependency X A holds, either
(a) X is a superkey of R, or
(b) A is a prime attribute of R

10.63
Third Normal Form (3NF)Third Normal Form (3NF)
Emp-Dept(Emp-Dept(SSN,SSN, Ename, Bdate, Address, Dnumber, Ename, Bdate, Address, Dnumber, Dname, DMGR-SSN)Dname, DMGR-SSN) FD1: SSN {Ename, Bdate, Address, Dnumber,
Dname, DMGR-SSN} FD2: Dnumber {Dname, DMGR-SSN} Emp-Dept is in 1NF, 2NF, but because of
SSN Dnumber and Dnumber Dname and Dname is a nonprime attribute, and Dnumber is not a superkey, Emp-Dept is not in 3NF.
To transform Emp-Dept into 3NF:To transform Emp-Dept into 3NF: Emp(Enam, SSN, Bdate, Address, Dnumber) Dept(Dnumber, Dname, DMG-SSN)

10.64
Third Normal Form (3NF)Third Normal Form (3NF)
Employees (SSN, Name, Age, Salary, Dept_name, Dept_manager_SSN).
Employees is in 2NF since SSN is the only candidate key and every
attribute is fully dependent on it.
Employees is not in 3NF because Dept_name Dept_manager_SSN

10.65
Third Normal Form (3NF)Third Normal Form (3NF)
LOTS(LOTS(Property-ID#Property-ID#, , County-Name, Lot#County-Name, Lot#, Area, Price, , Area, Price, Tax-Rate)Tax-Rate) FD1: Property-ID# {County-Name, Lot#, Area,
Price, Tax-Rate} FD2: {County-Name, Lot#} {Property-ID#, Area,
Price, Tax-Rate} FD3: County-Name Tax-Rate FD4: Area Price
2 candidate keys: {Property-ID#},{County-Name, Lot#}2 candidate keys: {Property-ID#},{County-Name, Lot#} LOTS is not in 2NF, because of LOTS is not in 2NF, because of County-Name County-Name Tax- Tax-
RateRate Tax-Rate is partially dependent on the candidate key
{County-Name, Lot#}. 2NF:2NF:
LOTS1(Property-ID#, County-Name, LOT#, Area, Price)
LOTS2(County-Name, Tax-Rate)

10.66
Third Normal Form (3NF)Third Normal Form (3NF)
The relation LOTS1 is not in 3NF, because of The relation LOTS1 is not in 3NF, because of Area Area Price Price Area is not a superkey and Price is not prime
attribute 3NF:3NF:
LOTS1A(Property-ID#, County-Name, Lot#, Area)
LOTS1B(Area, Price) LOT2(County-Name, Tax-Rate)
The above relation schemas are in 3NFThe above relation schemas are in 3NF

10.67
Boyce-Codd Normal Form (BCNF)Boyce-Codd Normal Form (BCNF)
Assume that we have thousands of lots, but two-Assume that we have thousands of lots, but two-counties:counties: Marion county and Liberty county. Lot areas in Marion county are
.5, .6, .7, .8, .9 and 1 acres Lot areas in Liberty county are
1.1,1.2, …, 1.9, 2.0 acres In this case we have :In this case we have : AREA AREA County- County-
NameName LOTS1A(LOTS1A(Property-ID#Property-ID#, , County-Name, Lot#,County-Name, Lot#,
Area)Area) FD5: Area County-Name Still in 3NF , since County-Name is a prime
attribute

10.68
Boyce-Codd Normal Form (BCNF)Boyce-Codd Normal Form (BCNF)
A relation schema R is in A relation schema R is in BCNFBCNF if whenever a if whenever a FD FD X X A A holds in R, then X is a superkey of R. holds in R, then X is a superkey of R.
R is in BCNF if for every non-trivial FD, the R is in BCNF if for every non-trivial FD, the left left sideside is a superkey. is a superkey.
LOTS1A-X(Property-ID#, Area, Lot#) LOTS1A-Y(Area, County-Name)
To describe a relation schema R as “good” it To describe a relation schema R as “good” it should be at least in 3NF (general) or BCNFshould be at least in 3NF (general) or BCNF
If R is in BCNF, then R is also in 3NFIf R is in BCNF, then R is also in 3NF However, R in 3NF R in BCNFHowever, R in 3NF R in BCNF

10.69
Normal Forms: SummaryNormal Forms: Summary
Relationships between different NFs.Relationships between different NFs.
1NF2NF
3NFBCNF

10.70
Normal Forms: SummaryNormal Forms: Summary
1NF: 1NF: Attributes should be single-valued and have
atomic domain Normalize into 1NF:
Form a new relations for each non-atomic attribute
2NF:2NF: 2NF removes some insertion anomalies and
deletion anomalies. 2NF removes some redundancies, namely,
redundancies caused by partial dependencies on key.

10.71
Normal Forms: SummaryNormal Forms: Summary
3NF:3NF: 3NF removes all insertion anomalies and
deletion anomalies. 3NF also removes some redundancies caused
by transitive dependencies.
BCNF:BCNF: achieves all achieved by 3NF. BCNF removes all redundancies caused by
FDs.


















